- Кластерний аналіз. Дискримінантний аналіз

Содержание
- 2. Кластерний аналіз Кластерний аналіз (англ. Data clustering) — задача розбиття заданої вибірки об'єктів (ситуацій) на підмножини,
- 3. Основна мета кластерного аналізу — знаходження груп схожих об'єктів у вибірці. Спектр застосувань кластерного аналізу дуже
- 4. Незалежно від конкретної сфери, застосування кластерного аналізу передбачає наступні етапи: Відбір вибірки для кластеризації. Визначення множини
- 5. Методи кластеризації Метод к-середніх Прикладна економетрика де d — метрика, — і-ий об'єкт даних, а —
- 6. Методи кластеризації Кластеризація методом к–середніх: Демонстрація алгоритму Прикладна економетрика
- 7. Методи кластеризації Ієрархічна кластеризація (також «графові алгоритми кластеризації») Прикладна економетрика
- 8. Методи кластеризації FOREL (Формальний Елемент) Прикладна економетрика де перше підсумовування ведеться за всіма кластерам вибірки, друге
- 9. Методи кластеризації Нейронна мережа Кохонена Прикладна економетрика Шар Кохонена складається з деякої кількості N паралельно діючих
- 10. Приклади кластерного аналізу Прикладна економетрика
- 11. Львів: попередня оцінка Прикладна економетрика
- 12. Львів: відбір кластерів Прикладна економетрика
- 13. Приклад кластерних сайтів: Групи подібності по контенту Прикладна економетрика
- 14. Дискримінантний аналіз Дискриміна́нтний ана́ліз — різновид багатовимірного аналізу, призначеного для вирішення задач розпізнавання образів. Використовується для
- 15. Загальна модель дискримінантного аналізу для кількісних змінних при відсутності інформації щодо апріорної ймовірності віднесення до певної
- 16. У світовій практиці одним з найважливіших інструментів системи раннього запобігання та прогнозування банкрутства підприємств є дискримінантний
- 17. Приклад дискримінантного аналізу за допомогою MDA Прикладна економетрика
- 18. Універсальна дискримінантна модель Прикладна економетрика Z = 1,5 Х 1 + 0,08 Х 2 + 10
- 19. Переваги та недоліки застосування кластерного аналізу Результат класифікації сильно залежить від випадкових початкових позицій кластерних центрів
- 20. Переваги та недоліки застосування дискримінантного аналізу широкий інтервал невизначеності. Дані такого прогнозування є вельми суб’єктивними і
- 22. Скачать презентацию

Кластерний аналіз
Кластерний аналіз (англ. Data clustering) — задача розбиття заданої вибірки об'єктів (ситуацій) на підмножини, що називаються кластерами,
Кластерний аналіз
Кластерний аналіз (англ. Data clustering) — задача розбиття заданої вибірки об'єктів (ситуацій) на підмножини, що називаються кластерами,

Основна мета кластерного аналізу — знаходження груп схожих об'єктів у вибірці. Спектр
Основна мета кластерного аналізу — знаходження груп схожих об'єктів у вибірці. Спектр

Незалежно від конкретної сфери, застосування кластерного аналізу передбачає наступні етапи:
Відбір вибірки для кластеризації.
Визначення
Незалежно від конкретної сфери, застосування кластерного аналізу передбачає наступні етапи:
Відбір вибірки для кластеризації.
Визначення

Методи кластеризації
Метод к-середніх
Прикладна економетрика
де d — метрика, — і-ий об'єкт даних, а
Методи кластеризації
Метод к-середніх
Прикладна економетрика
де d — метрика, — і-ий об'єкт даних, а
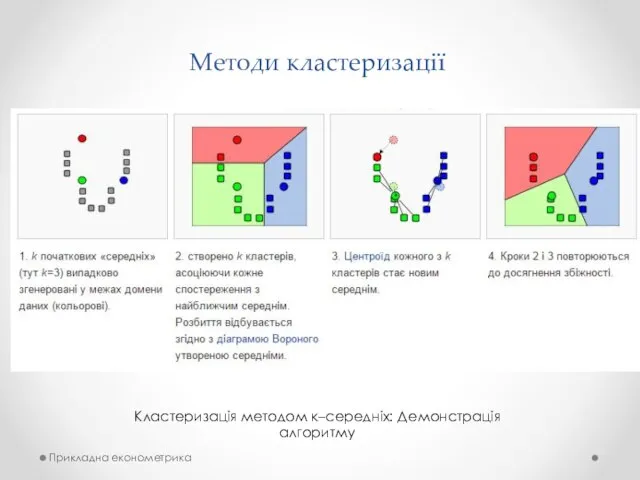
Методи кластеризації
Кластеризація методом к–середніх: Демонстрація алгоритму
Прикладна економетрика
Методи кластеризації
Кластеризація методом к–середніх: Демонстрація алгоритму
Прикладна економетрика

Методи кластеризації
Ієрархічна кластеризація (також «графові алгоритми кластеризації»)
Прикладна економетрика
Методи кластеризації
Ієрархічна кластеризація (також «графові алгоритми кластеризації»)
Прикладна економетрика

Методи кластеризації
FOREL (Формальний Елемент)
Прикладна економетрика
де перше підсумовування ведеться за всіма кластерам
Методи кластеризації
FOREL (Формальний Елемент)
Прикладна економетрика
де перше підсумовування ведеться за всіма кластерам

Методи кластеризації
Нейронна мережа Кохонена
Прикладна економетрика
Шар Кохонена складається з деякої кількості N
Методи кластеризації
Нейронна мережа Кохонена
Прикладна економетрика
Шар Кохонена складається з деякої кількості N

Приклади кластерного аналізу
Прикладна економетрика
Приклади кластерного аналізу
Прикладна економетрика
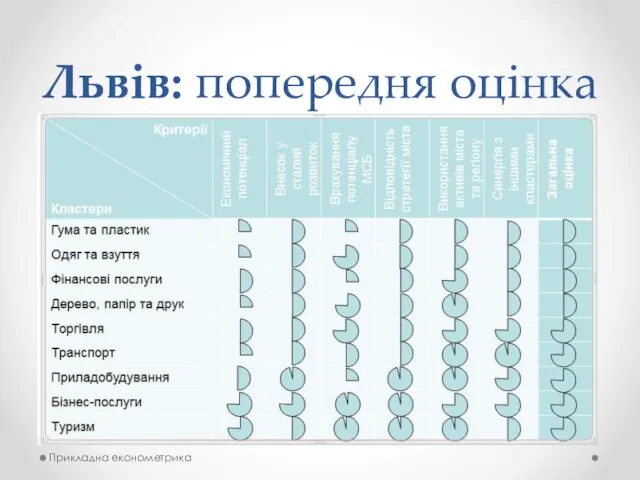
Львів: попередня оцінка
Прикладна економетрика
Львів: попередня оцінка
Прикладна економетрика

Львів: відбір кластерів
Прикладна економетрика
Львів: відбір кластерів
Прикладна економетрика

Приклад кластерних сайтів: Групи подібності по контенту
Прикладна економетрика
Приклад кластерних сайтів: Групи подібності по контенту
Прикладна економетрика

Дискримінантний аналіз
Дискриміна́нтний ана́ліз — різновид багатовимірного аналізу, призначеного для вирішення задач розпізнавання образів. Використовується
Дискримінантний аналіз
Дискриміна́нтний ана́ліз — різновид багатовимірного аналізу, призначеного для вирішення задач розпізнавання образів. Використовується

Загальна модель дискримінантного аналізу для кількісних змінних при відсутності інформації щодо
Загальна модель дискримінантного аналізу для кількісних змінних при відсутності інформації щодо

У світовій практиці одним з найважливіших інструментів системи раннього запобігання та
У світовій практиці одним з найважливіших інструментів системи раннього запобігання та

Приклад дискримінантного аналізу за допомогою MDA
Прикладна економетрика
Приклад дискримінантного аналізу за допомогою MDA
Прикладна економетрика

Універсальна дискримінантна модель
Прикладна економетрика
Z = 1,5 Х 1 + 0,08 Х
Універсальна дискримінантна модель
Прикладна економетрика
Z = 1,5 Х 1 + 0,08 Х

Переваги та недоліки застосування кластерного аналізу
Результат класифікації сильно залежить від випадкових
Переваги та недоліки застосування кластерного аналізу
Результат класифікації сильно залежить від випадкових

Переваги та недоліки застосування дискримінантного аналізу
широкий інтервал невизначеності. Дані такого прогнозування є вельми
Переваги та недоліки застосування дискримінантного аналізу
широкий інтервал невизначеності. Дані такого прогнозування є вельми
 Тренажер по математике для 1 класса
Тренажер по математике для 1 класса Презентация по математике "Параллельность прямых" - скачать
Презентация по математике "Параллельность прямых" - скачать  Азбука тригонометрии. Урок № 7. Формулы тригонометрии
Азбука тригонометрии. Урок № 7. Формулы тригонометрии Деление
Деление Письменное умножение на числа, оканчивающиеся нулями
Письменное умножение на числа, оканчивающиеся нулями Презентация по математике "СЛОЖЕНИЕ И ВЫЧИТАНИЕ МНОГОЧЛЕНОВ" - скачать бесплатно
Презентация по математике "СЛОЖЕНИЕ И ВЫЧИТАНИЕ МНОГОЧЛЕНОВ" - скачать бесплатно Урок математики
Урок математики  Презентация по математике "Признаки делимости на 2, на 5, на 10" - скачать бесплатно
Презентация по математике "Признаки делимости на 2, на 5, на 10" - скачать бесплатно Применение свойств квадратичной функции Алексеевский Сергей МБОУ «СОШ № 2 ст. Архонская»
Применение свойств квадратичной функции Алексеевский Сергей МБОУ «СОШ № 2 ст. Архонская» Урок математики
Урок математики Решение неравенств
Решение неравенств Параллельность прямых в пространстве
Параллельность прямых в пространстве Формирование смысла сложения и вычитания на примере УМК Гармония Н.Б. Истомина
Формирование смысла сложения и вычитания на примере УМК Гармония Н.Б. Истомина Формулы приведения
Формулы приведения Многочлен и его стандартный вид
Многочлен и его стандартный вид Конструирование системы заданий для организации продуктивной деятельности учащихся на уроке математики
Конструирование системы заданий для организации продуктивной деятельности учащихся на уроке математики Сложение и вычитание десятичных дробей. Устный счет
Сложение и вычитание десятичных дробей. Устный счет Основы математики. Вопросы по категориям
Основы математики. Вопросы по категориям Модуль числа. (6 класс)
Модуль числа. (6 класс) Теоремы сложения и умножения вероятностей
Теоремы сложения и умножения вероятностей Перевод одних единиц измерения в другие, решение пропорций
Перевод одних единиц измерения в другие, решение пропорций Многоугольники
Многоугольники Математическое развитие детей в семье
Математическое развитие детей в семье Вероятность. Вычисление вероятности
Вероятность. Вычисление вероятности Признаки подобия треугольников
Признаки подобия треугольников Деление натуральных чисел
Деление натуральных чисел Угол. Прямой и развернутый угол. Чертежный треугольник
Угол. Прямой и развернутый угол. Чертежный треугольник Логические задачи для дошкольников
Логические задачи для дошкольников