- Работа с файлами в Java

Содержание
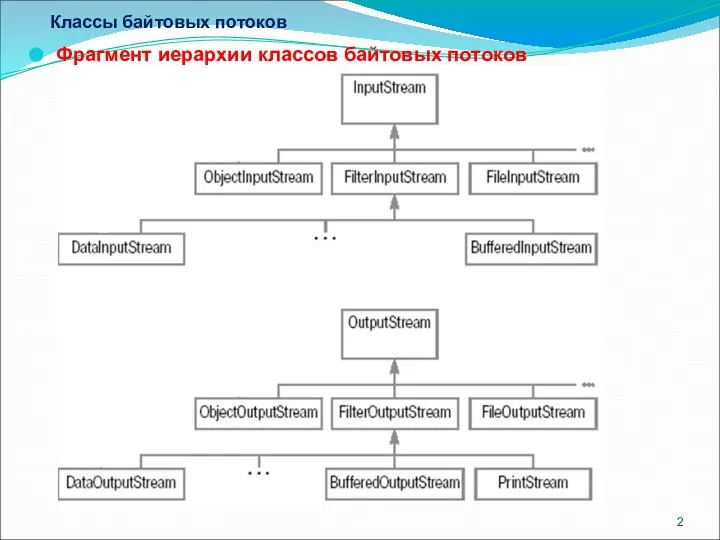
- 2. Классы байтовых потоков Фрагмент иерархии классов байтовых потоков
- 3. Классы байтовых потоков В Java так же как и в С++ для описания работы по вводу/выводу
- 4. Классы InputStream и OutputStream Методы класса InputStream: int read() int read(byte[] buf) int read(byte[] buf, int
- 5. Классы InputStream и OutputStream InputStream – это базовый класс для байтовых потоков ввода. Методы этого класса
- 6. Классы InputStream и OutputStream Класс OutputStream – это базовый класс для байтовых потоков вывода. В классе
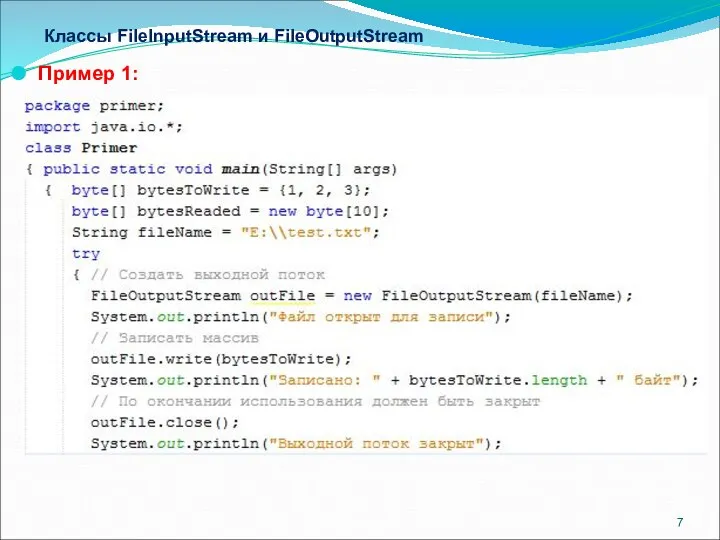
- 7. Классы FileInputStream и FileOutputStream Пример 1:
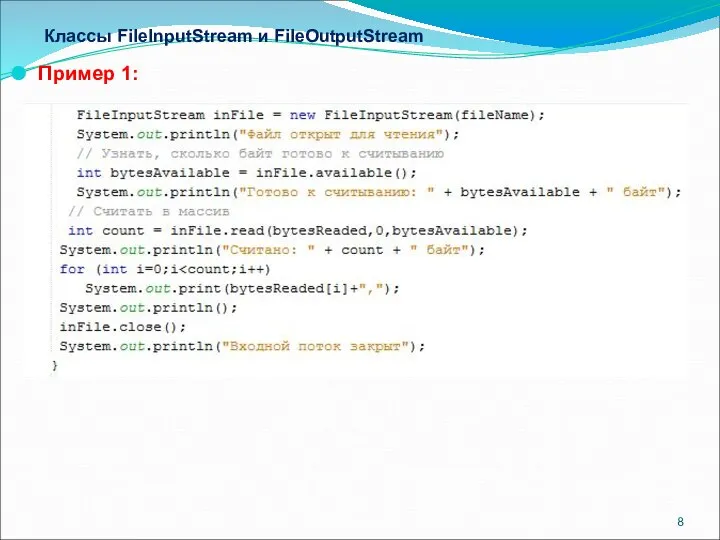
- 8. Классы FileInputStream и FileOutputStream Пример 1:
- 9. Классы FileInputStream и FileOutputStream Пример 1:
- 10. Классы FileInputStream и FileOutputStream Класс FileInputStream используется для чтения данных из файла. Конструктор такого класса в
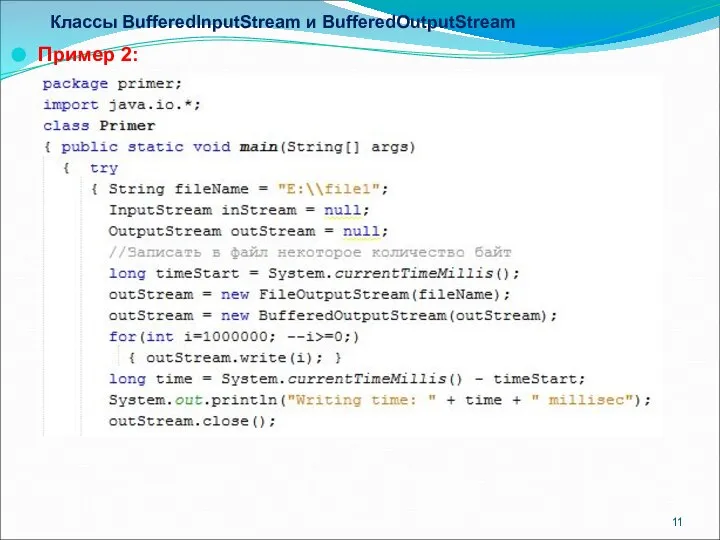
- 11. Классы BufferedInputStream и BufferedOutputStream Пример 2:
- 12. Классы BufferedInputStream и BufferedOutputStream Пример 2:
- 13. Классы BufferedInputStream и BufferedOutputStream Пример 2:
- 14. Классы BufferedInputStream и BufferedOutputStream На практике при считывании с внешних устройств ввод данных почти всегда необходимо
- 15. Классы DataInputStream и DataOutputStream Пример 3:
- 16. Классы DataInputStream и DataOutputStream Пример 3:
- 17. Классы DataInputStream и DataOutputStream Пример 3:
- 18. Классы DataInputStream и DataOutputStream До сих пор речь шла только о считывании и записи в поток
- 19. Классы ObjectInputStream и ObjectOutputStream Пример 4:
- 20. Классы ObjectInputStream и ObjectOutputStream Пример 4:
- 21. Классы ObjectInputStream и ObjectOutputStream Пример 4:
- 22. Классы ObjectInputStream и ObjectOutputStream Для объектов процесс преобразования в последовательность байт и обратно организован несколько сложнее
- 23. Классы ObjectInputStream и ObjectOutputStream Предположим, объект некоторого класса TestClass был сериализован и передан по сети на
- 24. Классы символьных потоков Фрагмент иерархии классов символьных потоков:
- 25. Классы символьных потоков Рассмотренные классы – наследники InputStream и OutputStream – работают с байтовыми данными. Если
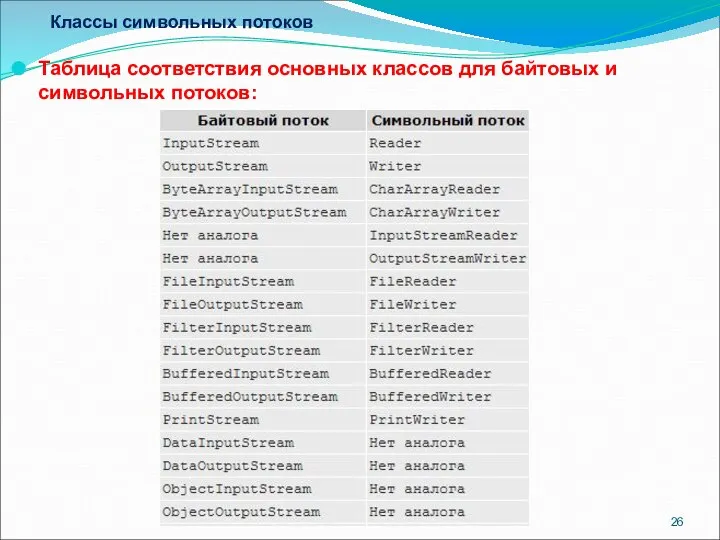
- 26. Классы символьных потоков Таблица соответствия основных классов для байтовых и символьных потоков:
- 27. Классы символьных потоков В таблице на слайде приведены соответствия классов для байтовых и символьных потоков. Как
- 28. Классы символьных потоков Пример 5:
- 29. Классы символьных потоков Пример 5:
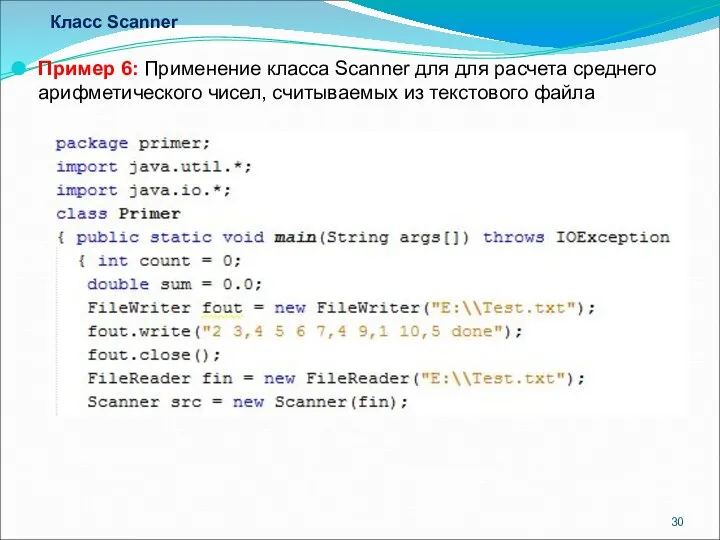
- 30. Класс Scanner Пример 6: Применение класса Scanner для для расчета среднего арифметического чисел, считываемых из текстового
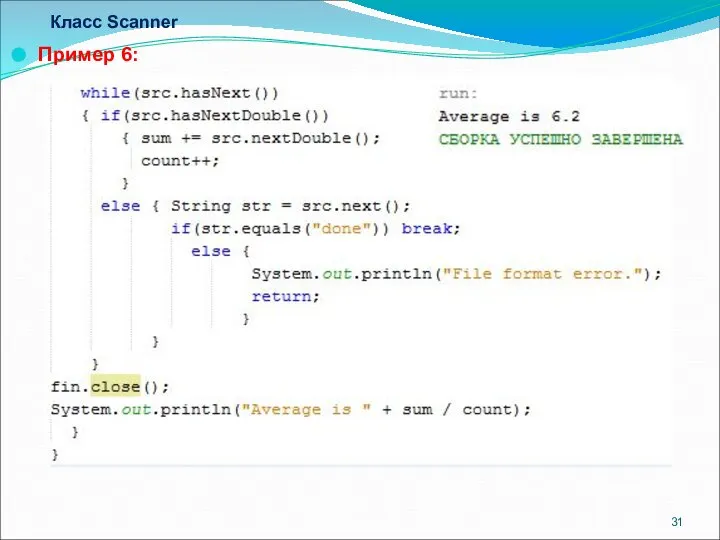
- 31. Класс Scanner Пример 6:
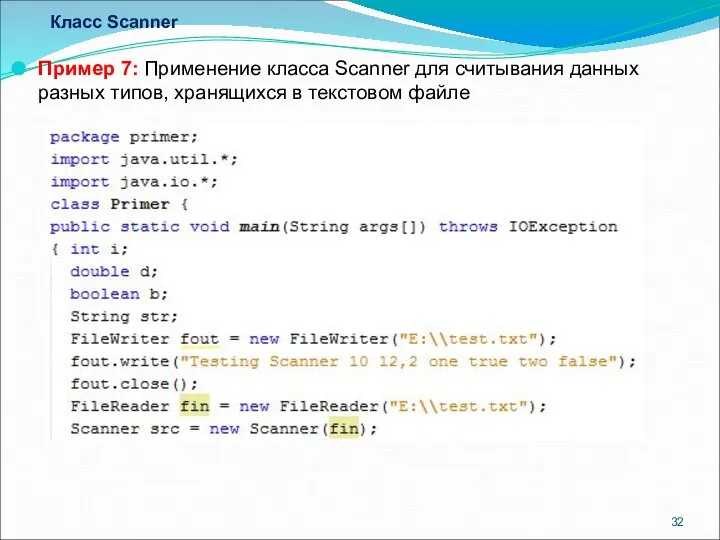
- 32. Класс Scanner Пример 7: Применение класса Scanner для считывания данных разных типов, хранящихся в текстовом файле
- 33. Класс Scanner Пример 7:
- 34. Класс RandomAccessFile Пример 8:
- 36. Скачать презентацию
Классы байтовых потоков
Фрагмент иерархии классов байтовых потоков
Классы байтовых потоков
Фрагмент иерархии классов байтовых потоков

Классы байтовых потоков
В Java так же как и в С++
Классы байтовых потоков
В Java так же как и в С++
![Классы InputStream и OutputStream Методы класса InputStream: int read() int read(byte[]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1290931/slide-3.jpg)
Классы InputStream и OutputStream
Методы класса InputStream:
int read()
int read(byte[] buf)
int read(byte[]
Классы InputStream и OutputStream
Методы класса InputStream:
int read()
int read(byte[] buf)
int read(byte[]

Классы InputStream и OutputStream
InputStream – это базовый класс для байтовых потоков ввода. Методы
Классы InputStream и OutputStream
InputStream – это базовый класс для байтовых потоков ввода. Методы

Классы InputStream и OutputStream
Класс OutputStream – это базовый класс для байтовых потоков вывода.
В классе OutputStream аналогичным
Классы InputStream и OutputStream
Класс OutputStream – это базовый класс для байтовых потоков вывода.
В классе OutputStream аналогичным
Классы FileInputStream и FileOutputStream
Пример 1:
Классы FileInputStream и FileOutputStream
Пример 1:
Классы FileInputStream и FileOutputStream
Пример 1:
Классы FileInputStream и FileOutputStream
Пример 1:

Классы FileInputStream и FileOutputStream
Пример 1:
Классы FileInputStream и FileOutputStream
Пример 1:

Классы FileInputStream и FileOutputStream
Класс FileInputStream используется для чтения данных из файла. Конструктор
Классы FileInputStream и FileOutputStream
Класс FileInputStream используется для чтения данных из файла. Конструктор
Классы BufferedInputStream и BufferedOutputStream
Пример 2:
Классы BufferedInputStream и BufferedOutputStream
Пример 2:
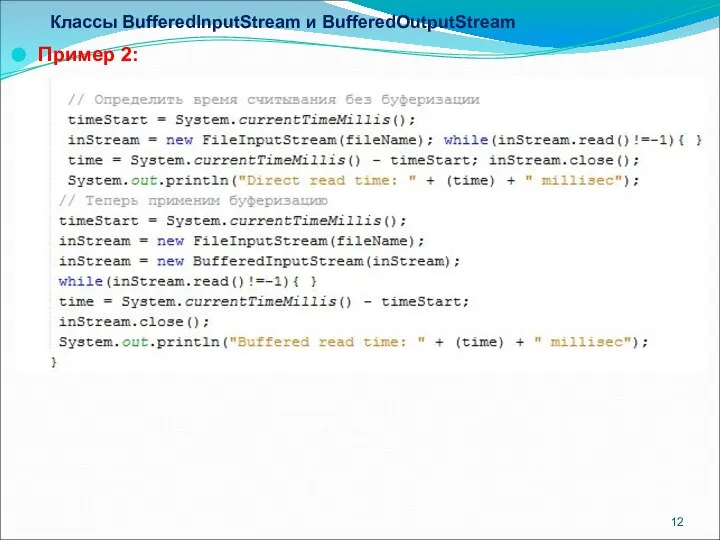
Классы BufferedInputStream и BufferedOutputStream
Пример 2:
Классы BufferedInputStream и BufferedOutputStream
Пример 2:
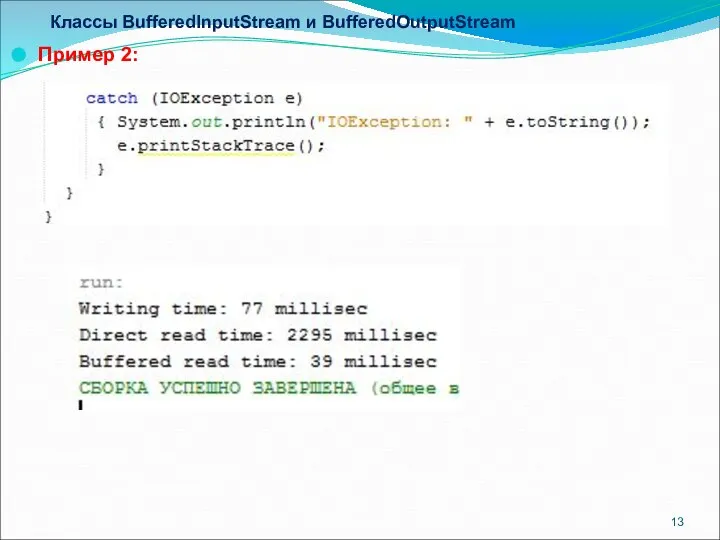
Классы BufferedInputStream и BufferedOutputStream
Пример 2:
Классы BufferedInputStream и BufferedOutputStream
Пример 2:

Классы BufferedInputStream и BufferedOutputStream
На практике при считывании с внешних устройств
Классы BufferedInputStream и BufferedOutputStream
На практике при считывании с внешних устройств
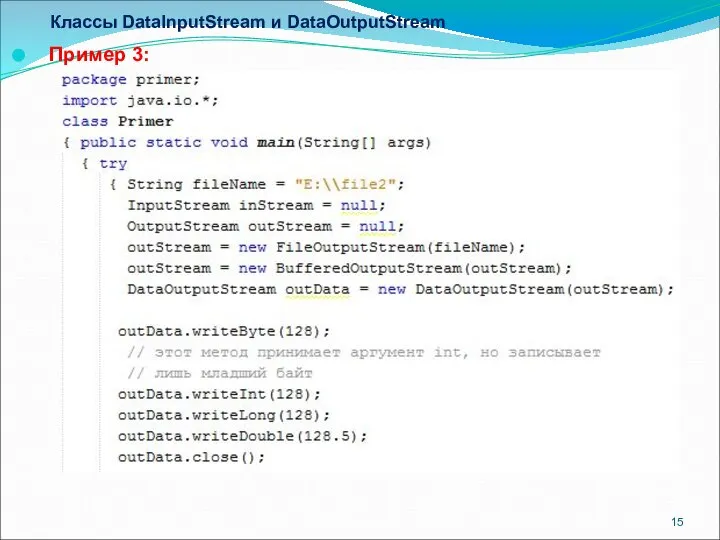
Классы DataInputStream и DataOutputStream
Пример 3:
Классы DataInputStream и DataOutputStream
Пример 3:
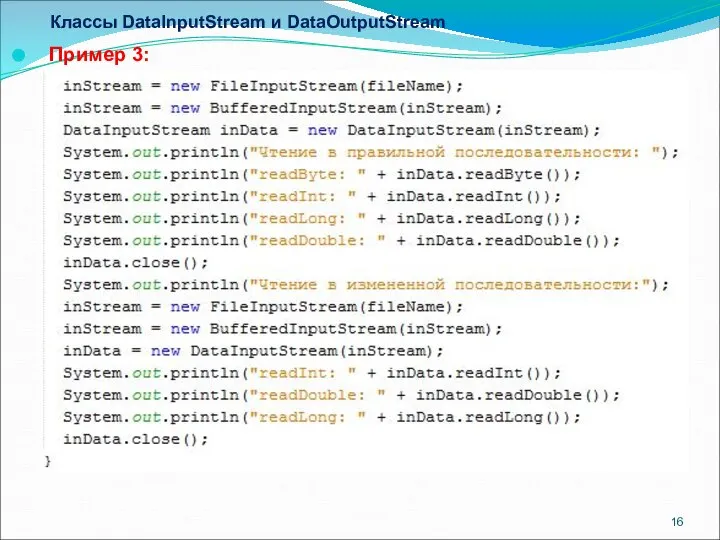
Классы DataInputStream и DataOutputStream
Пример 3:
Классы DataInputStream и DataOutputStream
Пример 3:
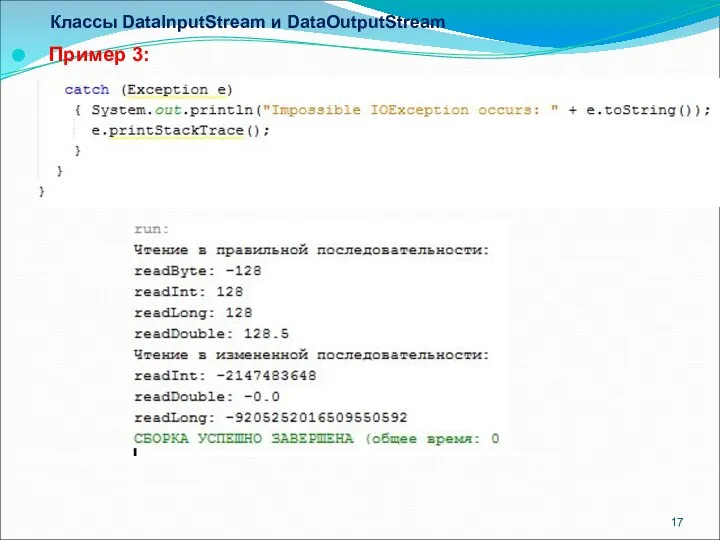
Классы DataInputStream и DataOutputStream
Пример 3:
Классы DataInputStream и DataOutputStream
Пример 3:

Классы DataInputStream и DataOutputStream
До сих пор речь шла только
Классы DataInputStream и DataOutputStream
До сих пор речь шла только
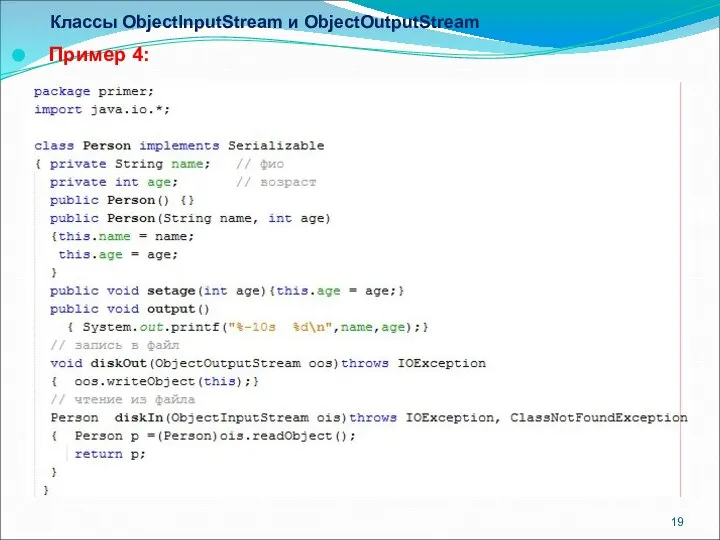
Классы ObjectInputStream и ObjectOutputStream
Пример 4:
Классы ObjectInputStream и ObjectOutputStream
Пример 4:
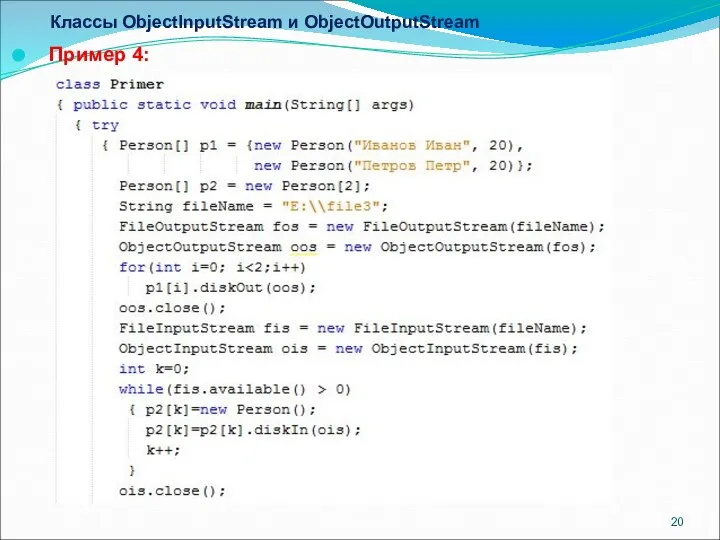
Классы ObjectInputStream и ObjectOutputStream
Пример 4:
Классы ObjectInputStream и ObjectOutputStream
Пример 4:

Классы ObjectInputStream и ObjectOutputStream
Пример 4:
Классы ObjectInputStream и ObjectOutputStream
Пример 4:

Классы ObjectInputStream и ObjectOutputStream
Для объектов процесс преобразования в последовательность
Классы ObjectInputStream и ObjectOutputStream
Для объектов процесс преобразования в последовательность

Классы ObjectInputStream и ObjectOutputStream
Предположим, объект некоторого класса TestClass был сериализован и
Классы ObjectInputStream и ObjectOutputStream
Предположим, объект некоторого класса TestClass был сериализован и
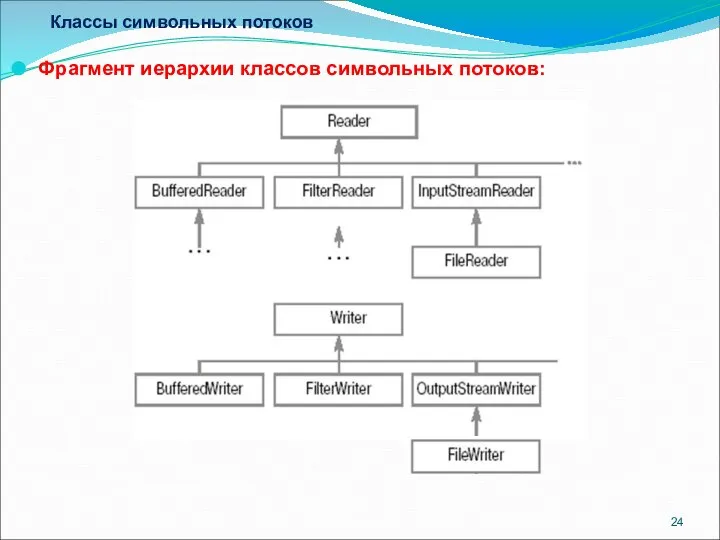
Классы символьных потоков
Фрагмент иерархии классов символьных потоков:
Классы символьных потоков
Фрагмент иерархии классов символьных потоков:

Классы символьных потоков
Рассмотренные классы – наследники InputStream и OutputStream – работают с байтовыми
Классы символьных потоков
Рассмотренные классы – наследники InputStream и OutputStream – работают с байтовыми
Классы символьных потоков
Таблица соответствия основных классов для байтовых и
Классы символьных потоков
Таблица соответствия основных классов для байтовых и

Классы символьных потоков
В таблице на слайде приведены соответствия классов для байтовых
Классы символьных потоков
В таблице на слайде приведены соответствия классов для байтовых

Классы символьных потоков
Пример 5:
Классы символьных потоков
Пример 5:

Классы символьных потоков
Пример 5:
Классы символьных потоков
Пример 5:
Класс Scanner
Пример 6: Применение класса Scanner для для расчета
Класс Scanner
Пример 6: Применение класса Scanner для для расчета
Класс Scanner
Пример 6:
Класс Scanner
Пример 6:
Класс Scanner
Пример 7: Применение класса Scanner для считывания данных
Класс Scanner
Пример 7: Применение класса Scanner для считывания данных

Класс Scanner
Пример 7:
Класс Scanner
Пример 7:
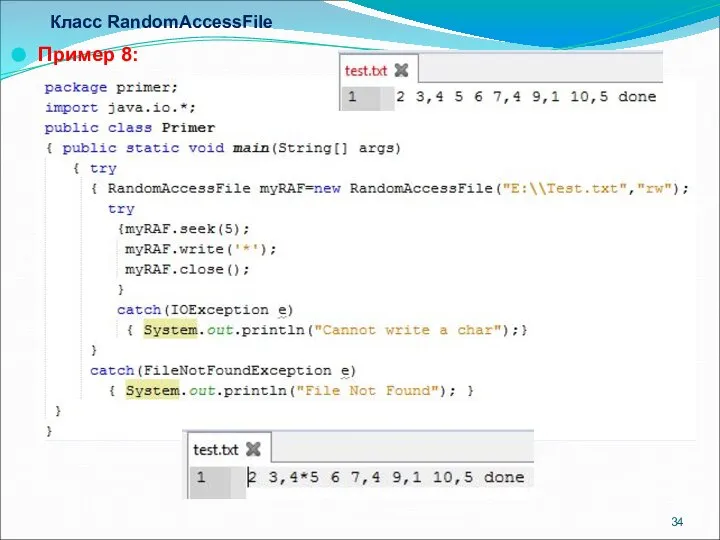
Класс RandomAccessFile
Пример 8:
Класс RandomAccessFile
Пример 8:
 Лабораторные, инструментальные и функциональные методы исследования системы органов дыхания
Лабораторные, инструментальные и функциональные методы исследования системы органов дыхания Назначение, общее устройство системы питания карбюраторного двигателя
Назначение, общее устройство системы питания карбюраторного двигателя Беркут: Биология, место обитания и меры охраны вида в Челябинской области Автор: Гафарова Ларина Рашитовна ученица 3б класса МОУ С
Беркут: Биология, место обитания и меры охраны вида в Челябинской области Автор: Гафарова Ларина Рашитовна ученица 3б класса МОУ С ООП на Delphi - 7: Программируем свою игрушку
ООП на Delphi - 7: Программируем свою игрушку Художественное проектирование серии изделий декоративно-прикладного и народного искусства «Секреты красоты»
Художественное проектирование серии изделий декоративно-прикладного и народного искусства «Секреты красоты» Абсолютно твердое тело. Сила. Задачи статики
Абсолютно твердое тело. Сила. Задачи статики Олимпийские игры в Древней Греции
Олимпийские игры в Древней Греции Полиомиелит
Полиомиелит Чистый денежный поток проекта
Чистый денежный поток проекта Концепция развития таможенных органов Российской Федерации Выполнил студент группы Т-111 Бобырь Алексей
Концепция развития таможенных органов Российской Федерации Выполнил студент группы Т-111 Бобырь Алексей Время свадеб. Обручальные кольца
Время свадеб. Обручальные кольца Подшипники скольжения
Подшипники скольжения Контрактная система при закупках товаров, работ, услуг для обеспечения государственных нужд. Экспертиза. Приемка
Контрактная система при закупках товаров, работ, услуг для обеспечения государственных нужд. Экспертиза. Приемка Роль религии в жизни общества
Роль религии в жизни общества Ta’lim sifatini yangilash va professional kadrlarni tayyorlash, qayta tayyorlash va malakasini oshirish
Ta’lim sifatini yangilash va professional kadrlarni tayyorlash, qayta tayyorlash va malakasini oshirish Пикорнавирусы
Пикорнавирусы  ВВС - Тема 2 - к лекции 24.09.2019
ВВС - Тема 2 - к лекции 24.09.2019 Мехатронные модули
Мехатронные модули Обобщающий урок по теме: «Арифметическая и геометрическая прогрессии.» 9 класс
Обобщающий урок по теме: «Арифметическая и геометрическая прогрессии.» 9 класс  Business object model Диаграммы классов
Business object model Диаграммы классов  Реализация основных алгоритмов. Практическое занятие 1
Реализация основных алгоритмов. Практическое занятие 1 Хлеб
Хлеб Презентация на тему "Здоровьесбережение и образовательный процесс" - скачать презентации по Педагогике
Презентация на тему "Здоровьесбережение и образовательный процесс" - скачать презентации по Педагогике Національна культура та етапи її формування
Національна культура та етапи її формування Основы IPадресации
Основы IPадресации Мужские аксессуары XIX столетия
Мужские аксессуары XIX столетия Разработки НИЦ "АТМОГРАФ" ретроспективных динамических моделей атмосферы для авиационной и космической практики
Разработки НИЦ "АТМОГРАФ" ретроспективных динамических моделей атмосферы для авиационной и космической практики Введение в программирование на языке Python. Цикл while
Введение в программирование на языке Python. Цикл while