- Архитектура современного компьютера

Содержание
- 2. Основные модели параллельного выполнения программы на многопроцессорных компьютерах: Модель передачи сообщений MPI Модель параллелизма по данным
- 3. Модель передачи сообщений. MPI Параллельная программа представляет собой множество процессов, каждый из которых имеет собственное локальное
- 4. Основные достоинства MPI (по сравнению с интерфейсами других коммуникационных библиотек) Возможность использования в языках Фортран, С,
- 5. Недостатки MPI слишком громоздкий и сложный интерфейс для прикладного программиста, а также для реализации ------------------------------------------------------------ В
- 6. MPI-2 Появившийся в 1997 проект стандарта MPI-2 выглядит еще более громоздким и неподъемным для полной реализации.
- 8. Модель параллелизма по данным. HPF Отсутствие понятия процесса и, как следствие, явная передача сообщений или явная
- 9. Достоинства модели параллелизма Параллелизм по данным – естественный параллелизм вычислительных задач. В модели параллелизма по данным
- 10. Модель с общей памятью OpenMP Процессы разделяют общее адресное пространство Программист должен явно специфицировать общие данные
- 11. Механизм выполнения Одним из механизмов выполнения параллельных процессов стало многонитевое программирование «легковесных процессов», для которых не
- 12. OpenMP реализует параллельные вычисления с помощью многопоточности, в которой «главный» поток создает набор подчиненных потоков и
- 13. Какие преимущества OpenMP дает разработчику? Идеально подходит для разработчиков, желающих быстро распараллелить свои вычислительные программы с
- 14. Недостатки OpenMP Ограниченность его области применения (мультипроцессоры и DSM-кластеры) Имеющиеся в нем средства распараллеливания циклов с
- 15. На примере простой программы умножения матриц можно увидеть, как использовать OpenMP для параллелизации программы. Рассмотрим следующий
- 16. #include #include “mpi.h” int main (int argc,char* argv[]) { int rank, n, i, message; MPI_Status status;
- 17. #include “mpi.h” // # include // #include // Int main(int argc,char**argv) Int myrank,np,I,n,y,s1,s2,x(20),a(10),b(10),m=n/2; File *dat,*res; dat=fopen(“d:
- 19. Скачать презентацию

Основные модели параллельного выполнения программы на многопроцессорных компьютерах:
Модель передачи сообщений MPI
Модель
Основные модели параллельного выполнения программы на многопроцессорных компьютерах:
Модель передачи сообщений MPI
Модель
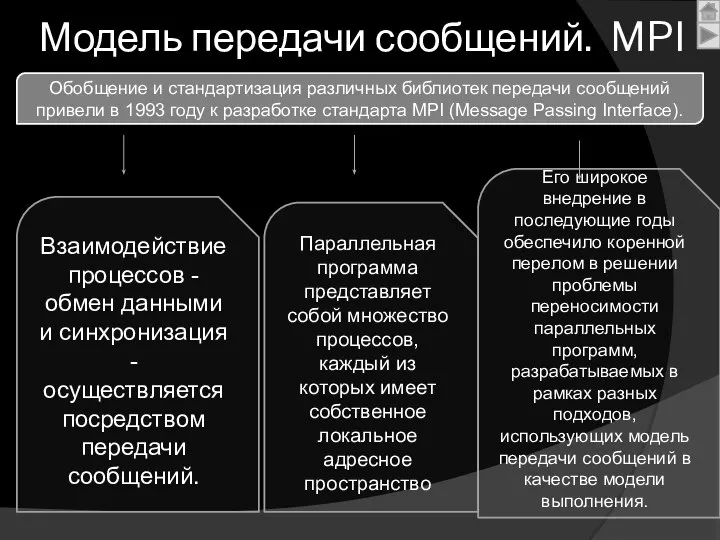
Модель передачи сообщений. MPI
Параллельная программа представляет собой множество процессов, каждый из
Модель передачи сообщений. MPI
Параллельная программа представляет собой множество процессов, каждый из

Основные достоинства MPI
(по сравнению с интерфейсами других коммуникационных библиотек)
Возможность использования в
Основные достоинства MPI
(по сравнению с интерфейсами других коммуникационных библиотек)
Возможность использования в

Недостатки MPI
слишком громоздкий и сложный интерфейс для прикладного программиста, а также
Недостатки MPI
слишком громоздкий и сложный интерфейс для прикладного программиста, а также

MPI-2
Появившийся в 1997 проект стандарта MPI-2 выглядит еще более громоздким и
MPI-2
Появившийся в 1997 проект стандарта MPI-2 выглядит еще более громоздким и
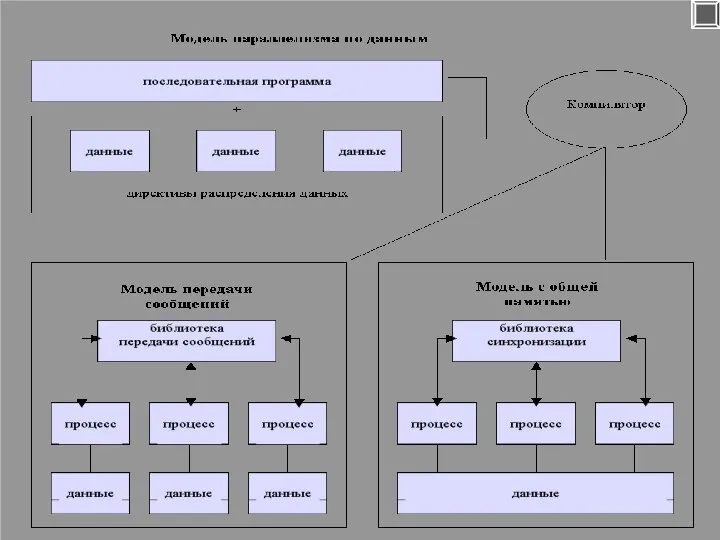

Модель параллелизма по данным. HPF
Отсутствие понятия процесса и, как следствие,
Модель параллелизма по данным. HPF
Отсутствие понятия процесса и, как следствие,

Достоинства модели параллелизма
Параллелизм по данным – естественный параллелизм вычислительных задач.
В
Достоинства модели параллелизма
Параллелизм по данным – естественный параллелизм вычислительных задач.
В

Модель с общей памятью OpenMP
Процессы разделяют общее адресное пространство
Программист должен явно
Модель с общей памятью OpenMP
Процессы разделяют общее адресное пространство
Программист должен явно

Механизм выполнения
Одним из механизмов выполнения параллельных процессов стало многонитевое программирование «легковесных
Механизм выполнения
Одним из механизмов выполнения параллельных процессов стало многонитевое программирование «легковесных

OpenMP реализует параллельные вычисления с помощью многопоточности, в которой «главный»
OpenMP реализует параллельные вычисления с помощью многопоточности, в которой «главный»
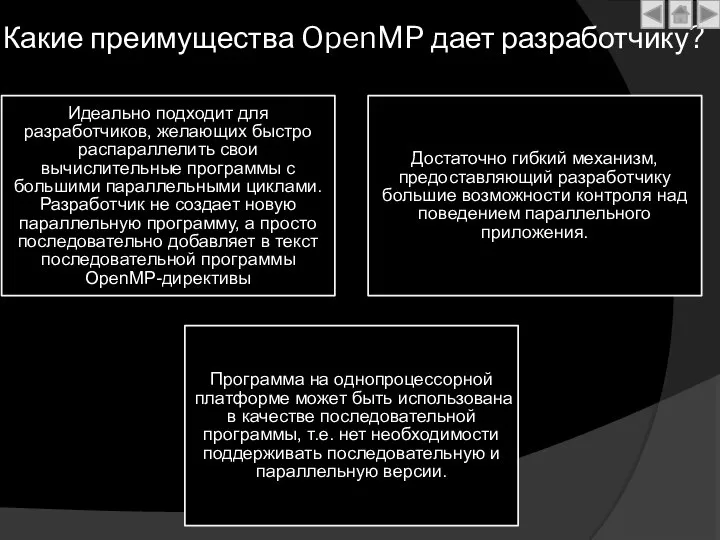
Какие преимущества OpenMP дает разработчику?
Идеально подходит для разработчиков, желающих быстро распараллелить
Какие преимущества OpenMP дает разработчику?
Идеально подходит для разработчиков, желающих быстро распараллелить

Недостатки OpenMP
Ограниченность его области применения (мультипроцессоры и DSM-кластеры)
Имеющиеся в нем средства
Недостатки OpenMP
Ограниченность его области применения (мультипроцессоры и DSM-кластеры)
Имеющиеся в нем средства

На примере простой программы умножения матриц можно увидеть, как использовать OpenMP
На примере простой программы умножения матриц можно увидеть, как использовать OpenMP
![#include #include “mpi.h” int main (int argc,char* argv[]) { int rank,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1296800/slide-15.jpg)
#include
#include “mpi.h”
int main (int argc,char* argv[])
{ int rank, n, i,
#include
#include “mpi.h”
int main (int argc,char* argv[])
{ int rank, n, i,
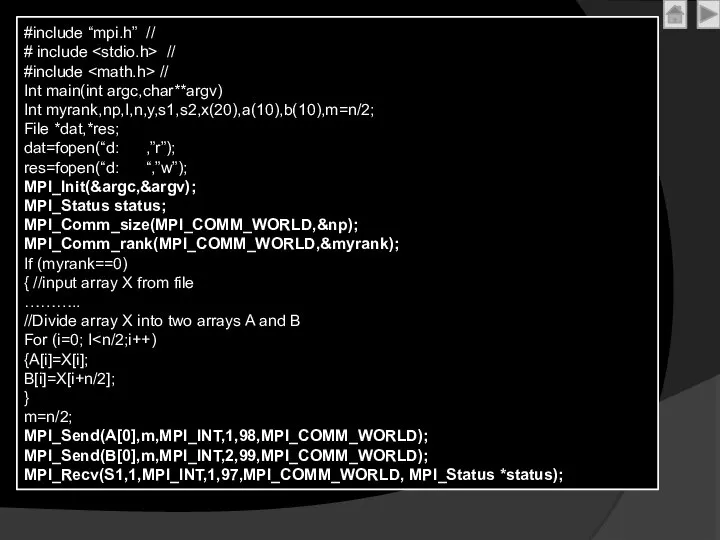
#include “mpi.h” //
# include //
#include //
Int main(int argc,char**argv)
Int
#include “mpi.h” //
# include
#include
Int main(int argc,char**argv)
Int
 РОЛЬ ГОСУДАРСТВА В ЭКОНОМИКЕ Мамыкина И.Г., учитель истории и обществознания МОУ СОШ № 102 Волгограда 2013 год
РОЛЬ ГОСУДАРСТВА В ЭКОНОМИКЕ Мамыкина И.Г., учитель истории и обществознания МОУ СОШ № 102 Волгограда 2013 год Корректировка фигуры одеждой. Типы фигуры. Фасон одежды
Корректировка фигуры одеждой. Типы фигуры. Фасон одежды Минералы
Минералы  Стилистическая эволюция английской мебели во второй половине XVIII в
Стилистическая эволюция английской мебели во второй половине XVIII в Средства подключения конечных пользователей к информационной системе. Тема 20
Средства подключения конечных пользователей к информационной системе. Тема 20 Организация проектной деятельности на уроках Учитель Чуб Алла Ахметовна
Организация проектной деятельности на уроках Учитель Чуб Алла Ахметовна Презентация Система источников международного права : понятие, виды, применение в практике международных отношений
Презентация Система источников международного права : понятие, виды, применение в практике международных отношений  Бытие
Бытие Конституционно-правовой статус несовершеннолетних
Конституционно-правовой статус несовершеннолетних Сертифицированные спасательные жилеты "Comfort"
Сертифицированные спасательные жилеты "Comfort" Развитие системы общественного контроля в Российской Федерации на современном этапе
Развитие системы общественного контроля в Российской Федерации на современном этапе Билл Гейтс
Билл Гейтс  Право Нового времени
Право Нового времени ОРУЖИЕ ПОРАЖАЮЩЕЕ ИЗЛУЧЕНИЕМ
ОРУЖИЕ ПОРАЖАЮЩЕЕ ИЗЛУЧЕНИЕМ Цифровая логика
Цифровая логика Що таке грунт. Охорона грунту - презентация для начальной школы_
Що таке грунт. Охорона грунту - презентация для начальной школы_ Проблемы исторической лексикологии
Проблемы исторической лексикологии Зарождение первобытной культуры
Зарождение первобытной культуры Хет-Ка-Птах «дом Ка Птаха». Птах — одно из имён Бога-Творца
Хет-Ка-Птах «дом Ка Птаха». Птах — одно из имён Бога-Творца Пушистый ёжик
Пушистый ёжик Программа индивидуального развития Бахитова Александра, ученика МОУ «Батыревская средняя общеобразовательная школа №2» Баты
Программа индивидуального развития Бахитова Александра, ученика МОУ «Батыревская средняя общеобразовательная школа №2» Баты Россия
Россия  Предпринимательская экосистема Пермь 2010
Предпринимательская экосистема Пермь 2010 Государственное образовательное учреждение высшего профессионального образования «Российская таможенная академия» КУРСОВА
Государственное образовательное учреждение высшего профессионального образования «Российская таможенная академия» КУРСОВА Федеральное агентство по образованию Российской Федерации Челябинский государственный университет Институт Экономики отраслей,
Федеральное агентство по образованию Российской Федерации Челябинский государственный университет Институт Экономики отраслей, Анализ деятельности политического обозревателя Михаила Ремизова
Анализ деятельности политического обозревателя Михаила Ремизова Хронический панкреатит. Рак поджелудочной железы
Хронический панкреатит. Рак поджелудочной железы Иные участники уголовного судопроизводства
Иные участники уголовного судопроизводства