- компьютерное распознавание и машинное обучение

Содержание
- 2. Содержание курса «Компьютерные методы обработки информации» Раздел 1. «Базовые методы компьютерной обработки информации» Принципы построения систем
- 3. Содержание лекции Обучение с учителем. Пространство признаков. Классы. Обучающая и тестовая выборки. Гипотеза компактности. Методы ближайших
- 4. Обучение с учителем Компоненты задачи: пространство объектов A, множество классов С={c1, …,cl}, разбиение объектов по классам:
- 5. Задача синтеза классификатора. Как описать «наилучшее разбиение»? Дополнительные компоненты задачи: Тестовая выборка с′Y(x): x∈Y |→ с∈С,
- 6. Задача синтеза классификатора. Как описать «наилучшее разбиение»? Дополнительные компоненты задачи: Тестовая выборка с′Y(x): x∈Y |→ с∈С,
- 7. Синтез классификатора. Анализ постановки задачи Требуется: Определить оператор оптимального синтеза θ, доставляющий минимум критерию JX(fX): θ:
- 8. Упрощение задачи: обучение классификатора вместо синтеза классификатора Дополнительные компоненты задачи обучения: Класс классификаторов FX Класс алгоритмов
- 9. Упрощение задачи: обучение классификатора вместо синтеза классификатора Дополнительные компоненты задачи обучения: Класс классификаторов FX Класс алгоритмов
- 10. Проблема сложности классификатора Ф(A,L) = J(A,L) → min(L∈F(x)) x f(x)
- 11. Проблема сложности классификатора Ф(A,L) = J(A,L) → min(L∈F(x)) x f(x)
- 12. Регуляризация по сложности Ф(A,L)=J(A,L)+α×Q(L)→min(L∈F(x)) x f(x)
- 13. Регуляризация ⇒ сегментация с потерями Ф(A,L)=J(A,L)+α×Q(L)→min(L∈F(x)) x f(x)
- 14. Упрощение задачи: наблюдаемый риск вместо ожидаемого Проблема: наблюдаемый риск JX(θсX) имеет глобальный минимум в точке fX
- 15. Упрощение задачи: обучение классификатора заданного класса с регуляризацией по сложности Требуется: минимизировать наблюдаемый риск с регуляризацией
- 16. GX Источники основных идей Принцип эмпирической неразличимости алгоритмов, дающих одинаковые результаты на объектах обучающей выборки. Вапник
- 17. Источники основных идей Принцип компактности: более близкие объекты должны с большей вероятностью принадлежать к одному классу.
- 18. О чем умолчал Учитель Важное замечание: наблюдаемые данные действительно искажены, а мы пытаемся вскрыть их истинную
- 19. О чем умолчал Учитель Важное замечание: наблюдаемые данные действительно искажены, а мы пытаемся вскрыть их истинную
- 20. Источники основных идей сX fX Возможность 01 Возможность 10 случайные опыты детерминированная возможность классов на выборке
- 21. Следующие несколько разделов мы изучаем по книге
- 22. Статистическое обучение Пример. Один признак
- 23. Статистическое обучение Пример. Два признака
- 24. Напоминание. Функции распределения Площадь под функцией распределения всегда = 1, поскольку хоть какое-то значение случайная величина
- 25. Напоминание. Нормальное распределение
- 26. Статистическое обучение Плотности распределения и случайные выборки
- 27. Статистическое обучение Случай двух классов
- 28. Статистическое обучение Случай двух классов
- 29. Статистическое обучение Случай двух классов. Ошибки 1 и 2 рода
- 30. Статистическое обучение
- 31. Статистическое обучение Случай двух классов
- 32. Статистическое обучение Случай двух классов. Байесовское правило Вероятность ошибки определяется выражением:
- 33. Статистическое обучение Случай двух классов. Байесовское правило
- 34. Статистическое обучение Случай двух классов. Байесовское правило. Отношение правдоподобия Ожидаемый (средний) риск при принятии решения:
- 35. Статистическое обучение Случай двух классов. Байесовское правило. Отношение правдоподобия Ожидаемый (средний) риск при принятии решения:
- 36. Статистическое обучение Байесовское решающее правило
- 37. Статистическое обучение Байесовское решающее правило
- 38. Статистическое обучение Байесовское решающее правило
- 39. Статистическое обучение Байесовское решающее правило
- 40. Статистическое обучение Байесовское решающее правило
- 41. Статистическое обучение Байесовское решающее правило 2 класса, одинаковые дисперсии
- 42. Статистическое обучение Байесовское решающее правило 4 класса, одинаковые дисперсии
- 43. Статистическое обучение Байесовское решающее правило 4 класса, одинаковые дисперсии по классам, различные по признакам
- 44. Статистическое обучение Байесовское решающее правило, различные дисперсии по классам
- 45. Линейные решающие правила
- 46. Линейные решающие правила Случай двух классов. Минимизация квадратичной ошибки
- 47. Линейные решающие правила Случай двух классов. Линейный дискриминант Фишера :
- 48. Линейные решающие правила Случай нескольких классов. Набор линейных разделителей
- 49. Линейные решающие правила Случай нескольких классов. Набор линейных разделителей
- 50. Кластерный анализ Выводы: Нужно подбирать подходящие метрики Нужно искать удачные процедуры группировки
- 51. Напоминание: Метрики (расстояния) Метрики в нормированных линейных пространствах Единичный шар в метриках Минковского:
- 52. Кластерный анализ
- 53. Кластерный анализ
- 54. Кластерный анализ Метод k средних (количество классов k считается известным) Это одна из наиболее известных итеративных
- 55. Кластерный анализ Метод k средних (количество классов k считается известным) Пример:
- 56. Кластерный анализ Метод k средних (количество классов k считается известным)
- 57. Кластерный анализ Метод k средних (количество классов k считается известным)
- 58. Кластерный анализ Растущий нейронный газ Нейронный газ осуществляет адаптивную кластеризацию входных данных. Начиная всего с двух
- 59. Алгоритм обучения растущего нейронного газа . Инициализация: создать два узла с векторами весов, разрешенными распределением входных
- 60. Алгоритм обучения растущего нейронного газа Если два лучших нейрона s и t соединены, обнулить возраст их
- 61. Пример обучения растущего нейронного газа DemoGNG (Version 1.5) http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
- 62. Пример обучения растущего нейронного газа DemoGNG (Version 1.5) http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
- 63. Пример обучения растущего нейронного газа DemoGNG (Version 1.5) http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
- 64. Пример обучения растущего нейронного газа DemoGNG (Version 1.5) http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
- 65. Пример обучения растущего нейронного газа DemoGNG (Version 1.5) http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
- 66. Пример обучения растущего нейронного газа DemoGNG (Version 1.5) http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
- 67. Пример обучения растущего нейронного газа DemoGNG (Version 1.5) http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
- 68. Пример обучения растущего нейронного газа DemoGNG (Version 1.5) http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
- 69. Свойства растущего нейронного газа Адаптивная кластеризация входных данных Количество кластеров определяется исходя из топологии и распределения
- 70. Пример классификации на основе растущего нейронного газа в задаче цветовой сегментации изображения Цветовое пространство: CIE Lab
- 71. Кластерный анализ Иерархическая группировка
- 72. Кластерный анализ Иерархическая группировка 3 примера
- 73. Кластерный анализ Иерархическая группировка "Ближайший сосед"
- 74. Кластерный анализ Иерархическая группировка "Дальний сосед"
- 75. Кластерный анализ Иерархическая группировка Минимальное покрывающее дерево
- 76. Приложение: Биометрия В биометрических системах для распознавания человека используется совокупность биометрических характеристик, основанных на биологических особенностях
- 77. Процесс биометрической верификации Алгоритм построения шаблона Алгоритм сравнения Критерии качества: FAR(False Accept Rate) – вероятность принятия
- 78. Процесс биометрической верификации Биометрия Чем меньше площадь под графиком, тем лучше качество
- 79. Процесс биометрической идентификации Алгоритм построения шаблона Алгоритм сравнения База шаблонов Критерий качества Pn вероятность попадания в
- 80. Процесс биометрической идентификации Биометрия
- 82. Скачать презентацию

Содержание курса
«Компьютерные методы обработки информации»
Раздел 1. «Базовые методы компьютерной
Содержание курса
«Компьютерные методы обработки информации»
Раздел 1. «Базовые методы компьютерной

Содержание лекции
Обучение с учителем. Пространство признаков. Классы. Обучающая и тестовая
Содержание лекции
Обучение с учителем. Пространство признаков. Классы. Обучающая и тестовая
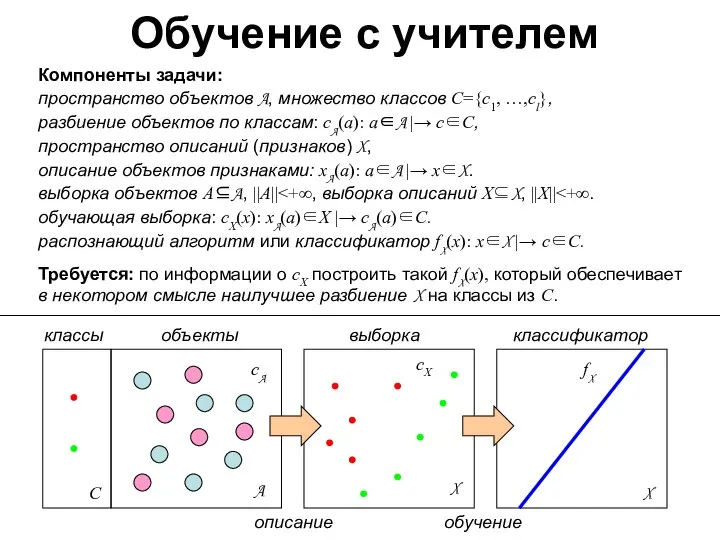
Обучение с учителем
Компоненты задачи:
пространство объектов A, множество классов С={c1, …,cl},
разбиение
Обучение с учителем
Компоненты задачи: пространство объектов A, множество классов С={c1, …,cl}, разбиение
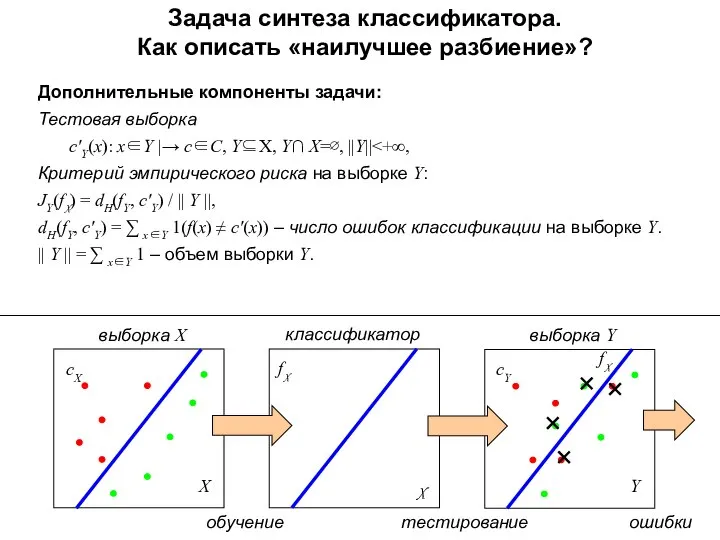
Задача синтеза классификатора.
Как описать «наилучшее разбиение»?
Дополнительные компоненты задачи:
Тестовая выборка
с′Y(x):
Задача синтеза классификатора.
Как описать «наилучшее разбиение»?
Дополнительные компоненты задачи:
Тестовая выборка
с′Y(x):

Задача синтеза классификатора.
Как описать «наилучшее разбиение»?
Дополнительные компоненты задачи:
Тестовая выборка
с′Y(x):
Задача синтеза классификатора.
Как описать «наилучшее разбиение»?
Дополнительные компоненты задачи:
Тестовая выборка
с′Y(x):

Синтез классификатора. Анализ постановки задачи
Требуется: Определить оператор оптимального синтеза θ,
Синтез классификатора. Анализ постановки задачи
Требуется: Определить оператор оптимального синтеза θ,
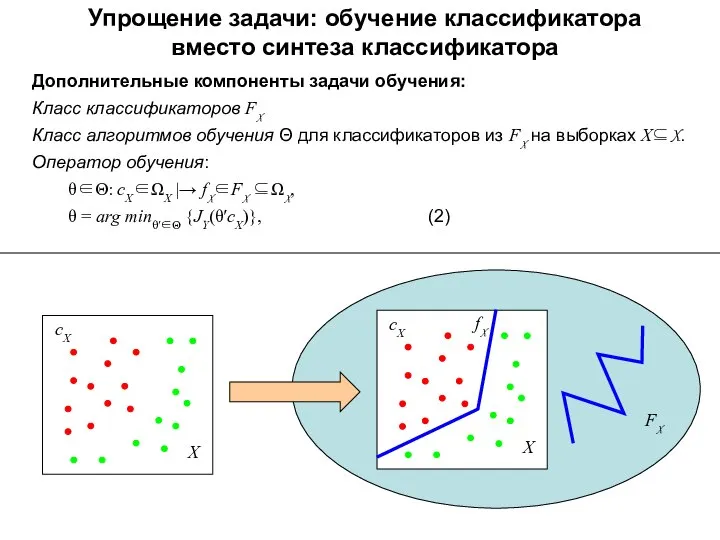
Упрощение задачи: обучение классификатора
вместо синтеза классификатора
Дополнительные компоненты задачи обучения:
Класс классификаторов
Упрощение задачи: обучение классификатора
вместо синтеза классификатора
Дополнительные компоненты задачи обучения:
Класс классификаторов
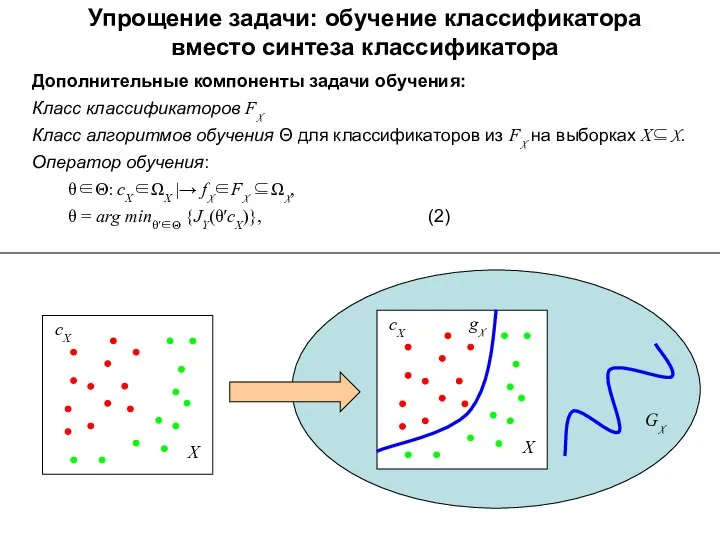
Упрощение задачи: обучение классификатора
вместо синтеза классификатора
Дополнительные компоненты задачи обучения:
Класс классификаторов
Упрощение задачи: обучение классификатора
вместо синтеза классификатора
Дополнительные компоненты задачи обучения:
Класс классификаторов

Проблема сложности классификатора
Ф(A,L) = J(A,L) → min(L∈F(x))
x
f(x)
Проблема сложности классификатора
Ф(A,L) = J(A,L) → min(L∈F(x))
x
f(x)
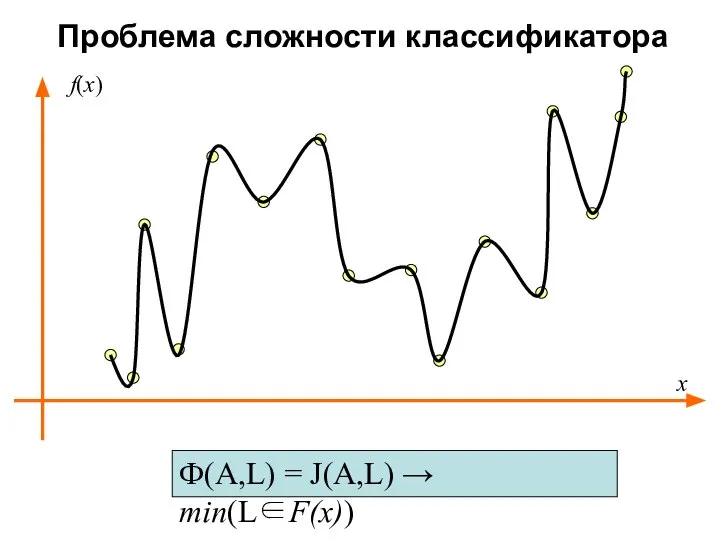
Проблема сложности классификатора
Ф(A,L) = J(A,L) → min(L∈F(x))
x
f(x)
Проблема сложности классификатора
Ф(A,L) = J(A,L) → min(L∈F(x))
x
f(x)
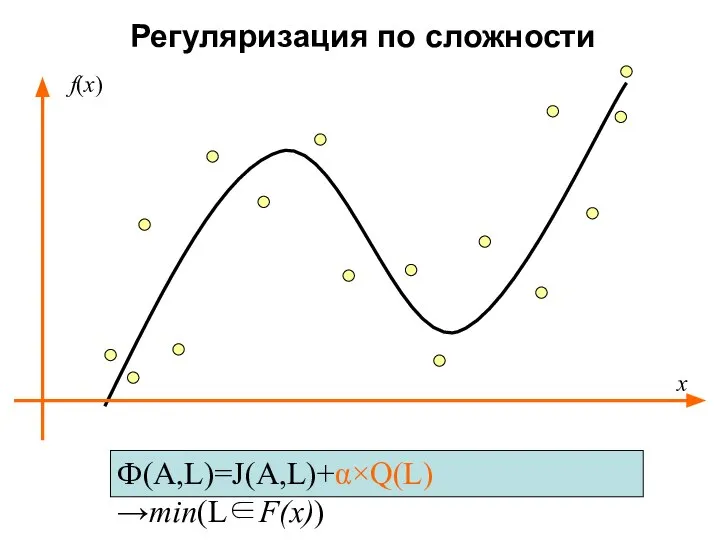
Регуляризация по сложности
Ф(A,L)=J(A,L)+α×Q(L)→min(L∈F(x))
x
f(x)
Регуляризация по сложности
Ф(A,L)=J(A,L)+α×Q(L)→min(L∈F(x))
x
f(x)
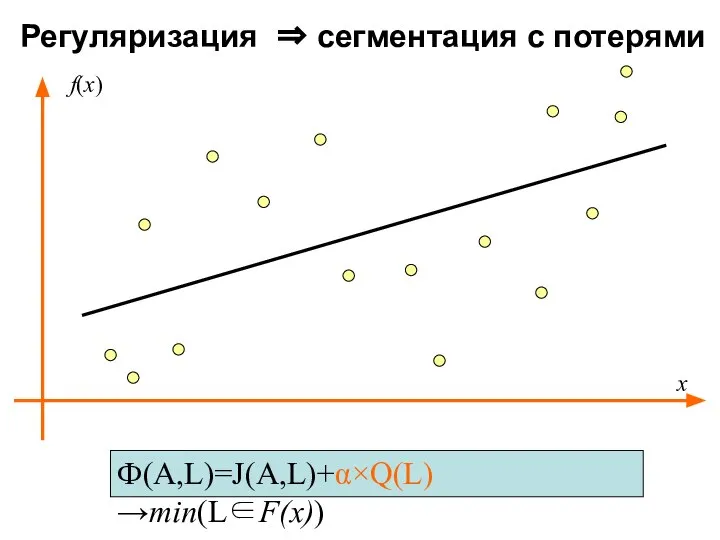
Регуляризация ⇒ сегментация с потерями
Ф(A,L)=J(A,L)+α×Q(L)→min(L∈F(x))
x
f(x)
Регуляризация ⇒ сегментация с потерями
Ф(A,L)=J(A,L)+α×Q(L)→min(L∈F(x))
x
f(x)
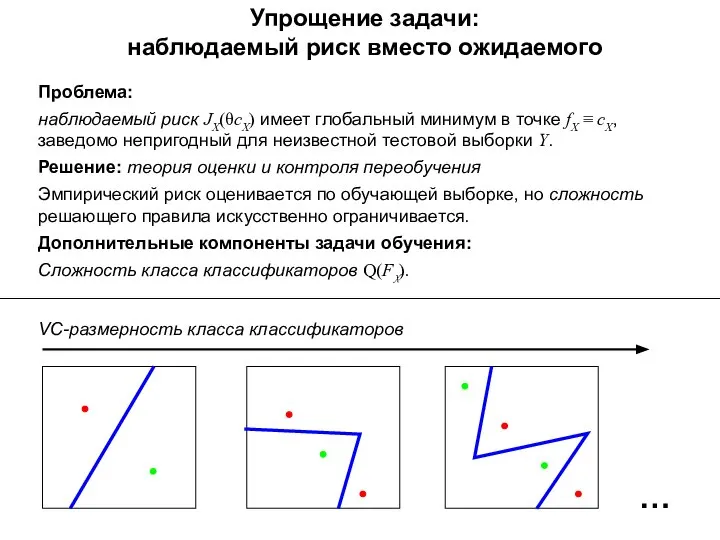
Упрощение задачи:
наблюдаемый риск вместо ожидаемого
Проблема:
наблюдаемый риск JX(θсX) имеет глобальный минимум
Упрощение задачи:
наблюдаемый риск вместо ожидаемого
Проблема:
наблюдаемый риск JX(θсX) имеет глобальный минимум

Упрощение задачи: обучение классификатора заданного класса с регуляризацией по сложности
Требуется:
Упрощение задачи: обучение классификатора заданного класса с регуляризацией по сложности
Требуется:
GX
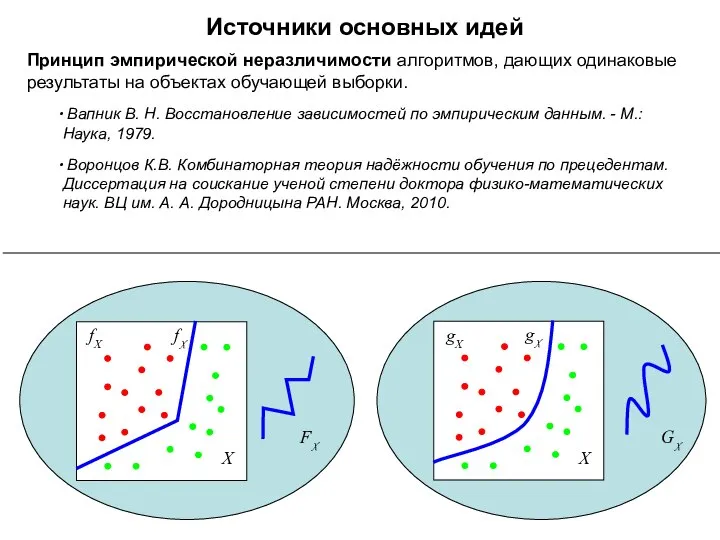
Источники основных идей
Принцип эмпирической неразличимости алгоритмов, дающих одинаковые результаты на объектах
GX
Источники основных идей
Принцип эмпирической неразличимости алгоритмов, дающих одинаковые результаты на объектах
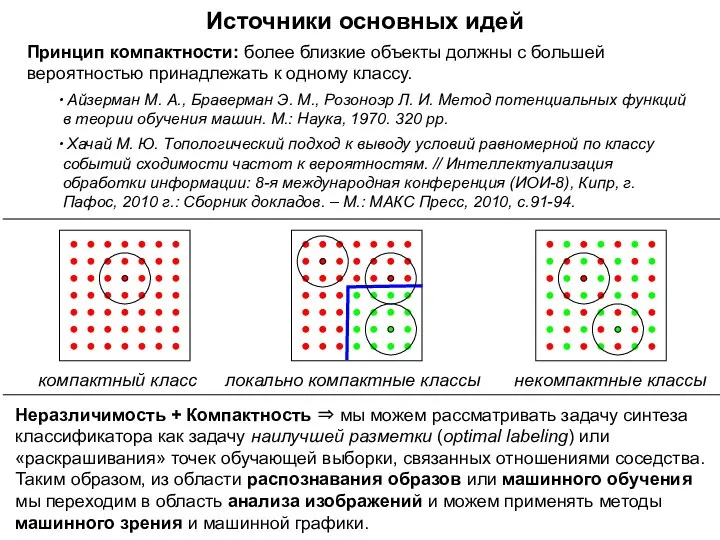
Источники основных идей
Принцип компактности: более близкие объекты должны с большей вероятностью
Источники основных идей
Принцип компактности: более близкие объекты должны с большей вероятностью

О чем умолчал Учитель
Важное замечание: наблюдаемые данные действительно искажены, а
О чем умолчал Учитель
Важное замечание: наблюдаемые данные действительно искажены, а
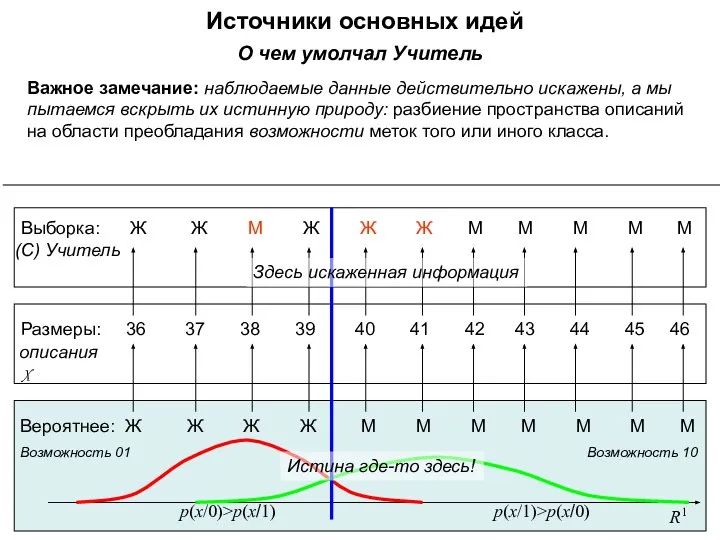
О чем умолчал Учитель
Важное замечание: наблюдаемые данные действительно искажены, а
О чем умолчал Учитель
Важное замечание: наблюдаемые данные действительно искажены, а
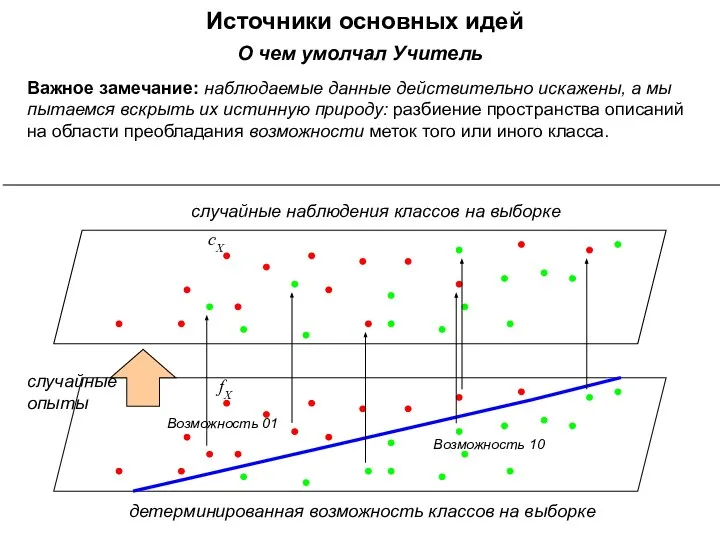
Источники основных идей
сX
fX
Возможность 01
Возможность 10
случайные
опыты
детерминированная возможность классов на выборке
случайные наблюдения классов
Источники основных идей
сX
fX
Возможность 01
Возможность 10
случайные
опыты
детерминированная возможность классов на выборке
случайные наблюдения классов

Следующие несколько разделов мы изучаем по книге
Следующие несколько разделов мы изучаем по книге
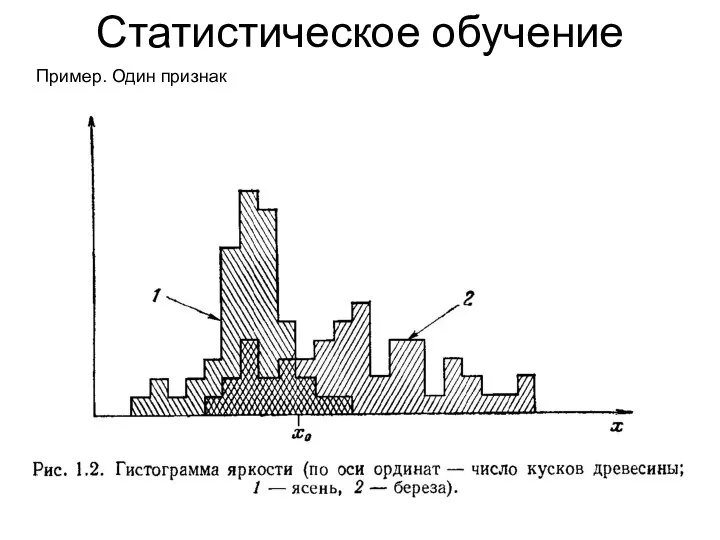
Статистическое обучение
Пример. Один признак
Статистическое обучение
Пример. Один признак
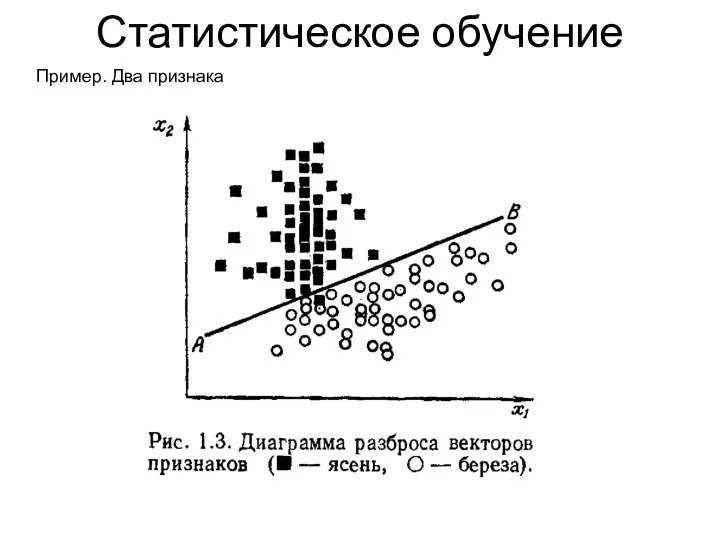
Статистическое обучение
Пример. Два признака
Статистическое обучение
Пример. Два признака
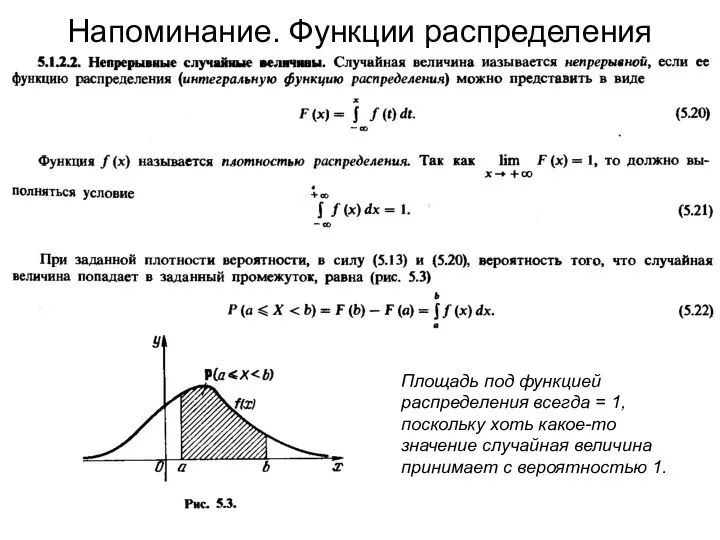
Напоминание. Функции распределения
Площадь под функцией распределения всегда = 1, поскольку
Напоминание. Функции распределения
Площадь под функцией распределения всегда = 1, поскольку
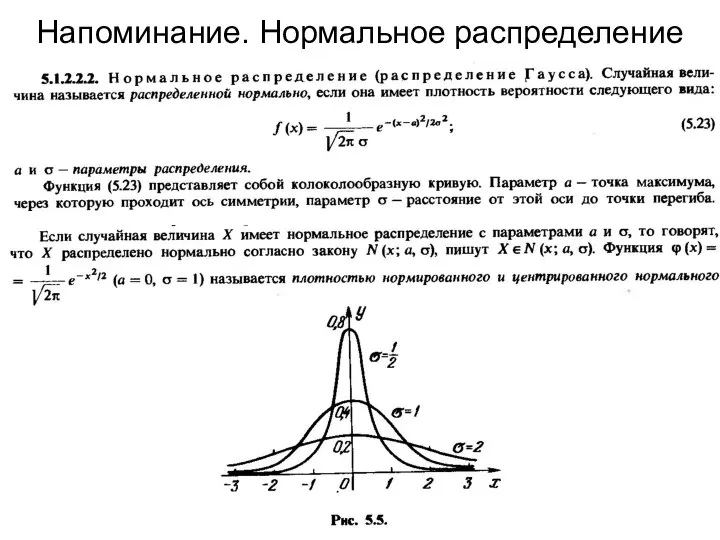
Напоминание. Нормальное распределение
Напоминание. Нормальное распределение
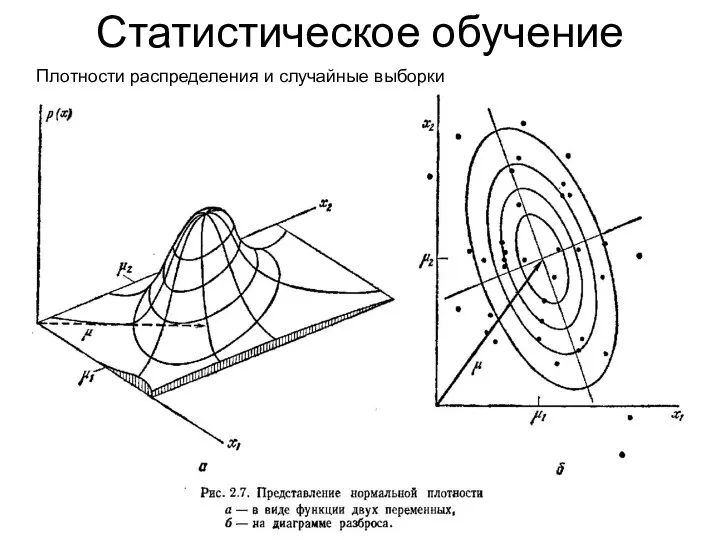
Статистическое обучение
Плотности распределения и случайные выборки
Статистическое обучение
Плотности распределения и случайные выборки
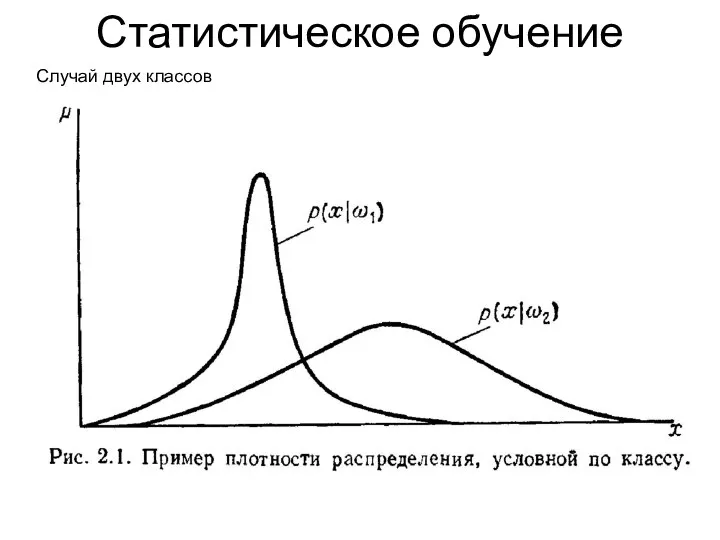
Статистическое обучение
Случай двух классов
Статистическое обучение
Случай двух классов
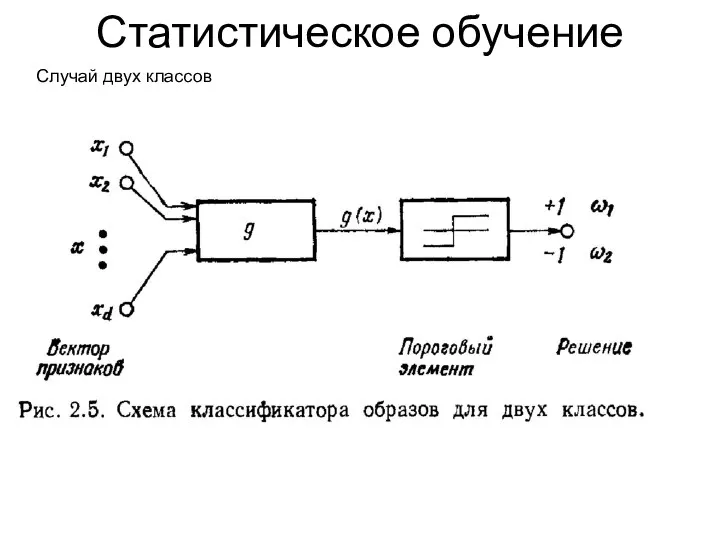
Статистическое обучение
Случай двух классов
Статистическое обучение
Случай двух классов
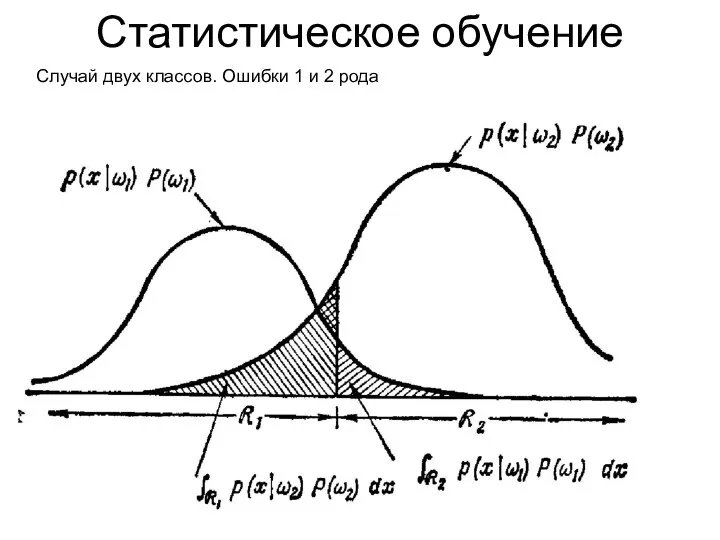
Статистическое обучение
Случай двух классов. Ошибки 1 и 2 рода
Статистическое обучение
Случай двух классов. Ошибки 1 и 2 рода

Статистическое обучение
Статистическое обучение
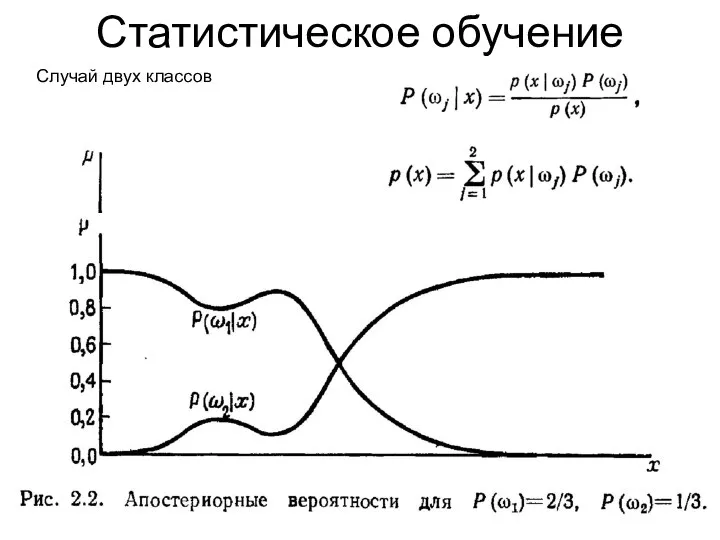
Статистическое обучение
Случай двух классов
Статистическое обучение
Случай двух классов

Статистическое обучение
Случай двух классов. Байесовское правило
Вероятность ошибки определяется выражением:
Статистическое обучение
Случай двух классов. Байесовское правило
Вероятность ошибки определяется выражением:

Статистическое обучение
Случай двух классов. Байесовское правило
Статистическое обучение
Случай двух классов. Байесовское правило

Статистическое обучение
Случай двух классов. Байесовское правило. Отношение правдоподобия
Ожидаемый (средний) риск
Статистическое обучение
Случай двух классов. Байесовское правило. Отношение правдоподобия
Ожидаемый (средний) риск

Статистическое обучение
Случай двух классов. Байесовское правило. Отношение правдоподобия
Ожидаемый (средний) риск
Статистическое обучение
Случай двух классов. Байесовское правило. Отношение правдоподобия
Ожидаемый (средний) риск
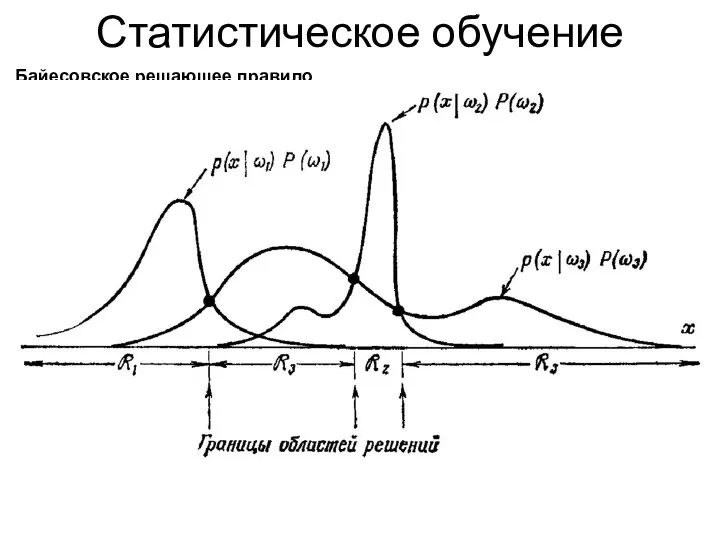
Статистическое обучение
Байесовское решающее правило
Статистическое обучение
Байесовское решающее правило
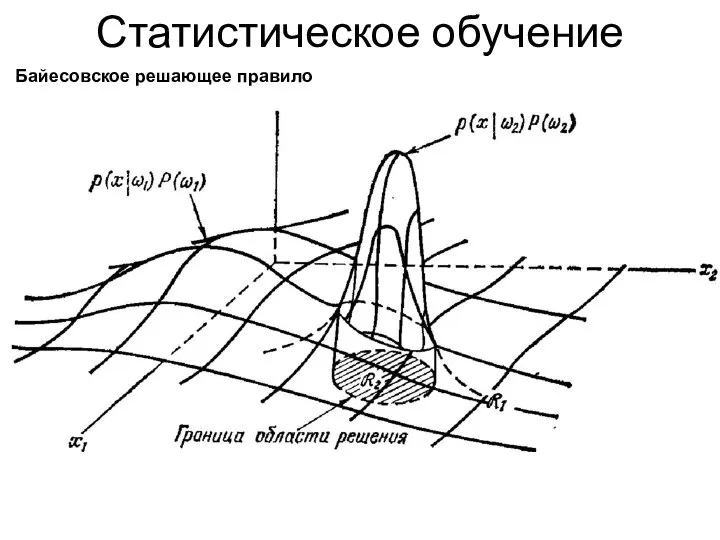
Статистическое обучение
Байесовское решающее правило
Статистическое обучение
Байесовское решающее правило
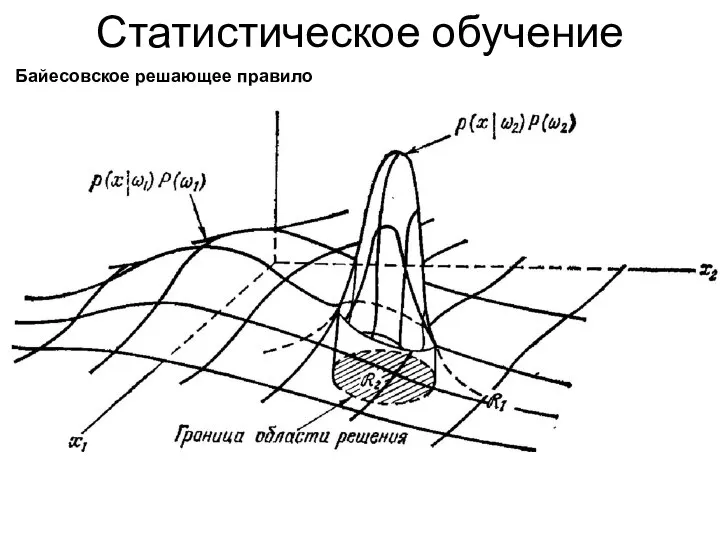
Статистическое обучение
Байесовское решающее правило
Статистическое обучение
Байесовское решающее правило

Статистическое обучение
Байесовское решающее правило
Статистическое обучение
Байесовское решающее правило

Статистическое обучение
Байесовское решающее правило
Статистическое обучение
Байесовское решающее правило
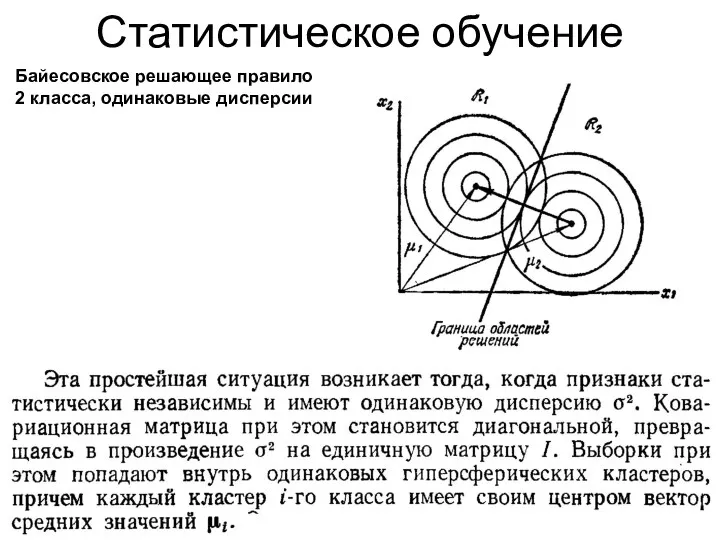
Статистическое обучение
Байесовское решающее правило
2 класса, одинаковые дисперсии
Статистическое обучение
Байесовское решающее правило
2 класса, одинаковые дисперсии
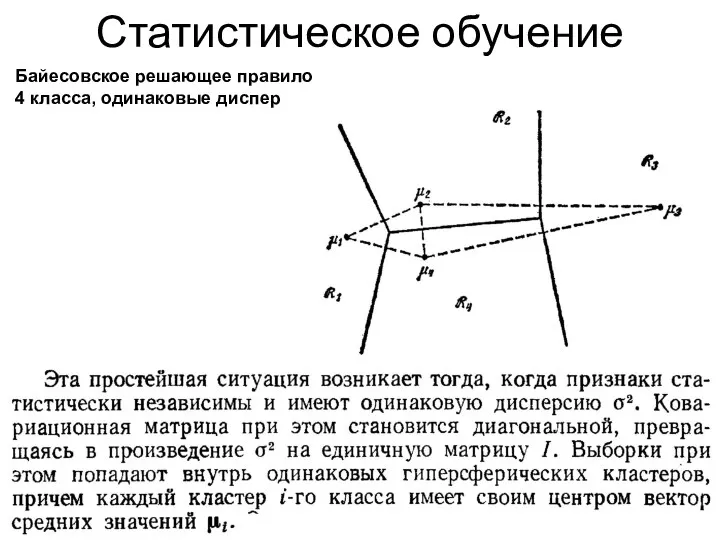
Статистическое обучение
Байесовское решающее правило
4 класса, одинаковые дисперсии
Статистическое обучение
Байесовское решающее правило
4 класса, одинаковые дисперсии
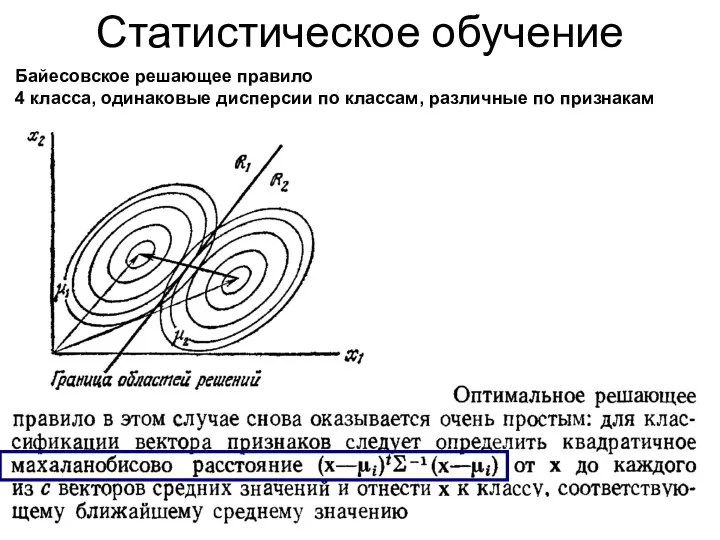
Статистическое обучение
Байесовское решающее правило
4 класса, одинаковые дисперсии по классам, различные
Статистическое обучение
Байесовское решающее правило
4 класса, одинаковые дисперсии по классам, различные

Статистическое обучение
Байесовское решающее правило, различные дисперсии по классам
Статистическое обучение
Байесовское решающее правило, различные дисперсии по классам
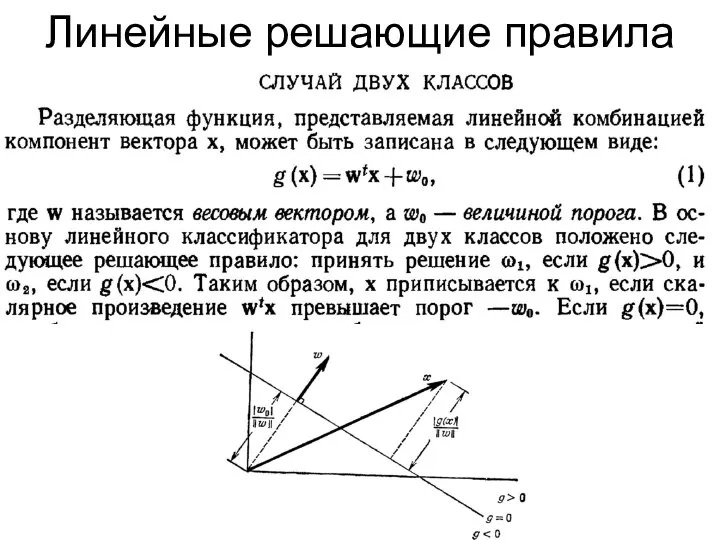
Линейные решающие правила
Линейные решающие правила
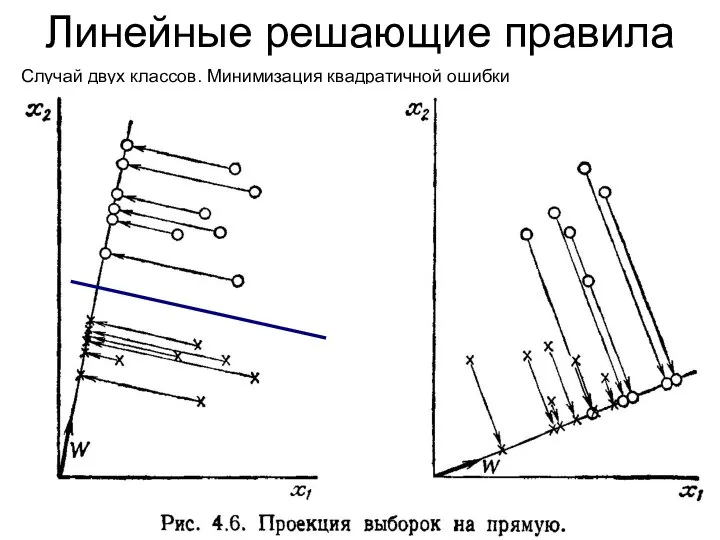
Линейные решающие правила
Случай двух классов. Минимизация квадратичной ошибки
Линейные решающие правила
Случай двух классов. Минимизация квадратичной ошибки

Линейные решающие правила
Случай двух классов. Линейный дискриминант Фишера
:
Линейные решающие правила
Случай двух классов. Линейный дискриминант Фишера
:
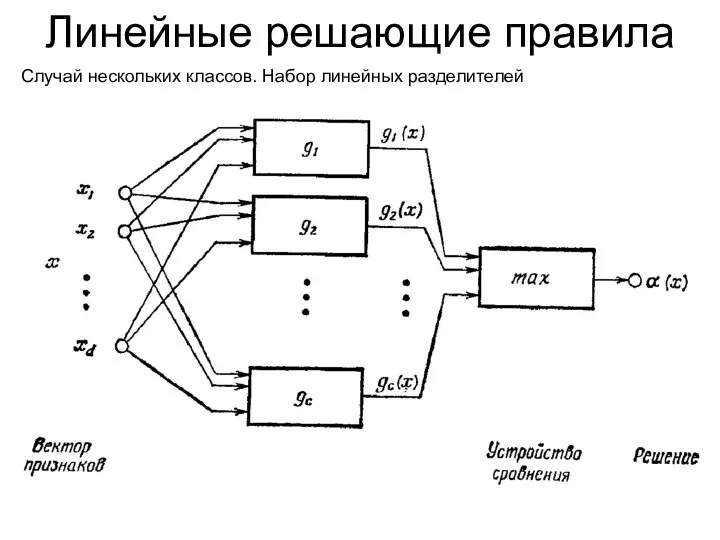
Линейные решающие правила
Случай нескольких классов. Набор линейных разделителей
Линейные решающие правила
Случай нескольких классов. Набор линейных разделителей
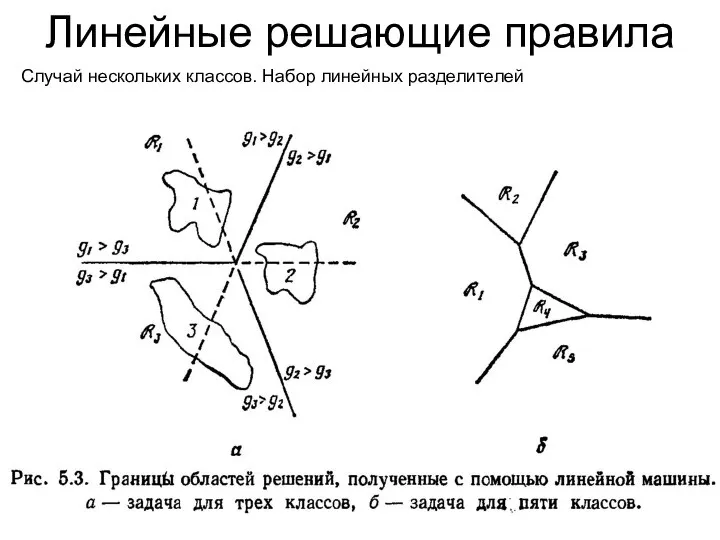
Линейные решающие правила
Случай нескольких классов. Набор линейных разделителей
Линейные решающие правила
Случай нескольких классов. Набор линейных разделителей

Кластерный анализ
Выводы:
Нужно подбирать подходящие метрики
Нужно искать удачные процедуры группировки
Кластерный анализ
Выводы:
Нужно подбирать подходящие метрики
Нужно искать удачные процедуры группировки
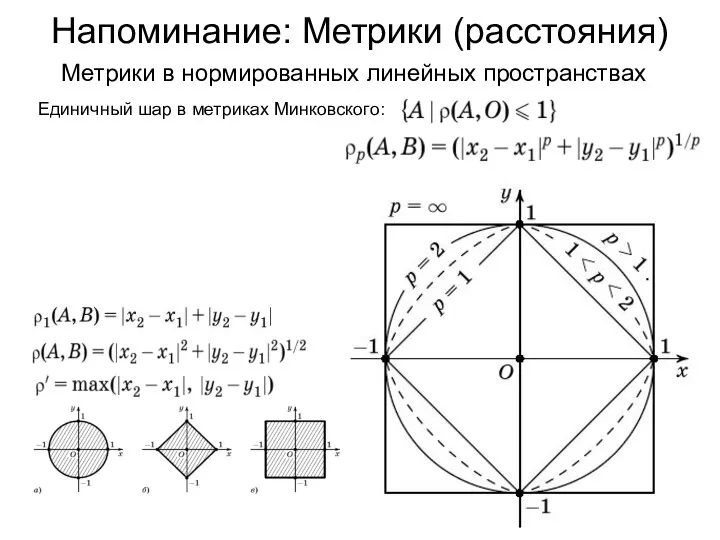
Напоминание: Метрики (расстояния)
Метрики в нормированных линейных пространствах
Единичный шар в метриках
Напоминание: Метрики (расстояния)
Метрики в нормированных линейных пространствах
Единичный шар в метриках
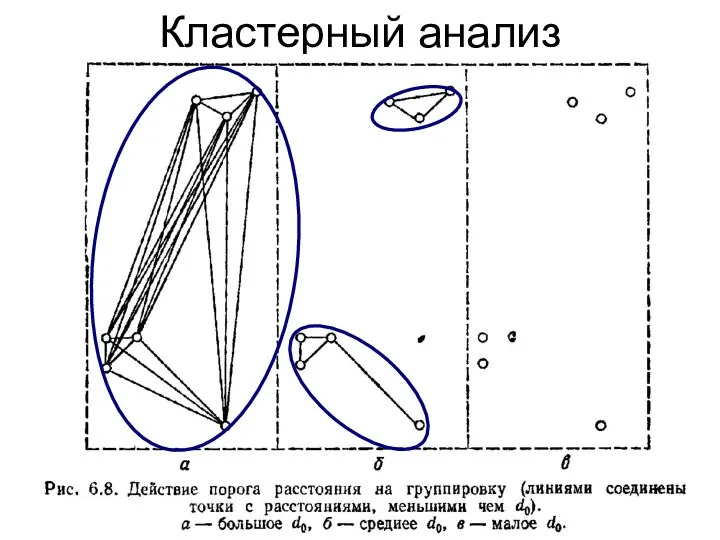
Кластерный анализ
Кластерный анализ
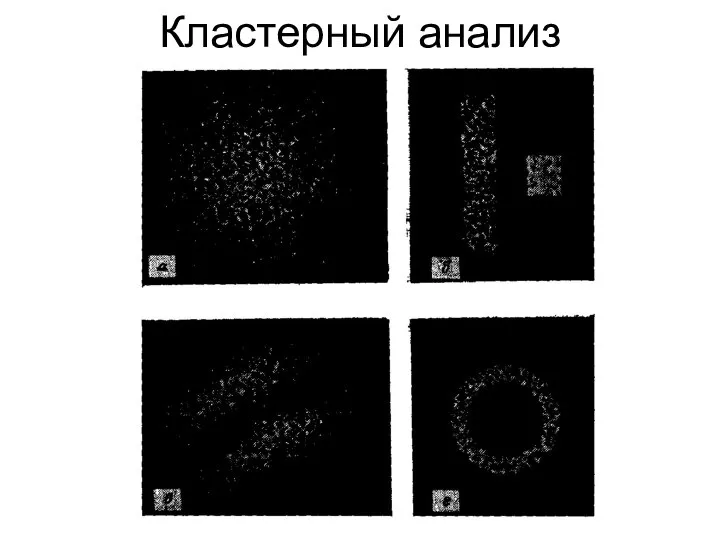
Кластерный анализ
Кластерный анализ

Кластерный анализ
Метод k средних (количество классов k считается известным)
Это одна
Кластерный анализ
Метод k средних (количество классов k считается известным)
Это одна
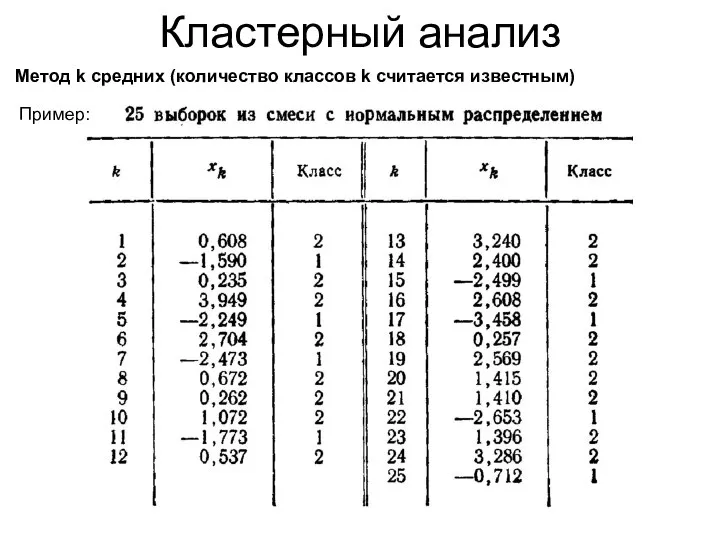
Кластерный анализ
Метод k средних (количество классов k считается известным)
Пример:
Кластерный анализ
Метод k средних (количество классов k считается известным)
Пример:
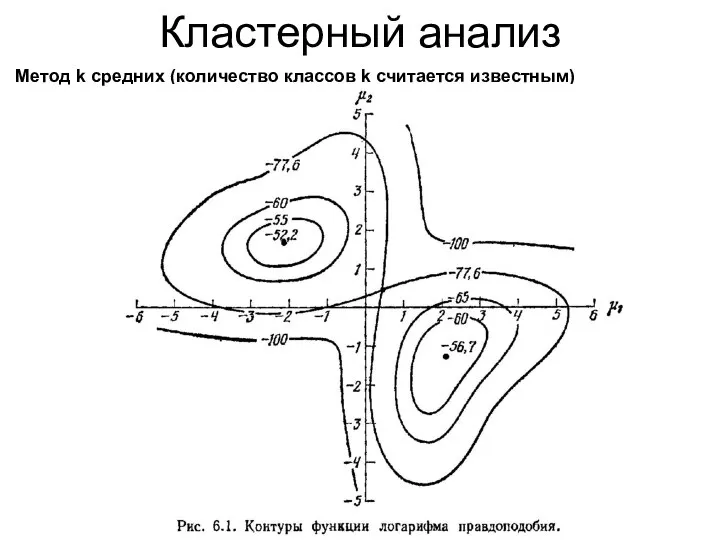
Кластерный анализ
Метод k средних (количество классов k считается известным)
Кластерный анализ
Метод k средних (количество классов k считается известным)
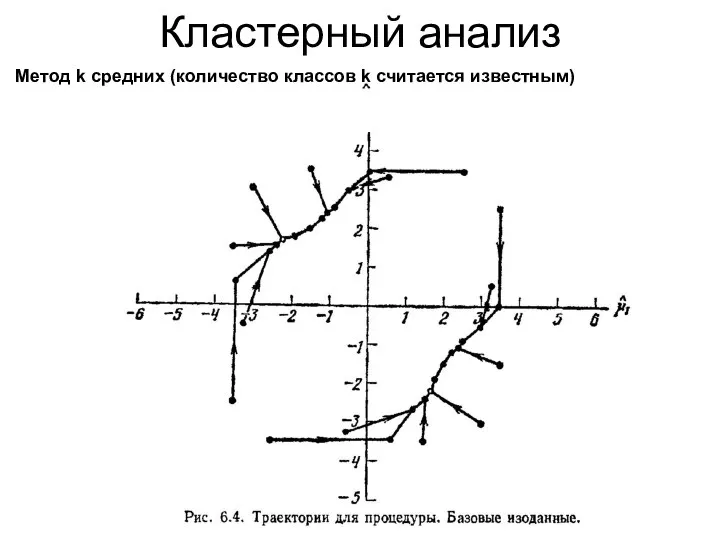
Кластерный анализ
Метод k средних (количество классов k считается известным)
Кластерный анализ
Метод k средних (количество классов k считается известным)
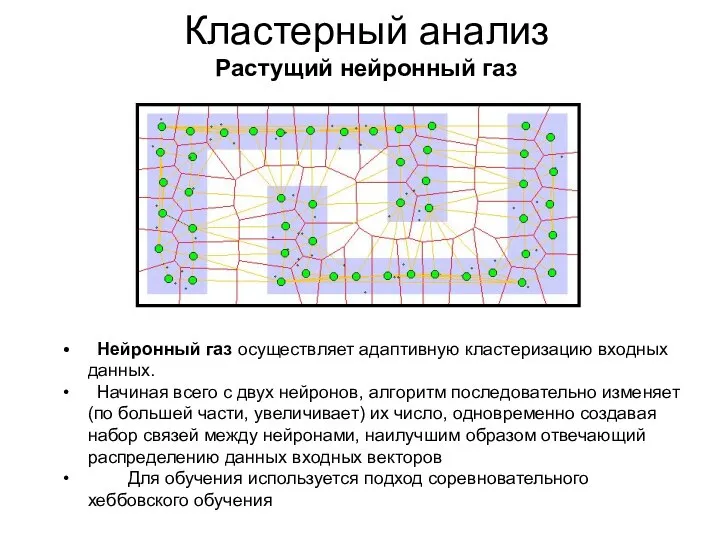
Кластерный анализ
Растущий нейронный газ
Нейронный газ осуществляет адаптивную кластеризацию входных данных.
Начиная
Кластерный анализ
Растущий нейронный газ
Нейронный газ осуществляет адаптивную кластеризацию входных данных.
Начиная

Алгоритм обучения растущего нейронного газа
. Инициализация: создать два узла с векторами
Алгоритм обучения растущего нейронного газа
. Инициализация: создать два узла с векторами

Алгоритм обучения растущего нейронного газа
Если два лучших нейрона s и t
Алгоритм обучения растущего нейронного газа
Если два лучших нейрона s и t
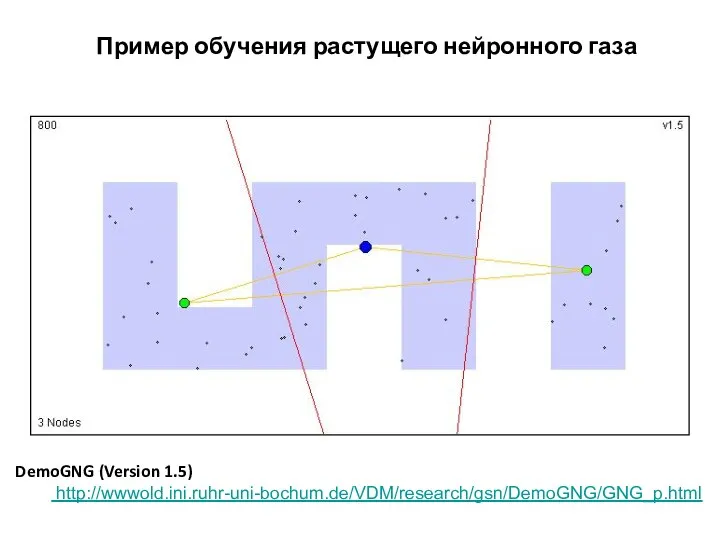
Пример обучения растущего нейронного газа
DemoGNG (Version 1.5)
http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
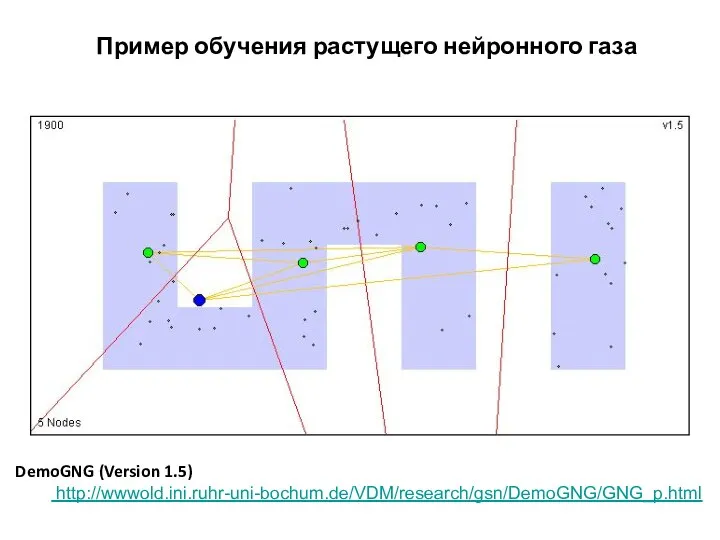
Пример обучения растущего нейронного газа
DemoGNG (Version 1.5)
http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
Пример обучения растущего нейронного газа
DemoGNG (Version 1.5)
http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
Пример обучения растущего нейронного газа
DemoGNG (Version 1.5)
http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
Пример обучения растущего нейронного газа
DemoGNG (Version 1.5)
http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
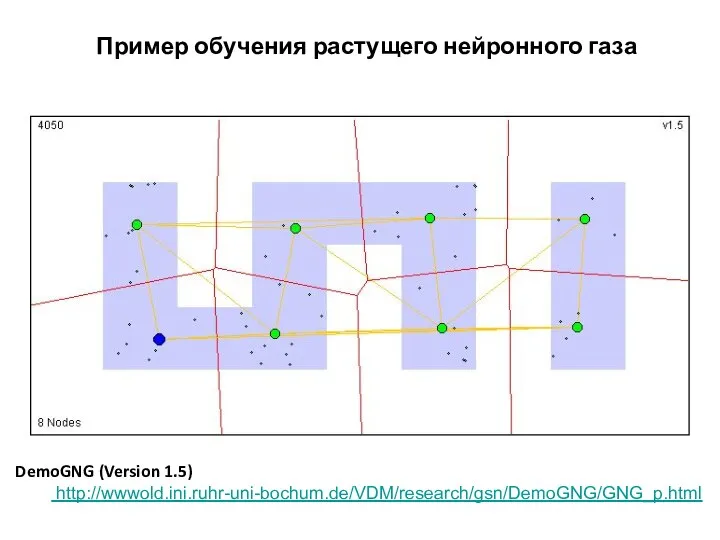
Пример обучения растущего нейронного газа
DemoGNG (Version 1.5)
http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html

Пример обучения растущего нейронного газа
DemoGNG (Version 1.5)
http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
Пример обучения растущего нейронного газа
DemoGNG (Version 1.5)
http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
Пример обучения растущего нейронного газа
DemoGNG (Version 1.5)
http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
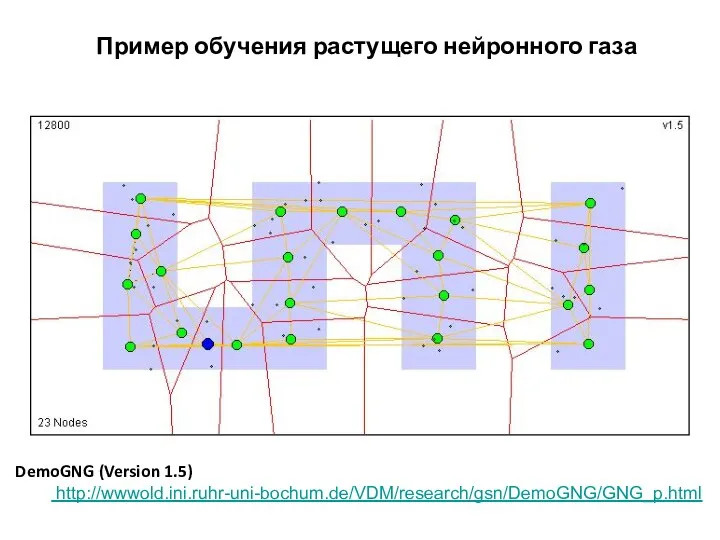
Пример обучения растущего нейронного газа
DemoGNG (Version 1.5)
http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
Пример обучения растущего нейронного газа
DemoGNG (Version 1.5)
http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
Пример обучения растущего нейронного газа
DemoGNG (Version 1.5)
http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
Пример обучения растущего нейронного газа
DemoGNG (Version 1.5)
http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
Пример обучения растущего нейронного газа
DemoGNG (Version 1.5)
http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
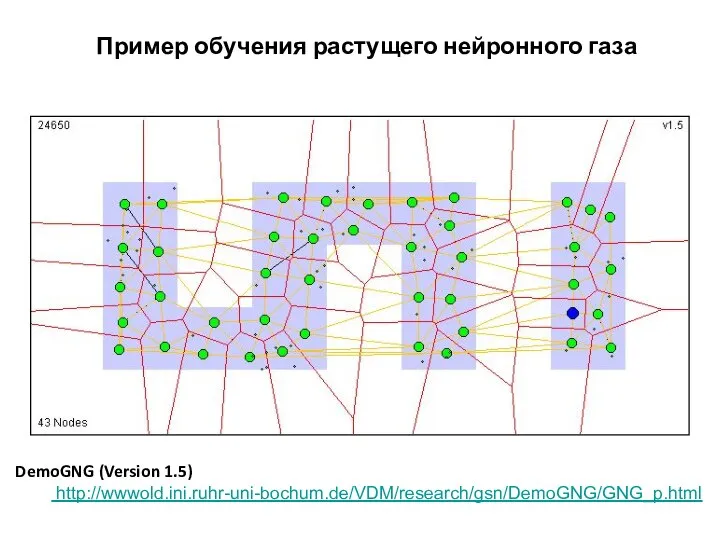
Пример обучения растущего нейронного газа
DemoGNG (Version 1.5)
http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html
Пример обучения растущего нейронного газа
DemoGNG (Version 1.5)
http://wwwold.ini.ruhr-uni-bochum.de/VDM/research/gsn/DemoGNG/GNG_p.html

Свойства растущего нейронного газа
Адаптивная кластеризация входных данных
Количество кластеров определяется исходя
Свойства растущего нейронного газа
Адаптивная кластеризация входных данных
Количество кластеров определяется исходя

Пример классификации на основе растущего нейронного газа в задаче цветовой сегментации
Пример классификации на основе растущего нейронного газа в задаче цветовой сегментации
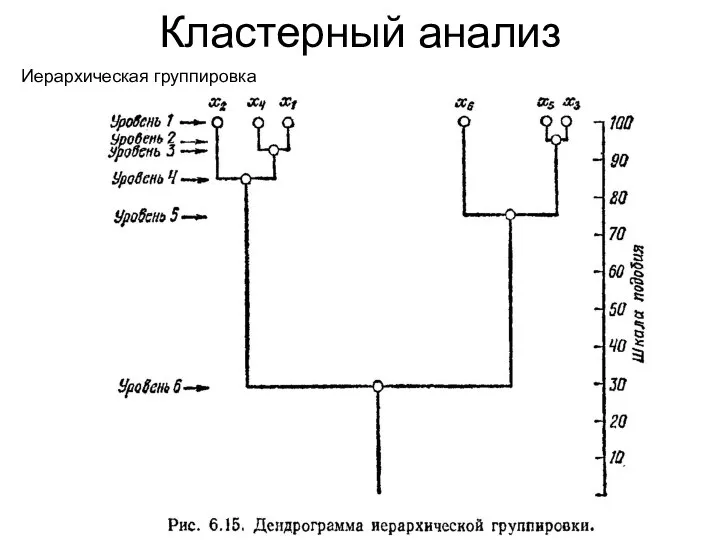
Кластерный анализ
Иерархическая группировка
Кластерный анализ
Иерархическая группировка

Кластерный анализ
Иерархическая группировка
3 примера
Кластерный анализ
Иерархическая группировка
3 примера
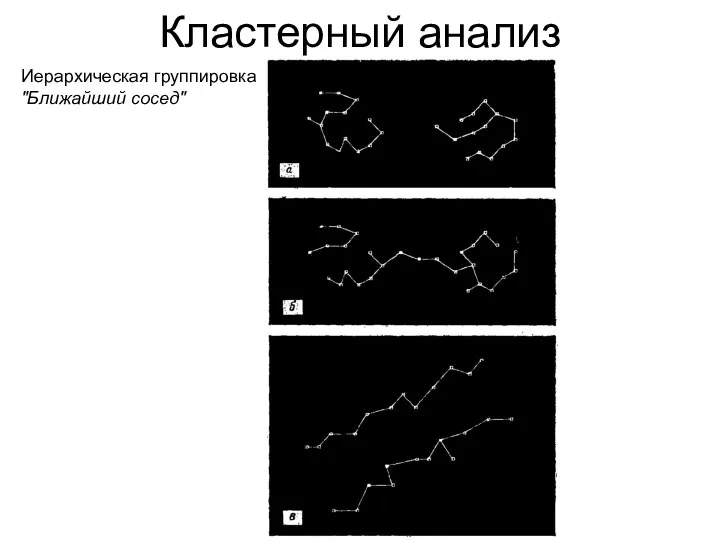
Кластерный анализ
Иерархическая группировка
"Ближайший сосед"
Кластерный анализ
Иерархическая группировка
"Ближайший сосед"

Кластерный анализ
Иерархическая группировка
"Дальний сосед"
Кластерный анализ
Иерархическая группировка
"Дальний сосед"

Кластерный анализ
Иерархическая группировка
Минимальное покрывающее
дерево
Кластерный анализ
Иерархическая группировка
Минимальное покрывающее
дерево

Приложение: Биометрия
В биометрических системах для распознавания человека используется совокупность биометрических
Приложение: Биометрия
В биометрических системах для распознавания человека используется совокупность биометрических
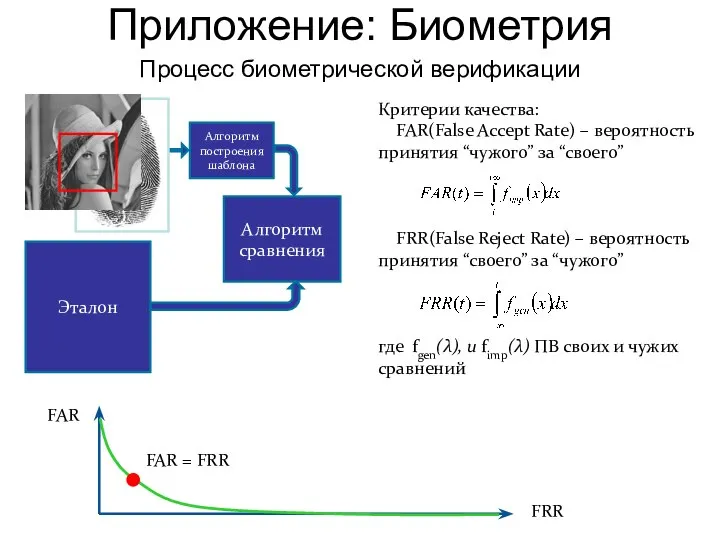
Процесс биометрической верификации
Алгоритм построения шаблона
Алгоритм сравнения
Критерии качества:
FAR(False Accept Rate) –
Процесс биометрической верификации
Алгоритм построения шаблона
Алгоритм сравнения
Критерии качества:
FAR(False Accept Rate) –
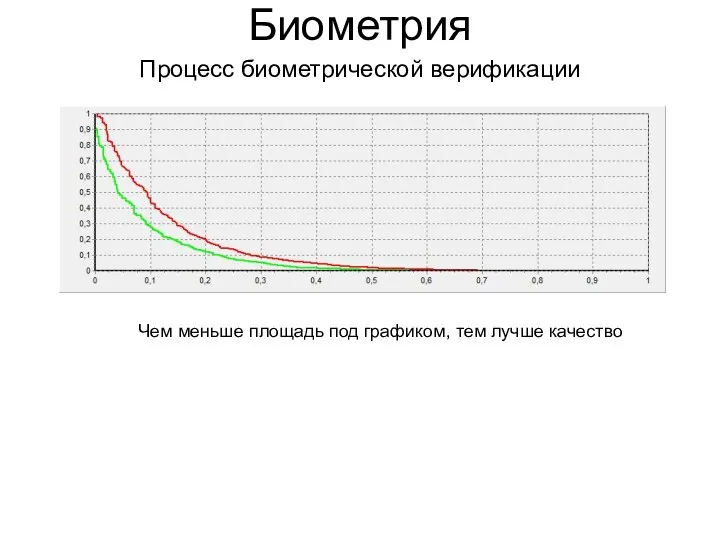
Процесс биометрической верификации
Биометрия
Чем меньше площадь под графиком, тем лучше качество
Процесс биометрической верификации
Биометрия
Чем меньше площадь под графиком, тем лучше качество
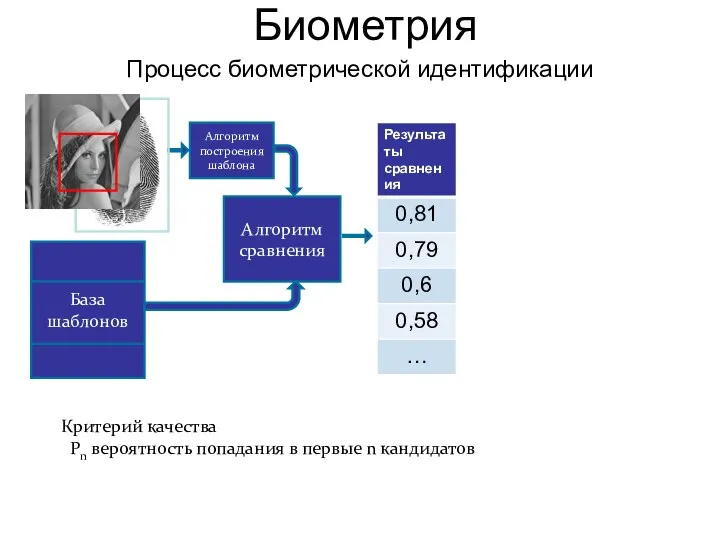
Процесс биометрической идентификации
Алгоритм построения шаблона
Алгоритм сравнения
База шаблонов
Критерий качества
Pn вероятность
Процесс биометрической идентификации
Алгоритм построения шаблона
Алгоритм сравнения
База шаблонов
Критерий качества
Pn вероятность
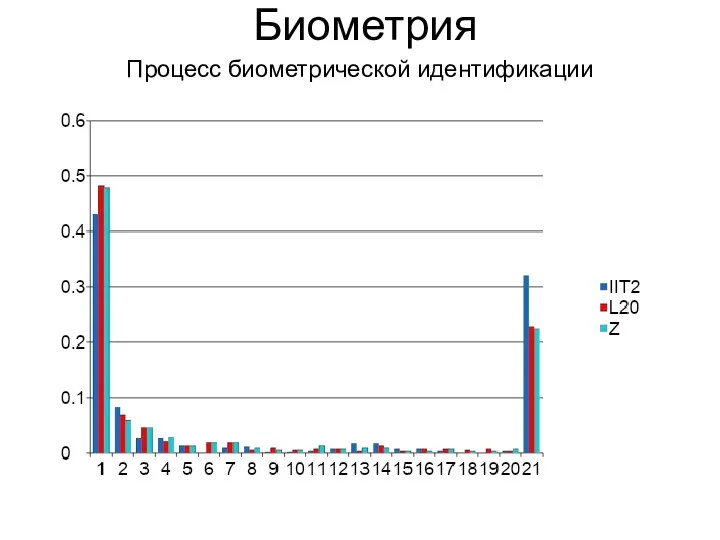
Процесс биометрической идентификации
Биометрия
Процесс биометрической идентификации
Биометрия
 Крутость или кротость
Крутость или кротость Автор: Шарова Валентина Степановна Учитель математики МОУ «СОШ №4» город Новочебоксарск Чувашской Республики Повторяем м
Автор: Шарова Валентина Степановна Учитель математики МОУ «СОШ №4» город Новочебоксарск Чувашской Республики Повторяем м Презентация "Ключ к пониманию бизнеса" - скачать презентации по Экономике
Презентация "Ключ к пониманию бизнеса" - скачать презентации по Экономике Материально-техническое обеспечение
Материально-техническое обеспечение Информационное моделирование зданий (BIM)
Информационное моделирование зданий (BIM) История терроризма
История терроризма Развитие внимания в процессе коррекционной работы с детьми ОВЗ. Учитель-дефектолог
Развитие внимания в процессе коррекционной работы с детьми ОВЗ. Учитель-дефектолог  Человек – объект генетического анализа Известно, что основной для решения большинства генетических задач является гибридоло
Человек – объект генетического анализа Известно, что основной для решения большинства генетических задач является гибридоло Второй закон Кирхгофа
Второй закон Кирхгофа Разработка ЭИС поддержки торговой деятельности
Разработка ЭИС поддержки торговой деятельности World Hospice and Palliative Care Day in Russia Всемирный День хосписной и паллиативной помощи в России
World Hospice and Palliative Care Day in Russia Всемирный День хосписной и паллиативной помощи в России Одномерные массивы
Одномерные массивы Язык программирования
Язык программирования Украшение елок в разных странах
Украшение елок в разных странах Презентация Исторический портрет М.М. Сперанского
Презентация Исторический портрет М.М. Сперанского  Вже дзвінок нам дав сигнал. Вже дзвінок нам дав сигнал. І на урок він нас покликав, А, отже, часу не втрачаймо, Роботу швидше почина
Вже дзвінок нам дав сигнал. Вже дзвінок нам дав сигнал. І на урок він нас покликав, А, отже, часу не втрачаймо, Роботу швидше почина Холодная война. Военно-политические союзы в системе международных отношений. Формирование мировой социалистической системы
Холодная война. Военно-политические союзы в системе международных отношений. Формирование мировой социалистической системы Искусство Индии
Искусство Индии Требования, предъявляемые к статистической информационной базе
Требования, предъявляемые к статистической информационной базе Л 1 Раздел 1. Тема 1.1. Значение математики в профессиональной деятельности
Л 1 Раздел 1. Тема 1.1. Значение математики в профессиональной деятельности Презентация Философия. Монтескьё, Шарль-Луи де Секонда
Презентация Философия. Монтескьё, Шарль-Луи де Секонда Нечеткие множества
Нечеткие множества  Акробатика и воздушная гимнастика на полотнах
Акробатика и воздушная гимнастика на полотнах Стихи любимого поэта - презентация для начальной школы_
Стихи любимого поэта - презентация для начальной школы_ Тренажер по геометрии (итоговое повторение 7 класс)
Тренажер по геометрии (итоговое повторение 7 класс)  Шахматы 1класс. Игры. Ладья против слона. Часть 2
Шахматы 1класс. Игры. Ладья против слона. Часть 2 Потоки ввода-вывода
Потоки ввода-вывода Исследование McKinsey проанализированы показатели свыше 200 ведущих финансовых компаний за период с 1997 по 2002 г. в 90 из них было выяв
Исследование McKinsey проанализированы показатели свыше 200 ведущих финансовых компаний за период с 1997 по 2002 г. в 90 из них было выяв