- Исследование метода аутентификации двоичных изображений при помощи технологии ЦВЗ

Содержание
- 2. Идея метода Разделяем двоичное изображение (ДИ) на блоки 3х3 пикселя X = (xij) 1≤i, j ≤3,
- 3. Формируем RSU-последовательность σ и назначаем R-область 1, S-область 0, U-область – nil Удаляем из последовательности nil-области
- 4. Проверка подлинности Дано ДИ с вложенным MAC. Формируем RSU-последовательность и назначаем 1, 0 и nil, как
- 5. Арифметическое кодирование Арифметическое кодирование (Arithmetic coding) — алгоритм сжатия информации без потерь, который при кодировании ставит
- 6. Кодирование Рассмотрим отрезок [0,1) на координатной прямой Поставим каждому символу текста в соответствие отрезок, длина которого
- 7. Декодирование Выберем на отрезке [0, 1), разделенном на части, длины которых равны вероятностям появления символов в
- 8. Результаты исследования NR,NS NU – количество R,S U областей соответственно NT = NR+NS
- 10. Выводы по таблице АК дает нам достаточно места для аутентификатора Меньше всего подходят для вложений пёстрые
- 11. Текстурность изображения n1, n2 – размер изображения - область 2х2 пикселя, где ij – координаты области,
- 12. Итоги Изучено арифметическое кодирование. Реализован адаптивный кодер на Java Произведен расчет количества R, S и U
- 13. Перспективы Реализация добавления аутентификатора к двоичному изображению Улучшение метода Установление связи между параметрами изображения и его
- 15. Скачать презентацию

Идея метода
Разделяем двоичное изображение (ДИ) на блоки 3х3 пикселя X =
Идея метода
Разделяем двоичное изображение (ДИ) на блоки 3х3 пикселя X =

Формируем RSU-последовательность σ и назначаем R-область 1, S-область 0, U-область –
Формируем RSU-последовательность σ и назначаем R-область 1, S-область 0, U-область –

Проверка подлинности
Дано ДИ с вложенным MAC. Формируем RSU-последовательность и назначаем 1,
Проверка подлинности
Дано ДИ с вложенным MAC. Формируем RSU-последовательность и назначаем 1,

Арифметическое кодирование
Арифметическое кодирование (Arithmetic coding) — алгоритм сжатия информации без потерь,
Арифметическое кодирование
Арифметическое кодирование (Arithmetic coding) — алгоритм сжатия информации без потерь,
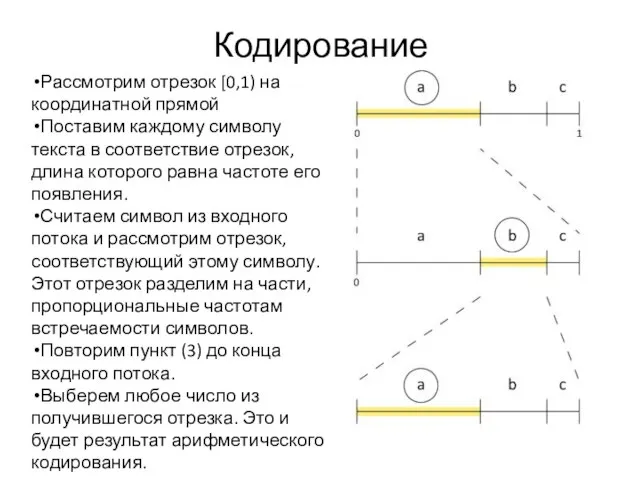
Кодирование
Рассмотрим отрезок [0,1) на координатной прямой
Поставим каждому символу текста в соответствие
Кодирование
Рассмотрим отрезок [0,1) на координатной прямой
Поставим каждому символу текста в соответствие

Декодирование
Выберем на отрезке [0, 1), разделенном на части, длины которых равны
Декодирование
Выберем на отрезке [0, 1), разделенном на части, длины которых равны

Результаты исследования
NR,NS NU – количество R,S U областей соответственно
NT = NR+NS
Результаты исследования
NR,NS NU – количество R,S U областей соответственно
NT = NR+NS


Выводы по таблице
АК дает нам достаточно места для аутентификатора
Меньше всего
Выводы по таблице
АК дает нам достаточно места для аутентификатора
Меньше всего

Текстурность изображения
n1, n2 – размер изображения
- область 2х2 пикселя, где
Текстурность изображения
n1, n2 – размер изображения
- область 2х2 пикселя, где

Итоги
Изучено арифметическое кодирование. Реализован адаптивный кодер на Java
Произведен расчет количества R,
Итоги
Изучено арифметическое кодирование. Реализован адаптивный кодер на Java
Произведен расчет количества R,

Перспективы
Реализация добавления аутентификатора к двоичному изображению
Улучшение метода
Установление связи между параметрами изображения
Перспективы
Реализация добавления аутентификатора к двоичному изображению
Улучшение метода
Установление связи между параметрами изображения
 Стратегические ориентиры и роль геопространственного обеспечения в реализации задач цифровой экономики
Стратегические ориентиры и роль геопространственного обеспечения в реализации задач цифровой экономики Методика изучения динамики явлений
Методика изучения динамики явлений Способы взлома программно-аппаратной защиты и шпионские программы - угроза безопасности вашего ПК
Способы взлома программно-аппаратной защиты и шпионские программы - угроза безопасности вашего ПК Медицинские информационные системы
Медицинские информационные системы Компьютерная обработка изображений
Компьютерная обработка изображений Домашнее задание по информатике
Домашнее задание по информатике Инструкция_для_курьера_по_работе_с_ПМПК
Инструкция_для_курьера_по_работе_с_ПМПК Принципы построения информационных систем в таможенной логистике
Принципы построения информационных систем в таможенной логистике Аттестационная работа. Использование ИКТ на уроках в начальных классах
Аттестационная работа. Использование ИКТ на уроках в начальных классах Гиперссылки в тексте
Гиперссылки в тексте Методы обработки числовых данных
Методы обработки числовых данных Презентация на тему Программы и файлы
Презентация на тему Программы и файлы  Концептуализация
Концептуализация Вспомогательные алгоритмы с аргументами
Вспомогательные алгоритмы с аргументами  Компьютер и слово
Компьютер и слово Дерево потомков. 3 класс
Дерево потомков. 3 класс Подписочная модель обмена сообщениями
Подписочная модель обмена сообщениями GameCore. Monogame
GameCore. Monogame Основы SQL. Практическое применение
Основы SQL. Практическое применение Память на магнитных носителях. Физические и логические диски
Память на магнитных носителях. Физические и логические диски Презентация "Сколько стоит интернет-магазин? На чем можно сэкономить" - скачать презентации по Информатике
Презентация "Сколько стоит интернет-магазин? На чем можно сэкономить" - скачать презентации по Информатике «МОЙ КОМПЬЮТЕР»
«МОЙ КОМПЬЮТЕР» Контекстная реклама
Контекстная реклама Обработка исключений. Предопределенные ИС
Обработка исключений. Предопределенные ИС Массивы. Определение, описание, размещение в памяти, использование. (Лекция 8)
Массивы. Определение, описание, размещение в памяти, использование. (Лекция 8) Статистические методы сжатия. Лекция 2
Статистические методы сжатия. Лекция 2 Базы данных
Базы данных Эталонная модель сетевого взаимодействия OSI
Эталонная модель сетевого взаимодействия OSI