- Операционные системы Введение в файловые системы

Содержание
- 2. Определение файловой системы Файловая система – это часть ОС, назначение которой состоит в том, чтобы обеспечить
- 3. Понятие файловой системы В широком смысле понятие “ФС” включает: совокупность всех файлов на диске; наборы структур
- 4. Файлы Файл – это именованный набор связанной информации, записанной во вторичную память. Файлы представляют собой абстрактные
- 5. Имена файлов Файлы идентифицируются символьными именами, которые им дают пользователи. Общий формат символьного имени файла: .
- 6. Типы файлов обычные файлы: специальные файлы; файлы-каталоги.
- 7. Обычные файлы Обычные файлы в свою очередь подразделяются на текстовые и двоичные: Текстовые файлы состоят из
- 8. Специальные файлы Специальные файлы – это файлы, ассоциированные с устройствами ввода-вывода, которые позволяют пользователю выполнять операции
- 9. Каталоги Каталоги – системные файлы, поддерживающие структуру файловой системы. Каталог это, с одной стороны, группа файлов,
- 10. Атрибуты файлов В разных файловых системах могут использоваться в качестве атрибутов разные характеристики: информация о разрешенном
- 11. Структура каталогов структура записи каталога ОС UNIX структура записи каталога FAT16 (32 байта) Каталоги могут непосредственно
- 12. Логическая организация ФС Каталоги могут образовывать иерархическую структуру за счет того, что каталог более низкого уровня
- 13. Логическая организация ФС - одноуровневая - иерархическая (дерево) - иерархическая (сеть)
- 14. Логическая организация файла Программист имеет дело с логической организацией файла, представляя файл в виде определенным образом
- 15. Логическая организация файла
- 16. Физическая организация файла Физическая организация файла описывает правила хранения файла на устройстве внешней памяти (например, магнитном
- 17. Цилиндры и сектора Головки перемещаются по круговым дорожкам (Tracks), каждая дорожка разделена на сектора (Sectors). Дорожки,
- 18. Кластеры Некоторые файловые системы (например, FAT и NTFS) в качестве единицы хранения информации используют логические блоки
- 19. Способы физической организации непрерывное размещение связанный список индексов связанный список блоков перечень номеров блоков
- 20. Непрерывное размещение Непрерывное размещение – простейший вариант физической организации (рисунок а), при котором файлу предоставляется последовательность
- 21. Иллюстрация непрерывного размещения
- 22. Связанный список блоков Следующий способ физической организации – размещение в виде связанного списка блоков дисковой памяти
- 23. Иллюстрация связанного списка блоков
- 24. Связанный список индексов Популярным способом, используемым, например, в файловой системе FAT операционной системы MS-DOS, является использование
- 25. Перечень номеров блоков В заключение рассмотрим задание физического расположения файла путем простого перечисления номеров блоков, занимаемых
- 26. Иллюстрация использования индексного узла (i-node) Размер блока – 4Kб, адрес – 4 байта Прямая адресация: 10
- 27. Способы учета свободного дискового пространства связанный список (linked list) – в этом случае все свободные блоки
- 28. Иллюстрация учета свободного дискового пространства
- 29. Права доступа к файлу Определить права доступа к файлу – значит определить для каждого пользователя набор
- 30. Управление правами доступа В некоторых системах пользователи могут быть разделены на отдельные категории. Для всех пользователей
- 31. Матрица прав доступа На пересечении строк и столбцов указываются разрешенные операции Строки соответствуют всем пользователям Столбцы
- 32. Кэширование диска Перехват запросов к внешним блочным ЗУ, промежуточным программным слоем – подсистемой буферизации (ПБ). ПБ
- 33. Кэширование диска – чтение При запросе на чтение некоторого блока подсистема буферизации (ПБ) просматривает свой буферный
- 34. Кэширование диска – запись отложенная запись (lazy commit) – сразу запись производится только в буферный пул,
- 35. Общая модель файловой системы Функционирование любой файловой системы можно представить многоуровневой моделью, в которой каждый уровень
- 36. Символьный и базовый уровень Задачей символьного уровня является определение по символьному имени файла его уникального имени.
- 37. Уровень проверки прав доступа и логический уровень Следующим этапом реализации запроса к файлу является проверка прав
- 38. Физический уровень На физическом уровне файловая система определяет номер физического блока, который содержит требуемую логическую запись,
- 39. RAID-системы RAID – Redundant Array of Independent (Inexpensive) Disks – избыточный массив независимых (недорогих) дисков. RAID
- 40. Основные уровни RAID систем RAID 0 (stripping, дисковый массив без избыточности) RAID 1 (mirroring, зеркалирование) RAID
- 41. RAID-0 Представляет собой дисковый массив, в котором данные разбиваются на блоки, и каждый блок записываются (или
- 42. RAID-0 Преимущества: наивысшая производительность для приложений требующих интенсивной обработки запросов ввода/вывода и данных большого объема; простота
- 43. RAID-1 Зеркалирование - традиционный способ для повышения надежности дискового массива небольшого объема. В простейшем варианте используется
- 44. RAID-1 Преимущества: простота реализации; простота восстановления массива в случае отказа (копирование); достаточно высокое быстродействие для приложений
- 45. Рекомендации по применению RAID-1 Применяйте RAID 1 для диска, на котором содержится ваша ОС, потому что
- 46. RAID-2 RAID-2 основан на разбиении входных данных на уровне битов и вычислении кода Хэмминга для контроля
- 47. RAID-4 Данные разбиваются на блочном уровне. Каждый блок данных записывается на отдельный диск и может быть
- 48. RAID-4 Преимущества: очень высокая скорость чтения данных больших объемов; высокая производительность при большой интенсивности запросов чтения
- 49. RAID-5 Этот уровень похож на RAID 4, но в отличие от предыдущего четность распределяется циклически по
- 50. RAID-5 Преимущества: высокая производительность при большой интенсивности запросов чтения/записи данных; малые накладные расходы для реализации избыточности.
- 51. Сравнение RAID-систем
- 52. Составные RAID системы RAID 0+1 / RAID 1+0 RAID 0+3 / RAID 3+0 RAID 0+5 /
- 53. Сравнение RAID 0+1 и RAID 1+0 В RAID 0+1 формируется 2 идентичных массива RAID-0 (только striping),
- 54. Рекомендации по применению RAID 1+0 Уровень RAID 10 является наилучшим отказоустойчивым решением, он обеспечивает хорошую защиту
- 55. Реализация RAID-систем программная (software-based); аппаратная - шинно-ориентированная (bus-based); аппаратная - автономная подсистема (subsystem-based).
- 56. Программная реализация RAID Главное преимущество программной реализации - низкая стоимость. Но при этом у нее много
- 57. Программная реализация RAID Ядро GNU/Linux 2.6.28 (последнее из вышедших в 2008 году) поддерживает программные RAID следующих
- 59. Скачать презентацию

Определение файловой системы
Файловая система – это часть ОС, назначение которой состоит
Определение файловой системы
Файловая система – это часть ОС, назначение которой состоит

Понятие файловой системы
В широком смысле понятие “ФС” включает:
совокупность всех файлов на
Понятие файловой системы
В широком смысле понятие “ФС” включает:
совокупность всех файлов на

Файлы
Файл – это именованный набор связанной информации, записанной во вторичную память.
Файлы
Файлы
Файл – это именованный набор связанной информации, записанной во вторичную память.
Файлы

Имена файлов
Файлы идентифицируются символьными именами, которые им дают пользователи.
Общий формат
Имена файлов
Файлы идентифицируются символьными именами, которые им дают пользователи.
Общий формат

Типы файлов
обычные файлы:
специальные файлы;
файлы-каталоги.
Типы файлов
обычные файлы:
специальные файлы;
файлы-каталоги.

Обычные файлы
Обычные файлы в свою очередь подразделяются на текстовые и двоичные:
Текстовые
Обычные файлы
Обычные файлы в свою очередь подразделяются на текстовые и двоичные:
Текстовые

Специальные файлы
Специальные файлы – это файлы, ассоциированные с устройствами ввода-вывода, которые
Специальные файлы
Специальные файлы – это файлы, ассоциированные с устройствами ввода-вывода, которые

Каталоги
Каталоги – системные файлы, поддерживающие структуру файловой системы.
Каталог это, с одной
Каталоги
Каталоги – системные файлы, поддерживающие структуру файловой системы.
Каталог это, с одной

Атрибуты файлов
В разных файловых системах могут использоваться в качестве атрибутов разные
Атрибуты файлов
В разных файловых системах могут использоваться в качестве атрибутов разные
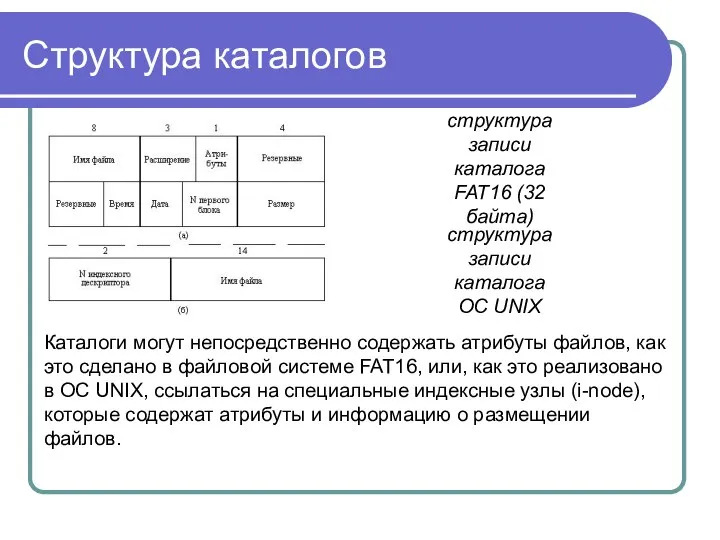
Структура каталогов
структура записи
каталога
ОС UNIX
структура записи
каталога
FAT16 (32 байта)
Каталоги
Структура каталогов
структура записи
каталога
ОС UNIX
структура записи
каталога
FAT16 (32 байта)
Каталоги

Логическая организация ФС
Каталоги могут образовывать иерархическую структуру за счет того, что
Логическая организация ФС
Каталоги могут образовывать иерархическую структуру за счет того, что
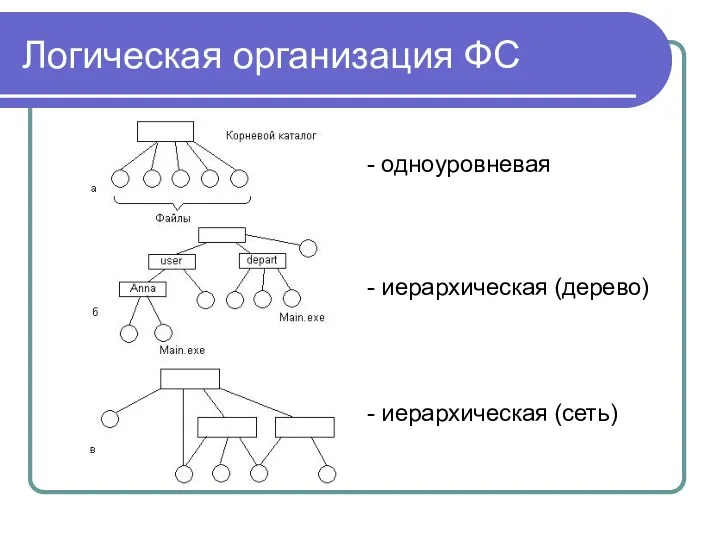
Логическая организация ФС
- одноуровневая
- иерархическая (дерево)
- иерархическая (сеть)
Логическая организация ФС
- одноуровневая
- иерархическая (дерево)
- иерархическая (сеть)

Логическая организация файла
Программист имеет дело с логической организацией файла, представляя файл
Логическая организация файла
Программист имеет дело с логической организацией файла, представляя файл
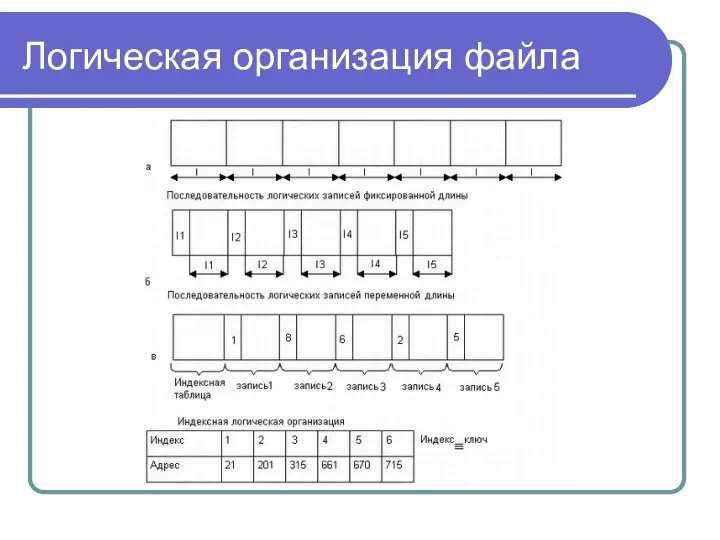
Логическая организация файла
Логическая организация файла
Физическая организация файла
Физическая организация файла описывает правила хранения файла на
Физическая организация файла
Физическая организация файла описывает правила хранения файла на
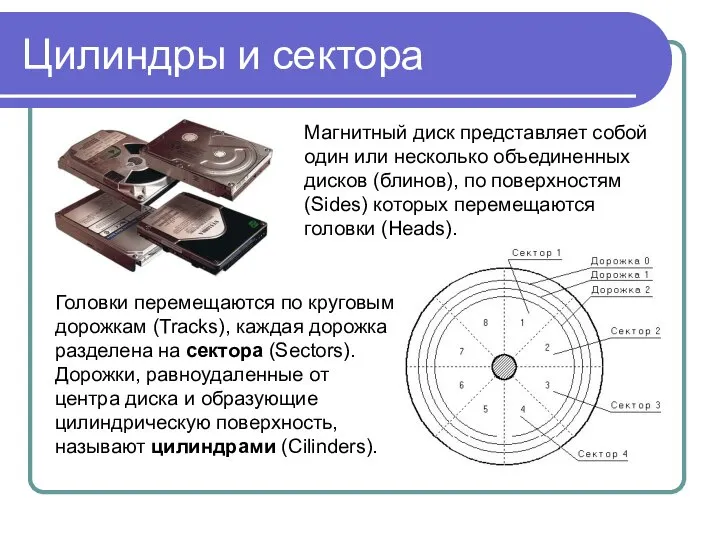
Цилиндры и сектора
Головки перемещаются по круговым дорожкам (Tracks), каждая дорожка разделена
Цилиндры и сектора
Головки перемещаются по круговым дорожкам (Tracks), каждая дорожка разделена
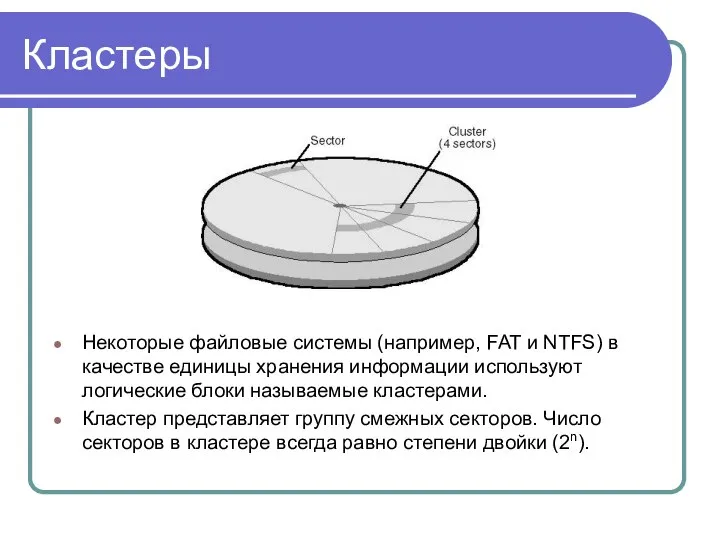
Кластеры
Некоторые файловые системы (например, FAT и NTFS) в качестве единицы хранения
Кластеры
Некоторые файловые системы (например, FAT и NTFS) в качестве единицы хранения
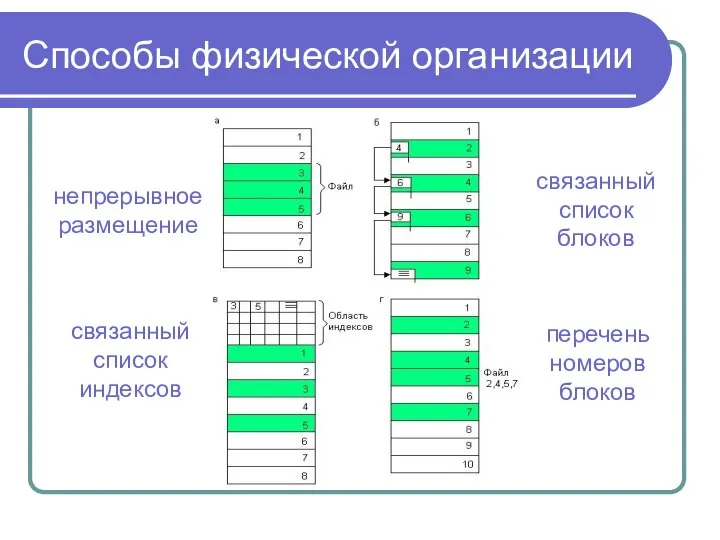
Способы физической организации
непрерывное
размещение
связанный
список
индексов
связанный
список
блоков
Способы физической организации
непрерывное
размещение
связанный
список
индексов
связанный
список
блоков

Непрерывное размещение
Непрерывное размещение – простейший вариант физической организации (рисунок а), при
Непрерывное размещение
Непрерывное размещение – простейший вариант физической организации (рисунок а), при

Иллюстрация непрерывного размещения
Иллюстрация непрерывного размещения

Связанный список блоков
Следующий способ физической организации – размещение в виде связанного
Связанный список блоков
Следующий способ физической организации – размещение в виде связанного
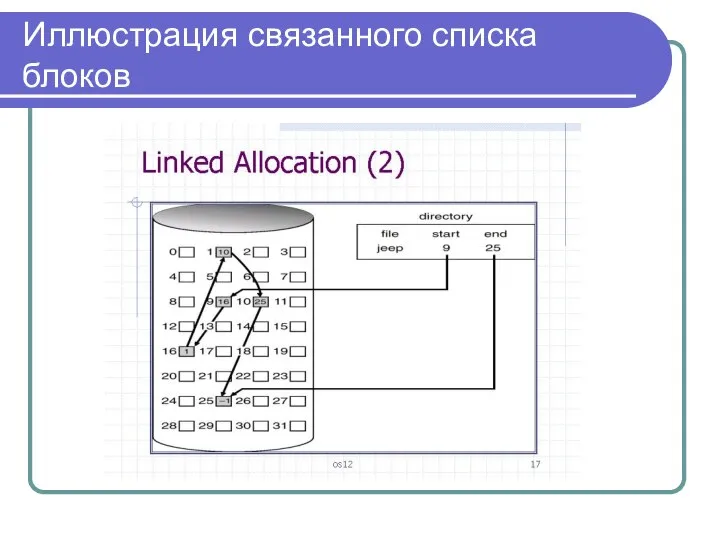
Иллюстрация связанного списка блоков
Иллюстрация связанного списка блоков

Связанный список индексов
Популярным способом, используемым, например, в файловой системе FAT операционной
Связанный список индексов
Популярным способом, используемым, например, в файловой системе FAT операционной

Перечень номеров блоков
В заключение рассмотрим задание физического расположения файла путем простого
Перечень номеров блоков
В заключение рассмотрим задание физического расположения файла путем простого
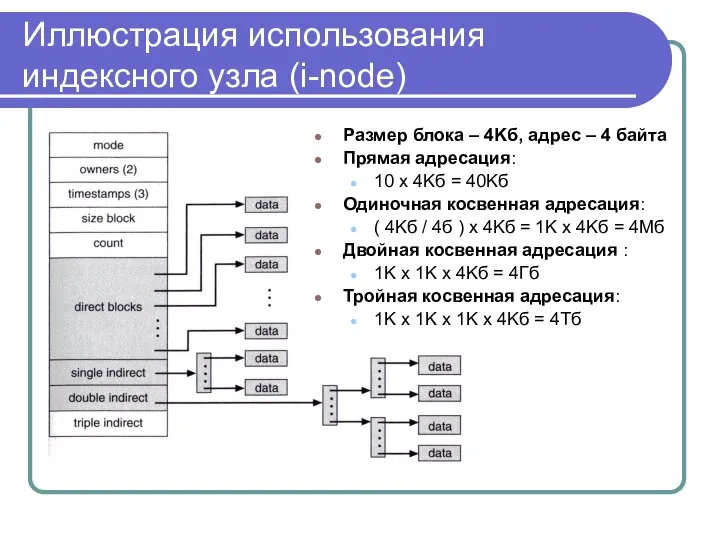
Иллюстрация использования индексного узла (i-node)
Размер блока – 4Kб, адрес – 4
Иллюстрация использования индексного узла (i-node)
Размер блока – 4Kб, адрес – 4

Способы учета свободного дискового пространства
связанный список (linked list) – в этом
Способы учета свободного дискового пространства
связанный список (linked list) – в этом

Иллюстрация учета свободного дискового пространства
Иллюстрация учета свободного дискового пространства

Права доступа к файлу
Определить права доступа к файлу – значит
Права доступа к файлу
Определить права доступа к файлу – значит

Управление правами доступа
В некоторых системах пользователи могут быть разделены на отдельные
Управление правами доступа
В некоторых системах пользователи могут быть разделены на отдельные
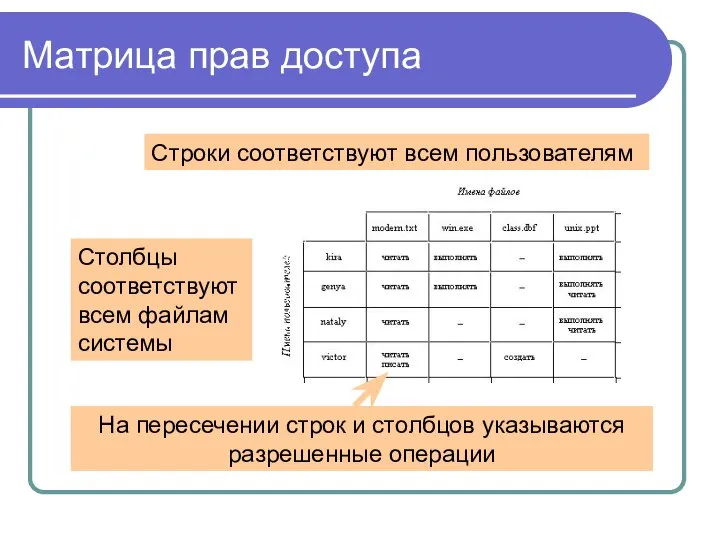
Матрица прав доступа
На пересечении строк и столбцов указываются разрешенные операции
Строки соответствуют
Матрица прав доступа
На пересечении строк и столбцов указываются разрешенные операции
Строки соответствуют

Кэширование диска
Перехват запросов к внешним блочным ЗУ, промежуточным программным слоем
Кэширование диска
Перехват запросов к внешним блочным ЗУ, промежуточным программным слоем

Кэширование диска – чтение
При запросе на чтение некоторого блока подсистема буферизации
Кэширование диска – чтение
При запросе на чтение некоторого блока подсистема буферизации

Кэширование диска – запись
отложенная запись (lazy commit) – сразу запись производится
Кэширование диска – запись
отложенная запись (lazy commit) – сразу запись производится
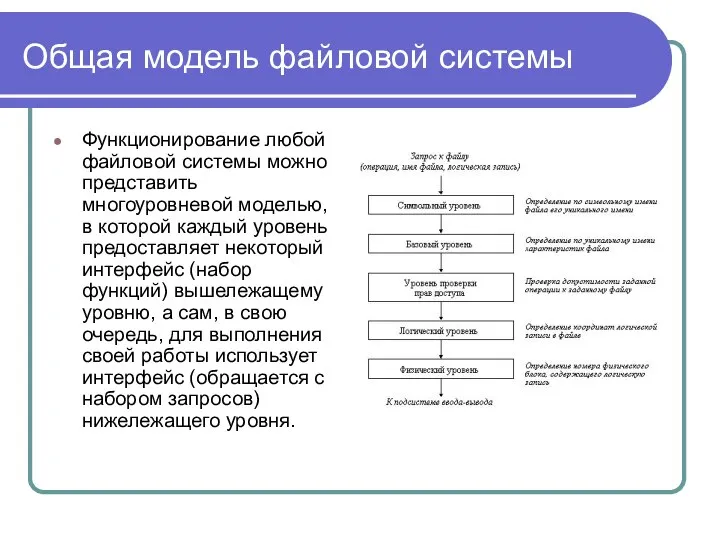
Общая модель файловой системы
Функционирование любой файловой системы можно представить многоуровневой
Общая модель файловой системы
Функционирование любой файловой системы можно представить многоуровневой

Символьный и базовый уровень
Задачей символьного уровня является определение по символьному
Символьный и базовый уровень
Задачей символьного уровня является определение по символьному

Уровень проверки прав доступа и логический уровень
Следующим этапом реализации запроса
Уровень проверки прав доступа и логический уровень
Следующим этапом реализации запроса

Физический уровень
На физическом уровне файловая система определяет номер физического блока,
Физический уровень
На физическом уровне файловая система определяет номер физического блока,
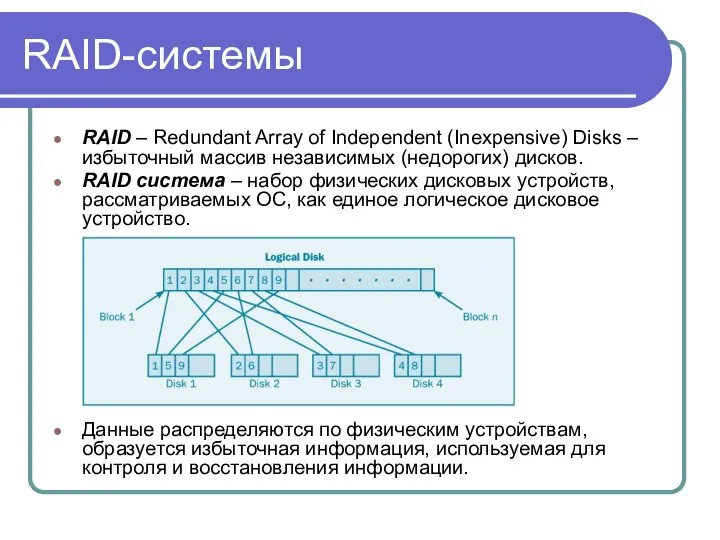
RAID-системы
RAID – Redundant Array of Independent (Inexpensive) Disks – избыточный массив
RAID-системы
RAID – Redundant Array of Independent (Inexpensive) Disks – избыточный массив

Основные уровни RAID систем
RAID 0 (stripping, дисковый массив без избыточности)
RAID 1
Основные уровни RAID систем
RAID 0 (stripping, дисковый массив без избыточности)
RAID 1
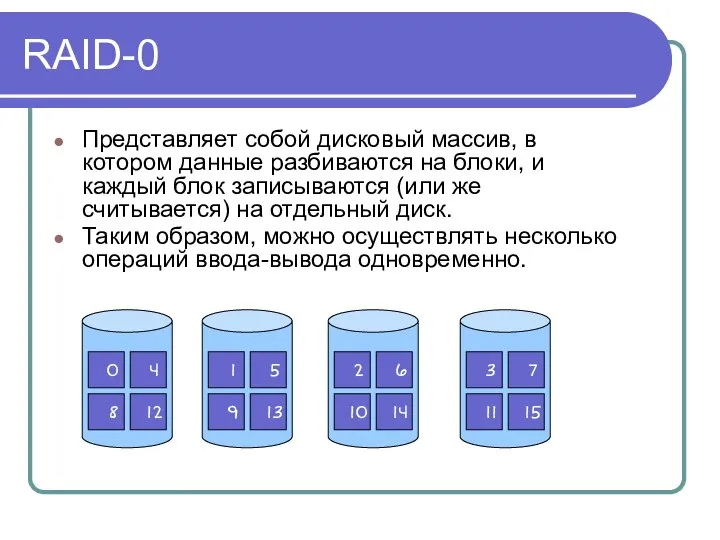
RAID-0
Представляет собой дисковый массив, в котором данные разбиваются на блоки, и
RAID-0
Представляет собой дисковый массив, в котором данные разбиваются на блоки, и

RAID-0
Преимущества:
наивысшая производительность для приложений требующих интенсивной обработки запросов ввода/вывода и
RAID-0
Преимущества:
наивысшая производительность для приложений требующих интенсивной обработки запросов ввода/вывода и
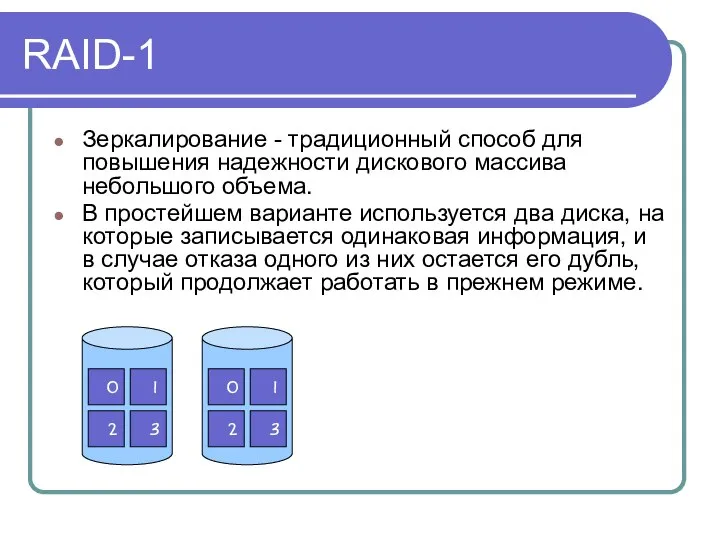
RAID-1
Зеркалирование - традиционный способ для повышения надежности дискового массива небольшого объема.
RAID-1
Зеркалирование - традиционный способ для повышения надежности дискового массива небольшого объема.

RAID-1
Преимущества:
простота реализации;
простота восстановления массива в случае отказа (копирование);
достаточно
RAID-1
Преимущества:
простота реализации;
простота восстановления массива в случае отказа (копирование);
достаточно

Рекомендации по применению RAID-1
Применяйте RAID 1 для диска, на котором содержится ваша
Рекомендации по применению RAID-1
Применяйте RAID 1 для диска, на котором содержится ваша
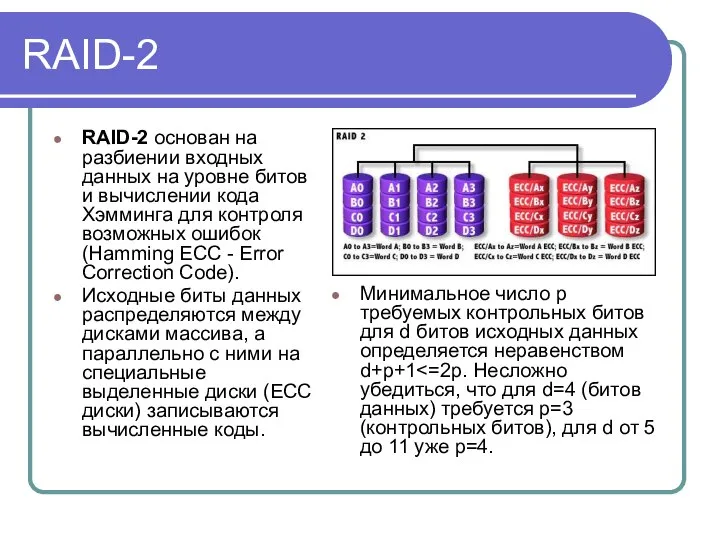
RAID-2
RAID-2 основан на разбиении входных данных на уровне битов и вычислении
RAID-2
RAID-2 основан на разбиении входных данных на уровне битов и вычислении
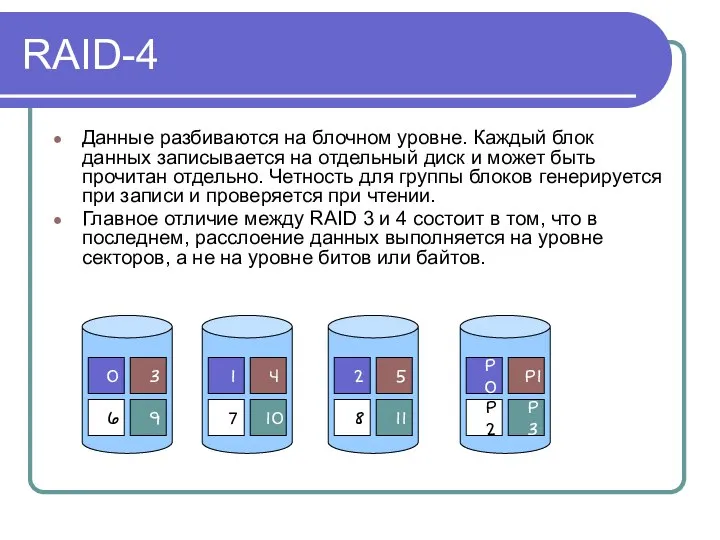
RAID-4
Данные разбиваются на блочном уровне. Каждый блок данных записывается на отдельный
RAID-4
Данные разбиваются на блочном уровне. Каждый блок данных записывается на отдельный

RAID-4
Преимущества:
очень высокая скорость чтения данных больших объемов;
высокая производительность при
RAID-4
Преимущества:
очень высокая скорость чтения данных больших объемов;
высокая производительность при
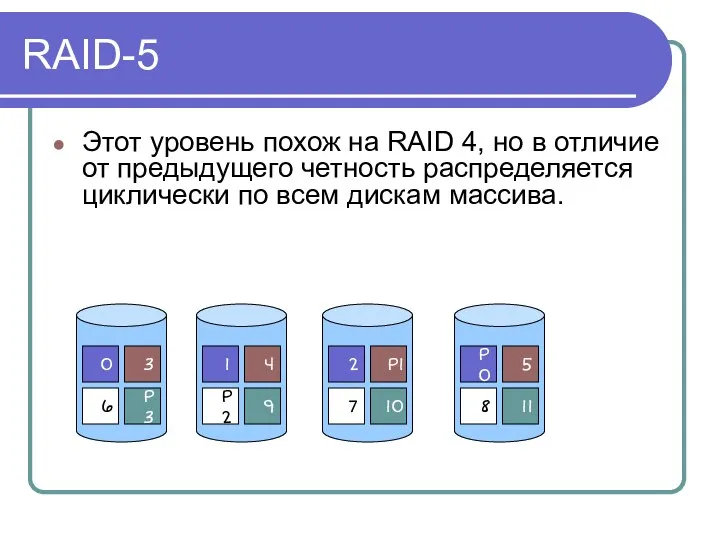
RAID-5
Этот уровень похож на RAID 4, но в отличие от предыдущего
RAID-5
Этот уровень похож на RAID 4, но в отличие от предыдущего

RAID-5
Преимущества:
высокая производительность при большой интенсивности запросов чтения/записи данных;
малые накладные
RAID-5
Преимущества:
высокая производительность при большой интенсивности запросов чтения/записи данных;
малые накладные
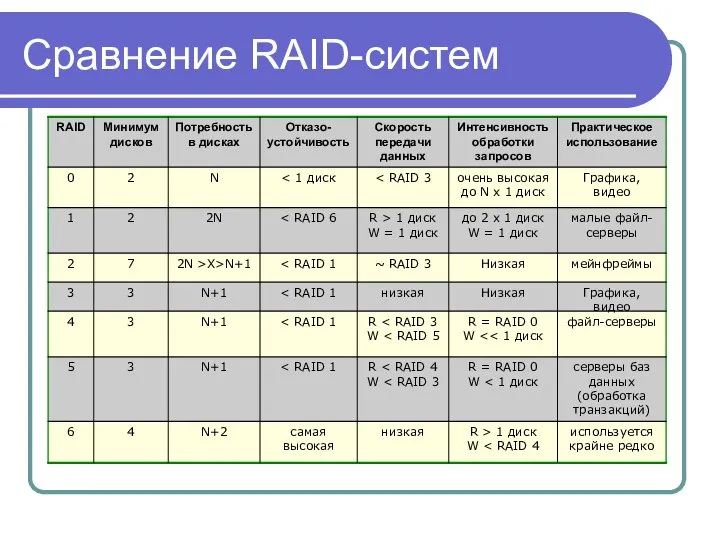
Сравнение RAID-систем
Сравнение RAID-систем

Составные RAID системы
RAID 0+1 / RAID 1+0
RAID 0+3 / RAID
Составные RAID системы
RAID 0+1 / RAID 1+0
RAID 0+3 / RAID

Сравнение RAID 0+1 и RAID 1+0
В RAID 0+1 формируется 2 идентичных
Сравнение RAID 0+1 и RAID 1+0
В RAID 0+1 формируется 2 идентичных
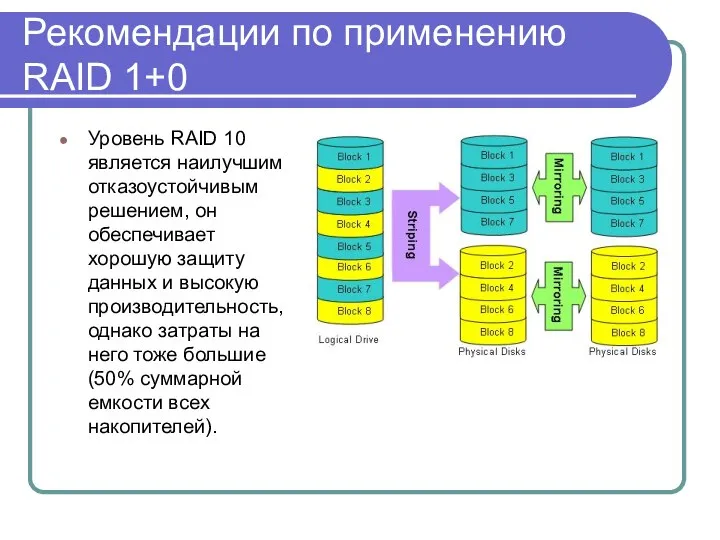
Рекомендации по применению RAID 1+0
Уровень RAID 10 является наилучшим отказоустойчивым решением, он
Рекомендации по применению RAID 1+0
Уровень RAID 10 является наилучшим отказоустойчивым решением, он

Реализация RAID-систем
программная (software-based);
аппаратная - шинно-ориентированная (bus-based);
аппаратная - автономная подсистема
Реализация RAID-систем
программная (software-based);
аппаратная - шинно-ориентированная (bus-based);
аппаратная - автономная подсистема

Программная реализация RAID
Главное преимущество программной реализации - низкая стоимость.
Но при
Программная реализация RAID
Главное преимущество программной реализации - низкая стоимость.
Но при

Программная реализация RAID
Ядро GNU/Linux 2.6.28 (последнее из вышедших в 2008 году)
Программная реализация RAID
Ядро GNU/Linux 2.6.28 (последнее из вышедших в 2008 году)
 ЖОСТОВО. РОСПИСЬ ПО МЕТАЛЛУ
ЖОСТОВО. РОСПИСЬ ПО МЕТАЛЛУ  Проектирование отделения асбестообогатительной фабрики для ведения технологического процесса согласно заданным параметрам
Проектирование отделения асбестообогатительной фабрики для ведения технологического процесса согласно заданным параметрам Презентация "Права акционеров, равноправное отношение и роль осударства" - скачать презентации по Экономике
Презентация "Права акционеров, равноправное отношение и роль осударства" - скачать презентации по Экономике Система смазки и суфлирования
Система смазки и суфлирования Общественное сознание и духовное производство
Общественное сознание и духовное производство П 7
П 7 Эдом. Происхождение эдома
Эдом. Происхождение эдома Компьютерные Сети
Компьютерные Сети  Рождество Христово
Рождество Христово Презентация Бюджетная система ФРГ
Презентация Бюджетная система ФРГ  Гришкова Т.П. Выступление на педсовете МАОУ СОШ № 50 города Томска 9.01.2012
Гришкова Т.П. Выступление на педсовете МАОУ СОШ № 50 города Томска 9.01.2012 Контрольно-измерительные приборы
Контрольно-измерительные приборы Модуляция. Способы и типы модуляции
Модуляция. Способы и типы модуляции Қылмыстық сот ісін жүргізу саласындағы халықаралық ынтымақтастық
Қылмыстық сот ісін жүргізу саласындағы халықаралық ынтымақтастық Общая одонтология Анатомия человека
Общая одонтология Анатомия человека Понятие политических институтов. Агенты политических отношений
Понятие политических институтов. Агенты политических отношений Современные проблемы экономической теории Раздел: Международная экономика
Современные проблемы экономической теории Раздел: Международная экономика  Женские образы святых в православной иконописи
Женские образы святых в православной иконописи Специфические особенности отчётности
Специфические особенности отчётности Сувенірна продукція
Сувенірна продукція Правоспособность и дееспособность гражданина
Правоспособность и дееспособность гражданина Венедиктова Светлана Евгеньевна, учитель русского языка и литературы, библиотекарь. Сорокина Тамара Алексеевна, учитель русского
Венедиктова Светлана Евгеньевна, учитель русского языка и литературы, библиотекарь. Сорокина Тамара Алексеевна, учитель русского Презентация Воспитание
Презентация Воспитание Знатоки искусства. Урок-викторина
Знатоки искусства. Урок-викторина Аксонометрические проекции окружностей (лекция №6)
Аксонометрические проекции окружностей (лекция №6) проект «Разработка модели современного урока»
проект «Разработка модели современного урока» Презентация на тему "Месть и прощение" - скачать презентации по Педагогике
Презентация на тему "Месть и прощение" - скачать презентации по Педагогике Методика подготовки и проведения лекции
Методика подготовки и проведения лекции