Лексический анализ языков программирования. Лексемы. Регулярные языки и грамматики. Матрица переходов КА. (Глава 3)
- Лексический анализ языков программирования. Лексемы. Регулярные языки и грамматики. Матрица переходов КА. (Глава 3)

Содержание
- 2. 3.1 Назначение и необходимость фазы лексического анализа Лексический анализ – первая фаза процесса трансляции, предназначенная для
- 3. 3.1 Назначение и необходимость фазы лексического анализа Задачи, решаемые сканером (преимущества сканера): представление элементарных конструкций языка
- 4. 3.2 Транслитератор Устройство, осуществляющее сопоставление класс с каждым отдельным символом, называется транслитератором. Наиболее типичными классами символов
- 5. 3.3 Регулярные языки и грамматики Пример. Классы лексем: идентификаторы; служебные слова (множество идентификаторов); целые числа, вещественные,
- 6. 3.3 Регулярные языки и грамматики Автоматные грамматики A -> Bt | t, где A, B ∈
- 7. 3.3 Регулярные языки и грамматики Доказано, что класс регулярной и автоматной грамматики почти эквиваленты. Любую регулярную
- 8. 3.4 КОНЕЧНЫЕ АВТОМАТЫ ГЛАВА 3. Лексический анализ
- 9. 3.4.1 Определение КА Конечный автомат (КА) – это пятерка (Q, V, δ, q0, F), где: Q
- 10. 3.4.1 Определение КА Конечный автомат называется полностью определенным, если в каждом его состоянии определена функция перехода
- 11. 3.4.2 Диаграмма переходов (состояний) Граф переходов (дерево, диаграмма) – направленный помеченный граф с символами состояний конечного
- 12. 3.5 Матрица переходов КА Каждая строка этой матрицы представляет состояние автомата, а каждый столбец соответствует возможному
- 13. 3.5 Матрица переходов КА ::= | фиксированной точкой > ::= ::= | | ::= . ::=
- 14. 3.5 Матрица переходов КА Матрица переходов состояний для распознавания десятичных чисел с фиксированной точкой
- 15. 3.5 Матрица переходов КА innum – значение следующей введенной цифры; insign – значение знака во входной
- 16. 3.5 Матрица переходов КА
- 17. 3.6 Детерминированный и недерминированный автомат Конечный автомат (Q, V, δ, q0, F) называется детерминированным конечным автоматом
- 18. 3.7 Лексический анализатор Лексический анализатор – программа, которая используя набор сканеров, преобразует исходный текст программы во
- 19. 3.7 Лексический анализатор ::= PROGRAM VAR BEGIN END. ::= id ::= ; | ; ::= :
- 20. 3.7 Лексический анализатор PROGRAM STATS VAR SUM, SUMSQ, I, VALUE, MEAN, VARIANCE: INTEGER; BEGIN SUM :=
- 21. 3.7 Лексический анализатор Таблица служебных слов TW 1 Таблица разделителей TD 2
- 22. 3.7 Лексический анализатор Таблица литералов (констант) TNUM 3 Таблица идентификаторов TID 4
- 23. 3.7 Лексический анализатор Переменные: buf – буфер для накопления символов лексем; с – очередной входной символ;
- 24. 3.7 Лексический анализатор Функции: void clear (void) – очистить буффер buf, void add (void) – добавление
- 25. 3.7 Лексический анализатор
- 26. 3.7 Лексический анализатор КА пользуясь набором сканера формирует набор лексем. PROGRAM STATS VAR SUM ... :
- 27. 3.7 Лексический анализатор F0={ gc() } F1={ clear(); add(); gc()} F3={ add(); gc() } F4={ j==look(TW)
- 28. 3.7 Лексический анализатор
- 29. 3.8 Связь регулярных грамматик КА На основании имеющейся регулярной грамматики можно построить эквивалентный ей КА, и
- 30. 3.8.1 Построение КА на основе леволинейной грамматики Необходимо построить КА M(Q, V, δ, q0, F), по
- 31. 3.8.1 Построение КА на основе леволинейной грамматики 3) Просматриваем все множество правил грамматики G. Если встречается
- 32. 3.8.1 Построение КА на основе леволинейной грамматики Построить автомат M(Q, V, δ, q0, F) на основе
- 33. 3.8.1 Построение КА на основе леволинейной грамматики Шаг 1. V = {0, 1} Шаг 2. Q
- 34. 3.8.1 Построение КА на основе леволинейной грамматики
- 35. 3.8.2 Построение леволинейной грамматики на основе КА 1) Множество терминальных символов строится на основании входных символов
- 36. 3.8.2 Построение леволинейной грамматики на основе КА 3) Просматриваем функции переходов автомата M для всех возможных
- 37. 3.8.2 Построение леволинейной грамматики на основе КА
- 39. Скачать презентацию

3.1 Назначение и необходимость фазы лексического анализа
Лексический анализ – первая фаза
3.1 Назначение и необходимость фазы лексического анализа
Лексический анализ – первая фаза

3.1 Назначение и необходимость фазы лексического анализа
Задачи, решаемые сканером (преимущества сканера):
представление
3.1 Назначение и необходимость фазы лексического анализа
Задачи, решаемые сканером (преимущества сканера):
представление

3.2 Транслитератор
Устройство, осуществляющее сопоставление класс с каждым отдельным символом, называется транслитератором.
3.2 Транслитератор
Устройство, осуществляющее сопоставление класс с каждым отдельным символом, называется транслитератором.

3.3 Регулярные языки и грамматики
Пример. Классы лексем:
идентификаторы;
служебные слова (множество идентификаторов);
целые
3.3 Регулярные языки и грамматики
Пример. Классы лексем:
идентификаторы;
служебные слова (множество идентификаторов);
целые

3.3 Регулярные языки и грамматики
Автоматные грамматики
A -> Bt | t, где
3.3 Регулярные языки и грамматики
Автоматные грамматики
A -> Bt | t, где

3.3 Регулярные языки и грамматики
Доказано, что класс регулярной и автоматной грамматики
3.3 Регулярные языки и грамматики
Доказано, что класс регулярной и автоматной грамматики

3.4 КОНЕЧНЫЕ АВТОМАТЫ
ГЛАВА 3. Лексический анализ
3.4 КОНЕЧНЫЕ АВТОМАТЫ
ГЛАВА 3. Лексический анализ

3.4.1 Определение КА
Конечный автомат (КА) – это пятерка (Q, V, δ,
3.4.1 Определение КА
Конечный автомат (КА) – это пятерка (Q, V, δ,

3.4.1 Определение КА
Конечный автомат называется полностью определенным, если в каждом его
3.4.1 Определение КА
Конечный автомат называется полностью определенным, если в каждом его
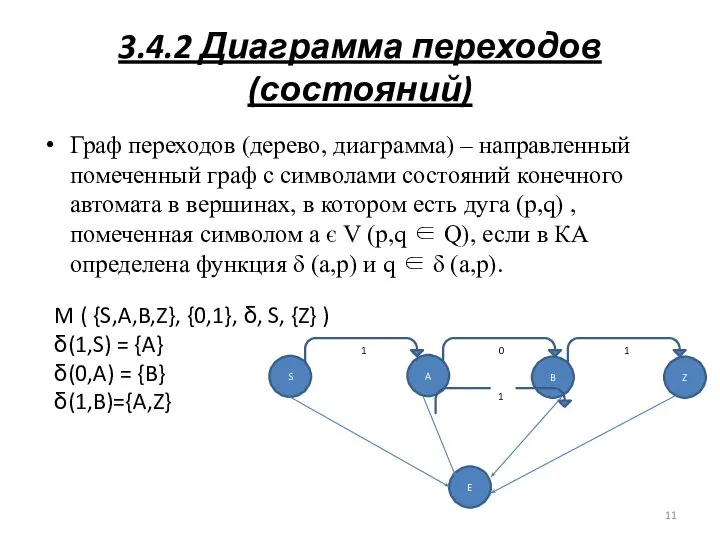
3.4.2 Диаграмма переходов (состояний)
Граф переходов (дерево, диаграмма) – направленный помеченный граф
3.4.2 Диаграмма переходов (состояний)
Граф переходов (дерево, диаграмма) – направленный помеченный граф

3.5 Матрица переходов КА
Каждая строка этой матрицы представляет состояние автомата, а
3.5 Матрица переходов КА
Каждая строка этой матрицы представляет состояние автомата, а
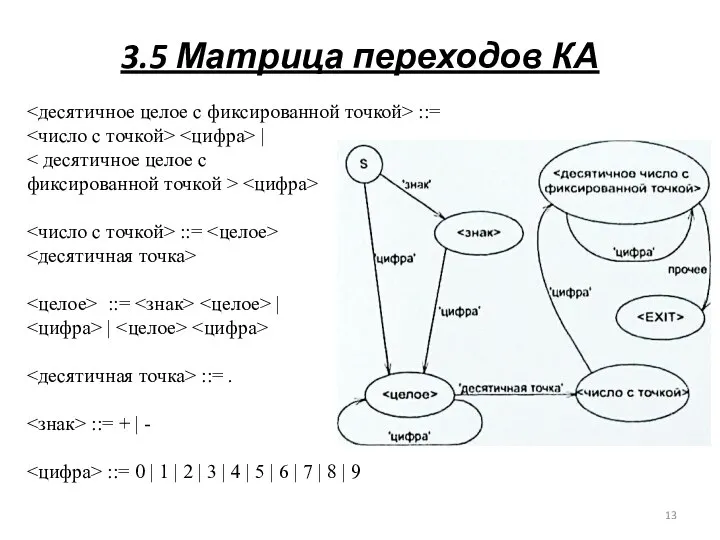
3.5 Матрица переходов КА
<десятичное целое с фиксированной точкой> ::=
<число с
3.5 Матрица переходов КА
<десятичное целое с фиксированной точкой> ::=
<число с
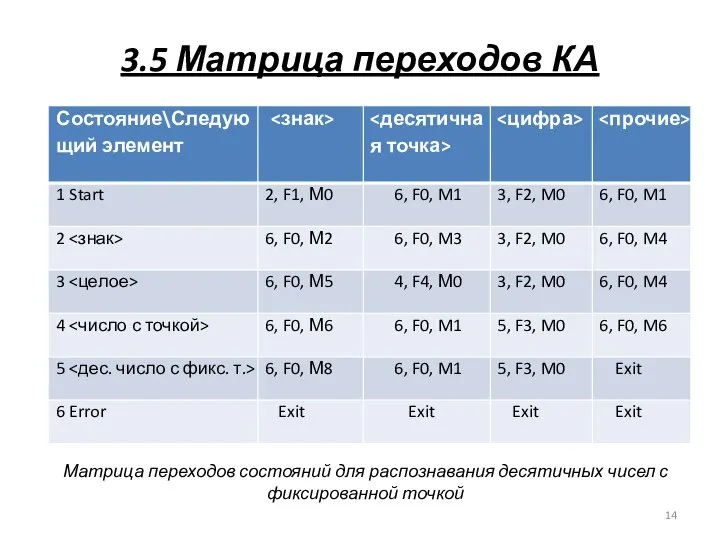
3.5 Матрица переходов КА
Матрица переходов состояний для распознавания десятичных чисел с
3.5 Матрица переходов КА
Матрица переходов состояний для распознавания десятичных чисел с

3.5 Матрица переходов КА
innum – значение следующей введенной цифры;
insign – значение
3.5 Матрица переходов КА
innum – значение следующей введенной цифры;
insign – значение
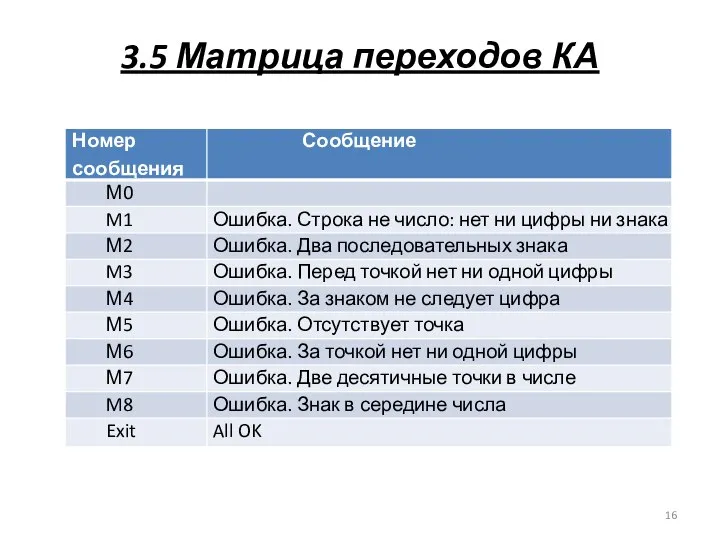
3.5 Матрица переходов КА
3.5 Матрица переходов КА

3.6 Детерминированный и недерминированный автомат
Конечный автомат (Q, V, δ, q0, F)
3.6 Детерминированный и недерминированный автомат
Конечный автомат (Q, V, δ, q0, F)

3.7 Лексический анализатор
Лексический анализатор – программа, которая используя набор сканеров, преобразует
3.7 Лексический анализатор
Лексический анализатор – программа, которая используя набор сканеров, преобразует

3.7 Лексический анализатор
<рrоg> ::= PROGRAM VAR BEGIN
3.7 Лексический анализатор
<рrоg> ::= PROGRAM

3.7 Лексический анализатор
PROGRAM STATS
VAR
SUM, SUMSQ, I, VALUE, MEAN, VARIANCE: INTEGER;
BEGIN
SUM :=
3.7 Лексический анализатор
PROGRAM STATS
VAR
SUM, SUMSQ, I, VALUE, MEAN, VARIANCE: INTEGER;
BEGIN
SUM :=
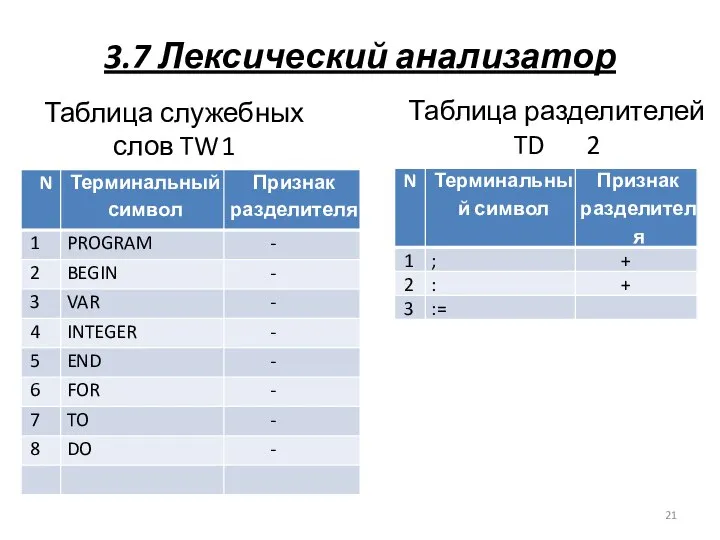
3.7 Лексический анализатор
Таблица служебных слов TW 1
Таблица разделителей
TD 2
3.7 Лексический анализатор
Таблица служебных слов TW 1
Таблица разделителей
TD 2
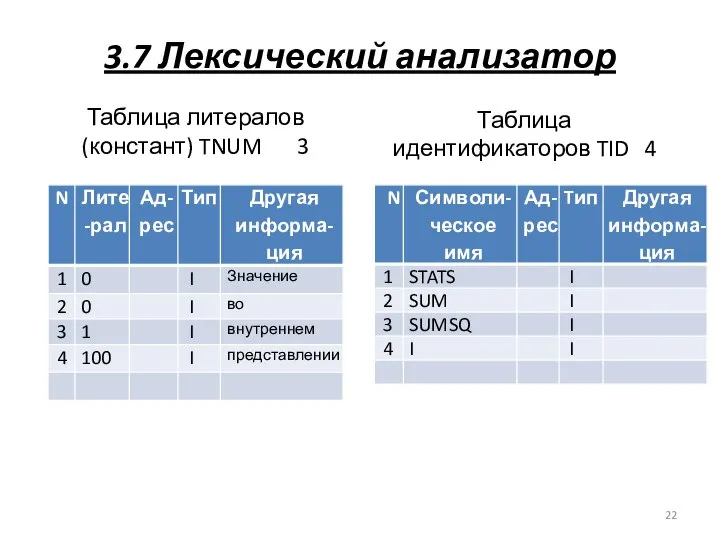
3.7 Лексический анализатор
Таблица литералов (констант) TNUM 3
Таблица идентификаторов TID 4
3.7 Лексический анализатор
Таблица литералов (констант) TNUM 3
Таблица идентификаторов TID 4

3.7 Лексический анализатор
Переменные:
buf – буфер для накопления символов лексем;
с –
3.7 Лексический анализатор
Переменные:
buf – буфер для накопления символов лексем;
с –

3.7 Лексический анализатор
Функции:
void clear (void) – очистить буффер buf,
void add (void)
3.7 Лексический анализатор
Функции:
void clear (void) – очистить буффер buf,
void add (void)
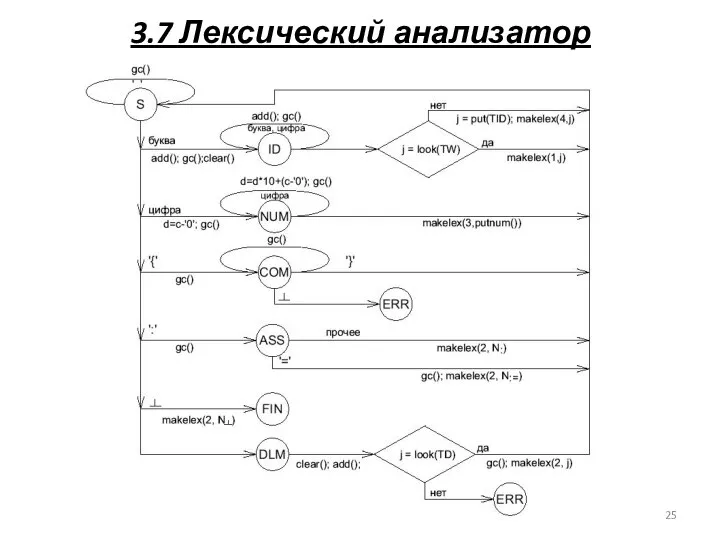
3.7 Лексический анализатор
3.7 Лексический анализатор

3.7 Лексический анализатор
КА пользуясь набором сканера формирует набор лексем.
<1,1> <4,1> <1,3>
3.7 Лексический анализатор
КА пользуясь набором сканера формирует набор лексем.
<1,1> <4,1> <1,3>

3.7 Лексический анализатор
F0={ gc() }
F1={ clear(); add(); gc()}
F3={ add(); gc() }
F4={
3.7 Лексический анализатор
F0={ gc() }
F1={ clear(); add(); gc()}
F3={ add(); gc() }
F4={
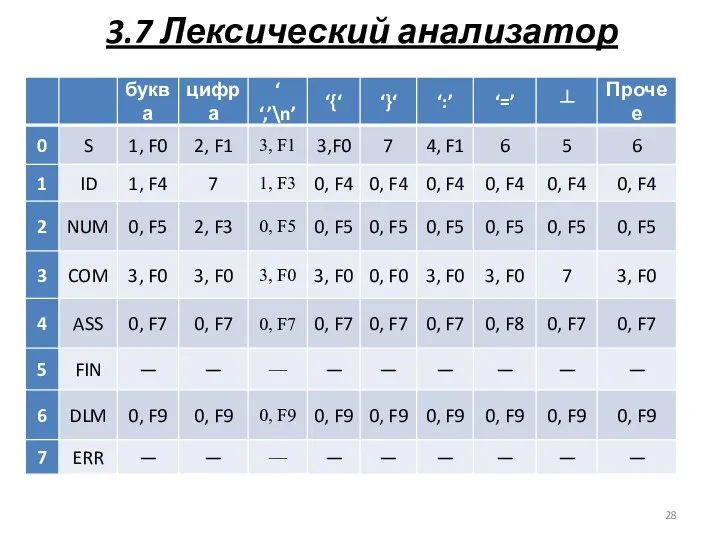
3.7 Лексический анализатор
3.7 Лексический анализатор

3.8 Связь регулярных грамматик КА
На основании имеющейся регулярной грамматики можно построить
3.8 Связь регулярных грамматик КА
На основании имеющейся регулярной грамматики можно построить

3.8.1 Построение КА на основе леволинейной грамматики
Необходимо построить КА M(Q, V,
3.8.1 Построение КА на основе леволинейной грамматики
Необходимо построить КА M(Q, V,

3.8.1 Построение КА на основе леволинейной грамматики
3) Просматриваем все множество правил
3.8.1 Построение КА на основе леволинейной грамматики
3) Просматриваем все множество правил

3.8.1 Построение КА на основе леволинейной грамматики
Построить автомат M(Q, V, δ,
3.8.1 Построение КА на основе леволинейной грамматики
Построить автомат M(Q, V, δ,
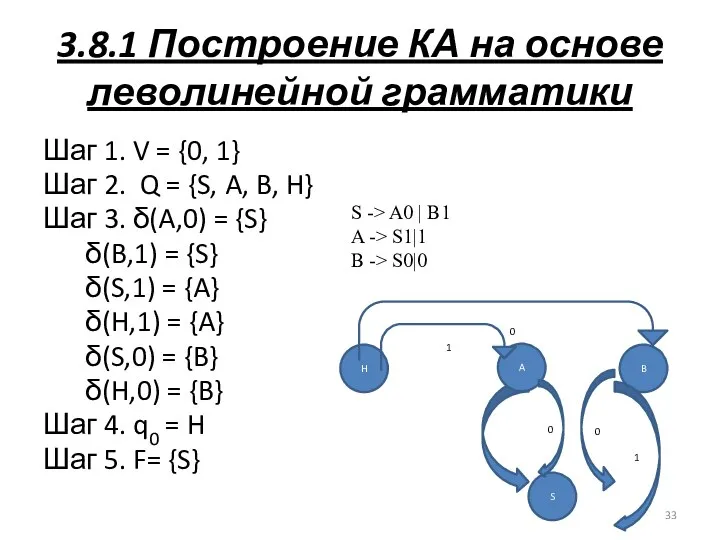
3.8.1 Построение КА на основе леволинейной грамматики
Шаг 1. V = {0,
3.8.1 Построение КА на основе леволинейной грамматики
Шаг 1. V = {0,

3.8.1 Построение КА на основе леволинейной грамматики
3.8.1 Построение КА на основе леволинейной грамматики

3.8.2 Построение леволинейной грамматики на основе КА
1) Множество терминальных символов строится
3.8.2 Построение леволинейной грамматики на основе КА
1) Множество терминальных символов строится

3.8.2 Построение леволинейной грамматики на основе КА
3) Просматриваем функции переходов автомата
3.8.2 Построение леволинейной грамматики на основе КА
3) Просматриваем функции переходов автомата
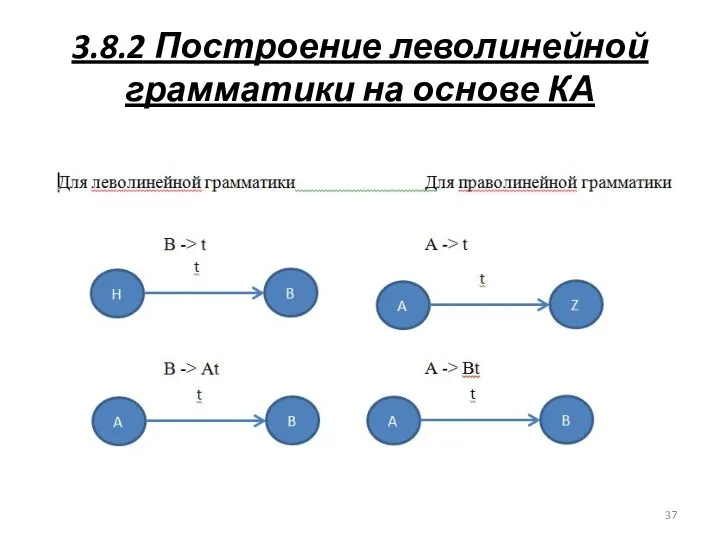
3.8.2 Построение леволинейной грамматики на основе КА
3.8.2 Построение леволинейной грамматики на основе КА
 Государственный образовательный стандарт начального общего образования Донецкой Народной Республики
Государственный образовательный стандарт начального общего образования Донецкой Народной Республики Статика твердого тела
Статика твердого тела Сервер устройства анализатора сигналов Rhode&Schwarz FSV-7 в стандарте TANGO
Сервер устройства анализатора сигналов Rhode&Schwarz FSV-7 в стандарте TANGO Презентация Процесс управления в системе таможенных органов
Презентация Процесс управления в системе таможенных органов Рынок труда и заработной платы
Рынок труда и заработной платы Арт-терапия в начальной школе Самая большая ценность в мире - Человек и жизнь: чужая, своя, …жизнь на всём её протяжении.
Арт-терапия в начальной школе Самая большая ценность в мире - Человек и жизнь: чужая, своя, …жизнь на всём её протяжении. Презентация Кроссворд по логике
Презентация Кроссворд по логике Формулы приветствия, прощания
Формулы приветствия, прощания Осмотр хода строительства «Зарядья» и высадка деревьев
Осмотр хода строительства «Зарядья» и высадка деревьев Соболев Курохтин Щелыково
Соболев Курохтин Щелыково Возрастная периодизация развития школьников и её учет в обучении и воспитании
Возрастная периодизация развития школьников и её учет в обучении и воспитании  Натуральные числа и шкалы.
Натуральные числа и шкалы.  Резьбовые соединения. Контроль крепежа
Резьбовые соединения. Контроль крепежа Строительный инжиниринг. Введение
Строительный инжиниринг. Введение Международное регулирование иностранных инвестиций
Международное регулирование иностранных инвестиций Многоэтажные здания
Многоэтажные здания Мир бабочек - презентация для начальной школы_
Мир бабочек - презентация для начальной школы_ Презентация+Профобучение
Презентация+Профобучение Программирование на языке Паскаль
Программирование на языке Паскаль Среда программирования С++
Среда программирования С++ Космическая симфония. Юрий Алексеевич Гагарин
Космическая симфония. Юрий Алексеевич Гагарин Игра по окружающему миру «Познай себя» Составитель Мальцева Жанна Геннадьевна, учитель начальных классов МБОУ «Сивинская средн
Игра по окружающему миру «Познай себя» Составитель Мальцева Жанна Геннадьевна, учитель начальных классов МБОУ «Сивинская средн Финансовые основы социальной работы
Финансовые основы социальной работы  Предмет макроэкономики и макроэкономический анализ
Предмет макроэкономики и макроэкономический анализ ОРГАНИЗАЦИЯ ЭКСПЛУАТАЦИИ АВТОМОБИЛЬНОЙ ТЕХНИКИ
ОРГАНИЗАЦИЯ ЭКСПЛУАТАЦИИ АВТОМОБИЛЬНОЙ ТЕХНИКИ Анализ материальных ресурсов
Анализ материальных ресурсов Заключение, изменение и расторжение договора
Заключение, изменение и расторжение договора Partie w systemie komunistycznym
Partie w systemie komunistycznym