- Кластерный анализ

Содержание
- 2. ПОНЯТИЕ КЛАСТЕРИЗАЦИИ Во многих прикладных задачах измерять степень сходства объектов существенно проще, чем формировать признаковые описания.
- 3. ЗАДАЧИ И УСЛОВИЯ КЛАСТЕРИЗАЦИИ Понять структуру множества объектов, разбив его на группы схожих объектов. Упростить дальнейшую
- 4. ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ Распознавание образов
- 5. ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ Распознавание образов
- 6. ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ Группировка объектов
- 7. ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ Классификация результатов поиска
- 9. ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ Сегментация изображений
- 10. ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ Сегментация изображений
- 11. ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ Кластеризация результатов поиска — используется для «интеллектуальной» группировки результатов при поиске файлов, веб-сайтов, других
- 12. ОБЩИЙ АЛГОРИТМ КЛАСТЕРИЗАЦИИ Выбор меры близости; Выбор алгоритма кластеризации; Представление полученных результатов;
- 13. МЕРЫ БЛИЗОСТИ Коэффициент сходства (также мера сходства, индекс сходства) — безразмерный показатель, применяемый для количественного определения
- 14. Обобщенный алгоритм Ллойда (Generalized Lloyd) или алгоритм k-средних (k-means) O(k*n*?) Метод k-средних – это метод кластерного
- 15. Обобщенный алгоритм Ллойда (Generalized Lloyd) или алгоритм k-средних (k-means) O(k*n*?) 2. Относим наблюдения к тем кластерам,
- 16. Обобщенный алгоритм Ллойда (Generalized Lloyd) или алгоритм k-средних (k-means) O(k*n*?)
- 17. Кластеризация объединением ближайших соседей (pairwise nearest neighbor) O(n2) Дано: n точек xi в многомерном пространстве, которые
- 18. Задача – разбить эти точки на два кластера
- 20. Скачать презентацию

ПОНЯТИЕ КЛАСТЕРИЗАЦИИ
Во многих прикладных задачах измерять степень сходства объектов существенно проще,
ПОНЯТИЕ КЛАСТЕРИЗАЦИИ
Во многих прикладных задачах измерять степень сходства объектов существенно проще,

ЗАДАЧИ И УСЛОВИЯ КЛАСТЕРИЗАЦИИ
Понять структуру множества объектов, разбив его на группы
ЗАДАЧИ И УСЛОВИЯ КЛАСТЕРИЗАЦИИ
Понять структуру множества объектов, разбив его на группы
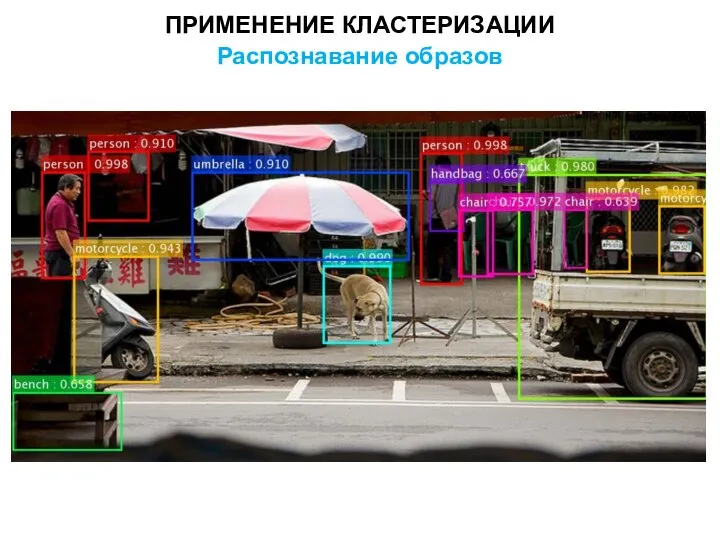
ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ
Распознавание образов
ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ
Распознавание образов
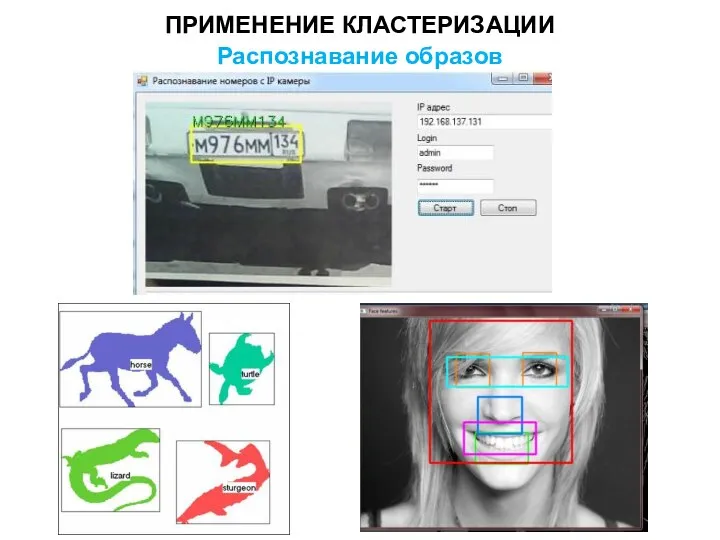
ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ
Распознавание образов
ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ
Распознавание образов
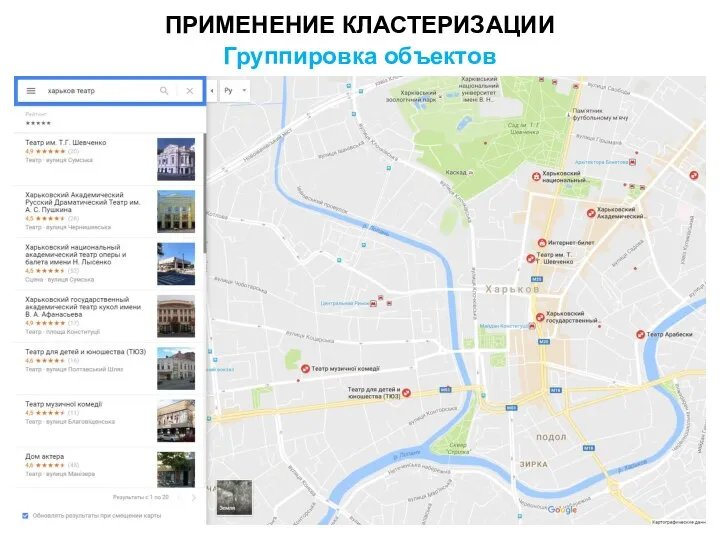
ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ
Группировка объектов
ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ
Группировка объектов

ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ
Классификация результатов поиска
ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ
Классификация результатов поиска

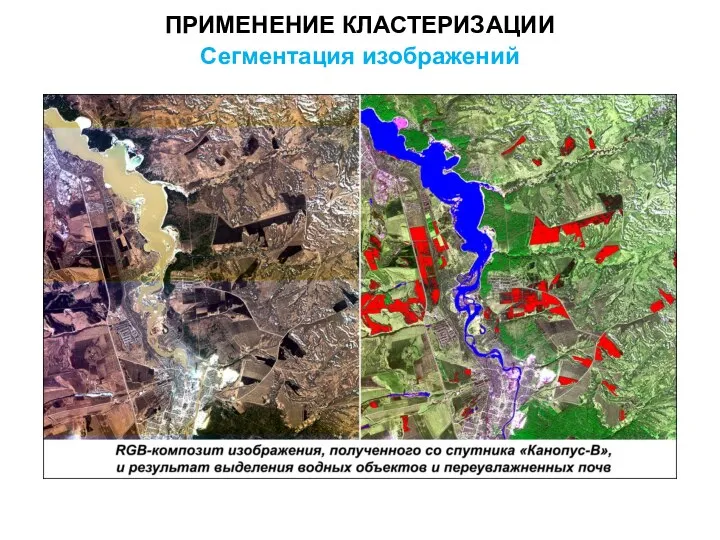
ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ
Сегментация изображений
ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ
Сегментация изображений

ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ
Сегментация изображений
ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ
Сегментация изображений

ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ
Кластеризация результатов поиска — используется для «интеллектуальной» группировки результатов при
ПРИМЕНЕНИЕ КЛАСТЕРИЗАЦИИ
Кластеризация результатов поиска — используется для «интеллектуальной» группировки результатов при

ОБЩИЙ АЛГОРИТМ КЛАСТЕРИЗАЦИИ
Выбор меры близости;
Выбор алгоритма кластеризации;
Представление полученных результатов;
ОБЩИЙ АЛГОРИТМ КЛАСТЕРИЗАЦИИ
Выбор меры близости;
Выбор алгоритма кластеризации;
Представление полученных результатов;

МЕРЫ БЛИЗОСТИ
Коэффициент сходства (также мера сходства, индекс сходства) — безразмерный показатель,
МЕРЫ БЛИЗОСТИ
Коэффициент сходства (также мера сходства, индекс сходства) — безразмерный показатель,

Обобщенный алгоритм Ллойда (Generalized
Lloyd) или алгоритм k-средних (k-means) O(k*n*?)
Метод k-средних
Обобщенный алгоритм Ллойда (Generalized
Lloyd) или алгоритм k-средних (k-means) O(k*n*?)
Метод k-средних

Обобщенный алгоритм Ллойда (Generalized
Lloyd) или алгоритм k-средних (k-means) O(k*n*?)
2. Относим
Обобщенный алгоритм Ллойда (Generalized
Lloyd) или алгоритм k-средних (k-means) O(k*n*?)
2. Относим
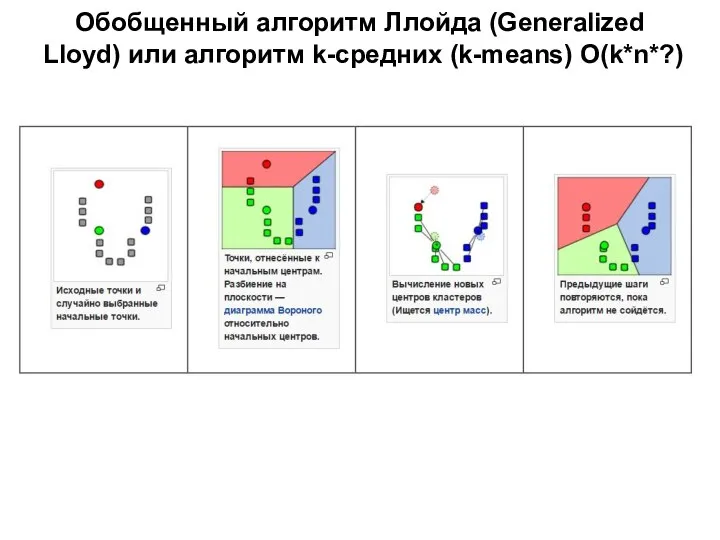
Обобщенный алгоритм Ллойда (Generalized
Lloyd) или алгоритм k-средних (k-means) O(k*n*?)
Обобщенный алгоритм Ллойда (Generalized
Lloyd) или алгоритм k-средних (k-means) O(k*n*?)

Кластеризация объединением ближайших соседей (pairwise nearest neighbor) O(n2)
Дано: n точек xi
Кластеризация объединением ближайших соседей (pairwise nearest neighbor) O(n2)
Дано: n точек xi
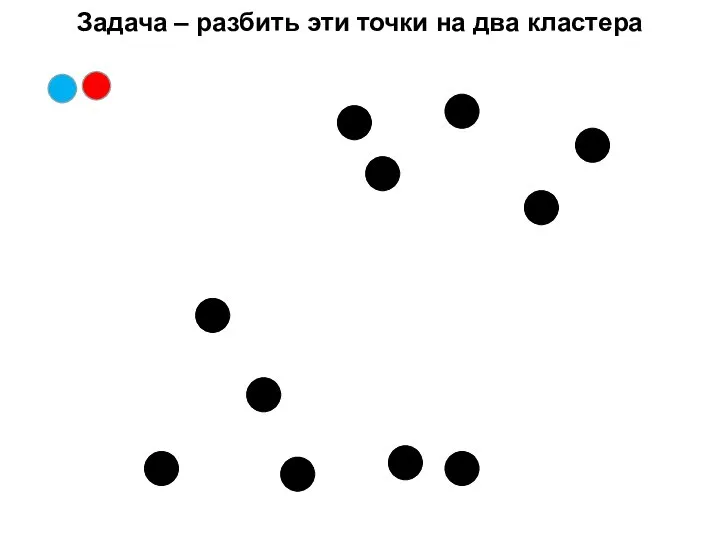
Задача – разбить эти точки на два кластера
Задача – разбить эти точки на два кластера
 В гостях у пчёлки Майи (игра по теме Состав чисел первого десятка)
В гостях у пчёлки Майи (игра по теме Состав чисел первого десятка) Доминино
Доминино Сфера. Уравнение сферы
Сфера. Уравнение сферы Повторение. Линейное уравнение с одной переменной
Повторение. Линейное уравнение с одной переменной Теорема Пифагора. Пифагор и его школа
Теорема Пифагора. Пифагор и его школа Квадраттық функцияның графигін салу алгоритмі
Квадраттық функцияның графигін салу алгоритмі Презентация на тему Тригонометрические функции числового аргумента.
Презентация на тему Тригонометрические функции числового аргумента. Медианы, биссектрисы и высоты треугольника
Медианы, биссектрисы и высоты треугольника Новые мерки и умножение урок 22, с. 64-66 учебник Петерсон Л.Г.
Новые мерки и умножение урок 22, с. 64-66 учебник Петерсон Л.Г. Урок геометрии в 7 классе «Искусство рассуждать»
Урок геометрии в 7 классе «Искусство рассуждать» Boolean algebra. Logic operations. Formula and their conversion
Boolean algebra. Logic operations. Formula and their conversion Схема решения инженерной задачи
Схема решения инженерной задачи Квадратные уравнения МОУ «Москаленский лицей»
Квадратные уравнения МОУ «Москаленский лицей»  Площадь треугольника
Площадь треугольника Преобразование выражений, содержащих квадратные корни. 8 класс
Преобразование выражений, содержащих квадратные корни. 8 класс Пересечение поверхностей
Пересечение поверхностей Действия с рациональными числами (интерактивный тест) Учитель математики Бадюк Ольга Ярославна, МКОУ «Москаленский лицей»
Действия с рациональными числами (интерактивный тест) Учитель математики Бадюк Ольга Ярославна, МКОУ «Москаленский лицей» Скачать презентацию Умножение
Скачать презентацию Умножение  Презентация по математике "Интересная математика для 6 класса" - скачать бесплатно
Презентация по математике "Интересная математика для 6 класса" - скачать бесплатно Площадь криволинейной трапеции и интеграл
Площадь криволинейной трапеции и интеграл Логические задачи
Логические задачи Симплекс-метод решения задачи линейного программирования
Симплекс-метод решения задачи линейного программирования Урок математики 3 класс Умножение числа 8, умножение на 8
Урок математики 3 класс Умножение числа 8, умножение на 8 Числа Шахерезады
Числа Шахерезады Зачем мы изучаем логарифмы
Зачем мы изучаем логарифмы Решение задач по готовым чертежам. Теорема Пифагора
Решение задач по готовым чертежам. Теорема Пифагора Треугольники. Практика. Первый уровень
Треугольники. Практика. Первый уровень Исследование закона распределения погрешностей средств радиотехнических измерений
Исследование закона распределения погрешностей средств радиотехнических измерений