- Основные направления исследований в области искусственного интеллекта

Содержание
- 2. Инженерия знаний Необходимой частью любой интеллектуальной системы являются знания. Понятие “инженерия знаний” в 1977 г. ввел
- 3. Данные, информация, знания Данными называют информацию фактического характера, описывающую объекты, процессы и явления предметной области, а
- 4. Данные, информация, знания представление на специальных языках описания данных, предназначенных для ввода и обработки исходных данных
- 5. Данные, информация, знания На практике часто отождествляются определения таких понятий, как "информация", "данные", "знания". Однако эти
- 6. Данные, информация, знания
- 7. Данные, информация, знания Пример 1. Мы можем услышать речь человека, обращающегося к нам, говорящего на иностранном
- 8. Данные, информация, знания Пример 1. Методы являются субъективными. В основе искусственных методов лежат алгоритмы (упорядоченные последовательности
- 9. Данные, информация, знания
- 10. Данные, информация, знания Пример 2. Когда мы видим 45, 12, 8, red и т.д., то можно
- 11. Данные, информация, знания Пример 3. С одной стороны, 45 кг - это информация. Но с другой
- 12. Данные, информация, знания Пример 3. Например, если нас интересует вес, который может выдержать мост, то 45
- 13. Данные, информация, знания Пример 3. Данные, составляющие информацию, имеют свойства, однозначно определяющие соответствующий метод получения этой
- 14. Данные, информация, знания
- 15. Данные, информация, знания
- 16. Данные, информация, знания Давайте охарактеризуем знания. Прежде всего, у каждого из нас есть индивидуальный способ их
- 17. Данные, информация, знания Можно сделать вывод, что фиксируемые воспринимаемые факты окружающего мира представляют собой данные. При
- 18. Категория “знания” Знания в ИИС существуют в следующих формах: исходные знания (правила, выведенные на основе практического
- 19. Категория “знания” описание исходных знаний средствами выбранной модели представления знаний (множество логических формул или продукционных правил,
- 20. Определение “знания” Из толкового словаря С. И. Ожегова: «Знание — постижение действительности сознанием, наука»; «Знание —
- 21. Определение “знания” Исследователи в области ИИ : «Знания — это закономерности предметной области (принципы, связи, законы),
- 22. Разработка интеллектуальных информационных систем или систем, основанных на знаниях. Цель - выявление, исследование и применение знаний
- 23. Разработка естественно-языковых интерфейсов и машинный перевод. Машинный перевод–выполняемое на компьютере действие по преобразованию текста на одном
- 24. Разработка естественно-языковых интерфейсов и машинный перевод. «Лингвистический арифмометр» Смирнова-Троянского В 1933 году изобретатель П.П.Смирнов-Троянский получил в
- 25. Разработка естественно-языковых интерфейсов и машинный перевод. 40-е годы −первые системы МП Теоретической основой начального периода работ
- 26. Разработка естественно-языковых интерфейсов и машинный перевод. Концепция Interlingva Идеи Уивера легли в основу подхода к МП,
- 27. Разработка естественно-языковых интерфейсов и машинный перевод. Первые системы МП В 1952 г. состоялась первая конференция по
- 28. Разработка естественно-языковых интерфейсов и машинный перевод. Системы прямого перевода Причины невысокого качества МП в 50-е годы
- 29. Разработка естественно-языковых интерфейсов и машинный перевод. Системы МП в 60-е годы Разработка систем МП в 60-е
- 30. Разработка естественно-языковых интерфейсов и машинный перевод. Новый импульс в разработке систем МП (70-80-е годы) Новый подъем
- 31. Разработка естественно-языковых интерфейсов и машинный перевод. Технология TM (translationmemory) В процессе перевода сохраняется исходный сегмент текста(предложение)
- 32. Разработка естественно-языковых интерфейсов и машинный перевод. Советские системы МП 70-80 гг. В СССР с середины 70-х
- 33. Разработка естественно-языковых интерфейсов и машинный перевод. Stylus — система МП, включающая множество словарей по разным ПрО;
- 34. Разработка естественно-языковых интерфейсов и машинный перевод.
- 35. Разработка естественно-языковых интерфейсов и машинный перевод. Проблему перевода английского предложения Е, скажем, во французское предложение F
- 36. Разработка естественно-языковых интерфейсов и машинный перевод. Это правило указывает, что мы должны рассмотреть все возможные французские
- 37. Разработка естественно-языковых интерфейсов и машинный перевод. Вероятность P(E\F) представляет собой модель перевода; она указывает, насколько велика
- 38. Разработка естественно-языковых интерфейсов и машинный перевод. В качестве языковой модели P(F) может использоваться любая модель, позволяющая
- 39. Разработка естественно-языковых интерфейсов и машинный перевод. Например, если с помощью Web будет собрано 100 миллионов французских
- 40. Разработка естественно-языковых интерфейсов и машинный перевод. Поэтому как правило используется языковая модель двухсловных сочетаний, в которой
- 41. Разработка естественно-языковых интерфейсов и машинный перевод. Для этого необходимо знать вероятности двухсловных сочетаний, такие как Р("Eiffel"
- 42. Разработка естественно-языковых интерфейсов и машинный перевод. Задача выбора модели перевода, Р(Е|F), является более сложной. Начнем с
- 43. Разработка естественно-языковых интерфейсов и машинный перевод. Рассматриваемая чрезмерно упрощенная модель перевода основана на таком принципе: "Чтобы
- 44. Системы автоматического реферирования и аннотирования Рефератом называют: доклад на определенную тему, включающий обзор соответствующих литературных и
- 45. Системы автоматического реферирования и аннотирования На первом проводится сопоставление текста и фразовых шаблонов, в результате чего
- 46. Системы автоматического реферирования и аннотирования k1 - учитывают расположение блока: во всем тексте или некотором разделе;
- 47. Системы автоматического реферирования и аннотирования k3 - учитывается наличие в блоке таких ключевых фраз и выражений,
- 48. Системы автоматического реферирования и аннотирования Microsoft Word (начиная с версии 7 имеется функция автоматического реферирования); ОРФО
- 49. Системы автоматического реферирования и аннотирования поисковая система «Следопыт», включающая средства автоматического реферирования и аннотирования документов; •
- 50. Генерация и распознавание речи. Системы распознавания по сложности обычно делят на следующие группы: Системы автоматического распознавания
- 51. Генерация и распознавание речи. Системы автоматического распознавания слитной речи. То есть система должна уметь выделять слова
- 52. Генерация и распознавание речи. Cистема распознавания русской речи RuSpeech. (компании Intel и Cognitive Technologies. В основе
- 53. Генерация и распознавание речи.
- 54. Генерация и распознавание речи. Необработанная речь. Обычно, поток звуковых данных, записанный с высокой дискретизацией (20 КГц
- 55. Генерация и распознавание речи. Анализ сигнала. Поступающий сигнал должен быть изначально трансформирован и сжат, для облегчения
- 56. Генерация и распознавание речи. Речевые кадры. Результатом анализа сигнала является последовательность речевых кадров. Обычно, каждый речевой
- 57. Генерация и распознавание речи.
- 58. Генерация и распознавание речи. Акустические модели. Для анализа состава речевых кадров требуется набор акустических моделей. Рассмотрим
- 59. Генерация и распознавание речи. Модель состояний. Каждое слово моделируется как последовательность состояний указывающих набор звуков, которые
- 60. Генерация и распознавание речи. Акустический анализ. Состоит в сопоставлении различных акустических моделей к каждому кадру речи
- 61. Генерация и распознавание речи. Корректировка времени. Используется для обработки временной вариативности, возникающей при произношении слов (например,
- 62. Генерация и распознавание речи. Последовательность слов. В результате работы, система распознавания речи выдает последовательность (или несколько
- 63. Генерация и распознавание речи. На сегодняшний день основными направлениями развития систем речевого общения видятся следующие: минимизация
- 64. Обработка визуальной информации (OCR-системы) Понятие образа Образ, класс — классификационная группировка в системе классификации, объединяющая (выделяющая)
- 65. Обработка визуальной информации (OCR-системы) Образное восприятие мира — одно из загадочных свойств живого мозга, позволяющее разобраться
- 66. Обработка визуальной информации (OCR-системы) Например, несмотря на существенное различие, к одной группе относятся все буквы А,
- 67. Обработка визуальной информации (OCR-системы) В лучших OCR-системах используется технология распознавания, свойственная человеку. У человека распознавание образа
- 68. Обработка визуальной информации (OCR-системы) Работа системы типа Fine Reader включает два крупных этапа. 1. Анализ графических
- 69. Обработка визуальной информации (OCR-системы) В шаблонных классификаторах с помощью критерия сравнения определяется, какой из шаблонов выбрать
- 70. Обработка визуальной информации (OCR-системы) Наиболее распространены признаковые классификаторы. Анализ в них проводится только по набору чисел
- 71. Обработка визуальной информации (OCR-системы) Структурные классификаторы переводят образ символа в его топологическое представление, отражающее информацию о
- 72. Обработка визуальной информации (OCR-системы) Технология распознавания с помощью структурно-пятенных эталонов получила название "фонтанное преобразование" (от английского
- 73. Обработка визуальной информации (OCR-системы) Эти отношения (то есть расположение пятен друг относительно друга) образуют структурные элементы,
- 74. Обработка визуальной информации (OCR-системы) Практическое применение OCR-систем поиск людей по фотографиям; поиск месторождений полезных ископаемых и
- 75. Обработка визуальной информации (OCR-системы) составление географических карт по исходной информации, используемой в предыдущей задаче; анализ отпечатков
- 76. Обучение и самообучение. Включает модели, методы и алгоритмы, ориентированные на автоматическое накопление и формирование знаний с
- 77. Обучение и самообучение. Деревья решения являются одним из наиболее популярных подходов к решению задач Data Mining.
- 78. Обучение и самообучение. Вопросы имеют вид "значение параметра A больше x?". Если ответ положительный, осуществляется переход
- 79. Обучение и самообучение.
- 80. Игры и машинное творчество. Охватывает создание компьютерной музыки, стихов, интеллектуальные системы для изобретения новых объектов, cоздание
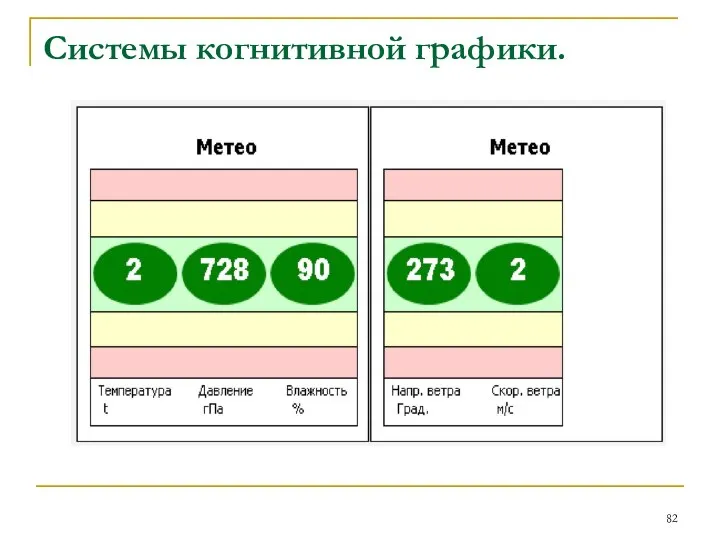
- 81. Системы когнитивной графики. Ориентированы на общение с пользователем ИИС посредством графических образов, которые генерируются в соответствии
- 82. Системы когнитивной графики.
- 83. Системы когнитивной графики.
- 84. Системы контекстной помощи. В них пользователь описывает проблему, а система на основе дополнительного диалога конкретизирует ее
- 85. Программное обеспечение систем ИИ Языки программирования, ориентированные на обработку символьной информации языки логического программирования (PROLOG), языки
- 86. Признаки ИИС коммуникативные способности — способ взаимодействия конечного пользователя с системой; решение сложных плохо формализуемых задач,
- 88. Скачать презентацию

Инженерия знаний
Необходимой частью любой интеллектуальной системы являются знания.
Понятие “инженерия знаний”
Инженерия знаний
Необходимой частью любой интеллектуальной системы являются знания.
Понятие “инженерия знаний”

Данные, информация, знания
Данными называют информацию фактического характера, описывающую объекты, процессы и
Данные, информация, знания
Данными называют информацию фактического характера, описывающую объекты, процессы и

Данные, информация, знания
представление на специальных языках описания данных, предназначенных для ввода
Данные, информация, знания
представление на специальных языках описания данных, предназначенных для ввода

Данные, информация, знания
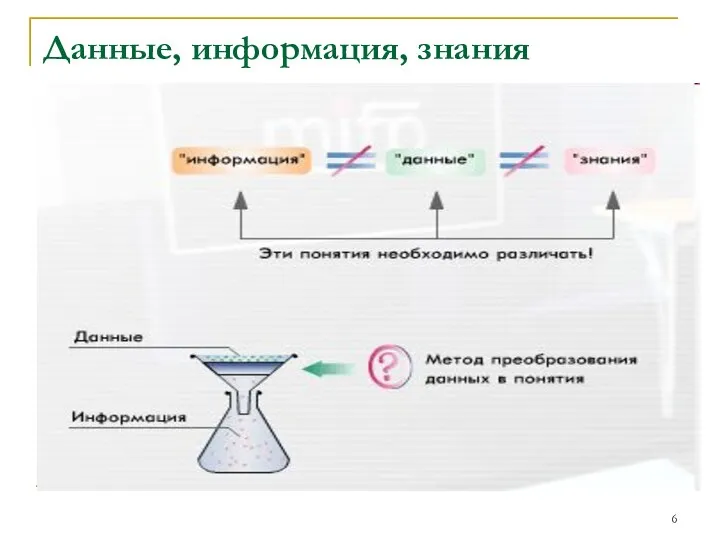
На практике часто отождествляются определения таких понятий, как "информация",
Данные, информация, знания
На практике часто отождествляются определения таких понятий, как "информация",
Данные, информация, знания
Данные, информация, знания

Данные, информация, знания
Пример 1.
Мы можем услышать речь человека, обращающегося к
Данные, информация, знания
Пример 1. Мы можем услышать речь человека, обращающегося к

Данные, информация, знания
Пример 1.
Методы являются субъективными. В основе искусственных методов
Данные, информация, знания
Пример 1. Методы являются субъективными. В основе искусственных методов
Данные, информация, знания
Данные, информация, знания

Данные, информация, знания
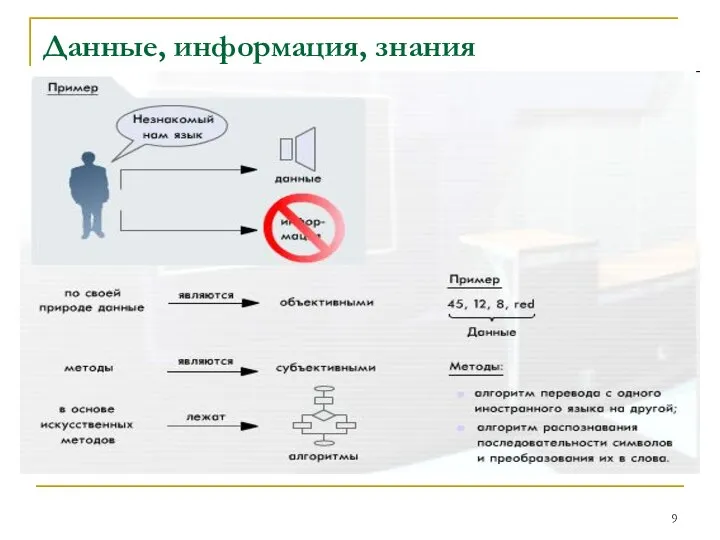
Пример 2.
Когда мы видим 45, 12, 8, red
Данные, информация, знания
Пример 2. Когда мы видим 45, 12, 8, red

Данные, информация, знания
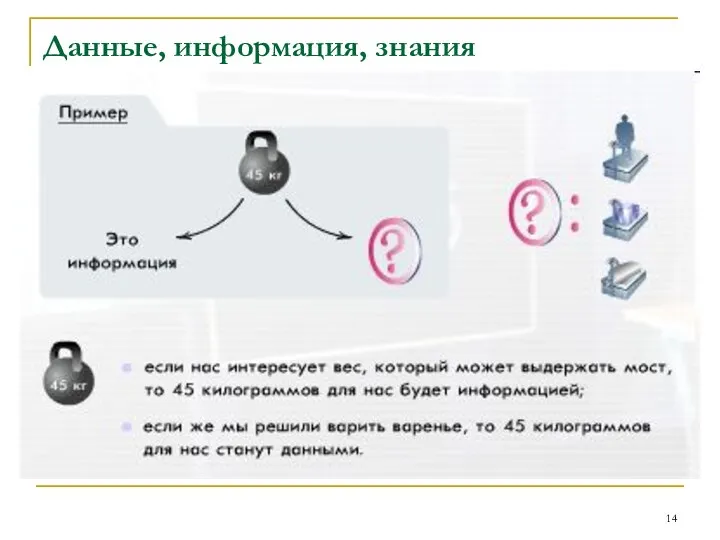
Пример 3.
С одной стороны, 45 кг - это
Данные, информация, знания
Пример 3. С одной стороны, 45 кг - это

Данные, информация, знания
Пример 3.
Например, если нас интересует вес, который может
Данные, информация, знания
Пример 3. Например, если нас интересует вес, который может

Данные, информация, знания
Пример 3.
Данные, составляющие информацию, имеют свойства, однозначно определяющие
Данные, информация, знания
Пример 3. Данные, составляющие информацию, имеют свойства, однозначно определяющие
Данные, информация, знания
Данные, информация, знания

Данные, информация, знания
Данные, информация, знания

Данные, информация, знания
Давайте охарактеризуем знания. Прежде всего, у каждого из нас
Данные, информация, знания
Давайте охарактеризуем знания. Прежде всего, у каждого из нас

Данные, информация, знания
Можно сделать вывод, что фиксируемые воспринимаемые факты окружающего мира
Данные, информация, знания
Можно сделать вывод, что фиксируемые воспринимаемые факты окружающего мира

Категория “знания”
Знания в ИИС существуют в следующих формах:
исходные знания (правила,
Категория “знания”
Знания в ИИС существуют в следующих формах:
исходные знания (правила,

Категория “знания”
описание исходных знаний средствами выбранной модели представления знаний (множество логических
Категория “знания”
описание исходных знаний средствами выбранной модели представления знаний (множество логических

Определение “знания”
Из толкового словаря С. И. Ожегова:
«Знание — постижение действительности сознанием,
Определение “знания”
Из толкового словаря С. И. Ожегова:
«Знание — постижение действительности сознанием,

Определение “знания”
Исследователи в области ИИ :
«Знания — это закономерности предметной области
Определение “знания”
Исследователи в области ИИ :
«Знания — это закономерности предметной области

Разработка интеллектуальных информационных систем или систем, основанных на знаниях.
Цель
Разработка интеллектуальных информационных систем или систем, основанных на знаниях.
Цель

Разработка естественно-языковых интерфейсов и машинный перевод.
Машинный перевод–выполняемое на компьютере действие
Разработка естественно-языковых интерфейсов и машинный перевод.
Машинный перевод–выполняемое на компьютере действие

Разработка естественно-языковых интерфейсов и машинный перевод.
«Лингвистический арифмометр» Смирнова-Троянского
В 1933 году
Разработка естественно-языковых интерфейсов и машинный перевод.
«Лингвистический арифмометр» Смирнова-Троянского
В 1933 году

Разработка естественно-языковых интерфейсов и машинный перевод.
40-е годы −первые системы МП
Разработка естественно-языковых интерфейсов и машинный перевод.
40-е годы −первые системы МП

Разработка естественно-языковых интерфейсов и машинный перевод.
Концепция Interlingva
Идеи Уивера легли в
Разработка естественно-языковых интерфейсов и машинный перевод.
Концепция Interlingva
Идеи Уивера легли в

Разработка естественно-языковых интерфейсов и машинный перевод.
Первые системы МП
В 1952 г.
Разработка естественно-языковых интерфейсов и машинный перевод.
Первые системы МП
В 1952 г.

Разработка естественно-языковых интерфейсов и машинный перевод.
Системы прямого перевода
Причины невысокого качества
Разработка естественно-языковых интерфейсов и машинный перевод.
Системы прямого перевода
Причины невысокого качества

Разработка естественно-языковых интерфейсов и машинный перевод.
Системы МП в 60-е годы
Разработка
Разработка естественно-языковых интерфейсов и машинный перевод.
Системы МП в 60-е годы
Разработка

Разработка естественно-языковых интерфейсов и машинный перевод.
Новый импульс в разработке систем
Разработка естественно-языковых интерфейсов и машинный перевод.
Новый импульс в разработке систем
Разработка естественно-языковых интерфейсов и машинный перевод.
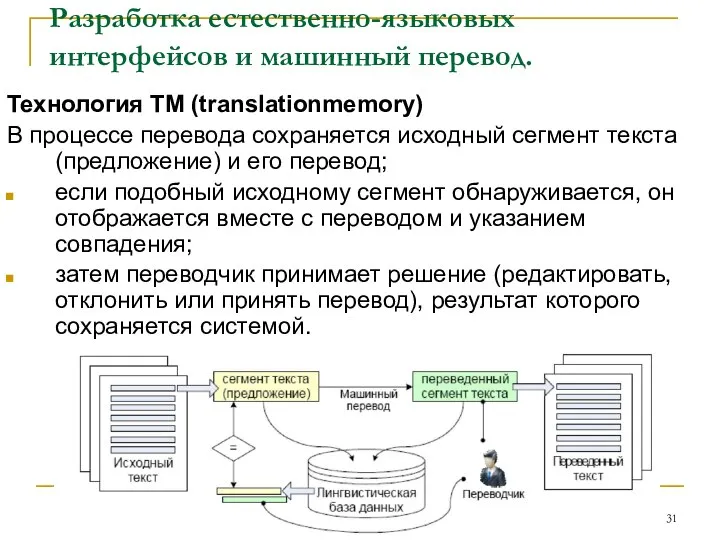
Технология TM (translationmemory)
В процессе перевода
Разработка естественно-языковых интерфейсов и машинный перевод.
Технология TM (translationmemory)
В процессе перевода

Разработка естественно-языковых интерфейсов и машинный перевод.
Советские системы МП 70-80 гг.
В
Разработка естественно-языковых интерфейсов и машинный перевод.
Советские системы МП 70-80 гг.
В

Разработка естественно-языковых интерфейсов и машинный перевод.
Stylus — система МП, включающая
Разработка естественно-языковых интерфейсов и машинный перевод.
Stylus — система МП, включающая
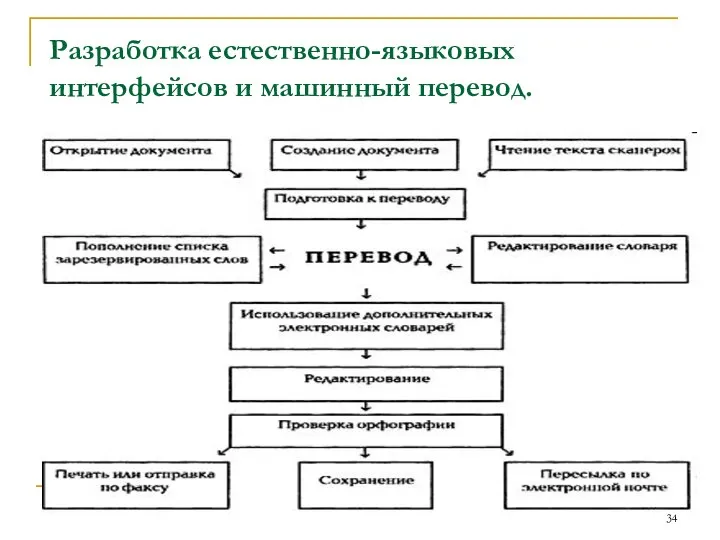
Разработка естественно-языковых интерфейсов и машинный перевод.
Разработка естественно-языковых интерфейсов и машинный перевод.

Разработка естественно-языковых интерфейсов и машинный перевод.
Проблему перевода английского предложения Е,
Разработка естественно-языковых интерфейсов и машинный перевод.
Проблему перевода английского предложения Е,

Разработка естественно-языковых интерфейсов и машинный перевод.
Это правило указывает, что мы
Разработка естественно-языковых интерфейсов и машинный перевод.
Это правило указывает, что мы

Разработка естественно-языковых интерфейсов и машинный перевод.
Вероятность P(E\F) представляет собой модель
Разработка естественно-языковых интерфейсов и машинный перевод.
Вероятность P(E\F) представляет собой модель

Разработка естественно-языковых интерфейсов и машинный перевод.
В качестве языковой модели P(F)
Разработка естественно-языковых интерфейсов и машинный перевод.
В качестве языковой модели P(F)

Разработка естественно-языковых интерфейсов и машинный перевод.
Например, если с помощью Web
Разработка естественно-языковых интерфейсов и машинный перевод.
Например, если с помощью Web

Разработка естественно-языковых интерфейсов и машинный перевод.
Поэтому как правило используется языковая
Разработка естественно-языковых интерфейсов и машинный перевод.
Поэтому как правило используется языковая

Разработка естественно-языковых интерфейсов и машинный перевод.
Для этого необходимо знать вероятности
Разработка естественно-языковых интерфейсов и машинный перевод.
Для этого необходимо знать вероятности

Разработка естественно-языковых интерфейсов и машинный перевод.
Задача выбора модели перевода, Р(Е|F),
Разработка естественно-языковых интерфейсов и машинный перевод.
Задача выбора модели перевода, Р(Е|F),

Разработка естественно-языковых интерфейсов и машинный перевод.
Рассматриваемая чрезмерно упрощенная модель перевода
Разработка естественно-языковых интерфейсов и машинный перевод.
Рассматриваемая чрезмерно упрощенная модель перевода

Системы автоматического реферирования и аннотирования
Рефератом называют:
доклад на определенную тему, включающий обзор
Системы автоматического реферирования и аннотирования
Рефератом называют:
доклад на определенную тему, включающий обзор

Системы автоматического реферирования и аннотирования
На первом проводится сопоставление текста и фразовых
Системы автоматического реферирования и аннотирования
На первом проводится сопоставление текста и фразовых

Системы автоматического реферирования и аннотирования
k1 - учитывают расположение блока: во всем
Системы автоматического реферирования и аннотирования
k1 - учитывают расположение блока: во всем

Системы автоматического реферирования и аннотирования
k3 - учитывается наличие в блоке таких
Системы автоматического реферирования и аннотирования
k3 - учитывается наличие в блоке таких

Системы автоматического реферирования и аннотирования
Microsoft Word (начиная с версии 7 имеется
Системы автоматического реферирования и аннотирования
Microsoft Word (начиная с версии 7 имеется

Системы автоматического реферирования и аннотирования
поисковая система «Следопыт», включающая средства автоматического реферирования
Системы автоматического реферирования и аннотирования
поисковая система «Следопыт», включающая средства автоматического реферирования

Генерация и распознавание речи.
Системы распознавания по сложности обычно делят
Генерация и распознавание речи.
Системы распознавания по сложности обычно делят

Генерация и распознавание речи.
Системы автоматического распознавания слитной речи. То есть
Генерация и распознавание речи.
Системы автоматического распознавания слитной речи. То есть

Генерация и распознавание речи.
Cистема распознавания русской речи RuSpeech. (компании
Генерация и распознавание речи.
Cистема распознавания русской речи RuSpeech. (компании
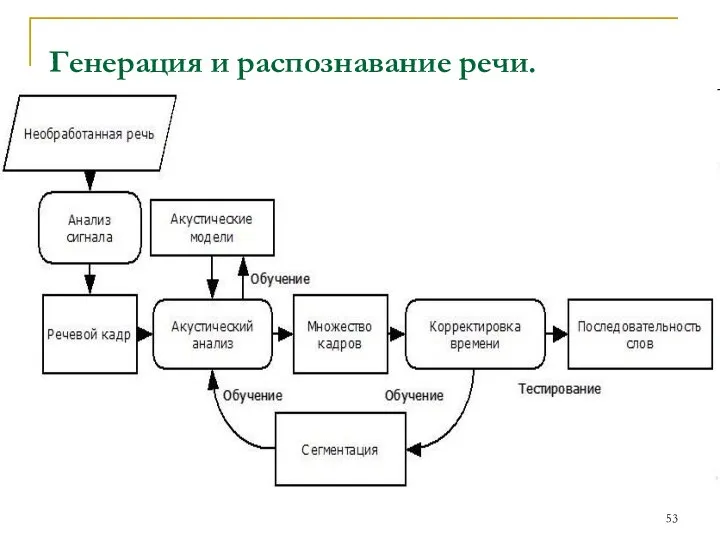
Генерация и распознавание речи.
Генерация и распознавание речи.
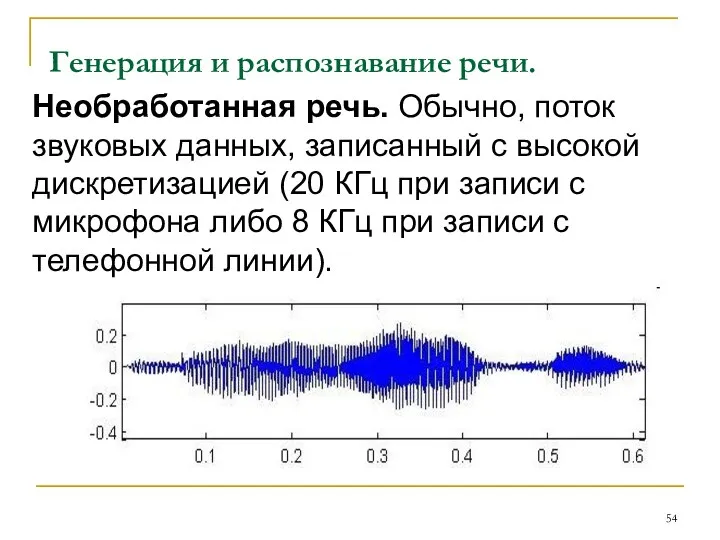
Генерация и распознавание речи.
Необработанная речь. Обычно, поток звуковых данных,
Генерация и распознавание речи.
Необработанная речь. Обычно, поток звуковых данных,
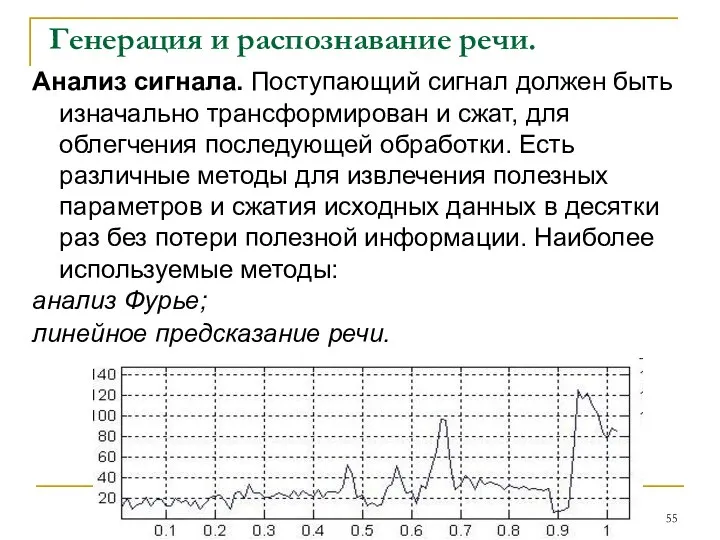
Генерация и распознавание речи.
Анализ сигнала. Поступающий сигнал должен быть
Генерация и распознавание речи.
Анализ сигнала. Поступающий сигнал должен быть

Генерация и распознавание речи.
Речевые кадры. Результатом анализа сигнала является
Генерация и распознавание речи.
Речевые кадры. Результатом анализа сигнала является
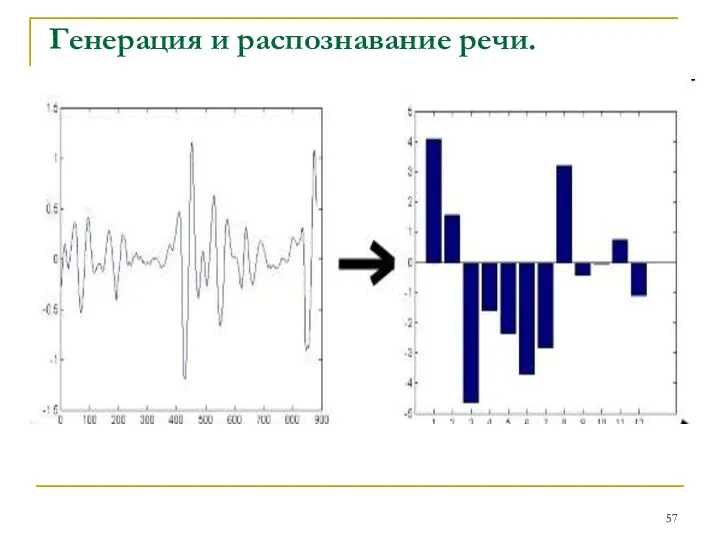
Генерация и распознавание речи.
Генерация и распознавание речи.

Генерация и распознавание речи.
Акустические модели. Для анализа состава речевых кадров
Генерация и распознавание речи.
Акустические модели. Для анализа состава речевых кадров

Генерация и распознавание речи.
Модель состояний. Каждое слово моделируется как последовательность
Генерация и распознавание речи.
Модель состояний. Каждое слово моделируется как последовательность

Генерация и распознавание речи.
Акустический анализ. Состоит в сопоставлении различных акустических
Генерация и распознавание речи.
Акустический анализ. Состоит в сопоставлении различных акустических
Генерация и распознавание речи.
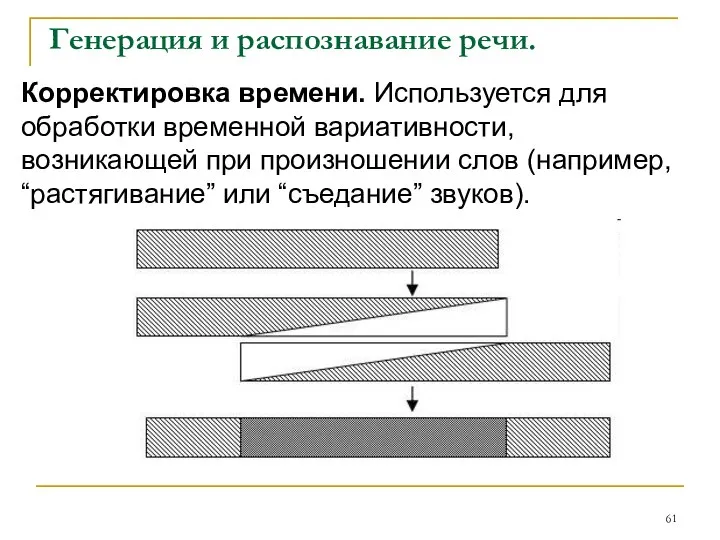
Корректировка времени. Используется для обработки временной вариативности,
Генерация и распознавание речи.
Корректировка времени. Используется для обработки временной вариативности,

Генерация и распознавание речи.
Последовательность слов. В результате работы, система распознавания
Генерация и распознавание речи.
Последовательность слов. В результате работы, система распознавания

Генерация и распознавание речи.
На сегодняшний день основными направлениями
развития систем речевого
Генерация и распознавание речи.
На сегодняшний день основными направлениями
развития систем речевого

Обработка визуальной информации
(OCR-системы)
Понятие образа
Образ, класс — классификационная группировка в
Обработка визуальной информации
(OCR-системы)
Понятие образа
Образ, класс — классификационная группировка в

Обработка визуальной информации
(OCR-системы)
Образное восприятие мира — одно из загадочных
Обработка визуальной информации
(OCR-системы)
Образное восприятие мира — одно из загадочных

Обработка визуальной информации
(OCR-системы)
Например, несмотря на существенное различие, к одной
Обработка визуальной информации
(OCR-системы)
Например, несмотря на существенное различие, к одной
Обработка визуальной информации
(OCR-системы)
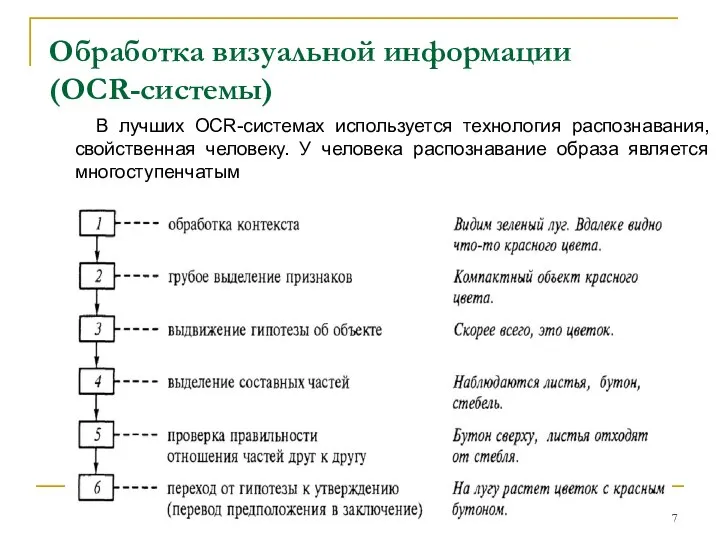
В лучших OCR-системах используется технология распознавания,
Обработка визуальной информации
(OCR-системы)
В лучших OCR-системах используется технология распознавания,

Обработка визуальной информации
(OCR-системы)
Работа системы типа Fine Reader включает
Обработка визуальной информации
(OCR-системы)
Работа системы типа Fine Reader включает

Обработка визуальной информации
(OCR-системы)
В шаблонных классификаторах с помощью критерия
Обработка визуальной информации
(OCR-системы)
В шаблонных классификаторах с помощью критерия

Обработка визуальной информации
(OCR-системы)
Наиболее распространены признаковые классификаторы. Анализ в
Обработка визуальной информации
(OCR-системы)
Наиболее распространены признаковые классификаторы. Анализ в

Обработка визуальной информации
(OCR-системы)
Структурные классификаторы переводят образ символа в
Обработка визуальной информации
(OCR-системы)
Структурные классификаторы переводят образ символа в

Обработка визуальной информации
(OCR-системы)
Технология распознавания с помощью структурно-пятенных эталонов
Обработка визуальной информации
(OCR-системы)
Технология распознавания с помощью структурно-пятенных эталонов

Обработка визуальной информации
(OCR-системы)
Эти отношения (то есть расположение пятен
Обработка визуальной информации
(OCR-системы)
Эти отношения (то есть расположение пятен

Обработка визуальной информации
(OCR-системы)
Практическое применение OCR-систем
поиск людей по фотографиям;
поиск месторождений
Обработка визуальной информации
(OCR-системы)
Практическое применение OCR-систем
поиск людей по фотографиям;
поиск месторождений

Обработка визуальной информации
(OCR-системы)
составление географических карт по исходной информации, используемой
Обработка визуальной информации
(OCR-системы)
составление географических карт по исходной информации, используемой

Обучение и самообучение.
Включает модели, методы и алгоритмы, ориентированные на
Обучение и самообучение.
Включает модели, методы и алгоритмы, ориентированные на

Обучение и самообучение.
Деревья решения являются одним из наиболее популярных
Обучение и самообучение.
Деревья решения являются одним из наиболее популярных

Обучение и самообучение.
Вопросы имеют вид "значение параметра A больше x?".
Обучение и самообучение.
Вопросы имеют вид "значение параметра A больше x?".
Обучение и самообучение.
Обучение и самообучение.

Игры и машинное творчество.
Охватывает создание компьютерной музыки, стихов, интеллектуальные
Игры и машинное творчество.
Охватывает создание компьютерной музыки, стихов, интеллектуальные

Системы когнитивной графики.
Ориентированы на общение с пользователем ИИС посредством графических образов,
Системы когнитивной графики.
Ориентированы на общение с пользователем ИИС посредством графических образов,
Системы когнитивной графики.
Системы когнитивной графики.

Системы когнитивной графики.
Системы когнитивной графики.

Системы контекстной помощи.
В них пользователь описывает проблему, а система
Системы контекстной помощи.
В них пользователь описывает проблему, а система

Программное обеспечение систем ИИ
Языки программирования, ориентированные на обработку символьной информации
Программное обеспечение систем ИИ
Языки программирования, ориентированные на обработку символьной информации

Признаки ИИС
коммуникативные способности — способ взаимодействия конечного пользователя с системой;
решение
Признаки ИИС
коммуникативные способности — способ взаимодействия конечного пользователя с системой;
решение
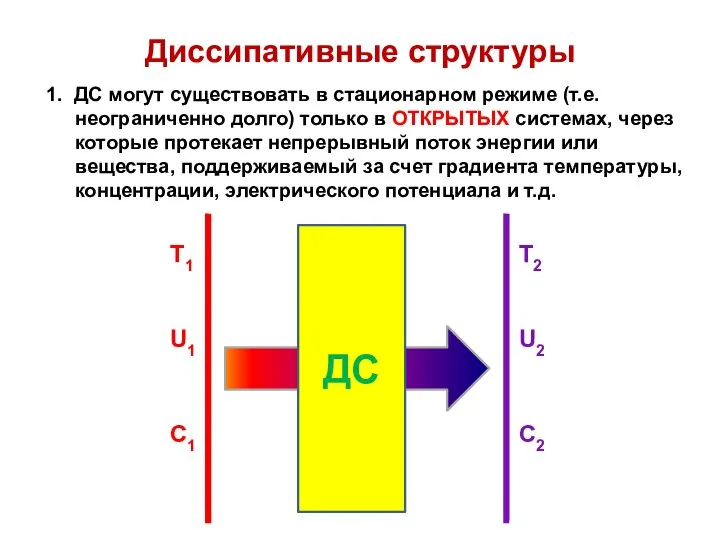 Диссипативные структуры
Диссипативные структуры селянської реформи 1861 року
селянської реформи 1861 року  Презентация "Славянские земледельческие обряды" - скачать презентации по МХК
Презентация "Славянские земледельческие обряды" - скачать презентации по МХК Презентация дисциплины Коррекционная педагогика
Презентация дисциплины Коррекционная педагогика Вступ. Культура як суспільне явище
Вступ. Культура як суспільне явище Архитектура Московского Кремля
Архитектура Московского Кремля Un usual kinds of sport un
Un usual kinds of sport un Устройство нановесы
Устройство нановесы Спорт төрҙәре
Спорт төрҙәре Искусство Индии Восток, Древность,Современость
Искусство Индии Восток, Древность,Современость История кинематографа Материалы к уроку изобразительного искусства в 9 классе по программе Б.Неменского
История кинематографа Материалы к уроку изобразительного искусства в 9 классе по программе Б.Неменского  УСЛОВНО-ПАТОГЕННЫЕ МИКРООРГАНИЗМЫ
УСЛОВНО-ПАТОГЕННЫЕ МИКРООРГАНИЗМЫ  Золушка Художник Сергий Елена
Золушка Художник Сергий Елена  Расчет пластин
Расчет пластин Принципы и методы управления. Принятие управленческих решений
Принципы и методы управления. Принятие управленческих решений Презентация Культура делового общения
Презентация Культура делового общения Изменение политической системы СССР в 1953-1964 гг
Изменение политической системы СССР в 1953-1964 гг Урок обучения чтению Тема : чтение слов и предложений с буквой «Й» Учитель начальных классов ГКОУ «Кабанская СКОШИ VIII» Панфилова
Урок обучения чтению Тема : чтение слов и предложений с буквой «Й» Учитель начальных классов ГКОУ «Кабанская СКОШИ VIII» Панфилова  Воры в законе
Воры в законе Презентация Режим государственной границы
Презентация Режим государственной границы  Пермская и Кунгурская епархия РПЦ Добрянское благочиние. Храм св.апостола Иоанна Богослова
Пермская и Кунгурская епархия РПЦ Добрянское благочиние. Храм св.апостола Иоанна Богослова Сердечно-сосудистая система
Сердечно-сосудистая система  «ПОМНИ ПРАВИЛА ДВИЖЕНЬЯ КАК ТАБЛИЦУ УМНОЖЕНЬЯ»
«ПОМНИ ПРАВИЛА ДВИЖЕНЬЯ КАК ТАБЛИЦУ УМНОЖЕНЬЯ»  Дом из газобетона
Дом из газобетона Поддержка за пару минут makedreamprofits.ru
Поддержка за пару минут makedreamprofits.ru Подшипники скольжения
Подшипники скольжения С П О СО Б Ы О Б Р А З О В А Н И Я С У Щ Е С Т В И Т Е Л Ь Н Ы Х
С П О СО Б Ы О Б Р А З О В А Н И Я С У Щ Е С Т В И Т Е Л Ь Н Ы Х Что такое ООП и с чем его едят
Что такое ООП и с чем его едят