- Графические процессоры для расчетов общего назначения

Содержание
- 2. Эволюция графических процессоров (1) ГПУ 1го поколения (середина 90х) До этого все операции с графикой выполнялись
- 3. Первые ГПУ обеспечивали растеризацию (перевод треугольников в массивы пикселей), поддержку буфера глубины, наложения текстур и альфа-блендинга
- 4. Первые шейдеры не могли иметь длину больше 20 команд, не поддерживались команды переходов, возможность вычислений только
- 5. ГПУ 3го поколения (c 2005 по настоящее время) Характеризуются расширенными возможностями программирования. Появляются операции ветвления и
- 6. Почему ГПУ ? (1) Почему ОВГПУ активно развивается, хотя программирование ГПУ существенно отличается от традиционного программирования
- 7. Средства программирования ГПУ Сегодня графический ускоритель – гибко программируемый массивно-параллельный процессор с высокой производительностью и пропускной
- 8. OpenGL – спецификация, определяющая платформо-независимый программный интерфейс для написания приложений, использующих двумерную и трёхмерную компьютерную графику.
- 9. OpenCL: первый открытый межплатформенный стандарт для параллельных вычислений на современных процессорах (включая многоядерные и графические), доступных
- 10. Технология CUDA: зачем? (1) CUDA (Compute Unified Device Architecture) — технология GPGPU (General-Purpose computing on Graphics
- 11. Технология CUDA: зачем? (2) Специализированные устройства для параллельных векторных вычислений, используемых в 3D-графике, достигают высокой пиковой
- 12. CUDA: общие положения (1) GPU (device) – сопроцессор для CPU (хоста) У GPU есть собственная память
- 13. CUDA: общие положения (2) Общая схема кода: Выделяется общая память на ГПУ Копируются необходимые данные из
- 14. Первая реализация CUDA была представлена в 2007. Технология предоставляла возможность программистам создавать ГПУ-приложения, пользуясь С-подобным языком.
- 15. CUDA: Основы создания программ (1) Первый шаг при переносе существующего приложения на CUDA – определение участков
- 16. CUDA: Основы создания программ (2) Каждый SM состоит из восьми и более ядер — потоковых процессоров,
- 17. CUDA: Модель памяти (1) Модель памяти в CUDA отличается возможностью побайтной адресации. Доступно до 1024 регистров
- 18. CUDA: Модель памяти (2) Память констант: область памяти (64 килобайт), доступная только для чтения всеми МП.
- 19. CUDA: спецификаторы Спецификаторы функций __device__ (выполняется на ГПУ, вызывается из ГПУ) __global__ (выполняется на ГПУ, вызывается
- 20. CUDA: добавленные типы и функции Добавленные типы: 1\2\3\4-мерные векторы базовых типов. Специальные переменные: gridDim (размер сетки);
- 21. __global__ void kernel (float *a, float *b, float *c) { // глобальный индекс нити Int idx
- 22. Resumé Cuda строится на концепции, что GPU выступает в роли массивно-параллельного сопроцессора к CPU. Cuda-код задействует
- 23. Podgainy D.V., Presentation on 41st PAC, 22/01/2015
- 25. Скачать презентацию

Эволюция графических процессоров (1)
ГПУ 1го поколения (середина 90х)
До этого все
Эволюция графических процессоров (1)
ГПУ 1го поколения (середина 90х)
До этого все

Первые ГПУ обеспечивали растеризацию (перевод треугольников в массивы пикселей), поддержку буфера
Первые ГПУ обеспечивали растеризацию (перевод треугольников в массивы пикселей), поддержку буфера

Первые шейдеры не могли иметь длину больше 20 команд, не поддерживались
Первые шейдеры не могли иметь длину больше 20 команд, не поддерживались

ГПУ 3го поколения (c 2005 по настоящее время)
Характеризуются расширенными возможностями программирования.
ГПУ 3го поколения (c 2005 по настоящее время)
Характеризуются расширенными возможностями программирования.

Почему ГПУ ? (1)
Почему ОВГПУ активно развивается, хотя программирование ГПУ существенно
Почему ГПУ ? (1)
Почему ОВГПУ активно развивается, хотя программирование ГПУ существенно

Средства
программирования ГПУ
Сегодня графический ускоритель – гибко программируемый массивно-параллельный процессор
Средства
программирования ГПУ
Сегодня графический ускоритель – гибко программируемый массивно-параллельный процессор

OpenGL – спецификация, определяющая платформо-независимый программный интерфейс для написания приложений, использующих двумерную
OpenGL – спецификация, определяющая платформо-независимый программный интерфейс для написания приложений, использующих двумерную

OpenCL: первый открытый межплатформенный стандарт для параллельных вычислений на современных процессорах
OpenCL: первый открытый межплатформенный стандарт для параллельных вычислений на современных процессорах

Технология CUDA: зачем? (1)
CUDA (Compute Unified Device Architecture) — технология GPGPU (General-Purpose
Технология CUDA: зачем? (1)
CUDA (Compute Unified Device Architecture) — технология GPGPU (General-Purpose
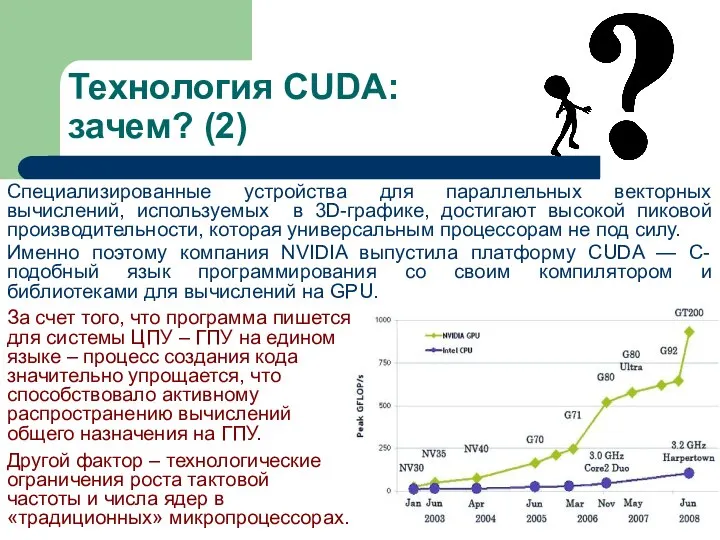
Технология CUDA:
зачем? (2)
Специализированные устройства для параллельных векторных вычислений, используемых
Технология CUDA:
зачем? (2)
Специализированные устройства для параллельных векторных вычислений, используемых

CUDA: общие положения (1)
GPU (device) – сопроцессор для CPU (хоста)
CUDA: общие положения (1)
GPU (device) – сопроцессор для CPU (хоста)

CUDA: общие положения (2)
Общая схема кода:
Выделяется общая память на ГПУ
Копируются необходимые
CUDA: общие положения (2)
Общая схема кода:
Выделяется общая память на ГПУ
Копируются необходимые

Первая реализация CUDA была представлена в 2007. Технология предоставляла возможность программистам
Первая реализация CUDA была представлена в 2007. Технология предоставляла возможность программистам

CUDA: Основы создания программ (1)
Первый шаг при переносе существующего приложения
CUDA: Основы создания программ (1)
Первый шаг при переносе существующего приложения

CUDA: Основы создания программ (2)
Каждый SM состоит из восьми и более
CUDA: Основы создания программ (2)
Каждый SM состоит из восьми и более

CUDA: Модель памяти (1)
Модель памяти в CUDA отличается возможностью побайтной адресации.
CUDA: Модель памяти (1)
Модель памяти в CUDA отличается возможностью побайтной адресации.

CUDA: Модель памяти (2)
Память констант: область памяти (64 килобайт), доступная только
CUDA: Модель памяти (2)
Память констант: область памяти (64 килобайт), доступная только

CUDA:
спецификаторы
Спецификаторы функций
__device__ (выполняется на ГПУ, вызывается из ГПУ)
__global__ (выполняется на ГПУ,
CUDA:
спецификаторы
Спецификаторы функций
__device__ (выполняется на ГПУ, вызывается из ГПУ)
__global__ (выполняется на ГПУ,

CUDA:
добавленные типы и функции
Добавленные типы: 1\2\3\4-мерные векторы базовых типов.
Специальные переменные:
gridDim (размер
CUDA:
добавленные типы и функции
Добавленные типы: 1\2\3\4-мерные векторы базовых типов.
Специальные переменные:
gridDim (размер

__global__ void kernel (float *a, float *b, float *c)
{
// глобальный индекс
__global__ void kernel (float *a, float *b, float *c)
{
// глобальный индекс

Resumé
Cuda строится на концепции, что GPU выступает в роли массивно-параллельного сопроцессора
Resumé
Cuda строится на концепции, что GPU выступает в роли массивно-параллельного сопроцессора
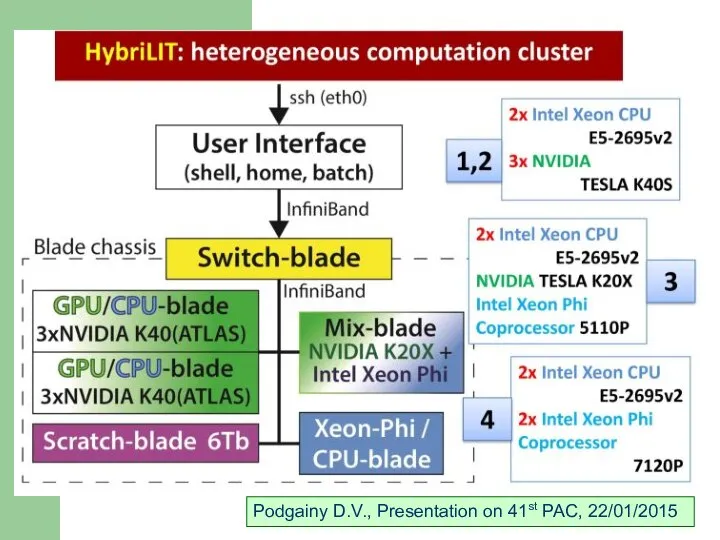
Podgainy D.V., Presentation on 41st PAC, 22/01/2015
Podgainy D.V., Presentation on 41st PAC, 22/01/2015
 Магистрально-модульный принцип построения компьютера
Магистрально-модульный принцип построения компьютера Данные в ячейках таблицы. Основные режимы работы электронных таблиц
Данные в ячейках таблицы. Основные режимы работы электронных таблиц Code. Routing
Code. Routing Графический редактор Paint
Графический редактор Paint Устройство и функционирование информационных систем. Теоретические основы проектирования ИС. Жизненный цикл ИС
Устройство и функционирование информационных систем. Теоретические основы проектирования ИС. Жизненный цикл ИС Атняшева Гульнария Борисовна Учитель математики и информатики МБОУ «Канабековская ООШ» с.Канабеки г. Лысьва Пермский край
Атняшева Гульнария Борисовна Учитель математики и информатики МБОУ «Канабековская ООШ» с.Канабеки г. Лысьва Пермский край Базы данных. Access 2007
Базы данных. Access 2007 Информация и информационные процессы (10 класс)
Информация и информационные процессы (10 класс) Моделирование
Моделирование Некоторые алгоритмы для массивов. Методы сортировки. Операции над матрицами
Некоторые алгоритмы для массивов. Методы сортировки. Операции над матрицами Мир без Интернета
Мир без Интернета Основные сведения при работе с MS Excel
Основные сведения при работе с MS Excel Адреса узлов в сетях. Организация имен в интернете
Адреса узлов в сетях. Организация имен в интернете Особенности ведения предпринимательской деятельности в сети Интернет. Понятие электронной оферты и акцепта. Заключение договора
Особенности ведения предпринимательской деятельности в сети Интернет. Понятие электронной оферты и акцепта. Заключение договора Протоколы взаимодействия открытых систем
Протоколы взаимодействия открытых систем Решение логических задач табличным способом
Решение логических задач табличным способом Введение в программную инженерию. От программирования к программной инженерии
Введение в программную инженерию. От программирования к программной инженерии Использование социальных сетей для обмена ботаническими данными и представления результатов научно-исследовательских работ
Использование социальных сетей для обмена ботаническими данными и представления результатов научно-исследовательских работ Ограничение и сортировка данных
Ограничение и сортировка данных BlackBerry OS Компания Research In Motion Limited (RIM).
BlackBerry OS Компания Research In Motion Limited (RIM). Юджин Гарфилд - создатель Science Citation Index (Web of Science )
Юджин Гарфилд - создатель Science Citation Index (Web of Science ) Фирменный бланк организации
Фирменный бланк организации Распараллеливание на компьютерах с общей памятью
Распараллеливание на компьютерах с общей памятью Информационные ресурсы интернета. Электронная почта
Информационные ресурсы интернета. Электронная почта Методы проектирования баз данных
Методы проектирования баз данных Графический редактор Adobe Photoshop
Графический редактор Adobe Photoshop Динамическая идентификация типа ООП
Динамическая идентификация типа ООП Автоматизированная обработка информации
Автоматизированная обработка информации