- Лексер, парсер. Этапы компиляции. (Часть 1)

Содержание
- 2. Фронтэнд Машинно независимые оптимизации Код генерация + машинно зависимые оптимизации Этапы компиляции
- 3. Лексический анализатор (лексер) Синтаксический анализатор (парсер) Семантический анализатор Генерация промежуточного представления Этапы фронтэнда
- 4. Схема работы Исходный код Лексер Парсер Символьная таблица Токен Следующий Семантический анализ
- 5. if (a == b) then a += 5; else a -= 5; if (a == b)
- 6. Лексер формирует последовательности входных символов в лексемы, определяет их тип и отправляет токены парсеру. Лексема –
- 7. Лексема -- Токен 12345 (число, 12345) temp_1 (идентификатор, указатель на симтаб) += (оператор, plus_assign) + (оператор,
- 8. Обрабатываемые лексером и парсером последовательности символов и токенов напрямую зависят от спецификации языка. Необходим способ описания
- 9. Алфавит – множество символов, используемых в языке Терминальный символ - символ из алфавита Нетерминальный символ –
- 10. Тип 0: неограниченные Тип 1: контекстно-зависимые / неукорачивающие Тип 2: контекстно-свободные Тип 3: регулярные: праволинейные/леволинейные Классификация
- 11. Регулярные грамматики: праволинейные (A → w, A → wB, A,B ∈ N, w ∈ T*) леволинейные
- 12. Тип 0 (неограниченные): естественные языки: Русский Английский Тип 2 (контекстно-свободные): большинство языков программирования: Java С++ Тип
- 13. Тип 2 контекстно – свободная грамматика: может быть описана с помощью конечного автомата с магазинной памятью
- 14. Строгие определения. Регулярные множества.
- 15. Выражению «(a(b|c))*c» удовлетворяют: с ababacc abacabc Не удовлетворяют: ac abbc abacac Пример регулярного выражения
- 16. Строгие определения. Конечные автоматы.
- 17. Схема построения лексера Лексическая спецификация Регулярное выражение Недетерминированный автомат Детерминированный автомат Диаграмма состояний
- 18. Регулярное Выражение -> НКА
- 19. Регулярное Выражение -> НКА
- 20. Рассмотрим регулярное выражение: Построим соответствующий НКА: Пример
- 21. ε-замыкание(S) — множество состояний, которые достижимы из S путём переходов по ε Начальное состояние ДКА -
- 22. НКА -> ДКА Пример
- 23. Пример построенной диаграммы S com1 / IDENTIFIER NUMBER com2 ! += temp != ++ + “STRING”
- 24. Неполная лексема Конец файла между /* … */ Конец файла внутри строки в кавычках Буквенный символ
- 26. Скачать презентацию

Фронтэнд
Машинно независимые оптимизации
Код генерация + машинно зависимые оптимизации
Этапы компиляции
Фронтэнд
Машинно независимые оптимизации
Код генерация + машинно зависимые оптимизации
Этапы компиляции

Лексический анализатор (лексер)
Синтаксический анализатор (парсер)
Семантический анализатор
Генерация промежуточного представления
Этапы фронтэнда
Лексический анализатор (лексер)
Синтаксический анализатор (парсер)
Семантический анализатор
Генерация промежуточного представления
Этапы фронтэнда
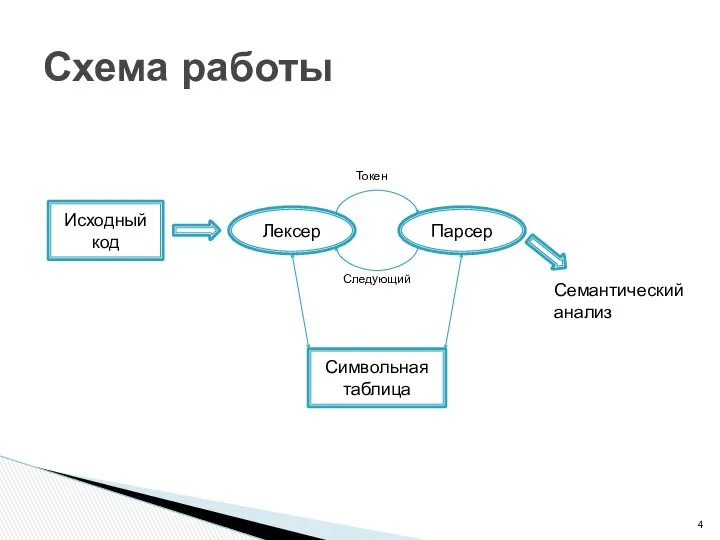
Схема работы
Исходный код
Лексер
Парсер
Символьная таблица
Токен
Следующий
Семантический
анализ
Схема работы
Исходный код
Лексер
Парсер
Символьная таблица
Токен
Следующий
Семантический
анализ

if (a == b) then
a += 5;
else
a -=
if (a == b) then
a += 5;
else
a -=

Лексер формирует последовательности входных символов в лексемы, определяет их тип и
Лексер формирует последовательности входных символов в лексемы, определяет их тип и

Лексема -- Токен
12345 (число, 12345)
temp_1 (идентификатор, указатель на симтаб)
+= (оператор, plus_assign)
+ (оператор,
Лексема -- Токен
12345 (число, 12345)
temp_1 (идентификатор, указатель на симтаб)
+= (оператор, plus_assign)
+ (оператор,

Обрабатываемые лексером и парсером последовательности символов и токенов напрямую зависят от
Обрабатываемые лексером и парсером последовательности символов и токенов напрямую зависят от

Алфавит – множество символов, используемых в языке
Терминальный символ - символ из
Алфавит – множество символов, используемых в языке
Терминальный символ - символ из

Тип 0: неограниченные
Тип 1: контекстно-зависимые / неукорачивающие
Тип 2: контекстно-свободные
Тип 3: регулярные:
Тип 0: неограниченные
Тип 1: контекстно-зависимые / неукорачивающие
Тип 2: контекстно-свободные
Тип 3: регулярные:

Регулярные грамматики:
праволинейные (A → w, A → wB, A,B ∈ N,
Регулярные грамматики:
праволинейные (A → w, A → wB, A,B ∈ N,

Тип 0 (неограниченные): естественные языки:
Русский
Английский
Тип 2 (контекстно-свободные): большинство языков программирования:
Java
С++
Тип 3:
Тип 0 (неограниченные): естественные языки:
Русский
Английский
Тип 2 (контекстно-свободные): большинство языков программирования:
Java
С++
Тип 3:

Тип 2 контекстно – свободная грамматика:
может быть описана с помощью конечного
Тип 2 контекстно – свободная грамматика:
может быть описана с помощью конечного

Строгие определения. Регулярные множества.
Строгие определения. Регулярные множества.

Выражению «(a(b|c))*c» удовлетворяют:
с
ababacc
abacabc
Не удовлетворяют:
ac
abbc
abacac
Пример регулярного выражения
Выражению «(a(b|c))*c» удовлетворяют:
с
ababacc
abacabc
Не удовлетворяют:
ac
abbc
abacac
Пример регулярного выражения

Строгие определения. Конечные автоматы.
Строгие определения. Конечные автоматы.
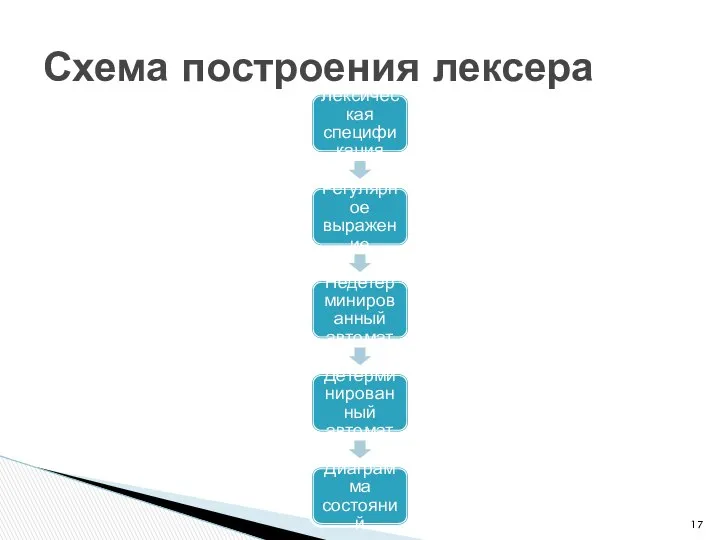
Схема построения лексера
Лексическая спецификация
Регулярное выражение
Недетерминированный автомат
Детерминированный автомат
Диаграмма состояний
Схема построения лексера
Лексическая спецификация
Регулярное выражение
Недетерминированный автомат
Детерминированный автомат
Диаграмма состояний
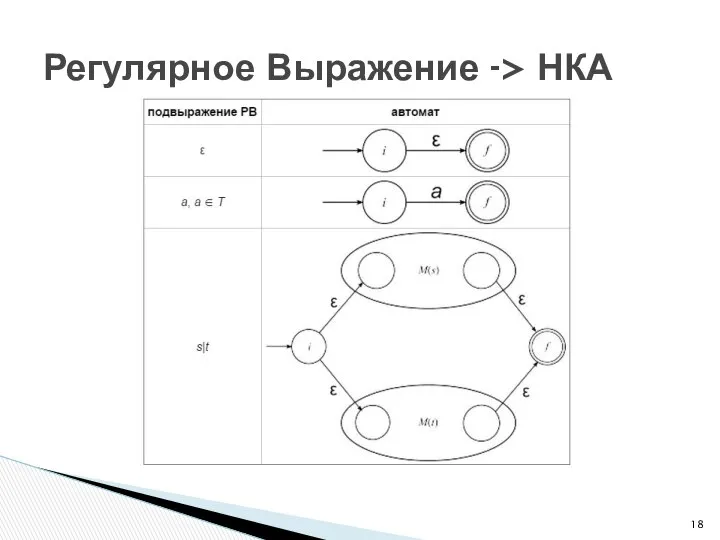
Регулярное Выражение -> НКА
Регулярное Выражение -> НКА
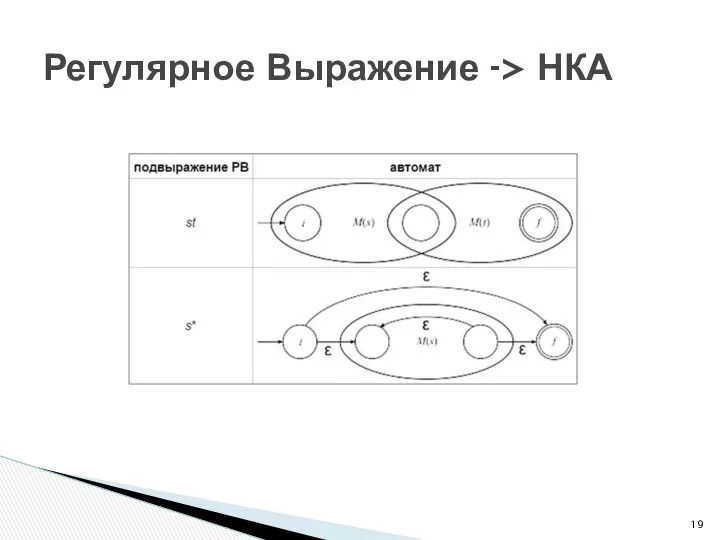
Регулярное Выражение -> НКА
Регулярное Выражение -> НКА
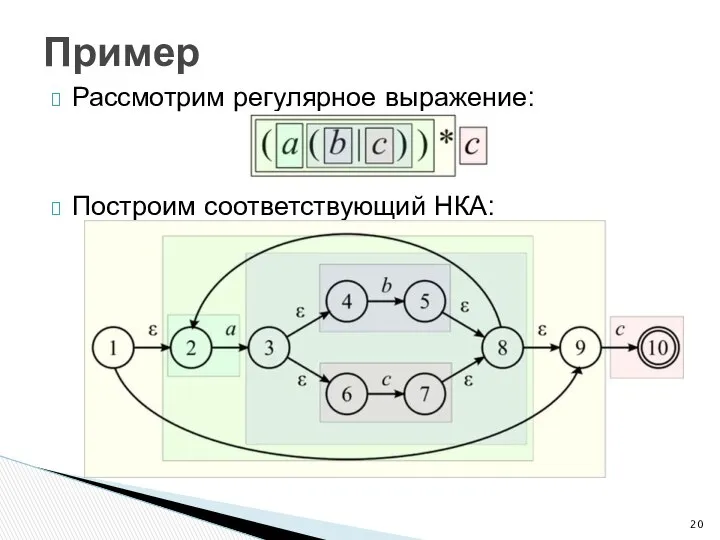
Рассмотрим регулярное выражение:
Построим соответствующий НКА:
Пример
Рассмотрим регулярное выражение:
Построим соответствующий НКА:
Пример

ε-замыкание(S) — множество состояний, которые достижимы из S путём переходов по
ε-замыкание(S) — множество состояний, которые достижимы из S путём переходов по
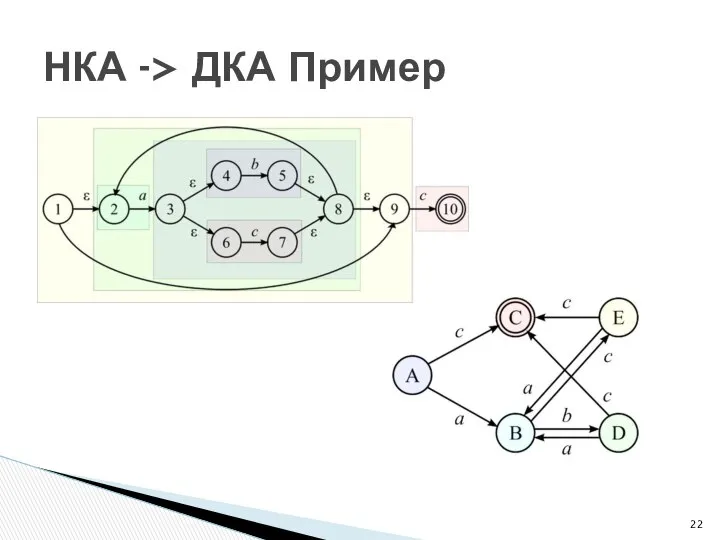
НКА -> ДКА Пример
НКА -> ДКА Пример
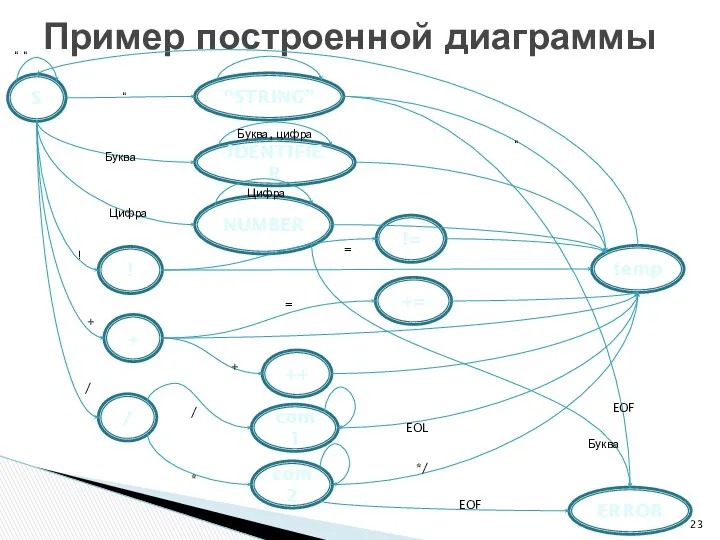
Пример построенной диаграммы
S
com1
/
IDENTIFIER
NUMBER
com2
!
+=
temp
!=
++
+
“STRING”
ERROR
Буква
Цифра
“
“
Буква, цифра
Цифра
Буква
EOF
EOF
*
*/
/
EOL
/
+
!
=
=
+
“ “
Пример построенной диаграммы
S
com1
/
IDENTIFIER
NUMBER
com2
!
+=
temp
!=
++
+
“STRING”
ERROR
Буква
Цифра
“
“
Буква, цифра
Цифра
Буква
EOF
EOF
*
*/
/
EOL
/
+
!
=
=
+
“ “

Неполная лексема
Конец файла между /* … */
Конец файла внутри строки в
Неполная лексема
Конец файла между /* … */
Конец файла внутри строки в
 Технология программирования. (Лекция 2)
Технология программирования. (Лекция 2) Методы оценки конкурентоспособности Анализ конкурентоспособности экономики России
Методы оценки конкурентоспособности Анализ конкурентоспособности экономики России Litania do Ducha Świętego
Litania do Ducha Świętego Последовательностные схемы. Элементы памяти. (Лекция 10)
Последовательностные схемы. Элементы памяти. (Лекция 10) STA-кот
STA-кот Döşemeler. Kirişli döşeme
Döşemeler. Kirişli döşeme МСБО 27 і МСБО 28 Консолідовані фінансові звіти та облік інвестицій у дочірні підприємства. Облік інвестицій у асоційовані комп
МСБО 27 і МСБО 28 Консолідовані фінансові звіти та облік інвестицій у дочірні підприємства. Облік інвестицій у асоційовані комп Организационные структуры управления проектом
Организационные структуры управления проектом Опасности, аксиомы БЖД
Опасности, аксиомы БЖД  Квадратные уравнения - презентация по Алгебре___
Квадратные уравнения - презентация по Алгебре___ Создание стандартных операционных процедур (СОП) для КДЛ как один из элементов обеспечения качества работы лаборатории
Создание стандартных операционных процедур (СОП) для КДЛ как один из элементов обеспечения качества работы лаборатории Физические лица, дееспособность, представительство
Физические лица, дееспособность, представительство «Воспитание происходит всегда, даже тогда, когда вас нет дома» А.С.Макаренко Гиперактивность и семейное воспитание. Родительско
«Воспитание происходит всегда, даже тогда, когда вас нет дома» А.С.Макаренко Гиперактивность и семейное воспитание. Родительско Презентация на тему "Программа социализации подростков через систему естественных социальных проб" - скачать презентации по
Презентация на тему "Программа социализации подростков через систему естественных социальных проб" - скачать презентации по  Енгізудің және шығарудың құрылымдары
Енгізудің және шығарудың құрылымдары Законы раздражения возбудимых тканей
Законы раздражения возбудимых тканей  ЛЬВІВСЬКА ПИВОВАРНЯ - СТУДЕНТАМ
ЛЬВІВСЬКА ПИВОВАРНЯ - СТУДЕНТАМ Презентация «ЭНЕРГОСНАБЖЕНИЕ»
Презентация «ЭНЕРГОСНАБЖЕНИЕ» Славянские истоки. Язычество
Славянские истоки. Язычество История медицины
История медицины Армения
Армения Я – УЧИТЕЛЬ!
Я – УЧИТЕЛЬ!  Требования к управленческим решениям
Требования к управленческим решениям  Тема 15. Финансовый контроль.
Тема 15. Финансовый контроль.  Respond & Achieve. Цифровая транкинговая система Hytera XPT
Respond & Achieve. Цифровая транкинговая система Hytera XPT Вектор Умова-Пойнтинга.
Вектор Умова-Пойнтинга. Разрез здания
Разрез здания Изготовление биполярной ИС с изоляцией транзисторов p-n-переходом
Изготовление биполярной ИС с изоляцией транзисторов p-n-переходом