- Разработка параллельных программ для GPU. Введение в CUDA

Содержание
- 2. АППАРАТНЫЕ ОСОБЕННОСТИ GPU Краткий обзор архитектурных особенностей GPU
- 3. Основные тенденции Переход к многопроцессорным системам Развития технологий параллельного программирования OpenMP, MPI, TPL etc. Простота в
- 4. Классификация архитектур Виды параллелизма На уровне данных (Data) На уровне задач (Instruction) *GPU: SIMT – Single
- 5. Архитектура многоядерных CPU Кэш первого уровня для инструкций (L1-I) для данных (L1-D) Кэш второго уровня на
- 6. Архитектура GPU: Device
- 7. Архитектура GPU: TPC Кластер текстурных блоков (TPC) Память для текстур Потоковый мультипроцессор
- 8. Архитектура GPU: SM Память констант Память инструкций Регистровая память Разделяемая память 8 скалярных процессоров 2 суперфункциональных
- 9. Основные отличия GPU от CPU Высокая степень параллелизма (SIMT) Минимальные затраты на кэш-память Ограничения функциональности
- 10. РАЗВИТИЕ ВЫЧИСЛЕНИЙ НА GPU Развитие технологии неграфических вычислений
- 11. Эволюция GPU
- 12. GPGPU General-Purpose Computation on GPU Вычисления на GPU общего (неграфического) назначения AMD FireStream NVIDIA CUDA DirectCompute
- 13. ПРОГРАММНАЯ МОДЕЛЬ CUDA Основные понятия и определения CUDA
- 14. CUDA – Compute Unified Device Architecture Host – CPU (Central Processing Unit) Device – GPU (Graphics
- 15. Организация работы CUDA GPU
- 16. Warp и латентность Warp Порция потоков для выполнения на потоковом мультипроцессоре (SM) Латентность Общая задержка всех
- 17. Топология блоков (block) Возможна 1, 2 и 3-мерная топология Количество потоков в блоке ограничено (512)
- 18. Топология сетки блоков (grid) Возможна 1 и 2-мерная топология Количество блоков в каждом измерении ограничено 65536=216
- 19. Адресация элементов данных CUDA предоставляет встроенные переменные, которые идентифицируют блоки и потоки blockIdx blockDim threadIdx 1D
- 20. Барьерная синхронизация Синхронизация потоков блока осуществляется встроенным оператором __synchronize
- 21. CUDA: РАСШИРЕНИЕ C++ Особенности написания программ для GPU CUDA
- 22. Расширение языка С++ Новые типы данных Спецификаторы для функций Спецификаторы для переменных Встроенные переменные (для ядра)
- 23. Процесс компиляции Файлы CUDA (GPU) *.cu Файлы CPU *.cpp, *.h Исполняемый модуль *.dll, *.exe nvcc VC90
- 24. Типы данных CUDA 1, 2, 3 и 4-мерные вектора базовых типов Целые: (u)char, (u)int, (u)short, (u)long,
- 25. Спецификаторы функций
- 26. Спецификаторы функций Ядро помечается __global__ Ядро не может возвращать значение Возможно совместное использование __host__ и __device__
- 27. Ограничения функций GPU Не поддерживается рекурсия Не поддерживаются static-переменные Нельзя брать адрес функции __device__ Не поддерживается
- 28. Спецификаторы переменных
- 29. Ограничения переменных GPU Переменные __shared__ не могут инициализироваться при объявлении Запись в __constant__ может производить только
- 30. Переменные ядра dim3 gridDim unit3 blockIdx dim3 blockDim uint3 threadIdx int warpSize
- 31. Директива запуска ядра Kernel >>(data) blocks – число блоков в сетке threads – число потоков в
- 32. Общая структура программы CUDA __global__ void Kernel(float* data) { . . . } void main() {
- 33. Предустановки Видеокарта NVIDIA с поддержкой CUDA Драйвера устройства с поддержкой CUDA NVIDIA CUDA Toolkit NVIDIA CUDA
- 34. Литература NVIDIA Developer Zone http://developer.nvidia.com/cuda NVIDAI CUDA – Неграфические вычисления на графических процессорах http://www.ixbt.com/video3/cuda-1.shtml Создание простого
- 36. Скачать презентацию

АППАРАТНЫЕ ОСОБЕННОСТИ GPU
Краткий обзор архитектурных особенностей GPU
АППАРАТНЫЕ ОСОБЕННОСТИ GPU
Краткий обзор архитектурных особенностей GPU

Основные тенденции
Переход к многопроцессорным системам
Развития технологий параллельного программирования
OpenMP, MPI, TPL etc.
Простота
Основные тенденции
Переход к многопроцессорным системам
Развития технологий параллельного программирования
OpenMP, MPI, TPL etc.
Простота

Классификация архитектур
Виды параллелизма
На уровне данных (Data)
На уровне задач (Instruction)
*GPU: SIMT –
Классификация архитектур
Виды параллелизма
На уровне данных (Data)
На уровне задач (Instruction)
*GPU: SIMT –
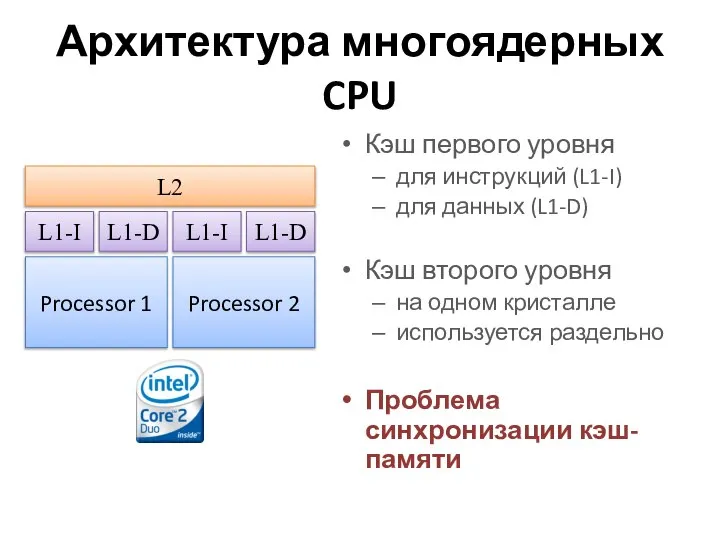
Архитектура многоядерных CPU
Кэш первого уровня
для инструкций (L1-I)
для данных (L1-D)
Кэш второго уровня
на
Архитектура многоядерных CPU
Кэш первого уровня
для инструкций (L1-I)
для данных (L1-D)
Кэш второго уровня
на
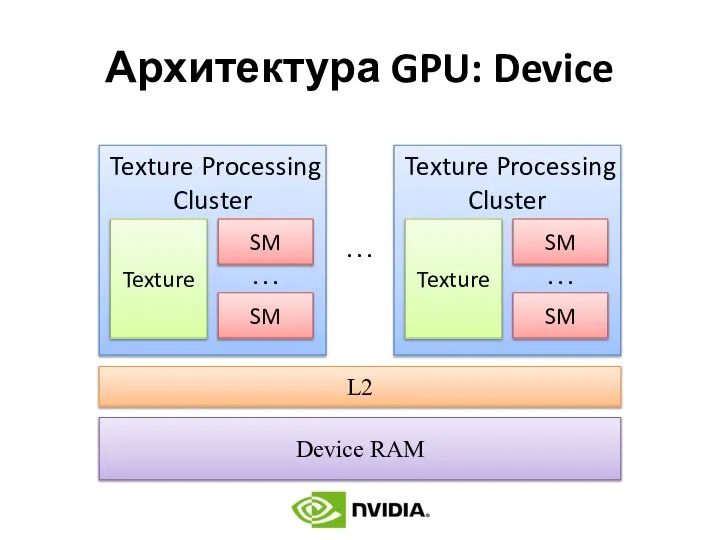
Архитектура GPU: Device
Архитектура GPU: Device
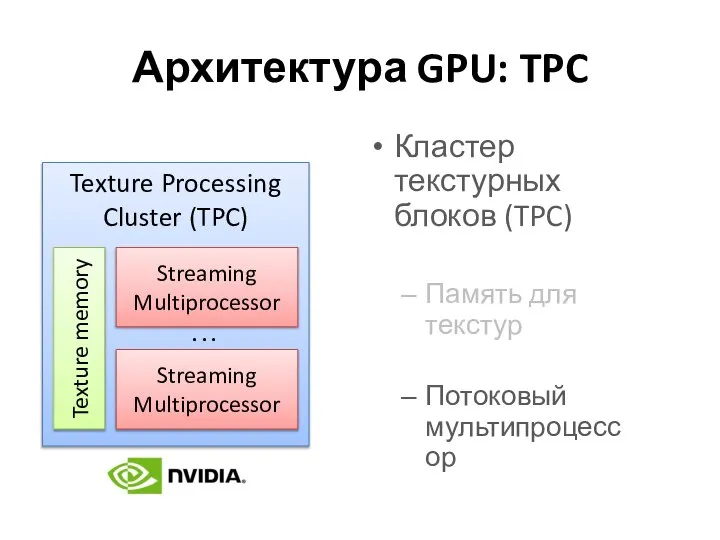
Архитектура GPU: TPC
Кластер текстурных блоков (TPC)
Память для текстур
Потоковый мультипроцессор
Архитектура GPU: TPC
Кластер текстурных блоков (TPC)
Память для текстур
Потоковый мультипроцессор
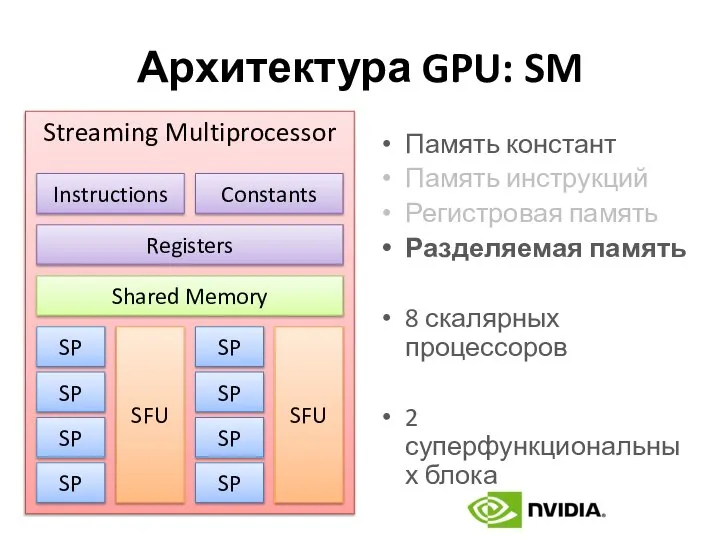
Архитектура GPU: SM
Память констант
Память инструкций
Регистровая память
Разделяемая память
8 скалярных процессоров
2 суперфункциональных блока
Архитектура GPU: SM
Память констант
Память инструкций
Регистровая память
Разделяемая память
8 скалярных процессоров
2 суперфункциональных блока

Основные отличия GPU от CPU
Высокая степень параллелизма (SIMT)
Минимальные затраты на кэш-память
Ограничения
Основные отличия GPU от CPU
Высокая степень параллелизма (SIMT)
Минимальные затраты на кэш-память
Ограничения

РАЗВИТИЕ ВЫЧИСЛЕНИЙ НА GPU
Развитие технологии неграфических вычислений
РАЗВИТИЕ ВЫЧИСЛЕНИЙ НА GPU
Развитие технологии неграфических вычислений
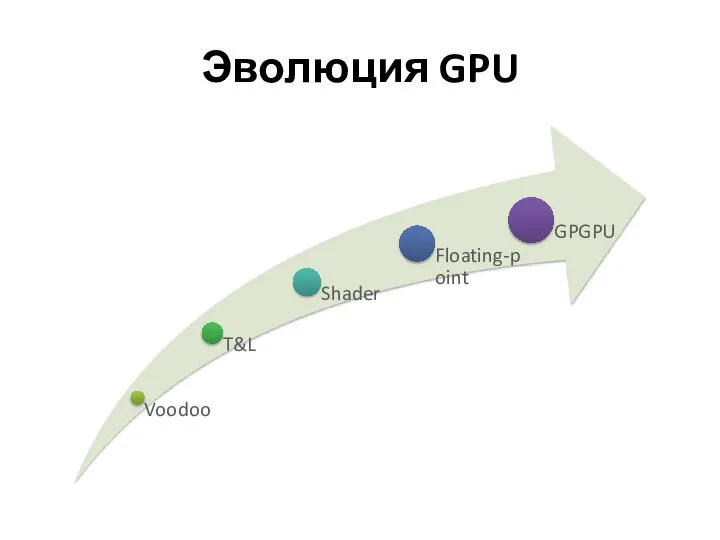
Эволюция GPU
Эволюция GPU

GPGPU
General-Purpose Computation on GPU
Вычисления на GPU общего (неграфического) назначения
AMD FireStream
NVIDIA CUDA
DirectCompute
GPGPU
General-Purpose Computation on GPU
Вычисления на GPU общего (неграфического) назначения
AMD FireStream
NVIDIA CUDA
DirectCompute

ПРОГРАММНАЯ МОДЕЛЬ CUDA
Основные понятия и определения CUDA
ПРОГРАММНАЯ МОДЕЛЬ CUDA
Основные понятия и определения CUDA

CUDA – Compute Unified Device Architecture
Host – CPU (Central Processing Unit)
Device
CUDA – Compute Unified Device Architecture
Host – CPU (Central Processing Unit)
Device
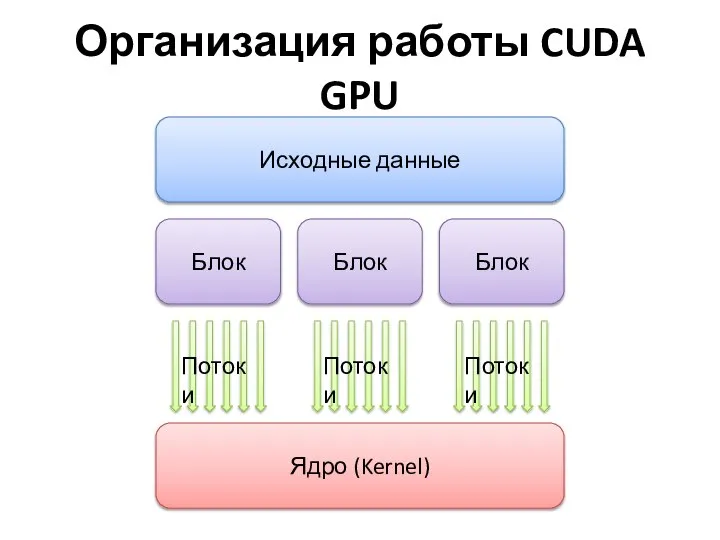
Организация работы CUDA GPU
Организация работы CUDA GPU

Warp и латентность
Warp
Порция потоков для выполнения на потоковом мультипроцессоре (SM)
Латентность
Общая задержка
Warp и латентность
Warp
Порция потоков для выполнения на потоковом мультипроцессоре (SM)
Латентность
Общая задержка
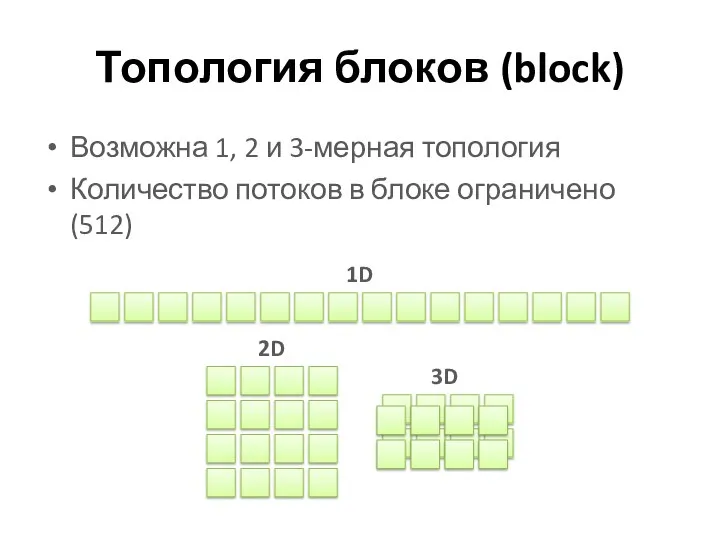
Топология блоков (block)
Возможна 1, 2 и 3-мерная топология
Количество потоков в блоке
Топология блоков (block)
Возможна 1, 2 и 3-мерная топология
Количество потоков в блоке
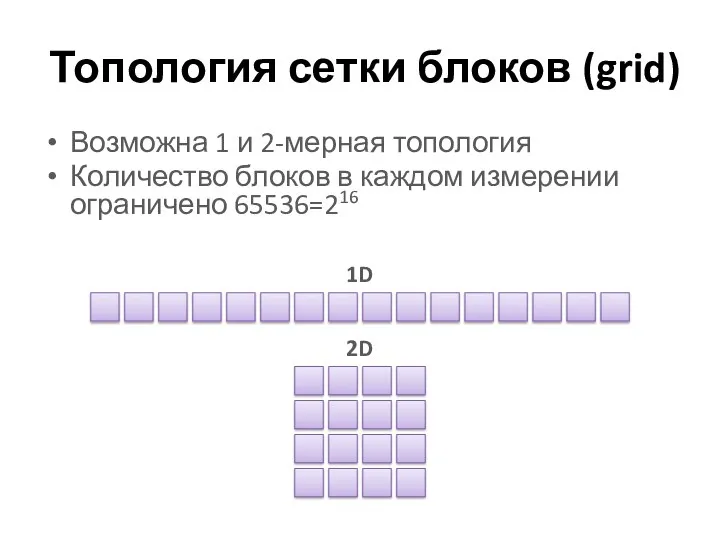
Топология сетки блоков (grid)
Возможна 1 и 2-мерная топология
Количество блоков в каждом
Топология сетки блоков (grid)
Возможна 1 и 2-мерная топология
Количество блоков в каждом

Адресация элементов данных
CUDA предоставляет встроенные переменные, которые идентифицируют блоки и потоки
blockIdx
blockDim
threadIdx
1D
Адресация элементов данных
CUDA предоставляет встроенные переменные, которые идентифицируют блоки и потоки
blockIdx
blockDim
threadIdx
1D
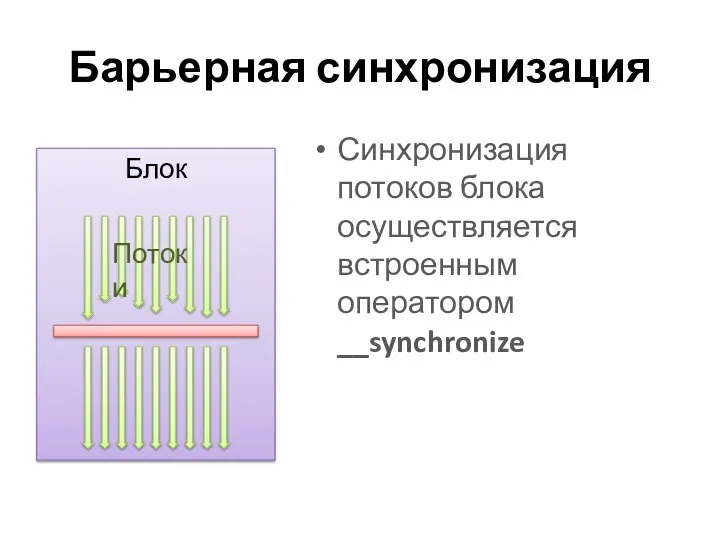
Барьерная синхронизация
Синхронизация потоков блока осуществляется встроенным оператором __synchronize
Барьерная синхронизация
Синхронизация потоков блока осуществляется встроенным оператором __synchronize

CUDA: РАСШИРЕНИЕ C++
Особенности написания программ для GPU CUDA
CUDA: РАСШИРЕНИЕ C++
Особенности написания программ для GPU CUDA

Расширение языка С++
Новые типы данных
Спецификаторы для функций
Спецификаторы для переменных
Встроенные переменные (для
Расширение языка С++
Новые типы данных
Спецификаторы для функций
Спецификаторы для переменных
Встроенные переменные (для
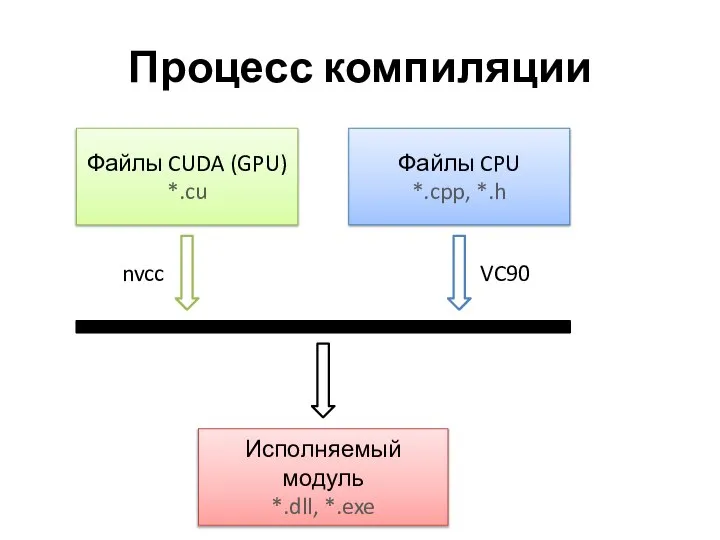
Процесс компиляции
Файлы CUDA (GPU)
*.cu
Файлы CPU
*.cpp, *.h
Исполняемый модуль
*.dll, *.exe
nvcc
VC90
Процесс компиляции
Файлы CUDA (GPU)
*.cu
Файлы CPU
*.cpp, *.h
Исполняемый модуль
*.dll, *.exe
nvcc
VC90

Типы данных CUDA
1, 2, 3 и 4-мерные вектора базовых типов
Целые: (u)char,
Типы данных CUDA
1, 2, 3 и 4-мерные вектора базовых типов
Целые: (u)char,
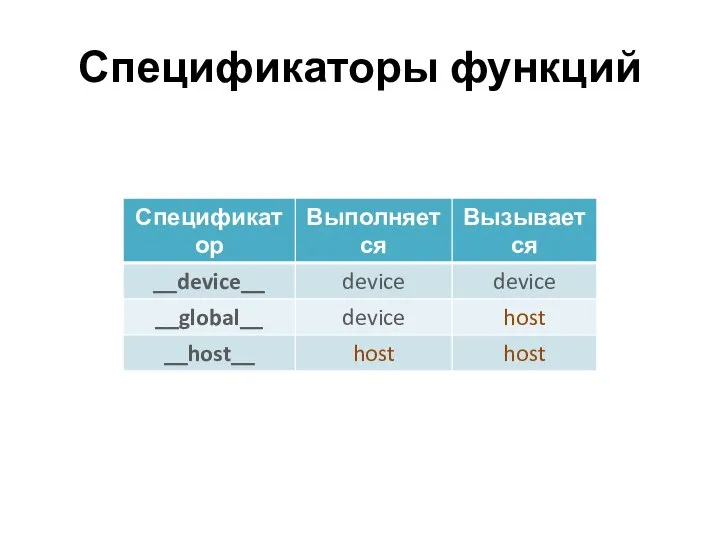
Спецификаторы функций
Спецификаторы функций

Спецификаторы функций
Ядро помечается __global__
Ядро не может возвращать значение
Возможно совместное использование __host__
Спецификаторы функций
Ядро помечается __global__
Ядро не может возвращать значение
Возможно совместное использование __host__

Ограничения функций GPU
Не поддерживается рекурсия
Не поддерживаются static-переменные
Нельзя брать адрес функции __device__
Не
Ограничения функций GPU
Не поддерживается рекурсия
Не поддерживаются static-переменные
Нельзя брать адрес функции __device__
Не
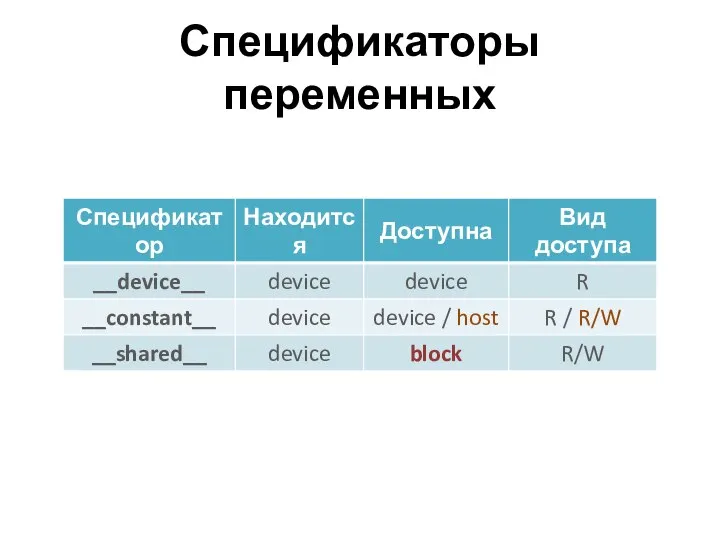
Спецификаторы переменных
Спецификаторы переменных

Ограничения переменных GPU
Переменные __shared__ не могут инициализироваться при объявлении
Запись в __constant__
Ограничения переменных GPU
Переменные __shared__ не могут инициализироваться при объявлении
Запись в __constant__

Переменные ядра
dim3 gridDim
unit3 blockIdx
dim3 blockDim
uint3 threadIdx
int
Переменные ядра
dim3 gridDim
unit3 blockIdx
dim3 blockDim
uint3 threadIdx
int

Директива запуска ядра
Kernel<<>>(data)
blocks – число блоков в сетке
threads – число
Директива запуска ядра
Kernel<<
blocks – число блоков в сетке
threads – число

Общая структура программы CUDA
__global__ void Kernel(float* data)
{
. . .
}
void main()
{
Общая структура программы CUDA
__global__ void Kernel(float* data)
{
. . .
}
void main()
{

Предустановки
Видеокарта NVIDIA с поддержкой CUDA
Драйвера устройства с поддержкой CUDA
NVIDIA CUDA Toolkit
NVIDIA
Предустановки
Видеокарта NVIDIA с поддержкой CUDA
Драйвера устройства с поддержкой CUDA
NVIDIA CUDA Toolkit
NVIDIA

Литература
NVIDIA Developer Zone
http://developer.nvidia.com/cuda
NVIDAI CUDA – Неграфические вычисления на графических процессорах
http://www.ixbt.com/video3/cuda-1.shtml
Создание простого
Литература
NVIDIA Developer Zone
http://developer.nvidia.com/cuda
NVIDAI CUDA – Неграфические вычисления на графических процессорах
http://www.ixbt.com/video3/cuda-1.shtml
Создание простого
 Прогресс общества. Гендерный аспект
Прогресс общества. Гендерный аспект Презентация на тему "Нравственное воспитание школьников" - скачать презентации по Педагогике
Презентация на тему "Нравственное воспитание школьников" - скачать презентации по Педагогике Олимпиадные задачи. Динамическое программирование
Олимпиадные задачи. Динамическое программирование Модель создания корпоративного имиджа по Б. Джи и ее применение в российских условиях Выполнила: Давыдова Лена, 401 группа Руков
Модель создания корпоративного имиджа по Б. Джи и ее применение в российских условиях Выполнила: Давыдова Лена, 401 группа Руков The 10 most extravagant hats for the Royal Ascot races Royal
The 10 most extravagant hats for the Royal Ascot races Royal Международные экономические организации 1. Международные правительственные (межгосударственные) экономические организации. 2.
Международные экономические организации 1. Международные правительственные (межгосударственные) экономические организации. 2.  Понятие и причины текучести персонала. Понятие абсентеизма, способы снижения абсентеизма на предприятии
Понятие и причины текучести персонала. Понятие абсентеизма, способы снижения абсентеизма на предприятии 1 апреля - день шуток и смеха
1 апреля - день шуток и смеха Саяны
Саяны  Строительство египетских пирамид
Строительство египетских пирамид Имидж современного педагога
Имидж современного педагога Презентация Microsoft PowerPoint
Презентация Microsoft PowerPoint Продовольственная безопасность России. Горовых А.Е (Т-093)
Продовольственная безопасность России. Горовых А.Е (Т-093)  Halloween. Origins and Traditions
Halloween. Origins and Traditions Недостоверное декларирование: не правильное присвоение кода товара по ЕТН ВЭД ТС Выполнили студентки 3-го курса ФТД группы Т-1209
Недостоверное декларирование: не правильное присвоение кода товара по ЕТН ВЭД ТС Выполнили студентки 3-го курса ФТД группы Т-1209  обмен веществ в эритроцитах
обмен веществ в эритроцитах  Отличие работы одиночной сваи от группы свай ПГС-152 Крупский Глеб
Отличие работы одиночной сваи от группы свай ПГС-152 Крупский Глеб Народ манси
Народ манси Коммерческая тайна. Материал для сотрудников РИЦ. КУП для бюджетных организаций
Коммерческая тайна. Материал для сотрудников РИЦ. КУП для бюджетных организаций Формы поведения
Формы поведения  Экспериментальная и инновационная работа с курсом «Проектная дея
Экспериментальная и инновационная работа с курсом «Проектная дея Презентация1
Презентация1 Чтобы быть хорошим преподавателем, нужно любить то, что преподаешь, и любить тех кому преподаешь. В. Ключевс
Чтобы быть хорошим преподавателем, нужно любить то, что преподаешь, и любить тех кому преподаешь. В. Ключевс Презентация Эмоции
Презентация Эмоции  Технология повышения среднего чека в магазине
Технология повышения среднего чека в магазине События и делегаты
События и делегаты Знать много языков - история моей страны
Знать много языков - история моей страны Раскладные механизмы диванов
Раскладные механизмы диванов