- Язык SQL

Содержание
- 2. Целые типы данных - поддерживают только целые числа (дробные части и десятичные точки не допускаются). Над
- 3. DECIMAL(p) - тип данных аналогичный FLOAT с числом значащих цифр p. DECIMAL(p,n) - аналогично предыдущему, p
- 4. DATETIME - тип данных для хранения моментов времени (год + месяц + день + часы +
- 5. 2. Операторы создания схемы базы данных. При описании команд предполагается, что: текст, набранный строчными буквами (например,
- 6. Создание таблицы: CREATE TABLE ( [NOT NULL] [UNIQUE | PRIMARY KEY] [REFERENCES [ ]] , ...)
- 7. Контроль за выполнением указанных условий осуществляет СУБД. Пример: создание базы данных publications: // (ПУБЛИКАЦИИ) CREATE DATABASE
- 8. CREATE TABLE wwwsiteauthors (au_id INT REFERENCES authors(au_id), site_id INT REFERENCES wwwsites(site_id)); Удаление таблицы: DROP TABLE Модификация
- 9. Модификация таблицы:
- 10. 3. Операторы управления правами доступа. По соображениям безопасности не каждому пользователю прикладной системы может быть разрешено
- 11. DELETE - удаление записей из таблицы INDEX - индексирование таблицы ALTER - изменение схемы определения таблицы
- 12. Отмена прав осуществляется командой REVOKE: REVOKE ON [ ] FROM Все ключевые слова данной команды эквивалентны
- 13. 4. Команды модификации данных. К этой группе относятся операторы добавления, изменения и удаления записей. Добавить новую
- 14. Модификация записей: UPDATE SET имя_столбца>= ,...[WHERE ] Если задано ключевое слово WHERE и условие, то команда
- 15. операции проверки на вхождение в диапазон: BETWEEN и NOT BETWEEN. операции проверки на вхождение в список:
- 16. Пример: DELETE FROM publishers WHERE publisher = "Super Computer Publishing"; Эта команда удаляет запись об издательстве
- 17. Оператор всегда начинается с ключевого слова SELECT. В конструкции определяется столбец или столбцы, включаемые в результат.
- 18. Другой вариант этой команды можно получить с использованием логической операции проверки на вхождение в интервал: SELECT
- 19. SELECT title FROM titles WHERE pub_id IN (SELECT pub_id FROM publishers WHERE publisher='Oracle Press'); При выполнении
- 20. Попробуем найти искомый web-site: SELECT publiser, url FROM publishers WHERE publisher LIKE '%Wiley%'; В соотвествии с
- 21. При выполнении оператора SELECT результирующее отношение (но не таблица!) может иметь несколько записей с одинаковыми значениями
- 22. Для выполнения операции такого рода в операторе SELECT после ключевого слова FROM указывается список таблиц, по
- 23. Имеется возможность производить слияние и более чем двух таблиц. Например, чтобы дополнить описанную выше выборку именами
- 24. SELECT title, yearpub-1992 FROM titles WHERE yearpub > 1992; В арифметических вражения допускаются операции сложения (+),
- 25. подсчитать количество книг в нашей базе данных: SELECT COUNT(*) FROM titles; Область действия данных функции можно
- 26. Определим для примера количество книг каждего издательства в нашей базе данных: SELECT publishers.publisher, count(titles.title) FROM titles,publishers
- 27. Другой вариант использования HAVING - включить в результат только те издательтва, название которых оканчивается на подстроку
- 28. Пример: сортировать список авторов по алфавиту: SELECT author FROM authors ORDER BY author; Более сложный пример:
- 29. 11.Использование представлений. До сих пор мы говорили о таблицах, которые реально хранятся в базе данных. Это,
- 30. 1) представление должно базироваться на единcтвенном запросе (UNION не допустимо) 2) выходные данные запроса, формирующего представление,
- 31. SELECT author,count(title) FROM books GROUP BY author (Права пользователей на доступ в представлениям назначаются также с
- 32. Здесь использована еще одна, ранее не описанная, возможность SQL - присвоение новых имен столбцам представления. В
- 33. 12. Дополнительные возможности SQL. Следующие возможности представлены в той или иной мере практически во всех современных
- 34. Обычно такие модули называют хранимыми процедурами. Они могут быть вызваны с передачей параметров любым пользователем, имеющим
- 35. Триггеры. Для каждой таблицы может быть назначена хранимая процедура без параметров, которая вызывается при выполнении оператора
- 36. Операторы SQL после ключевого слова AS описывают действия, которые выполняет триггер и условия выполнения этих действий.
- 37. Транзакции, блокировки и многопользовательский доступ к данным. Любая база данных годна к использованию только тогда, когда
- 38. Если в этот момент в системе произойдет сбой (например, выключение электропитания), то целостное состояние БД будет
- 39. Каждая транзакция начинается при целостном состоянии БД и оставляет это состояние целостным после своего завершения. Этот
- 40. Первую ситуацию можно рассматривать как особый вид мягкого аппаратного сбоя; при возникновении второй требуется ликвидировать последствия
- 41. изменении любого объекта БД должна попасть во внешнюю память журнала раньше, чем измененный объект попадет во
- 42. модифицированные транзакциями, которые к моменту сбоя успешно завершились (по причине использования буферов оперативной памяти, содержимое которых
- 43. жесткого сбоя необходимо, чтобы журнал не пропал. восстановление БД состоит в том, что исходя из архивной
- 44. Транзакция завершается одним из возможных способов: 1.оператор COMMIT означает успешное завершение транзакции, все изменения, внесенные в
- 46. Скачать презентацию

Целые типы данных - поддерживают только целые числа (дробные части и
Целые типы данных - поддерживают только целые числа (дробные части и

DECIMAL(p) - тип данных аналогичный FLOAT с числом значащих цифр p.
DECIMAL(p) - тип данных аналогичный FLOAT с числом значащих цифр p.

DATETIME - тип данных для хранения моментов времени (год + месяц
DATETIME - тип данных для хранения моментов времени (год + месяц

2. Операторы создания схемы базы данных.
При описании команд предполагается, что:
текст,
2. Операторы создания схемы базы данных.
При описании команд предполагается, что:
текст,
![Создание таблицы: CREATE TABLE ( [NOT NULL] [UNIQUE | PRIMARY KEY]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1303568/slide-5.jpg)
Создание таблицы:
CREATE TABLE <имя_таблицы>(<имя_столбца><тип_столбца> [NOT NULL]
[UNIQUE | PRIMARY KEY]
[REFERENCES <имя_мастер_таблицы> [<имя_столбца>]]
Создание таблицы:
CREATE TABLE <имя_таблицы>(<имя_столбца><тип_столбца> [NOT NULL]
[UNIQUE | PRIMARY KEY]
[REFERENCES <имя_мастер_таблицы> [<имя_столбца>]]

Контроль за выполнением указанных условий осуществляет СУБД.
Пример: создание базы данных
Контроль за выполнением указанных условий осуществляет СУБД.
Пример: создание базы данных
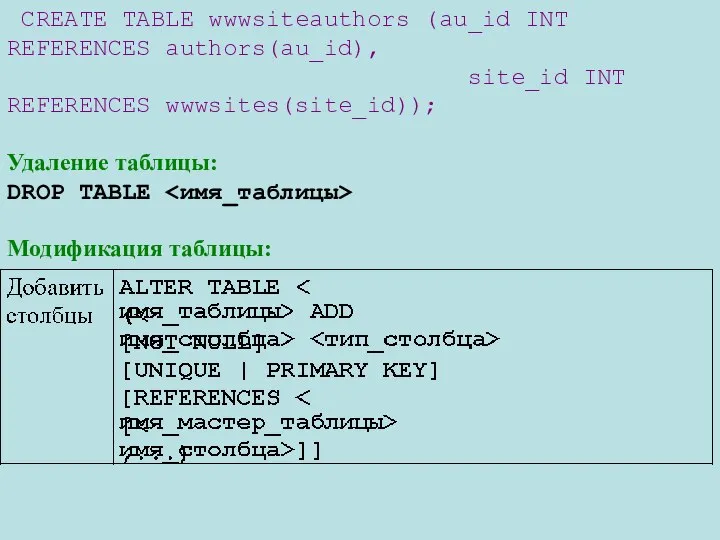
CREATE TABLE wwwsiteauthors (au_id INT REFERENCES authors(au_id),
site_id INT REFERENCES
CREATE TABLE wwwsiteauthors (au_id INT REFERENCES authors(au_id),
site_id INT REFERENCES
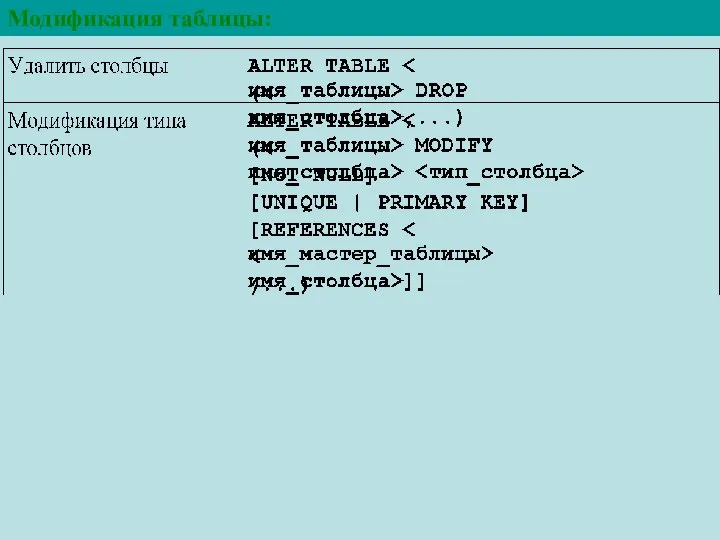
Модификация таблицы:
Модификация таблицы:

3. Операторы управления правами доступа.
По соображениям безопасности не каждому пользователю прикладной
3. Операторы управления правами доступа.
По соображениям безопасности не каждому пользователю прикладной

DELETE - удаление записей из таблицы
INDEX - индексирование таблицы
ALTER
DELETE - удаление записей из таблицы
INDEX - индексирование таблицы
ALTER
![Отмена прав осуществляется командой REVOKE: REVOKE ON [ ] FROM Все](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1303568/slide-11.jpg)
Отмена прав осуществляется командой REVOKE:
REVOKE <тип_права_на_таблицу>
ON <имя_таблицы> [<список_столбцов>]
FROM
Отмена прав осуществляется командой REVOKE:
REVOKE <тип_права_на_таблицу>
ON <имя_таблицы> [<список_столбцов>]
FROM

4. Команды модификации данных.
К этой группе относятся операторы добавления, изменения и
4. Команды модификации данных.
К этой группе относятся операторы добавления, изменения и
![Модификация записей: UPDATE SET имя_столбца>= ,...[WHERE ] Если задано ключевое слово](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1303568/slide-13.jpg)
Модификация записей:
UPDATE <имя_таблицы>
SET имя_столбца>=<значение>,...[WHERE <условие>]
Если задано ключевое слово WHERE
Модификация записей:
UPDATE <имя_таблицы>
SET имя_столбца>=<значение>,...[WHERE <условие>]
Если задано ключевое слово WHERE

операции проверки на вхождение в диапазон: BETWEEN и NOT BETWEEN.
операции
операции проверки на вхождение в диапазон: BETWEEN и NOT BETWEEN.
операции

Пример:
DELETE FROM publishers WHERE publisher = "Super Computer Publishing";
Эта команда
Пример:
DELETE FROM publishers WHERE publisher = "Super Computer Publishing";
Эта команда

Оператор всегда начинается с ключевого слова SELECT. В конструкции <список_выбора> определяется
Оператор всегда начинается с ключевого слова SELECT. В конструкции <список_выбора> определяется

Другой вариант этой команды можно получить с использованием логической операции проверки
Другой вариант этой команды можно получить с использованием логической операции проверки

SELECT title FROM titles WHERE pub_id IN
(SELECT pub_id FROM publishers
SELECT title FROM titles WHERE pub_id IN
(SELECT pub_id FROM publishers

Попробуем найти искомый web-site:
SELECT publiser, url FROM publishers WHERE publisher
Попробуем найти искомый web-site:
SELECT publiser, url FROM publishers WHERE publisher

При выполнении оператора SELECT результирующее отношение (но не таблица!) может иметь
При выполнении оператора SELECT результирующее отношение (но не таблица!) может иметь

Для выполнения операции такого рода в операторе SELECT после ключевого слова
Для выполнения операции такого рода в операторе SELECT после ключевого слова

Имеется возможность производить слияние и более чем двух таблиц. Например, чтобы
Имеется возможность производить слияние и более чем двух таблиц. Например, чтобы

SELECT title, yearpub-1992 FROM titles WHERE yearpub > 1992;
В арифметических вражения
SELECT title, yearpub-1992 FROM titles WHERE yearpub > 1992;
В арифметических вражения

подсчитать количество книг в нашей базе данных:
SELECT COUNT(*) FROM titles;
Область
подсчитать количество книг в нашей базе данных:
SELECT COUNT(*) FROM titles;
Область

Определим для примера количество книг каждего издательства в нашей базе данных:
Определим для примера количество книг каждего издательства в нашей базе данных:

Другой вариант использования HAVING - включить в результат только те издательтва,
Другой вариант использования HAVING - включить в результат только те издательтва,

Пример: сортировать список авторов по алфавиту:
SELECT author FROM authors ORDER
Пример: сортировать список авторов по алфавиту:
SELECT author FROM authors ORDER

11.Использование представлений.
До сих пор мы говорили о таблицах, которые реально хранятся
11.Использование представлений.
До сих пор мы говорили о таблицах, которые реально хранятся

1) представление должно базироваться на единcтвенном запросе (UNION не допустимо)
2) выходные
1) представление должно базироваться на единcтвенном запросе (UNION не допустимо) 2) выходные

SELECT author,count(title) FROM books GROUP BY author
(Права пользователей на доступ в
SELECT author,count(title) FROM books GROUP BY author
(Права пользователей на доступ в

Здесь использована еще одна, ранее не описанная, возможность SQL - присвоение
Здесь использована еще одна, ранее не описанная, возможность SQL - присвоение

12. Дополнительные возможности SQL.
Следующие возможности представлены в той или иной мере
12. Дополнительные возможности SQL.
Следующие возможности представлены в той или иной мере

Обычно такие модули называют хранимыми процедурами.
Они могут быть вызваны с
Обычно такие модули называют хранимыми процедурами.
Они могут быть вызваны с

Триггеры.
Для каждой таблицы может быть назначена хранимая процедура без параметров,
Триггеры.
Для каждой таблицы может быть назначена хранимая процедура без параметров,

Операторы SQL после ключевого слова AS описывают действия, которые выполняет триггер
Операторы SQL после ключевого слова AS описывают действия, которые выполняет триггер

Транзакции, блокировки и многопользовательский доступ к данным.
Любая база данных годна к
Транзакции, блокировки и многопользовательский доступ к данным.
Любая база данных годна к

Если в этот момент в системе произойдет сбой (например, выключение электропитания),
Если в этот момент в системе произойдет сбой (например, выключение электропитания),

Каждая транзакция начинается при целостном состоянии БД и оставляет это состояние
Каждая транзакция начинается при целостном состоянии БД и оставляет это состояние

Первую ситуацию можно рассматривать как особый вид мягкого аппаратного сбоя; при
Первую ситуацию можно рассматривать как особый вид мягкого аппаратного сбоя; при

изменении любого объекта БД должна попасть во внешнюю память журнала раньше,
изменении любого объекта БД должна попасть во внешнюю память журнала раньше,

модифицированные транзакциями, которые к моменту сбоя успешно завершились (по причине использования
модифицированные транзакциями, которые к моменту сбоя успешно завершились (по причине использования

жесткого сбоя необходимо, чтобы журнал не пропал. восстановление БД состоит в
жесткого сбоя необходимо, чтобы журнал не пропал. восстановление БД состоит в

Транзакция завершается одним из возможных способов:
1.оператор COMMIT означает успешное завершение
Транзакция завершается одним из возможных способов:
1.оператор COMMIT означает успешное завершение
 Межнациональные особенности невербального общения Выполнила студентка группы Ю-104 Чуева Яна
Межнациональные особенности невербального общения Выполнила студентка группы Ю-104 Чуева Яна Основы общественного производства. Воспроизводство и его фазы.
Основы общественного производства. Воспроизводство и его фазы. Образовательная технология «Портфолио»
Образовательная технология «Портфолио» Агбис
Агбис Движения земной коры
Движения земной коры Вербное воскресение. Неделя перед Пасхой
Вербное воскресение. Неделя перед Пасхой Презентация на тему "Инфекционная иммунология" - скачать презентации по Медицине
Презентация на тему "Инфекционная иммунология" - скачать презентации по Медицине Четыре вида стиля интерьера: ампир, классический, модерн, Ар Деко
Четыре вида стиля интерьера: ампир, классический, модерн, Ар Деко Современное состояние системы подготовки спортивного резерва в Пермском крае
Современное состояние системы подготовки спортивного резерва в Пермском крае От фантазии к реализации
От фантазии к реализации Олимпийские игры в древней Греции: система обслуживания спортсменов и гостей
Олимпийские игры в древней Греции: система обслуживания спортсменов и гостей Зимующие птицы Автор презентации: Калмычкова Е.В., учитель начальных классов ГБОУ СОШ 1980 города Москвы.
Зимующие птицы Автор презентации: Калмычкова Е.В., учитель начальных классов ГБОУ СОШ 1980 города Москвы. Основные направления применения педагогических средств восстановления
Основные направления применения педагогических средств восстановления Шайхиева Надежда Ивановна, учитель изобразительного искусства МОБУ СОШ№3 им.Ю.Гагарина г. Таганрога Ростовской области
Шайхиева Надежда Ивановна, учитель изобразительного искусства МОБУ СОШ№3 им.Ю.Гагарина г. Таганрога Ростовской области Анализ переходных процессов классическим методом в цепях с одним реактивным элементом. (Лекция 3)
Анализ переходных процессов классическим методом в цепях с одним реактивным элементом. (Лекция 3) Презентация "Роль денег в регулировании экономики" - скачать презентации по Экономике
Презентация "Роль денег в регулировании экономики" - скачать презентации по Экономике Презентация на тему "Использование метода проектов в начальной школе" - скачать презентации по Педагогике
Презентация на тему "Использование метода проектов в начальной школе" - скачать презентации по Педагогике Разработка Web-технологий в сопровождении НОЦ
Разработка Web-технологий в сопровождении НОЦ Chesotka
Chesotka Организация транспортного обслуживания международных экономических связей
Организация транспортного обслуживания международных экономических связей Презентация____
Презентация____ Презентация на тему "Рефлекс. Рефлекторная дуга" - скачать презентации по Медицине
Презентация на тему "Рефлекс. Рефлекторная дуга" - скачать презентации по Медицине Виды и системы безопасности
Виды и системы безопасности  Основные понятия языка
Основные понятия языка Основы технологической культуры Технология трудовой деятельности Степанова Лариса Иосифовна, учитель технологии МОУ «ТСОШ №3»
Основы технологической культуры Технология трудовой деятельности Степанова Лариса Иосифовна, учитель технологии МОУ «ТСОШ №3» Презентация "Авторское кино в России" - скачать презентации по МХК
Презентация "Авторское кино в России" - скачать презентации по МХК ГРОСС ГАНС и его основные идеи в криминалистике и юридической психологии. Подготовила: Студентка 2 курса Группы Юб03/1303 Шестёр
ГРОСС ГАНС и его основные идеи в криминалистике и юридической психологии. Подготовила: Студентка 2 курса Группы Юб03/1303 Шестёр Глава 1 Принципы экономики 3. Рыночная система экономики
Глава 1 Принципы экономики 3. Рыночная система экономики