Презентация "Учебный курс Параллельное программирование с OpenMP" - скачать презентации по Информатике
- Презентация "Учебный курс Параллельное программирование с OpenMP" - скачать презентации по Информатике

Содержание
- 2. Москва, 2012 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из 46 Содержание Тенденции развития
- 3. В течение нескольких десятилетий развитие ЭВМ сопровождалось удвоением их быстродействия каждые 1.5-2 года. Это обеспечивалось и
- 4. Время Тенденции развития современных процессоров В П В П В П В П В П В
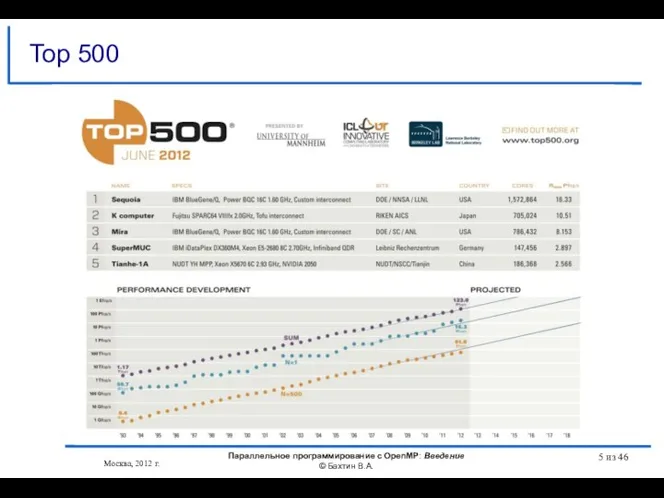
- 5. Москва, 2012 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из 46 Top 500
- 6. Современные суперкомпьютерные системы Москва, 2012 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из 46
- 7. Современные суперкомпьютерные системы Москва, 2012 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из 46
- 8. Тенденции развития современных процессоров Москва, 2012 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из
- 9. Тенденции развития современных процессоров Москва, 2012 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из
- 10. Тенденции развития современных процессоров Москва, 2012 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из
- 11. Тенденции развития современных процессоров Intel Itanium 9350 (Tukwila) 1,73 ГГц 4 ядeр 8 потоков с технологией
- 12. Тенденции развития современных процессоров IBM Power7 3,5 - 4,0 ГГц 8 ядер x 4 нити Simultaneuos
- 13. Тенденции развития современных процессоров Темпы уменьшения латентности памяти гораздо ниже темпов ускорения процессоров + прогресс в
- 14. Существующие подходы для создания параллельных программ Автоматическое / автоматизированное распараллеливание Библиотеки нитей Win32 API POSIX Библиотеки
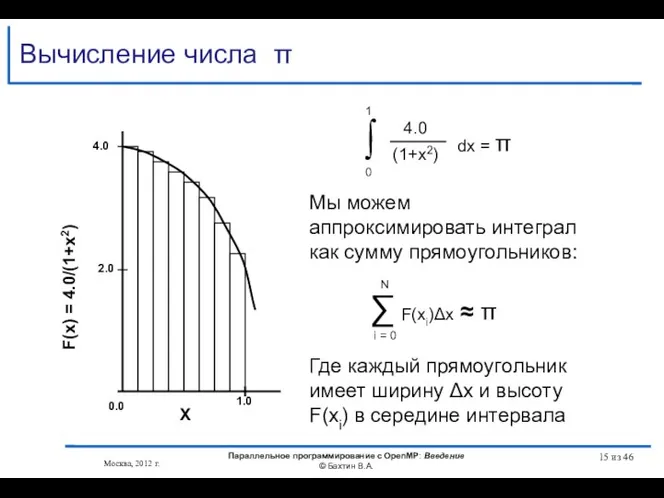
- 15. Москва, 2012 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из 46 Вычисление числа π
- 16. #include int main () { int n =100000, i; double pi, h, sum, x; h =
- 17. Автоматическое распараллеливание Polaris, CAPO, WPP, SUIF, VAST/Parallel, OSCAR, Intel/OpenMP, UTL icc -parallel pi.c pi.c(8): (col. 5)
- 18. Автоматизированное распараллеливание Intel/GAP (Guided Auto-Parallel), CAPTools/ParaWise, BERT77, FORGE Magic/DM, ДВОР (Диалоговый Высокоуровневый Оптимизирующий Распараллеливатель), САПФОР (Система
- 19. Автоматизированное распараллеливание test.cpp(49): remark #30521: (PAR) Loop at line 49 cannot be parallelized due to conditional
- 20. #include #include #define NUM_THREADS 2 CRITICAL_SECTION hCriticalSection; double pi = 0.0; int n =100000; void main
- 21. void Pi (void *arg) { int i, start; double h, sum, x; h = 1.0 /
- 22. Москва, 2012 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из 46 из 46 Конфликт
- 23. #include "mpi.h" #include int main (int argc, char *argv[]) { int n =100000, myid, numprocs, i;
- 24. for (i = myid + 1; i { x = h * ((double)i - 0.5); sum
- 25. #include int main () { int n =100000, i; double pi, h, sum, x; h =
- 26. Достоинства использования OpenMP вместо MPI для многоядерных процессоров Возможность инкрементального распараллеливания Упрощение программирования и эффективность на
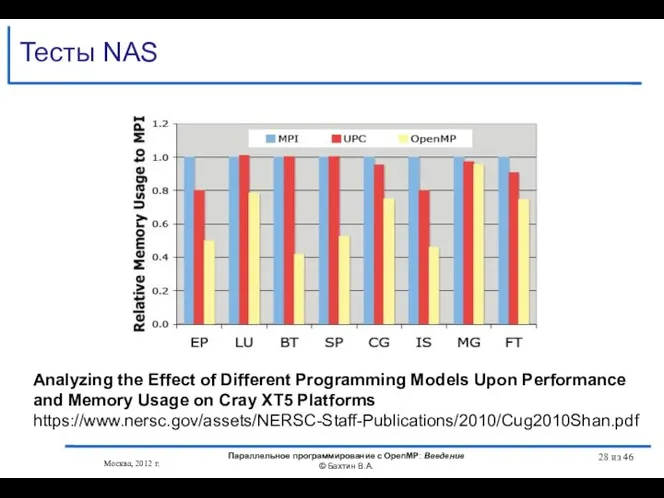
- 27. Тесты NAS Москва, 2012 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из 46
- 28. Тесты NAS Москва, 2012 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из 46 Analyzing
- 29. Тесты NAS Москва, 2012 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из 46 Analyzing
- 30. Достоинства использования OpenMP вместо MPI для многоядерных процессоров #define Max(a,b) ((a)>(b)?(a):(b)) #define L 8 #define ITMAX
- 31. Достоинства использования OpenMP вместо MPI для многоядерных процессоров Москва, 2012 г. Параллельное программирование с OpenMP: Введение
- 32. История OpenMP Москва, 2012 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из 46 OpenMP
- 33. OpenMP Architecture Review Board Москва, 2012 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из
- 34. Компиляторы, поддерживающие OpenMP Москва, 2012 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из 46
- 35. Обзор основных возможностей OpenMP omp_set_lock(lck) #pragma omp parallel for private(a, b) #pragma omp critical C$OMP PARALLEL
- 36. Все процессоры имеют доступ к любой точке памяти с одинаковой скоростью. Процессоры подключены к памяти либо
- 37. Fujitsu SPARC Enterprise M9000 SPARC64 VII 2,88 / 2,52 GHz 64 процессоров, 256 ядер, 512 нитей
- 38. Системы с неоднородным доступом к памяти (NUMA) Система состоит из однородных базовых модулей (плат), состоящих из
- 39. Системы с неоднородным доступом к памяти (NUMA) SGI Altix UV (UltraVioloet) 1000 256 Intel® Xeon® quad-,
- 40. Intel Many Integrated Core (MIC) !dir$ offload target(mic) !$omp parallel do do i=1,10 A(i) = B(i)
- 41. Литературa http://www.openmp.org http://www.compunity.org http://www.parallel.ru/tech/tech_dev/openmp.html Москва, 2012 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из
- 42. Литература Антонов А.С. Параллельное программирование с использованием технологии OpenMP: Учебное пособие.-М.: Изд-во МГУ, 2009. http://parallel.ru/info/parallel/openmp/OpenMP.pdf Воеводин
- 43. Литература Учебные курсы Интернет Университета Информационных технологий Гергель В.П. Теория и практика параллельных вычислений. — http://www.intuit.ru/department/calculate/paralltp/
- 44. Вопросы? Вопросы? Москва, 2012 г. Параллельное программирование с OpenMP: Введение © Бахтин В.А. из 46
- 45. OpenMP – модель параллелизма по управлению Следующая тема Москва, 2012 г. Параллельное программирование с OpenMP: Введение
- 47. Скачать презентацию

Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
из
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
из

В течение нескольких десятилетий развитие ЭВМ сопровождалось удвоением их быстродействия каждые
В течение нескольких десятилетий развитие ЭВМ сопровождалось удвоением их быстродействия каждые
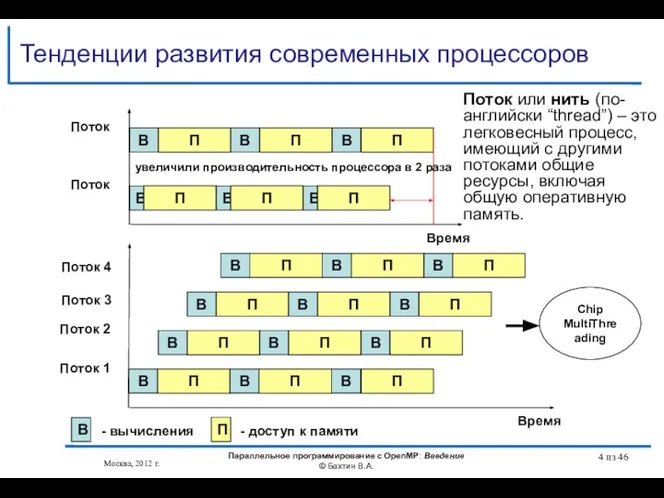
Время
Тенденции развития современных процессоров
В
П
В
П
В
П
В
П
В
П
В
П
Поток
Поток
Время
В
П
В
П
В
П
Поток 1
В
П
В
П
В
П
В
П
В
П
В
П
В
П
В
П
В
П
Поток 2
Поток 3
Поток 4
В
- вычисления
П
- доступ к
Время
Тенденции развития современных процессоров
В
П
В
П
В
П
В
П
В
П
В
П
Поток
Поток
Время
В
П
В
П
В
П
Поток 1
В
П
В
П
В
П
В
П
В
П
В
П
В
П
В
П
В
П
Поток 2
Поток 3
Поток 4
В
- вычисления
П
- доступ к
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
из
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
из

Современные суперкомпьютерные системы
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин
Современные суперкомпьютерные системы
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение © Бахтин

Современные суперкомпьютерные системы
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин
Современные суперкомпьютерные системы
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение © Бахтин

Тенденции развития современных процессоров
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
©
Тенденции развития современных процессоров
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение ©

Тенденции развития современных процессоров
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
©
Тенденции развития современных процессоров
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение ©

Тенденции развития современных процессоров
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
©
Тенденции развития современных процессоров
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение ©

Тенденции развития современных процессоров
Intel Itanium 9350 (Tukwila) 1,73 ГГц
4 ядeр
8 потоков
Тенденции развития современных процессоров
Intel Itanium 9350 (Tukwila) 1,73 ГГц
4 ядeр
8 потоков

Тенденции развития современных процессоров
IBM Power7
3,5 - 4,0 ГГц
8 ядер x 4
Тенденции развития современных процессоров
IBM Power7
3,5 - 4,0 ГГц
8 ядер x 4

Тенденции развития современных процессоров
Темпы уменьшения латентности памяти гораздо ниже темпов ускорения
Тенденции развития современных процессоров
Темпы уменьшения латентности памяти гораздо ниже темпов ускорения

Существующие подходы для создания параллельных программ
Автоматическое / автоматизированное распараллеливание
Библиотеки нитей
Win32 API
POSIX
Библиотеки
Существующие подходы для создания параллельных программ
Автоматическое / автоматизированное распараллеливание
Библиотеки нитей
Win32 API
POSIX
Библиотеки
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
из
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
из

#include
int main ()
{
int n =100000, i;
double pi, h,
#include
int main ()
{
int n =100000, i;
double pi, h,

Автоматическое распараллеливание
Polaris, CAPO, WPP, SUIF, VAST/Parallel, OSCAR, Intel/OpenMP, UTL
icc -parallel
Автоматическое распараллеливание
Polaris, CAPO, WPP, SUIF, VAST/Parallel, OSCAR, Intel/OpenMP, UTL
icc -parallel

Автоматизированное распараллеливание
Intel/GAP (Guided Auto-Parallel), CAPTools/ParaWise, BERT77, FORGE Magic/DM, ДВОР (Диалоговый
Автоматизированное распараллеливание
Intel/GAP (Guided Auto-Parallel), CAPTools/ParaWise, BERT77, FORGE Magic/DM, ДВОР (Диалоговый

Автоматизированное распараллеливание
test.cpp(49): remark #30521: (PAR) Loop at line 49 cannot be
Автоматизированное распараллеливание
test.cpp(49): remark #30521: (PAR) Loop at line 49 cannot be

#include
#include
#define NUM_THREADS 2
CRITICAL_SECTION hCriticalSection;
double pi = 0.0;
int n =100000;
void
#include
#include
#define NUM_THREADS 2
CRITICAL_SECTION hCriticalSection;
double pi = 0.0;
int n =100000;
void

void Pi (void *arg)
{
int i, start;
double h, sum, x;
void Pi (void *arg)
{
int i, start;
double h, sum, x;

Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
из
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
из
![#include "mpi.h" #include int main (int argc, char *argv[]) { int](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1266828/slide-22.jpg)
#include "mpi.h"
#include
int main (int argc, char *argv[])
{
int n =100000,
#include "mpi.h"
#include
int main (int argc, char *argv[])
{
int n =100000,

for (i = myid + 1; i <= n; i
for (i = myid + 1; i <= n; i

#include
int main ()
{
int n =100000, i;
double pi, h,
#include
int main ()
{
int n =100000, i;
double pi, h,

Достоинства использования OpenMP вместо MPI
для многоядерных процессоров
Возможность инкрементального распараллеливания
Упрощение программирования и
Достоинства использования OpenMP вместо MPI
для многоядерных процессоров
Возможность инкрементального распараллеливания
Упрощение программирования и

Тесты NAS
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
Тесты NAS
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
Тесты NAS
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
Тесты NAS
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
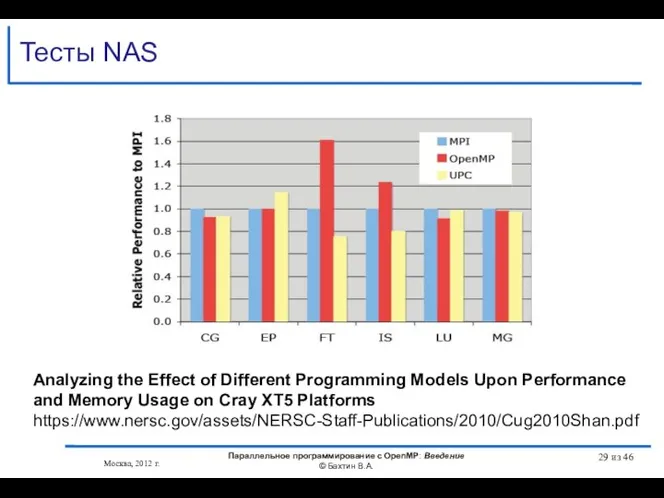
Тесты NAS
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
Тесты NAS
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.

Достоинства использования OpenMP вместо MPI
для многоядерных процессоров
#define Max(a,b) ((a)>(b)?(a):(b))
#define L 8
#define
Достоинства использования OpenMP вместо MPI
для многоядерных процессоров
#define Max(a,b) ((a)>(b)?(a):(b))
#define L 8
#define

Достоинства использования OpenMP вместо MPI
для многоядерных процессоров
Москва, 2012 г.
Параллельное программирование с
Достоинства использования OpenMP вместо MPI
для многоядерных процессоров
Москва, 2012 г.
Параллельное программирование с
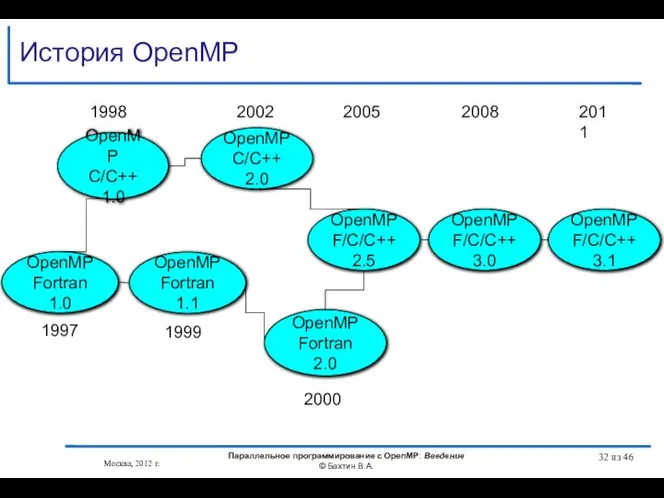
История OpenMP
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
История OpenMP
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
OpenMP Architecture Review Board
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
©
OpenMP Architecture Review Board
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение ©

Компиляторы, поддерживающие OpenMP
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин
Компиляторы, поддерживающие OpenMP
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение © Бахтин
Обзор основных возможностей OpenMP
omp_set_lock(lck)
#pragma omp parallel for private(a, b)
#pragma omp critical
C$OMP
Обзор основных возможностей OpenMP
omp_set_lock(lck)
#pragma omp parallel for private(a, b)
#pragma omp critical
C$OMP
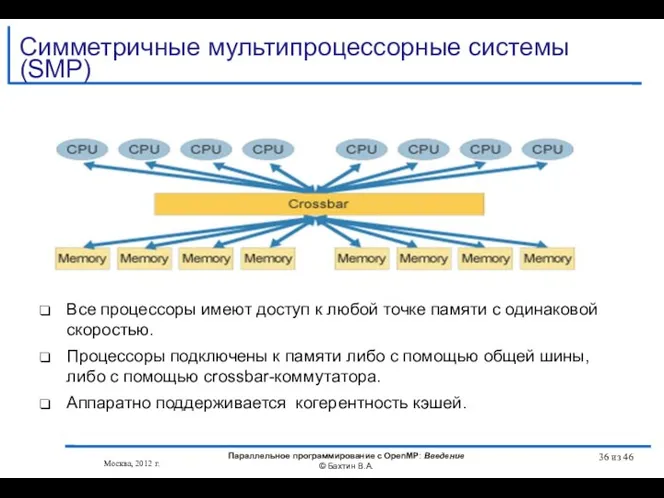
Все процессоры имеют доступ к любой точке памяти с одинаковой скоростью.
Процессоры
Все процессоры имеют доступ к любой точке памяти с одинаковой скоростью.
Процессоры

Fujitsu SPARC Enterprise M9000
SPARC64 VII 2,88 / 2,52 GHz
64 процессоров, 256
Fujitsu SPARC Enterprise M9000
SPARC64 VII 2,88 / 2,52 GHz
64 процессоров, 256
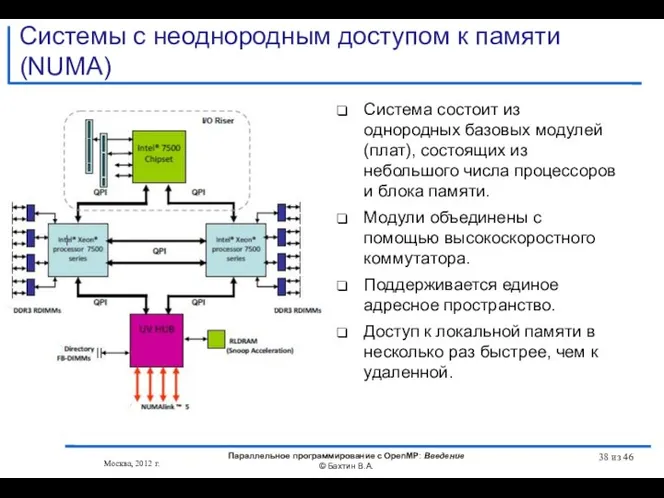
Системы с неоднородным доступом к памяти (NUMA)
Система состоит из однородных базовых
Системы с неоднородным доступом к памяти (NUMA)
Система состоит из однородных базовых

Системы с неоднородным доступом к памяти (NUMA)
SGI Altix UV (UltraVioloet) 1000
256
Системы с неоднородным доступом к памяти (NUMA)
SGI Altix UV (UltraVioloet) 1000
256

Intel Many Integrated Core (MIC)
!dir$ offload target(mic)
!$omp parallel do
do i=1,10
Intel Many Integrated Core (MIC)
!dir$ offload target(mic)
!$omp parallel do
do i=1,10

Литературa
http://www.openmp.org
http://www.compunity.org
http://www.parallel.ru/tech/tech_dev/openmp.html
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
из
Литературa
http://www.openmp.org
http://www.compunity.org
http://www.parallel.ru/tech/tech_dev/openmp.html
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
из

Литература
Антонов А.С. Параллельное программирование с использованием технологии OpenMP: Учебное пособие.-М.:
Литература
Антонов А.С. Параллельное программирование с использованием технологии OpenMP: Учебное пособие.-М.:

Литература
Учебные курсы Интернет Университета Информационных технологий
Гергель В.П. Теория и практика
Литература
Учебные курсы Интернет Университета Информационных технологий
Гергель В.П. Теория и практика

Вопросы?
Вопросы?
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
из
Вопросы?
Вопросы?
Москва, 2012 г.
Параллельное программирование с OpenMP: Введение
© Бахтин В.А.
из

OpenMP – модель параллелизма по управлению
Следующая тема
Москва, 2012 г.
Параллельное программирование
OpenMP – модель параллелизма по управлению
Следующая тема
Москва, 2012 г.
Параллельное программирование
 Ветвление в построчной записи алгоритма ЕСЛИ-ТО ЕСЛИ-ТО-ИНАЧЕ
Ветвление в построчной записи алгоритма ЕСЛИ-ТО ЕСЛИ-ТО-ИНАЧЕ Выпускная квалификационная работа на тему: Разработка информационной системы Стройотряд
Выпускная квалификационная работа на тему: Разработка информационной системы Стройотряд Преобразование презентаций PowerPoint
Преобразование презентаций PowerPoint PLC izvēle
PLC izvēle Оперативная память
Оперативная память Аппаратное и программное обеспечение обработки данных на ЭВМ. Лекция 4.2
Аппаратное и программное обеспечение обработки данных на ЭВМ. Лекция 4.2 Основы программирования на языке Pascal. Алфавит, типы данных, структура программ. Основные операторы
Основы программирования на языке Pascal. Алфавит, типы данных, структура программ. Основные операторы Кодирование и обработка текстовой информации
Кодирование и обработка текстовой информации Операторы языка С++
Операторы языка С++ Prepositions of time
Prepositions of time Преобразование логических выражений Составила: Антонова Е.П. По задачнику-практикуму под ред. Семакина И.Г. 2008г.
Преобразование логических выражений Составила: Антонова Е.П. По задачнику-практикуму под ред. Семакина И.Г. 2008г. ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ В РОБОТОТЕХНИКЕ Подготовила: студентка ИТ -11 Луговая Алина
ИСКУССТВЕННЫЙ ИНТЕЛЛЕКТ В РОБОТОТЕХНИКЕ Подготовила: студентка ИТ -11 Луговая Алина  Основные типы алгоритмов. Линейные алгоритмы.
Основные типы алгоритмов. Линейные алгоритмы. Медиадокументы
Медиадокументы Векторная графика CorelDraw Цель урока: - получить представление векторной графической программе CorelDraw, для создания изображений, д
Векторная графика CorelDraw Цель урока: - получить представление векторной графической программе CorelDraw, для создания изображений, д 6. Процедуры и функции
6. Процедуры и функции Презентация "Базы данных и информационные системы. Основные понятия" - скачать презентации по Информатике
Презентация "Базы данных и информационные системы. Основные понятия" - скачать презентации по Информатике Windows 2000
Windows 2000 Построение базы данных
Построение базы данных Создание сайта салона мягкой мебели Интерьер Холл
Создание сайта салона мягкой мебели Интерьер Холл Презентация "Информация и информационные процессы в технике" - скачать презентации по Информатике_
Презентация "Информация и информационные процессы в технике" - скачать презентации по Информатике_ Оператор повторения Цикл for…to…do Цикл for…downto…do
Оператор повторения Цикл for…to…do Цикл for…downto…do Системы цифровой обработки изображений
Системы цифровой обработки изображений Microsoft® Office Access 2007. Быстрое освоение программы
Microsoft® Office Access 2007. Быстрое освоение программы Создание интерактивной игры с помощью онлайн-платформы Canva и онлайн-сервиса LearningApps
Создание интерактивной игры с помощью онлайн-платформы Canva и онлайн-сервиса LearningApps Функциональные зависимости в реляционной модели данных. Декомпозиция. Нормальные формы
Функциональные зависимости в реляционной модели данных. Декомпозиция. Нормальные формы Обработка текста на компьютере
Обработка текста на компьютере Рубрикатор 2GIS
Рубрикатор 2GIS