Практические рекомендации по распараллеливанию с помощью OpenMP и измерению ускорения. Ошибки при многопоточном программировании
- Практические рекомендации по распараллеливанию с помощью OpenMP и измерению ускорения. Ошибки при многопоточном программировании

Содержание
- 2. OpenMP Практические рекомендации по распараллеливанию с помощью OpenMP и измерению ускорения. Ошибки при многопоточном программировании. Презентация
- 3. 1. Практические рекомендации по распараллеливанию с помощью OpenMP и измерению ускорения. 1.1. Время вычислений в параллельном
- 4. Потоки в современных Windows Процесс представляет выполняющийся экземпляр программы. Он имеет собственное адресное пространство, где содержаться
- 5. Классы потоков. Потоки OpenMP
- 6. Основные состояния потока. «Накладные расходы»
- 7. Неизбежные «накладные расходы» в многопоточной программе с несколькими параллельными регионами Создание потоков – самые большие «накладные
- 8. 1. 1. Время вычислений в параллельном регионе должно быть больше, чем время, затраченное на создание параллельного
- 9. 1.2. При входе в первый параллельный регион «накладные расходы» намного больше, чем при входах в следующие
- 10. Тестируемый код – проект time_parallel – ускорение как функция полного времени работы программы – последовательный код
- 11. Тестируемый код – проект time_parallel – ускорение как функция полного времени работы программы – параллельный код
- 12. Тестируемый код – проект time_parallel – ускорение как функция полного времени работы программы – параллельный код
- 13. Требования на выбор предельных значений переменных внешнего и внутреннего цикла 1. Внутренний цикл: treeData.N определяется из
- 14. Задание 1. Проект time_paral. Зависимость ускорения от M 1. Для запуска последовательного варианта аргументы в командной
- 15. Задание 2. Проект time_paral. Зависимость ускорения от M Демонстрация того, что все «накладные расходы» сосредоточены в
- 16. 2. Ошибки при многопоточном программировании 1. Конфликты «запись - запись» - два потока пишут в одну
- 17. Ошибки, которые находит ThreadChecker при программировании в OpenMP 1. Конфликты «запись - запись» - два потока
- 18. 3. Презентация материалов по OpenMP 3.1. Курс Гергеля 3.2. Материалы тренингов Intel
- 19. 3.1. Курс Гергеля Обзор методов многопоточного программирования для простейших алгоритмов умножение вектора на вектор матрицы на
- 20. 3.2. Материалы тренингов Intel Преобладающая особенность – все показывается на одной задаче Параллельный алгоритм Параллельные конструкции
- 21. 4. Распределение заданий между потоками По материалам тренинга Intel, проведенного для преподавателей вузов в апреле 2006
- 22. Цели и задачи Научиться технике распараллеливания последовательного кода на основе OpenMP Применять в цикле разработки инструменты
- 23. Содержание Стандартный цикл разработки Изучаемый пример: генерация простых чисел Как повысить эффективность вычислений
- 24. Определение параллелелизма Два или более процесса или потока выполняются одновременно Виды параллелелизма для архитектур, поддерживающих потоки
- 25. Закон Амдала Оценка «сверху» для ускорения параллельной программы по закону Амдала
- 26. Процессы и потоки
- 27. Потоки – «плюсы» и «минусы» «Плюсы» Позволяют повысить производительность и полнее использовать системные ресурсы Даже в
- 28. Генерация простых чисел bool TestForPrime(int val) { // let’s start checking from 3 int limit, factor
- 29. Задание 1. Выполнить запуски последовательной версии первоначального кода (проект Simple_number) Установить однопоточный режим работы (Visual Studio,
- 30. Методика разработки Анализ Определить участок кода с максимальной долей вычислений Проектирование (включить многопоточность) Определить, каким образом
- 31. Рабочий цикл
- 32. Провести анализ работы проекта Simple_number Входные данные: start = 3 end = 1000000 Анализ – «Sampling»
- 33. Анализ – «Sampling» («сэмплирование»)
- 34. Анализ – «Sampling» («сэмплирование»)
- 35. Анализ - Call Graph
- 36. Анализ Параллельная работа потоков будет эффективна в FindPrimes() Аргументы в пользу распараллеливания Мало внутренних взаимозависимостей Возможен
- 37. Задание 2 Выполните запуск с параметрами ‘1 5000000’ (границы диапазона поиска простых чисел) Цель запуска -
- 38. Метод проектирования Фостера Необходимо выполнить 4 шага: Разбить задачу на максимальное число подзадач Установить связи «данные
- 39. Проектирование многопоточной программы «Дробление» Разбить исходную задачу на подзадачи «Связи» Определить типы и количество связей между
- 40. Модели параллельного программирования Функциональная декомпозиция Параллельное выполнение разных подзадач Разделение на различные подзадачи, но обработка общих
- 41. Способы декомпозиции Функциональная декомпозиция Сфокусирована на методах обработки данных, выявляя структуру задачи
- 42. Аналогии для функциональной декомпозиции и декомпозиции по данным Независимые этапы вычислений Функциональная декомпозиция Задача потока связана
- 43. Проектирование Ожидаемый выигрыш Как бы его достичь минимальными усилиями? Долго ли это - распараллелить? Сразу получится
- 44. OpenMP «Вилочный» параллелелизм: «Мастер» - поток создает команду потоков Последовательная программа преображается в параллельную
- 45. Проектирование #pragma omp parallel for for( int i = start; i if( TestForPrime(i) ) globalPrimes[gPrimesFound++] =
- 46. Задание 3 Выполнить запуск версии кода с OpenMP Включите библиотеки OpenMP и установите многопоточный режим MultyThreaded
- 47. Проектирование А каков был ожидаемый выигрыш? А как его достичь ? А как долго ? А
- 48. Тестирование правильности работы программы по ее результатам Результаты неправильные Каждый запуск – свой результат…
- 49. Тестирование правильности работы Intel® Thread Checker может определить ошибки типа «гонки данных» или «конфликты запись-запись, чтение
- 50. Thread Checker – окно результатов после выполнения анализа
- 51. Thread Checker Двойной щелчок «мыши» - находим локализацию ошибки в коде
- 52. Thread Checker – локализация ошибки в коде
- 53. Задание 4 Примените Thread Checker для анализа правильности выполнения Создать Thread Checker activity Запуск приложения с
- 54. Тестирование правильности работы Сколько попыток еще предпринять? Как долго трудиться над этим распараллеливанием? Thread Checker обнаружил
- 55. Тестирование правильности работы #pragma omp parallel for for( int i = start; i if( TestForPrime(i) )
- 56. Задание 5 Модифицируйте версию кода с OpenMP Добавьте прагму критической секции в код Откомпилируйте код Проверьте
- 57. Correctness Работает-то правильно, да ускорение низкое…~1.33X Разве это предел, к которому мы стремились? Нет! По закону
- 58. Задачи повышения производительности Параллельный «оверхед» (оverhead) «Накладные расходы» на создание потоков, организацию «расписания» их работы …
- 59. Измерение производительности Thread Profiler определяет «узкие места» - участки кода многопоточной области, где работа потоков происходит
- 60. Thread Profiler for OpenMP Только для OpenMP приложений Окно результатов «Summary» - появляется сразу после завершения
- 61. Thread Profiler for OpenMP
- 62. Thread Profiler for OpenMP
- 63. Thread Profiler for OpenMP
- 64. Thread Profiler for OpenMP Окно «Regions»: регионы – область кода программы, либо полностью последовательного, либо полностью
- 65. Thread Profiler for OpenMP
- 66. Задание 6. Исследуйте параллельную работу программы Thread Profiler с теми же параметрами, что и базовое измерение
- 67. Диагностика Thread Profiler – большой дисбаланс – потоки «ждали друг друга» Поток 0 Поток 1 Поток
- 68. Определили дисбаланс загрузки Распределим работу более эффективно: не по ¼ от всего цикла сразу каждому потоку,
- 69. Борьба с дисбалансом – перераспределение заданий потокам Новое «распределение работы» по сравнению со старым будет следующим
- 71. Скачать презентацию

OpenMP
Практические рекомендации по распараллеливанию с помощью OpenMP и измерению ускорения.
Ошибки
OpenMP
Практические рекомендации по распараллеливанию с помощью OpenMP и измерению ускорения.
Ошибки

1. Практические рекомендации по распараллеливанию с помощью OpenMP и измерению ускорения.
1. Практические рекомендации по распараллеливанию с помощью OpenMP и измерению ускорения.

Потоки в современных Windows
Процесс представляет выполняющийся экземпляр программы. Он имеет собственное
Потоки в современных Windows
Процесс представляет выполняющийся экземпляр программы. Он имеет собственное

Классы потоков. Потоки OpenMP
Классы потоков. Потоки OpenMP

Основные состояния потока.
«Накладные расходы»
Основные состояния потока.
«Накладные расходы»

Неизбежные «накладные расходы» в многопоточной программе с несколькими параллельными регионами
Создание
Неизбежные «накладные расходы» в многопоточной программе с несколькими параллельными регионами
Создание

1. 1. Время вычислений в параллельном регионе должно быть больше, чем
1. 1. Время вычислений в параллельном регионе должно быть больше, чем

1.2. При входе в первый параллельный регион «накладные расходы» намного больше,
1.2. При входе в первый параллельный регион «накладные расходы» намного больше,

Тестируемый код – проект time_parallel – ускорение как функция полного времени
Тестируемый код – проект time_parallel – ускорение как функция полного времени

Тестируемый код – проект time_parallel – ускорение как функция полного времени
Тестируемый код – проект time_parallel – ускорение как функция полного времени

Тестируемый код – проект time_parallel – ускорение как функция полного времени
Тестируемый код – проект time_parallel – ускорение как функция полного времени

Требования на выбор предельных значений переменных внешнего и внутреннего цикла
1. Внутренний
Требования на выбор предельных значений переменных внешнего и внутреннего цикла
1. Внутренний

Задание 1. Проект time_paral. Зависимость ускорения от M
1. Для запуска последовательного
Задание 1. Проект time_paral. Зависимость ускорения от M
1. Для запуска последовательного

Задание 2. Проект time_paral. Зависимость ускорения от M
Демонстрация того, что все
Задание 2. Проект time_paral. Зависимость ускорения от M
Демонстрация того, что все

2. Ошибки при многопоточном программировании
1. Конфликты «запись - запись» - два
2. Ошибки при многопоточном программировании
1. Конфликты «запись - запись» - два

Ошибки, которые находит ThreadChecker при программировании в OpenMP
1. Конфликты «запись -
Ошибки, которые находит ThreadChecker при программировании в OpenMP
1. Конфликты «запись -

3. Презентация материалов по OpenMP
3.1. Курс Гергеля
3.2. Материалы тренингов Intel
3. Презентация материалов по OpenMP
3.1. Курс Гергеля
3.2. Материалы тренингов Intel

3.1. Курс Гергеля
Обзор методов многопоточного программирования для простейших алгоритмов
умножение вектора
3.1. Курс Гергеля
Обзор методов многопоточного программирования для простейших алгоритмов
умножение вектора

3.2. Материалы тренингов Intel
Преобладающая особенность – все показывается на одной задаче
Параллельный
3.2. Материалы тренингов Intel
Преобладающая особенность – все показывается на одной задаче
Параллельный

4. Распределение заданий между потоками
По материалам тренинга Intel, проведенного для преподавателей
4. Распределение заданий между потоками
По материалам тренинга Intel, проведенного для преподавателей

Цели и задачи
Научиться технике распараллеливания последовательного кода на основе OpenMP
Применять в
Цели и задачи
Научиться технике распараллеливания последовательного кода на основе OpenMP
Применять в

Содержание
Стандартный цикл разработки
Изучаемый пример: генерация простых чисел
Как повысить эффективность вычислений
Содержание
Стандартный цикл разработки
Изучаемый пример: генерация простых чисел
Как повысить эффективность вычислений

Определение параллелелизма
Два или более процесса или потока выполняются одновременно
Виды параллелелизма
Определение параллелелизма
Два или более процесса или потока выполняются одновременно
Виды параллелелизма

Закон Амдала
Оценка «сверху» для ускорения параллельной программы по закону Амдала
Закон Амдала
Оценка «сверху» для ускорения параллельной программы по закону Амдала

Процессы и потоки
Процессы и потоки

Потоки – «плюсы» и «минусы»
«Плюсы»
Позволяют повысить производительность и полнее использовать системные
Потоки – «плюсы» и «минусы»
«Плюсы»
Позволяют повысить производительность и полнее использовать системные
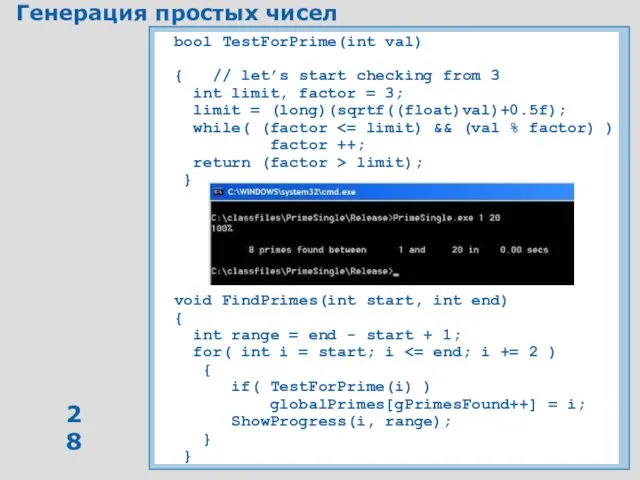
Генерация простых чисел
bool TestForPrime(int val)
{ // let’s start checking
Генерация простых чисел
bool TestForPrime(int val)
{ // let’s start checking

Задание 1.
Выполнить запуски последовательной версии первоначального кода (проект Simple_number)
Установить однопоточный режим
Задание 1.
Выполнить запуски последовательной версии первоначального кода (проект Simple_number)
Установить однопоточный режим

Методика разработки
Анализ
Определить участок кода с максимальной долей вычислений
Проектирование (включить многопоточность)
Определить, каким
Методика разработки
Анализ
Определить участок кода с максимальной долей вычислений
Проектирование (включить многопоточность)
Определить, каким

Рабочий цикл
Рабочий цикл

Провести анализ работы проекта Simple_number
Входные данные: start = 3 end =
Провести анализ работы проекта Simple_number
Входные данные: start = 3 end =

Анализ – «Sampling» («сэмплирование»)
Анализ – «Sampling» («сэмплирование»)

Анализ – «Sampling» («сэмплирование»)
Анализ – «Sampling» («сэмплирование»)

Анализ - Call Graph
Анализ - Call Graph

Анализ
Параллельная работа потоков будет эффективна в
FindPrimes()
Аргументы в пользу распараллеливания
Мало внутренних
Анализ
Параллельная работа потоков будет эффективна в
FindPrimes()
Аргументы в пользу распараллеливания
Мало внутренних

Задание 2
Выполните запуск с параметрами ‘1 5000000’ (границы диапазона поиска простых
Задание 2
Выполните запуск с параметрами ‘1 5000000’ (границы диапазона поиска простых

Метод проектирования Фостера
Необходимо выполнить 4 шага:
Разбить задачу на максимальное число подзадач
Установить
Метод проектирования Фостера
Необходимо выполнить 4 шага:
Разбить задачу на максимальное число подзадач
Установить
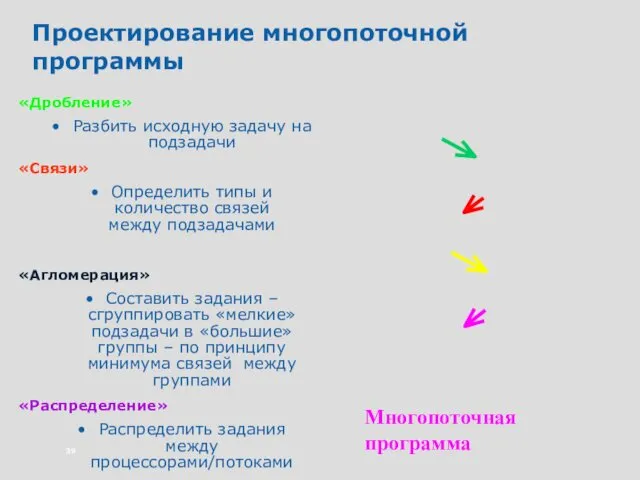
Проектирование многопоточной программы
«Дробление»
Разбить исходную задачу на подзадачи
«Связи»
Определить типы и количество связей
Проектирование многопоточной программы
«Дробление»
Разбить исходную задачу на подзадачи
«Связи»
Определить типы и количество связей

Модели параллельного программирования
Функциональная декомпозиция
Параллельное выполнение разных подзадач
Разделение на различные подзадачи, но
Модели параллельного программирования
Функциональная декомпозиция
Параллельное выполнение разных подзадач
Разделение на различные подзадачи, но

Способы декомпозиции
Функциональная декомпозиция
Сфокусирована на методах обработки данных, выявляя структуру задачи
Способы декомпозиции
Функциональная декомпозиция
Сфокусирована на методах обработки данных, выявляя структуру задачи

Аналогии для функциональной декомпозиции и декомпозиции по данным
Независимые этапы вычислений
Функциональная декомпозиция
Задача
Аналогии для функциональной декомпозиции и декомпозиции по данным
Независимые этапы вычислений
Функциональная декомпозиция
Задача

Проектирование
Ожидаемый выигрыш
Как бы его достичь минимальными усилиями?
Долго ли это -
Проектирование
Ожидаемый выигрыш
Как бы его достичь минимальными усилиями?
Долго ли это -

OpenMP
«Вилочный» параллелелизм:
«Мастер» - поток создает команду потоков
Последовательная программа преображается
OpenMP
«Вилочный» параллелелизм:
«Мастер» - поток создает команду потоков
Последовательная программа преображается

Проектирование
#pragma omp parallel for
for( int i = start; i <=
Проектирование
#pragma omp parallel for
for( int i = start; i <=

Задание 3
Выполнить запуск версии кода с OpenMP
Включите библиотеки OpenMP и установите
Задание 3
Выполнить запуск версии кода с OpenMP
Включите библиотеки OpenMP и установите

Проектирование
А каков был ожидаемый выигрыш?
А как его достичь ?
А как долго
Проектирование
А каков был ожидаемый выигрыш?
А как его достичь ?
А как долго

Тестирование правильности работы программы по ее результатам
Результаты неправильные
Каждый запуск – свой
Тестирование правильности работы программы по ее результатам
Результаты неправильные
Каждый запуск – свой
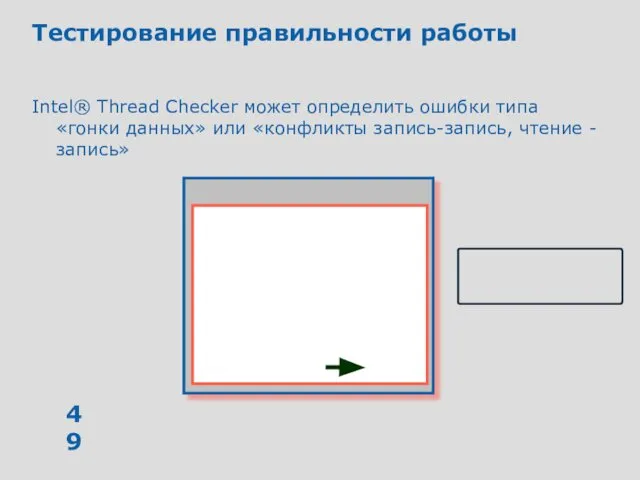
Тестирование правильности работы
Intel® Thread Checker может определить ошибки типа «гонки данных»
Тестирование правильности работы
Intel® Thread Checker может определить ошибки типа «гонки данных»

Thread Checker – окно результатов после выполнения анализа
Thread Checker – окно результатов после выполнения анализа

Thread Checker
Двойной щелчок «мыши» - находим локализацию ошибки в коде
Thread Checker
Двойной щелчок «мыши» - находим локализацию ошибки в коде

Thread Checker – локализация ошибки в коде
Thread Checker – локализация ошибки в коде

Задание 4
Примените Thread Checker для анализа правильности выполнения
Создать Thread Checker activity
Запуск
Задание 4
Примените Thread Checker для анализа правильности выполнения
Создать Thread Checker activity
Запуск

Тестирование правильности работы
Сколько попыток еще предпринять?
Как долго трудиться над этим распараллеливанием?
Thread
Тестирование правильности работы
Сколько попыток еще предпринять?
Как долго трудиться над этим распараллеливанием?
Thread

Тестирование правильности работы
#pragma omp parallel for
for( int i = start;
Тестирование правильности работы
#pragma omp parallel for
for( int i = start;

Задание 5
Модифицируйте версию кода с OpenMP
Добавьте прагму критической секции в код
Откомпилируйте
Задание 5
Модифицируйте версию кода с OpenMP
Добавьте прагму критической секции в код
Откомпилируйте

Correctness
Работает-то правильно, да ускорение низкое…~1.33X
Разве это предел, к которому мы стремились?
Нет!
Correctness
Работает-то правильно, да ускорение низкое…~1.33X
Разве это предел, к которому мы стремились?
Нет!

Задачи повышения производительности
Параллельный «оверхед» (оverhead)
«Накладные расходы» на создание потоков, организацию
Задачи повышения производительности
Параллельный «оверхед» (оverhead)
«Накладные расходы» на создание потоков, организацию

Измерение производительности
Thread Profiler определяет «узкие места» - участки кода многопоточной области,
Измерение производительности
Thread Profiler определяет «узкие места» - участки кода многопоточной области,

Thread Profiler for OpenMP
Только для OpenMP приложений
Окно результатов
Thread Profiler for OpenMP
Только для OpenMP приложений
Окно результатов

Thread Profiler for OpenMP
Thread Profiler for OpenMP

Thread Profiler for OpenMP
Thread Profiler for OpenMP

Thread Profiler for OpenMP
Thread Profiler for OpenMP

Thread Profiler for OpenMP
Окно «Regions»: регионы – область кода программы,
Thread Profiler for OpenMP
Окно «Regions»: регионы – область кода программы,

Thread Profiler for OpenMP
Thread Profiler for OpenMP

Задание 6.
Исследуйте параллельную работу программы Thread Profiler с теми же параметрами,
Задание 6.
Исследуйте параллельную работу программы Thread Profiler с теми же параметрами,
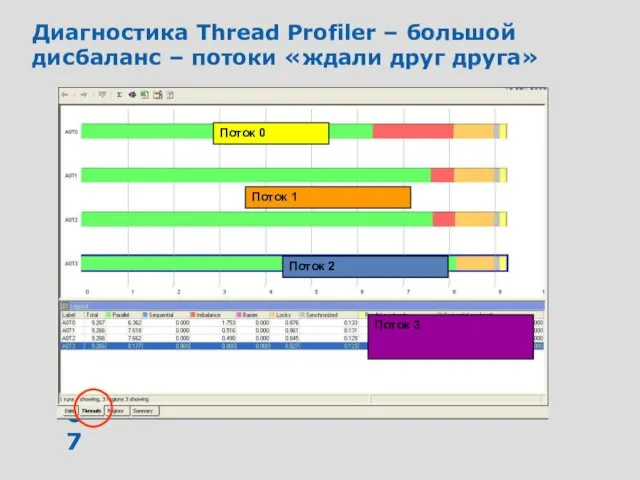
Диагностика Thread Profiler – большой дисбаланс – потоки «ждали друг друга»
Поток
Диагностика Thread Profiler – большой дисбаланс – потоки «ждали друг друга»
Поток

Определили дисбаланс загрузки
Распределим работу более эффективно: не по ¼ от всего
Определили дисбаланс загрузки
Распределим работу более эффективно: не по ¼ от всего

Борьба с дисбалансом – перераспределение заданий потокам
Новое «распределение работы» по сравнению
Борьба с дисбалансом – перераспределение заданий потокам
Новое «распределение работы» по сравнению
 Виды шрифтов
Виды шрифтов Фильтры поисковых систем. Антиспам
Фильтры поисковых систем. Антиспам ОЧЕНЬ ПОЛЕЗНЫЙ УРОК Занятие 1 Здравствуй, программа Paint!
ОЧЕНЬ ПОЛЕЗНЫЙ УРОК Занятие 1 Здравствуй, программа Paint! Ограничения на число выводимых строк
Ограничения на число выводимых строк Составление и отладка линейных программ
Составление и отладка линейных программ Виртуальные сервисы в работе учителя
Виртуальные сервисы в работе учителя Software Upgrade Guide v2
Software Upgrade Guide v2 Видеокарта
Видеокарта Кодирование изображения в компьютере. Обработка графической информации
Кодирование изображения в компьютере. Обработка графической информации Управление устройствами ввода-вывода
Управление устройствами ввода-вывода Тренды в веб дизайне 2021
Тренды в веб дизайне 2021 Презентация "Введение в мультимедийные базы данных 9" - скачать презентации по Информатике
Презентация "Введение в мультимедийные базы данных 9" - скачать презентации по Информатике Графические информационные объекты 11 класс Составила Антонова Е.П. 2012г.
Графические информационные объекты 11 класс Составила Антонова Е.П. 2012г. Инструкция по регистрации работников подрядной организации на Портале знаний
Инструкция по регистрации работников подрядной организации на Портале знаний Разработка инструментов оценки лояльности клиентов машиностроительного предприятия на основе интеллектуального анализа данных
Разработка инструментов оценки лояльности клиентов машиностроительного предприятия на основе интеллектуального анализа данных Архитектура Web-приложений
Архитектура Web-приложений Анимации в презентации
Анимации в презентации Подготовка к ЕГэ. Информация
Подготовка к ЕГэ. Информация Ветис и решение от ГК Штрих-М
Ветис и решение от ГК Штрих-М Продвижение в Инстаграм 2018
Продвижение в Инстаграм 2018 15573ecde79daf193248ffb700ad5a39
15573ecde79daf193248ffb700ad5a39 Мир без Интернета
Мир без Интернета Относительные, абсолютные и смешанные ссылки в MS Excel
Относительные, абсолютные и смешанные ссылки в MS Excel Мультимедийная платформа
Мультимедийная платформа Онлайн-лагерь Улыбка. Отчет по лагерю
Онлайн-лагерь Улыбка. Отчет по лагерю История развития языков программирования
История развития языков программирования Кинематографическая журналистика. Аудиовизуальное повествование в интернете
Кинематографическая журналистика. Аудиовизуальное повествование в интернете Тест по информатике Устройство персонального компьютера
Тест по информатике Устройство персонального компьютера