- Лекция 2-2022

Содержание
- 2. § 2.1. Мотивировка Первоначально понятие грамматики было формализовано лингвистами при изучении естественных языков. Они интересовались не
- 3. Надеялись, что, заложив в компьютер формальную грамматику, например, англий-ского языка, можно сделать его “понимаю-щим” этот язык,
- 4. Грамматический разбор Из школьного опыта известно, что собой представляет грамматический разбор предло-жения. При таком разборе определяется,
- 5. При разборе мы имеем дело с грамматическими категориями: ‘предложение’, ‘группа существительного’, ‘группа сказуемого’, ‘существительное’, ‘глагол’, ‘наречие’
- 6. Return 86
- 7. Правила грамматики Грамматический разбор предложений подразу-мевает использование правил некоторой грам-матики. Мы их будем представлять в следующей
- 8. Механизм порождения Здесь стрелочка → отделяет левую часть правила от правой, а грамматические термины заключены в
- 9. Механизм порождения Начиная с цепочки, включающей только грамматический термин, являющимся главным ( ), каждый грамма-тический термин,
- 10. § 2.2. Грамматика. Язык, порождаемый грамматикой 1) нетерминалы — грамматические термины , , …; 2) терминалы
- 11. 3) правила, левые и правые части которых состоят из нетерминалов и терминалов; → → The, ...
- 12. Грамматики. Выводимость. Определение 2.1. Грамматикой назы-вается четверка G = (VN, VT, P, S), где VN, VT
- 13. Грамматики. Выводимость.
- 14. Грамматики. Выводимость.
- 15. Выводимость
- 16. Выводимость Если мы хотим подчеркнуть, что такой вывод использует по крайней мере одно правило грамматики, то
- 17. Напомним, что для любого отношения R имеют место следующие тождества: R0 = E = {(α, α)⏐∀
- 18. Язык, порождаемый грамматикой
- 20. Пример 2.1. Рассмотрим грамматику G = (VN, VT, P, S), где VN = {S}, VT =
- 21. Грамматику, определённую в предыдущем параграфе, вслед за Н. Хомским назовем грамматикой типа 0. Им введено ещё
- 22. Определение 2.7. Грамматика G = (VN, VT, P, S) является грамматикой типа 1 или контекстно-зависимой грамматикой,
- 23. Часто вместо термина “контекстно-зависимая грамматика” используют аббре-виатуру csg (context-sensitive grammar). Очевидно, что грамматику типа 0, приведенную
- 24. 7: Наконец, применим n – 1 раз правило (7). 6: Применим один раз правило (6). 5:
- 25. Замечание 2.1. Некоторые авторы требуют, чтобы правила контекстно-зависимой грамматики имели вид: α1Aα2 → α1βα2, где α1,α2,β∈V*,
- 26. В отечественной литературе для таких грамматик чаще используется термин НС-грамматики — грамматики непосред-ственных составляющих, а грамматики
- 27. Грамматика, приведённая в примере 2.2, не является НС-грамматикой из-за того, что правило CB → BC не
- 29. каждое вхождение терминала a∈VT заменить на новый нетерминал Z, пополнить словарь нетерминалов этим символом и включить
- 30. Правило же вида X1X2…Xm → Y1Y2…Ym+q неукорачивающей грамматики, где m > 0, q ≥ 0, Xi
- 31. Замечание 2.2. Отметим, что новые правила с нетерминалами A могут применяться только в одной указанной последовательности
- 32. Пример 2.3. Покажем на примере, как построить НС-грамматику, эквиваленную неукорачивающей грамматике примера 2.2: G = (VN,
- 33. Правило (3) заменим группой правил: (3.1) CB → A1B, (3.2) A1B → A1A2, (3.3) A1A2 →
- 34. Определение 2.8. Грамматика G = (VN, VT, P, S) является грамматикой типа 2 или контекстно-свободной грамматикой,
- 35. Замечание 2.3. Правило вида A → β позволяет заменить A на β независимо от контекста, в
- 36. Грамматика, приведенная в примере 2.1, является не только грамматикой типа 0, грамматикой типа 1, но и
- 37. Пример 2.3. Рассмотрим интересную контекстно-свободную грамматику G = (VN, VT, P, S), где VN = {S,
- 38. Индукцией по длине цепочки покажем, что L(G) = {x∈{a, b}+ | #a x = #b x},
- 40. База. Очевидно, что все три утверждения выполняются для всех x: | x | = 1, поскольку
- 41. Индукционная гипотеза. Предположим, что утверждения 1–3 выполняются для всех x: | x | ≤ k (k
- 44. В случае (2.2) имеем A bAA bx1A bx1x2 = x; A x1, A x2, причём k1
- 45. Достаточность. Пусть | x | = k + 1. (1) Пусть #a x = #b x.
- 46. Регулярные грамматики Определение 2.9. Грамматика G = (VN, VT, P, S) является грамматикой типа 3 или
- 47. Замечание 2.4. В лекции 3 будет определено абстрактное устройство, называемое конечным автоматом, и показано, что языки,
- 48. Пример rg Пример 2.4. Рассмотрим грамматику G = (VN, VT, P, S), где VN ={S, A,
- 49. Ответ на вопрос Нетерминал B порождает символ 0 или 1, которому может предшествовать любое число 1:
- 50. Наконец, нетерминал S порождает: то же, что A, но с обязательным 0 в начале: 0+1+(0 ;
- 51. Классы языков Очевидно, что каждая грамматика типа 3 является грамматикой типа 2; каждая грамматика типа 2
- 52. В соответствии с текущей практикой язык типа 3 или регулярный язык часто называют регулярным множеством (rs
- 53. Далее будет показано, что языки типа 0 соответствуют языкам, которые интуитивно могут быть перечислимы конечно описываемыми
- 54. § 2.4. Пустое предложение Грамматики определены так, что пустое предложение (ε) не находится ни в контекстно-свободном
- 55. Имеет место следующая лемма. Лемма 2.1. Если G = (VN, VT, P, S) есть контекстно-зависимая, контекстно-свобод-ная
- 56. Доказательство. Пусть S1 — символ, не принадлежащий ни алфавиту нетерминалов, ни алфавиту терминалов. Положим G1 =
- 61. Очевидно, что грамматики G и G1 имеют один и тот же тип. Действительно, все правила грамматики
- 62. Теорема 2.2. Если L — контекстно-зависимый, контекстно-свободный или регулярный язык, то языки L ∪ {ε}, L
- 63. Если язык L = L(G) не содержит пустого предложения, то мы можем пополнить грамматику G ещё
- 64. Правило S → ε может использоваться только как первое и единственное правило вывода в G1, поскольку
- 65. Если же L = L(G) содержит пустое предложение, то среди правил грамматики G имеется правило вида
- 66. Согласно лемме 2.1 типы грамматик G и G1 одинаковы, поэтому одинаковы и типы языков, порождаемых этими
- 67. Перестроим грамматику G из (сл.24) примера 2.2 согласно лемме 2.1 так, чтобы начальный нетерминал не встречался
- 68. Построенная грамматика G1 отличается от исходной грамматики G только дополнительным нетерминалом S1, исполь-зуемым в качестве нового
- 69. Мы можем добавить пустое предложе-ние к L(G1), пополнив грамматику G1 ещё одним правилом: S1→ ε. Обозначим
- 70. § 2.5. Рекурсивность контекстно-зависимых грамматик Определение 2.10. Грамматика G = (VN, VT, P, S) — рекурсивна,
- 71. Пусть G = (VN, VT, P, S) — контекстно-зависимая грамматика. Проверить, порождается пустое пред-ложение данной грамматикой
- 72. Если ε∈L(G), то мы можем образовать новую грамматику: G1= (VN, VT, P1, S), отличающуюся от исходной
- 74. Предположим также, что j ≥ k×p Тогда среди этих сентенциальных форм, по крайней мере, какие-то две
- 75. Интуитивно ясно, что если существует какой-нибудь вывод терминальной цепочки, то существует и “не слишком длинный” её
- 76. Теорема 2.3. Если грамматика G = (VN, VT, P, S) — контекстно-зависима, то она рекурсивна. Доказательство.
- 79. Очевидно, что T0 = {S}, и при m > 0 Tm = Tm–1 ∪ {α |
- 82. Осталось доказать, что для некоторого m непременно будет Tm= Tm–1. Вспомним, что Ti ⊇ Ti–1 для
- 84. Таким образом, при некотором m ≤ (k + 1)n непременно случится, что Tm = Tm–1. Следовательно,
- 85. Пример 2.6. Рассмотрим грамматику G из примера 2.2. С помощью только что описанного алгоритма проверим: abac∈L(G)?
- 86. Рассмотрим теперь наглядный метод описания любого вывода в контекстно-свободной грамматике. Фактически мы его уже могли наблюдать
- 87. Определение 2.11. Пусть G = (VN, VT, P, S) — cfg. Дерево есть дерево вывода в
- 88. 4) если узлы n1, n2, ... , nk — прямые потомки узла n, перечисленные слева направо,
- 89. Пример 2.7. Рассмотрим КС-грамматику G = ({S, A}, {a, b}, P, S), где P = {(1)
- 90. S → a (2) A → ba (4) S → aAS (1) A → SbA (3)
- 91. Результат aabbaa этого дерева вывода получается, если выписать метки листьев слева направо. Заметим, что в сентенциальных
- 93. Если это вспомогательное утверждение будет доказано для любой грамматики GA, то справедливость утверждения теоремы будет следовать
- 94. Retrun to slade 49
- 95. Return 99 Return 97 Return 102
- 96. Индукционная гипотеза. Предположим, что утверждение выполняется для всех k ≤ n (n ≥ 1). Индукционный переход.
- 97. Рассмотрим прямых потомков корня данного дерева вывода (см. рис.2.3) . Они не могут быть все листьями,
- 99. Легко видеть, что если i Мы можем теперь, используя правило A → A1 A2 … Am
- 102. Если li = 0, то αi = Ai. Если li > 0, то по индукционному предположению
- 104. Скачать презентацию

§ 2.1. Мотивировка
Первоначально понятие грамматики было формализовано лингвистами при изучении
§ 2.1. Мотивировка
Первоначально понятие грамматики было формализовано лингвистами при изучении

Надеялись, что, заложив в компьютер формальную грамматику, например, англий-ского языка,
Надеялись, что, заложив в компьютер формальную грамматику, например, англий-ского языка,

Грамматический разбор
Из школьного опыта известно, что собой представляет грамматический разбор предло-жения.
Грамматический разбор
Из школьного опыта известно, что собой представляет грамматический разбор предло-жения.

При разборе мы имеем дело с грамматическими категориями:
‘предложение’, ‘группа существительного’,
При разборе мы имеем дело с грамматическими категориями:
‘предложение’, ‘группа существительного’,
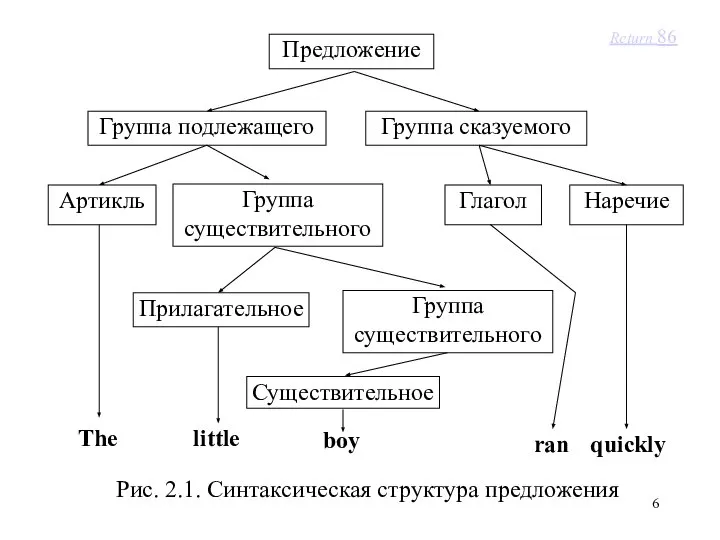
Return 86
Return 86

Правила грамматики
Грамматический разбор предложений подразу-мевает использование правил некоторой грам-матики. Мы
Правила грамматики
Грамматический разбор предложений подразу-мевает использование правил некоторой грам-матики. Мы

Механизм порождения
Здесь стрелочка → отделяет левую часть правила от правой,
Механизм порождения
Здесь стрелочка → отделяет левую часть правила от правой,

Механизм порождения
Начиная с цепочки, включающей только грамматический термин,
Механизм порождения
Начиная с цепочки, включающей только грамматический термин,

§ 2.2. Грамматика. Язык, порождаемый грамматикой
1) нетерминалы — грамматические термины
§ 2.2. Грамматика. Язык, порождаемый грамматикой
1) нетерминалы — грамматические термины

3) правила, левые и правые части которых состоят из нетерминалов и
3) правила, левые и правые части которых состоят из нетерминалов и

Грамматики. Выводимость.
Определение 2.1. Грамматикой назы-вается четверка G = (VN, VT,
Грамматики. Выводимость.
Определение 2.1. Грамматикой назы-вается четверка G = (VN, VT,

Грамматики. Выводимость.
Грамматики. Выводимость.

Грамматики. Выводимость.
Грамматики. Выводимость.

Выводимость
Выводимость

Выводимость
Если мы хотим подчеркнуть, что такой вывод использует по крайней мере
Выводимость
Если мы хотим подчеркнуть, что такой вывод использует по крайней мере

Напомним, что для любого отношения R имеют место следующие тождества:
Напомним, что для любого отношения R имеют место следующие тождества:

Язык, порождаемый грамматикой
Язык, порождаемый грамматикой


Пример 2.1.
Рассмотрим грамматику G = (VN, VT, P, S),
где
Пример 2.1.
Рассмотрим грамматику G = (VN, VT, P, S),
где

Грамматику, определённую в предыдущем параграфе, вслед за Н. Хомским назовем
Грамматику, определённую в предыдущем параграфе, вслед за Н. Хомским назовем

Определение 2.7. Грамматика
G = (VN, VT, P, S)
является
Определение 2.7. Грамматика
G = (VN, VT, P, S)
является

Часто вместо термина “контекстно-зависимая грамматика” используют аббре-виатуру csg (context-sensitive grammar).
Часто вместо термина “контекстно-зависимая грамматика” используют аббре-виатуру csg (context-sensitive grammar).

7: Наконец, применим n – 1 раз правило (7).
6: Применим один
7: Наконец, применим n – 1 раз правило (7).
6: Применим один

Замечание 2.1. Некоторые авторы требуют, чтобы правила контекстно-зависимой грамматики имели
Замечание 2.1. Некоторые авторы требуют, чтобы правила контекстно-зависимой грамматики имели

В отечественной литературе для таких грамматик чаще используется термин НС-грамматики
В отечественной литературе для таких грамматик чаще используется термин НС-грамматики

Грамматика, приведённая в примере 2.2, не является НС-грамматикой из-за того,
Грамматика, приведённая в примере 2.2, не является НС-грамматикой из-за того,


каждое вхождение терминала a∈VT заменить на новый нетерминал Z,
пополнить
каждое вхождение терминала a∈VT заменить на новый нетерминал Z,
пополнить

Правило же вида
X1X2…Xm → Y1Y2…Ym+q
неукорачивающей грамматики, где
m
Правило же вида
X1X2…Xm → Y1Y2…Ym+q
неукорачивающей грамматики, где
m

Замечание 2.2. Отметим, что новые правила с нетерминалами A могут
Замечание 2.2. Отметим, что новые правила с нетерминалами A могут

Пример 2.3. Покажем на примере, как построить НС-грамматику, эквиваленную неукорачивающей грамматике
Пример 2.3. Покажем на примере, как построить НС-грамматику, эквиваленную неукорачивающей грамматике

Правило (3) заменим группой правил:
(3.1) CB → A1B, (3.2)
Правило (3) заменим группой правил:
(3.1) CB → A1B, (3.2)

Определение 2.8. Грамматика
G = (VN, VT, P, S)
является
Определение 2.8. Грамматика
G = (VN, VT, P, S)
является

Замечание 2.3. Правило вида A → β позволяет заменить A
Замечание 2.3. Правило вида A → β позволяет заменить A

Грамматика, приведенная в примере 2.1, является не только грамматикой типа 0,
Грамматика, приведенная в примере 2.1, является не только грамматикой типа 0,

Пример 2.3. Рассмотрим интересную контекстно-свободную грамматику
G = (VN, VT, P,
Пример 2.3. Рассмотрим интересную контекстно-свободную грамматику
G = (VN, VT, P,

Индукцией по длине цепочки покажем, что
L(G) = {x∈{a, b}+
Индукцией по длине цепочки покажем, что
L(G) = {x∈{a, b}+


База. Очевидно, что все три утверждения выполняются для всех x:
База. Очевидно, что все три утверждения выполняются для всех x:

Индукционная гипотеза. Предположим, что утверждения 1–3 выполняются для всех x:
|
Индукционная гипотеза. Предположим, что утверждения 1–3 выполняются для всех x:
|



В случае (2.2) имеем
A bAA bx1A bx1x2 = x;
В случае (2.2) имеем
A bAA bx1A bx1x2 = x;

Достаточность. Пусть | x | = k + 1.
(1)
Достаточность. Пусть | x | = k + 1.
(1)

Регулярные грамматики
Определение 2.9. Грамматика
G = (VN, VT, P, S)
Регулярные грамматики
Определение 2.9. Грамматика
G = (VN, VT, P, S)

Замечание 2.4.
В лекции 3 будет определено абстрактное устройство, называемое
Замечание 2.4.
В лекции 3 будет определено абстрактное устройство, называемое

Пример rg
Пример 2.4. Рассмотрим грамматику
G = (VN, VT, P,
Пример rg
Пример 2.4. Рассмотрим грамматику
G = (VN, VT, P,

Ответ на вопрос
Нетерминал B порождает символ 0 или 1, которому
Ответ на вопрос
Нетерминал B порождает символ 0 или 1, которому

Наконец, нетерминал S порождает:
то же, что A, но с обязательным
Наконец, нетерминал S порождает:
то же, что A, но с обязательным

Классы языков
Очевидно, что
каждая грамматика типа 3 является грамматикой
Классы языков
Очевидно, что
каждая грамматика типа 3 является грамматикой

В соответствии с текущей практикой язык типа 3 или регулярный
В соответствии с текущей практикой язык типа 3 или регулярный

Далее будет показано, что языки типа 0 соответствуют языкам, которые
Далее будет показано, что языки типа 0 соответствуют языкам, которые

§ 2.4. Пустое предложение
Грамматики определены так, что пустое предложение (ε)
§ 2.4. Пустое предложение
Грамматики определены так, что пустое предложение (ε)

Имеет место следующая лемма.
Лемма 2.1. Если G = (VN,
Имеет место следующая лемма.
Лемма 2.1. Если G = (VN,

Доказательство. Пусть S1 — символ, не принадлежащий ни алфавиту нетерминалов,
Доказательство. Пусть S1 — символ, не принадлежащий ни алфавиту нетерминалов,





Очевидно, что грамматики G и G1 имеют один и тот
Очевидно, что грамматики G и G1 имеют один и тот

Теорема 2.2. Если L — контекстно-зависимый, контекстно-свободный или регулярный язык,
Теорема 2.2. Если L — контекстно-зависимый, контекстно-свободный или регулярный язык,

Если язык L = L(G) не содержит пустого предложения, то
Если язык L = L(G) не содержит пустого предложения, то

Правило S → ε может использоваться только как первое и
Правило S → ε может использоваться только как первое и

Если же L = L(G) содержит пустое предложение, то среди
Если же L = L(G) содержит пустое предложение, то среди

Согласно лемме 2.1 типы грамматик G и G1 одинаковы, поэтому
Согласно лемме 2.1 типы грамматик G и G1 одинаковы, поэтому

Перестроим грамматику G из (сл.24) примера 2.2 согласно лемме 2.1
Перестроим грамматику G из (сл.24) примера 2.2 согласно лемме 2.1

Построенная грамматика G1 отличается от исходной грамматики G только дополнительным
Построенная грамматика G1 отличается от исходной грамматики G только дополнительным

Мы можем добавить пустое предложе-ние к L(G1), пополнив грамматику G1
Мы можем добавить пустое предложе-ние к L(G1), пополнив грамматику G1

§ 2.5. Рекурсивность
контекстно-зависимых грамматик
Определение 2.10. Грамматика
G = (VN,
§ 2.5. Рекурсивность
контекстно-зависимых грамматик
Определение 2.10. Грамматика
G = (VN,

Пусть G = (VN, VT, P, S) — контекстно-зависимая грамматика.
Пусть G = (VN, VT, P, S) — контекстно-зависимая грамматика.

Если ε∈L(G), то мы можем образовать новую грамматику:
G1= (VN,
Если ε∈L(G), то мы можем образовать новую грамматику:
G1= (VN,


Предположим также, что j ≥ k×p
Тогда среди этих сентенциальных
Предположим также, что j ≥ k×p
Тогда среди этих сентенциальных

Интуитивно ясно, что если существует какой-нибудь вывод терминальной цепочки, то
Интуитивно ясно, что если существует какой-нибудь вывод терминальной цепочки, то

Теорема 2.3. Если грамматика
G = (VN, VT, P, S)
Теорема 2.3. Если грамматика
G = (VN, VT, P, S)



Очевидно, что
T0 = {S}, и при m > 0
Tm
Очевидно, что
T0 = {S}, и при m > 0
Tm



Осталось доказать, что для некоторого m непременно будет Tm= Tm–1.
Осталось доказать, что для некоторого m непременно будет Tm= Tm–1.


Таким образом, при некотором
m ≤ (k + 1)n
непременно
Таким образом, при некотором
m ≤ (k + 1)n
непременно

Пример 2.6. Рассмотрим грамматику G из примера 2.2.
С
Пример 2.6. Рассмотрим грамматику G из примера 2.2.
С

Рассмотрим теперь наглядный метод описания любого вывода в контекстно-свободной грамматике.
Рассмотрим теперь наглядный метод описания любого вывода в контекстно-свободной грамматике.

Определение 2.11. Пусть
G = (VN, VT, P, S) —
Определение 2.11. Пусть
G = (VN, VT, P, S) —

4) если узлы n1, n2, ... , nk — прямые потомки
4) если узлы n1, n2, ... , nk — прямые потомки

Пример 2.7. Рассмотрим КС-грамматику
G = ({S, A}, {a, b},
Пример 2.7. Рассмотрим КС-грамматику
G = ({S, A}, {a, b},
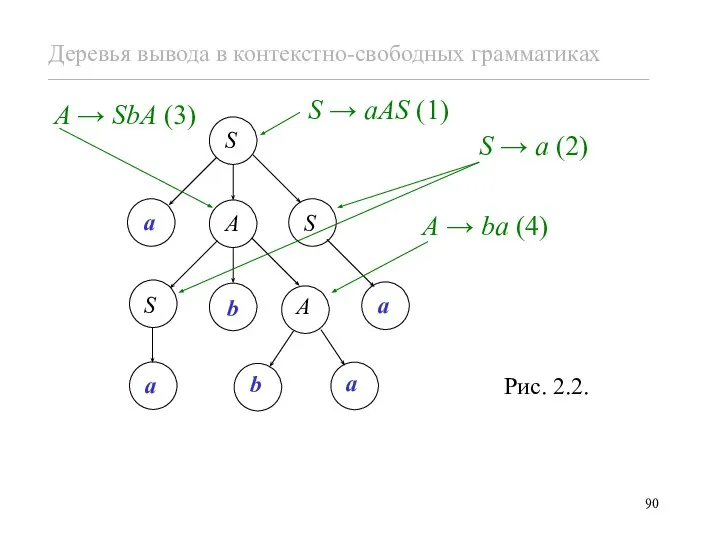
S → a (2)
A → ba (4)
S → aAS
S → a (2)
A → ba (4)
S → aAS

Результат aabbaa этого дерева вывода получается, если выписать метки листьев
Результат aabbaa этого дерева вывода получается, если выписать метки листьев


Если это вспомогательное утверждение будет доказано для любой грамматики GA,
Если это вспомогательное утверждение будет доказано для любой грамматики GA,

Retrun to slade 49
Retrun to slade 49
Return 99
Return 97
Return 102
Return 99
Return 97
Return 102

Индукционная гипотеза. Предположим, что утверждение выполняется для всех k ≤ n
Индукционная гипотеза. Предположим, что утверждение выполняется для всех k ≤ n

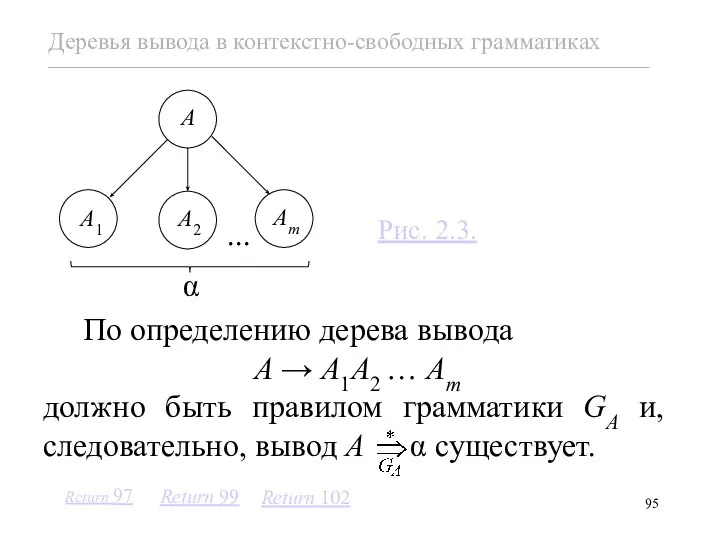
Рассмотрим прямых потомков корня данного дерева вывода (см. рис.2.3) .
Рассмотрим прямых потомков корня данного дерева вывода (см. рис.2.3) .


Легко видеть, что если i < j, то узел i
Легко видеть, что если i < j, то узел i



Если li = 0, то αi = Ai.
Если
Если li = 0, то αi = Ai.
Если
 Язык программирования Паскаль
Язык программирования Паскаль Лабораторна установка по дослідженню вбудованих систем керування на базі контролера Segnetics
Лабораторна установка по дослідженню вбудованих систем керування на базі контролера Segnetics Презентация к уроку информатики в 9 классе на тему «Паскаль. Цикл while»
Презентация к уроку информатики в 9 классе на тему «Паскаль. Цикл while» Поняття робочої групи, домену, користувача й сеансу користувача
Поняття робочої групи, домену, користувача й сеансу користувача ЯКласс – цифровая образовательная платформа XXI века
ЯКласс – цифровая образовательная платформа XXI века Геоинформационные системы в Интернете (ГИС)
Геоинформационные системы в Интернете (ГИС) Разработка мобильного приложения для контроля энергетического баланса человека
Разработка мобильного приложения для контроля энергетического баланса человека Модем. Единицы измерения скорости передачи данных
Модем. Единицы измерения скорости передачи данных Задачи на количество информации
Задачи на количество информации Системи управління базами даних Access
Системи управління базами даних Access Презентация на тему Кодирование графической информации Пространственная дискретизация 9 класс
Презентация на тему Кодирование графической информации Пространственная дискретизация 9 класс Создание базы данных персонала Арселормиттал Кривой Рог
Создание базы данных персонала Арселормиттал Кривой Рог Модель және модельдеу
Модель және модельдеу Электронная цифровая подпись
Электронная цифровая подпись Развитие детского творчества через сетевое взаимодействие в условиях цифрового общества
Развитие детского творчества через сетевое взаимодействие в условиях цифрового общества Программирование. Языки программирования высокого уровня
Программирование. Языки программирования высокого уровня Электронные деньги (Цифровые деньги). Системы электронной наличности
Электронные деньги (Цифровые деньги). Системы электронной наличности Технология обработки текстовой информации _
Технология обработки текстовой информации _ Предмет, метод и теоретические основы методов линейного программирования
Предмет, метод и теоретические основы методов линейного программирования Інформаційна безпека особистості
Інформаційна безпека особистості Средства обмена информацией в интернете
Средства обмена информацией в интернете Типы. Классы. Операторы. Перегрузка
Типы. Классы. Операторы. Перегрузка Компьютерный сленг
Компьютерный сленг Nheritance, polymorphism, and virtual functions
Nheritance, polymorphism, and virtual functions Введение в СУБД ORACLE. Администрирование баз данных. Лекция 1
Введение в СУБД ORACLE. Администрирование баз данных. Лекция 1 Компьютерные сети
Компьютерные сети Телекомунікаційні мережі наступного покоління. Системи управління комутацією і обслуговуванням викликами
Телекомунікаційні мережі наступного покоління. Системи управління комутацією і обслуговуванням викликами Ученический сайт Mind Meister
Ученический сайт Mind Meister