- Технологии повышения производительности МП

Содержание
- 2. Термины Команда. Микрооперация или микрокоманда. Микропрограмма. Микропрограммный автомат.
- 3. Повышение производительности процессоров Конвейеризация. Суперскаляризация. Увеличение количества исполнительных блоков. Введение принципа динамического исполнения команд. Гипертрейдинг. Параллелизм
- 4. Архитектура процессоров с параллелизмом уровня команд Как способ повышения производительности процессора Так было в начале эры
- 5. Суперконвейеризация Каждый этап исполнения команды разбивается на меньшие этапы и повышается частота задающего генератора
- 6. Оценка производительности идеального конвейера Предположим Твк=20; Тдк=15; Твд=20; Тик=25; Тзр=20; t = 5 – промежуточное время
- 7. Конвейер с точки зрения схемотехники КС RG КС RG КС RG CИ1 CИ2 CИ3 n Чем
- 8. Конфликты в конвейере Конфликты – это ситуации при конвейерной обработке, которые препятствуют выполнению очередной команды. Три
- 9. Причины структурных конфликтов и способы минимизации их последствий Скорость конвейера определяется скоростью исполнения самого медленного этапа
- 10. Конвейерная обработка команд суперскалярный процессор Блок выборки команд Блок декодирования Блок выборки операндов АЛУ АЛУ Блок
- 11. Суперскалярный процессор В общем случае суперскалярный процессор может менять порядок выполнения машинных команд, заданный в исходном
- 12. Конвейерное исполнение команд Принцип неупорядоченного выполнения команд Блок выборки команд Блок буфера команд Буфер очереди команд
- 13. Конфликты по управлению Возникают при конвейеризации команд меняющих значение счетчика команд. Метод выжидания Метод «задержанных переходов»
- 14. Статическое предсказание переходов Осуществляется на основе некоторой априорной информации о подлежащей исполнению программе. Известны следующие стратегии:
- 15. Статическое прогнозирование переходов ИСПОЛНЕНИЕ ПО ПРЕДПОЛОЖЕНИЮ При компилировании программы можно создать граф предполагаемых ветвлений и задать
- 16. Предикативное выполнение Предикация Блок 1 Блок 2 Блок 3 Блок 5 Блок 4 Блок 6 IN
- 17. Динамическое предсказание переходов Решение о наиболее вероятном исходе команды перехода принимается в ходе вычислений исходя из
- 18. Динамическое прогнозирование ветвлений Аппаратная реализация таблиц переходов Адрес\Тег перехода Бит перехода Бит достоверности Целевой адрес Вариант
- 19. Гибридный предиктор Макфарлинга Схема имеет два независимых предиктора, отличающиеся глубиной предыстории Счетчик выбора предиктора Младшие разряды
- 20. Общая схема гибридного предиктора
- 21. Опережающее чтение данных Спекулятивное выполнение команды Команда 1 Чтение с опережением Команда проверки Команда 9 Обработка
- 22. Выполнение одной команды зависит от результата выполнения другой Конфликты по данным и их решение Конфликт чтение
- 23. Планирование загрузки конвейера. Переименование регистров МП. Решение конфликтов по данным Базовый блок 1 программы 2 Команда
- 24. Технология динамического исполнения команд Суперскалярность. Предсказание переходов. Неупорядочное исполнение команд. Предварительная загрузка данных. Переименование регистров. Предикативное
- 25. Характеристика конвейeров МП Intel и AMD
- 26. Технология многократного декодирование команд используя CMS Предекодер Предекодер Предекодер Декодер Исполнительные блоки Команды CISC/RISC Команда VLIW
- 27. Технология макрослияния (macrofusion) Макрослияние позволяет объединять типичные пары последовательных команд (например - сравнение и условный переход)
- 28. Технология микрослияния (Micro-op fusion) Команды при декодировании могут использовать одинаковые микрокоманды Технология предусматривает однократный вызов микрокоманды
- 29. Технология резервирующей станции Команды выполняются с разным быстродействием. Команды могут зависеть друг от друга. Командам могут
- 30. Микроархитектура Pentium2 Устройство сопряжения с шиной Кэш первого уровня для команд Кэш первого уровня для данных
- 31. Микроархитектура Pentium2 блок вызова декодирования Кэш первого уровня для команд Блок выбора строк кэш Декодер длины
- 32. Микроархитектура Pentium2 блок отправки\выполнения Очередь микрокоманд 20 РЕЗЕРВАЦИЯ Блок выполнения операций с целыми числами Блок выполнения
- 33. Микроархитектура Pentium2 блок возврата Отвечает: - за отправку результатов в регистры или устройства, которым они требуются.
- 34. Пример конвейера AMD K8 часть1
- 35. Пример конвейера AMD K8 часть 2
- 36. Проблемы суперскальных МП Простои конвейеров из-за нерегулярной загрузки функциональных устройств МП. Наличие одного счетчика команд. Ограничение
- 37. Мультитрейдовые микропроцессоры Тред – вычислительный процесс обслуживаемый отдельным набором регистров. Однотрейдовый микропроцессор – имеет один счетчик
- 38. Принцип работы мультитрейдовой архитектуры Тред 1 Тред 2 Тред N Память Коммутатор M тактов Планировщик -
- 39. Технология Hyper-Threading Реализуется идея разделения времени на аппаратном уровне Задача 1 Задача 1 АЛУ Регистры Управление
- 40. Технология Hyper-Threading
- 41. Itanium Использование сложных команд переменной длины, обрабатываемых последовательно Использование простых команд одинаковой длины, сгруппированных в связки
- 42. Этапы развития структур МП по системам команд CISC RISC VLIW VLIW EPIC Внешние команды CISC ядро
- 43. Синтез команд для процессоров VLIW Задача эффективного планирования параллельных вычислений команд возлагается на «разумный» компилятор Code
- 44. Формат связки команд Компилятор формирует связки команд длинной 128 бит. Itanium Маска 8р. Команда 1 Команда
- 45. Взаимосвязь полей команды VLIW с исполнительными блоками До 128 байт Статическая суперскалярная архитектура – одно из
- 47. Скачать презентацию

Термины
Команда.
Микрооперация или микрокоманда.
Микропрограмма.
Микропрограммный автомат.
Термины
Команда.
Микрооперация или микрокоманда.
Микропрограмма.
Микропрограммный автомат.

Повышение производительности процессоров
Конвейеризация.
Суперскаляризация.
Увеличение количества исполнительных блоков.
Введение принципа динамического исполнения команд.
Гипертрейдинг.
Параллелизм исполнения
Повышение производительности процессоров
Конвейеризация.
Суперскаляризация.
Увеличение количества исполнительных блоков.
Введение принципа динамического исполнения команд.
Гипертрейдинг.
Параллелизм исполнения
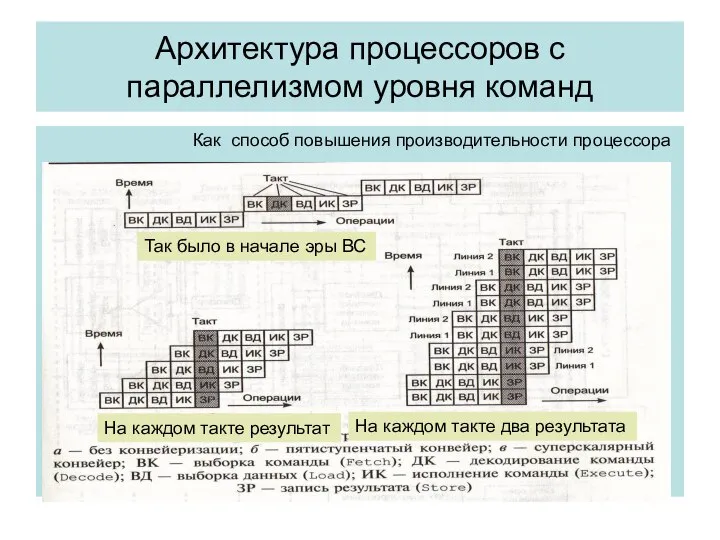
Архитектура процессоров с параллелизмом уровня команд
Как способ повышения производительности процессора
Так было
Архитектура процессоров с параллелизмом уровня команд
Как способ повышения производительности процессора
Так было

Суперконвейеризация
Каждый этап исполнения команды разбивается на меньшие этапы
и повышается частота
Суперконвейеризация
Каждый этап исполнения команды разбивается на меньшие этапы
и повышается частота

Оценка производительности идеального конвейера
Предположим Твк=20; Тдк=15; Твд=20; Тик=25; Тзр=20;
t = 5
Оценка производительности идеального конвейера
Предположим Твк=20; Тдк=15; Твд=20; Тик=25; Тзр=20;
t = 5
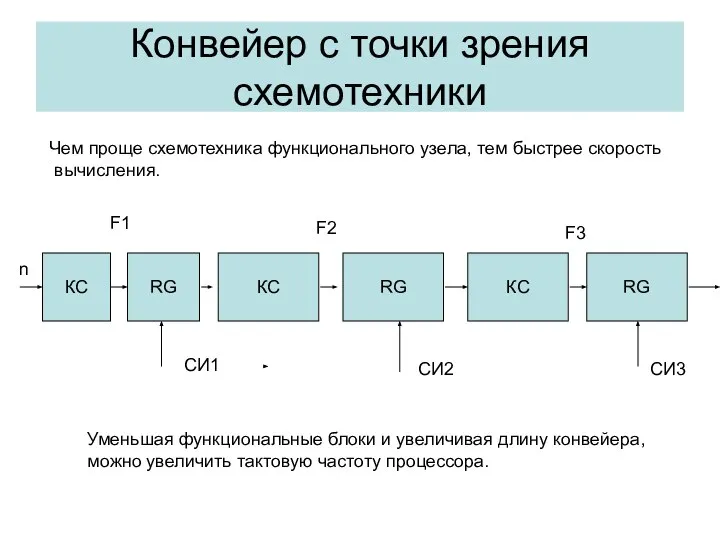
Конвейер с точки зрения схемотехники
КС
RG
КС
RG
КС
RG
CИ1
CИ2
CИ3
n
Чем проще схемотехника функционального узела, тем быстрее
Конвейер с точки зрения схемотехники
КС
RG
КС
RG
КС
RG
CИ1
CИ2
CИ3
n
Чем проще схемотехника функционального узела, тем быстрее

Конфликты в конвейере
Конфликты – это ситуации при конвейерной обработке, которые препятствуют
Конфликты в конвейере
Конфликты – это ситуации при конвейерной обработке, которые препятствуют
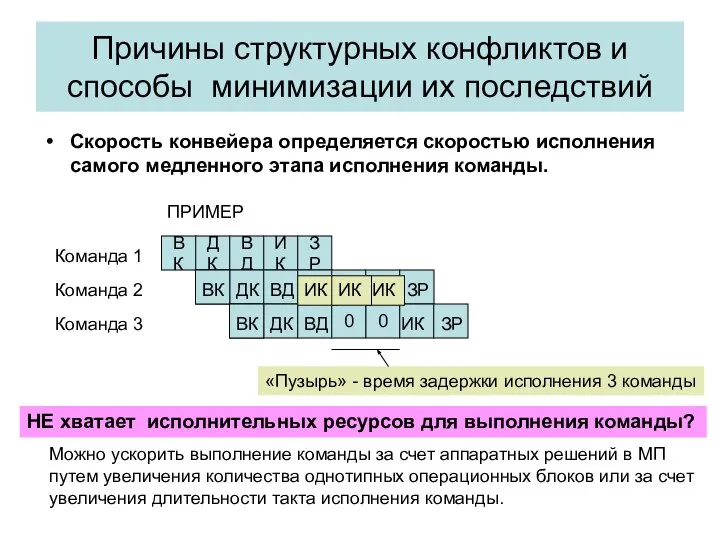
Причины структурных конфликтов и способы минимизации их последствий
Скорость конвейера определяется скоростью
Причины структурных конфликтов и способы минимизации их последствий
Скорость конвейера определяется скоростью
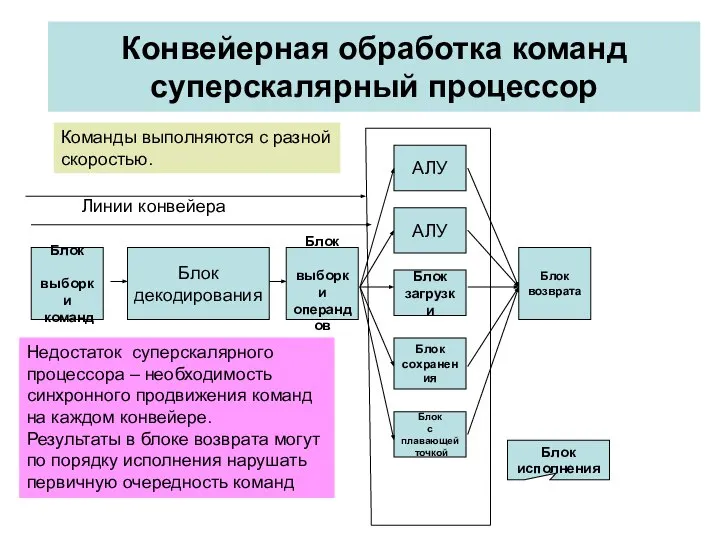
Конвейерная обработка команд суперскалярный процессор
Блок
выборки
команд
Блок
декодирования
Блок
выборки
операндов
АЛУ
АЛУ
Блок
загрузки
Блок
сохранения
Блок
с плавающей
точкой
Блок
возврата
Блок
исполнения
Команды
Конвейерная обработка команд суперскалярный процессор
Блок
выборки
команд
Блок
декодирования
Блок
выборки
операндов
АЛУ
АЛУ
Блок
загрузки
Блок
сохранения
Блок
с плавающей
точкой
Блок
возврата
Блок
исполнения
Команды
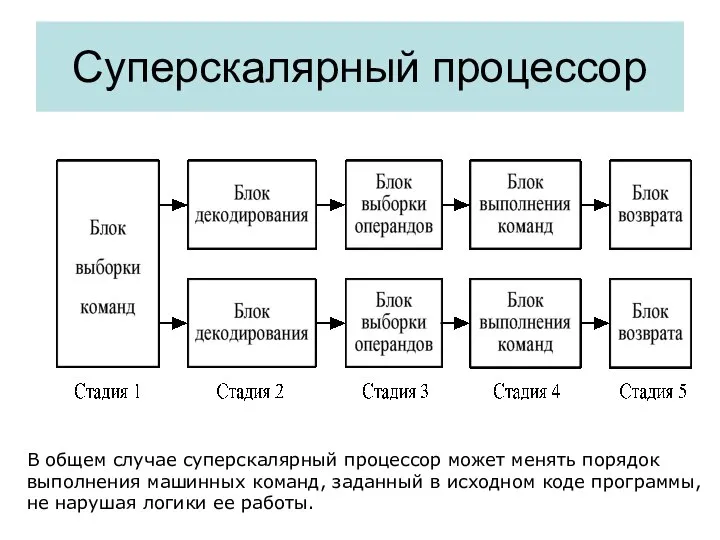
Суперскалярный процессор
В общем случае суперскалярный процессор может менять порядок
выполнения машинных
Суперскалярный процессор
В общем случае суперскалярный процессор может менять порядок
выполнения машинных
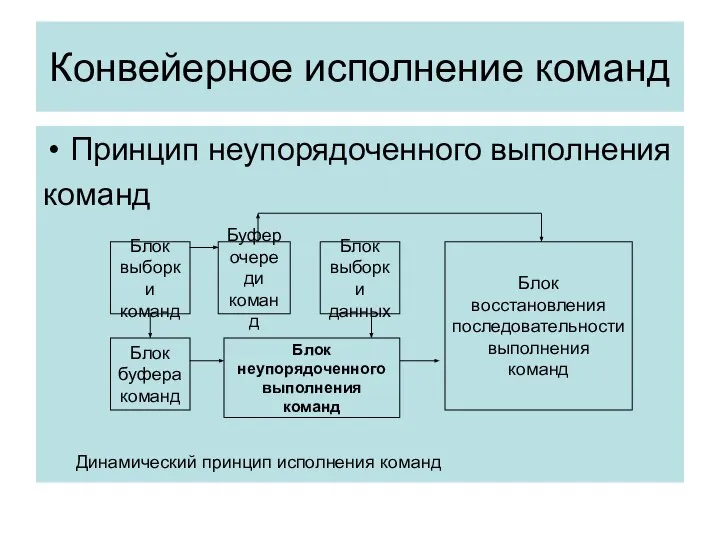
Конвейерное исполнение команд
Принцип неупорядоченного выполнения
команд
Блок
выборки
команд
Блок
буфера
команд
Буфер
очереди
команд
Блок
выборки
данных
Блок
неупорядоченного
выполнения
команд
Блок
восстановления
последовательности
выполнения
команд
Динамический принцип исполнения команд
Конвейерное исполнение команд
Принцип неупорядоченного выполнения
команд
Блок
выборки
команд
Блок
буфера
команд
Буфер
очереди
команд
Блок
выборки
данных
Блок
неупорядоченного
выполнения
команд
Блок
восстановления
последовательности
выполнения
команд
Динамический принцип исполнения команд
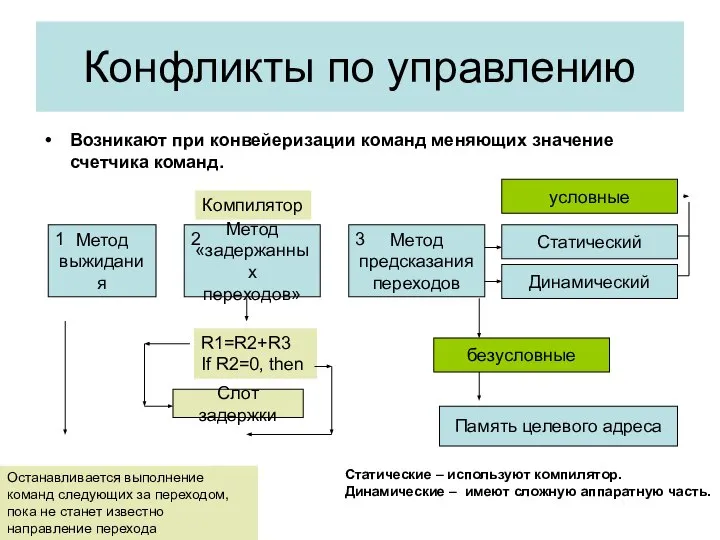
Конфликты по управлению
Возникают при конвейеризации команд меняющих значение счетчика команд.
Метод
выжидания
Метод
«задержанных
переходов»
Метод
предсказания
переходов
Статический
Динамический
R1=R2+R3
If R2=0,
Конфликты по управлению
Возникают при конвейеризации команд меняющих значение счетчика команд.
Метод
выжидания
Метод
«задержанных
переходов»
Метод
предсказания
переходов
Статический
Динамический
R1=R2+R3
If R2=0,

Статическое предсказание переходов
Осуществляется на основе некоторой априорной информации о подлежащей исполнению
Статическое предсказание переходов
Осуществляется на основе некоторой априорной информации о подлежащей исполнению

Статическое прогнозирование переходов ИСПОЛНЕНИЕ ПО ПРЕДПОЛОЖЕНИЮ
При компилировании программы можно создать граф
Статическое прогнозирование переходов ИСПОЛНЕНИЕ ПО ПРЕДПОЛОЖЕНИЮ
При компилировании программы можно создать граф
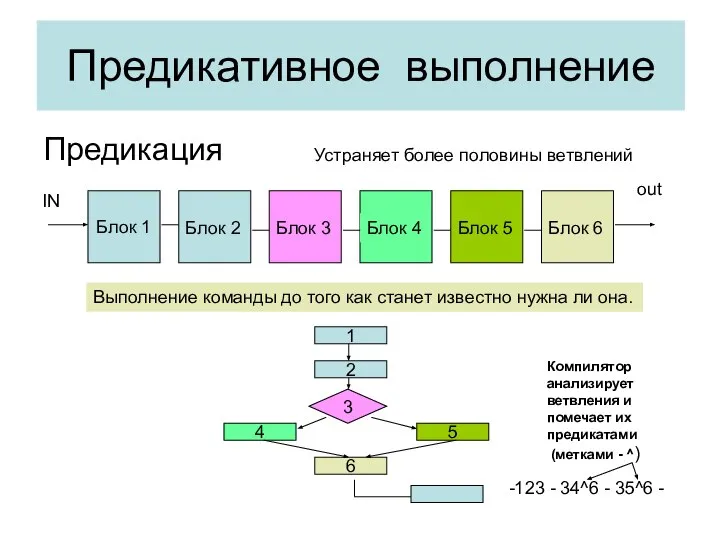
Предикативное выполнение
Предикация
Блок 1
Блок 2
Блок 3
Блок 5
Блок 4
Блок 6
IN
out
Выполнение команды до
Предикативное выполнение
Предикация
Блок 1
Блок 2
Блок 3
Блок 5
Блок 4
Блок 6
IN
out
Выполнение команды до

Динамическое предсказание переходов
Решение о наиболее вероятном исходе команды перехода принимается в
Динамическое предсказание переходов
Решение о наиболее вероятном исходе команды перехода принимается в
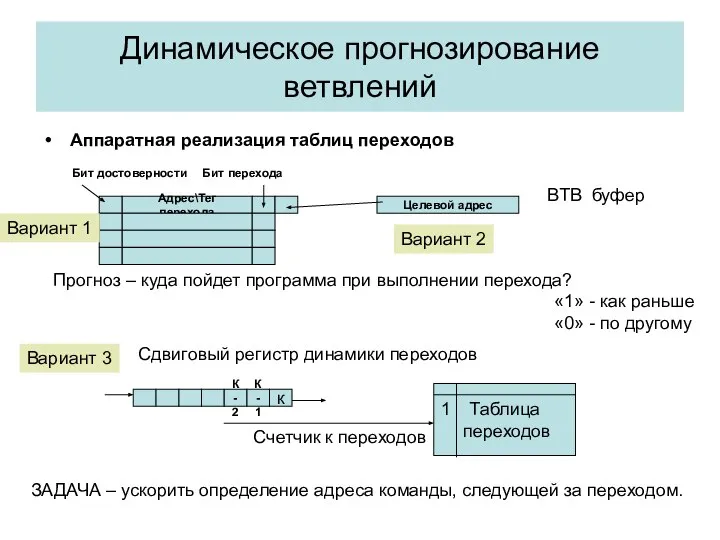
Динамическое прогнозирование ветвлений
Аппаратная реализация таблиц переходов
Адрес\Тег перехода
Бит перехода
Бит достоверности
Целевой адрес
Вариант 1
Вариант
Динамическое прогнозирование ветвлений
Аппаратная реализация таблиц переходов
Адрес\Тег перехода
Бит перехода
Бит достоверности
Целевой адрес
Вариант 1
Вариант
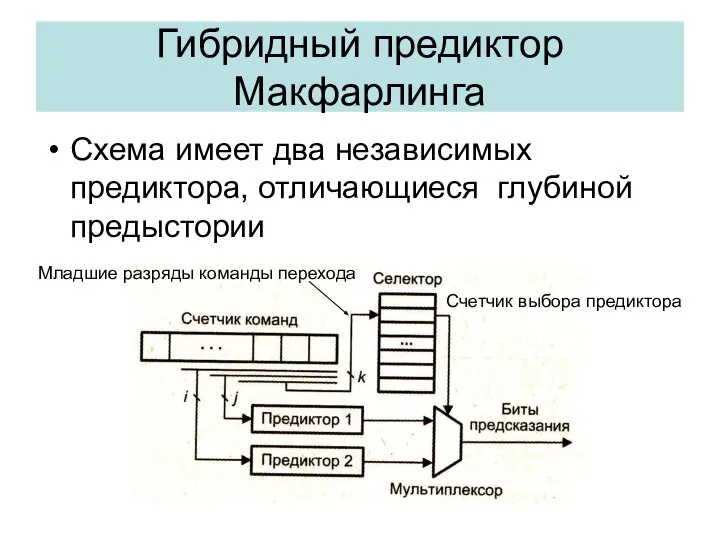
Гибридный предиктор Макфарлинга
Схема имеет два независимых предиктора, отличающиеся глубиной предыстории
Счетчик выбора
Гибридный предиктор Макфарлинга
Схема имеет два независимых предиктора, отличающиеся глубиной предыстории
Счетчик выбора
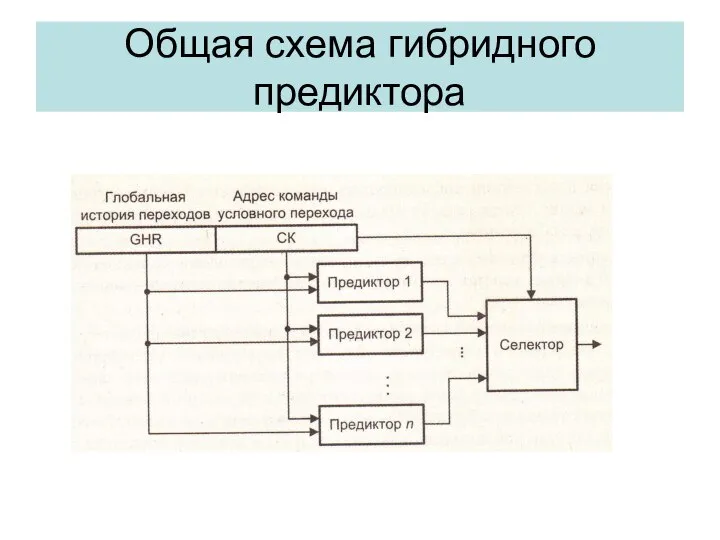
Общая схема гибридного предиктора
Общая схема гибридного предиктора
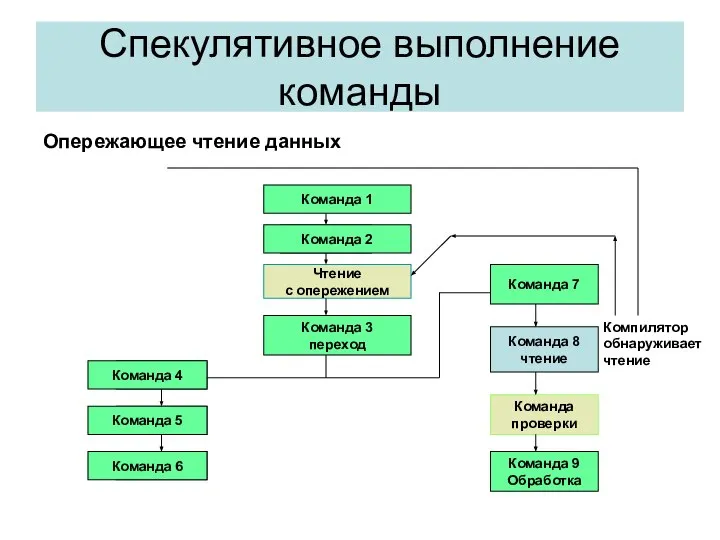
Опережающее чтение данных
Спекулятивное выполнение команды
Команда 1
Чтение
с опережением
Команда
проверки
Команда 9
Обработка
Команда 2
Команда 3
переход
Команда 4
Команда
Опережающее чтение данных
Спекулятивное выполнение команды
Команда 1
Чтение
с опережением
Команда
проверки
Команда 9
Обработка
Команда 2
Команда 3
переход
Команда 4
Команда
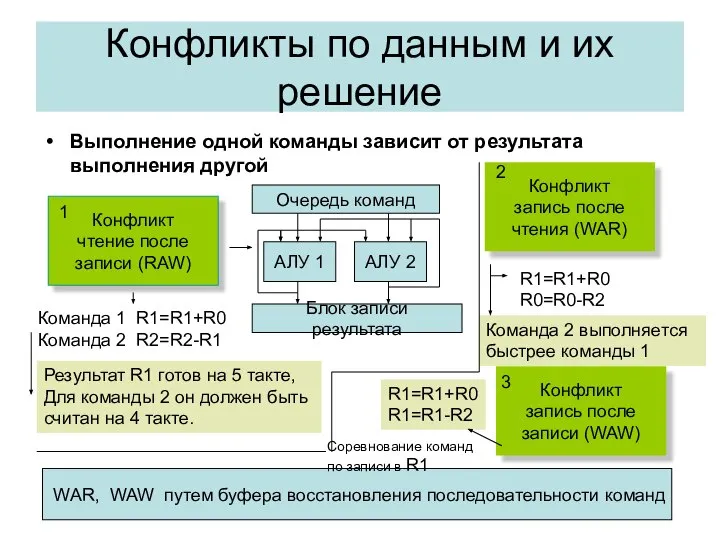
Выполнение одной команды зависит от результата выполнения другой
Конфликты по данным и
Выполнение одной команды зависит от результата выполнения другой
Конфликты по данным и
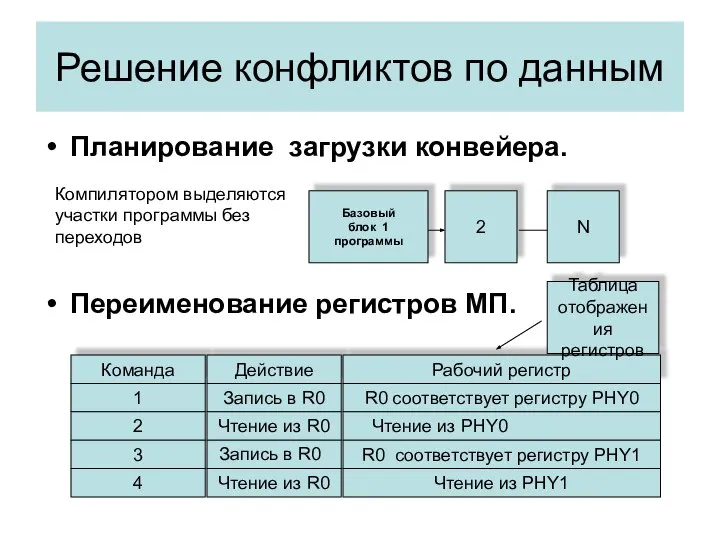
Планирование загрузки конвейера.
Переименование регистров МП.
Решение конфликтов по данным
Базовый
блок 1
программы
2
Команда
N
Компилятором выделяются
участки программы
Планирование загрузки конвейера.
Переименование регистров МП.
Решение конфликтов по данным
Базовый
блок 1
программы
2
Команда
N
Компилятором выделяются
участки программы

Технология динамического исполнения команд
Суперскалярность.
Предсказание переходов.
Неупорядочное исполнение команд.
Предварительная загрузка данных.
Переименование регистров.
Предикативное исполнение.
Резервирующая
Технология динамического исполнения команд
Суперскалярность.
Предсказание переходов.
Неупорядочное исполнение команд.
Предварительная загрузка данных.
Переименование регистров.
Предикативное исполнение.
Резервирующая
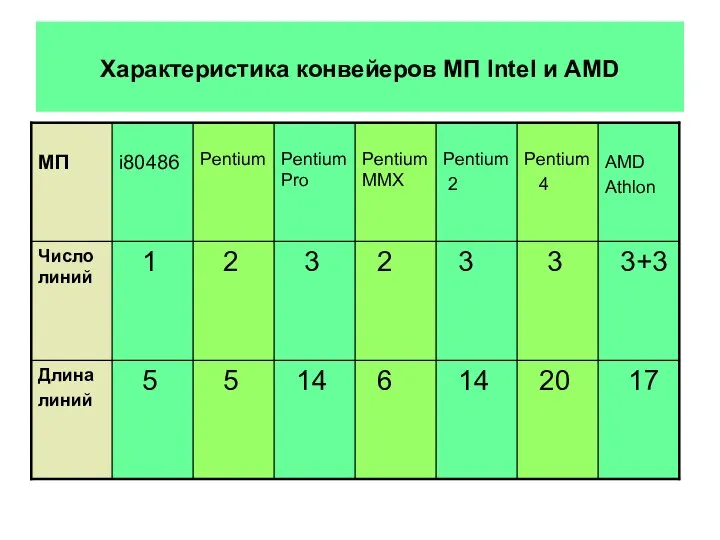
Характеристика конвейeров МП Intel и AMD
Характеристика конвейeров МП Intel и AMD
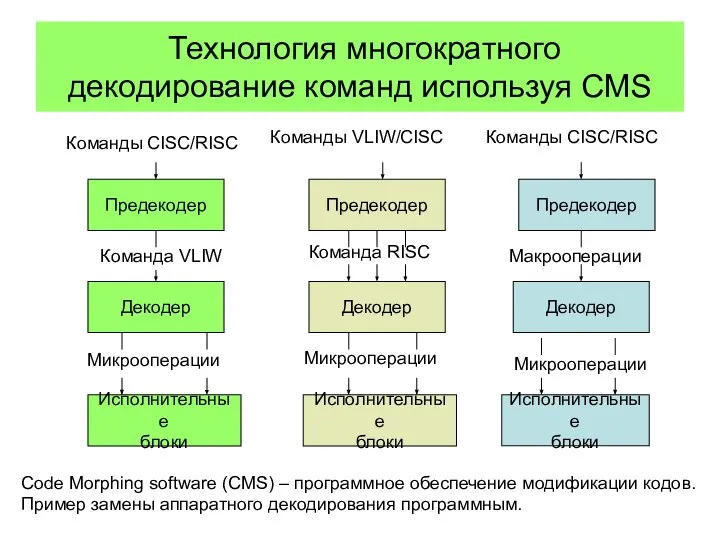
Технология многократного декодирование команд используя CMS
Предекодер
Предекодер
Предекодер
Декодер
Исполнительные
блоки
Команды CISC/RISC
Команда VLIW
Микрооперации
Микрооперации
Микрооперации
Исполнительные
блоки
Исполнительные
блоки
Макрооперации
Декодер
Декодер
Команда RISC
Команды VLIW/CISC
Команды
Технология многократного декодирование команд используя CMS
Предекодер
Предекодер
Предекодер
Декодер
Исполнительные
блоки
Команды CISC/RISC
Команда VLIW
Микрооперации
Микрооперации
Микрооперации
Исполнительные
блоки
Исполнительные
блоки
Макрооперации
Декодер
Декодер
Команда RISC
Команды VLIW/CISC
Команды
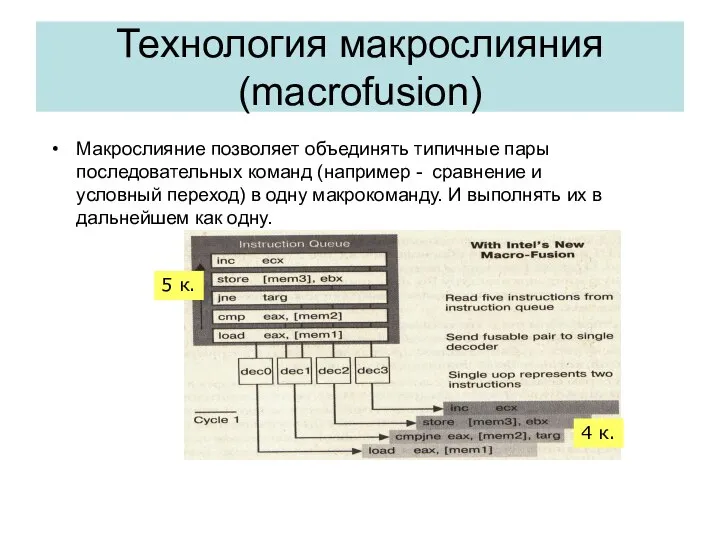
Технология макрослияния (macrofusion)
Макрослияние позволяет объединять типичные пары последовательных команд (например -
Технология макрослияния (macrofusion)
Макрослияние позволяет объединять типичные пары последовательных команд (например -

Технология микрослияния
(Micro-op fusion)
Команды при декодировании могут использовать одинаковые микрокоманды
Технология предусматривает однократный
Технология микрослияния
(Micro-op fusion)
Команды при декодировании могут использовать одинаковые микрокоманды
Технология предусматривает однократный

Технология резервирующей станции
Команды выполняются с разным быстродействием.
Команды могут зависеть друг от
Технология резервирующей станции
Команды выполняются с разным быстродействием.
Команды могут зависеть друг от
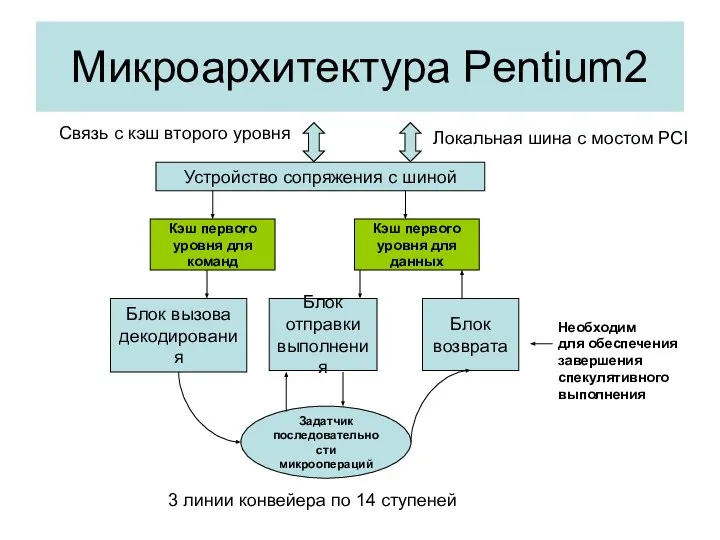
Микроархитектура Pentium2
Устройство сопряжения с шиной
Кэш первого
уровня для
команд
Кэш первого
уровня для
данных
Блок вызова
декодирования
Блок
отправки
выполнения
Блок
возврата
Задатчик
последовательности
микроопераций
Локальная шина
Микроархитектура Pentium2
Устройство сопряжения с шиной
Кэш первого
уровня для
команд
Кэш первого
уровня для
данных
Блок вызова
декодирования
Блок
отправки
выполнения
Блок
возврата
Задатчик
последовательности
микроопераций
Локальная шина
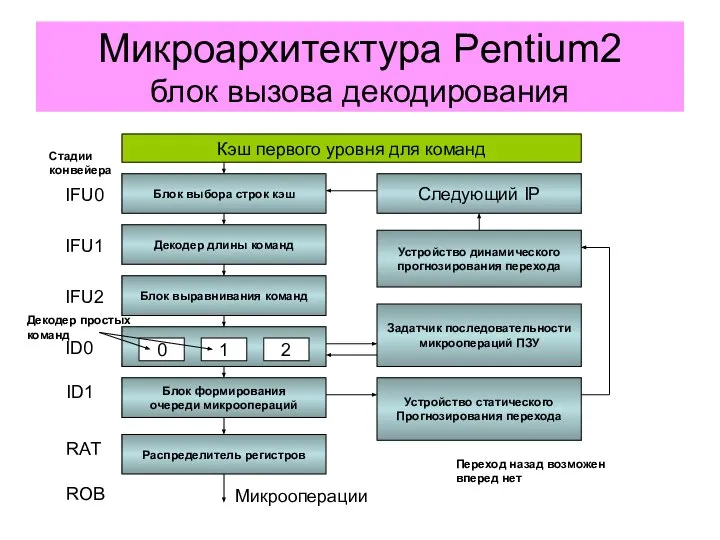
Микроархитектура Pentium2
блок вызова декодирования
Кэш первого уровня для команд
Блок выбора строк кэш
Декодер
Микроархитектура Pentium2
блок вызова декодирования
Кэш первого уровня для команд
Блок выбора строк кэш
Декодер
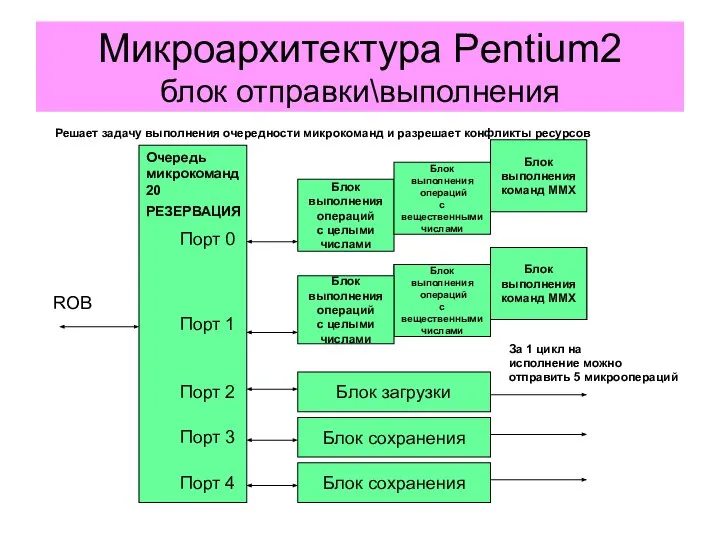
Микроархитектура Pentium2
блок отправки\выполнения
Очередь
микрокоманд
20
РЕЗЕРВАЦИЯ
Блок
выполнения
операций
с целыми
числами
Блок
выполнения
операций
с вещественными
числами
Блок
выполнения
команд ММХ
Блок загрузки
Блок сохранения
Блок
Микроархитектура Pentium2
блок отправки\выполнения
Очередь
микрокоманд
20
РЕЗЕРВАЦИЯ
Блок
выполнения
операций
с целыми
числами
Блок
выполнения
операций
с вещественными
числами
Блок
выполнения
команд ММХ
Блок загрузки
Блок сохранения
Блок

Микроархитектура Pentium2
блок возврата
Отвечает:
- за отправку результатов в регистры или устройства,
Микроархитектура Pentium2
блок возврата
Отвечает:
- за отправку результатов в регистры или устройства,
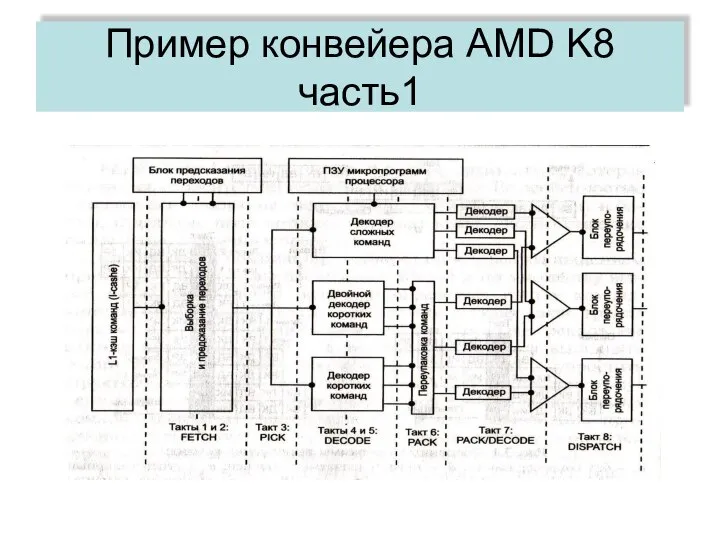
Пример конвейера AMD K8 часть1
Пример конвейера AMD K8 часть1
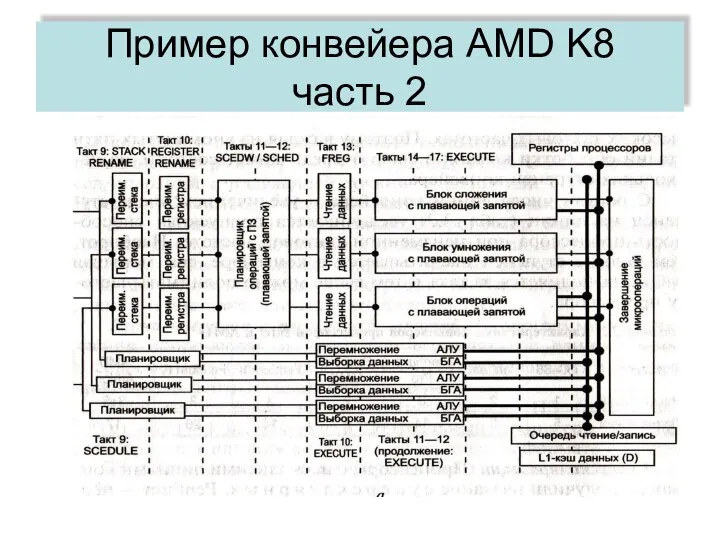
Пример конвейера AMD K8
часть 2
Пример конвейера AMD K8
часть 2

Проблемы суперскальных МП
Простои конвейеров из-за нерегулярной загрузки функциональных устройств МП.
Наличие одного
Проблемы суперскальных МП
Простои конвейеров из-за нерегулярной загрузки функциональных устройств МП.
Наличие одного

Мультитрейдовые микропроцессоры
Тред – вычислительный процесс обслуживаемый отдельным набором регистров.
Однотрейдовый микропроцессор –
Мультитрейдовые микропроцессоры
Тред – вычислительный процесс обслуживаемый отдельным набором регистров.
Однотрейдовый микропроцессор –
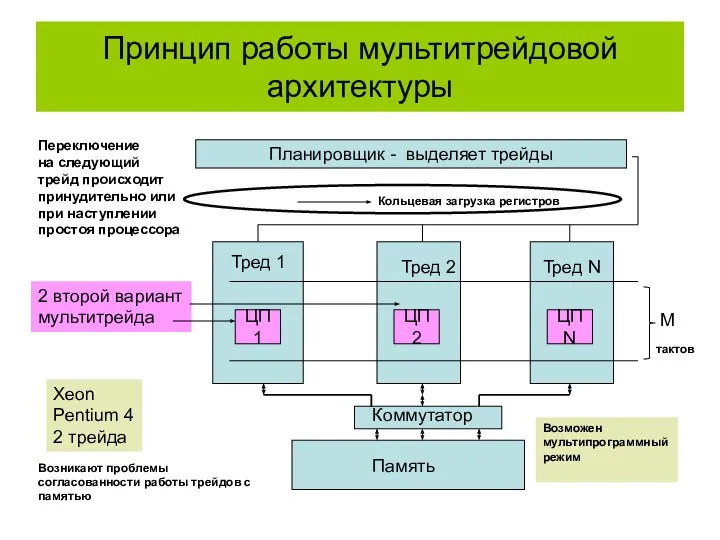
Принцип работы мультитрейдовой архитектуры
Тред 1
Тред 2
Тред N
Память
Коммутатор
M
тактов
Планировщик - выделяет трейды
Переключение
на следующий
Принцип работы мультитрейдовой архитектуры
Тред 1
Тред 2
Тред N
Память
Коммутатор
M
тактов
Планировщик - выделяет трейды
Переключение
на следующий
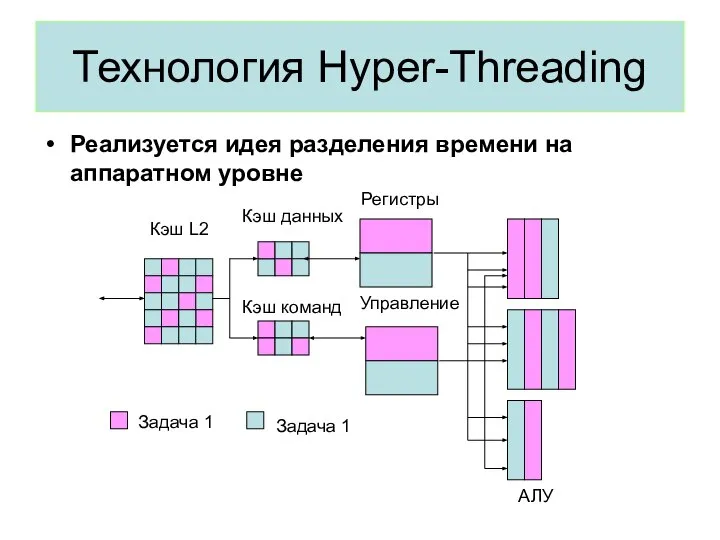
Технология Hyper-Threading
Реализуется идея разделения времени на аппаратном уровне
Задача 1
Задача 1
АЛУ
Регистры
Управление
Кэш данных
Кэш
Технология Hyper-Threading
Реализуется идея разделения времени на аппаратном уровне
Задача 1
Задача 1
АЛУ
Регистры
Управление
Кэш данных
Кэш
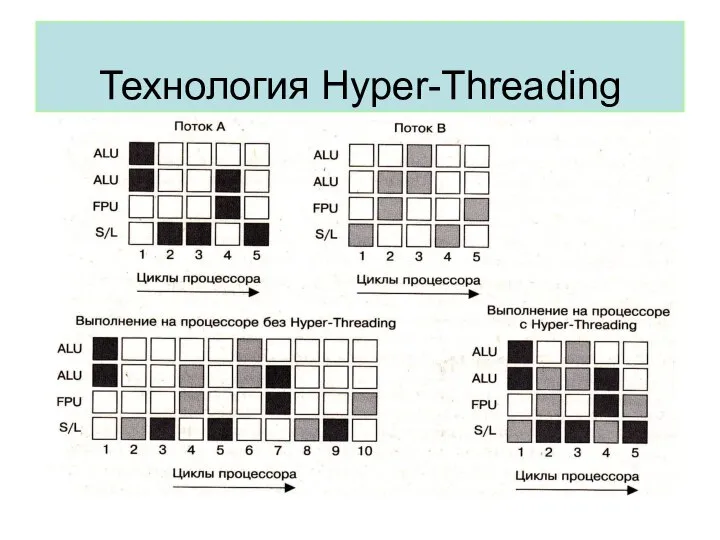
Технология Hyper-Threading
Технология Hyper-Threading
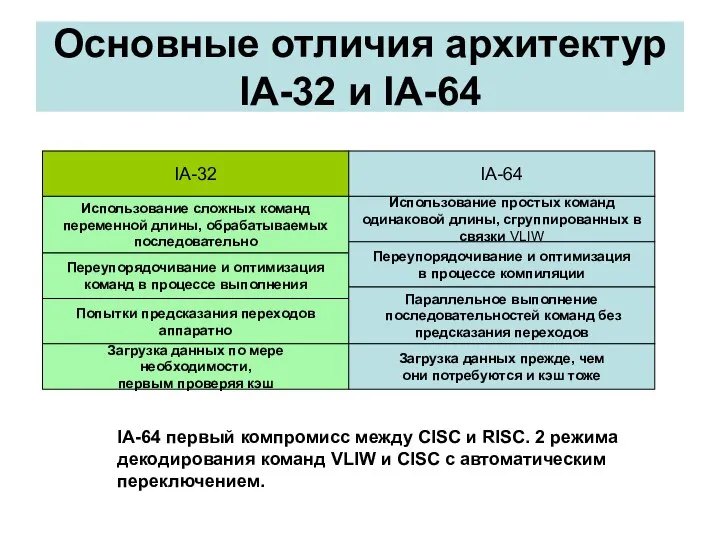
Itanium
Использование сложных команд
переменной длины, обрабатываемых
последовательно
Использование простых команд
одинаковой длины, сгруппированных в
Itanium
Использование сложных команд
переменной длины, обрабатываемых
последовательно
Использование простых команд
одинаковой длины, сгруппированных в
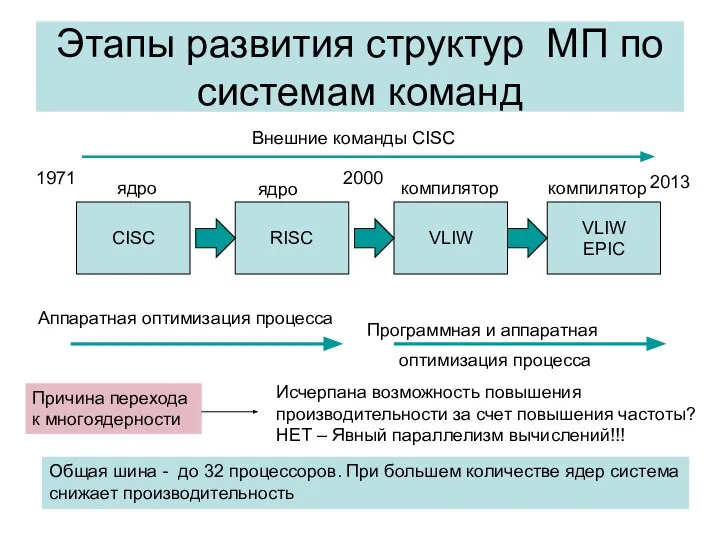
Этапы развития структур МП по системам команд
CISC
RISC
VLIW
VLIW
EPIC
Внешние команды CISC
ядро
компилятор
ядро
Аппаратная оптимизация процесса
Программная
Этапы развития структур МП по системам команд
CISC
RISC
VLIW
VLIW
EPIC
Внешние команды CISC
ядро
компилятор
ядро
Аппаратная оптимизация процесса
Программная
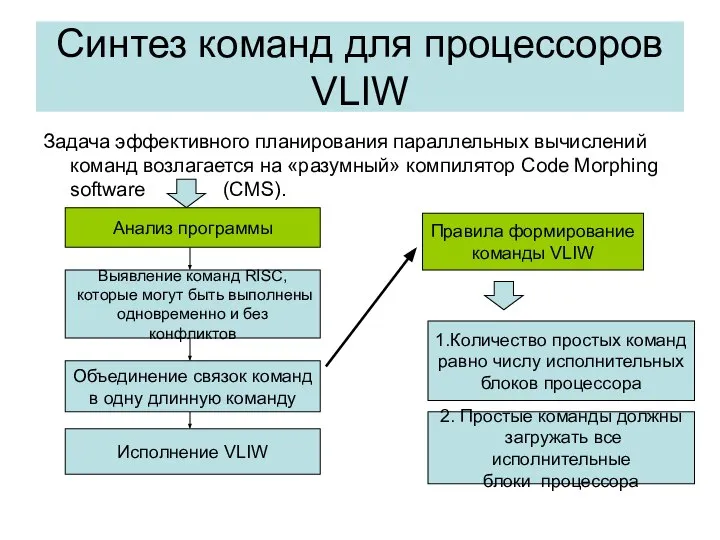
Синтез команд для процессоров VLIW
Задача эффективного планирования параллельных вычислений команд возлагается
Синтез команд для процессоров VLIW
Задача эффективного планирования параллельных вычислений команд возлагается
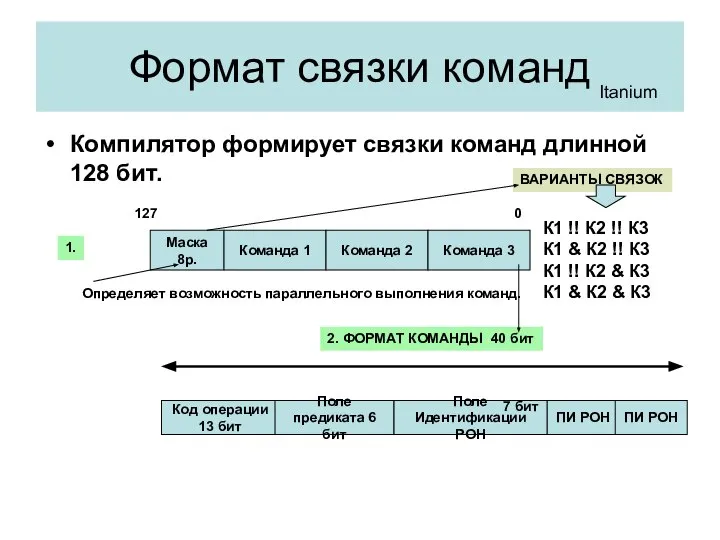
Формат связки команд
Компилятор формирует связки команд длинной 128 бит.
Itanium
Маска 8р.
Команда 1
Команда
Формат связки команд
Компилятор формирует связки команд длинной 128 бит.
Itanium
Маска 8р.
Команда 1
Команда
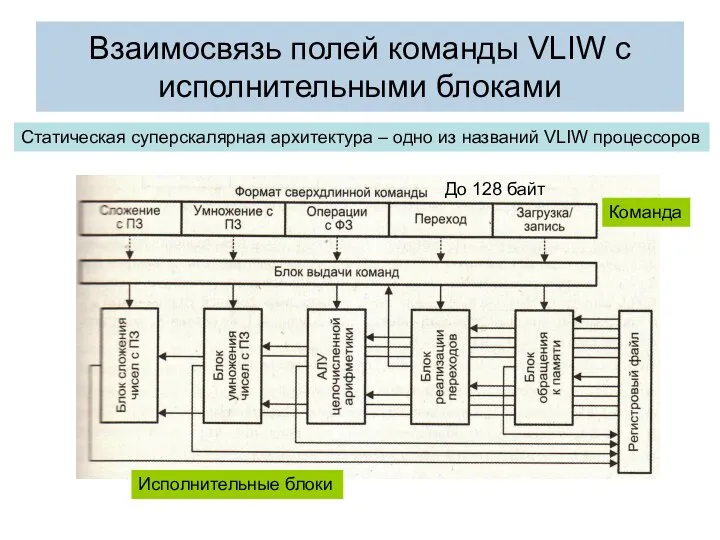
Взаимосвязь полей команды VLIW с исполнительными блоками
До 128 байт
Статическая суперскалярная архитектура
Взаимосвязь полей команды VLIW с исполнительными блоками
До 128 байт
Статическая суперскалярная архитектура
 косвенные налоги
косвенные налоги  Пересмотр вступивших в законную силу судебных решений
Пересмотр вступивших в законную силу судебных решений Дауыссыз дыбыстар
Дауыссыз дыбыстар Финансовая отчетность банка ВТБ Петрова Маргарита Куркина анна 3 курс фм
Финансовая отчетность банка ВТБ Петрова Маргарита Куркина анна 3 курс фм Каменные стены МКД
Каменные стены МКД Физиология заднего мозга
Физиология заднего мозга Искусство Древней Греции Афинский Акрополь
Искусство Древней Греции Афинский Акрополь Структура и типология культуры
Структура и типология культуры Ярмарка талантов. Российское движение школьников
Ярмарка талантов. Российское движение школьников Весёлые задачки - презентация для начальной школы_
Весёлые задачки - презентация для начальной школы_ Системы Счисления
Системы Счисления Описание слайда:
Модели поведения человека в институциональной экономике
Описание слайда:
Модели поведения человека в институциональной экономике Плавкие предохранители
Плавкие предохранители Семиотика и синдромология болезней крови. Геморраг. диатезы, лейкозы
Семиотика и синдромология болезней крови. Геморраг. диатезы, лейкозы Nikolay Vasilievich Sklifosovsky
Nikolay Vasilievich Sklifosovsky Паллиативная медицинская помощь в Российской Федерации. Изменения законодательства
Паллиативная медицинская помощь в Российской Федерации. Изменения законодательства Ранние формы религии. Часть III
Ранние формы религии. Часть III «Условия применения компьютерных программ в начальной школе» "Скажи мне, и я забуду. Покажи мне, - я см
«Условия применения компьютерных программ в начальной школе» "Скажи мне, и я забуду. Покажи мне, - я см История развития самбо
История развития самбо Презентация Целеполагание
Презентация Целеполагание Таможенная флотилия в современных условиях Подготовила студентка ФТД-1, группы Т-102 Телкова Алина
Таможенная флотилия в современных условиях Подготовила студентка ФТД-1, группы Т-102 Телкова Алина Рычаги в технике, быту и природе
Рычаги в технике, быту и природе Тектоника
Тектоника Правовое государство
Правовое государство Имя прилагательное как часть речи. Правописание прилагательных.
Имя прилагательное как часть речи. Правописание прилагательных. Вакуумный экскаватор
Вакуумный экскаватор Медицина в эпоху возрождения Выполнил:студент гр.102 стом. фак. Пеньковский Б.Г.
Медицина в эпоху возрождения Выполнил:студент гр.102 стом. фак. Пеньковский Б.Г.  черно-белые - презентация для начальной школы
черно-белые - презентация для начальной школы