- EnterpriseDB

Содержание
- 2. Overview PostgreSQL MVCC Motivation for Improvement HOT Basics HOT Internals Limitations Performance Numbers and Charts
- 3. What Does HOT Stand For ? Heap Organized Tuples Heap Optimized Tuples Heap Overflow Tuples Heap
- 4. Credits Its not entirely my work Several people contributed, some directly, many indirectly Simon Riggs –
- 5. Some Background - MVCC PostgreSQL uses MVCC (Multi Version Concurrency Control) for transaction semantics The good
- 6. MVCC - UPDATE V1 V2 V3 Index Heap Transaction T1 Updates V1 Transaction T1 Commits Transaction
- 7. MVCC - Visibility Index Heap Transaction T0 V3 V1 V2 T0 started before T1 committed T0
- 8. MVCC - Visibility Index Heap Transaction T2 Transaction T2 V3 V1 V2 T2 started after T1
- 9. MVCC - Visibility Index Heap Transaction T4 Transaction T4 Transaction T4 V3 V2 V1 T4 started
- 10. MVCC – Tuple States V2 Index Heap V1 and V2 are RECENTLY DEAD, V3 is the
- 11. Removing DEAD Tuples V2 Index Heap V1 V1 is DEAD. If it’s removed, we would have
- 12. MVCC - Index/Heap Bloat Updates Inserts Deletes Heap Index A Index B
- 13. MVCC - Index/Heap Bloat Heap Index A Index B VACUUM
- 14. Vacuum – Two Phase Process Heap Index A Index B
- 15. Vacuum Heap Index A Index B VACUUM can release free space only at the end of
- 16. Motivation Frequent Updates and Deletes bloat the heap and indexes resulting in performance degradation in long
- 17. Pgbench Results scale = 90, clients = 30, transactions/client = 1,000,000 two CPU, dual core, 2
- 18. Heap Bloat (# blocks) In 8.2, the heap bloat is too much for small and large
- 19. Postgres 8.3 – Multiple Autovacuum Multiple autovaccum processes helped small tables, but not large tables
- 20. Postgres 8.3 – HOT (Retail Vacuum)
- 21. Several Ideas Update In Place The first design. Replace old version with the new version and
- 22. HOT Update Necessary Condition A: UPDATE does not change any of the index keys Example: CREATE
- 23. HOT Update V1 V2 V3 Index Heap HOT Necessary Condition B: The new version should fit
- 24. HOT Update – Necessary Conditions Necessary Condition A: UPDATE does not change any of the index
- 25. Inside A Block Page Header tuple 1 tuple 2 tuple 4 tuple 3 tuple 5 tuple
- 26. HOT – Heap Scan V1 V2 V3 V4 Index Ref No change to Heap Scan Each
- 27. HOT – Index Scan V1 V2 V3 V4 Index Ref Index points to the Root Tuple
- 28. Pruning – Shortening the HOT Chain V3 V4 Index Ref V1 becomes DEAD V1 is removed,
- 29. Pruning – Shortening the HOT Chain V2 V3 V4 Index Ref Root LP is a redirected
- 30. Pruning – Shortening the HOT Chain V3 V4 Index Ref Root LP is a redirected LP
- 31. Pruning – Shortening the HOT Chain V4 Index Ref Root LP is a redirected LP V4
- 32. Pruning – Normal UPDATEs and DELETEs V1 Index Ref Normal UPDATEd and DELETEd tuples are removed
- 33. Pruning and Defragmentation Page Header tuple 1 tuple 2 tuple 4 tuple 3 tuple 5 tuple
- 34. Pruning – Recovering Dead Space Page Header tuple 1 tuple 2 tuple 4 tuple 3 tuple
- 35. Defragmentation – Collecting Dead Space Page Header tuple 5 tuple 6 tuple N Used Space Free
- 36. Billion $ Question – When to Prune/Defragment ? Pruning and defragmentation (PD) happens together – requires
- 37. Page Level Hints and Xid If UPDATE does not find enough free space in a page,
- 38. Lazy Vacuum / Vacuum Full Lazy Vacuum is almost unchanged. DEAD line pointers are collected and
- 39. Headline Numbers - Comparing TPS That’s a good 200% increase in TPS
- 40. Comparing Heap Bloat (# blocks) HOT significantly reduces heap bloat; for small and large tables
- 41. Comparing Index Bloat (# blocks) HOT significantly reduces index bloat too; for small and large tables
- 42. Comparing IO Stats
- 43. Comparing IO Stats
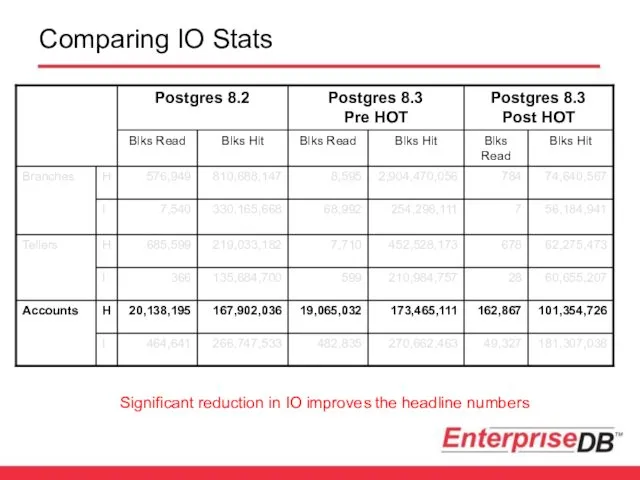
- 44. Comparing IO Stats Significant reduction in IO improves the headline numbers
- 45. What Should I Do ? Nothing! HOT is always enabled and there is no way to
- 46. Limitations Free space released by defragmentation can only be used for subsequent UPDATEs in the same
- 47. Create Index This was one of the most interesting challenges in HOT development. The goal was
- 48. Create Index - Challenges Handling broken HOT chains New Index must satisfy HOT properties All tuples
- 49. Create Index – Sane State 1, a, x 1, a, y 2, b, x 2, c,
- 50. Create Index – Broken HOT Chains 1, a, x 1, a, y 2, b, x 2,
- 51. Create Index – Building Index with Broken HOT Chains 2, b, x 2, c, y 3,
- 53. Скачать презентацию

Overview
PostgreSQL MVCC
Motivation for Improvement
HOT Basics
HOT Internals
Limitations
Performance Numbers and Charts
Overview
PostgreSQL MVCC
Motivation for Improvement
HOT Basics
HOT Internals
Limitations
Performance Numbers and Charts

What Does HOT Stand For ?
Heap Organized Tuples
Heap Optimized Tuples
Heap Overflow
What Does HOT Stand For ?
Heap Organized Tuples
Heap Optimized Tuples
Heap Overflow

Credits
Its not entirely my work
Several people contributed, some directly, many indirectly
Simon
Credits
Its not entirely my work
Several people contributed, some directly, many indirectly
Simon

Some Background - MVCC
PostgreSQL uses MVCC (Multi Version Concurrency Control) for
Some Background - MVCC
PostgreSQL uses MVCC (Multi Version Concurrency Control) for
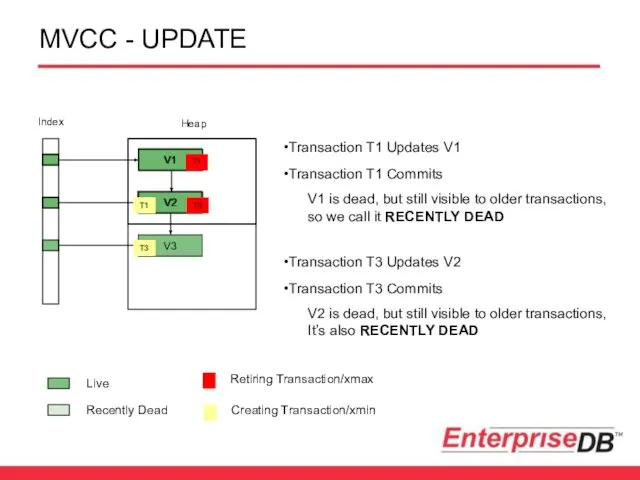
MVCC - UPDATE
V1
V2
V3
Index
Heap
Transaction T1 Updates V1
Transaction T1 Commits
Transaction T3 Updates V2
Transaction
MVCC - UPDATE
V1
V2
V3
Index
Heap
Transaction T1 Updates V1
Transaction T1 Commits
Transaction T3 Updates V2
Transaction
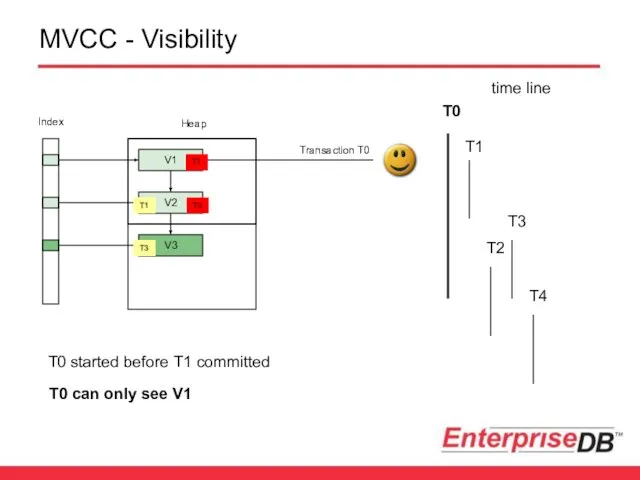
MVCC - Visibility
Index
Heap
Transaction T0
V3
V1
V2
T0 started before T1 committed
T0 can only see
MVCC - Visibility
Index
Heap
Transaction T0
V3
V1
V2
T0 started before T1 committed
T0 can only see
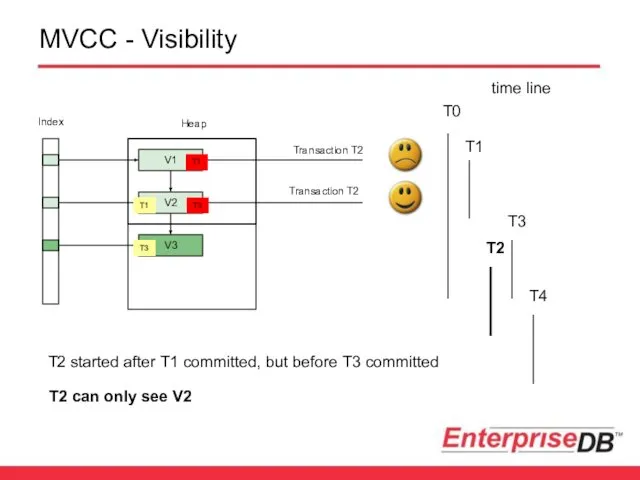
MVCC - Visibility
Index
Heap
Transaction T2
Transaction T2
V3
V1
V2
T2 started after T1 committed, but before
MVCC - Visibility
Index
Heap
Transaction T2
Transaction T2
V3
V1
V2
T2 started after T1 committed, but before

MVCC - Visibility
Index
Heap
Transaction T4
Transaction T4
Transaction T4
V3
V2
V1
T4 started after T3 committed
T4 can
MVCC - Visibility
Index
Heap
Transaction T4
Transaction T4
Transaction T4
V3
V2
V1
T4 started after T3 committed
T4 can
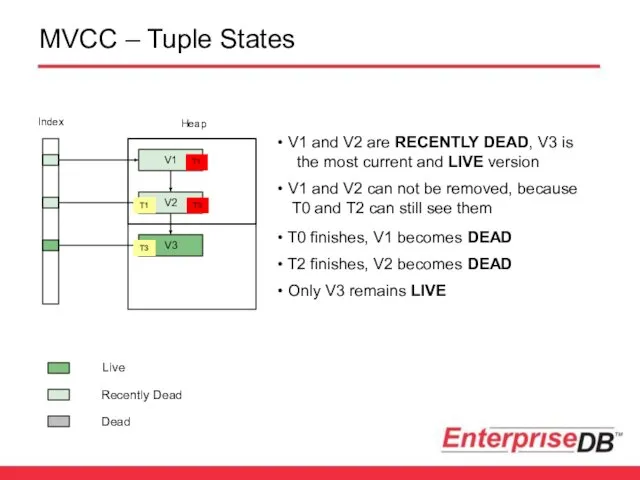
MVCC – Tuple States
V2
Index
Heap
V1 and V2 are RECENTLY DEAD, V3
MVCC – Tuple States
V2
Index
Heap
V1 and V2 are RECENTLY DEAD, V3

Removing DEAD Tuples
V2
Index
Heap
V1
V1 is DEAD. If it’s removed, we would
Removing DEAD Tuples
V2
Index
Heap
V1
V1 is DEAD. If it’s removed, we would
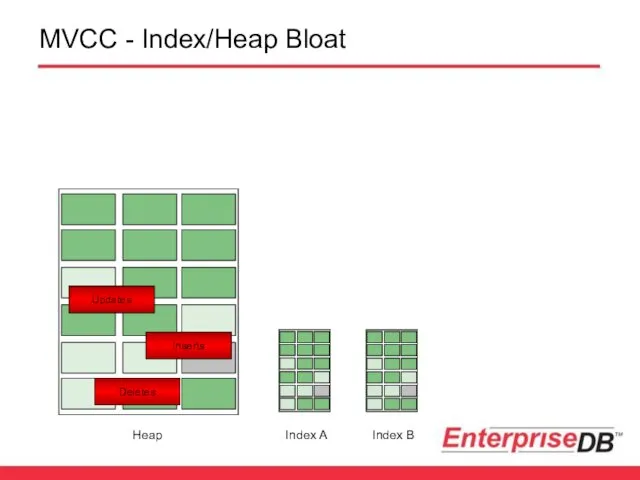
MVCC - Index/Heap Bloat
Updates
Inserts
Deletes
Heap
Index A
Index B
MVCC - Index/Heap Bloat
Updates
Inserts
Deletes
Heap
Index A
Index B

MVCC - Index/Heap Bloat
Heap
Index A
Index B
VACUUM
MVCC - Index/Heap Bloat
Heap
Index A
Index B
VACUUM
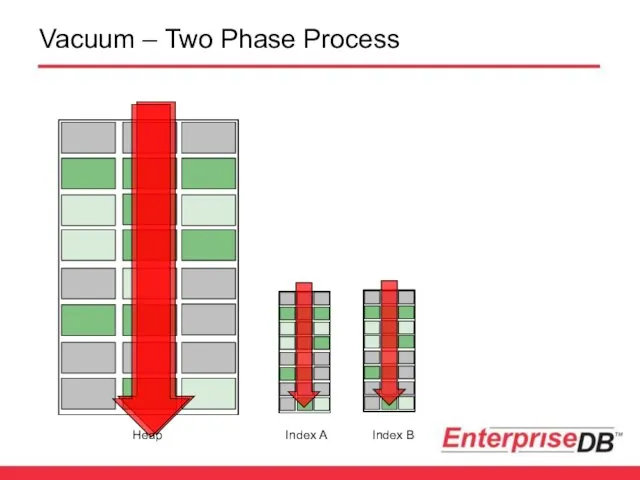
Vacuum – Two Phase Process
Heap
Index A
Index B
Vacuum – Two Phase Process
Heap
Index A
Index B
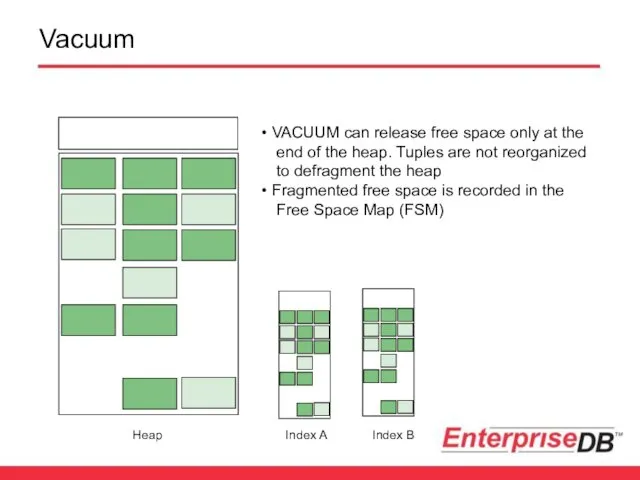
Vacuum
Heap
Index A
Index B
VACUUM can release free space only at the
Vacuum
Heap
Index A
Index B
VACUUM can release free space only at the

Motivation
Frequent Updates and Deletes bloat the heap and indexes resulting in
Motivation
Frequent Updates and Deletes bloat the heap and indexes resulting in

Pgbench Results
scale = 90, clients = 30, transactions/client = 1,000,000
two CPU,
Pgbench Results
scale = 90, clients = 30, transactions/client = 1,000,000
two CPU,

Heap Bloat (# blocks)
In 8.2, the heap bloat is too much
Heap Bloat (# blocks)
In 8.2, the heap bloat is too much

Postgres 8.3 – Multiple Autovacuum
Multiple autovaccum processes helped small tables, but
Postgres 8.3 – Multiple Autovacuum
Multiple autovaccum processes helped small tables, but

Postgres 8.3 – HOT (Retail Vacuum)
Postgres 8.3 – HOT (Retail Vacuum)

Several Ideas
Update In Place
The first design. Replace old version with the
Several Ideas
Update In Place
The first design. Replace old version with the

HOT Update
Necessary Condition A: UPDATE does not change any of the
HOT Update
Necessary Condition A: UPDATE does not change any of the
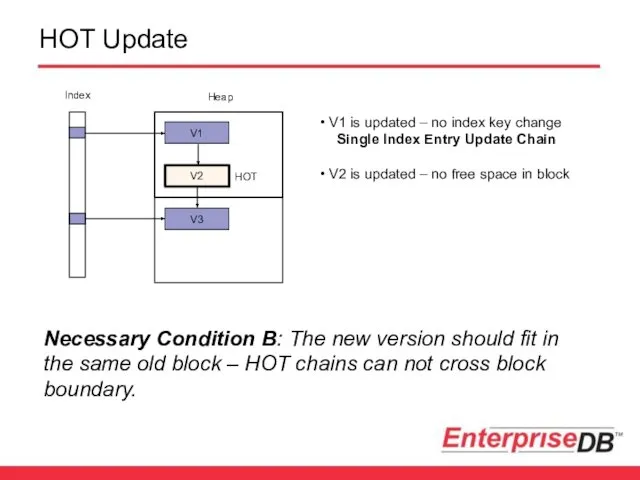
HOT Update
V1
V2
V3
Index
Heap
HOT
Necessary Condition B: The new version should fit in the
HOT Update
V1
V2
V3
Index
Heap
HOT
Necessary Condition B: The new version should fit in the

HOT Update – Necessary Conditions
Necessary Condition A: UPDATE does not change
HOT Update – Necessary Conditions
Necessary Condition A: UPDATE does not change

Inside A Block
Page Header
tuple 1
tuple 2
tuple 4
tuple 3
tuple 5
tuple 6
tuple N
Used
Inside A Block
Page Header
tuple 1
tuple 2
tuple 4
tuple 3
tuple 5
tuple 6
tuple N
Used

HOT – Heap Scan
V1
V2
V3
V4
Index Ref
No change to Heap Scan
Each
HOT – Heap Scan
V1
V2
V3
V4
Index Ref
No change to Heap Scan
Each

HOT – Index Scan
V1
V2
V3
V4
Index Ref
Index points to the Root Tuple
HOT – Index Scan
V1
V2
V3
V4
Index Ref
Index points to the Root Tuple

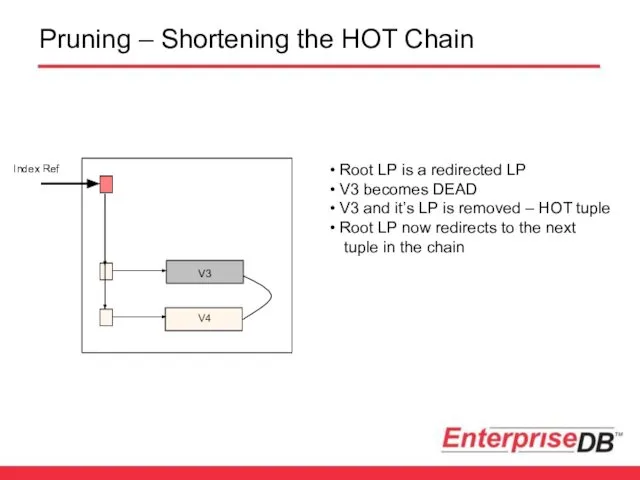
Pruning – Shortening the HOT Chain
V3
V4
Index Ref
V1 becomes DEAD
V1
Pruning – Shortening the HOT Chain
V3
V4
Index Ref
V1 becomes DEAD
V1

Pruning – Shortening the HOT Chain
V2
V3
V4
Index Ref
Root LP is a
Pruning – Shortening the HOT Chain
V2
V3
V4
Index Ref
Root LP is a
Pruning – Shortening the HOT Chain
V3
V4
Index Ref
Root LP is a
Pruning – Shortening the HOT Chain
V3
V4
Index Ref
Root LP is a

Pruning – Shortening the HOT Chain
V4
Index Ref
Root LP is a
Pruning – Shortening the HOT Chain
V4
Index Ref
Root LP is a

Pruning – Normal UPDATEs and DELETEs
V1
Index Ref
Normal UPDATEd and DELETEd
Pruning – Normal UPDATEs and DELETEs
V1
Index Ref
Normal UPDATEd and DELETEd
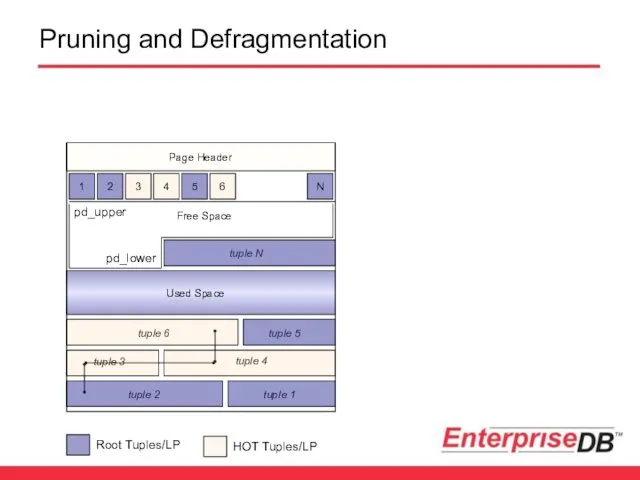
Pruning and Defragmentation
Page Header
tuple 1
tuple 2
tuple 4
tuple 3
tuple 5
tuple 6
tuple N
Used
Pruning and Defragmentation
Page Header
tuple 1
tuple 2
tuple 4
tuple 3
tuple 5
tuple 6
tuple N
Used

Pruning – Recovering Dead Space
Page Header
tuple 1
tuple 2
tuple 4
tuple 3
tuple 5
tuple
Pruning – Recovering Dead Space
Page Header
tuple 1
tuple 2
tuple 4
tuple 3
tuple 5
tuple
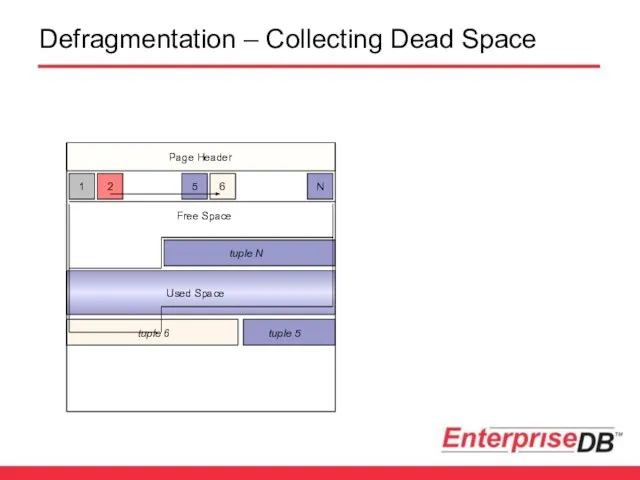
Defragmentation – Collecting Dead Space
Page Header
tuple 5
tuple 6
tuple N
Used Space
Free Space
6
1
2
5
N
Defragmentation – Collecting Dead Space
Page Header
tuple 5
tuple 6
tuple N
Used Space
Free Space
6
1
2
5
N

Billion $ Question – When to Prune/Defragment ?
Pruning and defragmentation (PD)
Billion $ Question – When to Prune/Defragment ?
Pruning and defragmentation (PD)

Page Level Hints and Xid
If UPDATE does not find enough free
Page Level Hints and Xid
If UPDATE does not find enough free
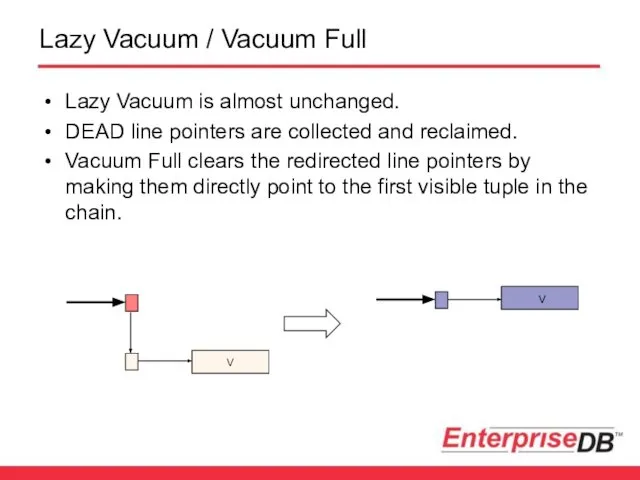
Lazy Vacuum / Vacuum Full
Lazy Vacuum is almost unchanged.
DEAD line pointers
Lazy Vacuum / Vacuum Full
Lazy Vacuum is almost unchanged.
DEAD line pointers

Headline Numbers - Comparing TPS
That’s a good 200% increase in TPS
Headline Numbers - Comparing TPS
That’s a good 200% increase in TPS
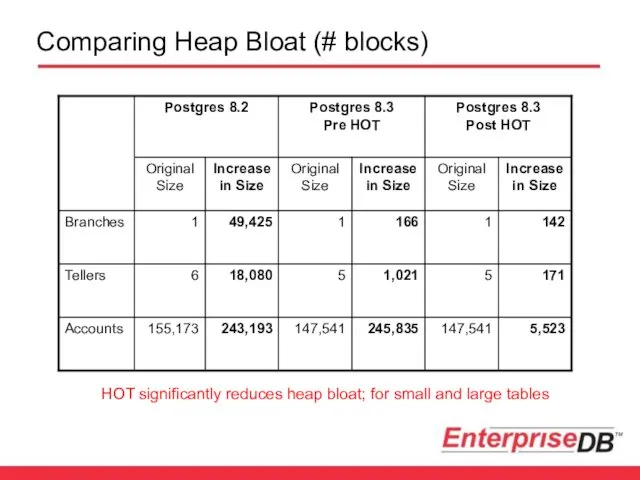
Comparing Heap Bloat (# blocks)
HOT significantly reduces heap bloat; for small
Comparing Heap Bloat (# blocks)
HOT significantly reduces heap bloat; for small
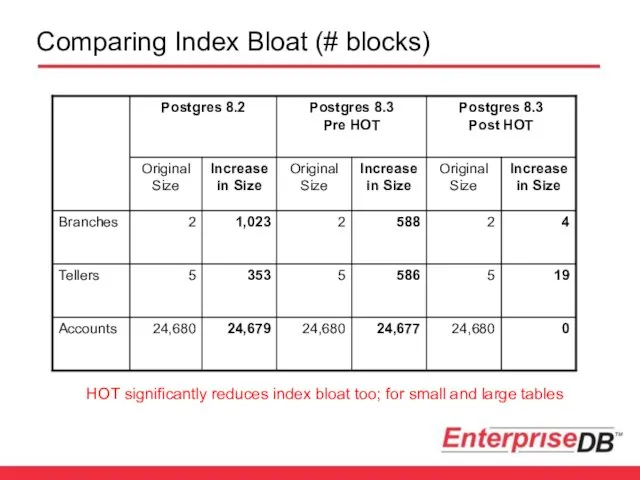
Comparing Index Bloat (# blocks)
HOT significantly reduces index bloat too; for
Comparing Index Bloat (# blocks)
HOT significantly reduces index bloat too; for
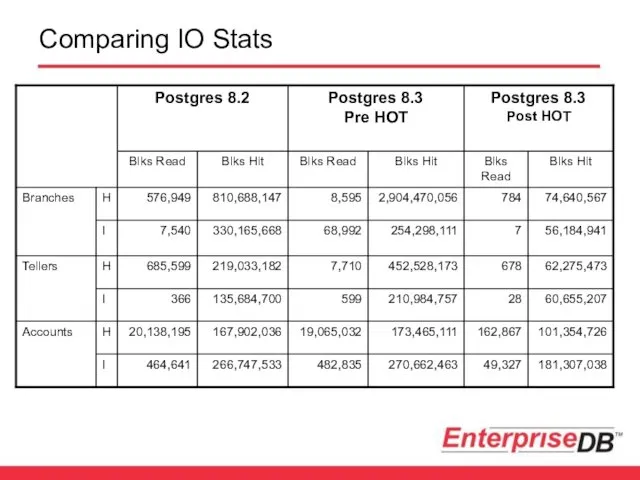
Comparing IO Stats
Comparing IO Stats
Comparing IO Stats
Comparing IO Stats
Comparing IO Stats
Significant reduction in IO improves the headline numbers
Comparing IO Stats
Significant reduction in IO improves the headline numbers

What Should I Do ?
Nothing! HOT is always enabled and there
What Should I Do ?
Nothing! HOT is always enabled and there

Limitations
Free space released by defragmentation can only be used for subsequent
Limitations
Free space released by defragmentation can only be used for subsequent

Create Index
This was one of the most interesting challenges in HOT
Create Index
This was one of the most interesting challenges in HOT

Create Index - Challenges
Handling broken HOT chains
New Index must satisfy HOT
Create Index - Challenges
Handling broken HOT chains
New Index must satisfy HOT
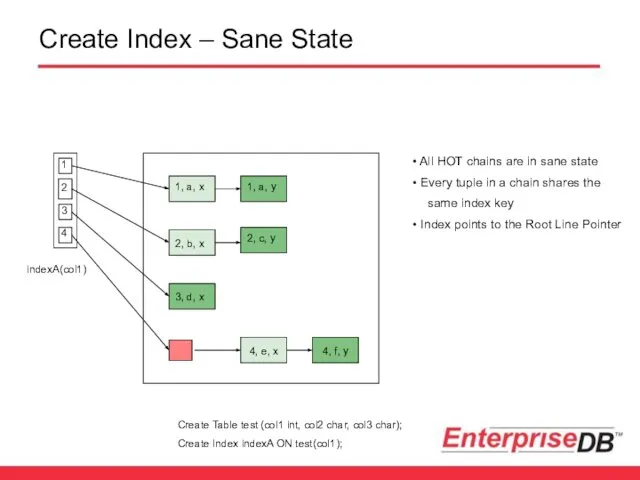
Create Index – Sane State
1, a, x
1, a, y
2, b, x
2,
Create Index – Sane State
1, a, x
1, a, y
2, b, x
2,
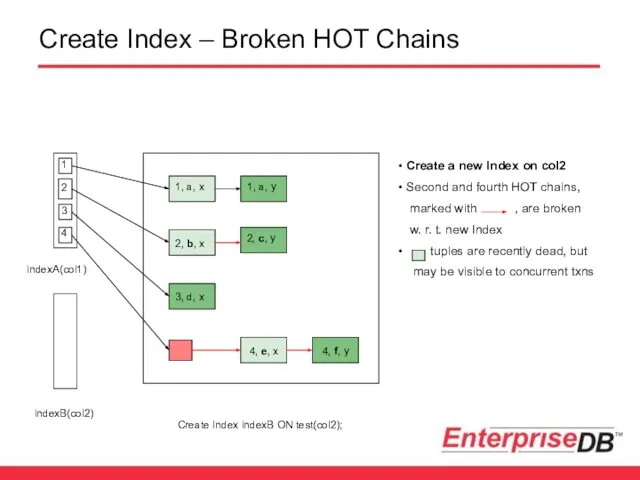
Create Index – Broken HOT Chains
1, a, x
1, a, y
2, b,
Create Index – Broken HOT Chains
1, a, x
1, a, y
2, b,
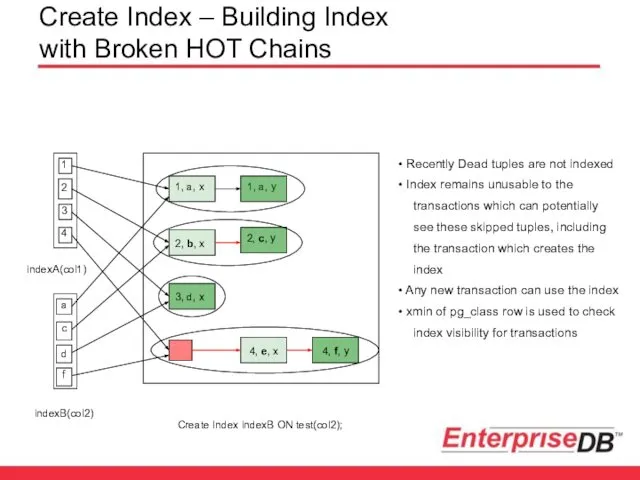
Create Index – Building Index with Broken HOT Chains
2, b, x
2,
Create Index – Building Index with Broken HOT Chains
2, b, x
2,
 рисунки анатомия
рисунки анатомия Терроризм и Беслан
Терроризм и Беслан Электродвигатель компрессора НБ-231М
Электродвигатель компрессора НБ-231М Насосы для отопления
Насосы для отопления Знакомство с декоративной росписью, рисование орнамента кистью
Знакомство с декоративной росписью, рисование орнамента кистью Гидроаккумулирующие электростанции
Гидроаккумулирующие электростанции История военного знамени в разные эпохи
История военного знамени в разные эпохи Breech presentation
Breech presentation Жизнь и творчество В. Гюго. Даниил Пашков
Жизнь и творчество В. Гюго. Даниил Пашков Успенский собор
Успенский собор Презентация+№+1
Презентация+№+1 Ламинат. Ламинированный пол
Ламинат. Ламинированный пол Дрон - доставщик еды больным и пожилым людям
Дрон - доставщик еды больным и пожилым людям Игна О.Н._науч.рук
Игна О.Н._науч.рук Урок 1. Презентация
Урок 1. Презентация Vvodnaya_lektsia_MOOK_Osnovy_proektnogo_menedzhmenta
Vvodnaya_lektsia_MOOK_Osnovy_proektnogo_menedzhmenta Дашеньке
Дашеньке ppt04
ppt04 Мово моя барвінкова, калинова мова
Мово моя барвінкова, калинова мова k.d._ushinskiy_o_detyah
k.d._ushinskiy_o_detyah 4 октября - день гражданской обороны Российской Федерации
4 октября - день гражданской обороны Российской Федерации Свято-Димитриевское училище сестёр милосердия
Свято-Димитриевское училище сестёр милосердия Отношение к смерти в христианстве
Отношение к смерти в христианстве Нежилое помещение г. Нижний Новгород (фото)
Нежилое помещение г. Нижний Новгород (фото) Требования к земельному участку
Требования к земельному участку Сирек кездесетін сусымалы және жер металдарын өндіру
Сирек кездесетін сусымалы және жер металдарын өндіру Субөнімдерді өңдеу. Етсүйекті, жұмсақ, шырышты, субөнімдер. ІҚМ малдың басын өңдеу
Субөнімдерді өңдеу. Етсүйекті, жұмсақ, шырышты, субөнімдер. ІҚМ малдың басын өңдеу Пищевые токсикоинфекции и их профилактика
Пищевые токсикоинфекции и их профилактика