- Потоки ввода вывода

Содержание
- 2. Основные принципы потоковых классов ввода-вывода остались неизменными, но были добавлены некоторые важные новшества, расширяющие возможности настройки
- 3. В С++ операции ввода-вывода выполняются при помощи потоков данных. Согласно принципам объектно-ориентированного программирования, поток данных предcтaвляeт
- 4. Одним из аргументов в пользу потоков является простота использования: нет необходимости задумываться о форматировании – каждый
- 5. В библиотеке IOStream определено несколько глобальных объектов типов istream и ostream. Эти объекты соответствуют стандартным каналам
- 6. Операторы сдвига >> и int а, b: // Пока операции ввода а и b проходят успешно
- 7. В конце большинства команд потокового ввода-вывода записывается так называемый манипулятор: std::cout Манипуляторы - специальные объекты, предназначенные
- 8. В классах потокового ввода-вывода istream и ostream определен (кроме рассмотренного endl) следующий набор манипуляторов: Манипуляторы -
- 9. Программа читает два вещественных числа и выводит их произведение. Простой пример int f() { double х,
- 10. Для шаблонных классов в верхней строке указано имя шаблона, а в нижней - имена специализаций для
- 11. Базовый класс ios_base определяет свойства всех потоковых классов, не зависящие от типа и трактовок символов. Класс
- 12. Шаблоны basic_istream и basic_ostream , виртуально производные от basic_ios , определяют объекты, которые могут использоваться соответственно
- 13. Назначение потоковых буферных классов Библиотека IOStream предполагает строгое разделение обязанностей. Классы, производные от basic_ios, ограничиваются форматированием
- 14. Заголовочные файлы Определения потоковых классов распределены по нескольким заголовочным файлам. . Содержит опережающие объявления потоковых классов.
- 15. Заголовочные файлы -2 Заголовок следует включать только при использовании стандартных потоковых объектов. В некоторых реализациях в
- 16. Состояние потока данных - константы Общее состояние потока данных определяется несколькими флагами, представленными константами типа iostate.
- 17. Состояние потока данных – константы 2 Основное отличие флагов failbit и badbit состоит в том, что
- 18. Функции для работы с состоянием потока данных Основное отличие флагов failbit и badbit состоит в том,
- 19. Пример работы с функциями Как установить и сбросить флаг failbit: // Проверка установки флага failbit if
- 20. Класс istream Класс istream предназначен для извлечения данных из потока ввода. К этому классу относится объект
- 21. Класс istream - функции ввода символа int istream::get () 1) Читает следующий символ. 2) Возвращает прочитанный
- 22. Класс istream - функции get istream& istream::get (char* str, streamsize count) istream& istream::get (char* str, streamsize
- 23. Класс istream - функции getline и read istream& istream::getline (char* str, streamsize count) istream& istream::getline (char*
- 24. Класс istream - функции readsome и gcount streamsize istream::readsome (char* str, streamsize count) Читает до count
- 25. Класс istream - функции ignore istream& istream::ignore () istream& istream::ignore (streamsize count) istream& istream::ignore (streamsize count,
- 26. Класс istream - функции unget, putback и peek istream& istream::unget () istream& istream::putback (char с) Обе
- 27. Класс istream - функции - резюме При чтении С-строк описанные здесь функции безопаснее оператора >>, поскольку
- 28. Класс ostream – функции ostream& ostream::put (char с) Записывает аргумент c в поток данных. Возвращает объект
- 29. Пример Классический фильтр - вывод в выходной поток все прочитанные символы : #include using namespace std;
- 30. Тесты … Вопрос: Что будет выведено на экран? #include class A { int count; public: A()
- 31. Тесты … Вопрос: Что будет выведено на экран? #include class A { int count; public: A()
- 32. Тесты … Что будет выведено на консоль в результате выполнения программы? #include struct A { char
- 33. Тесты … Что будет выведено на консоль в результате выполнения программы? #include struct A { char
- 34. Тесты … Вопрос: В каких строках (укажите номера) допущены ошибки: class cl { static int x;
- 36. Скачать презентацию

Основные принципы потоковых классов ввода-вывода остались неизменными, но были добавлены некоторые
Основные принципы потоковых классов ввода-вывода остались неизменными, но были добавлены некоторые

В С++ операции ввода-вывода выполняются при помощи потоков данных.
Согласно принципам объектно-ориентированного
В С++ операции ввода-вывода выполняются при помощи потоков данных.
Согласно принципам объектно-ориентированного

Одним из аргументов в пользу потоков является простота использования: нет необходимости
Одним из аргументов в пользу потоков является простота использования: нет необходимости

В библиотеке IOStream определено несколько глобальных объектов типов istream и ostream.
В библиотеке IOStream определено несколько глобальных объектов типов istream и ostream.

Операторы сдвига >> и << были перегружены для потоковых классов и
Операторы сдвига >> и << были перегружены для потоковых классов и

В конце большинства команд потокового ввода-вывода записывается так называемый манипулятор:
std::cout <<
В конце большинства команд потокового ввода-вывода записывается так называемый манипулятор:
std::cout <<
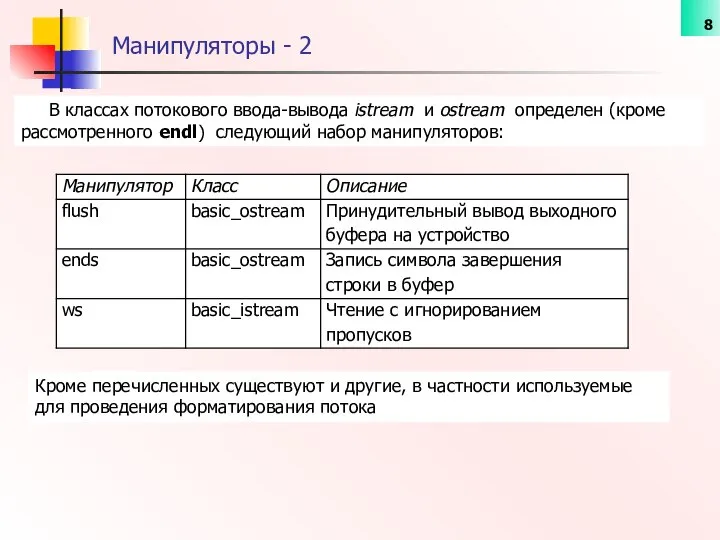
В классах потокового ввода-вывода istream и ostream определен (кроме рассмотренного endl)
В классах потокового ввода-вывода istream и ostream определен (кроме рассмотренного endl)

Программа читает два вещественных числа и выводит их произведение.
Простой пример
int f()
{
Программа читает два вещественных числа и выводит их произведение.
Простой пример
int f()
{
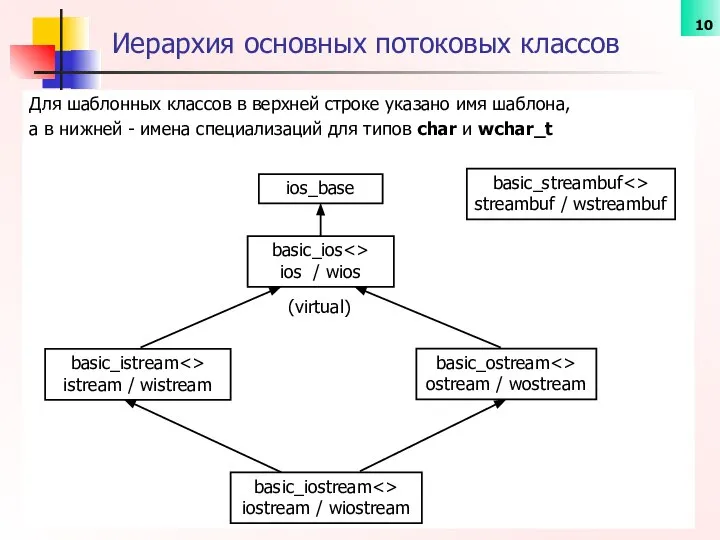
Для шаблонных классов в верхней строке указано имя шаблона,
а в нижней
Для шаблонных классов в верхней строке указано имя шаблона,
а в нижней

Базовый класс ios_base определяет свойства всех потоковых классов, не зависящие от
Базовый класс ios_base определяет свойства всех потоковых классов, не зависящие от

Шаблоны basic_istream<> и basic_ostream<>, виртуально производные от basic_ios< >, определяют объекты,
Шаблоны basic_istream<> и basic_ostream<>, виртуально производные от basic_ios< >, определяют объекты,

Назначение потоковых буферных классов
Библиотека IOStream предполагает строгое разделение обязанностей.
Классы, производные от
Назначение потоковых буферных классов
Библиотека IOStream предполагает строгое разделение обязанностей.
Классы, производные от

Заголовочные файлы
Определения потоковых классов распределены по нескольким заголовочным файлам.
. Содержит опережающие
Заголовочные файлы
Определения потоковых классов распределены по нескольким заголовочным файлам.

Заголовочные файлы -2
Заголовок следует включать только при использовании стандартных потоковых
Заголовочные файлы -2
Заголовок
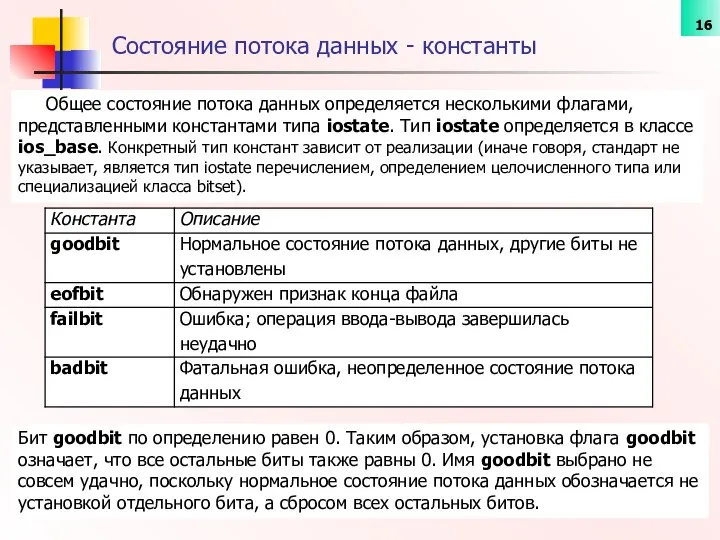
Состояние потока данных - константы
Общее состояние потока данных определяется несколькими флагами,
Состояние потока данных - константы
Общее состояние потока данных определяется несколькими флагами,

Состояние потока данных – константы 2
Основное отличие флагов failbit и badbit
Состояние потока данных – константы 2
Основное отличие флагов failbit и badbit
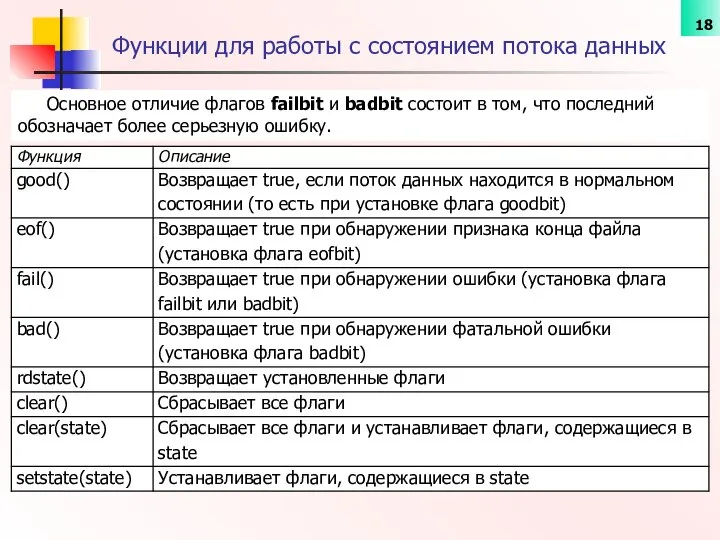
Функции для работы с состоянием потока данных
Основное отличие флагов failbit и
Функции для работы с состоянием потока данных
Основное отличие флагов failbit и

Пример работы с функциями
Как установить и сбросить флаг failbit:
// Проверка
Пример работы с функциями
Как установить и сбросить флаг failbit:
// Проверка
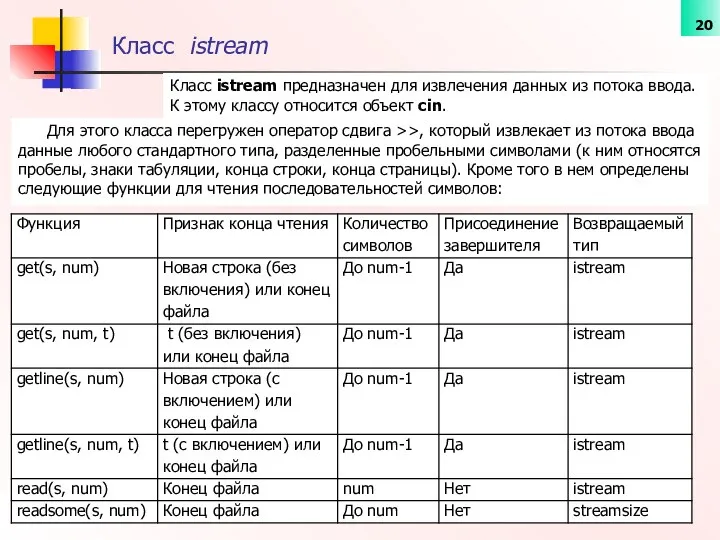
Класс istream
Класс istream предназначен для извлечения данных из потока ввода.
Класс istream
Класс istream предназначен для извлечения данных из потока ввода.

Класс istream - функции ввода символа
int istream::get ()
1) Читает
Класс istream - функции ввода символа
int istream::get ()
1) Читает

Класс istream - функции get
istream& istream::get (char* str, streamsize count)
istream& istream::get
Класс istream - функции get
istream& istream::get (char* str, streamsize count)
istream& istream::get

Класс istream - функции getline и read
istream& istream::getline (char* str, streamsize
Класс istream - функции getline и read
istream& istream::getline (char* str, streamsize

Класс istream - функции readsome и gcount
streamsize istream::readsome (char* str, streamsize
Класс istream - функции readsome и gcount
streamsize istream::readsome (char* str, streamsize

Класс istream - функции ignore
istream& istream::ignore ()
istream& istream::ignore (streamsize count)
istream& istream::ignore
Класс istream - функции ignore
istream& istream::ignore ()
istream& istream::ignore (streamsize count)
istream& istream::ignore

Класс istream - функции unget, putback и peek
istream& istream::unget ()
istream& istream::putback
Класс istream - функции unget, putback и peek
istream& istream::unget ()
istream& istream::putback

Класс istream - функции - резюме
При чтении С-строк описанные здесь функции
Класс istream - функции - резюме
При чтении С-строк описанные здесь функции

Класс ostream – функции
ostream& ostream::put (char с)
Записывает аргумент c в
Класс ostream – функции
ostream& ostream::put (char с)
Записывает аргумент c в

Пример
Классический фильтр - вывод в выходной поток все прочитанные символы :
#include
Пример
Классический фильтр - вывод в выходной поток все прочитанные символы :
#include

Тесты …
Вопрос: Что будет выведено на экран?
#include
class A {
Тесты …
Вопрос: Что будет выведено на экран?
#include
class A {

Тесты …
Вопрос: Что будет выведено на экран?
#include
class A {
Тесты …
Вопрос: Что будет выведено на экран?
#include
class A {

Тесты …
Что будет выведено на консоль в результате выполнения программы?
#include
Тесты …
Что будет выведено на консоль в результате выполнения программы?
#include

Тесты …
Что будет выведено на консоль в результате выполнения программы?
#include
Тесты …
Что будет выведено на консоль в результате выполнения программы?
#include

Тесты …
Вопрос: В каких строках (укажите номера) допущены ошибки:
class cl
{
Тесты …
Вопрос: В каких строках (укажите номера) допущены ошибки:
class cl
{
 Сущность инноваций в образовании
Сущность инноваций в образовании  Геополитические проблемы России на Кавказе
Геополитические проблемы России на Кавказе ТЕПЛОВОЕ ИЗЛУЧЕНИЕ. Основные экспериментальные закономерности
ТЕПЛОВОЕ ИЗЛУЧЕНИЕ. Основные экспериментальные закономерности Истинная красота
Истинная красота Формы культуры
Формы культуры Книги? Фильмы? Может лучше видеоигры? Фильмы по играм
Книги? Фильмы? Может лучше видеоигры? Фильмы по играм Резьбы
Резьбы Классификация религий
Классификация религий Питание современных подростков Здоровье до того перевешивает все остальные блага жизни, что поистине здоровый нищий счастли
Питание современных подростков Здоровье до того перевешивает все остальные блага жизни, что поистине здоровый нищий счастли Государственная (итоговая) аттестация выпускников IX классов в новой форме
Государственная (итоговая) аттестация выпускников IX классов в новой форме Оборудование для диагностирования рулевого управления
Оборудование для диагностирования рулевого управления Культура межличностных отношений
Культура межличностных отношений Здоровьесбережение детей второй младшей группы
Здоровьесбережение детей второй младшей группы Сборка и оптимизация размещения монтажного оборудования
Сборка и оптимизация размещения монтажного оборудования P/BV =полной стоимости компании (капитализации) /балансовой стоимости активов
P/BV =полной стоимости компании (капитализации) /балансовой стоимости активов Прикладное программное обеспечение
Прикладное программное обеспечение Презентация Ценообразующие факторы российского рубля
Презентация Ценообразующие факторы российского рубля  Буддизм
Буддизм Поздняя бронза
Поздняя бронза Instagram vs reality
Instagram vs reality Министерство образования и науки Российской Федерации
Министерство образования и науки Российской Федерации Основные правила игры в волейбол
Основные правила игры в волейбол Трелевочная машина КАТ525 (скидер)
Трелевочная машина КАТ525 (скидер) Международная защита прав человека
Международная защита прав человека Обеспечение безопасности детей в информационном пространстве
Обеспечение безопасности детей в информационном пространстве Революции и государственные перевороты в современном мире. Регионы нестабильности. Новые независимые государства
Революции и государственные перевороты в современном мире. Регионы нестабильности. Новые независимые государства Векторная алгебра.Линейные операции над векторами
Векторная алгебра.Линейные операции над векторами Informatika2.ppt
Informatika2.ppt