- Градиентный бустинг

Содержание
- 2. Алгоритм градиентного бустинга
- 3. Градиентный бустинг над деревьями
- 4. Градиентный бустинг над решаюшими деревьями
- 5. XGBoost XGBoost (eXtreme Gradient Boosting) представляет собой усовершенствованную реализацию алгоритма градиентного бустинга. XGBoost обладает высокой предсказательной
- 6. LightGBM LightGBM – это библиотека градиентного бустинга, которая выращивает деревья вертикально, в то время как XGBoost
- 7. CatBoost CatBoost (происходит от двух слов category и boosting) может автоматически обрабатывать категориальные переменные, при этом
- 8. Сравнение LightGBM и XGBoost Иллюстрация работы XGBoost. Иллюстрация работы LightGBM
- 9. LightGBM реализация from lightgbm import LGBMClassifier Создаем классификатор model = LGBMClassifier(n_estimators=40, num_leaves=255, learning_rate=0.1) Обучаемся model.fit( X_train,
- 10. CatBoost реализация from catboost import CatBoostClassifier Создаем классификатор best_model = CatBoostClassifier( iterations=500, depth=4, l2_leaf_reg = 4.0,
- 12. Скачать презентацию

Алгоритм градиентного бустинга
Алгоритм градиентного бустинга

Градиентный бустинг над деревьями
Градиентный бустинг над деревьями

Градиентный бустинг над решаюшими деревьями
Градиентный бустинг над решаюшими деревьями

XGBoost
XGBoost (eXtreme Gradient Boosting) представляет собой усовершенствованную реализацию алгоритма градиентного бустинга.
XGBoost
XGBoost (eXtreme Gradient Boosting) представляет собой усовершенствованную реализацию алгоритма градиентного бустинга.

LightGBM
LightGBM – это библиотека градиентного бустинга, которая выращивает деревья вертикально, в
LightGBM
LightGBM – это библиотека градиентного бустинга, которая выращивает деревья вертикально, в

CatBoost
CatBoost (происходит от двух слов category и boosting) может автоматически обрабатывать
CatBoost
CatBoost (происходит от двух слов category и boosting) может автоматически обрабатывать

Сравнение LightGBM и XGBoost
Иллюстрация работы XGBoost.
Иллюстрация работы LightGBM
Сравнение LightGBM и XGBoost
Иллюстрация работы XGBoost.
Иллюстрация работы LightGBM

LightGBM реализация
from lightgbm import LGBMClassifier
Создаем классификатор
model = LGBMClassifier(n_estimators=40, num_leaves=255, learning_rate=0.1)
Обучаемся
model.fit( X_train,
LightGBM реализация
from lightgbm import LGBMClassifier
Создаем классификатор
model = LGBMClassifier(n_estimators=40, num_leaves=255, learning_rate=0.1)
Обучаемся
model.fit( X_train,

CatBoost реализация
from catboost import CatBoostClassifier
Создаем классификатор
best_model = CatBoostClassifier( iterations=500, depth=4,
CatBoost реализация
from catboost import CatBoostClassifier
Создаем классификатор
best_model = CatBoostClassifier( iterations=500, depth=4,
 Аксиомы стереометрии
Аксиомы стереометрии Нахождение дроби от числа
Нахождение дроби от числа Определенный интеграл
Определенный интеграл Числовий вираз. Числові рівності та нерівності
Числовий вираз. Числові рівності та нерівності Аксиомы стереометрии 10 класс
Аксиомы стереометрии 10 класс Сложение обыкновенных дробей. Графический диктант 4. 5 класс
Сложение обыкновенных дробей. Графический диктант 4. 5 класс Задания на устный счет
Задания на устный счет Свойства степени с натуральным показателем (тренажер). 7 класс
Свойства степени с натуральным показателем (тренажер). 7 класс Презентация по математике "Портфоліо" - скачать
Презентация по математике "Портфоліо" - скачать  Интерактивный тренажер Тригонометрические уравнения
Интерактивный тренажер Тригонометрические уравнения Презентация по математике "Приемы устного умножения и деления" - скачать
Презентация по математике "Приемы устного умножения и деления" - скачать  Основные типы задач по усвоению общего функционального материала
Основные типы задач по усвоению общего функционального материала Дифференцированный подход в обучении учащихся при подготовке к ГИА
Дифференцированный подход в обучении учащихся при подготовке к ГИА Игра на поиск логических пар
Игра на поиск логических пар Туындының көмегімен функцияны зерттеу және оның графигін салу
Туындының көмегімен функцияны зерттеу және оның графигін салу Сложение обыкновенных дробей. Графический диктант 4. 5 класс
Сложение обыкновенных дробей. Графический диктант 4. 5 класс Формулы сокращенного умнажения
Формулы сокращенного умнажения ГИА. Задание 19
ГИА. Задание 19 Новые типы обратных связей в системах автоматического управления
Новые типы обратных связей в системах автоматического управления Основы композиции. Правила заполнения кадра
Основы композиции. Правила заполнения кадра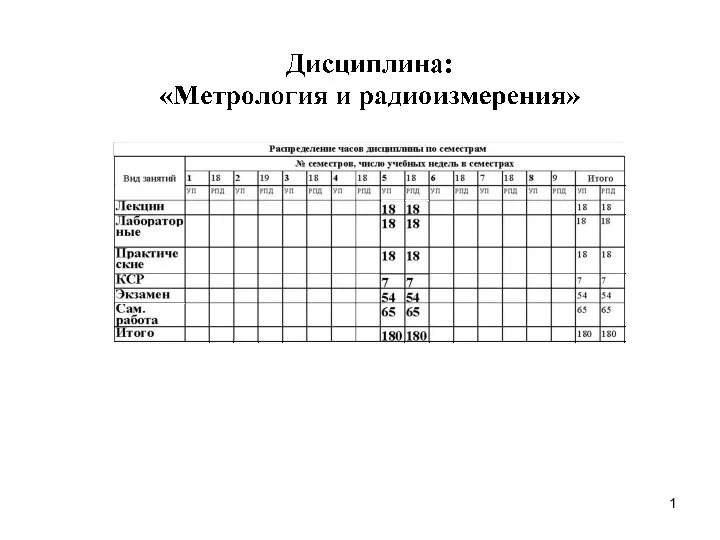 Основные понятия и термины метрологии
Основные понятия и термины метрологии Аттестационная работа. Исследовательская деятельность учащихся при изучении математики
Аттестационная работа. Исследовательская деятельность учащихся при изучении математики Решение прикладных задач
Решение прикладных задач Сантиметр. Измерительные интструменты
Сантиметр. Измерительные интструменты Умножение и деление десятичных дробей на натуральные числа. Урок-сказка. 5 класс
Умножение и деление десятичных дробей на натуральные числа. Урок-сказка. 5 класс Методика изучения трехмерных геометрических фигур. Тела вращения
Методика изучения трехмерных геометрических фигур. Тела вращения Сложение и вычитание двузначных чисел с переходом через десяток
Сложение и вычитание двузначных чисел с переходом через десяток На ошибках учатся… Не решая квадратные уравнения, определить знаки его корней
На ошибках учатся… Не решая квадратные уравнения, определить знаки его корней