- Потоки ОС Linux, Task Windows

Содержание
- 2. Командный интерпретатор bash — это самая популярная командная оболочка (командный интерпретатор) Linux. Основное предназначение bash —
- 3. Типы файлов
- 4. Типы файлов Режим файла в Linux
- 5. Доступ к файлу Получить доступ к файлу могут: владелец файла (пользователь, создавший файл), группа владельца (пользователи,
- 6. Процессы Linux Linux — многозадачная система. Многозадачность построена на иерархии процессов. Всегда находится процесс, который запустит
- 7. Состояния процессов Linux Со временем модель трех состояний процессов усовершенствовалась и превратилась в модель пяти состояний.
- 8. Состояния процессов Linux Операции над процессами создание процесса — переход из состояния рождения в состояние готовности;
- 9. Состояния процессов Linux Представим, что наша программа вызвала системный вызов fork(). Этот системный вызов создает новый
- 10. Состояния процессов Linux Представим, что наша программа вызвала системный вызов fork(). Этот системный вызов создает новый
- 11. Состояния процессов Linux
- 12. Состояния процессов Linux Использование системного вызова wait(), который блокирует родительский процесс, пока не завершился дочерний
- 13. Состояния процессов Linux Каждый процесс может создать новый процесс, используя системный вызов fork(). С помощью системного
- 14. Потоки в Linux Как уже было сказано ранее, у каждого процесса есть свой идентификатор процесса (PID).
- 15. Потоки в Linux Ваша программа продолжает выполняться сразу после вызова функции pthread_create(). Основная программа не ждет
- 16. Потоки в Linux
- 17. Потоки в Linux Функция pthread_join() позволяет "подключиться" к потоку. Данную функцию можно вызвать, например, из основного
- 18. Потоки в Linux
- 19. Потоки в Linux Каналы бывают полудуплексными и полнодуплексными (каналы потоков). Полудуп лексные каналы позволяют обмениваться информацией
- 20. Потоки в Linux Каналы бывают полудуплексными и полнодуплексными (каналы потоков). Полудуп лексные каналы позволяют обмениваться информацией
- 21. Именованные каналы в Linux Следующий способ взаимодействия процессов — каналы FIFO (First In First Out). Такие
- 22. Именованные каналы в Linux sudo mknod FIFO p sudo mkfifo a=rw FIFO Обе команды создают канал
- 23. Именованные каналы в Linux
- 24. Семафоры Семафоры — это средство IPC (межпроцессное взаимодействие), управляющее доступом к общим ресурсам, например устройствам. Семафоры
- 25. Task Task- важная часть Task Parallel Library. Это легкий объект, который асинхронно управляет Task . Task
- 26. Task
- 27. Task Task mytask = new Task(actionMethod), где actionMethod actionMethod - это метод, который имеет тип возвращаемого
- 29. Скачать презентацию

Командный интерпретатор
bash — это самая популярная командная оболочка (командный интерпретатор)
Linux. Основное
Командный интерпретатор
bash — это самая популярная командная оболочка (командный интерпретатор)
Linux. Основное
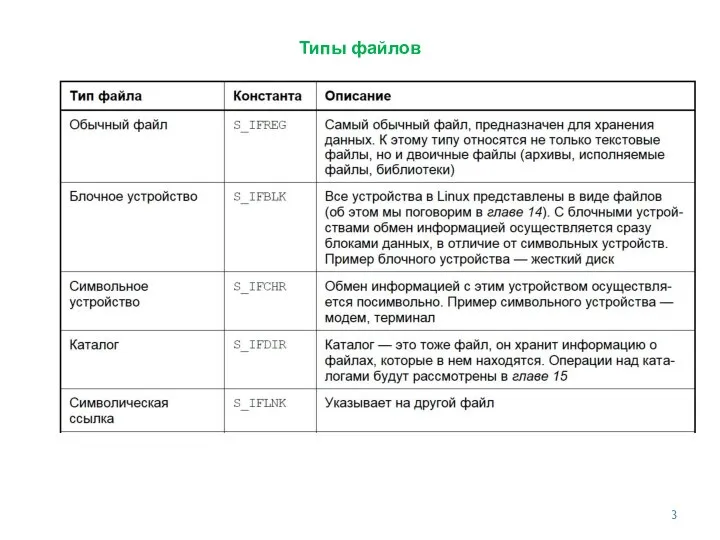
Типы файлов
Типы файлов
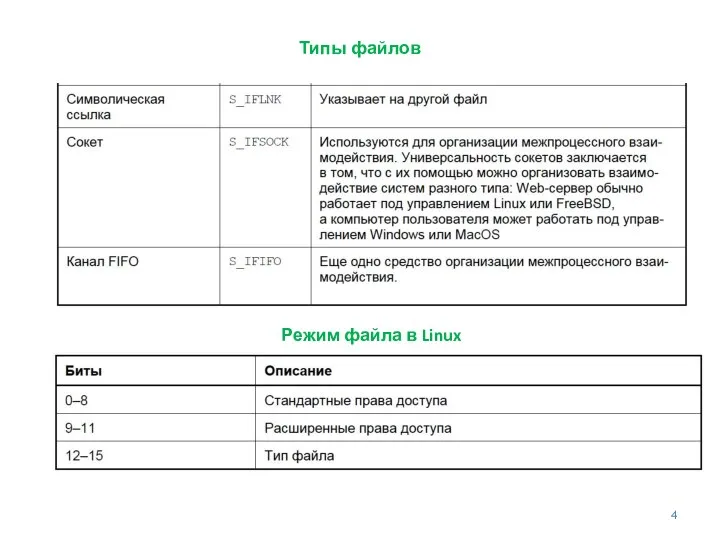
Типы файлов
Режим файла в Linux
Типы файлов
Режим файла в Linux

Доступ к файлу
Получить доступ к файлу могут: владелец файла (пользователь, создавший
Доступ к файлу
Получить доступ к файлу могут: владелец файла (пользователь, создавший

Процессы Linux
Linux — многозадачная система. Многозадачность построена на
иерархии процессов. Всегда находится
Процессы Linux
Linux — многозадачная система. Многозадачность построена на
иерархии процессов. Всегда находится

Состояния процессов Linux
Со временем модель трех состояний процессов усовершенствовалась и превратилась
Состояния процессов Linux
Со временем модель трех состояний процессов усовершенствовалась и превратилась

Состояния процессов Linux
Операции над процессами
создание процесса — переход из состояния рождения
Состояния процессов Linux
Операции над процессами
создание процесса — переход из состояния рождения

Состояния процессов Linux
Представим, что наша программа вызвала системный вызов fork(). Этот
Состояния процессов Linux
Представим, что наша программа вызвала системный вызов fork(). Этот

Состояния процессов Linux
Представим, что наша программа вызвала системный вызов fork(). Этот
Состояния процессов Linux
Представим, что наша программа вызвала системный вызов fork(). Этот

Состояния процессов Linux
Состояния процессов Linux

Состояния процессов Linux
Использование системного вызова wait(), который блокирует родительский процесс, пока
Состояния процессов Linux
Использование системного вызова wait(), который блокирует родительский процесс, пока

Состояния процессов Linux
Каждый процесс может создать новый процесс, используя
системный вызов fork().
Состояния процессов Linux
Каждый процесс может создать новый процесс, используя
системный вызов fork().

Потоки в Linux
Как уже было сказано ранее, у каждого процесса есть
Потоки в Linux
Как уже было сказано ранее, у каждого процесса есть

Потоки в Linux
Ваша программа продолжает выполняться сразу после вызова функции
pthread_create(). Основная
Потоки в Linux
Ваша программа продолжает выполняться сразу после вызова функции
pthread_create(). Основная

Потоки в Linux
Потоки в Linux

Потоки в Linux
Функция pthread_join() позволяет "подключиться" к потоку. Данную функцию
можно вызвать,
Потоки в Linux
Функция pthread_join() позволяет "подключиться" к потоку. Данную функцию
можно вызвать,

Потоки в Linux
Потоки в Linux

Потоки в Linux
Каналы бывают полудуплексными и полнодуплексными (каналы потоков). Полудуп
лексные каналы
Потоки в Linux
Каналы бывают полудуплексными и полнодуплексными (каналы потоков). Полудуп
лексные каналы

Потоки в Linux
Каналы бывают полудуплексными и полнодуплексными (каналы потоков). Полудуп
лексные каналы
Потоки в Linux
Каналы бывают полудуплексными и полнодуплексными (каналы потоков). Полудуп
лексные каналы

Именованные каналы в Linux
Следующий способ взаимодействия процессов — каналы FIFO (First
Именованные каналы в Linux
Следующий способ взаимодействия процессов — каналы FIFO (First

Именованные каналы в Linux
sudo mknod FIFO p
sudo mkfifo a=rw FIFO
Обе команды
Именованные каналы в Linux
sudo mknod FIFO p
sudo mkfifo a=rw FIFO
Обе команды

Именованные каналы в Linux
Именованные каналы в Linux

Семафоры
Семафоры — это средство IPC (межпроцессное взаимодействие), управляющее доступом к общим
Семафоры
Семафоры — это средство IPC (межпроцессное взаимодействие), управляющее доступом к общим

Task
Task- важная часть Task Parallel Library. Это легкий объект, который асинхронно
управляет
Task
Task- важная часть Task Parallel Library. Это легкий объект, который асинхронно
управляет

Task
Task

Task
Task mytask = new Task(actionMethod),
где
actionMethod actionMethod - это метод, который имеет
Task
Task mytask = new Task(actionMethod),
где
actionMethod actionMethod - это метод, который имеет
 Проект Выполнили: Макаров П. Михайлов А. Бирюков Е. Руководитель проекта: Сарапкина М.М.
Проект Выполнили: Макаров П. Михайлов А. Бирюков Е. Руководитель проекта: Сарапкина М.М.  Презентация "Игра" - скачать презентации по Информатике
Презентация "Игра" - скачать презентации по Информатике Виды и способы мошенничества в сети интернет
Виды и способы мошенничества в сети интернет Относительные, абсолютные и смешанные ссылки в MS Excel
Относительные, абсолютные и смешанные ссылки в MS Excel Электронные таблицы. Встроенные функции
Электронные таблицы. Встроенные функции Информационные технологии в журналистике Выполнила: Вера Букина, ИФиЯК
Информационные технологии в журналистике Выполнила: Вера Букина, ИФиЯК Управление доступом к базе данных. (Лекция 4)
Управление доступом к базе данных. (Лекция 4) Введение в СУБД ORACLE. Лекция 1
Введение в СУБД ORACLE. Лекция 1 Модель памяти в языке С. Функции в языке С. Функции в ассемблере
Модель памяти в языке С. Функции в языке С. Функции в ассемблере Система счисления
Система счисления Тестирование ПК и основных устройств
Тестирование ПК и основных устройств Библиографическое описание документов
Библиографическое описание документов Проблемы проектирования инфокоммуникационных систем и сетей NGN и пост-NGN. (Лекции 1-2)
Проблемы проектирования инфокоммуникационных систем и сетей NGN и пост-NGN. (Лекции 1-2) Полезные приложения для телефона
Полезные приложения для телефона Согласование требований заказчика
Согласование требований заказчика Алгоритм. Свойства алгоритмов. Исполнители
Алгоритм. Свойства алгоритмов. Исполнители Pre-Order и Целевые запасы
Pre-Order и Целевые запасы Архитектура_компьютерных_систем_ПК350_Исаев А. Н._05.09.2022 (1)
Архитектура_компьютерных_систем_ПК350_Исаев А. Н._05.09.2022 (1) Знакомство с языками программирования. Начальные сведения о Паскале
Знакомство с языками программирования. Начальные сведения о Паскале Формат JPEG2000
Формат JPEG2000 Устройства ввода и вывода информации
Устройства ввода и вывода информации Табличные информационные модели. Типы таблиц. Решение логических задач
Табличные информационные модели. Типы таблиц. Решение логических задач Создание простейших анимаций в среде Macromedia Flash 7.0
Создание простейших анимаций в среде Macromedia Flash 7.0 資訊法律與個資
資訊法律與個資 Лекция № 1 Введение в информационные технологии
Лекция № 1 Введение в информационные технологии Запросы на выборку данных
Запросы на выборку данных Обработка графической информации формирование изображения на экране монитора
Обработка графической информации формирование изображения на экране монитора Операционная система Программное обеспечение _
Операционная система Программное обеспечение _