- Информационные технологии управления данными. Базы данных и системы управления базами данных

Содержание
- 2. Профессиональная деятельность человека постоянно связана с восприятием и накоплением информации об окружающей среде, отбором и обработкой
- 3. В результате деятельности каждое из подразделений, взаимодействуя с другими подразделениями, накапливает данные, которые описывают и деятельность
- 4. Следует всегда помнить о том, что единственная цель размещения данных в информационной системе – последующее извлечение
- 5. Информационная технология баз данных и систем управлениями базами данных (СУБД) –неотъемлемая часть практически любой информационной системы
- 6. Общепринятый современный способ реализации этой технологии – применение баз данных (БД) и систем управления базами данных
- 7. База данных (БД) предназначена для хранения: данных «инструментов» для извлечения информации (но эти «инструменты» могут работать
- 8. Разделение возникло в результате опыта эксплуатации информационных систем, и причины такого разделения связаны с двумя обстоятельствами:
- 9. Классические примеры: список контактов в вашем телефоне, справочная система к любой прикладной программе, системы резервирования авиа
- 10. Окончательно: База данных (БД) – это хранилище, в котором хранятся данные о тех объектах, для которых
- 11. Основные требования, предъявляемые к БД Адекватность информации состоянию предметной области. База данных является информационной моделью предметной
- 12. Быстродействие и производительность. Первое из них определяется временем ответа (реакции) системы на запрос. Это время зависит
- 13. Защита информации. Возможность расширения. Архитектура системы должна допускать расширение ее возможностей путем модификации или замены существующих
- 14. Модели организации данных (предварительные замечания) Любая база данных реализует какую-то модель организации данных. Предшественниками технологии баз
- 15. «Примитивная» ИС Файл (или несколько файлов), в котором хранятся данные, плюс какие-то прикладные программы, с помощью
- 16. Минимальной «информационной единицей» объекта «Студенты специальностей ГМУ и МО» в данном примере является отдельный студент, поэтому
- 17. Запись (состоит из значений реквизитов) Поле (имя поля – название реквизита)
- 18. Названия (имена) полей таблицы – это названия (имена) реквизитов (атрибутов): фамилия имя отчество название группы …
- 19. Открыв этот файл, например, с помощью программы «Блокнот», вы получаете возможность: редактировать (изменять данные, добавлять записи)
- 20. Таким образом, используя текстовый файл с данными и две прикладные программы, мы получили примитивную информационную систему,
- 21. Если открыть этот же текстовый файл в программе Word, то круг возможных операций с данными расширится
- 22. Если открыть этот же текстовый файл в программе Excel, то круг возможных операций с данными расширяется
- 23. Следствия из рассмотренного примера: В первом приближении – «база данных» это хранилище данных. Обратите внимание: в
- 24. Недостатки рассмотренной «информационной системы» Первый и очевидный недостаток – «не очень удобный интерфейс». Все современные СУБД
- 25. Второй недостаток – открытость и доступность для пользователя файла (файлов), в которых хранятся данные. Накопленный к
- 26. Третий недостаток – хранение так называемых «избыточных данных». Избыточные данные – это одни и те же
- 27. Нежелательность хранения избыточных данных (1) Нерациональное использование памяти. Например, каждая буква в текстовых данных требует для
- 28. Нежелательность хранения избыточных данных (2) Неоднозначность данных. «Человеку свойственно ошибаться». Следствием этого могут быть, например, орфографические
- 29. Нежелательность хранения избыточных данных (3) Несогласованность данных. Если какое-то данное повторяется многократно (хранится в базе во
- 30. В «устройстве» всех современных СУБД заложена концепция: в идеале все данные записываются только однажды (в одном
- 31. Объект, для информационного описания которого создается база данных, состоит, как правило, из множества отдельных «сущностей», взаимодействующих
- 32. Возможное решение, позволяющее «избавиться» от избыточных данных – хранение данных в отдельных таблицах. Простой пример: Создадим
- 33. Позитивные следствия разделения данных: Исчезли повторяющиеся данные о названиях групп (очевидно, что при большом числе записей
- 34. Негативное следствие разделения данных: Появилась «проблема» – проблема выдачи информации в удобном виде, поскольку, например, в
- 35. Модели данных Важнейшую роль при обеспечении эффективного хранения данных извлечения из них информации играют методы организации
- 36. В настоящее время известны и применяются следующие модели организации данных: Иерархическая Сетевая Реляционная Объектно-ориентированная Объектно-реляционная Следует
- 37. Иерархическая модель Записи организованы в наборы, которые связываются друг с другом связями «владения» Данные связаны между
- 38. Сетевая модель Очень похожа «внешне» на иерархическую модель, но допускает связи между данными, находящимися, например, на
- 39. Реляционная модель. Основные положения Перевод слова «relation»: отношение, связь, зависимость Концепцию, лежащую в основе реляционных баз
- 40. Каждая таблица реляционной базы данных содержит сведения о какой-то части объекта, о «сущностях» из которых состоит
- 41. Специфика таблиц реляционной БД Таблица состоит из строк одинакового вида и имеет своё уникальное имя Строки
- 42. Пример использования СУБД Access для реализации реляционной модели данных Прикладная программа Microsoft Access, входящая в состав
- 43. Иллюстрация основных положений на примере реляционной БД Таблицы, в которых содержатся данные о составляющих объекта «факультет»
- 44. Первичный ключ По определению, таблица реляционной БД есть множество уникальных записей, поэтому таблицы не могут содержать
- 45. Вторичный (внешний) ключ В таблицах реляционной БД хранятся данные не только об отдельных сущностях, но и
- 46. Связи между полями таблиц Связи между полями отражают реальные взаимосвязи между сущностями Данные о сущностях и
- 47. «Устройство» реляционной базы данных
- 48. Процесс извлечения информации в реляционных базах данных «перекладывается» на «инструменты» базы данных, которые содержат алгоритмы извлечения
- 49. Инструменты базы данных Запросы Формы Отчеты … «Инструменты» базы данных хранятся вместе с базой данных, но
- 50. Запросы Служат для извлечения данных из таблиц и представления их пользователю в удобном виде. По существу
- 51. Запросы (пользовательский аспект) Обратите внимание: многие из перечисленных операций можно выполнить непосредственно в таблицах, но из
- 52. Запросы (технологический аспект) Данные в запросе не хранятся Запрос наполняется данными из таблиц (и из других
- 53. Типы запросов Запрос на выборку Запрос на обновление данных в таблицах Запрос на добавление данных (присоединение
- 54. Запрос на выборку Позволяет выбрать данные из одной или нескольких таблиц и ранее созданных запросов Результаты
- 55. Запрос на выборку (продолжение) Могут быть использованы условия отбора практически любой степени сложности как по данным
- 56. Перекрестный запрос Назначение – перекрестный запрос позволяет взглянуть на данные, содержащиеся в таблице или запросе, «под
- 57. Формы (бланки) Цель применения форм – сделать удобной работу пользователя с базой данных на экране Форма
- 58. Формы (продолжение) Форма может содержать различные элементы: поля списки поля со списками командные кнопки переключатели, флажки
- 59. Отчеты Предназначены для вывода данных на печать Исходные данные для отчета могут быть взяты из таблиц
- 60. Средства Ms Access для создания таблиц и инструментов Конструктор Мастера Автоформа Автоотчет Построитель выражений Вся база
- 61. Проектирование БД Все базы данных можно разделить на «удобные» и «неудобные» (по тому, как к ним
- 62. Техническое задание на проектирование базы данных должен предоставить заказчик. Для этого он должен знать, хотя бы
- 63. От ТЗ к проектированию Результатом проектирования является логическая структура базы данных, т.е. состав таблиц, их структура
- 64. Далее надо распределить свойства (реквизиты) по таблицам (каждому реквизиту соответствует поле). Это можно сделать двумя путями:
- 65. Интуитивный подход На основе знания конкретной предметной области происходит выделение отдельных информационных сущностей (например, для базы
- 66. Интуитивный подход (продолжение1) Экземпляр сущности образуется совокупностью конкретных значений реквизитов и должен однозначно определяться, т.е. идентифицироваться
- 67. Интуитивный подход (продолжение2) Анализ полученных основных таблиц. Если в них будут обнаружены повторяющиеся записи в некоторых
- 68. Формальный подход (Сущности выделяются на основе анализа взаимосвязей всех реквизитов) Теория реляционных баз данных – 70
- 69. О проектировании баз данных Оба подхода отображают информационно-логическую модель объекта При интуитивном подходе возможны существенные ошибки,
- 70. Разработка инструментов базы данных Состав, структуру и характеристики инструментов базы данных можно определить не только на
- 71. Архитектура организации хранения и доступа к данным
- 72. Основные требования к БД организации Адекватность данных состоянию предметной области База данных является информационной моделью предметной
- 73. Надежность функционирования Быстродействие и производительность Эти два близких друг другу требования отражают временные потребности пользователей. Первое
- 74. Простота и удобство использования Это требование предъявляется к БД со стороны всех без исключения категорий пользователей,
- 75. Защита информации Система должна обеспечивать защиту хранимых в ней данных и программ как от случайных искажений
- 76. По архитектуре организации хранения данных можно выделить: Локальные СУБД (все части локальной СУБД размещаются на одном
- 77. Файл-серверные и клиент-серверные технологии доступа к данным Файл-серверная технология доступа к данным Архитектура систем баз данных
- 78. Общая база данных размещается на сервере. С рабочей станции передается требование к серверу не на выдачу
- 79. Клиент-серверная технология доступа Пользователь (клиент) передает со своего компьютера запрос на машину сервера, где мощная СУБД
- 80. Документационные информационные системы и базы данных В фактографических базах данных элементом данных является запись. Это не
- 81. В зависимости от особенностей реализации хранилища документов ДИС можно разделить на две группы: Системы с поиском
- 82. Системы с поиском на основе индексирования В системах на основе индексирования документы помещаются в базу данных
- 83. При создании запроса формируется поисковый образ запроса (ПОЗ) и пользователь получает документы, для которых поля поисковых
- 84. Предметная рубрика может иметь подрубрики. Таким образом, может быть построена иерархическая классификация. Примером построения перечислительной и
- 85. Семантические навигационные системы В семантических навигационных системах документы снабжаются гиперссылками, соответствующими смысловым связям между документами или
- 86. Полнотекстовые информационные системы Сочетают два способа поиска дескрипторный и семантический. Примерами документационных баз данных, в которых
- 88. Скачать презентацию

Профессиональная деятельность человека постоянно связана с восприятием и накоплением информации об
Профессиональная деятельность человека постоянно связана с восприятием и накоплением информации об

В результате деятельности каждое из подразделений, взаимодействуя с другими подразделениями, накапливает
В результате деятельности каждое из подразделений, взаимодействуя с другими подразделениями, накапливает

Следует всегда помнить о том, что единственная цель размещения данных в
Следует всегда помнить о том, что единственная цель размещения данных в

Информационная технология баз данных и систем управлениями базами данных (СУБД) –неотъемлемая
Информационная технология баз данных и систем управлениями базами данных (СУБД) –неотъемлемая

Общепринятый современный способ реализации этой технологии – применение баз данных (БД)
Общепринятый современный способ реализации этой технологии – применение баз данных (БД)

База данных (БД) предназначена для хранения:
данных
«инструментов» для извлечения информации (но эти
База данных (БД) предназначена для хранения:
данных
«инструментов» для извлечения информации (но эти

Разделение возникло в результате опыта эксплуатации информационных систем, и причины такого
Разделение возникло в результате опыта эксплуатации информационных систем, и причины такого

Классические примеры: список контактов в вашем телефоне, справочная система к любой
Классические примеры: список контактов в вашем телефоне, справочная система к любой

Окончательно:
База данных (БД) – это хранилище, в котором хранятся данные о
Окончательно:
База данных (БД) – это хранилище, в котором хранятся данные о

Основные требования, предъявляемые к БД
Адекватность информации состоянию предметной области. База
Основные требования, предъявляемые к БД
Адекватность информации состоянию предметной области. База

Быстродействие и производительность. Первое из них определяется временем ответа (реакции) системы
Быстродействие и производительность. Первое из них определяется временем ответа (реакции) системы

Защита информации.
Возможность расширения. Архитектура системы должна допускать расширение ее возможностей
Защита информации.
Возможность расширения. Архитектура системы должна допускать расширение ее возможностей

Модели организации данных (предварительные замечания)
Любая база данных реализует какую-то модель организации
Модели организации данных (предварительные замечания)
Любая база данных реализует какую-то модель организации

«Примитивная» ИС
Файл (или несколько файлов), в котором хранятся данные, плюс какие-то
«Примитивная» ИС
Файл (или несколько файлов), в котором хранятся данные, плюс какие-то

Минимальной «информационной единицей» объекта «Студенты специальностей ГМУ и МО» в данном
Минимальной «информационной единицей» объекта «Студенты специальностей ГМУ и МО» в данном
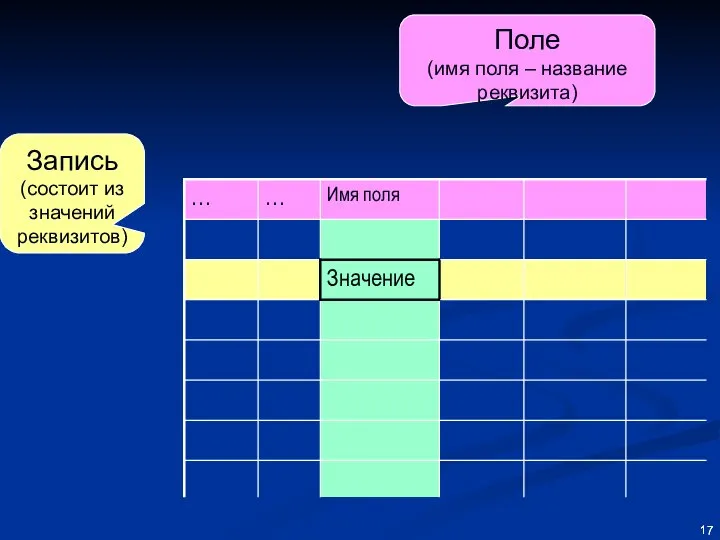
Запись
(состоит из значений реквизитов)
Поле
(имя поля – название реквизита)
Запись
(состоит из значений реквизитов)
Поле
(имя поля – название реквизита)

Названия (имена) полей таблицы – это названия (имена) реквизитов (атрибутов):
фамилия
имя
отчество
название
Названия (имена) полей таблицы – это названия (имена) реквизитов (атрибутов):
фамилия
имя
отчество
название

Открыв этот файл, например, с помощью программы «Блокнот», вы получаете возможность:
редактировать
Открыв этот файл, например, с помощью программы «Блокнот», вы получаете возможность:
редактировать

Таким образом, используя текстовый файл с данными и две прикладные программы,
Таким образом, используя текстовый файл с данными и две прикладные программы,

Если открыть этот же текстовый файл в программе Word, то круг
Если открыть этот же текстовый файл в программе Word, то круг

Если открыть этот же текстовый файл в программе Excel, то круг
Если открыть этот же текстовый файл в программе Excel, то круг

Следствия из рассмотренного примера:
В первом приближении – «база данных» это хранилище
Следствия из рассмотренного примера:
В первом приближении – «база данных» это хранилище

Недостатки рассмотренной
«информационной системы»
Первый и очевидный недостаток – «не очень удобный
Недостатки рассмотренной
«информационной системы»
Первый и очевидный недостаток – «не очень удобный

Второй недостаток – открытость и доступность для пользователя файла (файлов), в
Второй недостаток – открытость и доступность для пользователя файла (файлов), в

Третий недостаток – хранение так называемых «избыточных данных».
Избыточные данные – это
Третий недостаток – хранение так называемых «избыточных данных». Избыточные данные – это

Нежелательность хранения
избыточных данных (1)
Нерациональное использование памяти.
Например, каждая буква в
Нежелательность хранения
избыточных данных (1)
Нерациональное использование памяти. Например, каждая буква в

Нежелательность хранения
избыточных данных (2)
Неоднозначность данных.
«Человеку свойственно ошибаться». Следствием этого могут
Нежелательность хранения
избыточных данных (2)
Неоднозначность данных. «Человеку свойственно ошибаться». Следствием этого могут

Нежелательность хранения
избыточных данных (3)
Несогласованность данных.
Если какое-то данное повторяется многократно (хранится
Нежелательность хранения
избыточных данных (3)
Несогласованность данных. Если какое-то данное повторяется многократно (хранится

В «устройстве» всех современных СУБД заложена концепция: в идеале все данные

Объект, для информационного описания которого создается база данных, состоит, как правило,
Объект, для информационного описания которого создается база данных, состоит, как правило,

Возможное решение, позволяющее «избавиться» от избыточных данных – хранение данных в
Возможное решение, позволяющее «избавиться» от избыточных данных – хранение данных в

Позитивные следствия разделения данных:
Исчезли повторяющиеся данные о названиях групп (очевидно, что
Позитивные следствия разделения данных:
Исчезли повторяющиеся данные о названиях групп (очевидно, что

Негативное следствие разделения данных:
Появилась «проблема» – проблема выдачи информации в удобном
Негативное следствие разделения данных:
Появилась «проблема» – проблема выдачи информации в удобном

Модели данных
Важнейшую роль при обеспечении эффективного хранения данных извлечения из них
Модели данных
Важнейшую роль при обеспечении эффективного хранения данных извлечения из них

В настоящее время известны и применяются следующие модели организации данных:
Иерархическая
Сетевая
Реляционная
Объектно-ориентированная
Объектно-реляционная
Следует
В настоящее время известны и применяются следующие модели организации данных:
Иерархическая
Сетевая
Реляционная
Объектно-ориентированная
Объектно-реляционная
Следует

Иерархическая модель
Записи организованы в наборы, которые связываются друг с другом связями
Иерархическая модель
Записи организованы в наборы, которые связываются друг с другом связями

Сетевая модель
Очень похожа «внешне» на иерархическую модель, но допускает связи между
Сетевая модель
Очень похожа «внешне» на иерархическую модель, но допускает связи между

Реляционная модель. Основные положения
Перевод слова «relation»: отношение, связь, зависимость
Концепцию, лежащую в
Реляционная модель. Основные положения
Перевод слова «relation»: отношение, связь, зависимость
Концепцию, лежащую в

Каждая таблица реляционной базы данных содержит сведения о какой-то части объекта,
Каждая таблица реляционной базы данных содержит сведения о какой-то части объекта,

Специфика таблиц реляционной БД
Таблица состоит из строк одинакового вида и имеет
Специфика таблиц реляционной БД
Таблица состоит из строк одинакового вида и имеет

Пример использования СУБД Access для реализации реляционной модели данных
Прикладная программа Microsoft
Пример использования СУБД Access для реализации реляционной модели данных
Прикладная программа Microsoft

Иллюстрация основных положений на примере реляционной БД
Таблицы, в которых содержатся данные
Иллюстрация основных положений на примере реляционной БД
Таблицы, в которых содержатся данные

Первичный ключ
По определению, таблица реляционной БД есть множество уникальных записей, поэтому
Первичный ключ
По определению, таблица реляционной БД есть множество уникальных записей, поэтому

Вторичный (внешний) ключ
В таблицах реляционной БД хранятся данные не только об
Вторичный (внешний) ключ
В таблицах реляционной БД хранятся данные не только об

Связи между полями таблиц
Связи между полями отражают реальные взаимосвязи между сущностями
Данные
Связи между полями таблиц
Связи между полями отражают реальные взаимосвязи между сущностями
Данные
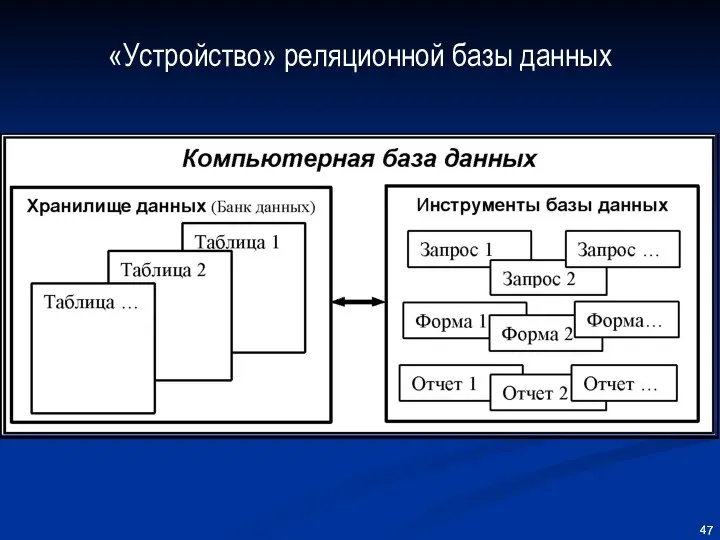
«Устройство» реляционной базы данных
«Устройство» реляционной базы данных

Процесс извлечения информации в реляционных базах данных «перекладывается» на «инструменты» базы
Процесс извлечения информации в реляционных базах данных «перекладывается» на «инструменты» базы

Инструменты базы данных
Запросы
Формы
Отчеты
…
«Инструменты» базы данных хранятся вместе с базой данных, но
Инструменты базы данных
Запросы
Формы
Отчеты
…
«Инструменты» базы данных хранятся вместе с базой данных, но

Запросы
Служат для извлечения данных
из таблиц и представления их пользователю
Запросы
Служат для извлечения данных из таблиц и представления их пользователю

Запросы (пользовательский аспект)
Обратите внимание:
многие из перечисленных операций можно выполнить непосредственно
Запросы (пользовательский аспект)
Обратите внимание:
многие из перечисленных операций можно выполнить непосредственно

Запросы (технологический аспект)
Данные в запросе не хранятся
Запрос наполняется данными из таблиц
Запросы (технологический аспект)
Данные в запросе не хранятся
Запрос наполняется данными из таблиц

Типы запросов
Запрос на выборку
Запрос на обновление данных в таблицах
Запрос на добавление
Типы запросов
Запрос на выборку
Запрос на обновление данных в таблицах
Запрос на добавление

Запрос на выборку
Позволяет выбрать данные из одной или нескольких таблиц и
Запрос на выборку
Позволяет выбрать данные из одной или нескольких таблиц и

Запрос на выборку (продолжение)
Могут быть использованы условия отбора практически любой степени
Запрос на выборку (продолжение)
Могут быть использованы условия отбора практически любой степени

Перекрестный запрос
Назначение – перекрестный запрос позволяет взглянуть на данные, содержащиеся в
Перекрестный запрос
Назначение – перекрестный запрос позволяет взглянуть на данные, содержащиеся в

Формы (бланки)
Цель применения форм – сделать удобной работу пользователя с базой
Формы (бланки)
Цель применения форм – сделать удобной работу пользователя с базой

Формы (продолжение)
Форма может содержать различные элементы:
поля
списки
поля со списками
командные кнопки
переключатели, флажки
изображения
Формы (продолжение)
Форма может содержать различные элементы:
поля
списки
поля со списками
командные кнопки
переключатели, флажки
изображения

Отчеты
Предназначены для вывода данных на печать
Исходные данные для отчета могут быть
Отчеты
Предназначены для вывода данных на печать
Исходные данные для отчета могут быть

Средства Ms Access для создания таблиц и инструментов
Конструктор
Мастера
Автоформа
Автоотчет
Построитель выражений
Вся база
Средства Ms Access для создания таблиц и инструментов
Конструктор
Мастера
Автоформа
Автоотчет
Построитель выражений
Вся база

Проектирование БД
Все базы данных можно разделить на «удобные» и «неудобные» (по
Проектирование БД
Все базы данных можно разделить на «удобные» и «неудобные» (по

Техническое задание на проектирование базы данных должен предоставить заказчик. Для этого
Техническое задание на проектирование базы данных должен предоставить заказчик. Для этого

От ТЗ к проектированию
Результатом проектирования является логическая структура базы данных, т.е.
От ТЗ к проектированию
Результатом проектирования является логическая структура базы данных, т.е.

Далее надо распределить свойства (реквизиты) по таблицам (каждому реквизиту соответствует поле).
Далее надо распределить свойства (реквизиты) по таблицам (каждому реквизиту соответствует поле).

Интуитивный подход
На основе знания конкретной предметной области происходит выделение отдельных информационных
Интуитивный подход
На основе знания конкретной предметной области происходит выделение отдельных информационных

Интуитивный подход (продолжение1)
Экземпляр сущности образуется совокупностью конкретных значений реквизитов и должен
Интуитивный подход (продолжение1)
Экземпляр сущности образуется совокупностью конкретных значений реквизитов и должен

Интуитивный подход (продолжение2)
Анализ полученных основных таблиц. Если в них будут обнаружены
Интуитивный подход (продолжение2)
Анализ полученных основных таблиц. Если в них будут обнаружены

Формальный подход
(Сущности выделяются на основе анализа взаимосвязей всех реквизитов)
Теория реляционных
Формальный подход
(Сущности выделяются на основе анализа взаимосвязей всех реквизитов)
Теория реляционных

О проектировании баз данных
Оба подхода отображают информационно-логическую модель объекта
При интуитивном подходе
О проектировании баз данных
Оба подхода отображают информационно-логическую модель объекта
При интуитивном подходе

Разработка инструментов базы данных
Состав, структуру и характеристики инструментов базы данных можно
Разработка инструментов базы данных
Состав, структуру и характеристики инструментов базы данных можно

Архитектура организации
хранения и доступа к данным
Архитектура организации
хранения и доступа к данным

Основные требования к БД организации
Адекватность данных состоянию предметной области
База данных
Основные требования к БД организации
Адекватность данных состоянию предметной области
База данных

Надежность функционирования
Быстродействие и производительность
Эти два близких друг другу требования
Надежность функционирования
Быстродействие и производительность
Эти два близких друг другу требования

Простота и удобство использования
Это требование предъявляется к БД со стороны
Простота и удобство использования
Это требование предъявляется к БД со стороны

Защита информации
Система должна обеспечивать защиту хранимых в ней данных и
Защита информации
Система должна обеспечивать защиту хранимых в ней данных и

По архитектуре организации хранения данных
можно выделить:
Локальные СУБД (все части локальной
По архитектуре организации хранения данных
можно выделить:
Локальные СУБД (все части локальной

Файл-серверные и клиент-серверные
технологии доступа к данным
Файл-серверная технология доступа к данным
Файл-серверные и клиент-серверные
технологии доступа к данным
Файл-серверная технология доступа к данным

Общая база данных размещается на сервере.
С рабочей станции передается требование
Общая база данных размещается на сервере.
С рабочей станции передается требование

Клиент-серверная технология доступа
Пользователь (клиент) передает со своего компьютера запрос на машину
Клиент-серверная технология доступа
Пользователь (клиент) передает со своего компьютера запрос на машину

Документационные информационные системы
и базы данных
В фактографических базах данных элементом данных
Документационные информационные системы
и базы данных
В фактографических базах данных элементом данных

В зависимости от особенностей реализации хранилища документов ДИС можно разделить
на
В зависимости от особенностей реализации хранилища документов ДИС можно разделить на

Системы с поиском на основе индексирования
В системах на основе индексирования документы
Системы с поиском на основе индексирования
В системах на основе индексирования документы

При создании запроса формируется поисковый образ запроса (ПОЗ) и пользователь получает
При создании запроса формируется поисковый образ запроса (ПОЗ) и пользователь получает

Предметная рубрика может иметь подрубрики. Таким образом, может быть построена иерархическая
Предметная рубрика может иметь подрубрики. Таким образом, может быть построена иерархическая

Семантические навигационные системы
В семантических навигационных системах документы снабжаются гиперссылками, соответствующими смысловым
Семантические навигационные системы
В семантических навигационных системах документы снабжаются гиперссылками, соответствующими смысловым

Полнотекстовые информационные системы
Сочетают два способа поиска дескрипторный и семантический.
Примерами документационных баз
Полнотекстовые информационные системы
Сочетают два способа поиска дескрипторный и семантический.
Примерами документационных баз
 Методы описательной психологии
Методы описательной психологии учитель начальных классов ГОУ (гимназия) №498
учитель начальных классов ГОУ (гимназия) №498 ВКР: Разработка и экономическое обоснования плана продаж продукции и услуг предприятия
ВКР: Разработка и экономическое обоснования плана продаж продукции и услуг предприятия Выразительные средства и техники работы в графике
Выразительные средства и техники работы в графике Согласование проектной документации на строительство, реконструкцию, модернизацию и ликвидацию опасных производственных объект
Согласование проектной документации на строительство, реконструкцию, модернизацию и ликвидацию опасных производственных объект Rok liturgiczny
Rok liturgiczny Взаимодействие процессов в UNIX
Взаимодействие процессов в UNIX Презентация "Скульптуры эллинизма" - скачать презентации по МХК
Презентация "Скульптуры эллинизма" - скачать презентации по МХК Метод индуктивных утверждений
Метод индуктивных утверждений Презентация Диаграмма причинно-следственных связей
Презентация Диаграмма причинно-следственных связей Религиозно- нравственная традиция в русской политической мысли конца 19- начала 20 вв. Подготовила Ермакова М. С.
Религиозно- нравственная традиция в русской политической мысли конца 19- начала 20 вв. Подготовила Ермакова М. С. Факториал
Факториал Умный город и умный дом для пенсионера
Умный город и умный дом для пенсионера Художественная культура Культура — область человеческой деятельности, связанная с самовыражением человека, проявлением его с
Художественная культура Культура — область человеческой деятельности, связанная с самовыражением человека, проявлением его с Три медведя
Три медведя  Управление сроками проекта
Управление сроками проекта Сфера духовной жизни
Сфера духовной жизни РАДИОТЕХНИЧЕСКИЕ ЦЕПИ И СИГНАЛЫ 15
РАДИОТЕХНИЧЕСКИЕ ЦЕПИ И СИГНАЛЫ 15 Система энергообеспечения клетки
Система энергообеспечения клетки  Старение информации или рассеяние информации во времени
Старение информации или рассеяние информации во времени Классическая теория электропроводности металлов. (Лекция 13)
Классическая теория электропроводности металлов. (Лекция 13) Народные Спортивные Игры
Народные Спортивные Игры Управление проектами
Управление проектами Презентация на тему "Роль познавательного интереса младших школьников в учебном процессе" - скачать презентации по Педагогик
Презентация на тему "Роль познавательного интереса младших школьников в учебном процессе" - скачать презентации по Педагогик Основные понятия. Принципы электрических измерений
Основные понятия. Принципы электрических измерений Политика и власть
Политика и власть Физическая культура как социальная система
Физическая культура как социальная система .01.2017 НТР и мировое хозяйство
.01.2017 НТР и мировое хозяйство