- Теория формальных языков и грамматик. (Глава 2)

Содержание
- 2. 2.1 ЯЗЫКИ И ЦЕПОЧКИ СИМВОЛОВ. СПОСОБЫ ЗАДАНИЯ ЯЗЫКОВ ГЛАВА 2. Основы теории формальных языков и грамматик
- 3. 2.1.1 Цепочки символов. Операции над ними Цепочкой (строкой) называется последовательность символов записанных один за одним. α
- 4. 2.1.1 Цепочки символов. Операции над ними Если из цепочки единичной длины |α|=1 удаляется этот единственный символ,
- 5. 2.1.1 Цепочки символов. Операции над ними Если α и β - цепочки, то цепочка αβ называется
- 6. 2.1.2 Формальное определение языка. Понятие языка Язык – это заданный набор символов и правил, устанавливающих способы
- 7. 2.1.2 Формальное определение языка. Понятие языка V* множество, содержащее все цепочки в алфавите V, включая пустую
- 8. 2.1.2 Формальное определение языка. Понятие языка Языком L над алфавитом V называют некоторое счетное подмножество цепочек
- 9. 2.1.2 Формальное определение языка. Понятие языка Язык L над алфавитом V включает в себя язык L’
- 10. 2.1.3 Способы задания языка перечисление всех допустимых цепочек языка с помощью указания способа порождения цепочек языка
- 11. 2.1.4 Синтаксис и семантика Лексема – это языковая конструкция, которая состоит из элементов алфавита языка и
- 12. 2.2 ОПРЕДЕЛЕНИЕ ГРАММАТИКИ ГЛАВА 2. Основы теории формальных языков и грамматик
- 13. 2.2.1 Понятие о грамматике языка Грамматика – описание способов построения предложений некоторого языка. Грамматика — один
- 14. 2.2.1 Понятие о грамматике языка Грамматики G1 и G2 называются эквивалентными, если L(G1) = L(G2). G1
- 15. 2.2.2 Формальное определение грамматики По определению Хомского формальная грамматика представляет собой четвёрку: G={VT, VN, P, S}
- 16. 2.2.2 Формальное определение грамматики Грамматика, определяющая целое число без знака: G={VT,VN,P,S} VN = {A,B} VТ =
- 17. 2.3 СПОСОБЫ ЗАПИСИ СИНТАКСИСА ЯЗЫКА ГЛАВА 2. Основы теории формальных языков и грамматик Метаязык - язык,
- 18. 2.3.1 Метаязык Хомского -> символ отделяет левую часть правила от правой (читается как "порождает" и "это
- 19. 2.3.1 Метаязык Хомского Описание идентификатора на метаязыке Хомского
- 20. 2.3.2 Бэкуса-Наура формы (БНФ) символ "::=" отделяет левую часть правила от правой; нетерминалы обозначаются произвольной символьной
- 21. 2.3.2 Бэкуса-Наура формы (БНФ) 1. ::= A | B| C …| Z| а| b| c| …|
- 22. 2.3.2 Бэкуса-Наура формы (БНФ) ::= ::= | ::= БЛАТНОЙ| КОНКРЕТНЫЙ ::= ПАЦАН| БРАТАН| СИЛА ::= |
- 23. 2.3.3 РБНФ (расширенная) [ ] – синтаксическая конструкция может отсутствовать; { } – повторение синтаксической конструкции
- 24. 2.3.3 РБНФ ::= A | B| C …| Z| а| b| c| …| z ::= 0|
- 25. 2.3.4 Диаграмма Вирта терминальный символ, принадлежащий алфавиту языка постоянная группа терминальных символов, определяющая название лексемы, ключевое
- 26. 2.3.4 Диаграмма Вирта Пример описания идентификатора с использованием диаграмм Вирта
- 27. 2.4 КЛАССИФИКАЦИЯ ЯЗЫКОВ И ГРАММАТИК ГЛАВА 2. Основы теории формальных языков и грамматик
- 28. 2.4.1 Классификация грамматик
- 29. 2.4.1 Классификация грамматик
- 30. 2.4.1 Классификация грамматик Эта иерархия грамматик – включающая. Грамматика 2 включает 3, но не наоборот. Любая
- 31. 2.4.2 Классификация языков Языки классифицируются в соответствие с типами грамматик с помощью которых они заданы. Поскольку
- 32. 2.4.2 Классификация языков Грамматика 0 G1 = ({0,1}, {A,S}, P1, S) и P1: S -> 0A1
- 33. 2.4.2 Классификация языков Сложность языка убывает с возрастанием классификационного типа языка. Тип 0. Язык с фразовой
- 34. 2.4.3 Примеры классификации языков и грамматик Язык типа 2: L(G3) = {(ac)n (cb)n | n >
- 35. 2.4.3 Примеры классификации языков и грамматик
- 36. 2.5 ЦЕПОЧКИ ВЫВОДА. СЕНТЕНЦИАЛЬНАЯ ФОРМА ГЛАВА 2. Основы теории формальных языков и грамматик
- 37. 2.5.1 Вывод. Цепочка вывода. Выводом называется процесс порождения предложений языка на основе правил, определяющих язык. Цепочка
- 38. 2.5.1 Вывод. Цепочка вывода. Цепочка β ∈ V* выводима из цепочки α ∈ V+ в грамматике
- 39. 2.5.1 Вывод. Цепочка вывода. Если цепочка вывода от α к β содержит одну и более промежуточных
- 40. 2.5.1 Вывод. Цепочка вывода. G=({A, S) {0, 1}, Р, S) P: S -> 0А1 0A ->
- 41. 2.5.2 Сентенциальная форма грамматики. Основа Вывод называется законченным, если на основе цепочки β, полученной в результате
- 42. 2.5.2 Сентенциальная форма грамматики. Основа Пусть G=(VN, VT, P, S) грамматика и цепочка w = γ1
- 43. 2.5.3 Левосторонний и правосторонний вывод Вывод цепочки β ∈ (VT)* из S ∈ VN в КС-грамматике
- 44. 2.5.3 Левосторонний и правосторонний вывод Например, для цепочки a+b+a в грамматике G = ({a,b,+}, {S,T}, {S
- 46. Скачать презентацию

2.1 ЯЗЫКИ И ЦЕПОЧКИ СИМВОЛОВ. СПОСОБЫ ЗАДАНИЯ ЯЗЫКОВ
ГЛАВА 2. Основы теории
2.1 ЯЗЫКИ И ЦЕПОЧКИ СИМВОЛОВ. СПОСОБЫ ЗАДАНИЯ ЯЗЫКОВ
ГЛАВА 2. Основы теории

2.1.1 Цепочки символов. Операции над ними
Цепочкой (строкой) называется последовательность символов записанных
2.1.1 Цепочки символов. Операции над ними
Цепочкой (строкой) называется последовательность символов записанных

2.1.1 Цепочки символов. Операции над ними
Если из цепочки единичной длины |α|=1
2.1.1 Цепочки символов. Операции над ними
Если из цепочки единичной длины |α|=1

2.1.1 Цепочки символов. Операции над ними
Если α и β - цепочки,
2.1.1 Цепочки символов. Операции над ними
Если α и β - цепочки,

2.1.2 Формальное определение языка. Понятие языка
Язык – это заданный набор символов
2.1.2 Формальное определение языка. Понятие языка
Язык – это заданный набор символов

2.1.2 Формальное определение языка. Понятие языка
V* множество, содержащее все цепочки в
2.1.2 Формальное определение языка. Понятие языка
V* множество, содержащее все цепочки в

2.1.2 Формальное определение языка. Понятие языка
Языком L над алфавитом V называют
2.1.2 Формальное определение языка. Понятие языка
Языком L над алфавитом V называют

2.1.2 Формальное определение языка. Понятие языка
Язык L над алфавитом V включает
2.1.2 Формальное определение языка. Понятие языка
Язык L над алфавитом V включает

2.1.3 Способы задания языка
перечисление всех допустимых цепочек языка
с помощью указания способа
2.1.3 Способы задания языка
перечисление всех допустимых цепочек языка
с помощью указания способа

2.1.4 Синтаксис и семантика
Лексема – это языковая конструкция, которая состоит из
2.1.4 Синтаксис и семантика
Лексема – это языковая конструкция, которая состоит из

2.2 ОПРЕДЕЛЕНИЕ ГРАММАТИКИ
ГЛАВА 2. Основы теории формальных языков и грамматик
2.2 ОПРЕДЕЛЕНИЕ ГРАММАТИКИ
ГЛАВА 2. Основы теории формальных языков и грамматик

2.2.1 Понятие о грамматике языка
Грамматика – описание способов построения предложений некоторого
2.2.1 Понятие о грамматике языка
Грамматика – описание способов построения предложений некоторого

2.2.1 Понятие о грамматике языка
Грамматики G1 и G2 называются эквивалентными, если
2.2.1 Понятие о грамматике языка
Грамматики G1 и G2 называются эквивалентными, если

2.2.2 Формальное определение грамматики
По определению Хомского формальная грамматика представляет собой четвёрку:
G={VT,
2.2.2 Формальное определение грамматики
По определению Хомского формальная грамматика представляет собой четвёрку:
G={VT,

2.2.2 Формальное определение грамматики
Грамматика, определяющая целое число без знака:
G={VT,VN,P,S}
VN
2.2.2 Формальное определение грамматики
Грамматика, определяющая целое число без знака:
G={VT,VN,P,S}
VN

2.3 СПОСОБЫ ЗАПИСИ СИНТАКСИСА ЯЗЫКА
ГЛАВА 2. Основы теории формальных языков и
2.3 СПОСОБЫ ЗАПИСИ СИНТАКСИСА ЯЗЫКА
ГЛАВА 2. Основы теории формальных языков и

2.3.1 Метаязык Хомского
-> символ отделяет левую часть правила от правой (читается
2.3.1 Метаязык Хомского
-> символ отделяет левую часть правила от правой (читается

2.3.1 Метаязык Хомского
Описание идентификатора на метаязыке Хомского
2.3.1 Метаязык Хомского
Описание идентификатора на метаязыке Хомского

2.3.2 Бэкуса-Наура формы (БНФ)
символ "::=" отделяет левую часть правила от правой;
нетерминалы
2.3.2 Бэкуса-Наура формы (БНФ)
символ "::=" отделяет левую часть правила от правой;
нетерминалы

2.3.2 Бэкуса-Наура формы (БНФ)
1. <буква> ::= A | B| C …|
2.3.2 Бэкуса-Наура формы (БНФ)
1. <буква> ::= A | B| C …|
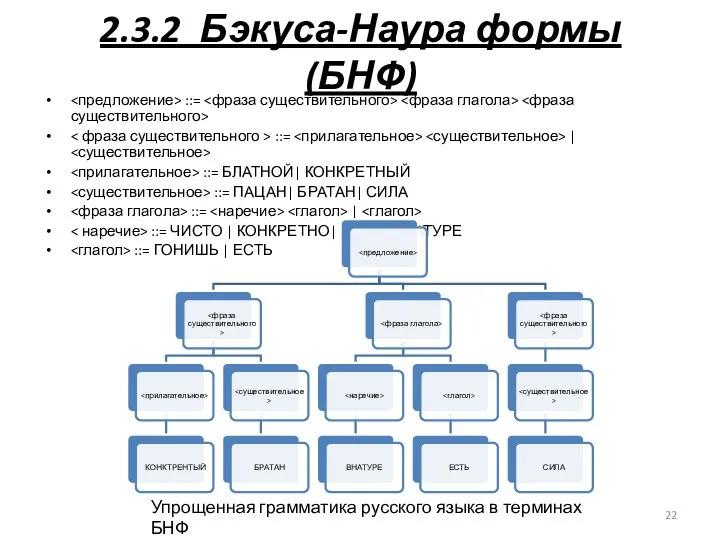
2.3.2 Бэкуса-Наура формы (БНФ)
<предложение> ::= <фраза существительного> <фраза глагола> <фраза существительного>
2.3.2 Бэкуса-Наура формы (БНФ)
<предложение> ::= <фраза существительного> <фраза глагола> <фраза существительного>
![2.3.3 РБНФ (расширенная) [ ] – синтаксическая конструкция может отсутствовать; {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1365637/slide-22.jpg)
2.3.3 РБНФ (расширенная)
[ ] – синтаксическая конструкция может отсутствовать;
{ } –
2.3.3 РБНФ (расширенная)
[ ] – синтаксическая конструкция может отсутствовать;
{ } –

2.3.3 РБНФ
<буква> ::= A | B| C …| Z| а| b|
2.3.3 РБНФ
<буква> ::= A | B| C …| Z| а| b|

2.3.4 Диаграмма Вирта
терминальный символ, принадлежащий алфавиту языка
постоянная группа терминальных символов, определяющая
2.3.4 Диаграмма Вирта
терминальный символ, принадлежащий алфавиту языка
постоянная группа терминальных символов, определяющая
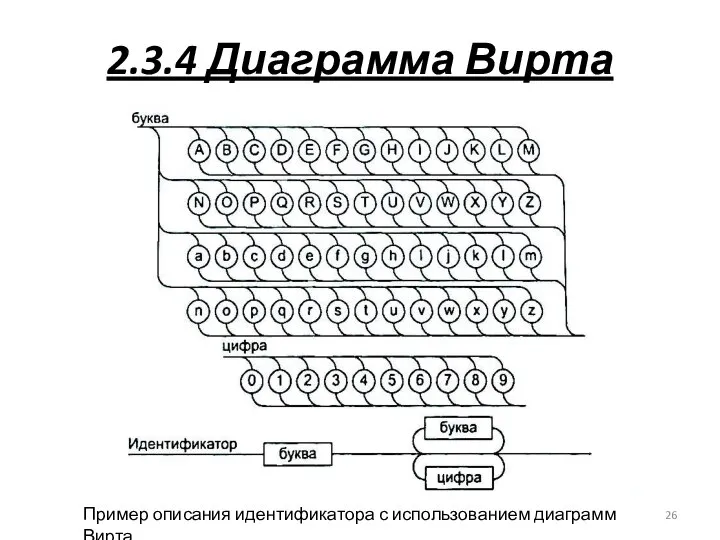
2.3.4 Диаграмма Вирта
Пример описания идентификатора с использованием диаграмм Вирта
2.3.4 Диаграмма Вирта
Пример описания идентификатора с использованием диаграмм Вирта

2.4 КЛАССИФИКАЦИЯ ЯЗЫКОВ И ГРАММАТИК
ГЛАВА 2. Основы теории формальных языков и
2.4 КЛАССИФИКАЦИЯ ЯЗЫКОВ И ГРАММАТИК
ГЛАВА 2. Основы теории формальных языков и

2.4.1 Классификация грамматик
2.4.1 Классификация грамматик

2.4.1 Классификация грамматик
2.4.1 Классификация грамматик

2.4.1 Классификация грамматик
Эта иерархия грамматик – включающая.
Грамматика 2 включает 3, но
2.4.1 Классификация грамматик
Эта иерархия грамматик – включающая.
Грамматика 2 включает 3, но

2.4.2 Классификация языков
Языки классифицируются в соответствие с типами грамматик с помощью
2.4.2 Классификация языков
Языки классифицируются в соответствие с типами грамматик с помощью

2.4.2 Классификация языков
Грамматика 0 G1 = ({0,1}, {A,S}, P1, S) и
P1: S
2.4.2 Классификация языков
Грамматика 0 G1 = ({0,1}, {A,S}, P1, S) и
P1: S

2.4.2 Классификация языков
Сложность языка убывает с возрастанием классификационного типа языка.
Тип 0.
2.4.2 Классификация языков
Сложность языка убывает с возрастанием классификационного типа языка.
Тип 0.

2.4.3 Примеры классификации языков и грамматик
Язык типа 2: L(G3) = {(ac)n
2.4.3 Примеры классификации языков и грамматик
Язык типа 2: L(G3) = {(ac)n

2.4.3 Примеры классификации языков и грамматик
2.4.3 Примеры классификации языков и грамматик

2.5 ЦЕПОЧКИ ВЫВОДА. СЕНТЕНЦИАЛЬНАЯ ФОРМА
ГЛАВА 2. Основы теории формальных языков и
2.5 ЦЕПОЧКИ ВЫВОДА. СЕНТЕНЦИАЛЬНАЯ ФОРМА
ГЛАВА 2. Основы теории формальных языков и

2.5.1 Вывод. Цепочка вывода.
Выводом называется процесс порождения предложений языка на основе
2.5.1 Вывод. Цепочка вывода.
Выводом называется процесс порождения предложений языка на основе

2.5.1 Вывод. Цепочка вывода.
Цепочка β ∈ V* выводима из цепочки α
2.5.1 Вывод. Цепочка вывода.
Цепочка β ∈ V* выводима из цепочки α

2.5.1 Вывод. Цепочка вывода.
Если цепочка вывода от α к β содержит
2.5.1 Вывод. Цепочка вывода.
Если цепочка вывода от α к β содержит

2.5.1 Вывод. Цепочка вывода.
G=({A, S) {0, 1}, Р, S)
P: S ->
2.5.1 Вывод. Цепочка вывода.
G=({A, S) {0, 1}, Р, S)
P: S ->

2.5.2 Сентенциальная форма грамматики. Основа
Вывод называется законченным, если на основе цепочки
2.5.2 Сентенциальная форма грамматики. Основа
Вывод называется законченным, если на основе цепочки

2.5.2 Сентенциальная форма грамматики. Основа
Пусть G=(VN, VT, P, S) грамматика и
2.5.2 Сентенциальная форма грамматики. Основа
Пусть G=(VN, VT, P, S) грамматика и

2.5.3 Левосторонний и правосторонний вывод
Вывод цепочки β ∈ (VT)* из S
2.5.3 Левосторонний и правосторонний вывод
Вывод цепочки β ∈ (VT)* из S

2.5.3 Левосторонний и правосторонний вывод
Например, для цепочки a+b+a в грамматике
G =
2.5.3 Левосторонний и правосторонний вывод
Например, для цепочки a+b+a в грамматике
G =
 P9X79 Series Confidential
P9X79 Series Confidential Электрооборудование. Электроснабжение бортовой сети
Электрооборудование. Электроснабжение бортовой сети Бережливое производство в практике российских предприятий Бизнес-форум 28.02.2012. Пермь Ведущий: А.Б.Семенцов
Бережливое производство в практике российских предприятий Бизнес-форум 28.02.2012. Пермь Ведущий: А.Б.Семенцов Статистические свойства системы
Статистические свойства системы «Поведение потребителей автомобилей» Бондарева Лидия Гавриш Кристина Житкова Екатерина Пономарева Виктория
«Поведение потребителей автомобилей» Бондарева Лидия Гавриш Кристина Житкова Екатерина Пономарева Виктория Биография Д.И. Менделеева в датах
Биография Д.И. Менделеева в датах Тестирование и отладка программного обеспечения. Нормативно-правовая база
Тестирование и отладка программного обеспечения. Нормативно-правовая база 1. К участковому стоматологу обратилась бабушка ребенка 2 мес. с незарощением верхней губы. 1. К участковому стоматологу обратил
1. К участковому стоматологу обратилась бабушка ребенка 2 мес. с незарощением верхней губы. 1. К участковому стоматологу обратил Передачи. Ременные, цепные, фрикционные передачи
Передачи. Ременные, цепные, фрикционные передачи Жанна д’Арк Национальная героиня Франции
Жанна д’Арк Национальная героиня Франции Миграция и религия
Миграция и религия ЕИТКС МВД России. Интегрированный банк данных «ИБД-Регион»
ЕИТКС МВД России. Интегрированный банк данных «ИБД-Регион» Патристика IV - VIII веков. Греческая патристика
Патристика IV - VIII веков. Греческая патристика Млечный путь
Млечный путь Лекция 5. Тип Круглые черви Nemathelminthes – паразиты человека и животных.
Лекция 5. Тип Круглые черви Nemathelminthes – паразиты человека и животных.  Традиции народа Африки. "Бушмены"
Традиции народа Африки. "Бушмены" Операции и выражения. Операторы
Операции и выражения. Операторы Государство как универсальный политический институт Кучеров Илья Колосков Игорь
Государство как универсальный политический институт Кучеров Илья Колосков Игорь Государственная политика в сфере физической культуры и спорта в условиях становления социального государства
Государственная политика в сфере физической культуры и спорта в условиях становления социального государства Понятие «физическая готовность» в структуре общей готовности человека к профессиональной деятельности
Понятие «физическая готовность» в структуре общей готовности человека к профессиональной деятельности Презентация Пряжа и нити текстильные
Презентация Пряжа и нити текстильные Роль религии в жизни общества
Роль религии в жизни общества Необычные материалы для скульптуры Выполнила студентка 3Б группы Зубкова Д.А.
Необычные материалы для скульптуры Выполнила студентка 3Б группы Зубкова Д.А.  Гимнастические залы и площадки
Гимнастические залы и площадки Рождение ислама
Рождение ислама Гигиена труда в механических цехах
Гигиена труда в механических цехах Презентация Анализ форм занятости населения, видов трудоустройства
Презентация Анализ форм занятости населения, видов трудоустройства  Україна – це моя Батьківщина
Україна – це моя Батьківщина