- Работа с составными типами данных. Применение коллекций, записей и объектных типов

Содержание
- 2. Рассматриваемые вопросы Создание пользовательских записей PL/SQL Создание записи с атрибутом %ROWTYPE Создание таблицы PL/SQL INDEX BY
- 3. Составные типы данных Два типа данных: PL/SQL RECORDs (записи) PL/SQL коллекции Nested table collections (Вложенные таблицы),
- 4. DECLARE m_COMPANY VARCHAR2(30); m_CUST_REP INTEGER; m_CREDIT_LIMIT NUMBER; Но иногда удобнее использовать, так называемый составной тип. Одним
- 5. Для создания записи необходимо: Объявить тип данных RECORD; Объявить переменную этого типа данных. TYPE type_name IS
- 6. SQL> SET SERVEROUTPUT ON SQL> DECLARE 2 TYPE is_SmplRec IS RECORD 3 ( 4 m_Fld1 VARCHAR2(10),
- 7. SET SERVEROUTPUT ON DECLARE TYPE is_SmplRecOne IS RECORD ( m_Fld1 VARCHAR2(10), m_Fld2 VARCHAR2(30), m_DtFld DATE, m_Fld3
- 8. DECLARE TYPE is_Customers IS RECORD ( m_COMPANY CUSTOMERS.COMPANY%TYPE, m_CUST_REP CUSTOMERS.CUST_REP%TYPE, m_CREDIT_LIMIT CUSTOMERS.CREDIT_LIMIT%TYPE ); MY_CUST is_Customers; BEGIN
- 9. Атрибут %ROWTYPE Используется для объявления переменной типа "запись« на основе совокупности столбцов в таблице или представлении
- 10. Составной тип TABLE! В своей сути это одномерный массив скалярного типа. Он не может содержать тип
- 11. SET SERVEROUTPUT ON DECLARE TYPE m_SmplTable IS TABLE OF VARCHAR2(128) INDEX BY BINARY_INTEGER; TYPE m_SmplTblData IS
- 12. Преимущества использования %ROWTYPE Количество базовых столбцов базы данных и типы данных в них могут быть неизвестны.
- 13. Атрибут %ROWTYPE В первом объявлении на слайде создается запись с такими же именами полей и типами
- 14. DECLARE TYPE is_Customers IS TABLE OF CUSTOMERS%ROWTYPE INDEX BY BINARY_INTEGER; MY_CUST is_Customers; BEGIN SELECT * INTO
- 15. The %ROWTYPE Attribute ... DEFINE employee_number = 124 DECLARE emp_rec employees%ROWTYPE; BEGIN SELECT * INTO emp_rec
- 16. ... DEFINE employee_number = 124 DECLARE emp_rec retired_emps%ROWTYPE; BEGIN SELECT employee_id, last_name, job_id, manager_id, hire_date, hire_date,
- 17. SET SERVEROUTPUT ON SET VERIFY OFF DEFINE employee_number = 124 DECLARE emp_rec retired_emps%ROWTYPE; BEGIN SELECT *
- 18. SQL> SET SERVEROUTPUT ON SQL> DECLARE TYPE m_SmplTable IS TABLE OF VARCHAR2(128) INDEX BY BINARY_INTEGER; MY_TBL
- 19. SET SERVEROUTPUT ON -- DELETE DECLARE TYPE m_SmplTable IS TABLE OF VARCHAR2(128) INDEX BY BINARY_INTEGER; MY_TBL
- 20. SET SERVEROUTPUT ON -- EXISTS DECLARE TYPE m_SmplTable IS TABLE OF VARCHAR2(128) INDEX BY BINARY_INTEGER; MY_TBL
- 21. Расширения оператора GROUP BY Операторы ROLLUP, CUBE и GROUPING SETS являются расширениями предложения GROUP BY. Операторы
- 22. Пример. Запрос просуммировал данные по зарплатам на уровнях по отделам, должностям и подвел общий итог
- 23. Функция CUBE Оператор CUBE формирует результирующий набор, представляющий собой многомерный куб. То есть, результирующий набор содержит
- 24. Пример ниже показывает запрос, ранее уже использованный, но с функцией CUBE для получения дополнительной агрегированной информации:
- 25. Различия между CUBE и ROLLUP: CUBE создает результирующий набор, содержащий статистические выражения для всех комбинаций значений
- 26. Пример:
- 27. Функция GROUPING SETS GROUPING SETS является дальнейшее расширение предложения GROUP BY, которые можно использовать для указания
- 28. Следующий запрос вычисляет все 8 (2 * 2 * 2) группировки, но только по группам: SELECT
- 29. Объединение группировок Объединение групп - краткий путь для создания полезной комбинации группировок. Каскадной группировки указано, перечислив
- 31. Интерактивный запрос значений переменных в командах Oracle При рассмотрении команды INSERT мы использовали переменную подстановки. Достаточно
- 32. Переменные в SQL*Plus можно предопределить с помощью команд ACCEPT или DEFINE. Команда ACCEPT считывает строку пользовательских
- 33. Пользовательские переменные можно определять до выполнения команды SELECT. Для определения и установки значений пользовательских переменных SQL*Plus
- 34. Пример: Напишите запрос, который вы выводил информацию об имени, фамилии и заработной плате сотрудников из таблицы
- 36. Конструкции MERGE и WITH Оператор MERGE MERGE — DML-оператор вставки (INSERT)/обновления (UPDATE)/удаления (DELETE, начиная с Oracle
- 37. Пример. Следующий пример использует таблицу BONUSES в примере схемы ОЕ со значением бонуса по умолчанию в
- 38. 4) SELECT * FROM bonuses ORDER BY employee_id; EMPLOYEE_ID BONUS ----------- ------ 153 100 154 100
- 39. 6) SELECT * FROM bonuses ORDER BY employee_id; EMPLOYEE_ID BONUS ----------------- ----------- 153 180 154 175
- 40. Пример : Слияние строк - пример показывает соответствия EMPLOYEE_ID в таблице COPY_EMP к EMPLOYEE_ID в таблице
- 41. Использование конструкции WITH Oracle допускает вынесение определений подзапросов из тела основного запроса с помощью особой фразы
- 42. WITH A AS ( SELECT ... ) , B AS ( SELECT ... FROM x )
- 43. Пример . Запрос создает запросы DEPT_COSTS и AVG_COST, а затем использует их в теле основного запроса.
- 44. Формулирование рекурсивных запросов С версии Oracle 11.2 фраза WITH может использоваться для формулирования рекурсивных запросов, в
- 45. Предложение SELECT для исходного множества строк Oracle называет опорным (anchor) членом фразы WITH. Предложение SELECT для
- 46. Операция UNION ALL здесь используется символически, в рамках определенного контекста, для указания способа рекурсивного накопления результата.
- 47. Пример с дополнительным разъяснением способа выполнения: SQL> WITH 2 anchor1234 ( n ) AS ( --
- 48. Пример. Вычислить какое количество сотрудников ежегодно поступает на работу с 2002 по 2010 гг. WITH period
- 49. Необязательный оператор START WITH (начать с) - если задано, то позволяет указать, с какой вершины (строки)
- 51. Чтобы получить нормальную иерархию нужно использовать специальный оператор, который называется PRIOR. Это обычный унарный оператор, точно
- 52. 3. Oracle выбирает следующие одно за другим поколения дочерних строк. Сначала выбираются потомки строк, полученных на
- 54. Пример . Показать менеджеров и сотрудников пока employee_id=101. SELECT employee_id, last_name, job_id, manager_id FROM employees START
- 55. Оператор SELECT, осуществляющий древовидный запрос, может использовать псевдостолбец LEVEL, содержащий уровень вложенности для каждой строки. Для
- 57. Используя функцию LPAD и псевдостолбец LEVEL можно украсить выводимый результат, предварительно отформатировав столбец «tree» : SELECT
- 58. Напишем запрос, который возвращал бы из таблицы hr.employees информацию: имя сотрудника; фамилию сотрудника; уровень подчиненности (самый
- 60. Чтобы указать БД в Oracle, что сортировать надо только в пределах одного уровня иерархии, нам поможет
- 61. Транзакции в Oracle SQL. В Oracle нет явного оператора, чтобы начать транзакцию, но и нет автоматического
- 62. COMMIT - завершает транзакцию и делает любые выполненные в ней изменения постоянными. Освобождаются блокировки. ROLLBACK -
- 63. Некоторые особенности выполнения транзакций в Oracle: 1.Транзакция обычно состоит из нескольких операторов DML. Если один оператор
- 64. 3. Oracle анонимный блок PL/SQL считает оператором. Например, begin оператор1; оператор2; end; То есть для него
- 65. Распределённая транзакция имеет то же свойство, что и обычная: все или ничего. Только фиксация происходит в
- 67. Скачать презентацию

Рассматриваемые вопросы
Создание пользовательских записей PL/SQL
Создание записи с атрибутом %ROWTYPE
Создание таблицы
Рассматриваемые вопросы
Создание пользовательских записей PL/SQL
Создание записи с атрибутом %ROWTYPE
Создание таблицы

Составные типы данных
Два типа данных:
PL/SQL RECORDs (записи)
PL/SQL коллекции
Nested table collections
Составные типы данных
Два типа данных:
PL/SQL RECORDs (записи)
PL/SQL коллекции
Nested table collections

DECLARE
m_COMPANY VARCHAR2(30);
m_CUST_REP INTEGER;
m_CREDIT_LIMIT NUMBER;
Но иногда удобнее использовать, так называемый составной тип.
DECLARE
m_COMPANY VARCHAR2(30);
m_CUST_REP INTEGER;
m_CREDIT_LIMIT NUMBER;
Но иногда удобнее использовать, так называемый составной тип.

Для создания записи необходимо:
Объявить тип данных RECORD;
Объявить переменную этого типа данных.
Для создания записи необходимо:
Объявить тип данных RECORD;
Объявить переменную этого типа данных.

SQL> SET SERVEROUTPUT ON
SQL> DECLARE
2 TYPE is_SmplRec IS RECORD
3 (
SQL> SET SERVEROUTPUT ON
SQL> DECLARE
2 TYPE is_SmplRec IS RECORD
3 (

SET SERVEROUTPUT ON
DECLARE
TYPE is_SmplRecOne IS RECORD
( m_Fld1 VARCHAR2(10),
m_Fld2
SET SERVEROUTPUT ON
DECLARE
TYPE is_SmplRecOne IS RECORD
( m_Fld1 VARCHAR2(10),
m_Fld2

DECLARE
TYPE is_Customers IS RECORD
(
m_COMPANY CUSTOMERS.COMPANY%TYPE,
m_CUST_REP CUSTOMERS.CUST_REP%TYPE,
m_CREDIT_LIMIT CUSTOMERS.CREDIT_LIMIT%TYPE
);
MY_CUST is_Customers;
BEGIN
SELECT COMPANY, CUST_REP,
DECLARE
TYPE is_Customers IS RECORD
(
m_COMPANY CUSTOMERS.COMPANY%TYPE,
m_CUST_REP CUSTOMERS.CUST_REP%TYPE,
m_CREDIT_LIMIT CUSTOMERS.CREDIT_LIMIT%TYPE
);
MY_CUST is_Customers;
BEGIN
SELECT COMPANY, CUST_REP,

Атрибут %ROWTYPE
Используется для объявления переменной типа "запись« на основе совокупности столбцов
Атрибут %ROWTYPE
Используется для объявления переменной типа "запись« на основе совокупности столбцов

Составной тип TABLE! В своей сути это одномерный массив скалярного типа.
Составной тип TABLE! В своей сути это одномерный массив скалярного типа.

SET SERVEROUTPUT ON
DECLARE
TYPE m_SmplTable IS TABLE OF VARCHAR2(128)
INDEX BY BINARY_INTEGER;
TYPE m_SmplTblData
SET SERVEROUTPUT ON
DECLARE
TYPE m_SmplTable IS TABLE OF VARCHAR2(128)
INDEX BY BINARY_INTEGER;
TYPE m_SmplTblData

Преимущества использования %ROWTYPE
Количество базовых столбцов базы данных и типы данных в
Преимущества использования %ROWTYPE
Количество базовых столбцов базы данных и типы данных в

Атрибут %ROWTYPE
В первом объявлении на слайде создается запись с такими же
Атрибут %ROWTYPE
В первом объявлении на слайде создается запись с такими же

DECLARE
TYPE is_Customers IS TABLE OF CUSTOMERS%ROWTYPE
INDEX BY BINARY_INTEGER;
MY_CUST is_Customers;
BEGIN
SELECT * INTO
DECLARE
TYPE is_Customers IS TABLE OF CUSTOMERS%ROWTYPE
INDEX BY BINARY_INTEGER;
MY_CUST is_Customers;
BEGIN
SELECT * INTO

The %ROWTYPE Attribute
...
DEFINE employee_number = 124
DECLARE
emp_rec employees%ROWTYPE;
BEGIN
SELECT
The %ROWTYPE Attribute
...
DEFINE employee_number = 124
DECLARE
emp_rec employees%ROWTYPE;
BEGIN
SELECT

...
DEFINE employee_number = 124
DECLARE
emp_rec retired_emps%ROWTYPE;
BEGIN
SELECT employee_id, last_name, job_id, manager_id,
...
DEFINE employee_number = 124
DECLARE
emp_rec retired_emps%ROWTYPE;
BEGIN
SELECT employee_id, last_name, job_id, manager_id,
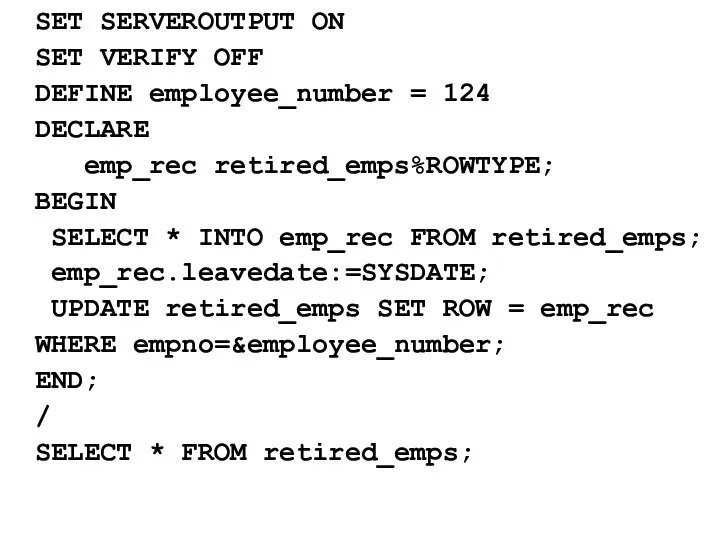
SET SERVEROUTPUT ON
SET VERIFY OFF
DEFINE employee_number = 124
DECLARE
emp_rec retired_emps%ROWTYPE;
BEGIN
SELECT
SET SERVEROUTPUT ON
SET VERIFY OFF
DEFINE employee_number = 124
DECLARE
emp_rec retired_emps%ROWTYPE;
BEGIN
SELECT

SQL> SET SERVEROUTPUT ON
SQL> DECLARE
TYPE m_SmplTable IS TABLE OF VARCHAR2(128)
INDEX BY
SQL> SET SERVEROUTPUT ON
SQL> DECLARE
TYPE m_SmplTable IS TABLE OF VARCHAR2(128)
INDEX BY

SET SERVEROUTPUT ON
-- DELETE
DECLARE
TYPE m_SmplTable IS TABLE OF VARCHAR2(128)
INDEX BY BINARY_INTEGER;
MY_TBL
SET SERVEROUTPUT ON
-- DELETE
DECLARE
TYPE m_SmplTable IS TABLE OF VARCHAR2(128)
INDEX BY BINARY_INTEGER;
MY_TBL

SET SERVEROUTPUT ON
-- EXISTS
DECLARE
TYPE m_SmplTable IS TABLE OF VARCHAR2(128)
INDEX BY BINARY_INTEGER;
MY_TBL
SET SERVEROUTPUT ON
-- EXISTS
DECLARE
TYPE m_SmplTable IS TABLE OF VARCHAR2(128)
INDEX BY BINARY_INTEGER;
MY_TBL

Расширения оператора GROUP BY
Операторы ROLLUP, CUBE и GROUPING SETS являются
Расширения оператора GROUP BY
Операторы ROLLUP, CUBE и GROUPING SETS являются
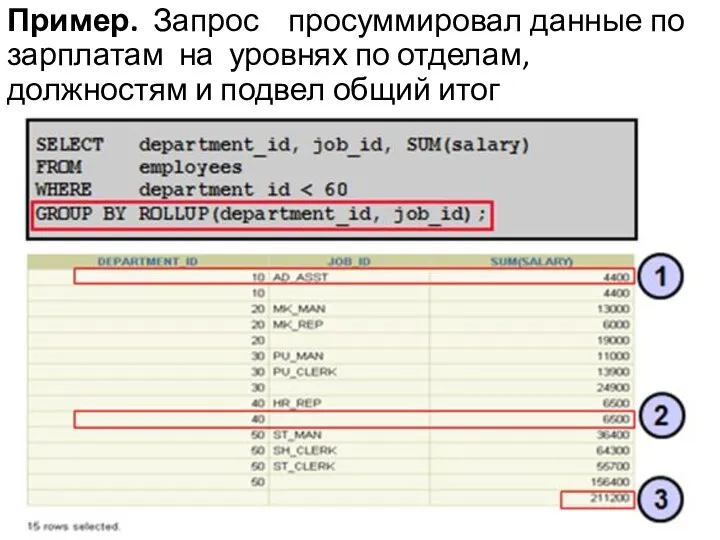
Пример. Запрос просуммировал данные по зарплатам на уровнях по отделам, должностям
Пример. Запрос просуммировал данные по зарплатам на уровнях по отделам, должностям

Функция CUBE
Оператор CUBE формирует результирующий набор, представляющий собой многомерный куб. То
Функция CUBE
Оператор CUBE формирует результирующий набор, представляющий собой многомерный куб. То
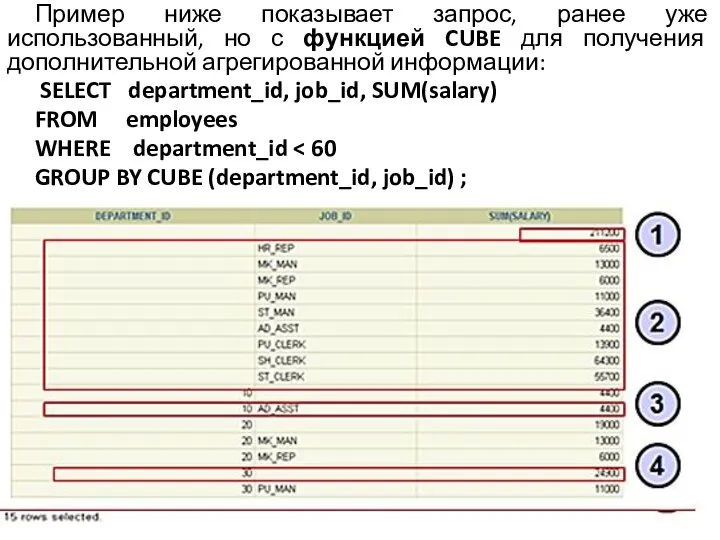
Пример ниже показывает запрос, ранее уже использованный, но с функцией CUBE
Пример ниже показывает запрос, ранее уже использованный, но с функцией CUBE

Различия между CUBE и ROLLUP: CUBE создает результирующий набор, содержащий статистические
Различия между CUBE и ROLLUP: CUBE создает результирующий набор, содержащий статистические
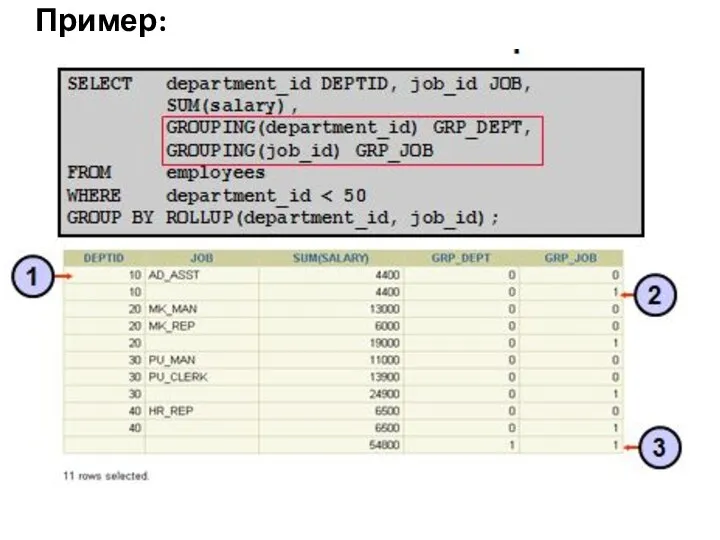
Пример:
Пример:

Функция GROUPING SETS
GROUPING SETS является дальнейшее расширение предложения GROUP BY,
Функция GROUPING SETS
GROUPING SETS является дальнейшее расширение предложения GROUP BY,

Следующий запрос вычисляет все 8 (2 * 2 * 2) группировки,
Следующий запрос вычисляет все 8 (2 * 2 * 2) группировки,

Объединение группировок
Объединение групп - краткий путь для создания полезной комбинации группировок.
Объединение группировок
Объединение групп - краткий путь для создания полезной комбинации группировок.


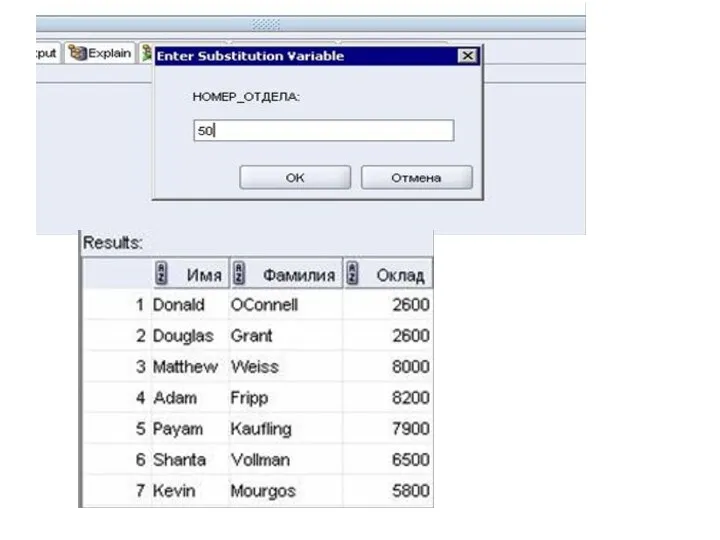
Интерактивный запрос значений переменных в командах Oracle
При рассмотрении команды INSERT
Интерактивный запрос значений переменных в командах Oracle
При рассмотрении команды INSERT

Переменные в SQL*Plus можно предопределить с помощью команд ACCEPT или DEFINE.
Переменные в SQL*Plus можно предопределить с помощью команд ACCEPT или DEFINE.

Пользовательские переменные можно определять до выполнения команды SELECT. Для определения и
Пользовательские переменные можно определять до выполнения команды SELECT. Для определения и

Пример: Напишите запрос, который вы выводил информацию об имени, фамилии и
Пример: Напишите запрос, который вы выводил информацию об имени, фамилии и

Конструкции MERGE и WITH
Оператор MERGE
MERGE — DML-оператор вставки (INSERT)/обновления (UPDATE)/удаления
Конструкции MERGE и WITH
Оператор MERGE
MERGE — DML-оператор вставки (INSERT)/обновления (UPDATE)/удаления

Пример. Следующий пример использует таблицу BONUSES в примере схемы ОЕ со
Пример. Следующий пример использует таблицу BONUSES в примере схемы ОЕ со

4)
SELECT *
FROM bonuses
ORDER BY employee_id;
EMPLOYEE_ID BONUS
----------- ------
4)
SELECT *
FROM bonuses
ORDER BY employee_id;
EMPLOYEE_ID BONUS
----------- ------

6)
SELECT *
FROM bonuses
ORDER BY employee_id;
EMPLOYEE_ID BONUS
----------------- -----------
153
6)
SELECT *
FROM bonuses
ORDER BY employee_id;
EMPLOYEE_ID BONUS
----------------- -----------
153

Пример : Слияние строк - пример показывает соответствия EMPLOYEE_ID в таблице
Пример : Слияние строк - пример показывает соответствия EMPLOYEE_ID в таблице

Использование конструкции WITH
Oracle допускает вынесение определений подзапросов из тела основного
Использование конструкции WITH
Oracle допускает вынесение определений подзапросов из тела основного

WITH
A AS ( SELECT ... )
, B AS (
WITH
A AS ( SELECT ... )
, B AS (

Пример . Запрос создает запросы DEPT_COSTS и AVG_COST, а затем использует
Пример . Запрос создает запросы DEPT_COSTS и AVG_COST, а затем использует

Формулирование рекурсивных запросов
С версии Oracle 11.2 фраза WITH может использоваться для
Формулирование рекурсивных запросов
С версии Oracle 11.2 фраза WITH может использоваться для

Предложение SELECT для исходного множества строк Oracle называет опорным (anchor) членом
Предложение SELECT для исходного множества строк Oracle называет опорным (anchor) членом

Операция UNION ALL здесь используется символически, в рамках определенного контекста, для
Операция UNION ALL здесь используется символически, в рамках определенного контекста, для

Пример с дополнительным разъяснением способа выполнения:
SQL> WITH
2 anchor1234 ( n
Пример с дополнительным разъяснением способа выполнения:
SQL> WITH
2 anchor1234 ( n

Пример. Вычислить какое количество сотрудников ежегодно поступает на работу с 2002
Пример. Вычислить какое количество сотрудников ежегодно поступает на работу с 2002

Необязательный оператор START WITH (начать с) - если задано, то позволяет
Необязательный оператор START WITH (начать с) - если задано, то позволяет

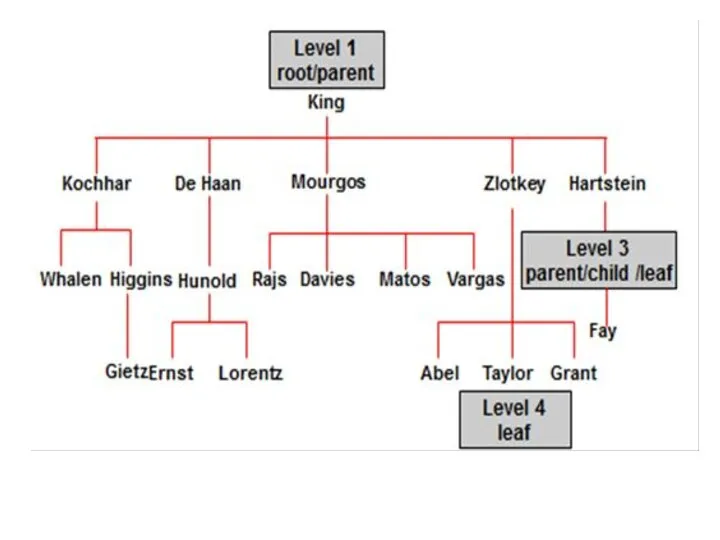
Чтобы получить нормальную иерархию нужно использовать специальный оператор, который называется PRIOR.
Чтобы получить нормальную иерархию нужно использовать специальный оператор, который называется PRIOR.

3. Oracle выбирает следующие одно за другим поколения дочерних строк. Сначала
3. Oracle выбирает следующие одно за другим поколения дочерних строк. Сначала

Пример . Показать менеджеров и сотрудников пока employee_id=101.
SELECT employee_id, last_name, job_id,
Пример . Показать менеджеров и сотрудников пока employee_id=101.
SELECT employee_id, last_name, job_id,

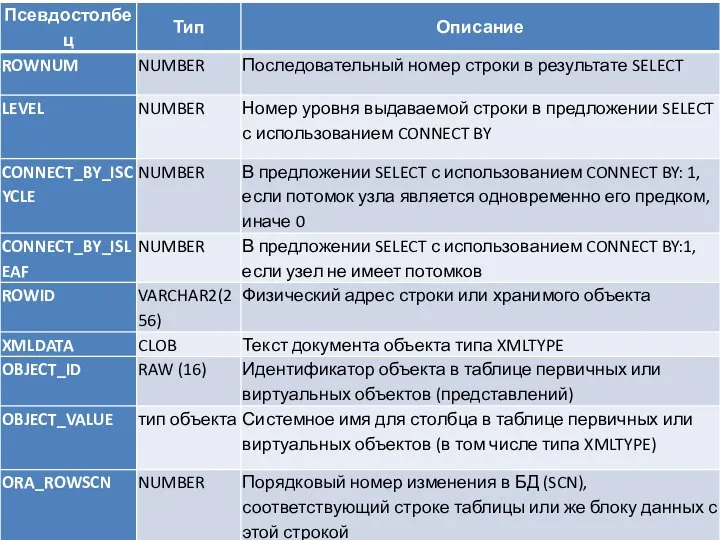
Оператор SELECT, осуществляющий древовидный запрос, может использовать псевдостолбец LEVEL, содержащий уровень
Оператор SELECT, осуществляющий древовидный запрос, может использовать псевдостолбец LEVEL, содержащий уровень
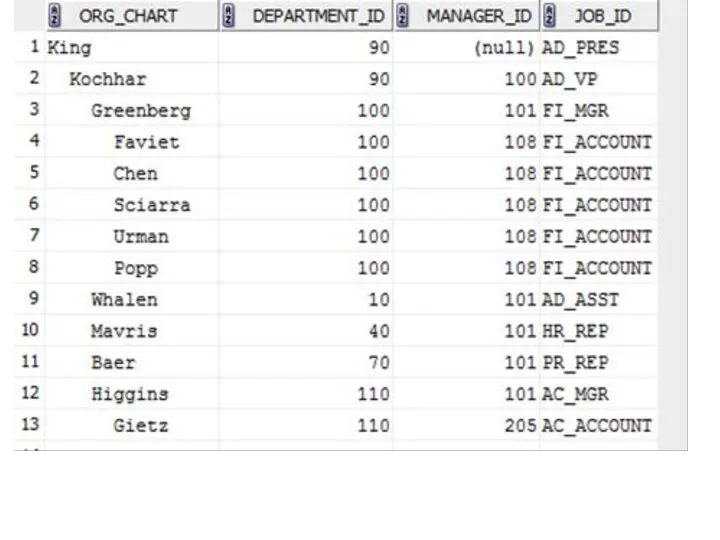
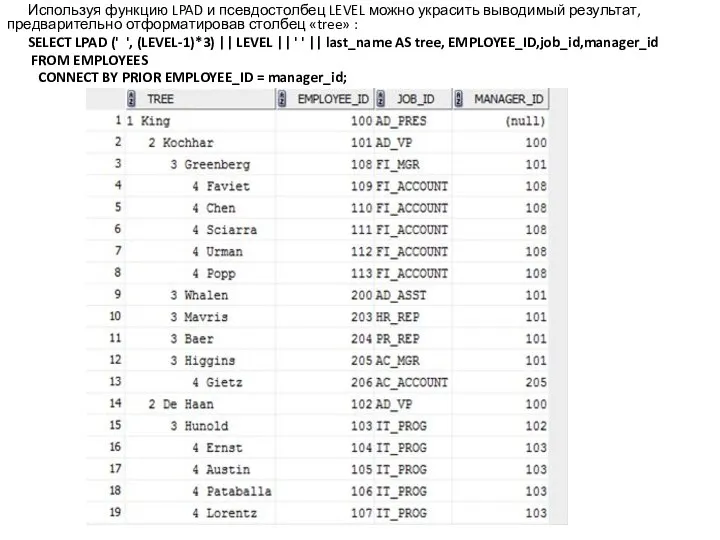
Используя функцию LPAD и псевдостолбец LEVEL можно украсить выводимый результат, предварительно
Используя функцию LPAD и псевдостолбец LEVEL можно украсить выводимый результат, предварительно

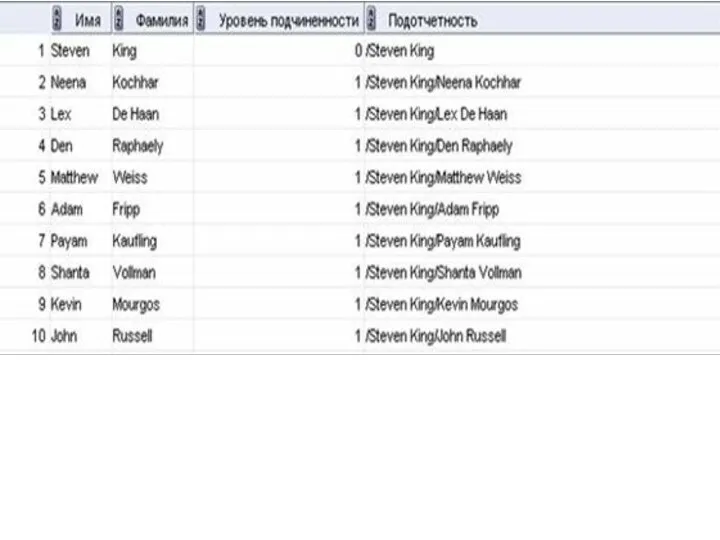
Напишем запрос, который возвращал бы из таблицы hr.employees информацию:
имя сотрудника;
фамилию сотрудника;
уровень
Напишем запрос, который возвращал бы из таблицы hr.employees информацию:
имя сотрудника;
фамилию сотрудника;
уровень

Чтобы указать БД в Oracle, что сортировать надо только в пределах
Чтобы указать БД в Oracle, что сортировать надо только в пределах

Транзакции в Oracle SQL.
В Oracle нет явного оператора, чтобы начать
Транзакции в Oracle SQL.
В Oracle нет явного оператора, чтобы начать

COMMIT - завершает транзакцию и делает любые выполненные в ней изменения
COMMIT - завершает транзакцию и делает любые выполненные в ней изменения

Некоторые особенности выполнения транзакций в Oracle:
1.Транзакция обычно состоит из нескольких операторов
Некоторые особенности выполнения транзакций в Oracle:
1.Транзакция обычно состоит из нескольких операторов

3. Oracle анонимный блок PL/SQL считает оператором. Например, begin оператор1; оператор2;
3. Oracle анонимный блок PL/SQL считает оператором. Например, begin оператор1; оператор2;

Распределённая транзакция имеет то же свойство, что и обычная: все или
Распределённая транзакция имеет то же свойство, что и обычная: все или
 ОАиП текстовые файлы
ОАиП текстовые файлы ГуглКласс құралдары
ГуглКласс құралдары Компьютер как универсальное устройство для обработки информации Программная обработка данных на компьютере
Компьютер как универсальное устройство для обработки информации Программная обработка данных на компьютере  Цветовые модели и типы растровых изображений
Цветовые модели и типы растровых изображений Табличные базы данных
Табличные базы данных Презентация к уроку информатики на тему: «Адресация в сети интернет» Автор: учитель математики и информатики МБОУ «Леплейская СО
Презентация к уроку информатики на тему: «Адресация в сети интернет» Автор: учитель математики и информатики МБОУ «Леплейская СО Топ 3 героев по моему мнению
Топ 3 героев по моему мнению Мультимедийная журналистика. Графическая модель
Мультимедийная журналистика. Графическая модель Програмне та апаратне забезпечення, локальні мережі
Програмне та апаратне забезпечення, локальні мережі Компания Nippon Telegraph and Telephone Corporation
Компания Nippon Telegraph and Telephone Corporation Пользовательский интерфейс. Компьютер как универсальное устройство для работы с информацией. (7 класс)
Пользовательский интерфейс. Компьютер как универсальное устройство для работы с информацией. (7 класс) Універсальна десяткова класифікація (УДК) в Україні
Універсальна десяткова класифікація (УДК) в Україні Аттестационная работа. Использование технологии проектной деятельности на уроках Информатики
Аттестационная работа. Использование технологии проектной деятельности на уроках Информатики Разработка и исследование сети FTTH в городе Севастополь
Разработка и исследование сети FTTH в городе Севастополь Электронная почта
Электронная почта Интернет в жизни старшеклассника: за и против
Интернет в жизни старшеклассника: за и против Разработка программного средства Портфолио студента
Разработка программного средства Портфолио студента Модули и пакеты в Python
Модули и пакеты в Python Artificial Intelegence
Artificial Intelegence Тренажёр. Звуковой анализ слова
Тренажёр. Звуковой анализ слова Язык разметки гипертекста HTML
Язык разметки гипертекста HTML Командная строка
Командная строка История вычислительной техники
История вычислительной техники Основы HTML
Основы HTML Муниципальное общеобразовательное учреждение гимназия №1 Учитель информатики: Скабёлкина М.Ю. Липецк 2011 8 класс
Муниципальное общеобразовательное учреждение гимназия №1 Учитель информатики: Скабёлкина М.Ю. Липецк 2011 8 класс Продвижение профсоюзных мероприятий
Продвижение профсоюзных мероприятий Алгоритмы управления. (9 класс)
Алгоритмы управления. (9 класс) Сборка отряда в игре Genshin Impact
Сборка отряда в игре Genshin Impact