- Разработка многопотоковых программ

Содержание
- 2. План Многопотоковые библиотеки Стандарт POSIX Создание потоков Синхронизация Стандарт OpenMP
- 3. Литература Учебное пособие по многопоточному программированию http://www.yolinux.com/TUTORIALS/LinuxTutorialPosixThreads.html Учебное пособие по OpenMP http://www.llnl.gov/computing/tutorials/openMP/
- 4. Многопотоковость Поток – последовательность команд, которые выполняются параллельно с другими потоками в одном адресном пространстве Все
- 5. Поддержка многопотоковости Существует несколько стандартов SUN threads – первая библиотека многопоточной работы Windows thread - M$
- 6. Стандарт POSIX Функции Создания потоков Завершения потоков Синхронизации между потоками Данные потоков
- 7. Создание потоков int pthread_create( pthread_t * thread, //идентификатор потока pthread_attr_t * attr, // атрибуты потока void
- 8. Завершение потоков Выход из функции потока Принудительное завершение из другого потока Не рекомендуется из-за сложности обработки
- 9. Пример #include #include void* thread_function(void* arg){ int num = (int) arg; int i; for (i=0; i
- 10. Пример выполнения [saa@cluster threads]$ gcc -pthread create.c [saa@cluster threads]$ ./a.out I am thread number 2 I
- 11. Функции потоков Функции должны правильно работать с общими ресурсами Должны корректно выполняться параллельно одна другой Быть
- 12. Пример нереентерабельной функции char* mem ; // общая переменная void* thread_function(void* arg){ int num = (int)
- 13. Реентерабельные версии библиотечных функций Функция форматирования даты в виде текстовой строки char *ctime(const time_t *timep); Использует
- 14. Пример использования #include #include #include #include void* thread_function(void* arg){ time_t t = time(0); char buf[30]; printf("time
- 15. Синхронизация Защита данных Обращение к общим переменным Гарантия, что при асинхронном завершении общие данные будут в
- 16. Защита данных Мьютексы Взаимоисключающие блокировки Типы Быстрый – обычный тип блокировки Рекурсивный – поддерживается счетчик захватов
- 17. Создание мьютексов Статическое создание pthread_mutex_t fastmutex = PTHREAD_MUTEX_INITIALIZER; pthread_mutex_t recmutex = PTHREAD_RECURSIVE_MUTEX_INITIALIZER_NP; pthread_mutex_t errchkmutex = PTHREAD_ERRORCHECK_MUTEX_INITIALIZER_NP;
- 18. Блокировка - освобождение Блокировка int pthread_mutex_lock(pthread_mutex_t *mutex); Освобождение int pthread_mutex_unlock(pthread_mutex_t *mutex); Проверка int pthread_mutex_trylock(pthread_mutex_t *mutex); Аналогично
- 19. Пример программы без блокировки #include #include #include #include long counter = 0; // счетчик void* thread_function(void*
- 20. Выполнение программы без блокировок [saa@cluster threads]$ gcc -pthread mutex.c [saa@cluster threads]$ ./a.out thread # 1, counter=1320529
- 21. Пример той же программы с блокировками #include #include #include #include long counter = 0; pthread_mutex_t mutex
- 22. Семафоры Семафор – целочисленный атомарный счетчик с блокировкой Поддерживаются семафоры POSIX Отличия от семафоров UNIX Другие
- 23. Условные переменные Ожидание наступления некоторого условия Поток проверки Проверка условия Захват блокировки Установка на ожидание Повторить
- 24. Инициализация и удаление Статическая pthread_cond_t cond = PTHREAD_COND_INITIALIZER; Динамическая int pthread_cond_init(pthread_cond_t *cond, pthread_condattr_t *cond_attr); Удаление (только
- 25. Условия Условие – некоторая переменная стала иметь некоторое значение Установлен флаг Счетчик стал достаточно большим Данные,
- 26. Проверка условия Захватить мьютекс связанный с условием Проверить условие, если не выполнено Вызвать функцию проверки int
- 27. Сигнал о выполнении условия Вызвать функцию для указанной условной переменной int pthread_cond_broadcast(pthread_cond_t *cond); Функция переводит в
- 28. Пример #include #include #include #include long counter = 0; int thr_count = 0; pthread_mutex_t mutex =
- 29. Синхронизация действий Ожидание окончания потока int pthread_join(pthread_t th, void **thread_return); Вызывающий поток ждет завершения потока th
- 30. Пример join #include #include #include #include long counter = 0; pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; void* thread_function(void*
- 31. Пример выполнения [saa@cluster threads]$ gcc -pthread join.c -g [saa@cluster threads]$ ./a.out thread # 2, counter=974887 thread
- 32. Данные связанные с потоками Все глобальные переменные общие для всех потоков Можно создать ключ – переменную,
- 33. Стандарт OpenMP Разработка параллельных программ с использованием многопотоковости требует стандартных действий и стандартных правил Некоторые структуры
- 34. Как распараллеливается Программа разбивается на параллельные участки, которые выполняются последовательно Fork-Join модель Каждый параллельный участок выполняется
- 35. Изменение программного кода Изменение кода выполняется путем указания компилятору какие участки и как распараллеливать Указания вводятся
- 36. Как вводятся директивы Фортран !$OMP PARALLEL [clause ...] IF (scalar_logical_expression) PRIVATE (list) SHARED (list) DEFAULT (PRIVATE
- 37. Типы директив Какие участки распараллеливать #pragma omp parallel Какие участки выполнять в разных потоках #pragma omp
- 38. Распараллеливание циклов for #pragma omp parallel for #include #include using namespace std; int main (void){ #pragma
- 39. Пример выполнения [saa@cluster omp]$ icc -openmp for.cpp for.cpp(7) : (col. 1) remark: OpenMP DEFINED LOOP WAS
- 40. Участи параллельного выполнения #pragma omp parallel sections #pragma omp section Каждая секция будет выполняться в своем
- 41. Пример выполнения [saa@cluster omp]$ icc -openmp section.cpp [saa@cluster omp]$ OMP_NUM_THREADS=4 ./a.out 05 1 2 3 4
- 42. Типы планирования Применяется совместно с for Shedule(тип, порция) Порция – количество итераций Типы Static – работа
- 43. Синхронизация Указывается для блока команд Critical – указание критического раздела Master – выполняется только master потоком
- 44. Пример critical #include #include using namespace std; int main (void){ #pragma omp parallel for for (int
- 45. Пример выполнения критического раздела Без critical [saa@cluster omp]$ OMP_NUM_THREADS=10 ./a.out 0756893241 С указанием critical [saa@cluster omp]$
- 46. Видимость данный Используется совместно с for, section или после определения данных SHARED (данные) – данные совместного
- 47. Пример частных и общих данных #include int alpha[10], beta[10], i; #pragma omp threadprivate(alpha) main () {
- 48. Пример выполнения [saa@cluster omp]$ icc -openmp ./threadprivate.c ./threadprivate.c(9) : (col. 1) remark: OpenMP DEFINED REGION WAS
- 49. Операции редукции Reduce(оператор:данные) Используется для указания параллельных блоков в котором выполняется операция редукции Опепраторы могут быть
- 50. Пример редукции #include #include using namespace std; int k=0,l=0; int main (void){ #pragma omp parallel for
- 51. Результат выполнения [saa@cluster omp]$ icc -openmp ./reduce.cpp ./reduce.cpp(7) : (col. 1) remark: OpenMP DEFINED LOOP WAS
- 53. Скачать презентацию

План
Многопотоковые библиотеки
Стандарт POSIX
Создание потоков
Синхронизация
Стандарт OpenMP
План
Многопотоковые библиотеки
Стандарт POSIX
Создание потоков
Синхронизация
Стандарт OpenMP

Литература
Учебное пособие по многопоточному программированию
http://www.yolinux.com/TUTORIALS/LinuxTutorialPosixThreads.html
Учебное пособие по OpenMP
http://www.llnl.gov/computing/tutorials/openMP/
Литература
Учебное пособие по многопоточному программированию
http://www.yolinux.com/TUTORIALS/LinuxTutorialPosixThreads.html
Учебное пособие по OpenMP
http://www.llnl.gov/computing/tutorials/openMP/

Многопотоковость
Поток – последовательность команд, которые выполняются параллельно с другими потоками в
Многопотоковость
Поток – последовательность команд, которые выполняются параллельно с другими потоками в

Поддержка многопотоковости
Существует несколько стандартов
SUN threads – первая библиотека многопоточной работы
Windows thread
Поддержка многопотоковости
Существует несколько стандартов
SUN threads – первая библиотека многопоточной работы
Windows thread

Стандарт POSIX
Функции
Создания потоков
Завершения потоков
Синхронизации между потоками
Данные потоков
Стандарт POSIX
Функции
Создания потоков
Завершения потоков
Синхронизации между потоками
Данные потоков

Создание потоков
int pthread_create(
pthread_t * thread, //идентификатор потока
pthread_attr_t * attr, // атрибуты
Создание потоков
int pthread_create( pthread_t * thread, //идентификатор потока pthread_attr_t * attr, // атрибуты

Завершение потоков
Выход из функции потока
Принудительное завершение из другого потока
Не рекомендуется из-за
Завершение потоков
Выход из функции потока
Принудительное завершение из другого потока
Не рекомендуется из-за

Пример
#include
#include
void* thread_function(void* arg){
int num = (int) arg;
int
Пример
#include
#include
void* thread_function(void* arg){
int num = (int) arg;
int
![Пример выполнения [saa@cluster threads]$ gcc -pthread create.c [saa@cluster threads]$ ./a.out I](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1302597/slide-9.jpg)
Пример выполнения
[saa@cluster threads]$ gcc -pthread create.c
[saa@cluster threads]$ ./a.out
I am thread number
Пример выполнения
[saa@cluster threads]$ gcc -pthread create.c
[saa@cluster threads]$ ./a.out
I am thread number

Функции потоков
Функции должны правильно работать с общими ресурсами
Должны корректно выполняться параллельно
Функции потоков
Функции должны правильно работать с общими ресурсами
Должны корректно выполняться параллельно

Пример нереентерабельной функции
char* mem ; // общая переменная
void* thread_function(void* arg){
int
Пример нереентерабельной функции
char* mem ; // общая переменная
void* thread_function(void* arg){
int

Реентерабельные версии библиотечных функций
Функция форматирования даты в виде текстовой строки
char *ctime(const
Реентерабельные версии библиотечных функций
Функция форматирования даты в виде текстовой строки
char *ctime(const

Пример использования
#include
#include
#include
#include
void* thread_function(void* arg){
time_t t =
Пример использования
#include
#include
#include
#include
void* thread_function(void* arg){
time_t t =

Синхронизация
Защита данных
Обращение к общим переменным
Гарантия, что при асинхронном завершении общие данные
Синхронизация
Защита данных
Обращение к общим переменным
Гарантия, что при асинхронном завершении общие данные

Защита данных
Мьютексы
Взаимоисключающие блокировки
Типы
Быстрый – обычный тип блокировки
Рекурсивный – поддерживается счетчик захватов
С
Защита данных
Мьютексы
Взаимоисключающие блокировки
Типы
Быстрый – обычный тип блокировки
Рекурсивный – поддерживается счетчик захватов
С

Создание мьютексов
Статическое создание
pthread_mutex_t fastmutex = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t recmutex = PTHREAD_RECURSIVE_MUTEX_INITIALIZER_NP;
pthread_mutex_t errchkmutex
Создание мьютексов
Статическое создание
pthread_mutex_t fastmutex = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t recmutex = PTHREAD_RECURSIVE_MUTEX_INITIALIZER_NP;
pthread_mutex_t errchkmutex

Блокировка - освобождение
Блокировка
int pthread_mutex_lock(pthread_mutex_t *mutex);
Освобождение
int pthread_mutex_unlock(pthread_mutex_t *mutex);
Проверка
int pthread_mutex_trylock(pthread_mutex_t *mutex);
Аналогично
Блокировка - освобождение
Блокировка
int pthread_mutex_lock(pthread_mutex_t *mutex);
Освобождение
int pthread_mutex_unlock(pthread_mutex_t *mutex);
Проверка
int pthread_mutex_trylock(pthread_mutex_t *mutex);
Аналогично

Пример программы без блокировки
#include
#include
#include
#include
long counter = 0;
Пример программы без блокировки
#include
#include
#include
#include
long counter = 0;
![Выполнение программы без блокировок [saa@cluster threads]$ gcc -pthread mutex.c [saa@cluster threads]$](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1302597/slide-19.jpg)
Выполнение программы без блокировок
[saa@cluster threads]$ gcc -pthread mutex.c
[saa@cluster threads]$ ./a.out
thread #
Выполнение программы без блокировок
[saa@cluster threads]$ gcc -pthread mutex.c
[saa@cluster threads]$ ./a.out
thread #

Пример той же программы с блокировками
#include
#include
#include
#include
long counter
Пример той же программы с блокировками
#include
#include
#include
#include
long counter

Семафоры
Семафор – целочисленный атомарный счетчик с блокировкой
Поддерживаются семафоры POSIX
Отличия от семафоров
Семафоры
Семафор – целочисленный атомарный счетчик с блокировкой
Поддерживаются семафоры POSIX
Отличия от семафоров

Условные переменные
Ожидание наступления некоторого условия
Поток проверки
Проверка условия
Захват блокировки
Установка на ожидание
Повторить
Поток, который
Условные переменные
Ожидание наступления некоторого условия
Поток проверки
Проверка условия
Захват блокировки
Установка на ожидание
Повторить
Поток, который

Инициализация и удаление
Статическая
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
Динамическая
int pthread_cond_init(pthread_cond_t *cond, pthread_condattr_t *cond_attr);
Удаление (только
Инициализация и удаление
Статическая
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
Динамическая
int pthread_cond_init(pthread_cond_t *cond, pthread_condattr_t *cond_attr);
Удаление (только

Условия
Условие – некоторая переменная стала иметь некоторое значение
Установлен флаг
Счетчик стал достаточно
Условия
Условие – некоторая переменная стала иметь некоторое значение
Установлен флаг
Счетчик стал достаточно

Проверка условия
Захватить мьютекс связанный с условием
Проверить условие, если не выполнено
Вызвать функцию
Проверка условия
Захватить мьютекс связанный с условием
Проверить условие, если не выполнено
Вызвать функцию

Сигнал о выполнении условия
Вызвать функцию для указанной условной переменной
int pthread_cond_broadcast(pthread_cond_t *cond);
Функция
Сигнал о выполнении условия
Вызвать функцию для указанной условной переменной
int pthread_cond_broadcast(pthread_cond_t *cond);
Функция

Пример
#include
#include
#include
#include
long counter = 0;
int thr_count = 0;
pthread_mutex_t
Пример
#include
#include
#include
#include
long counter = 0;
int thr_count = 0;
pthread_mutex_t

Синхронизация действий
Ожидание окончания потока
int pthread_join(pthread_t th, void **thread_return);
Вызывающий поток ждет
Синхронизация действий
Ожидание окончания потока
int pthread_join(pthread_t th, void **thread_return);
Вызывающий поток ждет

Пример join
#include
#include
#include
#include
long counter = 0;
pthread_mutex_t mutex =
Пример join
#include
#include
#include
#include
long counter = 0;
pthread_mutex_t mutex =
![Пример выполнения [saa@cluster threads]$ gcc -pthread join.c -g [saa@cluster threads]$ ./a.out](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1302597/slide-30.jpg)
Пример выполнения
[saa@cluster threads]$ gcc -pthread join.c -g
[saa@cluster threads]$ ./a.out
thread # 2,
Пример выполнения
[saa@cluster threads]$ gcc -pthread join.c -g
[saa@cluster threads]$ ./a.out
thread # 2,

Данные связанные с потоками
Все глобальные переменные общие для всех потоков
Можно создать
Данные связанные с потоками
Все глобальные переменные общие для всех потоков
Можно создать

Стандарт OpenMP
Разработка параллельных программ с использованием многопотоковости требует стандартных действий и
Стандарт OpenMP
Разработка параллельных программ с использованием многопотоковости требует стандартных действий и
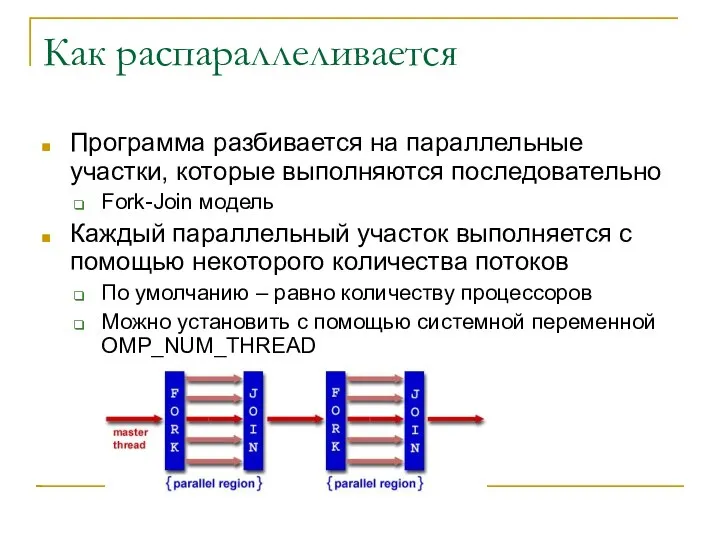
Как распараллеливается
Программа разбивается на параллельные участки, которые выполняются последовательно
Fork-Join модель
Каждый параллельный
Как распараллеливается
Программа разбивается на параллельные участки, которые выполняются последовательно
Fork-Join модель
Каждый параллельный

Изменение программного кода
Изменение кода выполняется путем указания компилятору какие участки и
Изменение программного кода
Изменение кода выполняется путем указания компилятору какие участки и
![Как вводятся директивы Фортран !$OMP PARALLEL [clause ...] IF (scalar_logical_expression) PRIVATE](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1302597/slide-35.jpg)
Как вводятся директивы
Фортран
!$OMP PARALLEL [clause ...]
IF (scalar_logical_expression)
PRIVATE (list)
SHARED
Как вводятся директивы
Фортран
!$OMP PARALLEL [clause ...]
IF (scalar_logical_expression)
PRIVATE (list)
SHARED

Типы директив
Какие участки распараллеливать
#pragma omp parallel
Какие участки выполнять в разных потоках
#pragma
Типы директив
Какие участки распараллеливать
#pragma omp parallel
Какие участки выполнять в разных потоках
#pragma

Распараллеливание циклов for
#pragma omp parallel for
#include
#include
using namespace std;
int main
Распараллеливание циклов for
#pragma omp parallel for
#include
#include
using namespace std;
int main
![Пример выполнения [saa@cluster omp]$ icc -openmp for.cpp for.cpp(7) : (col. 1)](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1302597/slide-38.jpg)
Пример выполнения
[saa@cluster omp]$ icc -openmp for.cpp
for.cpp(7) : (col. 1) remark: OpenMP
Пример выполнения
[saa@cluster omp]$ icc -openmp for.cpp
for.cpp(7) : (col. 1) remark: OpenMP

Участи параллельного выполнения
#pragma omp parallel sections
#pragma omp section
Каждая секция
Участи параллельного выполнения
#pragma omp parallel sections
#pragma omp section
Каждая секция
![Пример выполнения [saa@cluster omp]$ icc -openmp section.cpp [saa@cluster omp]$ OMP_NUM_THREADS=4 ./a.out](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1302597/slide-40.jpg)
Пример выполнения
[saa@cluster omp]$ icc -openmp section.cpp
[saa@cluster omp]$ OMP_NUM_THREADS=4 ./a.out
05
1
2
3
4
6
7
8
9
Пример выполнения
[saa@cluster omp]$ icc -openmp section.cpp
[saa@cluster omp]$ OMP_NUM_THREADS=4 ./a.out
05
1
2
3
4
6
7
8
9

Типы планирования
Применяется совместно с for
Shedule(тип, порция)
Порция – количество итераций
Типы
Static –
Типы планирования
Применяется совместно с for
Shedule(тип, порция)
Порция – количество итераций
Типы
Static –

Синхронизация
Указывается для блока команд
Critical – указание критического раздела
Master – выполняется только
Синхронизация
Указывается для блока команд
Critical – указание критического раздела
Master – выполняется только

Пример critical
#include
#include
using namespace std;
int main (void){
#pragma omp parallel for
Пример critical
#include
#include
using namespace std;
int main (void){
#pragma omp parallel for
![Пример выполнения критического раздела Без critical [saa@cluster omp]$ OMP_NUM_THREADS=10 ./a.out 0756893241](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1302597/slide-44.jpg)
Пример выполнения критического раздела
Без critical
[saa@cluster omp]$ OMP_NUM_THREADS=10 ./a.out
0756893241
С указанием critical
[saa@cluster omp]$
Пример выполнения критического раздела
Без critical
[saa@cluster omp]$ OMP_NUM_THREADS=10 ./a.out
0756893241
С указанием critical
[saa@cluster omp]$

Видимость данный
Используется совместно с for, section или после определения данных
SHARED (данные)
Видимость данный
Используется совместно с for, section или после определения данных
SHARED (данные)
![Пример частных и общих данных #include int alpha[10], beta[10], i; #pragma](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1302597/slide-46.jpg)
Пример частных и общих данных
#include
int alpha[10], beta[10], i;
#pragma omp threadprivate(alpha)
main
Пример частных и общих данных
#include
int alpha[10], beta[10], i;
#pragma omp threadprivate(alpha)
main
![Пример выполнения [saa@cluster omp]$ icc -openmp ./threadprivate.c ./threadprivate.c(9) : (col. 1)](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1302597/slide-47.jpg)
Пример выполнения
[saa@cluster omp]$ icc -openmp ./threadprivate.c
./threadprivate.c(9) : (col. 1) remark: OpenMP
Пример выполнения
[saa@cluster omp]$ icc -openmp ./threadprivate.c
./threadprivate.c(9) : (col. 1) remark: OpenMP

Операции редукции
Reduce(оператор:данные)
Используется для указания параллельных блоков в котором выполняется операция редукции
Опепраторы
Операции редукции
Reduce(оператор:данные)
Используется для указания параллельных блоков в котором выполняется операция редукции
Опепраторы

Пример редукции
#include
#include
using namespace std;
int k=0,l=0;
int main (void){
#pragma omp parallel
Пример редукции
#include
#include
using namespace std;
int k=0,l=0;
int main (void){
#pragma omp parallel
![Результат выполнения [saa@cluster omp]$ icc -openmp ./reduce.cpp ./reduce.cpp(7) : (col. 1)](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1302597/slide-50.jpg)
Результат выполнения
[saa@cluster omp]$ icc -openmp ./reduce.cpp
./reduce.cpp(7) : (col. 1) remark: OpenMP
Результат выполнения
[saa@cluster omp]$ icc -openmp ./reduce.cpp
./reduce.cpp(7) : (col. 1) remark: OpenMP
 Общие сведения о принципе передачи цветного изображения
Общие сведения о принципе передачи цветного изображения Религиозная организация христиан еры евангельской
Религиозная организация христиан еры евангельской Leben in Russland
Leben in Russland Предвыборная агитация. Влияние предвыборной агитации на электорат
Предвыборная агитация. Влияние предвыборной агитации на электорат Методическая разработка Савченко Е.М. МОУ гимназия №1, г. Полярные Зори, Мурманской обл. - презентация
Методическая разработка Савченко Е.М. МОУ гимназия №1, г. Полярные Зори, Мурманской обл. - презентация Пример выполнения презентации
Пример выполнения презентации  Компоненты духовной сферы жизни общества
Компоненты духовной сферы жизни общества Ўзбекистон таълим, фан ва маданият. Ходимлари касаба уюшмаси учтепа туман кенгашига. Хуш келибсиз
Ўзбекистон таълим, фан ва маданият. Ходимлари касаба уюшмаси учтепа туман кенгашига. Хуш келибсиз Экспериментальное исследование МДП-структур
Экспериментальное исследование МДП-структур Линии влияния силовых факторов в статически неопределимых системах. (Часть 2)
Линии влияния силовых факторов в статически неопределимых системах. (Часть 2) Файли. Строки. Обробка виключень
Файли. Строки. Обробка виключень Механические свойства древесины
Механические свойства древесины Логические основы компьютера
Логические основы компьютера «Слова-паразиты, или экология речи» Исполнитель Пинчугина Алена Руководитель Карпенко Е.В., учитель русского языка
«Слова-паразиты, или экология речи» Исполнитель Пинчугина Алена Руководитель Карпенко Е.В., учитель русского языка Бесікке салу
Бесікке салу Выполнила: воспитатель I категории Дорошенко Ирина Николаевна г.Прокопьевск
Выполнила: воспитатель I категории Дорошенко Ирина Николаевна г.Прокопьевск  Древесина. Строение древесины
Древесина. Строение древесины Сущность и формы познания
Сущность и формы познания Африка
Африка  Курс базовой теоретической подготовки по системе менеджмента качества РС
Курс базовой теоретической подготовки по системе менеджмента качества РС Правила выполнения рабочей документации автоматизации технологических процессов
Правила выполнения рабочей документации автоматизации технологических процессов ПРОЧЬ ОТ НАРКОТИКОВ - презентация для начальной школы
ПРОЧЬ ОТ НАРКОТИКОВ - презентация для начальной школы Основные свойства и применение проводниковых материалов
Основные свойства и применение проводниковых материалов Крестовоздвиженские церкви Череповецкого уезда
Крестовоздвиженские церкви Череповецкого уезда Основы офисного программирования VBA
Основы офисного программирования VBA Радиоприемник А.С. Попова
Радиоприемник А.С. Попова ИММУНОСПЕЦИФИЧЕСКИЕ ГРУППЫ КРОВИ
ИММУНОСПЕЦИФИЧЕСКИЕ ГРУППЫ КРОВИ Основные этапы определения кадастровой стоимости земель водного фонда
Основные этапы определения кадастровой стоимости земель водного фонда