- Обработка и анализ данных

Содержание
- 2. План занятия Общие рекомендации по анализу данных Работа с текстовыми данными Анализ результатов
- 3. Обработка и анализ данных feature extraction and feature engineering – превращение данных, специфических для предметной области,
- 4. Обработка и анализ данных Построение матриц ошибок Построение гистограмм, анализ коррелирующих признаков,
- 5. Признаки Вещественные (Возраст, площадь квартиры) Бинарные ( Доход клиента больше среднего по городу?) Порядковые (тип населенного
- 6. Label Encoder
- 7. Оne-hot-кодирование
- 8. Другие способы кодирования
- 9. Обработка и анализ текстовых данных - токенизация (nltk) - приведение к одному регистру - лемматизация (nltk,
- 10. Векторизация текста Разбиение текста на слова и преобразование каждого слова в вектор Разбиение текста на символы
- 11. Преобазование токенов в векторы One-hot encoding( прямое кодирование слов и символов) One-hot hashing trick ( прямое
- 12. Bag of words («Мешок слов»)
- 13. N-граммы
- 14. TF-IDF IDF (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово
- 15. Embeddings Малоразмерные представления Геометрические отношения между векторами отражают семантические связи
- 16. Embeddings
- 18. Скачать презентацию

План занятия
Общие рекомендации по анализу данных
Работа с текстовыми данными
Анализ результатов
План занятия
Общие рекомендации по анализу данных
Работа с текстовыми данными
Анализ результатов

Обработка и анализ данных
feature extraction and feature engineering – превращение данных,
Обработка и анализ данных
feature extraction and feature engineering – превращение данных,
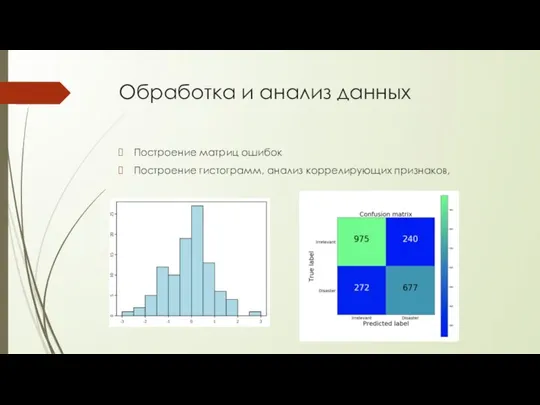
Обработка и анализ данных
Построение матриц ошибок
Построение гистограмм, анализ коррелирующих признаков,
Обработка и анализ данных
Построение матриц ошибок
Построение гистограмм, анализ коррелирующих признаков,

Признаки
Вещественные (Возраст, площадь квартиры)
Бинарные ( Доход клиента больше среднего по городу?)
Порядковые
Признаки
Вещественные (Возраст, площадь квартиры)
Бинарные ( Доход клиента больше среднего по городу?)
Порядковые

Label Encoder
Label Encoder

Оne-hot-кодирование
Оne-hot-кодирование

Другие способы кодирования
Другие способы кодирования

Обработка и анализ текстовых данных
- токенизация (nltk)
- приведение к одному регистру
Обработка и анализ текстовых данных
- токенизация (nltk)
- приведение к одному регистру

Векторизация текста
Разбиение текста на слова и преобразование каждого слова в вектор
Разбиение
Векторизация текста
Разбиение текста на слова и преобразование каждого слова в вектор
Разбиение

Преобазование токенов в векторы
One-hot encoding( прямое кодирование слов и символов)
One-hot hashing
Преобазование токенов в векторы
One-hot encoding( прямое кодирование слов и символов)
One-hot hashing

Bag of words («Мешок слов»)
Bag of words («Мешок слов»)
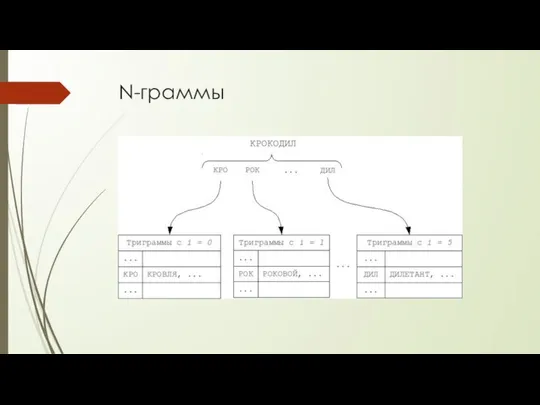
N-граммы
N-граммы

TF-IDF
IDF (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое
TF-IDF
IDF (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое

Embeddings
Малоразмерные представления
Геометрические отношения между векторами отражают семантические связи
Embeddings
Малоразмерные представления
Геометрические отношения между векторами отражают семантические связи
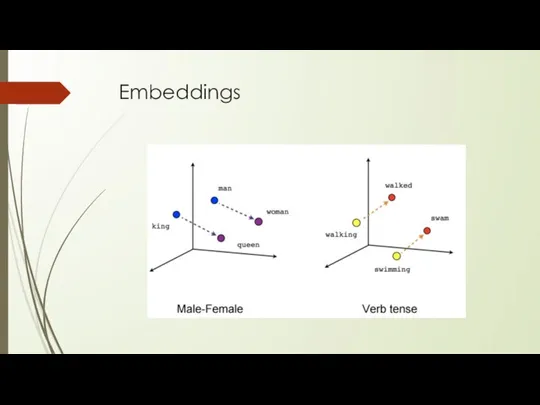
Embeddings
Embeddings
 Эффективное обучение (применимые лайфхаки)
Эффективное обучение (применимые лайфхаки) Файлы и файловые. Структуры компьютер как унивесальное устройство для работы с информацией
Файлы и файловые. Структуры компьютер как унивесальное устройство для работы с информацией Информационная разминка
Информационная разминка מערכת CRMלמוקד סמייל
מערכת CRMלמוקד סמייל  Язык программирования высокого уровня. Лекция №7
Язык программирования высокого уровня. Лекция №7 Основы Linux
Основы Linux Сатурн и его кольца на экране монитора Моделирование на языке программирования QBASIC
Сатурн и его кольца на экране монитора Моделирование на языке программирования QBASIC Программное обеспечение
Программное обеспечение Точные построения графических объектов. Клавиша точных построений
Точные построения графических объектов. Клавиша точных построений Нормальные формы баз данных
Нормальные формы баз данных Векторный графический редактор Inkscape
Векторный графический редактор Inkscape Электронная почта
Электронная почта Презентация на тему Поколение ЭВМ
Презентация на тему Поколение ЭВМ Схема и карта. Схема передачи информации
Схема и карта. Схема передачи информации Миграция на сервисы
Миграция на сервисы Как правильно организовать поиск в Интернете
Как правильно организовать поиск в Интернете Автономный мобильный робот-поисковик
Автономный мобильный робот-поисковик LTE HO Strategy. Features. KPIs
LTE HO Strategy. Features. KPIs Алгоритмы и способы их описания
Алгоритмы и способы их описания JavaScript kursas
JavaScript kursas Схема ЭОД в условиях эксперимента
Схема ЭОД в условиях эксперимента Устройство Компа
Устройство Компа Компьютерные презентации Урок информатики 10 класс
Компьютерные презентации Урок информатики 10 класс Принтеры Выполнили: ученицы 10 А класса Лебедева Виктория Зорина Таня
Принтеры Выполнили: ученицы 10 А класса Лебедева Виктория Зорина Таня Пример даталогического проектирования БД
Пример даталогического проектирования БД Аттестационная работа. Методическая разработка по выполнению проекта Защита информации
Аттестационная работа. Методическая разработка по выполнению проекта Защита информации Программирование на языке Python
Программирование на языке Python Автоматическое тестирование
Автоматическое тестирование