- Deklarace proměnných v programovacích jazycích

Содержание
- 2. ASN.1 Deklarace proměnných v programovacích jazycích Typy: Jednoduchý („vestavěný“) typ, který již dále není strukturován. Např.
- 3. Rodiny kódování BER DER CER PER - (Packet encoding rules). BER předpokládá, že kóduje zpráva, tj.
- 4. BER kódování
- 5. Pole typ dat
- 6. Univerzální typy Tág Tág Typ desítkově šestnáctkově Význam END OF CONT. 0 0 Konec pole dat
- 7. Pole délka dat
- 8. Příklad V kódování BER vyjádřete jednu položku z kartotéky zaměstnanců firmy kapitalista.cz. Tato firma má každého
- 9. Příklad - pokračování V ASN.1 se v praxi zápis Typu Zamestnanec píše elegantněji: Zamestnanec ::= SEQUENCE
- 10. Příklad - dokončení Takže konkrétní kartu v kódování BER pro zaměstnance: Bobek Bob TRUE (Pohlavi) FALSE
- 11. Program dumpasn1 Praktická ukázka
- 12. Prázdný typ Prázdný typ se kóduje opět dle schématu: tág (05), délka (nula) a hodnota (ta
- 13. BOOLEAN Pravda se kóduje: 01 01 FF Nepravda se kóduje: 01 01 00
- 14. INTEGER Typ INTEGER se kóduje binárně tak, jak je to běžné, tj. nejvýznamnější bit nastavený na
- 15. Výčet Pomocí typu INTEGER lze vytvořit výčet tak, že se jednotlivé hodnoty pojmenují identifikátory. V kulatých
- 16. SEQUENCE, SEQUENCE OF, SET a SET OF Jedná se o strukturované typy (k tágu se připočítává
- 17. Čas Používáme dva typy pro čas: UTCTime (tág 23) a GeneralisedTime (tág 24). Oba plníme časem
- 18. Bitový řetězec Řetězec bitů se zprava doplňuje výplní tak, aby jeho délka byla násobkem 8 (tj.
- 19. Identifikátory objektů
- 20. Identifikátory objektů
- 21. Identifikátory objektů
- 22. Identifikátory objektů - příklady Nové objekty se definují pomocí operátoru ::= . Např. objekt internet se
- 23. Kódování BER Identifikace objektu rsadsi vyjádřená ve složených závorkách je tedy {1.2.840.113549} . Při konverzi do
- 24. Kódujeme 840 jako následující číslo 84010= 11010010002, takže máme-li k dispozici pouze 7 bitů z každého
- 25. Kódujeme 113549 1135949 = 0000110 1110111 0001101 dvojkově (odděleno po sedmicích). První a duhou sedmici doplníme
- 26. Kódujeme {1.2.840.113549} První dvě čísla {1.2…} se kódují jako 2A (viz před-před-předchozí příklad). Další čísle je
- 27. Odvozené typy
- 28. Příklady implicitně odvozených typů Příklad 14.14: Určete typy pro šířku, výšku a hloubku tak, aby byly
- 29. Příklady – explicitně odvozené typy Příklad 14.16 (obdoba příkladu 14.14 pro explicitně odvozené typy): Jelikož explicitně
- 30. Odvozené typy
- 31. Speciální typ CHOICE CHOICE umožňuje výběr z několika variant v jazyce ASN.1. CHOICE se nokóduje!!!!!!!!!!!!!!!!!!! Např.
- 32. Speciální typ ANY Typ ANY označuje jakýkoliv typ. Příklad opět z certifikátu X.509: AlgorithmIdentifier ::= SEQUENCE
- 33. UTF-8 Unicode UCS-4 UCS-2 – též Basic Multilingual Plane (BMP).
- 34. UTF-8 UCS-4 rozsah (šestnáctkově) UTF-8 binárně 0000 0000-0000 007F 0xxxxxxx 0000 0080-0000 07FF 110xxxxx 10xxxxxx 0000
- 35. Příklad UCS-2 UCS-2 UTF-8 Název znaku (Unicode) binárně binárně UTF-8 Velké řecké písmeno ómega 03 A9
- 37. Скачать презентацию

ASN.1
Deklarace proměnných v programovacích jazycích
Typy:
Jednoduchý („vestavěný“) typ, který již dále není
ASN.1
Deklarace proměnných v programovacích jazycích
Typy:
Jednoduchý („vestavěný“) typ, který již dále není

Rodiny kódování
BER
DER
CER
PER - (Packet encoding rules). BER předpokládá, že kóduje zpráva,
Rodiny kódování
BER
DER
CER
PER - (Packet encoding rules). BER předpokládá, že kóduje zpráva,
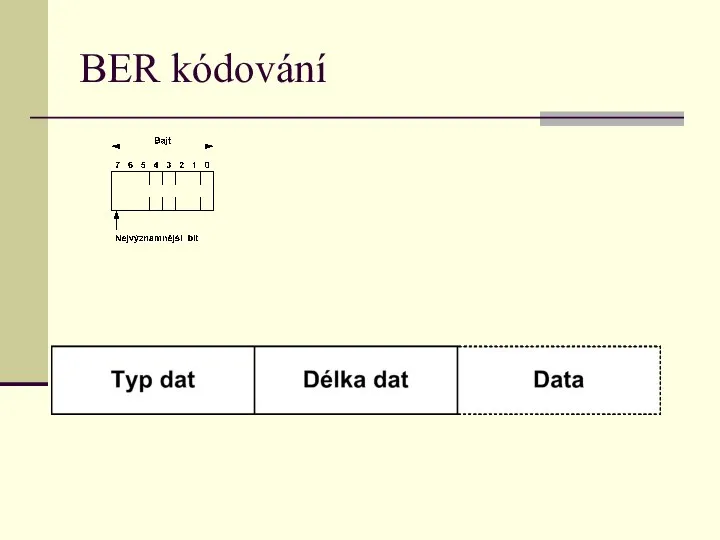
BER kódování
BER kódování
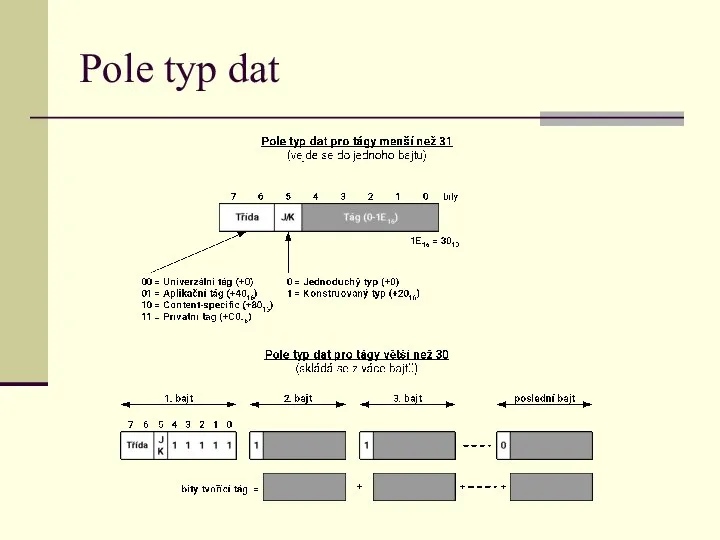
Pole typ dat
Pole typ dat

Univerzální typy
Tág Tág
Typ desítkově šestnáctkově Význam
END OF CONT. 0 0 Konec pole
Univerzální typy
Tág Tág
Typ desítkově šestnáctkově Význam
END OF CONT. 0 0 Konec pole
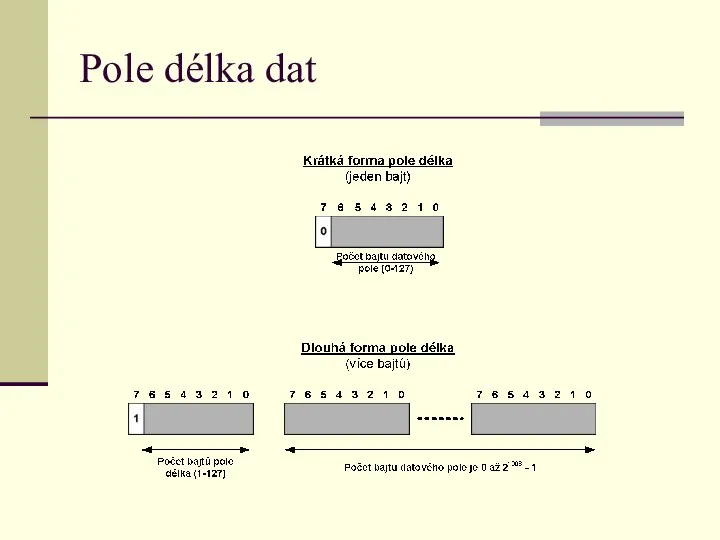
Pole délka dat
Pole délka dat

Příklad
V kódování BER vyjádřete jednu položku z
kartotéky zaměstnanců firmy kapitalista.cz.
Tato
Příklad
V kódování BER vyjádřete jednu položku z
kartotéky zaměstnanců firmy kapitalista.cz.
Tato

Příklad - pokračování
V ASN.1 se v praxi zápis Typu Zamestnanec píše
Příklad - pokračování
V ASN.1 se v praxi zápis Typu Zamestnanec píše

Příklad - dokončení
Takže konkrétní kartu v kódování BER pro zaměstnance:
Bobek
Příklad - dokončení
Takže konkrétní kartu v kódování BER pro zaměstnance:
Bobek

Program dumpasn1
Praktická ukázka
Program dumpasn1
Praktická ukázka

Prázdný typ
Prázdný typ se kóduje opět dle schématu:
tág (05), délka
Prázdný typ
Prázdný typ se kóduje opět dle schématu: tág (05), délka

BOOLEAN
Pravda se kóduje: 01 01 FF
Nepravda se kóduje: 01 01 00
BOOLEAN
Pravda se kóduje: 01 01 FF
Nepravda se kóduje: 01 01 00

INTEGER
Typ INTEGER se kóduje binárně tak, jak je to běžné, tj.
INTEGER
Typ INTEGER se kóduje binárně tak, jak je to běžné, tj.

Výčet
Pomocí typu INTEGER lze vytvořit výčet tak, že se jednotlivé hodnoty
Výčet
Pomocí typu INTEGER lze vytvořit výčet tak, že se jednotlivé hodnoty

SEQUENCE, SEQUENCE OF, SET a SET OF
Jedná se o strukturované
SEQUENCE, SEQUENCE OF, SET a SET OF
Jedná se o strukturované

Čas
Používáme dva typy pro čas: UTCTime (tág 23) a GeneralisedTime (tág
Čas
Používáme dva typy pro čas: UTCTime (tág 23) a GeneralisedTime (tág

Bitový řetězec
Řetězec bitů se zprava doplňuje výplní tak, aby jeho délka
Bitový řetězec
Řetězec bitů se zprava doplňuje výplní tak, aby jeho délka
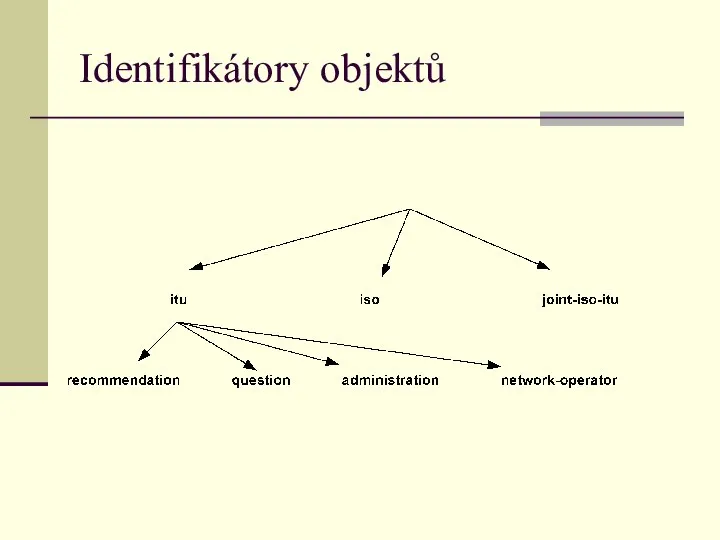
Identifikátory objektů
Identifikátory objektů
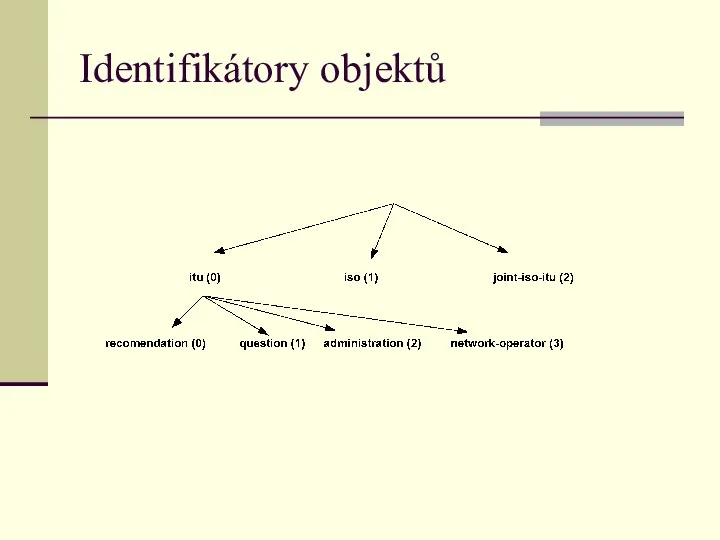
Identifikátory objektů
Identifikátory objektů
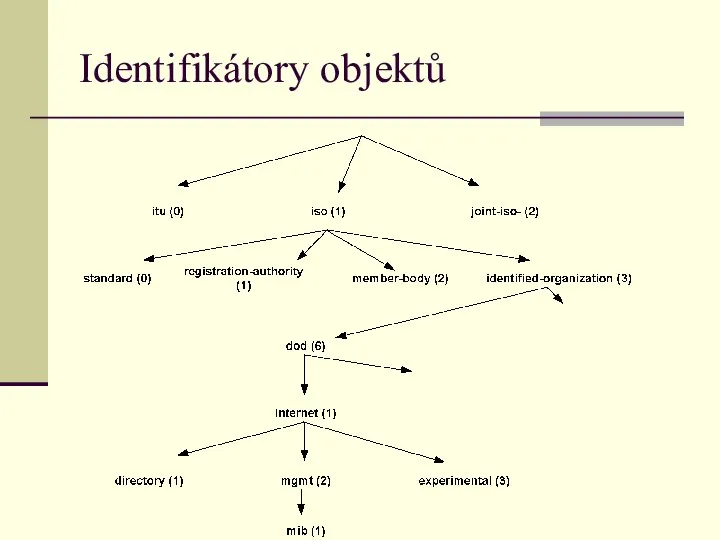
Identifikátory objektů
Identifikátory objektů

Identifikátory objektů - příklady
Nové objekty se definují pomocí operátoru ::= .
Identifikátory objektů - příklady
Nové objekty se definují pomocí operátoru ::= .

Kódování BER
Identifikace objektu rsadsi vyjádřená ve složených závorkách je tedy {1.2.840.113549}
Kódování BER
Identifikace objektu rsadsi vyjádřená ve složených závorkách je tedy {1.2.840.113549}

Kódujeme 840 jako následující číslo
84010= 11010010002, takže máme-li k dispozici pouze
Kódujeme 840 jako následující číslo
84010= 11010010002, takže máme-li k dispozici pouze

Kódujeme 113549
1135949 = 0000110 1110111 0001101 dvojkově (odděleno po sedmicích). První
Kódujeme 113549
1135949 = 0000110 1110111 0001101 dvojkově (odděleno po sedmicích). První

Kódujeme {1.2.840.113549}
První dvě čísla {1.2…} se kódují jako 2A (viz
Kódujeme {1.2.840.113549}
První dvě čísla {1.2…} se kódují jako 2A (viz
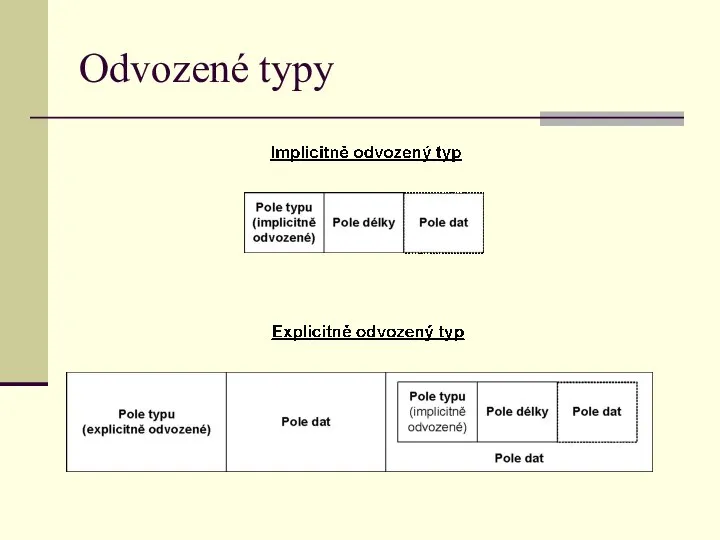
Odvozené typy
Odvozené typy

Příklady implicitně odvozených typů
Příklad 14.14:
Určete typy pro šířku, výšku a
Příklady implicitně odvozených typů
Příklad 14.14:
Určete typy pro šířku, výšku a

Příklady – explicitně odvozené typy
Příklad 14.16 (obdoba příkladu 14.14 pro explicitně
Příklady – explicitně odvozené typy
Příklad 14.16 (obdoba příkladu 14.14 pro explicitně
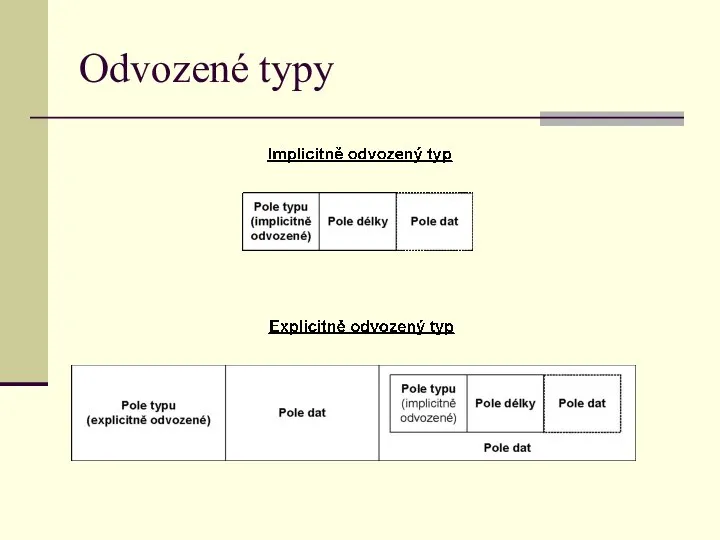
Odvozené typy
Odvozené typy

Speciální typ CHOICE
CHOICE umožňuje výběr z několika variant v jazyce ASN.1.
Speciální typ CHOICE
CHOICE umožňuje výběr z několika variant v jazyce ASN.1.

Speciální typ ANY
Typ ANY označuje jakýkoliv typ.
Příklad opět z certifikátu
Speciální typ ANY
Typ ANY označuje jakýkoliv typ.
Příklad opět z certifikátu

UTF-8
Unicode
UCS-4
UCS-2 – též Basic Multilingual Plane (BMP).
UTF-8
Unicode
UCS-4
UCS-2 – též Basic Multilingual Plane (BMP).

UTF-8
UCS-4 rozsah (šestnáctkově) UTF-8 binárně
0000 0000-0000 007F 0xxxxxxx
0000 0080-0000 07FF
UTF-8
UCS-4 rozsah (šestnáctkově) UTF-8 binárně
0000 0000-0000 007F 0xxxxxxx
0000 0080-0000 07FF
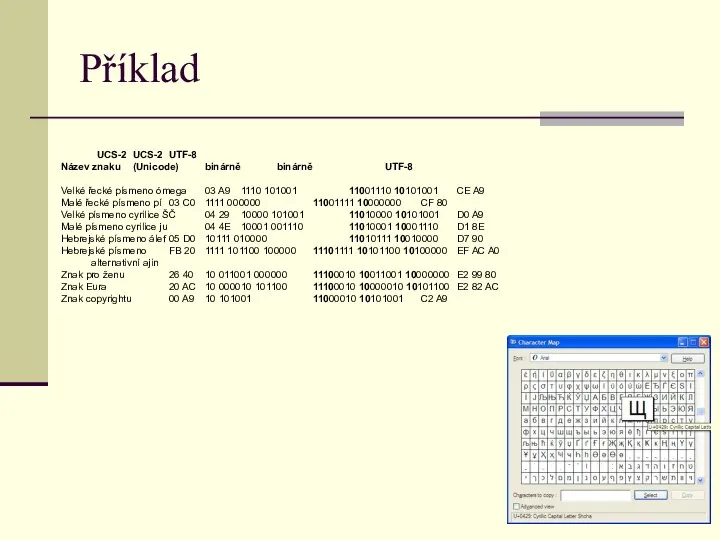
Příklad
UCS-2 UCS-2 UTF-8
Název znaku (Unicode) binárně binárně UTF-8
Velké řecké písmeno ómega 03
Příklad
UCS-2 UCS-2 UTF-8
Název znaku (Unicode) binárně binárně UTF-8
Velké řecké písmeno ómega 03
 Сегментно-страничная организация ячеек. Организация памяти
Сегментно-страничная организация ячеек. Организация памяти Различные способы распространения правовой информации, их достоинства и недостатки
Различные способы распространения правовой информации, их достоинства и недостатки Создание презентации с помощью шаблона оформления
Создание презентации с помощью шаблона оформления Методические принципы создания электронных учебников
Методические принципы создания электронных учебников ООП на Delphi – 10: Базы данных на Delphi
ООП на Delphi – 10: Базы данных на Delphi Потоки ОС Linux, Task Windows
Потоки ОС Linux, Task Windows Автоматизация процессов разработки веб-приложения
Автоматизация процессов разработки веб-приложения Презентация "Состав предметов и их действия Повторение" - скачать презентации по Информатике
Презентация "Состав предметов и их действия Повторение" - скачать презентации по Информатике Обеспечение качества аэронавигационных данных
Обеспечение качества аэронавигационных данных Корпоративный университет ОАО РЖД. Итоговое тестирование по курсу Внедрение проектного подхода в компании
Корпоративный университет ОАО РЖД. Итоговое тестирование по курсу Внедрение проектного подхода в компании Двоичное кодирование числовой информации
Двоичное кодирование числовой информации АЛГОРИТМЫ Способы представления алгоритмов
АЛГОРИТМЫ Способы представления алгоритмов Регламенты библиотечно-информационных технологий. (Лекция 5)
Регламенты библиотечно-информационных технологий. (Лекция 5) Анимации для web. GIF-анимации с помощью Corel Draw, Flash technology
Анимации для web. GIF-анимации с помощью Corel Draw, Flash technology Асинхронные и синхронные триггеры
Асинхронные и синхронные триггеры Как заполнить заявку на конкурс?
Как заполнить заявку на конкурс? Обзор программируемых логических интегральных схем и интегральных схем гибкой логики
Обзор программируемых логических интегральных схем и интегральных схем гибкой логики Криптография — одна из старейших наук
Криптография — одна из старейших наук Дети в интернете
Дети в интернете Подсистема Производство
Подсистема Производство Указатели и ссылки
Указатели и ссылки تررین پرترا جامع ترین و پرر ینننر ت اجتماعی کشور
تررین پرترا جامع ترین و پرر ینننر ت اجتماعی کشور Текстові величини. Програмування
Текстові величини. Програмування Как изменилась наша жизнь с появлением Интернета
Как изменилась наша жизнь с появлением Интернета Файлы и папки
Файлы и папки Системы автоматизированного проектирования (САПР)
Системы автоматизированного проектирования (САПР) Leasehold Conveyancing - Conversion Audit for graphics update_sanitized
Leasehold Conveyancing - Conversion Audit for graphics update_sanitized Разработка web-портала спортивной общественной организации
Разработка web-портала спортивной общественной организации