- Манипулирование данными в R

Содержание
- 2. Сортировка. Функция order Упорядочение лучше производить косвенно: найти вектор индексов, на котором выполнять операцию сортировки, и
- 3. Пример > x > y > z > xyz > dimnames(xyz)[[2]] > xyz a b c
- 4. Функция sort Функция sort сортирует вектор или список в возрастающем или убывающем > sort(x) [1] 1
- 5. Функция rank Чтобы вывести ранг значений вектора, используется функция rank. По умолчанию ранг одинаковых элементов усредняется,
- 6. Дата и время В R есть несколько механизмов для представления даты и времени. Стандартный - это
- 7. Конверсия из одной формы в другую Функция as.POSIXlt(obj) преобразует из POSIXct в POSIXlt. Функция as.POSIXct(obj) преобразует
- 8. Примеры В какой день недели вы родились и сколько дней вы прожили? > myBday > class(myBday)
- 9. Арифметические действия с объектами POSIXt Допускаются следующие арифметические действия с объектами дата/время (POSIXlt или POSIXct): •
- 10. Таблицы Иногда удобно табулировать данные (представлять в виде таблиц частот). Это можно сделать с помощью функции
- 11. Split Функция split делит данные, заданные вектором x, на группы, определенные фактором f. Эта функция может
- 12. Графики
- 13. Функции with, subset and transform Эти функции производят операции над объектом или над элементами внутри объекта.
- 14. Векторизованные вычисления R позволяет выполнять вычисления над целыми векторами/матрицами/блоками данных/списками вместо их отдельных элементов. Четыре функции:
- 15. Функция apply Эта функция позволяет оперировать последовательными частями массива. Для иллюстрации вычислим среднее каждого столбца набора
- 16. Функция tapply Неровные массивы представляют собой комбинацию вектора и фактора меток групп, где размеры групп неправильные
- 17. Функции lapply и sapply lapply и sapply оперируют с компонентами списка или вектора lapply всегда возвращает
- 18. Импорт и экспорт данных
- 19. Чтение данных в R scan() - низкоуровневое средство чтения read.table() - для чтения блоков данных из
- 20. Низкоуровневая функция ввода scan() Для чтения численных данных > vec 1: 22 35 1.7 2.5e+01 77
- 21. scan() для чтения смешанных данных > lis 1: a 10 3.6 2: a 20 2.4 3:
- 22. Импорт прямоугольных таблиц read.table() Эта функция позволяет определять аргумент заголовка, разделители, способ работы с пропущенными значениями
- 23. Пример > samp1 > samp1[1:3,] ID Name Prob 1 1 a 0.812 2 2 b 0.982
- 24. Импорт формата с фиксированной шириной read.fwf() Формат с фиксированной шириной необычен для большинства наборов данных. Обычно
- 25. Пример > dat.ff > cat(file=dat.ff,"12345678","abcdefgh",sep="\n") > read.fwf(dat.ff,width=c(2,4,1,1)) V1 V2 V3 V4 1 12 3456 7 8
- 26. Редактирование данных Функции edit и fix позволяют менять файлы данных. Это удобно для маленьких наборов данных
- 27. Импорт бинарных файлов Бинарные файлы, записанные в других статистических пакетах, могут быть прочитаны в R. Пакет
- 29. Чтение больших файлов данных Есть ограничения на типы файлов, которые R может считывать. Большие файлы с
- 30. Пакет RODBC RODBC позволяет связаться с БД и доставить информацию. Важные функции RODBC включают Установку соединений
- 31. Вывод данных из R Функция cat является базовой для экспорта данных. Она записывает объекты в файлы
- 32. Функция cat Этой функцией очень удобно пользоваться для печати на экране > cat("Hello World\n") Hello World
- 33. Функция sink Может использоваться для записи объектов и текста в файл. > sink("output.txt") > sample(1:100,100,replace=T) >
- 34. Функция write.table Пример 1. Создание соединения перед записью > con > write.table(myData, con, sep = ",")
- 35. Вывод графики из R Есть 4 способа для экспорта графики из R. Функция postscript производит инкапсулированный
- 37. Скачать презентацию

Сортировка. Функция order
Упорядочение лучше производить косвенно: найти вектор индексов, на котором
Сортировка. Функция order
Упорядочение лучше производить косвенно: найти вектор индексов, на котором
![Пример > x > y > z > xyz > dimnames(xyz)[[2]]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1372382/slide-2.jpg)
Пример
> x <- sample(1:5, 20, rep=T)
> y <- sample(1:5, 20, rep=T)
>
Пример
> x <- sample(1:5, 20, rep=T)
> y <- sample(1:5, 20, rep=T)
>

Функция sort
Функция sort сортирует вектор или список в возрастающем или убывающем
Функция sort
Функция sort сортирует вектор или список в возрастающем или убывающем

Функция rank
Чтобы вывести ранг значений вектора, используется функция rank. По умолчанию
Функция rank
Чтобы вывести ранг значений вектора, используется функция rank. По умолчанию

Дата и время
В R есть несколько механизмов для представления даты и
Дата и время
В R есть несколько механизмов для представления даты и

Конверсия из одной формы в другую
Функция as.POSIXlt(obj) преобразует из POSIXct в
Конверсия из одной формы в другую
Функция as.POSIXlt(obj) преобразует из POSIXct в

Примеры
В какой день недели вы родились и сколько дней вы
Примеры
В какой день недели вы родились и сколько дней вы

Арифметические действия с объектами POSIXt
Допускаются следующие арифметические действия с объектами дата/время
Арифметические действия с объектами POSIXt
Допускаются следующие арифметические действия с объектами дата/время

Таблицы
Иногда удобно табулировать данные (представлять в виде таблиц частот). Это можно
Таблицы
Иногда удобно табулировать данные (представлять в виде таблиц частот). Это можно

Split
Функция split делит данные, заданные вектором x, на группы, определенные фактором
Split
Функция split делит данные, заданные вектором x, на группы, определенные фактором
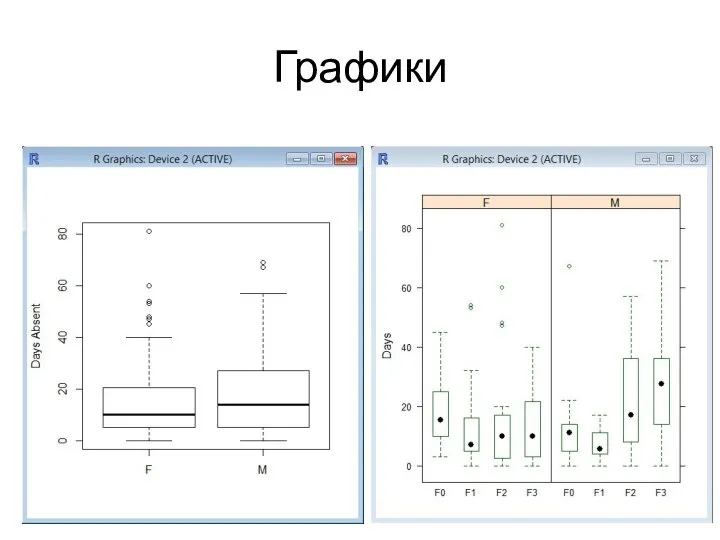
Графики
Графики

Функции with, subset and transform
Эти функции производят операции над объектом или
Функции with, subset and transform
Эти функции производят операции над объектом или

Векторизованные вычисления
R позволяет выполнять вычисления над целыми векторами/матрицами/блоками данных/списками вместо их
Векторизованные вычисления
R позволяет выполнять вычисления над целыми векторами/матрицами/блоками данных/списками вместо их

Функция apply
Эта функция позволяет оперировать последовательными частями массива. Для иллюстрации вычислим
Функция apply
Эта функция позволяет оперировать последовательными частями массива. Для иллюстрации вычислим

Функция tapply
Неровные массивы представляют собой комбинацию вектора и фактора меток групп,
Функция tapply
Неровные массивы представляют собой комбинацию вектора и фактора меток групп,

Функции lapply и sapply
lapply и sapply оперируют с компонентами списка или
Функции lapply и sapply
lapply и sapply оперируют с компонентами списка или

Импорт и экспорт данных
Импорт и экспорт данных

Чтение данных в R
scan() - низкоуровневое средство чтения
read.table() - для чтения
Чтение данных в R
scan() - низкоуровневое средство чтения
read.table() - для чтения

Низкоуровневая функция ввода scan()
Для чтения численных данных
> vec <- scan()
1: 22
Низкоуровневая функция ввода scan()
Для чтения численных данных
> vec <- scan()
1: 22

scan() для чтения смешанных данных
> lis <- scan(what = list(flag =
scan() для чтения смешанных данных
> lis <- scan(what = list(flag =

Импорт прямоугольных таблиц read.table()
Эта функция позволяет определять аргумент заголовка, разделители, способ
Импорт прямоугольных таблиц read.table()
Эта функция позволяет определять аргумент заголовка, разделители, способ
![Пример > samp1 > samp1[1:3,] ID Name Prob 1 1 a](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1372382/slide-22.jpg)
Пример
> samp1 <- read.csv("samp1.csv")
> samp1[1:3,]
ID Name Prob
1 1 a 0.812
2 2
Пример
> samp1 <- read.csv("samp1.csv")
> samp1[1:3,]
ID Name Prob
1 1 a 0.812
2 2

Импорт формата с фиксированной шириной read.fwf()
Формат с фиксированной шириной необычен для
Импорт формата с фиксированной шириной read.fwf()
Формат с фиксированной шириной необычен для

Пример
> dat.ff <- tempfile()
> cat(file=dat.ff,"12345678","abcdefgh",sep="\n")
> read.fwf(dat.ff,width=c(2,4,1,1))
V1 V2 V3 V4
1 12 3456
Пример
> dat.ff <- tempfile()
> cat(file=dat.ff,"12345678","abcdefgh",sep="\n")
> read.fwf(dat.ff,width=c(2,4,1,1))
V1 V2 V3 V4
1 12 3456

Редактирование данных
Функции edit и fix позволяют менять файлы данных. Это удобно
Редактирование данных
Функции edit и fix позволяют менять файлы данных. Это удобно

Импорт бинарных файлов
Бинарные файлы, записанные в других статистических пакетах, могут быть
Импорт бинарных файлов
Бинарные файлы, записанные в других статистических пакетах, могут быть


Чтение больших файлов данных
Есть ограничения на типы файлов, которые R может
Чтение больших файлов данных
Есть ограничения на типы файлов, которые R может

Пакет RODBC
RODBC позволяет связаться с БД и доставить информацию. Важные функции
Пакет RODBC
RODBC позволяет связаться с БД и доставить информацию. Важные функции

Вывод данных из R
Функция cat является базовой для экспорта данных. Она
Вывод данных из R
Функция cat является базовой для экспорта данных. Она

Функция cat
Этой функцией очень удобно пользоваться для печати на экране
> cat("Hello
Функция cat
Этой функцией очень удобно пользоваться для печати на экране
> cat("Hello

Функция sink
Может использоваться для записи объектов и текста в файл.
> sink("output.txt")
>
Функция sink
Может использоваться для записи объектов и текста в файл.
> sink("output.txt")
>

Функция write.table
Пример 1. Создание соединения перед записью
> con <- file("myData.csv", "w+")
>
Функция write.table
Пример 1. Создание соединения перед записью
> con <- file("myData.csv", "w+")
>

Вывод графики из R
Есть 4 способа для экспорта графики из R.
Вывод графики из R
Есть 4 способа для экспорта графики из R.
 МАОУ «Гимназия №33» г. Перми. ШСК "Сириус"
МАОУ «Гимназия №33» г. Перми. ШСК "Сириус" Элитарная демократия и корпоративизм Выполнил: Бродовский М.А. Григоров Г.С. Т-082
Элитарная демократия и корпоративизм Выполнил: Бродовский М.А. Григоров Г.С. Т-082 Достопримечательности Сочи
Достопримечательности Сочи Презентация на тему "Дефекты зрения и способы их устранения" - скачать презентации по Медицине
Презентация на тему "Дефекты зрения и способы их устранения" - скачать презентации по Медицине Алгоритмы с ветвлениями и циклами - презентация для начальной школы_
Алгоритмы с ветвлениями и циклами - презентация для начальной школы_ Қалқанша бездің обыры
Қалқанша бездің обыры 5. Экономический оборот
5. Экономический оборот История ЭВМ Часть1
История ЭВМ Часть1  春节 Chūnjié
春节 Chūnjié Координация помощи и поддержки парламентам
Координация помощи и поддержки парламентам Моделирование воспитательной системы 5 – 9 классов «Я расту» Выполнила: классный руководитель 5 класса Шарандина Н.Л.
Моделирование воспитательной системы 5 – 9 классов «Я расту» Выполнила: классный руководитель 5 класса Шарандина Н.Л. Тема. Изменчивость. Формы и закономерности. Вопросы 1. Фенотипическая измен 2. биометрия 3. Генотипическая измен 4. Комбинатив
Тема. Изменчивость. Формы и закономерности. Вопросы 1. Фенотипическая измен 2. биометрия 3. Генотипическая измен 4. Комбинатив Презентация Методы принятия управленческих решений
Презентация Методы принятия управленческих решений Презентация на тему "Работа с неблагополучными семьями" - скачать презентации по Педагогике
Презентация на тему "Работа с неблагополучными семьями" - скачать презентации по Педагогике Введение в язык VBA. Макросы
Введение в язык VBA. Макросы Легализация (отмывание) денежных средств. Современное состояние и предупреждение
Легализация (отмывание) денежных средств. Современное состояние и предупреждение Способы фиксации следов обуви в различных условиях
Способы фиксации следов обуви в различных условиях Проект. Робот сборщик мусора на поверхности воды
Проект. Робот сборщик мусора на поверхности воды Украшение рукавички
Украшение рукавички garmin GTХ-327
garmin GTХ-327  Русский язык 2 класс «Мой друг и помощник – словарь!» Коледова Галина Николаевна Учитель начальных классов ГОУ Гимназия №205 С
Русский язык 2 класс «Мой друг и помощник – словарь!» Коледова Галина Николаевна Учитель начальных классов ГОУ Гимназия №205 С Роль партії у житті суспільства
Роль партії у житті суспільства Алматы облысының фермерлері дайындаған шұбат және қымыз микроорганизмдерінің штаммдарын бөлу технологиясын өңдеу
Алматы облысының фермерлері дайындаған шұбат және қымыз микроорганизмдерінің штаммдарын бөлу технологиясын өңдеу ВО «Машиноимпорт» Презентация по дисциплине: «Основы ВЭД» Выполнила: студентка 3-го курса экономического факультета группа МЭ0
ВО «Машиноимпорт» Презентация по дисциплине: «Основы ВЭД» Выполнила: студентка 3-го курса экономического факультета группа МЭ0 Применение бесконтактного инфракрасного термометра для мониторинга температуры тела пациента в операционной
Применение бесконтактного инфракрасного термометра для мониторинга температуры тела пациента в операционной Инструментальный Тайм-менеджмент
Инструментальный Тайм-менеджмент Вычислительно стойкие системы шифрования
Вычислительно стойкие системы шифрования Презентация на тему "Оздоровительное влияние средств физической культуры при нарушении осанки, сколиозе" - скачать презентац
Презентация на тему "Оздоровительное влияние средств физической культуры при нарушении осанки, сколиозе" - скачать презентац