- Индексы Архитектуры

Содержание
- 2. Использование индексов. Методы доступа к данным Основная причина, побуждающая к постоянному cовершенствованию всей технологии организации структур
- 3. Использование индексов. Методы доступа к данным. Далее рассматриваются методы, способствующие достижению этой цели, иными словами, методы
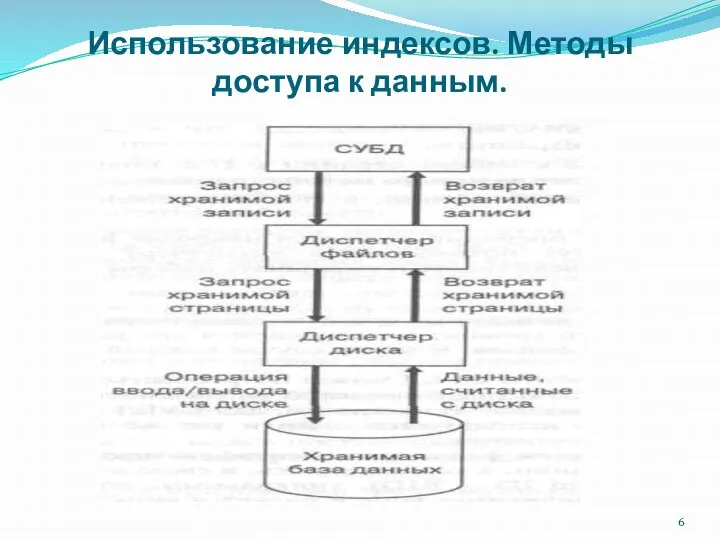
- 4. Использование индексов. Методы доступа к данным. Шаг 1. Вначале СУБД определяет, какая ей требуется запись, и
- 5. Использование индексов. Методы доступа к данным. Безусловно, что иногда требуемая страница может уже находиться в буфере
- 6. Использование индексов. Методы доступа к данным.
- 7. Использование индексов. Методы доступа к данным. Кластеризация. Это обзорное описание не будет полным без краткого упоминания
- 8. Использование индексов. Методы доступа к данным. Кластеризация. 2. Если страницы p1 и р2 являются разными, но
- 9. Использование индексов Рассмотрим данные о поставщиках. Предположим, что одним из самых важных (т.е. часто выполняемых и
- 10. Использование индексов
- 11. Использование индексов 1. Выполнить поиск во всем файле поставщиков, отбирая те записи, в которых значение города
- 12. Использование индексов В данном примере файл городов может рассматриваться как индекс ("индекс CITY") к файлу поставщиков;
- 13. Использование индексов Фундаментальным преимуществом любого индекса по сравнению с другими путями доступа является то, что он
- 14. Использование индексов Существует также возможность сформировать индекс на основе значений двух или нескольких полей, составляющих единую
- 15. Использование индексов
- 16. Операторы SQL Создание индекса СREATE INDEX ОN ( , , …….); Удаление индекса DROP INDEX ;
- 17. Распределенные базы данных Система распределенных баз данных состоит из набора узлов (site), связанных коммуникационной сетью, в
- 18. Распределенные базы данных
- 19. Распределенные базы данных Зачем нужны распределенные базы данных? Основная причина заключается в том, что сами предприятия
- 20. Распределенные базы данных Для того чтобы лучше в этом разобраться, приведем пример. Предположим, что есть только
- 21. Распределенные базы данных Принцип локальной независимости Узлы в распределенной системе должны быть независимы, или автономны. Локальная
- 22. Распределенные базы данных Принцип отсутствия зависимости от центрального узла Локальная независимость предполагает, что все узлы в
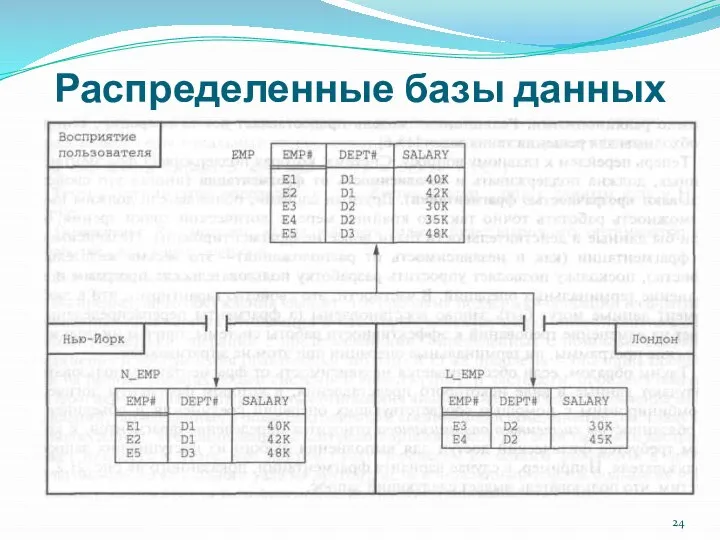
- 23. Распределенные базы данных Принцип независимости от фрагментации Система поддерживает независимость данных от фрагментации, если некоторая переменная
- 24. Распределенные базы данных
- 25. Распределенные базы данных К обязанностям системного оптимизатора относится определение фрагментов, к которым требуется физический доступ для
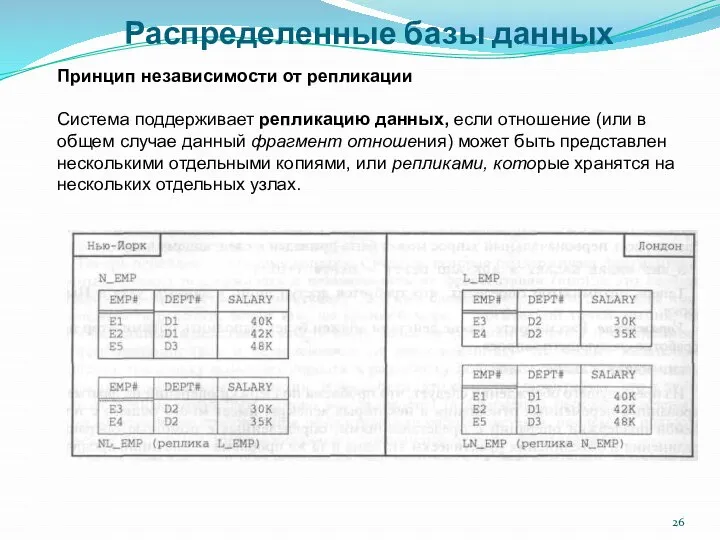
- 26. Распределенные базы данных Принцип независимости от репликации Система поддерживает репликацию данных, если отношение (или в общем
- 27. Связи между БД Возможный шлюз между разными БД. В ОRACLE для организации доступа от одной к
- 28. Архитектура клиент-сервер
- 29. Трехуровневая архитектура
- 30. Трехуровневая архитектура Терминал - это интерфейсный (обычно графический) компонент, который представляет первый уровень, собственно приложение для
- 32. Скачать презентацию

Использование индексов. Методы доступа к данным
Основная причина, побуждающая к постоянному cовершенствованию
Использование индексов. Методы доступа к данным
Основная причина, побуждающая к постоянному cовершенствованию

Использование индексов. Методы доступа к данным.
Далее рассматриваются методы, способствующие достижению
Использование индексов. Методы доступа к данным.
Далее рассматриваются методы, способствующие достижению

Использование индексов. Методы доступа к данным.
Шаг 1. Вначале СУБД определяет, какая
Использование индексов. Методы доступа к данным.
Шаг 1. Вначале СУБД определяет, какая

Использование индексов. Методы доступа к данным.
Безусловно, что иногда требуемая страница может
Использование индексов. Методы доступа к данным.
Безусловно, что иногда требуемая страница может
Использование индексов. Методы доступа к данным.
Использование индексов. Методы доступа к данным.

Использование индексов. Методы доступа к данным. Кластеризация.
Это обзорное описание не будет
Использование индексов. Методы доступа к данным. Кластеризация.
Это обзорное описание не будет

Использование индексов. Методы доступа к данным. Кластеризация.
2. Если страницы p1 и
Использование индексов. Методы доступа к данным. Кластеризация.
2. Если страницы p1 и

Использование индексов
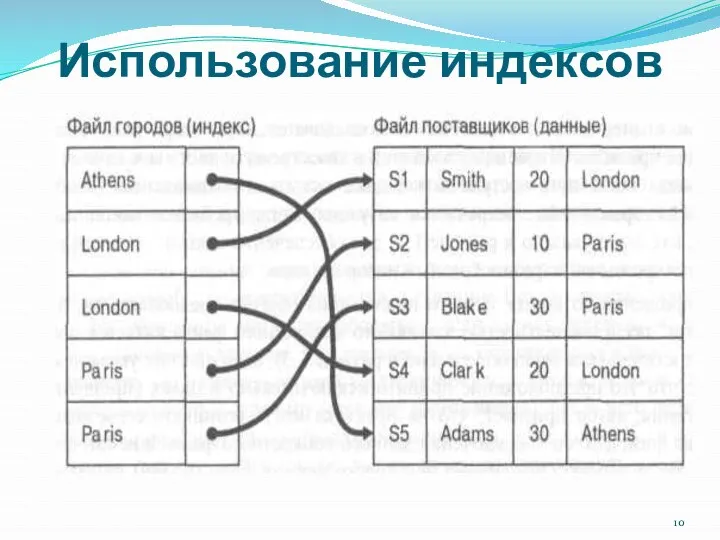
Рассмотрим данные о поставщиках. Предположим, что одним из самых
Использование индексов
Рассмотрим данные о поставщиках. Предположим, что одним из самых
Использование индексов
Использование индексов

Использование индексов
1. Выполнить поиск во всем файле поставщиков, отбирая те записи,
Использование индексов
1. Выполнить поиск во всем файле поставщиков, отбирая те записи,

Использование индексов
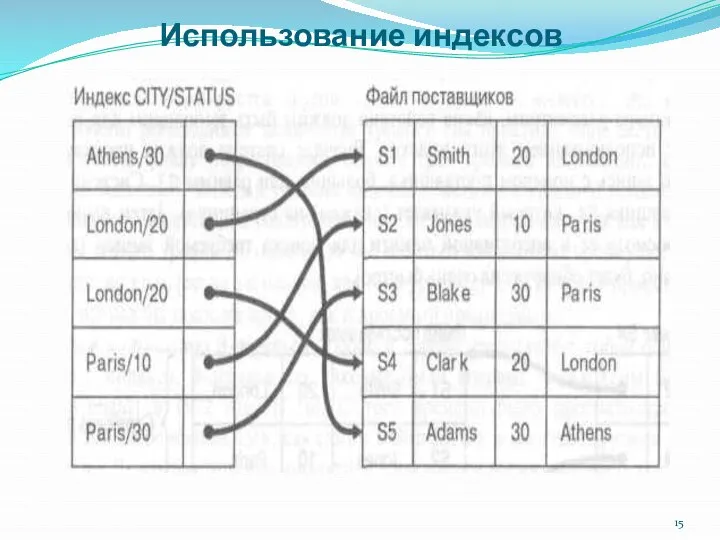
В данном примере файл городов может рассматриваться как индекс ("индекс
Использование индексов
В данном примере файл городов может рассматриваться как индекс ("индекс

Использование индексов
Фундаментальным преимуществом любого индекса по сравнению с другими путями доступа
Использование индексов
Фундаментальным преимуществом любого индекса по сравнению с другими путями доступа

Использование индексов
Существует также возможность сформировать индекс на основе значений двух или
Использование индексов
Существует также возможность сформировать индекс на основе значений двух или
Использование индексов
Использование индексов

Операторы SQL
Создание индекса
СREATE INDEX <имя индекса>
ОN <имя таблицы>
Операторы SQL
Создание индекса
СREATE INDEX <имя индекса>
ОN <имя таблицы>

Распределенные базы данных
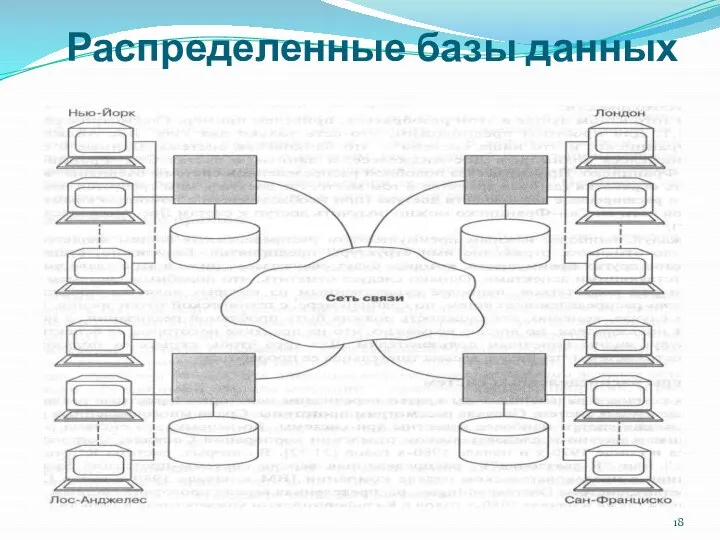
Система распределенных баз данных состоит из набора узлов (site),
Распределенные базы данных
Система распределенных баз данных состоит из набора узлов (site),
Распределенные базы данных
Распределенные базы данных

Распределенные базы данных
Зачем нужны распределенные базы данных? Основная причина заключается в
Распределенные базы данных
Зачем нужны распределенные базы данных? Основная причина заключается в

Распределенные базы данных
Для того чтобы лучше в этом разобраться, приведем пример.
Распределенные базы данных
Для того чтобы лучше в этом разобраться, приведем пример.

Распределенные базы данных
Принцип локальной независимости
Узлы в распределенной системе должны быть
Распределенные базы данных
Принцип локальной независимости
Узлы в распределенной системе должны быть

Распределенные базы данных
Принцип отсутствия зависимости от центрального узла
Локальная независимость предполагает, что
Распределенные базы данных
Принцип отсутствия зависимости от центрального узла
Локальная независимость предполагает, что

Распределенные базы данных
Принцип независимости от фрагментации
Система поддерживает независимость данных
Распределенные базы данных
Принцип независимости от фрагментации
Система поддерживает независимость данных
Распределенные базы данных
Распределенные базы данных

Распределенные базы данных
К обязанностям системного оптимизатора относится определение фрагментов, к
Распределенные базы данных
К обязанностям системного оптимизатора относится определение фрагментов, к
Распределенные базы данных
Принцип независимости от репликации
Система поддерживает репликацию данных, если отношение
Распределенные базы данных
Принцип независимости от репликации
Система поддерживает репликацию данных, если отношение
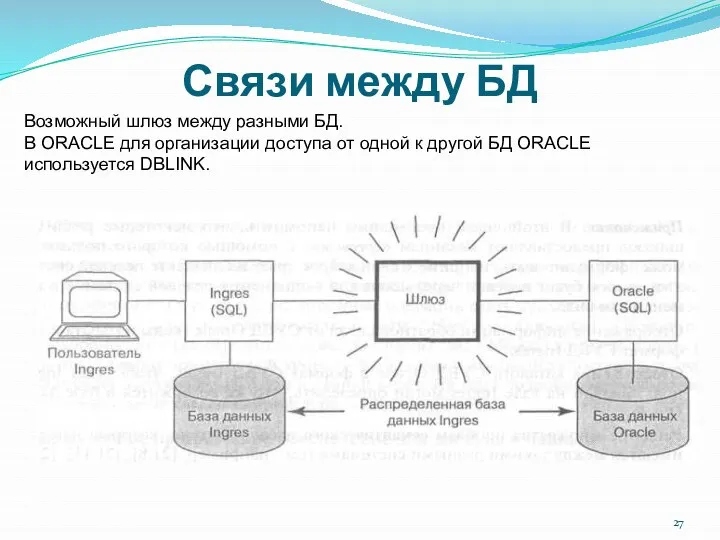
Связи между БД
Возможный шлюз между разными БД.
В ОRACLE для организации
Связи между БД
Возможный шлюз между разными БД.
В ОRACLE для организации
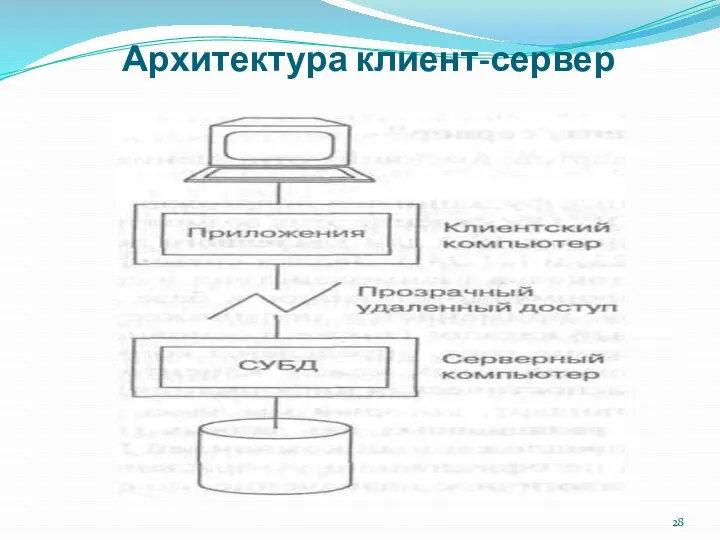
Архитектура клиент-сервер
Архитектура клиент-сервер
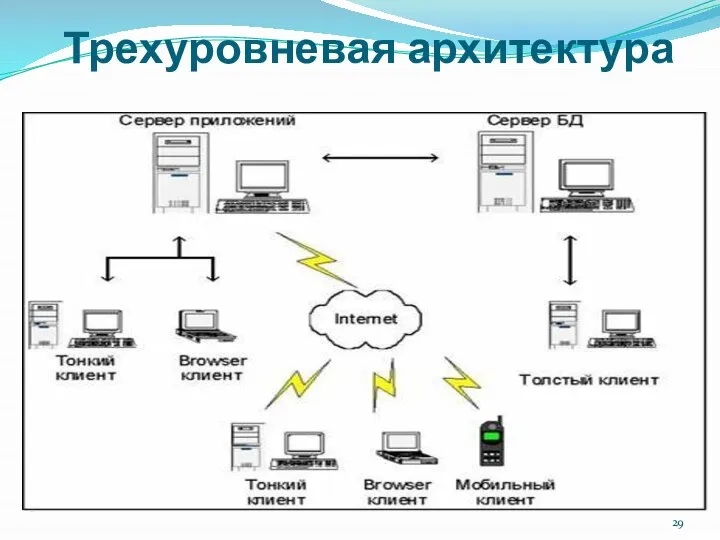
Трехуровневая архитектура
Трехуровневая архитектура

Трехуровневая архитектура
Терминал - это интерфейсный (обычно графический) компонент, который представляет первый
Трехуровневая архитектура
Терминал - это интерфейсный (обычно графический) компонент, который представляет первый
 Презентация____
Презентация____ Весняні свята на Україні
Весняні свята на Україні Game Develop. Создание игр
Game Develop. Создание игр Договор строительного подряда
Договор строительного подряда Презентация Предмет трудового права как отрасли права
Презентация Предмет трудового права как отрасли права  PubMed – медициналық ақпапарттық желісі 4- топша
PubMed – медициналық ақпапарттық желісі 4- топша Ідеологічно-пропагандивний блок
Ідеологічно-пропагандивний блок Экономика природопользования
Экономика природопользования Тайны планеты Меркурий
Тайны планеты Меркурий Принятие управленческих решений
Принятие управленческих решений Пути превращения иных гексоз в глюкозу. Галактоземии.
Пути превращения иных гексоз в глюкозу. Галактоземии. Целочисленные алгоритмы
Целочисленные алгоритмы СЛОЖЕНИЕ С ПЕРЕХОДОМ ЧЕРЕЗ ДЕСЯТОК. Сложение вида + 6. Презентацию выполнила учитель начальных классов МБОУ СОШ №8 Хазиева А.
СЛОЖЕНИЕ С ПЕРЕХОДОМ ЧЕРЕЗ ДЕСЯТОК. Сложение вида + 6. Презентацию выполнила учитель начальных классов МБОУ СОШ №8 Хазиева А. Слово жизни. Об извилистых и труднопроходимых путях
Слово жизни. Об извилистых и труднопроходимых путях Функции
Функции Организация проведения таможенного досмотра Презентацию подготовила студентка 1 курса группы ЮБ02/1403 Иванова Ксения
Организация проведения таможенного досмотра Презентацию подготовила студентка 1 курса группы ЮБ02/1403 Иванова Ксения  лекция 4
лекция 4 Презентация "Культура России в XVI в" - скачать презентации по МХК
Презентация "Культура России в XVI в" - скачать презентации по МХК Программирование с "защитой от ошибок". Сквозной структурный контроль
Программирование с "защитой от ошибок". Сквозной структурный контроль Презентация Делегирование полномочий
Презентация Делегирование полномочий Презентация "Права потребителей" - скачать презентации по Экономике
Презентация "Права потребителей" - скачать презентации по Экономике Учебно–методический комплекс по дисциплине «Инженерная графика»
Учебно–методический комплекс по дисциплине «Инженерная графика» Памятники культуры Древнего и Средневекового мира (разные цивилизации). Новое. Часть 2
Памятники культуры Древнего и Средневекового мира (разные цивилизации). Новое. Часть 2 Презентация Определяющие тенденции эволюции сферы внешнеэкономической и таможенной деятельности России
Презентация Определяющие тенденции эволюции сферы внешнеэкономической и таможенной деятельности России  Как называется? Познавательная викторина
Как называется? Познавательная викторина Презентация "Изображение фигуры человека и образ человека (тест)" - скачать презентации по МХК
Презентация "Изображение фигуры человека и образ человека (тест)" - скачать презентации по МХК Правоведение. Понятие, признаки и формы правового государства
Правоведение. Понятие, признаки и формы правового государства ТЕМА 7. СТАТИСТИЧЕСКОЕ ИЗУЧЕНИЕ ВАРИАЦИИ
ТЕМА 7. СТАТИСТИЧЕСКОЕ ИЗУЧЕНИЕ ВАРИАЦИИ