- Базы данных

Содержание
- 2. 6.1. История возникновения баз данных В широком аспекте понятие истории баз данных обобщается до истории любых
- 3. Оперативные сетевые базы данных появились в середине 1960-х. Операции над оперативными базами данных обрабатывались в интерактивном
- 4. 6.2. Основные понятия баз данных, виды моделей и структур данных Информационная система – это совокупность программно-аппаратных
- 5. База да́нных — представленная в объективной форме совокупность самостоятельных материалов (статей, расчетов, нормативных актов, судебных решений
- 6. База данных (БД)– организованная структура, предназначенная для хранения информации. Современные БД позволяют размещать в своих структурах
- 7. Виды моделей Наборы принципов, которые определяют организацию логической структуры хранения данных в базе, называются моделями данных.
- 8. В течение многих лет преимущественно использовались плоские таблицы (плоские БД) типа списков в Excel. В настоящее
- 9. Структурирование данных Структура данных (в информационном смысле) – это представление пользователя о данных, не зависящее от
- 10. Парадигматическое отношение представляет собой семантическое (смысловое) отношение, существующее между словами естественного или информационного языка. Оно также
- 11. Ассоциативные отношения бывают двух видов: отношение подчинения - соответствует родовидовому отношению между словами, понятиями или предметами
- 12. Двухиндексный идентификатор Xij идентифицирует двумерный массив и т.д. В упорядоченных таким образом массивах возникают отношения следования.
- 13. Более сложные, составные структуры данных, представленные в виде фиксированной системы понятий и правил для описания структуры,
- 14. Особенности иерархических моделей данных Верхний узел называется корнем, родовым или старшим узлом. Узлы, из которых выходят
- 15. Особенности сетевых моделей данных В сетевых моделях данных порожденный узел может иметь более одного исходного, т.е.
- 16. Реляционные модели данных предложены в 1970 г. Основаны на представлении данных в виде отношений, которые могут
- 17. Для описания отношений и манипуляций над ними в реляционной модели данных используется строгий математический язык, основанный
- 18. В состав большинства СУБД входят три основных компонента: командный язык, интерпретирующая система или компилятор для обработки
- 19. К числу СУБД реляционного типа относятся хорошо известные системы: Access, dBase, Clipper, FoxBASE, R:BASE, Paradox, FoxPro?
- 20. Основные функции СУБД: определение данных (описание структуры баз данных) обработка данных управление данными Прежде чем заносить
- 21. отношение «многие-ко-многим» - преподаватели и курсы лекций (преподаватель может читать несколько курсов, но и один курс
- 22. Любая СУБД позволяет выполнять четыре простейшие операции с данными: добавлять в таблицу одну или несколько записей;
- 23. 6.5. Базы данных с графической информацией Данные в БД хранятся в таблицах, связанных между собой с
- 24. Принципы проектирования: 1. В каждой ячейке располагается минимальная единица информации. 2. Локальность хранения данных: если значения
- 25. Примеры студенческих работ – Access Режим - конструктор
- 26. Режим – макет (1)
- 28. Различные виды макетов – вариант 2
- 30. Вариант 3
- 32. Вариант 4
- 34. Вариант 5
- 37. Вариант 6
- 38. 6.6. Процесс создания баз данных Концепцию, в рамках которой удобно и полезно рассматривать развитие системы БД
- 39. Принято рассматривать используемые для описания предметной области данные в виде трехуровневой схемы: внешнее представление, уровень реализации,
- 40. На концептуальном уровне определяют: сущности (личности, факты, объекты); атрибуты (данные, описывающие сущности); связи (отношения между атрибутами).
- 41. Фаза анализа и проектирования БД 1. Формулирование и анализ требований 2. Концептуальное проектирование 3. Проектирование реализации
- 43. Скачать презентацию

6.1. История возникновения баз данных
В широком аспекте понятие истории баз данных
6.1. История возникновения баз данных
В широком аспекте понятие истории баз данных

Оперативные сетевые базы данных появились в середине 1960-х. Операции над оперативными
Оперативные сетевые базы данных появились в середине 1960-х. Операции над оперативными

6.2. Основные понятия баз данных, виды моделей и структур данных
Информационная система
6.2. Основные понятия баз данных, виды моделей и структур данных
Информационная система

База да́нных — представленная в объективной форме совокупность самостоятельных материалов (статей, расчетов,
База да́нных — представленная в объективной форме совокупность самостоятельных материалов (статей, расчетов,

База данных (БД)– организованная структура, предназначенная для хранения информации. Современные БД
База данных (БД)– организованная структура, предназначенная для хранения информации. Современные БД

Виды моделей
Наборы принципов, которые определяют организацию логической структуры хранения данных в
Виды моделей
Наборы принципов, которые определяют организацию логической структуры хранения данных в

В течение многих лет преимущественно использовались плоские таблицы (плоские БД) типа
В течение многих лет преимущественно использовались плоские таблицы (плоские БД) типа

Структурирование данных
Структура данных (в информационном смысле) – это представление пользователя о
Структурирование данных
Структура данных (в информационном смысле) – это представление пользователя о

Парадигматическое отношение представляет собой семантическое (смысловое) отношение, существующее между словами естественного
Парадигматическое отношение представляет собой семантическое (смысловое) отношение, существующее между словами естественного

Ассоциативные отношения бывают двух видов: отношение подчинения - соответствует родовидовому отношению
Ассоциативные отношения бывают двух видов: отношение подчинения - соответствует родовидовому отношению

Двухиндексный идентификатор Xij идентифицирует двумерный массив и т.д.
В упорядоченных таким образом
Двухиндексный идентификатор Xij идентифицирует двумерный массив и т.д.
В упорядоченных таким образом

Более сложные, составные структуры данных, представленные в виде фиксированной системы понятий
Более сложные, составные структуры данных, представленные в виде фиксированной системы понятий
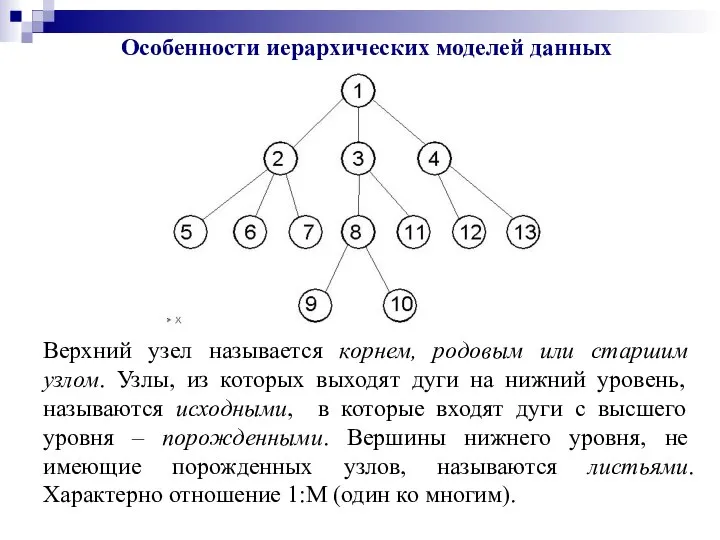
Особенности иерархических моделей данных
Верхний узел называется корнем, родовым или старшим узлом.
Особенности иерархических моделей данных
Верхний узел называется корнем, родовым или старшим узлом.
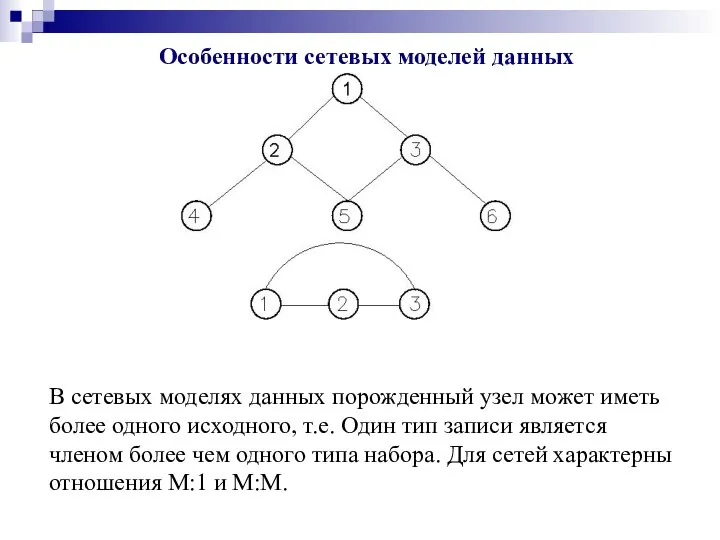
Особенности сетевых моделей данных
В сетевых моделях данных порожденный узел может иметь
Особенности сетевых моделей данных
В сетевых моделях данных порожденный узел может иметь

Реляционные модели данных предложены в 1970 г. Основаны на представлении данных
Реляционные модели данных предложены в 1970 г. Основаны на представлении данных
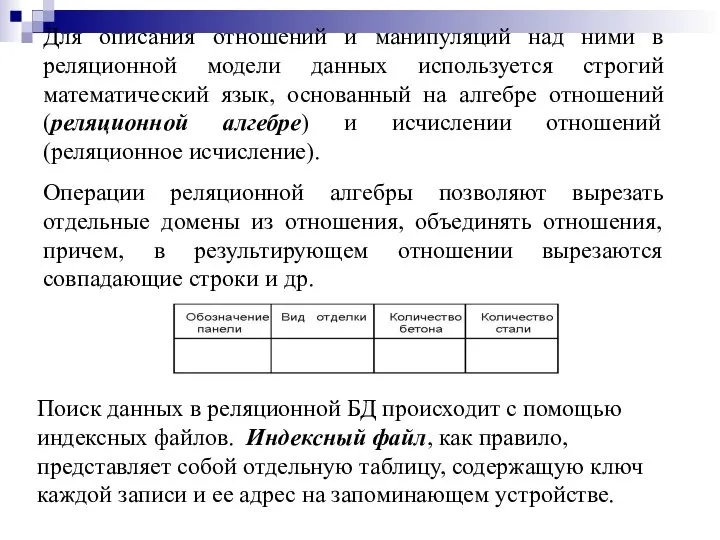
Для описания отношений и манипуляций над ними в реляционной модели данных
Для описания отношений и манипуляций над ними в реляционной модели данных

В состав большинства СУБД входят три основных компонента: командный язык, интерпретирующая
В состав большинства СУБД входят три основных компонента: командный язык, интерпретирующая

К числу СУБД реляционного типа относятся хорошо известные системы: Access, dBase,
К числу СУБД реляционного типа относятся хорошо известные системы: Access, dBase,

Основные функции СУБД:
определение данных (описание структуры баз данных)
обработка данных
управление данными
Прежде
Основные функции СУБД:
определение данных (описание структуры баз данных)
обработка данных
управление данными
Прежде

отношение «многие-ко-многим» - преподаватели и курсы лекций (преподаватель может читать несколько
отношение «многие-ко-многим» - преподаватели и курсы лекций (преподаватель может читать несколько

Любая СУБД позволяет выполнять четыре простейшие операции с данными:
добавлять в таблицу
Любая СУБД позволяет выполнять четыре простейшие операции с данными:
добавлять в таблицу

6.5. Базы данных с графической информацией
Данные в БД хранятся в таблицах, связанных между
6.5. Базы данных с графической информацией
Данные в БД хранятся в таблицах, связанных между

Принципы проектирования:
1. В каждой ячейке располагается минимальная единица информации.
2. Локальность
Принципы проектирования:
1. В каждой ячейке располагается минимальная единица информации.
2. Локальность
Примеры студенческих работ – Access
Режим - конструктор
Примеры студенческих работ – Access
Режим - конструктор
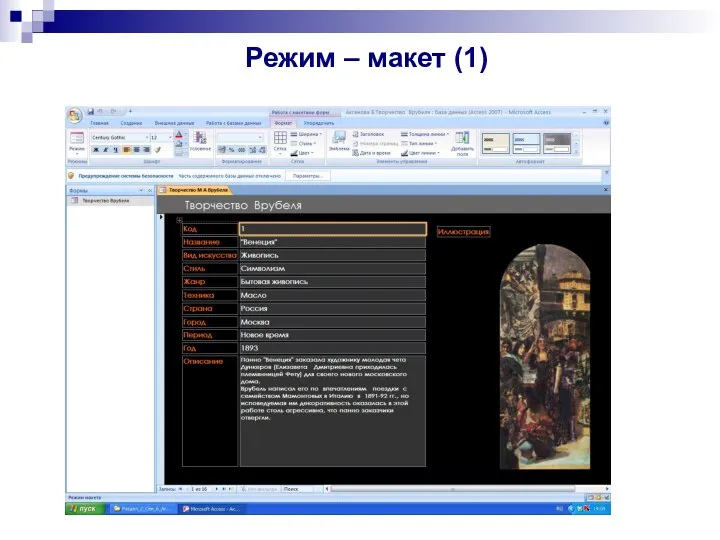
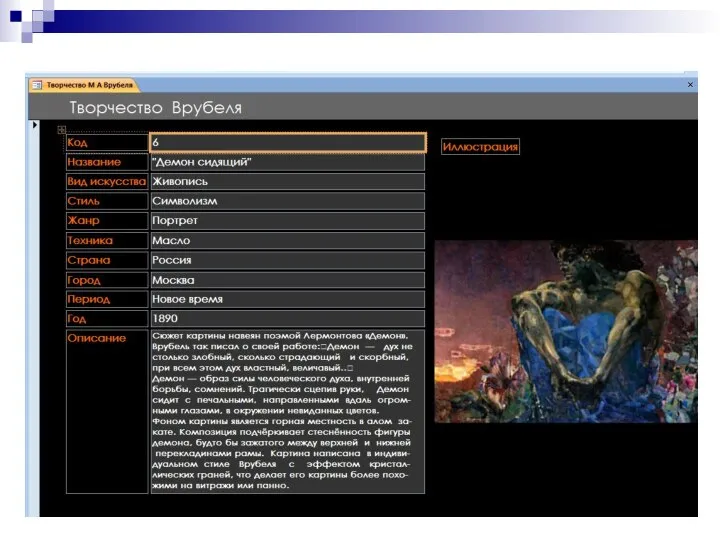
Режим – макет (1)
Режим – макет (1)
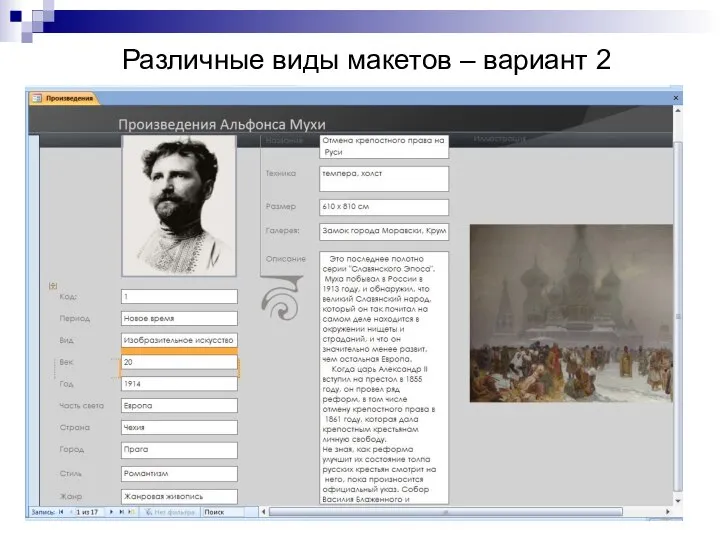
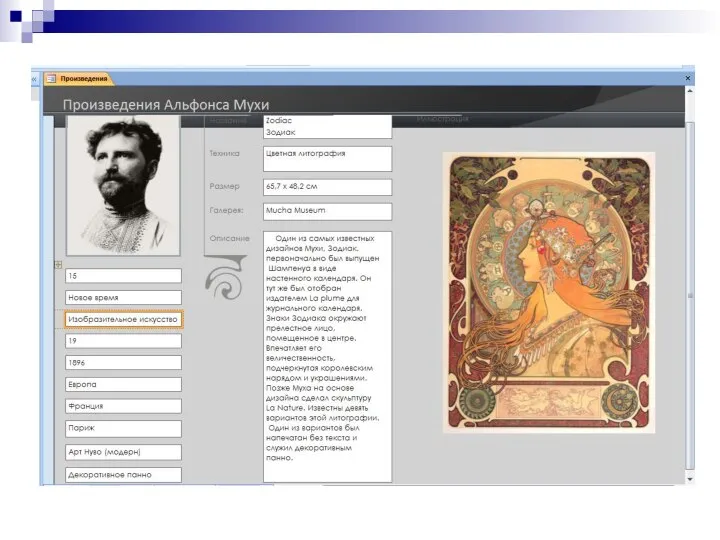
Различные виды макетов – вариант 2
Различные виды макетов – вариант 2
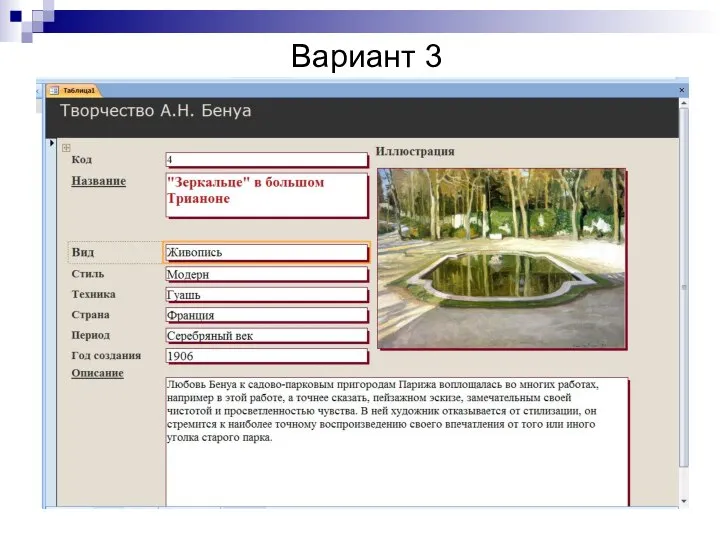
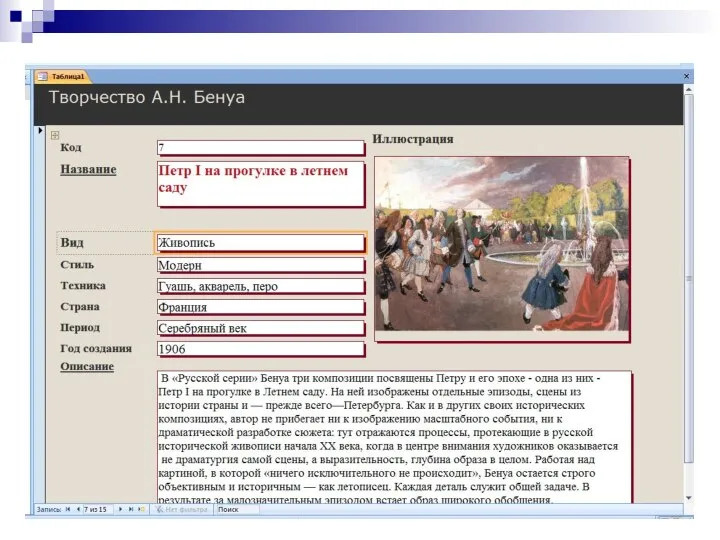
Вариант 3
Вариант 3
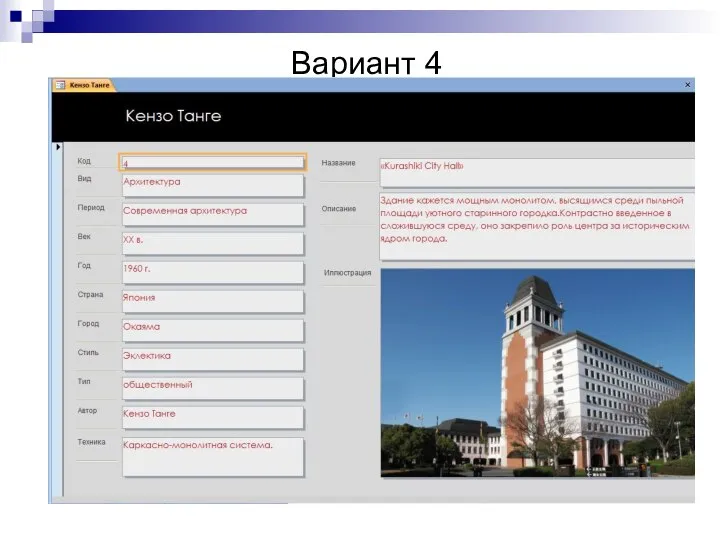
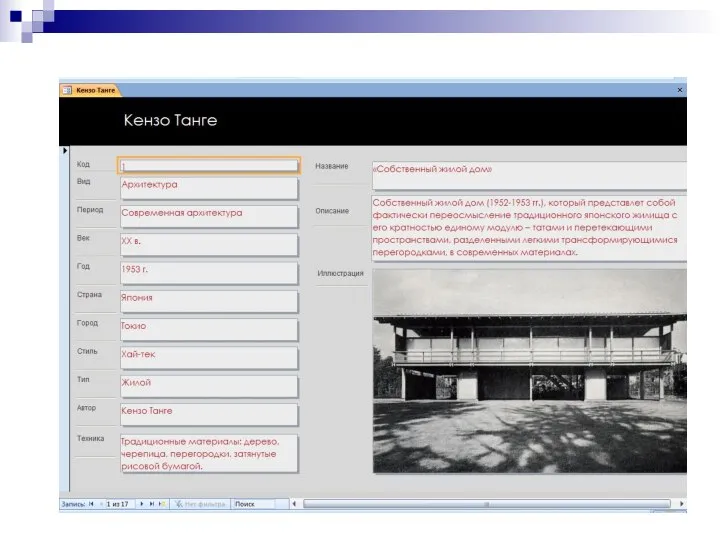
Вариант 4
Вариант 4
Вариант 5
Вариант 5
Вариант 6
Вариант 6

6.6. Процесс создания баз данных
Концепцию, в рамках которой удобно и полезно
6.6. Процесс создания баз данных
Концепцию, в рамках которой удобно и полезно
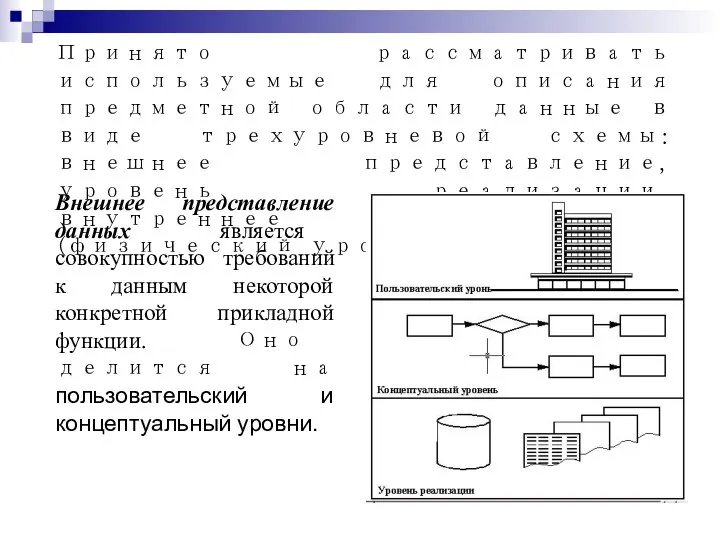
Принято рассматривать используемые для описания предметной области данные в виде трехуровневой
Принято рассматривать используемые для описания предметной области данные в виде трехуровневой

На концептуальном уровне определяют:
сущности (личности, факты, объекты); атрибуты (данные, описывающие
На концептуальном уровне определяют:
сущности (личности, факты, объекты); атрибуты (данные, описывающие
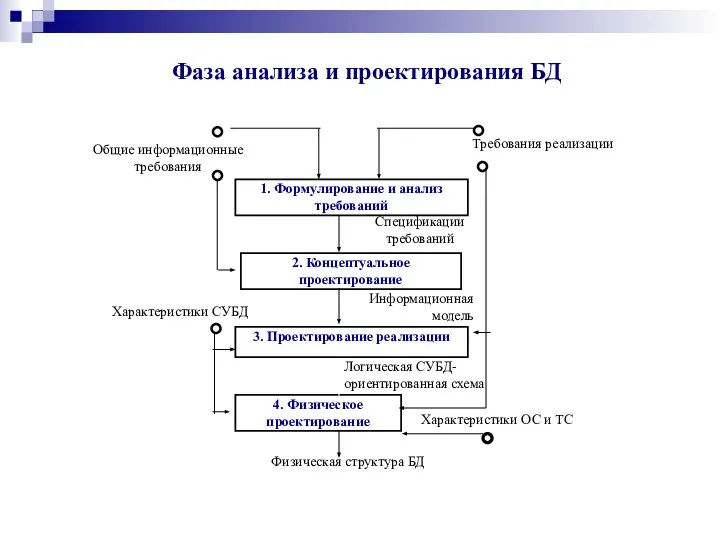
Фаза анализа и проектирования БД
1. Формулирование и анализ
требований
2. Концептуальное
проектирование
3. Проектирование
Фаза анализа и проектирования БД
1. Формулирование и анализ
требований
2. Концептуальное
проектирование
3. Проектирование
 Соединения заформовкой
Соединения заформовкой Достижения культуры народов Индии и Китая
Достижения культуры народов Индии и Китая Степень и её свойства - презентация по Алгебре
Степень и её свойства - презентация по Алгебре Verbes du 1 groupe
Verbes du 1 groupe ОФОРМЛЕНИЕ РЕЗЮМЕ Резюме - это краткий вывод из сказанного, написанного или прочитанного, сжато излагающий основные положе
ОФОРМЛЕНИЕ РЕЗЮМЕ Резюме - это краткий вывод из сказанного, написанного или прочитанного, сжато излагающий основные положе St. Patrick’s Day. History and traditions
St. Patrick’s Day. History and traditions Кабельні мережі. Загальні положення
Кабельні мережі. Загальні положення Презентация Функциональная логистика
Презентация Функциональная логистика Powracam do Boga
Powracam do Boga Современный образовательный процесс в начальной школе в контексте стандарта второго поколения Воронцов Алексей Борисович, канд
Современный образовательный процесс в начальной школе в контексте стандарта второго поколения Воронцов Алексей Борисович, канд Психологическая помощь в Ярославле. Консультация психиатра и помощь психотерапевта
Психологическая помощь в Ярославле. Консультация психиатра и помощь психотерапевта Понятие преступления в уголовном праве
Понятие преступления в уголовном праве Измерение параметров линии связи. Назначение и виды электрических измерений кабельных цепей
Измерение параметров линии связи. Назначение и виды электрических измерений кабельных цепей Сервлеты, компоненты приложений Java 2 Platform Enterprise Edition. (Лекция 17)
Сервлеты, компоненты приложений Java 2 Platform Enterprise Edition. (Лекция 17) Голосовая характеристика и культура речи
Голосовая характеристика и культура речи Предмет и задачи патофизиологии
Предмет и задачи патофизиологии Технология внедрения WMS системы на складе автозапчастей ООО “Консид Решения” Илья Шилов, руководитель отдела внедрения +7 (495) 729 83 70
Технология внедрения WMS системы на складе автозапчастей ООО “Консид Решения” Илья Шилов, руководитель отдела внедрения +7 (495) 729 83 70 JS2 (JavaScript)
JS2 (JavaScript) Культура стародавнього Єгипту
Культура стародавнього Єгипту Повторение прошедших тем. Логические выражения
Повторение прошедших тем. Логические выражения Основы программирования на Бейсике. Массивы
Основы программирования на Бейсике. Массивы Трудовые ресурсы предприятия
Трудовые ресурсы предприятия Система ввода/вывода языка программирования. Лекция 12
Система ввода/вывода языка программирования. Лекция 12 Городское поселение Ржавки Солнечногорского муниципального района Московской области
Городское поселение Ржавки Солнечногорского муниципального района Московской области Язык программирования Programming language
Язык программирования Programming language Петербругская мода во второй половине ХlХ века
Петербругская мода во второй половине ХlХ века доп образование и профилактическая работа
доп образование и профилактическая работа Политический режим
Политический режим