- Алгоритмы поиска в строке

Содержание
- 2. Поиск подстроки в строке — типичная задача поиска информации. На сегодняшний день существует огромное разнообразие алгоритмов
- 3. ГДЕ ПРИМЕНЯЮТСЯ АЛГОРИТМЫ ПОИСКА В СТРОКЕ?
- 4. ГДЕ ПРИМЕНЯЮТСЯ АЛГОРИТМЫ ПОИСКА В СТРОКЕ?
- 5. ГДЕ ПРИМЕНЯЮТСЯ АЛГОРИТМЫ ПОИСКА В СТРОКЕ?
- 6. ЛИНЕЙНЫЙ ПОИСК Линейный, последовательный поиск (поиск методом полного перебора или брутфорса) — алгоритм нахождения заданного значения
- 7. ЛИНЕЙНЫЙ ПОИСК В связи с малой эффективностью по сравнению с другими алгоритмами линейный поиск обычно используют,
- 8. ЛИНЕЙНЫЙ ПОИСК Условие: дано два массива A и B. Нужно определить, является ли массив A подстрокой
- 9. АЛГОРИТМ БОЙЕРА-МУРА Алгоритм поиска строки Бойера-Мура, считается наиболее быстрым среди алгоритмов общего назначения, предназначенных для поиска
- 10. АЛГОРИТМ БОЙЕРА-МУРА 2. Эвристика стоп-символа. Предположим, что мы производим поиск слова «колокол». Первая же буква не
- 11. АЛГОРИТМ БОЙЕРА-МУРА Если стоп-символ «к» оказался за другой буквой «к», эвристика стоп-символа не работает. В таких
- 12. АЛГОРИТМ БОЙЕРА-МУРА Обе эвристики требуют предварительных вычислений — в зависимости от шаблона поиска заполняются две таблицы.
- 13. АЛГОРИТМ БОЙЕРА-МУРА Таблица суффиксов Для каждого возможного суффикса S шаблона строки указываем наименьшую величину, на которую
- 14. АЛГОРИТМ КНУТА-МОРРИСА-ПРАТТА Этот алгоритм – в общем случае самый быстрый из алгоритмов поиска подстроки в тексте
- 15. АЛГОРИТМ КНУТА-МОРРИСА-ПРАТТА Шаг 1. Построение таблицы префиксов TB. TB – массив целых чисел длиной m. Объявим
- 16. Пример 1. S=‘арарат’; % 6 букв TB=zeros(1,6); % заполняем нулями таблицу префиксов. TB(1)=0. k=2. S(1:2) =
- 17. % Matlab % Быстрый алгоритм заполнения таблицы префиксов % для строки S длиной m: TB=zeros(1,m); %
- 18. Шаг 2. Быстрый поиск подстроки S в тексте T с использованием полученной таблицы префиксов TB, где
- 19. Пример 123456789012345 T=‘оконокнокнокаон’ n=15 S=‘окнока’ m=6 TB=[0 0 0 1 2 0] j=1. i=1. S(1)==T(1) ?
- 21. Скачать презентацию

Поиск подстроки в строке — типичная задача поиска информации. На сегодняшний

ГДЕ ПРИМЕНЯЮТСЯ АЛГОРИТМЫ ПОИСКА В СТРОКЕ?
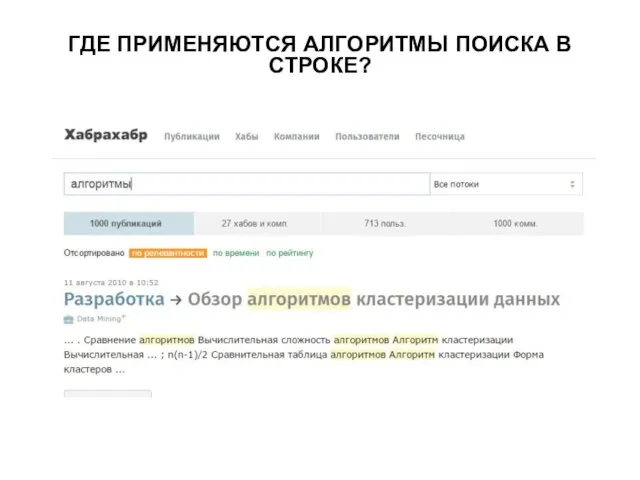
ГДЕ ПРИМЕНЯЮТСЯ АЛГОРИТМЫ ПОИСКА В СТРОКЕ?
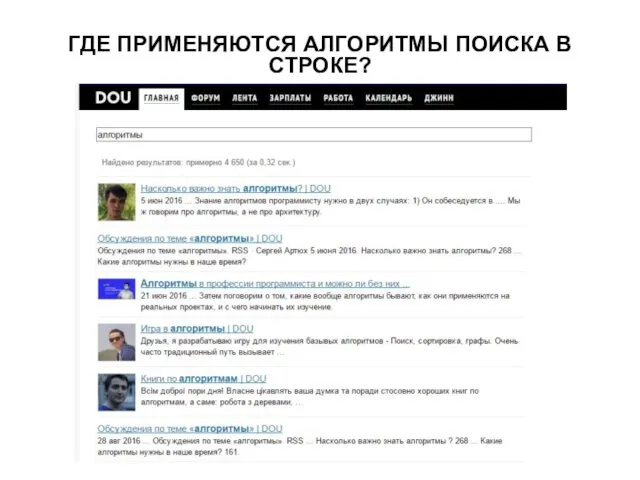
ГДЕ ПРИМЕНЯЮТСЯ АЛГОРИТМЫ ПОИСКА В СТРОКЕ?

ЛИНЕЙНЫЙ ПОИСК
Линейный, последовательный поиск (поиск методом полного перебора или брутфорса) —
ЛИНЕЙНЫЙ ПОИСК
Линейный, последовательный поиск (поиск методом полного перебора или брутфорса) —

ЛИНЕЙНЫЙ ПОИСК
В связи с малой эффективностью по сравнению с другими алгоритмами
ЛИНЕЙНЫЙ ПОИСК
В связи с малой эффективностью по сравнению с другими алгоритмами

ЛИНЕЙНЫЙ ПОИСК
Условие: дано два массива A и B. Нужно определить, является
ЛИНЕЙНЫЙ ПОИСК
Условие: дано два массива A и B. Нужно определить, является

АЛГОРИТМ БОЙЕРА-МУРА
Алгоритм поиска строки Бойера-Мура, считается наиболее быстрым среди алгоритмов общего
АЛГОРИТМ БОЙЕРА-МУРА
Алгоритм поиска строки Бойера-Мура, считается наиболее быстрым среди алгоритмов общего

АЛГОРИТМ БОЙЕРА-МУРА
2. Эвристика стоп-символа. Предположим, что мы производим поиск слова «колокол».
АЛГОРИТМ БОЙЕРА-МУРА
2. Эвристика стоп-символа. Предположим, что мы производим поиск слова «колокол».

АЛГОРИТМ БОЙЕРА-МУРА
Если стоп-символ «к» оказался за другой буквой «к», эвристика стоп-символа
АЛГОРИТМ БОЙЕРА-МУРА
Если стоп-символ «к» оказался за другой буквой «к», эвристика стоп-символа

АЛГОРИТМ БОЙЕРА-МУРА
Обе эвристики требуют предварительных вычислений — в зависимости от шаблона
АЛГОРИТМ БОЙЕРА-МУРА
Обе эвристики требуют предварительных вычислений — в зависимости от шаблона

АЛГОРИТМ БОЙЕРА-МУРА
Таблица суффиксов
Для каждого возможного суффикса S шаблона строки указываем наименьшую величину, на которую нужно
АЛГОРИТМ БОЙЕРА-МУРА
Таблица суффиксов
Для каждого возможного суффикса S шаблона строки указываем наименьшую величину, на которую нужно

АЛГОРИТМ КНУТА-МОРРИСА-ПРАТТА
Этот алгоритм – в общем случае самый быстрый из алгоритмов
АЛГОРИТМ КНУТА-МОРРИСА-ПРАТТА
Этот алгоритм – в общем случае самый быстрый из алгоритмов

АЛГОРИТМ КНУТА-МОРРИСА-ПРАТТА
Шаг 1. Построение таблицы префиксов TB. TB – массив целых
АЛГОРИТМ КНУТА-МОРРИСА-ПРАТТА
Шаг 1. Построение таблицы префиксов TB. TB – массив целых

Пример 1.
S=‘арарат’; % 6 букв
TB=zeros(1,6); % заполняем нулями таблицу префиксов. TB(1)=0.
k=2. S(1:2)
Пример 1.
S=‘арарат’; % 6 букв
TB=zeros(1,6); % заполняем нулями таблицу префиксов. TB(1)=0.
k=2. S(1:2)

% Matlab
% Быстрый алгоритм заполнения таблицы префиксов % для строки S
% Matlab
% Быстрый алгоритм заполнения таблицы префиксов % для строки S

Шаг 2. Быстрый поиск подстроки S в тексте T с использованием
Шаг 2. Быстрый поиск подстроки S в тексте T с использованием

Пример
123456789012345
T=‘оконокнокнокаон’ n=15
S=‘окнока’ m=6
TB=[0 0 0 1 2 0]
j=1. i=1.
S(1)==T(1) ? j=2.
Пример
123456789012345
T=‘оконокнокнокаон’ n=15
S=‘окнока’ m=6
TB=[0 0 0 1 2 0]
j=1. i=1.
S(1)==T(1) ? j=2.
 Электронная почта
Электронная почта Организация вычислений в электронных таблицах
Организация вычислений в электронных таблицах База данных и ее объекты. Создание структуры базы данных
База данных и ее объекты. Создание структуры базы данных Как делать посты красиво и читабельно
Как делать посты красиво и читабельно Анализ речевого жанра комментарий
Анализ речевого жанра комментарий Методика навчання інформатики. (Лекция 2)
Методика навчання інформатики. (Лекция 2) Владивостокский государственный университет экономики и сервиса Институт информатики инноваций и бизнес систем Владивосто
Владивостокский государственный университет экономики и сервиса Институт информатики инноваций и бизнес систем Владивосто Microsoft Excel программасының функциясы
Microsoft Excel программасының функциясы Основные сведения при работе с MS Excel
Основные сведения при работе с MS Excel Диаграммы классов - UML
Диаграммы классов - UML Занятие №1. Введение в HTML и CSS
Занятие №1. Введение в HTML и CSS Решение задач на кодирование графической информации
Решение задач на кодирование графической информации Introduction of kns55 platform
Introduction of kns55 platform ER- диаграммы. Модель "сущность-связь"
ER- диаграммы. Модель "сущность-связь" Файлы и файловые структуры
Файлы и файловые структуры Word 2007. Спецкурс
Word 2007. Спецкурс Система Антиплагиат – инструмент обнаружения заимствований в учебных и научных работах
Система Антиплагиат – инструмент обнаружения заимствований в учебных и научных работах Файлдық жүйелер мен ДҚБЖ арасындағы негізгі айырмашылық
Файлдық жүйелер мен ДҚБЖ арасындағы негізгі айырмашылық Создание макросов на языке VBA
Создание макросов на языке VBA Тип данных. Функции обработки строк
Тип данных. Функции обработки строк Способы кодирования информации
Способы кодирования информации Компьютерные вирусы и антивирусы
Компьютерные вирусы и антивирусы Киберугрозы современности. Правила их распознавания и предотвращения
Киберугрозы современности. Правила их распознавания и предотвращения Типы баз данных (иерархические, сетевые, реляционные)
Типы баз данных (иерархические, сетевые, реляционные) Графические редакторы и их отличия
Графические редакторы и их отличия Системы счисления и двоичное представление информации в памяти компьютера Подготовка к ЕГЭ Задания А1
Системы счисления и двоичное представление информации в памяти компьютера Подготовка к ЕГЭ Задания А1 Хайрулина Анастасия Владиславовна, МОУ СОШ №10, г. Кандалакша, Мурманская обл.
Хайрулина Анастасия Владиславовна, МОУ СОШ №10, г. Кандалакша, Мурманская обл.  Презентация "Система управления базами данных Access" - скачать презентации по Информатике
Презентация "Система управления базами данных Access" - скачать презентации по Информатике