- Наивный Байесовский классификатор

Содержание
- 2. Теоретические основы Наивный байесовский алгоритм – это алгоритм классификации, основанный на теореме Байеса с допущением о
- 3. Формулы P(c|x) – апостериорная вероятность данного класса c (т.е. данного значения целевой переменной) при данном значении
- 4. Пример Рассмотрим обучающий набор данных, содержащий один признак «Погодные условия» (weather) и целевую переменную «Игра» (play),
- 5. Пример(2)
- 6. Пример(3) Шаг 3. С помощью теоремы Байеса рассчитаем апостериорную вероятность для каждого класса при данных погодных
- 7. Положительные стороны Классификация, в том числе многоклассовая, выполняется легко и быстро. Когда допущение о независимости выполняется,
- 8. Отрицательные стороны Если в тестовом наборе данных присутствует некоторое значение категорийного признака, которое не встречалось в
- 10. Скачать презентацию

Теоретические основы
Наивный байесовский алгоритм – это алгоритм классификации, основанный на теореме
Теоретические основы
Наивный байесовский алгоритм – это алгоритм классификации, основанный на теореме

Формулы
P(c|x) – апостериорная вероятность данного класса c (т.е. данного значения целевой
Формулы
P(c|x) – апостериорная вероятность данного класса c (т.е. данного значения целевой

Пример
Рассмотрим обучающий набор данных, содержащий один признак «Погодные условия» (weather) и
Пример
Рассмотрим обучающий набор данных, содержащий один признак «Погодные условия» (weather) и
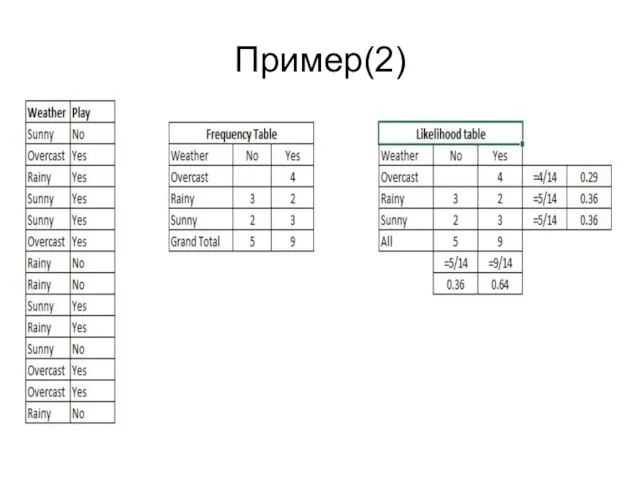
Пример(2)
Пример(2)

Пример(3)
Шаг 3. С помощью теоремы Байеса рассчитаем апостериорную вероятность для каждого
Пример(3)
Шаг 3. С помощью теоремы Байеса рассчитаем апостериорную вероятность для каждого

Положительные стороны
Классификация, в том числе многоклассовая, выполняется легко и быстро.
Когда
Положительные стороны
Классификация, в том числе многоклассовая, выполняется легко и быстро.
Когда

Отрицательные стороны
Если в тестовом наборе данных присутствует некоторое значение категорийного
Отрицательные стороны
Если в тестовом наборе данных присутствует некоторое значение категорийного
 Системы управления базами данных
Системы управления базами данных Тестирование программного обеспечения. Веб-приложения. (Урок 7)
Тестирование программного обеспечения. Веб-приложения. (Урок 7) Учебно-ознакомительная практика в ООО Онлайн-Медиа
Учебно-ознакомительная практика в ООО Онлайн-Медиа Защитный экран/ Классическая касса
Защитный экран/ Классическая касса Настрою интернет-рекламу в Рекламной Сети Яндекса
Настрою интернет-рекламу в Рекламной Сети Яндекса Основы программирования на языке Pascal. Алфавит, типы данных, структура программ. Основные операторы
Основы программирования на языке Pascal. Алфавит, типы данных, структура программ. Основные операторы Безопасный интернет
Безопасный интернет Работа с ярлыками
Работа с ярлыками  Виды информационных измерительных систем. Каналы связи и интерфейсы ИИС
Виды информационных измерительных систем. Каналы связи и интерфейсы ИИС Дистанционное образование использованием обучающей среды Moodle
Дистанционное образование использованием обучающей среды Moodle Динамическое программирование
Динамическое программирование RAD тәсілінің негізгі принциптері
RAD тәсілінің негізгі принциптері Система активного захисту інформації від витоку технічними каналами
Система активного захисту інформації від витоку технічними каналами Цикл “for” на языке Паскаль
Цикл “for” на языке Паскаль Презентация "Государственный научно-исследовательский институт информационных технологий и телекоммуникаций «Информика»"
Презентация "Государственный научно-исследовательский институт информационных технологий и телекоммуникаций «Информика»"  Компьютерные технологии и системы автоматизированного проектирования цифровых устройств
Компьютерные технологии и системы автоматизированного проектирования цифровых устройств Алгоритми з повторенням і розгалуженням. Урок №14. 7 клас
Алгоритми з повторенням і розгалуженням. Урок №14. 7 клас Кодирование цветовой информации
Кодирование цветовой информации Типы данных языка С++
Типы данных языка С++ Векторная графика. Рисуем солнышко Сегодня вы научитесь: Рисовать во встроенном графическом редакторе (MS Word, OpenOffice.org Writer). Создав
Векторная графика. Рисуем солнышко Сегодня вы научитесь: Рисовать во встроенном графическом редакторе (MS Word, OpenOffice.org Writer). Создав Предмет информатики информация и информационные технологии. Единицы измерения информации. магистрально-модульный принцип
Предмет информатики информация и информационные технологии. Единицы измерения информации. магистрально-модульный принцип Анализ элементов одномерного массива Презентация к уроку информатики в 10 А классе Выполнена учителем Лицея № 24 г. Сергиев П
Анализ элементов одномерного массива Презентация к уроку информатики в 10 А классе Выполнена учителем Лицея № 24 г. Сергиев П Мобільні віруси – це загроза чи міф
Мобільні віруси – це загроза чи міф Форма модуля как объект конфигурации 1С
Форма модуля как объект конфигурации 1С Оперативная память
Оперативная память Нужен ли в школе Wi-Fi?
Нужен ли в школе Wi-Fi? Вычисления в электронных таблицах
Вычисления в электронных таблицах Импорт GRADLE проекта Spring boot В IntelliJ IDEA
Импорт GRADLE проекта Spring boot В IntelliJ IDEA