- Принципы сжатия видеоинформации

Содержание
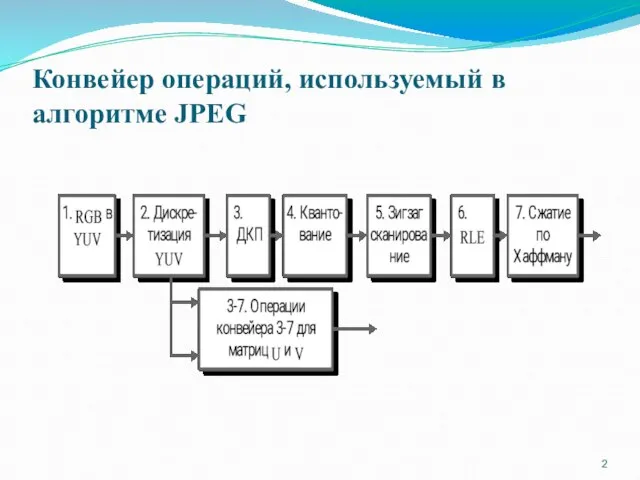
- 2. Конвейер операций, используемый в алгоритме JPEG
- 3. Шаги преобразования 1 шаг. Преобразования цветового пространства в сигнал яркости Y и два цветоразностных сигнала U
- 4. 1 шаг. Преобразования цветового пространства в сигнал яркости Y и два цветоразностных сигнала U и V.
- 5. 2 шаг. Прореживание U и V данных цветности Прореживание U и V данных цветности. При прореживании
- 6. 3 шаг. Преобразование блоков изображения при помощи двухмерного ДКП Преобразование небольших блоков изображения при помощи двухмерного
- 7. 4 шаг. Операция квантования Матрица проходит операцию квантования, которая позволяет сократить разрядность коэффициентов. Это математически соответствует
- 8. 5 шаг. Матрица вытягивается в строку данных. Матрица после квантования вытягивается в строку данных так, что
- 9. 6 Шаг. Статистическое кодирование по методу Хаффмана Статистическое кодирование по методу Хаффмана, считается, что этот метод
- 10. Положительными сторонами алгоритма является то, что: Задается степень сжатия. Выходное цветное изображение может иметь 24 бита
- 12. Алгоритм Хаффмана Классический алгоритм Хаффмана. Алгоритм использует только частоту появления одинаковых байт в изображении. Сопоставляет символам
- 13. Определения Определение 1 Пусть задан алфавит ψ = {a1, ……ar}, состоящий из конечного числа букв. Конечную
- 14. Определение 2. Рассмотрим соответствие между буквами алфавита Y и некоторыми словами алфавита Ω: а1 -- В
- 15. Определение 3. Пусть слово В имеет вид В = В’B” (1.7) Тогда слово В’ называется началом
- 16. Схема S обладает свойством префикса, если для любых i и j (1 ≤ i, j ≤
- 17. Определение 5. Коды, определяемые схемой с lср = l*, называются кодами с минимальной избыточностью или кодами
- 18. Алгоритм построения схемы Шаг 1. Упорядочиваем все буквы входного алфавита в порядке убывания вероятности. Считаем все
- 19. Пример: Пусть у нас есть 4 буквы в алфавите Ψ = {а1, a r} (r =4),
- 20. Производя действия, соответствующие 2-му шагу, мы получаем псевдосимвол с вероятностью 0.26 (и приписываем 0 и 1
- 21. Характеристики классического алгоритма Хаффмана: Коэффициенты компрессии: 8, 1,5, 1 (Лучший, средний, худший коэффициенты). Класс изображений: Практически
- 22. Векторное квантование Считается перспективным и используется в JPEG векторное квантование. Векторное квантование эффективно, когда требуемое число
- 24. Скачать презентацию
Конвейер операций, используемый в алгоритме JPEG
Конвейер операций, используемый в алгоритме JPEG

Шаги преобразования
1 шаг. Преобразования цветового пространства в сигнал яркости Y и
Шаги преобразования
1 шаг. Преобразования цветового пространства в сигнал яркости Y и

1 шаг. Преобразования цветового пространства в сигнал яркости Y и два
1 шаг. Преобразования цветового пространства в сигнал яркости Y и два

2 шаг. Прореживание U и V данных цветности
Прореживание U и V
2 шаг. Прореживание U и V данных цветности
Прореживание U и V

3 шаг. Преобразование блоков изображения при помощи двухмерного ДКП
Преобразование небольших
3 шаг. Преобразование блоков изображения при помощи двухмерного ДКП
Преобразование небольших

4 шаг. Операция квантования
Матрица проходит операцию квантования, которая позволяет сократить разрядность
4 шаг. Операция квантования
Матрица проходит операцию квантования, которая позволяет сократить разрядность

5 шаг. Матрица вытягивается в строку данных.
Матрица после квантования вытягивается
5 шаг. Матрица вытягивается в строку данных.
Матрица после квантования вытягивается

6 Шаг. Статистическое кодирование по методу Хаффмана
Статистическое кодирование по методу Хаффмана,
6 Шаг. Статистическое кодирование по методу Хаффмана
Статистическое кодирование по методу Хаффмана,

Положительными сторонами алгоритма является то, что:
Задается степень сжатия.
Выходное цветное
Положительными сторонами алгоритма является то, что:
Задается степень сжатия.
Выходное цветное


Алгоритм Хаффмана
Классический алгоритм Хаффмана.
Алгоритм использует только частоту появления одинаковых байт в
Алгоритм Хаффмана
Классический алгоритм Хаффмана.
Алгоритм использует только частоту появления одинаковых байт в

Определения
Определение 1
Пусть задан алфавит ψ = {a1, ……ar}, состоящий из
Определения
Определение 1
Пусть задан алфавит ψ = {a1, ……ar}, состоящий из

Определение 2.
Рассмотрим соответствие между буквами алфавита Y и некоторыми словами алфавита
Определение 2.
Рассмотрим соответствие между буквами алфавита Y и некоторыми словами алфавита

Определение 3.
Пусть слово В имеет вид
В = В’B” (1.7)
Тогда слово
Определение 3.
Пусть слово В имеет вид
В = В’B” (1.7)
Тогда слово

Схема S обладает свойством префикса,
если для любых i и j
если для любых i и j

Определение 5.
Коды, определяемые схемой с lср = l*, называются кодами с
Определение 5.
Коды, определяемые схемой с lср = l*, называются кодами с

Алгоритм построения схемы
Шаг 1.
Упорядочиваем все буквы входного алфавита в порядке
Алгоритм построения схемы
Шаг 1.
Упорядочиваем все буквы входного алфавита в порядке

Пример:
Пусть у нас есть 4 буквы в алфавите Ψ =
Пример:
Пусть у нас есть 4 буквы в алфавите Ψ =

Производя действия, соответствующие 2-му шагу, мы получаем псевдосимвол с вероятностью 0.26
Производя действия, соответствующие 2-му шагу, мы получаем псевдосимвол с вероятностью 0.26

Характеристики классического алгоритма Хаффмана:
Коэффициенты компрессии: 8, 1,5, 1 (Лучший, средний, худший
Характеристики классического алгоритма Хаффмана:
Коэффициенты компрессии: 8, 1,5, 1 (Лучший, средний, худший

Векторное квантование
Считается перспективным и используется в JPEG векторное квантование.
Векторное квантование эффективно,
Векторное квантование
Считается перспективным и используется в JPEG векторное квантование.
Векторное квантование эффективно,
 Data Modeling and Databases Lab 3: Introduction to SQL
Data Modeling and Databases Lab 3: Introduction to SQL Операционная система
Операционная система Величини логічного типу, операції над ними. Алгоритми з розгалуженнями для опрацювання величин
Величини логічного типу, операції над ними. Алгоритми з розгалуженнями для опрацювання величин Designing Security for Microsoft® Networks
Designing Security for Microsoft® Networks Базы данных - 4
Базы данных - 4 Базовый курс Robin. Методология внедрения программных роботов
Базовый курс Robin. Методология внедрения программных роботов Живая лексика интернета
Живая лексика интернета Система и окружающая среда. Урок информатики в 7 классе
Система и окружающая среда. Урок информатики в 7 классе Устройство обработки информации Процессор
Устройство обработки информации Процессор Интерактивные викторины для пользователей детских и школьных библиотек. Мультимедийный конспект лекции № 2
Интерактивные викторины для пользователей детских и школьных библиотек. Мультимедийный конспект лекции № 2 Город, о котором я мечтаю
Город, о котором я мечтаю Кодирование текстовой информации. Кодировки русского алфавита
Кодирование текстовой информации. Кодировки русского алфавита Выявление и отбор документов для публикации
Выявление и отбор документов для публикации Принципи організації розподілених інформаційних систем на основі баз даних та експертних систем в освіті
Принципи організації розподілених інформаційних систем на основі баз даних та експертних систем в освіті Microsoft Office бағдарламасында құжат құру
Microsoft Office бағдарламасында құжат құру Microsoft Excel для создания информационных объектов Выполнил: студент гр. МиИ-5Б Иванов Леонид Юрьевич Руководитель: Софронова Натал
Microsoft Excel для создания информационных объектов Выполнил: студент гр. МиИ-5Б Иванов Леонид Юрьевич Руководитель: Софронова Натал Создание кроссворда средствами Microsoft Word
Создание кроссворда средствами Microsoft Word Алгоритм, свойства алгоритма, исполнители алгоритмов Компьютер как формальный исполнитель алгоритмов
Алгоритм, свойства алгоритма, исполнители алгоритмов Компьютер как формальный исполнитель алгоритмов Крылов А.П. Лабораторная работа №2 Коммуникативная природа информационного общества
Крылов А.П. Лабораторная работа №2 Коммуникативная природа информационного общества Системы перевода и распознования текстов
Системы перевода и распознования текстов Многомерные массивы. Занятие 9
Многомерные массивы. Занятие 9 Git – система контроля версий
Git – система контроля версий Word Pad мәтіндік редакторымен жұмыс
Word Pad мәтіндік редакторымен жұмыс Файлы и файловая система
Файлы и файловая система Какие СМИ я читаю и почему
Какие СМИ я читаю и почему Авторы работы: Новоселов Виталий Аношкина Карина Место выполнения работы: МОУ «СОШ №
Авторы работы: Новоселов Виталий Аношкина Карина Место выполнения работы: МОУ «СОШ № Blowfish — криптографический алгоритм. Twofish — симметричный алгоритм блочного шифрования
Blowfish — криптографический алгоритм. Twofish — симметричный алгоритм блочного шифрования Совмещение изображений
Совмещение изображений