- Кластерные архитектуры

Содержание
- 2. Введение Кластер - это группа вычислительных машин, которые связаны между собою и функционируют как один узел
- 3. История развития кластерной архитектуры. Впервые в классификации вычислительных систем термин "кластер” определила DEC (Digital Equipment Corporation)
- 4. Общие требование к системам. Высокая готовность В случае сбоя программного обеспечения на одном узле приложение продолжает
- 5. Классификация в рамках распределения программно-аппаратных ресурсов Тесно связанная мультипроцессорная система Умеренно связанная мультипроцессорная система Слабо связанная
- 6. Функциональная классификиция. Высокоскоростные кластеры используются для задач, которые требуют значительной вычислительной мощности. Классическими областями, в которых
- 7. Системы высокой готовности. Все типы систем высокой готовности имеют общую цель - минимизацию времени простоя. Стоимость
- 8. Системы высокой готовности. Система с общими дисками может оказаться эффективным решением задачи, если в задаче удается
- 9. Системы высокой готовности. Shared Nothing Architecture Архитектура без разделения ресурсов, в которой каждый узел системы имеет
- 10. Высокоскоростные системы. Кластеры для высокопроизводительных вычислений предназначены для параллельных расчётов. Быстродействие High Performance кластерной системы определяется
- 11. Проблемы выполнения сети связи процессоров в кластерной системе. Архитектура кластерной системы (способ соединения процессоров друг с
- 12. Примеры гиперкубов Архитектура гиперкуба является второй по эффективности, но самой наглядной. Используются и другие топологии сетей
- 13. Архитектура кольца с полной связью по хордам (Chordal Ring) Наиболее эффективной является архитектура с топологией "толстого
- 14. Зарубежные разработки TOP500(июнь 2009) :
- 15. IBM-roadrunner Местоположение- Лос-Аламосская национальная лаборатория в Нью-Мексико, США 1 место TOP500 на июнь 2009 г. Пиковая
- 16. Cray Jaguar Местоположение- Национальный центр компьютерных исследований в Окридже, штат Теннеси 2 место TOP500 на июнь
- 17. Отечественные разработки TOP500(июнь 2009) : СНГ — Тор50(июнь 2009): 1. МВС-100K (МСЦ РАН,НP) – 54 позиция
- 18. МВС-100K Пиковая производительность - 95,04 TFlops. Технические средства "МВС-100K": 990 вычислительных модулей (7920 процессорных ядер) Вычислительный
- 19. СКИФ МГУ июнь 2008 -1-ое место ТОП 50 июнь 2009 -2-ое место совместная разработка МГУ, Института
- 20. СКИФ МГУ Технические характеристики суперкомпьютера «СКИФ МГУ»:
- 22. Скачать презентацию

Введение
Кластер - это группа вычислительных машин, которые связаны между собою и
Введение
Кластер - это группа вычислительных машин, которые связаны между собою и
История развития кластерной архитектуры.
Впервые в классификации вычислительных систем термин "кластер” определила
История развития кластерной архитектуры.
Впервые в классификации вычислительных систем термин "кластер” определила

Общие требование к системам.
Высокая готовность
В случае сбоя программного обеспечения на
Общие требование к системам.
Высокая готовность
В случае сбоя программного обеспечения на
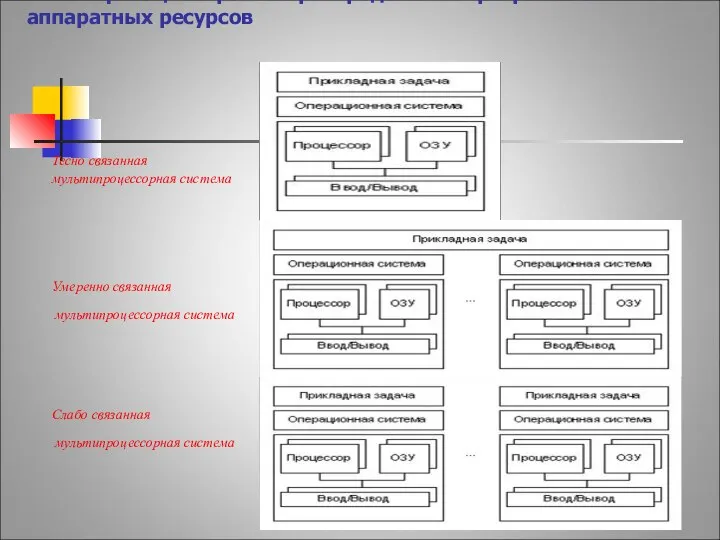
Классификация в рамках распределения программно-аппаратных ресурсов
Тесно связанная
мультипроцессорная система
Умеренно связанная
Классификация в рамках распределения программно-аппаратных ресурсов
Тесно связанная
мультипроцессорная система
Умеренно связанная
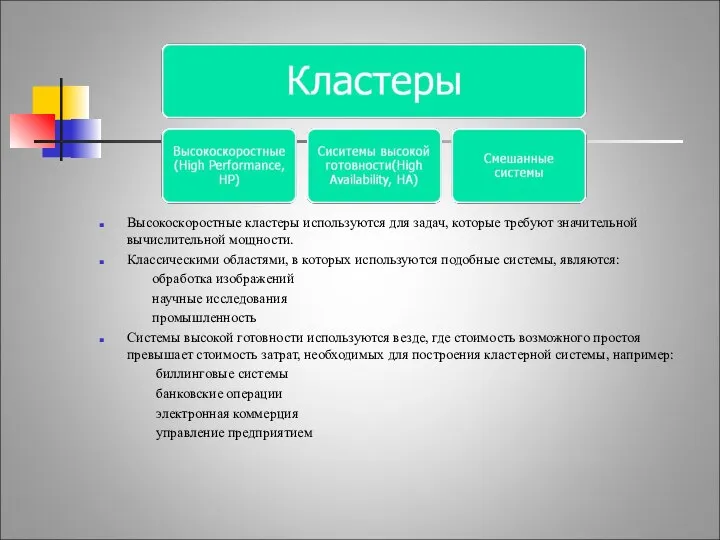
Функциональная классификиция.
Высокоскоростные кластеры используются для задач, которые требуют значительной вычислительной мощности.
Функциональная классификиция.
Высокоскоростные кластеры используются для задач, которые требуют значительной вычислительной мощности.

Системы высокой готовности.
Все типы систем высокой готовности имеют общую цель -
Системы высокой готовности.
Все типы систем высокой готовности имеют общую цель -

Системы высокой готовности.
Система с общими дисками может оказаться эффективным решением задачи,
Системы высокой готовности.
Система с общими дисками может оказаться эффективным решением задачи,
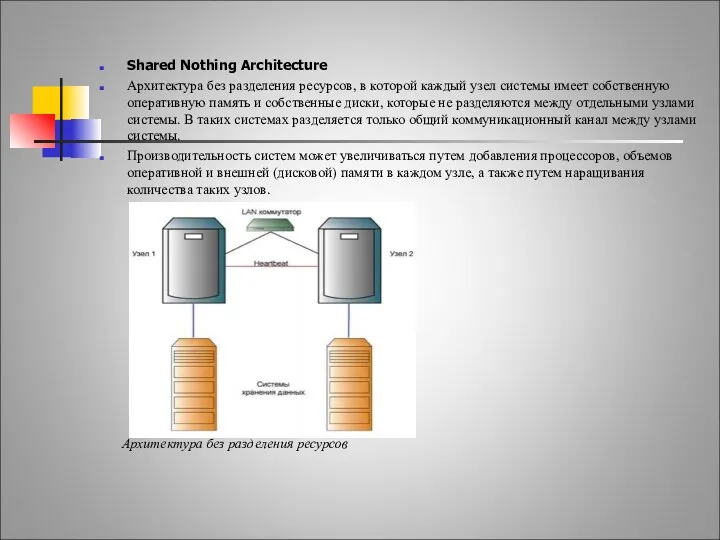
Системы высокой готовности.
Shared Nothing Architecture
Архитектура без разделения ресурсов, в которой
Системы высокой готовности.
Shared Nothing Architecture
Архитектура без разделения ресурсов, в которой

Высокоскоростные системы.
Кластеры для высокопроизводительных вычислений предназначены для параллельных расчётов.
Быстродействие High Performance
Высокоскоростные системы.
Кластеры для высокопроизводительных вычислений предназначены для параллельных расчётов.
Быстродействие High Performance

Проблемы выполнения сети связи процессоров в кластерной системе.
Архитектура кластерной системы (способ
Проблемы выполнения сети связи процессоров в кластерной системе.
Архитектура кластерной системы (способ
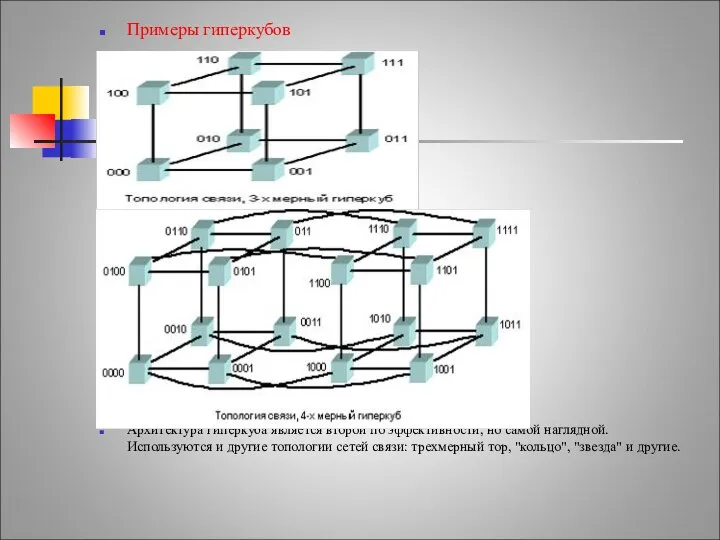
Примеры гиперкубов
Архитектура гиперкуба является второй по эффективности, но самой наглядной. Используются
Примеры гиперкубов
Архитектура гиперкуба является второй по эффективности, но самой наглядной. Используются
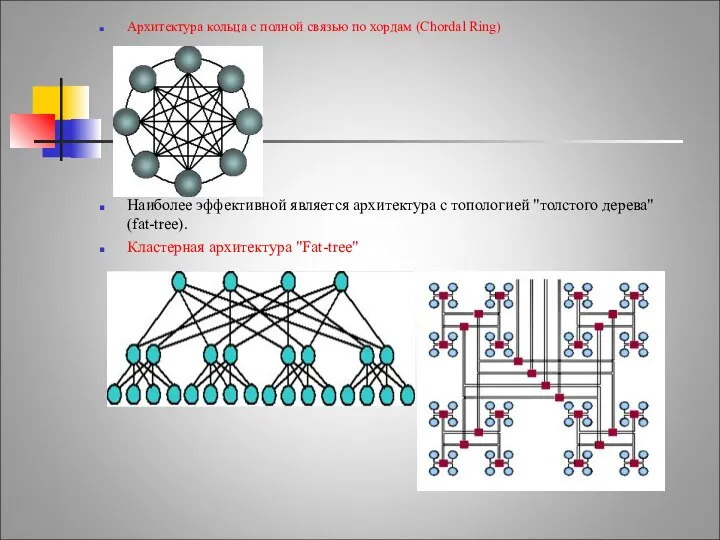
Архитектура кольца с полной связью по хордам (Chordal Ring)
Наиболее эффективной является
Архитектура кольца с полной связью по хордам (Chordal Ring)
Наиболее эффективной является
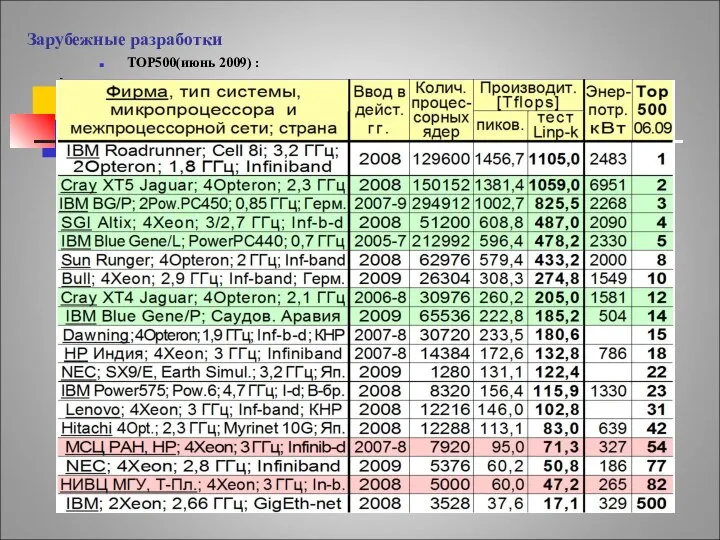
Зарубежные разработки
TOP500(июнь 2009) :
Зарубежные разработки
TOP500(июнь 2009) :

IBM-roadrunner
Местоположение- Лос-Аламосская национальная лаборатория в Нью-Мексико, США
1 место TOP500 на
IBM-roadrunner
Местоположение- Лос-Аламосская национальная лаборатория в Нью-Мексико, США
1 место TOP500 на

Cray Jaguar
Местоположение- Национальный центр компьютерных исследований в Окридже, штат Теннеси
2
Cray Jaguar
Местоположение- Национальный центр компьютерных исследований в Окридже, штат Теннеси
2
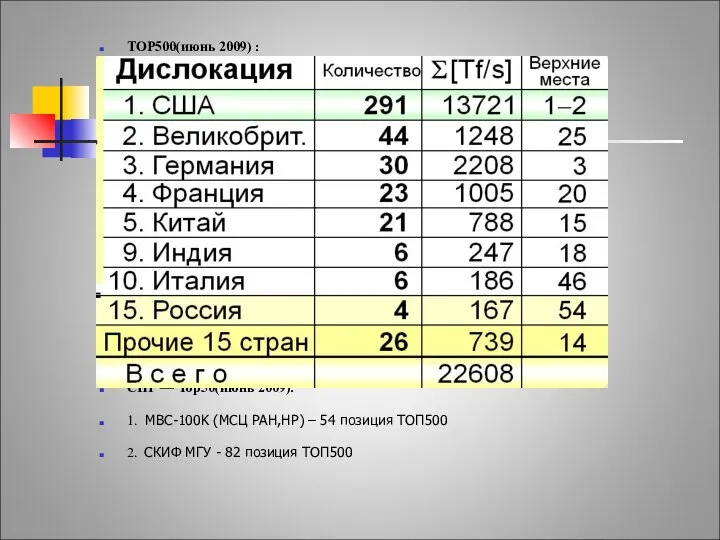
Отечественные разработки
TOP500(июнь 2009) :
СНГ — Тор50(июнь 2009):
1. МВС-100K (МСЦ РАН,НP) –
Отечественные разработки
TOP500(июнь 2009) :
СНГ — Тор50(июнь 2009):
1. МВС-100K (МСЦ РАН,НP) –

МВС-100K
Пиковая производительность - 95,04 TFlops.
Технические средства "МВС-100K":
990 вычислительных модулей
МВС-100K
Пиковая производительность - 95,04 TFlops.
Технические средства "МВС-100K":
990 вычислительных модулей

СКИФ МГУ
июнь 2008 -1-ое место ТОП 50
июнь 2009 -2-ое место
совместная разработка
СКИФ МГУ
июнь 2008 -1-ое место ТОП 50
июнь 2009 -2-ое место
совместная разработка
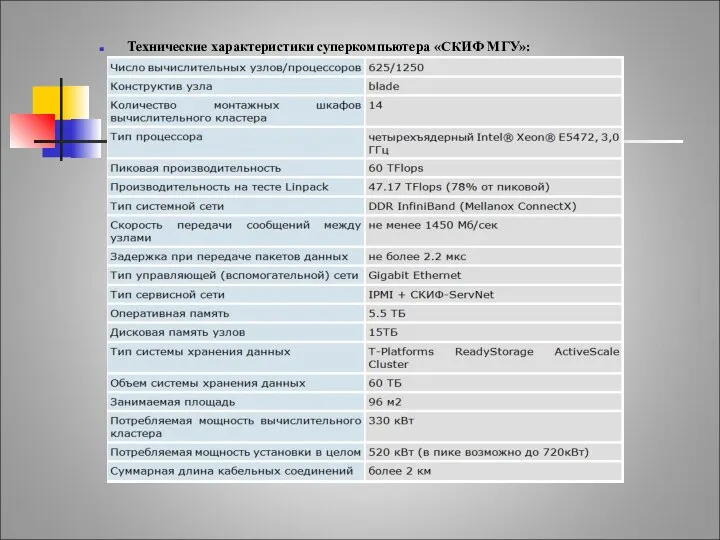
СКИФ МГУ
Технические характеристики суперкомпьютера «СКИФ МГУ»:
СКИФ МГУ
Технические характеристики суперкомпьютера «СКИФ МГУ»:
 Ringvorlesung Linguistik. Geschichte Eine. Einführung in sprachwissenschaftliche Theorien
Ringvorlesung Linguistik. Geschichte Eine. Einführung in sprachwissenschaftliche Theorien Системы электронного документооборота
Системы электронного документооборота Политический терроризм как угроза современному обществу
Политический терроризм как угроза современному обществу Музеи и галереи Красноярского края
Музеи и галереи Красноярского края Налог на прибыль оценщики
Налог на прибыль оценщики Организация государственной системы РСЧС
Организация государственной системы РСЧС синусоидальный ток
синусоидальный ток Судебная риторика: тактика, приемы, особенности
Судебная риторика: тактика, приемы, особенности Особенности математики в Python. Задания
Особенности математики в Python. Задания Политическая философия Н. Макиавелли
Политическая философия Н. Макиавелли Античность. Мифология. Боги Древней Греции
Античность. Мифология. Боги Древней Греции Молодёжное предпринимательство как социальная практика
Молодёжное предпринимательство как социальная практика The Thirteen Colonies
The Thirteen Colonies  Целостность данных
Целостность данных Проект реконструкции и озеленения территории МКОУ Бутурлиновская ООШ № 9 г. Бутурлиновка Воронежской области
Проект реконструкции и озеленения территории МКОУ Бутурлиновская ООШ № 9 г. Бутурлиновка Воронежской области Происхождение христианства Иудейская традиция
Происхождение христианства Иудейская традиция
 Система 5S Путь к стандартизации работ и новому качеству рабочих мест (уровень компании) Семинар по бережливому производству
Система 5S Путь к стандартизации работ и новому качеству рабочих мест (уровень компании) Семинар по бережливому производству Преподаватель математики: Шутилина С.Н.
Преподаватель математики: Шутилина С.Н.  Виктор Михайлович Васнецов 1848 - 1926 гг
Виктор Михайлович Васнецов 1848 - 1926 гг Полимеризационные пластмассы
Полимеризационные пластмассы  Устойчивые словосочетания со словами her, bir, hiç
Устойчивые словосочетания со словами her, bir, hiç Презентация Особенности таможенного контроля товаров, в отношении которых применяются тарифные преференции
Презентация Особенности таможенного контроля товаров, в отношении которых применяются тарифные преференции История 8 марта. Викторина!
История 8 марта. Викторина! Wellness-1 Почему индустрия Wellness востребована?
Wellness-1 Почему индустрия Wellness востребована? Глава 21. Вход Господень в Иерусалим, или Вербное воскресенье
Глава 21. Вход Господень в Иерусалим, или Вербное воскресенье Я – парикмахер - презентация для начальной школы_
Я – парикмахер - презентация для начальной школы_ Презентация на тему "Гражданское право и гражданские правоотношения" - скачать презентации по Педагогике
Презентация на тему "Гражданское право и гражданские правоотношения" - скачать презентации по Педагогике Презентацию подготовила: Презентацию подготовила: Голуб Светлана Васильевна, учитель МОУ СОШ №1 г. Туринска http://www.golubsv.ucoz.ru/
Презентацию подготовила: Презентацию подготовила: Голуб Светлана Васильевна, учитель МОУ СОШ №1 г. Туринска http://www.golubsv.ucoz.ru/