- Хэш - функции (лекция 7)

Содержание
- 2. Криптографическая хэш-функция h — это функция, определенная на битовых строках произвольной длины со значениями строк битов
- 3. В криптографии хэш-функции применяются для задач: — построения систем контроля целостности данных при их передаче или
- 4. При решении второй задачи - аутентификации источника данных, обмен данными происходит между не доверяющими друг другу
- 5. Классификация хэш-функций Криптографические хэш-функции разделяются на два класса: - хэш-функции без ключа (MDC (Modification (Manipulation) Detect
- 6. Схема Меркеля – Дамгарда Наиболее распространенной криптографической функцией хэширования на основе одношаговой функции сжатия является итеративная
- 7. Последовательная процедура вычисления свертки: Н0 = v Нi = f (Mi , Hi-1 ) (*) h(M)
- 8. Ключевые хэш-функции Используются алгоритмы блочного шифрования в Н0 = 0 Нi = Ek (Mi xor Hi-1
- 10. Бесключевые хэш-функции Большинство известных бесключевых ХФ основано на разбиении произвольно длинных сообщений на блоки фиксированной длины
- 12. Требования к хэш-функциям Хэш-функция Н должна применяться к блоку данных любой длины. Хэш-функция Н создает выход
- 13. Первые три свойства требуют, чтобы хэш-функция создавала хэш-код для любого сообщения. Четвертое свойство определяет требование односторонности
- 14. Пятое свойство гарантирует, что невозможно найти другое сообщение, чье значение хэш-функции совпадало бы со значением хэш-функции
- 15. Не доказано существование необратимых хэш-функций, для которых вычисление какого-либо прообраза заданного значения хэш-функции теоретически невозможно. Обычно
- 16. Простейшая хеш-функция может быть составлена с использованием операции "сумма по модулю 2" следующим образом: получаем входную
- 17. Однако такую хеш-функцию нельзя использовать для криптографических целей, например для формирования электронной подписи, так как достаточно
- 18. Контрольные суммы Алгоритм вычисления контрольной суммы (CRC, cyclic redundancy check, проверка избыточности циклической суммы) — способ
- 19. Циклический избыточный код CRC (Cyclic redundancy code) Алгоритм CRC базируется на свойствах деления с остатком двоичных
- 21. В зависимости от вида порождающего многочлена и его длины, изменяется вероятность совпадения контрольных сумм для различных
- 22. Коллизии Коллизией хеш-функции называется два различных входных блока данных х и у таких, что Коллизии существуют
- 24. Использование коллизий для взлома В качестве примера можно рассмотреть простую процедуру аутентификации пользователя: при регистрации в
- 25. Защита от использования коллизий Существует ряд методов защиты от взломаСуществует ряд методов защиты от взлома, защиты
- 26. Методы поиска коллизий Атака «дней рождения» позволяет находить коллизии для хеш-функции с длиной значений n битов
- 27. Применяя так называемый "парадокс дня рождения" к слабым-хэш функциям формулируется следующая задача: Предположим, количество выходных значений
- 29. Хэш-функция SHA-1 Алгоритм получает на входе сообщение максимальной длины 264 бит и создает в качестве выхода
- 30. Шаг 1: добавление недостающих битов Сообщение добавляется таким образом, чтобы его длина была кратна 448 по
- 31. Шаг 3: инициализация SHA-1 буфера Используется 160-битный буфер для хранения промежуточных и окончательных результатов хэш-функции. Буфер
- 32. Шаг 4: обработка сообщения в 512-битных (16-словных) блоках Основой алгоритма является модуль, состоящий из 80 циклических
- 33. В каждом цикле используется дополнительная константа Кt, Для получения SHAq+1 выход 80-го цикла складывается со значением
- 34. Рассмотрим более детально логику в каждом из 80 циклов обработки одного 512-битного блока. Каждый цикл можно
- 36. 32-битные слова Wt получаются из очередного 512-битного блока сообщения следующим образом. Wt= Yt , при t
- 37. Алгоритм SHA-1 можно суммировать следующим образом: SHA0 = IV SHAq+1 = Σ32 (SHAq , ABCDEq )
- 38. MD5
- 39. ГОСТ Р 34.11 — 2012 Размер хеша: 256 или 512 бит Размер блока входных данных: 512
- 40. В основу хеш-функции положена итерационная конструкция Меркла-Дамгарда с использованием MD-усиления. Под MD-усилением понимается дополнение неполного блока
- 43. Скачать презентацию

Криптографическая хэш-функция h — это функция, определенная на битовых строках произвольной
Криптографическая хэш-функция h — это функция, определенная на битовых строках произвольной

В криптографии хэш-функции применяются для задач:
— построения систем контроля целостности данных
В криптографии хэш-функции применяются для задач:
— построения систем контроля целостности данных

При решении второй задачи - аутентификации источника данных, обмен данными происходит
При решении второй задачи - аутентификации источника данных, обмен данными происходит

Классификация хэш-функций
Криптографические хэш-функции разделяются на два класса:
- хэш-функции без ключа
Классификация хэш-функций
Криптографические хэш-функции разделяются на два класса:
- хэш-функции без ключа

Схема Меркеля – Дамгарда
Наиболее распространенной криптографической функцией хэширования на основе одношаговой
Схема Меркеля – Дамгарда
Наиболее распространенной криптографической функцией хэширования на основе одношаговой

Последовательная процедура вычисления свертки: Н0 = v
Нi = f
Последовательная процедура вычисления свертки: Н0 = v
Нi = f

Ключевые хэш-функции
Используются алгоритмы блочного шифрования в
Н0 = 0
Нi
Ключевые хэш-функции
Используются алгоритмы блочного шифрования в
Н0 = 0
Нi


Бесключевые хэш-функции
Большинство известных бесключевых ХФ основано на разбиении произвольно длинных сообщений
Бесключевые хэш-функции
Большинство известных бесключевых ХФ основано на разбиении произвольно длинных сообщений


Требования к хэш-функциям
Хэш-функция Н должна применяться к блоку данных любой длины.
Хэш-функция Н создает
Требования к хэш-функциям
Хэш-функция Н должна применяться к блоку данных любой длины.
Хэш-функция Н создает

Первые три свойства требуют, чтобы хэш-функция создавала хэш-код для любого сообщения.
Четвертое свойство определяет требование односторонности хэш-функции:
Первые три свойства требуют, чтобы хэш-функция создавала хэш-код для любого сообщения.
Четвертое свойство определяет требование односторонности хэш-функции:

Пятое свойство гарантирует, что невозможно найти другое сообщение, чье значение хэш-функции совпадало бы
Пятое свойство гарантирует, что невозможно найти другое сообщение, чье значение хэш-функции совпадало бы

Не доказано существование необратимых хэш-функций, для которых вычисление какого-либо прообраза заданного
Не доказано существование необратимых хэш-функций, для которых вычисление какого-либо прообраза заданного

Простейшая хеш-функция может быть составлена с использованием операции "сумма по модулю
Простейшая хеш-функция может быть составлена с использованием операции "сумма по модулю

Однако такую хеш-функцию нельзя использовать для криптографических целей, например для формирования
Однако такую хеш-функцию нельзя использовать для криптографических целей, например для формирования

Контрольные суммы
Алгоритм вычисления контрольной суммы (CRC, cyclic redundancy check, проверка избыточности циклической суммы)
Контрольные суммы
Алгоритм вычисления контрольной суммы (CRC, cyclic redundancy check, проверка избыточности циклической суммы)

Циклический избыточный код CRC (Cyclic redundancy code)
Алгоритм CRC базируется на свойствах
Циклический избыточный код CRC (Cyclic redundancy code)
Алгоритм CRC базируется на свойствах


В зависимости от вида порождающего многочлена и его длины, изменяется вероятность
В зависимости от вида порождающего многочлена и его длины, изменяется вероятность

Коллизии
Коллизией хеш-функции называется два различных входных блока данных х и у таких, что
Коллизии
Коллизии
Коллизией хеш-функции называется два различных входных блока данных х и у таких, что
Коллизии


Использование коллизий для взлома
В качестве примера можно рассмотреть простую процедуру аутентификации пользователя:
при регистрации
Использование коллизий для взлома
В качестве примера можно рассмотреть простую процедуру аутентификации пользователя:
при регистрации

Защита от использования коллизий
Существует ряд методов защиты от взломаСуществует ряд методов защиты
Защита от использования коллизий
Существует ряд методов защиты от взломаСуществует ряд методов защиты

Методы поиска коллизий
Атака «дней рождения» позволяет находить коллизии для хеш-функции с
Методы поиска коллизий
Атака «дней рождения» позволяет находить коллизии для хеш-функции с

Применяя так называемый "парадокс дня рождения" к слабым-хэш функциям формулируется следующая
Применяя так называемый "парадокс дня рождения" к слабым-хэш функциям формулируется следующая

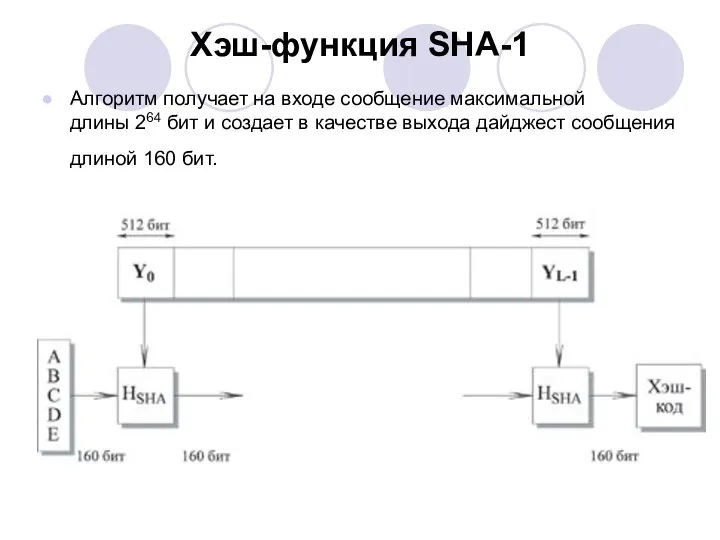
Хэш-функция SHA-1
Алгоритм получает на входе сообщение максимальной длины 264 бит и создает в
Хэш-функция SHA-1
Алгоритм получает на входе сообщение максимальной длины 264 бит и создает в

Шаг 1: добавление недостающих битов
Сообщение добавляется таким образом, чтобы его длина
Шаг 1: добавление недостающих битов
Сообщение добавляется таким образом, чтобы его длина

Шаг 3: инициализация SHA-1 буфера
Используется 160-битный буфер для хранения промежуточных и
Шаг 3: инициализация SHA-1 буфера
Используется 160-битный буфер для хранения промежуточных и

Шаг 4: обработка сообщения в 512-битных (16-словных) блоках
Основой алгоритма является модуль,
Шаг 4: обработка сообщения в 512-битных (16-словных) блоках
Основой алгоритма является модуль,

В каждом цикле используется дополнительная константа Кt,
Для получения SHAq+1 выход 80-го цикла складывается
В каждом цикле используется дополнительная константа Кt,
Для получения SHAq+1 выход 80-го цикла складывается

Рассмотрим более детально логику в каждом из 80 циклов обработки одного
Рассмотрим более детально логику в каждом из 80 циклов обработки одного


32-битные слова Wt получаются из очередного 512-битного блока сообщения следующим образом.
Wt= Yt ,
32-битные слова Wt получаются из очередного 512-битного блока сообщения следующим образом.
Wt= Yt ,

Алгоритм SHA-1 можно суммировать следующим образом:
SHA0 = IV
SHAq+1 = Σ32 (SHAq ,
Алгоритм SHA-1 можно суммировать следующим образом:
SHA0 = IV
SHAq+1 = Σ32 (SHAq ,

MD5
MD5

ГОСТ Р 34.11 — 2012
Размер хеша: 256 или 512 бит
Размер блока входных
ГОСТ Р 34.11 — 2012
Размер хеша: 256 или 512 бит
Размер блока входных

В основу хеш-функции положена итерационная конструкция Меркла-Дамгарда с использованием MD-усиления. Под MD-усилением понимается
В основу хеш-функции положена итерационная конструкция Меркла-Дамгарда с использованием MD-усиления. Под MD-усилением понимается

 Компьютерная грамотность и информационная культура
Компьютерная грамотность и информационная культура Алгоритм построения суффиксного дерева с учетом замечаний
Алгоритм построения суффиксного дерева с учетом замечаний Расчет количества модулей для установок порошкового пожаротушения с помощью табличного процессора MS Excel
Расчет количества модулей для установок порошкового пожаротушения с помощью табличного процессора MS Excel МегаТекст. Как писать интересные посты в социальных сетях?
МегаТекст. Как писать интересные посты в социальных сетях? Общие сведения о сети интернет Лекция 1
Общие сведения о сети интернет Лекция 1 Презентация "Поиск в базе данных MS ACCESS 2007" - скачать презентации по Информатике
Презентация "Поиск в базе данных MS ACCESS 2007" - скачать презентации по Информатике Некоторые элементарные приёмы теории графов при решении отдельных задач Автор: Корбу Наталья Александровна
Некоторые элементарные приёмы теории графов при решении отдельных задач Автор: Корбу Наталья Александровна  IX Межрегиональный ИТ-Форум. Электронные учебники для начальной школы
IX Межрегиональный ИТ-Форум. Электронные учебники для начальной школы Интернет как сфера распространения идеологии терроризма
Интернет как сфера распространения идеологии терроризма Проектирование корпоративных информационных систем
Проектирование корпоративных информационных систем Prezentatsia_4 (1)
Prezentatsia_4 (1) Программирование на языке С++
Программирование на языке С++ Архитектура ЭВМ. Компьютерная организация
Архитектура ЭВМ. Компьютерная организация Работа в MS Visio 2016. Связывание данных со схемами (часть 3)
Работа в MS Visio 2016. Связывание данных со схемами (часть 3) Объектно-ориентированное программирование (ООП)
Объектно-ориентированное программирование (ООП) Создание и редактирование текстового документа 8 класс
Создание и редактирование текстового документа 8 класс Безпека в Інтернеті
Безпека в Інтернеті Правила поведения при наводнении
Правила поведения при наводнении STM32WL MCU series беспроводная система-на-кристалле
STM32WL MCU series беспроводная система-на-кристалле Текстовый редактор Word. Вставка графических объектов в текстовый документ
Текстовый редактор Word. Вставка графических объектов в текстовый документ Почему мне надо купить ноутбук MSI
Почему мне надо купить ноутбук MSI Средства информационных и коммуникационных технологий. Программное обеспечение персонального компьютера
Средства информационных и коммуникационных технологий. Программное обеспечение персонального компьютера Презентация "ОС Windows" - скачать презентации по Информатике
Презентация "ОС Windows" - скачать презентации по Информатике Работа в MS Office 365. Лабораторная работа 3
Работа в MS Office 365. Лабораторная работа 3 ИКТ компетентность в рамках современного урока
ИКТ компетентность в рамках современного урока WebMaster
WebMaster Введение в программную инженерию
Введение в программную инженерию СПАМ И защита от него
СПАМ И защита от него