- Массивы. Поиск элемента в массиве

Содержание
- 2. Массивы Строки Записи и таблицы Множества Динамические массивы Постановка задачи поиска элемента в массиве Алгоритмы поиска:
- 3. Рассмотрим статические структуры данных: массивы, записи, множества. Цель описания типа данных и определения некоторых переменных, относящихся
- 4. 1. Массивы
- 5. Массив – это поименованная совокупность однотипных элементов, упорядоченных по индексам, определяющих положение элемента в массиве. Следующее
- 6. Количество используемых индексов определяет размерность массива. Массив может быть одномерным (вектор), двумерным (матрица), трехмерным (куб) и
- 7. В Паскале определены такие операции над массивами в целом, как сравнение на равенство и неравенство массивов,
- 8. Можно также выполнять операции над отдельными элементами массива. Перечень таких операций определяется типом элементов. Доступ к
- 9. 2. Строки
- 10. Строка – это последовательность символов (элементов символьного типа). В Паскале количество символов в строке (длина строки)
- 11. Каждый символ строки имеет свой индекс, принимающий значение от 1 до заданной длины строки. Следует обратить
- 12. Однако есть ряд отличий: операций сравнения строк больше, чем аналогичных операций для массивов: , >, ;
- 13. 3. Записи и таблицы
- 14. Запись – это агрегат, составляющие которого (поля) имеют имя и могут быть различного типа. Рассмотрим пример
- 15. В Паскале определена операция присваивания для записей в целом (записи должны быть одного типа). Доступ к
- 16. Таблица представляет собой одномерный массив (вектор), элементами которого являются записи. Отдельная запись массива называется строкой таблицы.
- 17. Характерной особенностью таблиц является то, что доступ к элементам таблицы производится не по индексу, а по
- 18. Если последовательность записей упорядочена относительно какого-либо столбца (поля), то такая таблица называется упорядоченной, иначе – таблица
- 19. Перечень операций над отдельной ячейкой определяется типом ячейки: PersonList[1].Index := 190000; PersonList[1].Name := 'Иванов'; PersonList[1].Adress :=
- 20. 4. Множества
- 21. Наряду с массивами и записями существует еще один структурированный тип – множество. Этот тип используется не
- 22. Тип множество соответствует математическому понятию множества в смысле операций, которые допускаются над структурами такого типа. Множество
- 23. Множества, так же как и массивы, объединяют однотипные элементы. Поэтому в описании множества обязательно должен быть
- 24. В отличие от массивов и записей в множестве отсутствует возможность обращения к отдельным элементам. Операции выполняются
- 25. В Паскале в качестве типов элементов множества могут использоваться типы, максимальное количество значений которых не превышает
- 26. 5. Динамические массивы
- 27. При работе с массивами практически всегда возникает задача настройки программы на фактическое количество элементов массива. В
- 28. Первый вариант – использование констант для задания размерности массива. Program first; const n = 10; var
- 29. Второй вариант – программист планирует некоторое условно максимальное (теоретическое) количество элементов, которое и используется при объявлении
- 30. Program second; var a : array [1..25] of real; i, nf : integer; begin writeln('введите фактич.
- 31. Вариант третий – в нужный момент времени надо выделить динамическую память в требуемом объеме, а после
- 32. Program dynam_memory; type mas = array[1..2] of ; ms = ^mas; var a : ms; i,
- 33. Где нужны динамические массивы? Задача. Ввести размер массива, затем – элементы массива. Отсортировать массив и вывести
- 34. © С.В.Кухта, 2010 Использование указателей program qq; type intArray = array[1..1] of integer; var A: ^intArray;
- 35. Использование указателей для выделения памяти используют процедуру GetMem( указатель, размер в байтах ); указатель должен быть
- 36. 6. Постановка задачи поиска элемента в массиве
- 37. Поиск в массиве Одно из наиболее часто встречающихся в программировании действий – поиск данных. Существует несколько
- 38. Пусть A = {a1, a2, ...} – последовательность однотипных элементов и b – некоторый элемент, обладающий
- 39. Поскольку представление последовательности в памяти может быть осуществлено в виде массива, задачи могут быть уточнены как
- 40. Максимальный элемент Задача: найти в массиве максимальный элемент. Алгоритм: Псевдокод: { считаем, что первый элемент –
- 41. Максимальный элемент max := a[1]; { считаем, что первый – максимальный } iMax := 1; for
- 42. © С.В.Кухта, 2009 program qq; const N = 5; var a: array [1..N] of integer; i,
- 43. При дальнейшем рассмотрении делается принципиальное допущение: группа данных, в которой необходимо найти заданный элемент, фиксирована. Будем
- 44. Задача заключается в поиске элемента, ключ которого равен заданному «аргументу поиска» x. Полученный в результате индекс
- 45. С точки зрения теории множеств поиск можно рассматривать, как отображение множества X = {x1, x2, ...,
- 46. Алгоритм поиска может возвратить элемент массива (или всю найденную запись массива) или чаще всего может возвратить
- 47. Поиск, по завершении которого найден элемент массива с ключом, равным аргументу поиска, называется успешным или результативным.
- 48. Однако возможно, что поиск некоторого конкретного аргумента в массиве является неудачным (безрезультатным), т.е. в данном массиве
- 49. Поиск требуемой информации применяется ко всем основным структурам данных с произвольным доступом: массивам, спискам (одно- и
- 50. Задача – найти в массиве элемент, равный x, или установить, что его нет. Решение: для произвольного
- 51. 7. Алгоритмы поиска элемента в массиве
- 52. Нахождение информации в неотсортированной структуре данных, например в массиве, требует применения последовательного поиска. Последовательный (или линейный)
- 53. Линейный поиск nX := 0; for i:=1 to N do if A[i] = X then begin
- 54. Рассмотрим примеры последовательного поиска с циклами for и while. Функции линейного поиска Type Item = record
- 55. Функции линейного поиска function search_s1(A: Mas; N: integer; key: Item): integer; var i: integer; begin for
- 56. Функции линейного поиска function search_s2(A: Mas; N: integer; key: Item): integer; var i: integer; begin i:=0;
- 57. Последовательный поиск выполнит в среднем случае проверку N/2 элементов, в лучшем – 1 элемента, а в
- 58. Недостаток этого поиска: медленное выполнение при большом объеме просматриваемого массива. Но если данные не отсортированы, то
- 59. Двоичный (или бинарный) поиск основан на итерационном сравнении ключа поиска с центральным элементом текущей части массива.
- 60. При каждой итерации находится середина текущей анализируемой части, т.е. интервал анализа делится пополам (на 2): 1/2,
- 61. Двоичный поиск X = 7 X 8 4 X > 4 6 X > 6 Выбрать
- 62. Двоичный поиск nX := 0; L := 1; R := N; {границы: ищем от A[1] до
- 63. Этот метод поиска значительно эффективнее чем последовательный поиск, но требует, чтобы данные были предварительно упорядочены (отсортированы).
- 65. Скачать презентацию

Массивы
Строки
Записи и таблицы
Множества
Динамические массивы
Постановка задачи поиска элемента в массиве
Алгоритмы поиска:
последовательный поиск;
двоичный
Массивы
Строки
Записи и таблицы
Множества
Динамические массивы
Постановка задачи поиска элемента в массиве
Алгоритмы поиска:
последовательный поиск;
двоичный

Рассмотрим статические структуры данных:
массивы,
записи,
множества.
Цель описания типа данных
Рассмотрим статические структуры данных:
массивы,
записи,
множества.
Цель описания типа данных

1. Массивы
1. Массивы

Массив – это поименованная совокупность однотипных элементов, упорядоченных по индексам, определяющих
Массив – это поименованная совокупность однотипных элементов, упорядоченных по индексам, определяющих

Количество используемых индексов определяет размерность массива.
Массив может быть
одномерным (вектор),
Количество используемых индексов определяет размерность массива.
Массив может быть
одномерным (вектор),

В Паскале определены такие операции над массивами в целом,
как сравнение
В Паскале определены такие операции над массивами в целом,
как сравнение

Можно также выполнять операции над отдельными элементами массива.
Перечень таких операций
Можно также выполнять операции над отдельными элементами массива.
Перечень таких операций

2. Строки
2. Строки

Строка – это последовательность символов (элементов символьного типа).
В Паскале количество символов
Строка – это последовательность символов (элементов символьного типа).
В Паскале количество символов

Каждый символ строки имеет свой индекс, принимающий значение от 1 до
Каждый символ строки имеет свой индекс, принимающий значение от 1 до

Однако есть ряд отличий:
операций сравнения строк больше, чем аналогичных операций
Однако есть ряд отличий:
операций сравнения строк больше, чем аналогичных операций

3. Записи и таблицы
3. Записи и таблицы

Запись – это агрегат, составляющие которого (поля) имеют имя и могут
Запись – это агрегат, составляющие которого (поля) имеют имя и могут

В Паскале определена операция присваивания для записей в целом (записи должны
В Паскале определена операция присваивания для записей в целом (записи должны

Таблица представляет собой одномерный массив (вектор), элементами которого являются записи.
Отдельная запись
Таблица представляет собой одномерный массив (вектор), элементами которого являются записи.
Отдельная запись

Характерной особенностью таблиц является то, что доступ к элементам таблицы производится
Характерной особенностью таблиц является то, что доступ к элементам таблицы производится

Если последовательность записей упорядочена относительно какого-либо столбца (поля), то такая таблица
Если последовательность записей упорядочена относительно какого-либо столбца (поля), то такая таблица
![Перечень операций над отдельной ячейкой определяется типом ячейки: PersonList[1].Index := 190000;](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1366425/slide-18.jpg)
Перечень операций над отдельной ячейкой определяется типом ячейки:
PersonList[1].Index := 190000;
PersonList[1].Name :=
Перечень операций над отдельной ячейкой определяется типом ячейки:
PersonList[1].Index := 190000;
PersonList[1].Name :=

4. Множества
4. Множества

Наряду с массивами и записями существует еще один структурированный тип –
Наряду с массивами и записями существует еще один структурированный тип –

Тип множество соответствует математическому понятию множества в смысле операций, которые допускаются
Тип множество соответствует математическому понятию множества в смысле операций, которые допускаются

Множества, так же как и массивы, объединяют однотипные элементы. Поэтому в
Множества, так же как и массивы, объединяют однотипные элементы. Поэтому в

В отличие от массивов и записей в множестве отсутствует возможность обращения
В отличие от массивов и записей в множестве отсутствует возможность обращения

В Паскале в качестве типов элементов множества могут использоваться типы, максимальное
В Паскале в качестве типов элементов множества могут использоваться типы, максимальное

5. Динамические массивы
5. Динамические массивы

При работе с массивами практически всегда возникает задача настройки программы на
При работе с массивами практически всегда возникает задача настройки программы на

Первый вариант – использование констант для задания размерности массива.
Program first;
const
Первый вариант – использование констант для задания размерности массива.
Program first;
const

Второй вариант – программист планирует некоторое условно максимальное (теоретическое) количество элементов,
Второй вариант – программист планирует некоторое условно максимальное (теоретическое) количество элементов,
![Program second; var a : array [1..25] of real; i, nf](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1366425/slide-29.jpg)
Program second;
var a : array [1..25] of real;
i,
Program second;
var a : array [1..25] of real;
i,

Вариант третий – в нужный момент времени надо выделить динамическую память
Вариант третий – в нужный момент времени надо выделить динамическую память
![Program dynam_memory; type mas = array[1..2] of ; ms = ^mas;](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1366425/slide-31.jpg)
Program dynam_memory;
type mas = array[1..2] of <требуемый_тип_элемента>;
ms = ^mas;
var
Program dynam_memory;
type mas = array[1..2] of <требуемый_тип_элемента>;
ms = ^mas;
var

Где нужны динамические массивы?
Задача. Ввести размер массива, затем – элементы массива.
Где нужны динамические массивы?
Задача. Ввести размер массива, затем – элементы массива.
![© С.В.Кухта, 2010 Использование указателей program qq; type intArray = array[1..1]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1366425/slide-33.jpg)
© С.В.Кухта, 2010
Использование указателей
program qq;
type intArray = array[1..1] of integer;
var A:
© С.В.Кухта, 2010
Использование указателей
program qq;
type intArray = array[1..1] of integer;
var A:

Использование указателей
для выделения памяти используют процедуру
GetMem( указатель, размер в байтах
Использование указателей
для выделения памяти используют процедуру
GetMem( указатель, размер в байтах

6. Постановка задачи поиска элемента в массиве
6. Постановка задачи поиска элемента в массиве

Поиск в массиве
Одно из наиболее часто встречающихся в программировании действий –
Поиск в массиве
Одно из наиболее часто встречающихся в программировании действий –

Пусть A = {a1, a2, ...} – последовательность однотипных элементов и
Пусть A = {a1, a2, ...} – последовательность однотипных элементов и

Поскольку представление последовательности в памяти может быть осуществлено в виде массива,
Поскольку представление последовательности в памяти может быть осуществлено в виде массива,
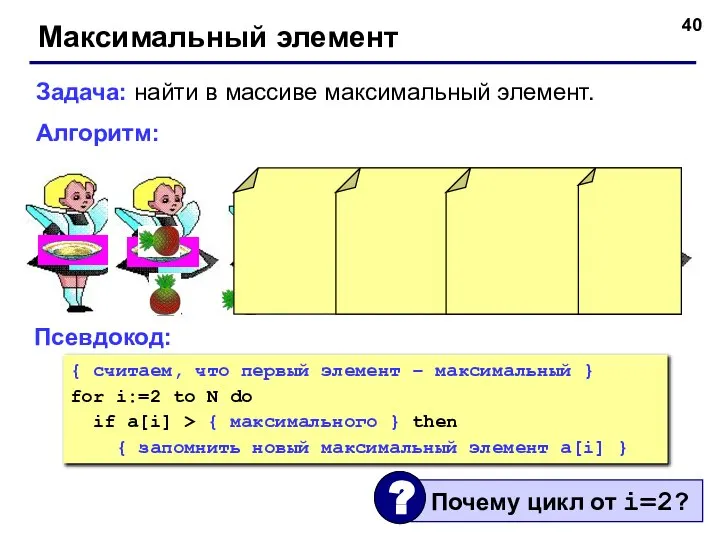
Максимальный элемент
Задача: найти в массиве максимальный элемент.
Алгоритм:
Псевдокод:
{ считаем, что первый
Максимальный элемент
Задача: найти в массиве максимальный элемент.
Алгоритм:
Псевдокод:
{ считаем, что первый
![Максимальный элемент max := a[1]; { считаем, что первый – максимальный](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1366425/slide-40.jpg)
Максимальный элемент
max := a[1]; { считаем, что первый – максимальный }
iMax
Максимальный элемент
max := a[1]; { считаем, что первый – максимальный }
iMax

© С.В.Кухта, 2009
program qq;
const N = 5;
var a: array [1..N] of
© С.В.Кухта, 2009
program qq;
const N = 5;
var a: array [1..N] of

При дальнейшем рассмотрении делается принципиальное допущение:
группа данных, в которой необходимо
При дальнейшем рассмотрении делается принципиальное допущение:
группа данных, в которой необходимо

Задача заключается в поиске элемента, ключ которого равен заданному «аргументу поиска»
Задача заключается в поиске элемента, ключ которого равен заданному «аргументу поиска»

С точки зрения теории множеств поиск можно рассматривать, как
отображение множества
С точки зрения теории множеств поиск можно рассматривать, как
отображение множества

Алгоритм поиска может
возвратить элемент массива (или всю найденную запись массива)
или
Алгоритм поиска может
возвратить элемент массива (или всю найденную запись массива)
или

Поиск, по завершении которого найден элемент массива с ключом, равным аргументу
Поиск, по завершении которого найден элемент массива с ключом, равным аргументу

Однако возможно, что поиск некоторого конкретного аргумента в массиве является неудачным
Однако возможно, что поиск некоторого конкретного аргумента в массиве является неудачным

Поиск требуемой информации применяется ко всем основным структурам данных с произвольным
Поиск требуемой информации применяется ко всем основным структурам данных с произвольным

Задача – найти в массиве элемент, равный x, или установить, что
Задача – найти в массиве элемент, равный x, или установить, что

7. Алгоритмы поиска элемента
в массиве
7. Алгоритмы поиска элемента
в массиве

Нахождение информации в неотсортированной структуре данных, например в массиве, требует применения
Нахождение информации в неотсортированной структуре данных, например в массиве, требует применения

Линейный поиск
nX := 0;
for i:=1 to N do
if A[i] =
Линейный поиск
nX := 0;
for i:=1 to N do
if A[i] =
Рассмотрим примеры последовательного поиска с циклами for и while.
Функции линейного
Рассмотрим примеры последовательного поиска с циклами for и while.
Функции линейного

Функции линейного поиска
function search_s1(A: Mas; N: integer; key: Item):
integer;
var
Функции линейного поиска
function search_s1(A: Mas; N: integer; key: Item):
integer;
var

Функции линейного поиска
function search_s2(A: Mas; N: integer; key: Item):
integer;
var
Функции линейного поиска
function search_s2(A: Mas; N: integer; key: Item):
integer;
var

Последовательный поиск выполнит
в среднем случае проверку N/2 элементов,
в лучшем
Последовательный поиск выполнит
в среднем случае проверку N/2 элементов,
в лучшем

Недостаток этого поиска:
медленное выполнение при большом объеме просматриваемого массива.
Но
Недостаток этого поиска:
медленное выполнение при большом объеме просматриваемого массива.
Но
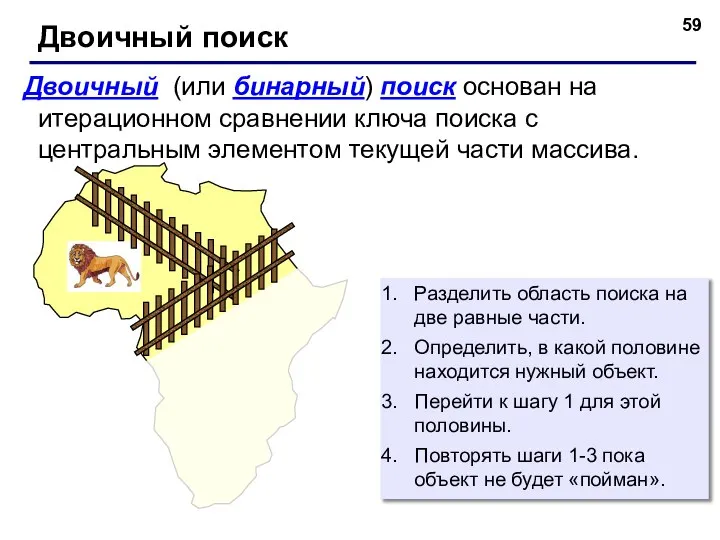
Двоичный (или бинарный) поиск основан на итерационном сравнении ключа поиска с
Двоичный (или бинарный) поиск основан на итерационном сравнении ключа поиска с

При каждой итерации находится середина текущей анализируемой части,
т.е. интервал анализа
При каждой итерации находится середина текущей анализируемой части,
т.е. интервал анализа
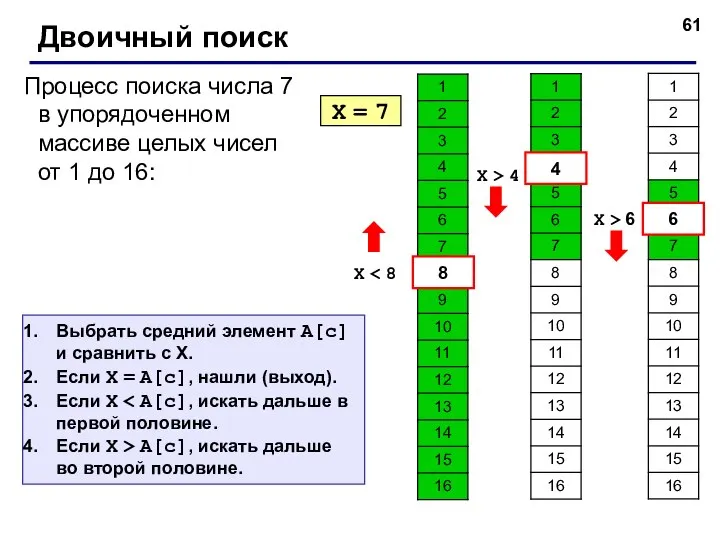
Двоичный поиск
X = 7
X < 8
8
4
X > 4
6
X > 6
Выбрать средний
Двоичный поиск
X = 7
X < 8
8
4
X > 4
6
X > 6
Выбрать средний
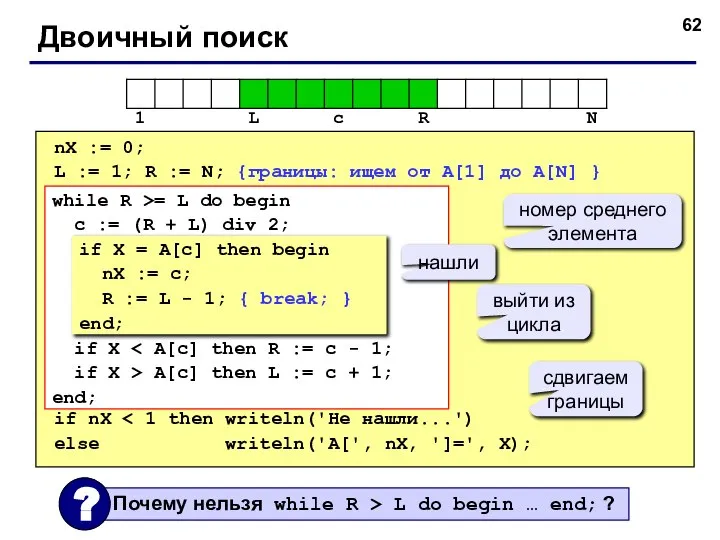
Двоичный поиск
nX := 0;
L := 1; R :=
Двоичный поиск
nX := 0;
L := 1; R :=

Этот метод поиска значительно эффективнее чем последовательный поиск, но требует, чтобы
Этот метод поиска значительно эффективнее чем последовательный поиск, но требует, чтобы
 Развитие городошного спорта на территории города Шебекино
Развитие городошного спорта на территории города Шебекино Квадратичная функция. функция
Квадратичная функция. функция Физическая культура. Тестовые задания
Физическая культура. Тестовые задания Ресурсний потенціал для розвитку зеленого туризму на Дубровиччині
Ресурсний потенціал для розвитку зеленого туризму на Дубровиччині Медико-социальные аспекты здоровья населения
Медико-социальные аспекты здоровья населения Глоссарий
Глоссарий Декартовы координаты
Декартовы координаты ЦИРК Выполнила Торопова Елена Владимировна Учитель начальных классов МОУ СОШ №5 г. Кохма 2010г.
ЦИРК Выполнила Торопова Елена Владимировна Учитель начальных классов МОУ СОШ №5 г. Кохма 2010г. Да́нте Аліг'є́рі— видатний італійський поет
Да́нте Аліг'є́рі— видатний італійський поет Гидропривод машин
Гидропривод машин МИТОХОНДРИАЛЬНЫЕ БОЛЕЗНИ
МИТОХОНДРИАЛЬНЫЕ БОЛЕЗНИ Weight of Commercial Sector and Reproduction Scheme. Hiroshi ONISHI
Weight of Commercial Sector and Reproduction Scheme. Hiroshi ONISHI Медицина древнего Египта
Медицина древнего Египта  Mit, nach, aus, zu, von, bei
Mit, nach, aus, zu, von, bei Old XPSAT substituted by new XPSATE
Old XPSAT substituted by new XPSATE Презентация по алгебре Графики функций y= ax2+n
Презентация по алгебре Графики функций y= ax2+n Вадим ЧУВЕЛЁВ Партнёр «Мирмекс» vchuvelev@myrmex.ru, @Vadim_C Конференция «Интернет для бизнеса: Эффективный и экономичный канал привлечения к
Вадим ЧУВЕЛЁВ Партнёр «Мирмекс» vchuvelev@myrmex.ru, @Vadim_C Конференция «Интернет для бизнеса: Эффективный и экономичный канал привлечения к Способы обеспечения обязательств: залог
Способы обеспечения обязательств: залог Мікропроцесорна техніка PSoC Creator 4.2 Designing with PSoC 3/5. (Лекція 4)
Мікропроцесорна техніка PSoC Creator 4.2 Designing with PSoC 3/5. (Лекція 4) Современные методы лечения и профилактики заболеваний парадонта у детей Выполнил : вр
Современные методы лечения и профилактики заболеваний парадонта у детей Выполнил : вр Преобразователи кодов
Преобразователи кодов Инженерная графика. Виды графики. (Лекция 1)
Инженерная графика. Виды графики. (Лекция 1) Схема персонального компьютера
Схема персонального компьютера  Adventure tourism
Adventure tourism Основы технической механики. Механические передачи
Основы технической механики. Механические передачи Подшипники качения
Подшипники качения Статика и динамика технологических объектов управления
Статика и динамика технологических объектов управления Этикет деловых отношений. Поведение в общественных местах. Этикет деловых приемов
Этикет деловых отношений. Поведение в общественных местах. Этикет деловых приемов