- SQL. Часть II

Содержание
- 2. Хранимые процедуры Хранимая процедура – это последовательность компилированных операторов Transact-SQL, выполняемых в виде пакета и хранящихся
- 3. Хранимые процедуры это набор операторов SQL и другие логические конструкции, например операторы If и WHERE. Этот
- 4. Хранимые процедуры можно создать непосредственно на сервере, следовательно, когда для решения определенных задач требуется многократно выполнять
- 5. Применение хранимых процедур упрощает доступ к БД, т.к. пользователи могут в этом случае и не знать
- 6. Хранимые процедуры могут содержать как входные, так и выходные параметры; могут содержать инструкции, которые управляют потоком
- 7. Первоначальное выполнение хранимой процедуры: Лексический анализ разбивает ХП на отдельные компоненты. Разрешение ссылок – компоненты,ссылающиеся на
- 8. Дерево запроса считывается и окончательно оптимизируется. При последующих вызовах ХП выполняется только шаг 5. План выполнения
- 9. Преимущества использования ХП Выполняются быстрее, чем последовательность отдельных операторов; Необходимые для выполнения операторы уже содержатся в
- 10. Преимущества использования ХП (продолжение): Могут вызывать другие ХП и функции; Могут быть вызваны из прикладных программ
- 11. Создание и запуск ХП. CREATE PROC имя-процедуры [параметры] AS Запрос SQL Запуск EXEC имя-процедуры [параметры]
- 12. Пример 1 – процедура без параметров Вывести, когда и какой предмет сдавал студент Иванов ВВ. CREATE
- 13. Пример 2 – процедура с входным параметром Тоже, только для любого студента CREATE PROC my_proc2 @F
- 14. Пример 3 – процедура с входными параметрами Для некоторого студента снизить оплату на 5%. CREATE PROC
- 15. Пример 4 – процедура с входными параметрами и значениями по умолчанию CREATE PROC my_proc4 @N varchar(5)=
- 16. Пример 5 – процедура с входными и выходными параметрами Вывести общую сумму, уплаченную студентами за конкретный
- 17. Для чего в основном используют хранимые процедуры? Для упрощения сложных операций за счет инкапсуляции процессов в
- 18. Для чего в основном используют хранимые процедуры? Для упрощения управления изменениями. Если таблицы, имена столбцов, деловые
- 19. Для чего в основном используют хранимые процедуры? Существует элементы языка SQL и некоторые возможности, реализуемые только
- 20. Использование хранимых процедур для всех повторяющихся действий в базе данных является хорошим стилем программирования.
- 21. Триггеры - это особые хранимые процедуры, автоматически выполняемые при обращении к БД с целью изменения данных.
- 22. Триггер всегда связан с конкретной таблицей и выполняется при совершении над ней операций INSERT, UPDATE, DELETE
- 23. Триггеры Все производимые Т модификации рассматриваются как одна транзакция (срабатывает как транзакция). Создает Т только владелец
- 24. Триггеры чаще всего используются для: Проверки корректности введенных данных и выполнении сложных ограничений целостности данных, которые
- 25. Триггеры чаще всего используются для: Для выполнения дополнительной проверки и отмены введения данных (например, чтобы удостоверится,
- 26. В разных коммерческих СУБД рассматриваются разные триггеры. Так, в MS SQL Server триггеры определены только как
- 27. Триггеры могут быть эффективно использованы для поддержки семантической целостности БД, однако приоритет их ниже, чем приоритет
- 28. Предложения SQL для триггеров CREATE TRIGGER создает триггер ALTER TRIGGER изменяет триггер DROP TRIGGER удаляет триггер
- 29. Создание триггера CREATE TRIGGER имя_триггера ON имя таблицы или представления FOR {INSERT, UPDATE, DELETE} [WITH ENCRYPTION]
- 30. По умолчанию триггер выполняется после изменения данных, но если указать параметр INSEAD OF, то создается триггер,
- 31. Изменение триггера ALTER TRIGGER имеет тот же синтаксис, что и CREATE TRIGGER, и применяется для изменения
- 32. Удаление триггера DROP TRIGGER имя триггера. Автоматически триггер удаляется при удалении таблицы, для которой он был
- 33. Триггеры По умолчанию триггер выполняется после изменения данных, но если указать параметр INSTEAD OF, то такой
- 34. Пример 1 Создать триггер, который будет при каждом добавлении или изменении данных таблицы «Преподаватели» возвращать сообщение
- 35. Запуск INSERT (Табельный Номер, ФИО, Должность) VALUES (’33п28’,’Иванов ВВ’,’доцент’)
- 36. Пример 2 Триггер срабатывает при удалении экземпляра некоторой книги, например, в случае утери. Он проверяет остался
- 37. Транзакция - это последовательность операций, производимых над БД, рассматриваемая СУБД как единое целое, и переводящая ее
- 38. Транзакция Инициализация Т м.б. вызвана как пользователем так и прикладной программой. Т особенно важны для многопользовательских
- 39. Проектирование транзакции заключается в определении: данных, используемых Т, функциональных характеристик Т, выходных данных, формируемых Т, степени
- 40. Свойства транзакций Атомарность – транзакция должна быть выполнена целиком или не выполнена вовсе. Согласованность – гарантирует,
- 41. Свойства транзакций Изолированность – означает, что конкурирующие за доступ к БД транзакции физически обрабатываются последовательно, изолированно
- 42. ФИКСАЦИЯ ИЛИ ОТКАТ? Если все операторы выполнены успешно и не произошло никаких сбоев программного или аппаратного
- 43. Модель транзакций Стандартом ANSI/ISO SQL определена модель транзакций и функции операторов COMMIT - фиксация ROLLBACK -
- 44. Транзакция завершается одним из 4-х возможных вариантов: Оператор COMMIT означает успешное завершение транзакции; его использование делает
- 45. Транзакция завершается одним из 4-х возможных вариантов: Успешное завершение программы, в которой была инициирована текущая транзакция,
- 46. ПРИМЕР В таблице Ведомость изменить значение поля Оценка на 0, если записано значение NULL. BEGIN TRAN
- 47. Журнал транзакций ЖТ – это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью,
- 48. Журнал транзакций (продолжение) Используется стратегия «упреждающей» записи (протокол WAL) – запись об изменении любого объекта БД
- 49. Проблемы параллельного выполнения транзакций. Пропавшие изменения, Проблемы промежуточных данных, Проблемы несогласованных данных, Проблемы строк-фантомов.
- 50. Феномен «грязное чтение»
- 51. Феномен фантомов
- 52. Феномен неповторяемого чтения
- 53. Как бороться с проблемами? Сериализация транзакций. Выработать процедуру согласованного выполнения Т: В ходе выполнения Т пользователь
- 54. Сериализация транзакций. Самый популярный механизм реализации сериализации Т – механизм блокировок.
- 55. Блокировки Чтобы запретить нескольким пользователям одновременно изменять данные в базе и считывать «грязные» данные используется блокировка.
- 56. Режимы блокировок: Разделяемый Обновления Монопольный Намерения Схемы Массового обновления
- 57. Разделяемая блокировка Применяется только для чтения и позволяет параллельным транзакциям одновременно считывать данные из одного и
- 58. Блокировка обновления Применяется, когда допустимо обновление ресурса. Только одна транзакция единовременно может наложить ее. Если транзакция
- 59. Блокировка намерения Монопольная блокировка Применяется для модификации данных. При этом никакая другая транзакция не может читать
- 60. Блокировка намерения применяется для иерархического упорядочения блокировок. Блокировка схемы применяется при выполнении операции, затрагивающей схему таблицы,
- 61. Блокировка массового обновления Применяется при копировании больших объемов данных в таблицу с указанием TABLOCK.
- 62. Индексы это набор ссылок, упорядоченных по определенному столбцу таблицы, это наборы уникальных значений для некоторой таблицы
- 63. Файлы Индексированный файл – это основной файл, содержащий данные отношения, для которого создан индексный файл. Индексный
- 64. Индекс представляет собой физический объект базы данных, имеющий структуру b-дерева и используемый оптимизатором для ускорения доступа
- 65. Кластерный индекс Создание кластерного индекса приводит к физической сортировке данных. У каждой таблицы может быть лишь
- 66. Некластерные индексы позволяют индексировать данные на основании значения ключа в каждой записи. SQL Server позволяет создать
- 67. Полнотекстовый индекс - хранящаяся в базе проиндексированных текстов совокупность идентификаторов, определяющих учитываемую совокупность индексов для всех
- 68. Индексы (создание) CREATE INDEX имя_индекса ON имя_таблицы (столбцы для индексации)
- 69. Индексы. Что следует учитывать: Индексы повышают производительность операций выборки, но ухудшают производительность операций-действий; Для хранения данных
- 71. Скачать презентацию

Хранимые процедуры
Хранимая процедура – это последовательность компилированных операторов Transact-SQL, выполняемых в
Хранимые процедуры
Хранимая процедура – это последовательность компилированных операторов Transact-SQL, выполняемых в

Хранимые процедуры
это набор операторов SQL и другие логические конструкции, например операторы
Хранимые процедуры
это набор операторов SQL и другие логические конструкции, например операторы

Хранимые процедуры
можно создать непосредственно на сервере, следовательно, когда для решения определенных
Хранимые процедуры
можно создать непосредственно на сервере, следовательно, когда для решения определенных

Применение хранимых процедур
упрощает доступ к БД, т.к. пользователи могут в этом
Применение хранимых процедур
упрощает доступ к БД, т.к. пользователи могут в этом

Хранимые процедуры
могут содержать как входные, так и выходные параметры;
могут содержать инструкции,
Хранимые процедуры
могут содержать как входные, так и выходные параметры;
могут содержать инструкции,

Первоначальное выполнение хранимой процедуры:
Лексический анализ разбивает ХП на отдельные компоненты.
Разрешение ссылок
Первоначальное выполнение хранимой процедуры:
Лексический анализ разбивает ХП на отдельные компоненты.
Разрешение ссылок

Дерево запроса считывается и окончательно оптимизируется.
При последующих вызовах ХП выполняется только
При последующих вызовах ХП выполняется только

Преимущества использования ХП
Выполняются быстрее, чем последовательность отдельных операторов;
Необходимые для выполнения операторы
Преимущества использования ХП
Выполняются быстрее, чем последовательность отдельных операторов;
Необходимые для выполнения операторы

Преимущества использования ХП (продолжение):
Могут вызывать другие ХП и функции;
Могут быть вызваны
Преимущества использования ХП (продолжение):
Могут вызывать другие ХП и функции;
Могут быть вызваны
![Создание и запуск ХП. CREATE PROC имя-процедуры [параметры] AS Запрос SQL Запуск EXEC имя-процедуры [параметры]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/719187/slide-10.jpg)
Создание и запуск ХП.
CREATE PROC имя-процедуры
[параметры]
AS
Запрос SQL
Запуск
EXEC имя-процедуры
[параметры]
Создание и запуск ХП.
CREATE PROC имя-процедуры
[параметры]
AS
Запрос SQL
Запуск
EXEC имя-процедуры
[параметры]

Пример 1 – процедура без параметров
Вывести, когда и какой предмет сдавал
Пример 1 – процедура без параметров
Вывести, когда и какой предмет сдавал

Пример 2 – процедура с входным параметром
Тоже, только для любого студента
CREATE
Пример 2 – процедура с входным параметром
Тоже, только для любого студента
CREATE

Пример 3 – процедура с входными параметрами
Для некоторого студента снизить оплату
Пример 3 – процедура с входными параметрами
Для некоторого студента снизить оплату

Пример 4 – процедура с входными параметрами и значениями по умолчанию
CREATE
Пример 4 – процедура с входными параметрами и значениями по умолчанию
CREATE

Пример 5 – процедура с входными и выходными параметрами
Вывести общую сумму,
Пример 5 – процедура с входными и выходными параметрами
Вывести общую сумму,

Для чего в основном используют хранимые процедуры?
Для упрощения сложных операций за
Для чего в основном используют хранимые процедуры?
Для упрощения сложных операций за

Для чего в основном используют хранимые процедуры?
Для упрощения управления изменениями. Если
Для чего в основном используют хранимые процедуры?
Для упрощения управления изменениями. Если

Для чего в основном используют хранимые процедуры?
Существует элементы языка SQL и
Для чего в основном используют хранимые процедуры?
Существует элементы языка SQL и

Использование хранимых процедур для всех повторяющихся действий в базе данных является
Использование хранимых процедур для всех повторяющихся действий в базе данных является

Триггеры
- это особые хранимые процедуры, автоматически выполняемые при обращении к БД
Триггеры
- это особые хранимые процедуры, автоматически выполняемые при обращении к БД

Триггер
всегда связан с конкретной таблицей и
выполняется при совершении над ней операций
Триггер
всегда связан с конкретной таблицей и
выполняется при совершении над ней операций

Триггеры
Все производимые Т модификации рассматриваются как одна транзакция (срабатывает как транзакция).
Создает
Триггеры
Все производимые Т модификации рассматриваются как одна транзакция (срабатывает как транзакция).
Создает

Триггеры чаще всего используются для:
Проверки корректности введенных данных и выполнении сложных
Триггеры чаще всего используются для:
Проверки корректности введенных данных и выполнении сложных

Триггеры чаще всего используются для:
Для выполнения дополнительной проверки и отмены введения
Триггеры чаще всего используются для:
Для выполнения дополнительной проверки и отмены введения

В разных коммерческих СУБД рассматриваются разные триггеры. Так, в MS SQL
В разных коммерческих СУБД рассматриваются разные триггеры. Так, в MS SQL

Триггеры могут быть эффективно использованы для поддержки семантической целостности БД, однако
Триггеры могут быть эффективно использованы для поддержки семантической целостности БД, однако

Предложения SQL для триггеров
CREATE TRIGGER создает триггер
ALTER TRIGGER изменяет триггер
DROP TRIGGER
Предложения SQL для триггеров
CREATE TRIGGER создает триггер
ALTER TRIGGER изменяет триггер
DROP TRIGGER

Создание триггера
CREATE TRIGGER имя_триггера
ON имя таблицы или представления
FOR {INSERT, UPDATE, DELETE}
Создание триггера
CREATE TRIGGER имя_триггера
ON имя таблицы или представления
FOR {INSERT, UPDATE, DELETE}

По умолчанию триггер выполняется после изменения данных, но если указать параметр
По умолчанию триггер выполняется после изменения данных, но если указать параметр

Изменение триггера
ALTER TRIGGER имеет тот же синтаксис, что и CREATE TRIGGER,
Изменение триггера
ALTER TRIGGER имеет тот же синтаксис, что и CREATE TRIGGER,

Удаление триггера
DROP TRIGGER имя триггера.
Автоматически триггер удаляется при удалении таблицы,
Удаление триггера
DROP TRIGGER имя триггера.
Автоматически триггер удаляется при удалении таблицы,

Триггеры
По умолчанию триггер выполняется после изменения данных, но если указать параметр
Триггеры
По умолчанию триггер выполняется после изменения данных, но если указать параметр

Пример 1
Создать триггер, который будет при каждом добавлении или изменении данных
Пример 1
Создать триггер, который будет при каждом добавлении или изменении данных

Запуск
INSERT (Табельный Номер, ФИО, Должность)
VALUES (’33п28’,’Иванов ВВ’,’доцент’)
Запуск
INSERT (Табельный Номер, ФИО, Должность)
VALUES (’33п28’,’Иванов ВВ’,’доцент’)

Пример 2
Триггер срабатывает при удалении экземпляра некоторой книги, например, в случае
Пример 2
Триггер срабатывает при удалении экземпляра некоторой книги, например, в случае

Транзакция
- это последовательность операций, производимых над БД, рассматриваемая СУБД как единое
Транзакция
- это последовательность операций, производимых над БД, рассматриваемая СУБД как единое

Транзакция
Инициализация Т м.б. вызвана как пользователем так и прикладной программой.
Т
Транзакция
Инициализация Т м.б. вызвана как пользователем так и прикладной программой.
Т

Проектирование транзакции заключается в определении:
данных, используемых Т,
функциональных характеристик Т,
выходных данных,
Проектирование транзакции заключается в определении:
данных, используемых Т,
функциональных характеристик Т,
выходных данных,

Свойства транзакций
Атомарность – транзакция должна быть выполнена целиком или не выполнена
Свойства транзакций
Атомарность – транзакция должна быть выполнена целиком или не выполнена

Свойства транзакций
Изолированность – означает, что конкурирующие за доступ к БД транзакции
Свойства транзакций
Изолированность – означает, что конкурирующие за доступ к БД транзакции

ФИКСАЦИЯ ИЛИ ОТКАТ?
Если все операторы выполнены успешно и не произошло никаких
ФИКСАЦИЯ ИЛИ ОТКАТ?
Если все операторы выполнены успешно и не произошло никаких

Модель транзакций
Стандартом ANSI/ISO SQL определена модель транзакций и функции операторов
COMMIT -
Модель транзакций
Стандартом ANSI/ISO SQL определена модель транзакций и функции операторов
COMMIT -

Транзакция завершается одним из 4-х возможных вариантов:
Оператор COMMIT означает успешное
Транзакция завершается одним из 4-х возможных вариантов:
Оператор COMMIT означает успешное

Транзакция завершается одним из 4-х возможных вариантов:
Успешное завершение программы, в которой
Транзакция завершается одним из 4-х возможных вариантов:
Успешное завершение программы, в которой

ПРИМЕР
В таблице Ведомость изменить значение поля Оценка на 0, если записано
ПРИМЕР
В таблице Ведомость изменить значение поля Оценка на 0, если записано

Журнал транзакций
ЖТ – это особая часть БД, недоступная пользователям СУБД и
Журнал транзакций
ЖТ – это особая часть БД, недоступная пользователям СУБД и

Журнал транзакций (продолжение)
Используется стратегия «упреждающей» записи (протокол WAL) – запись об
Журнал транзакций (продолжение)
Используется стратегия «упреждающей» записи (протокол WAL) – запись об

Проблемы параллельного выполнения транзакций.
Пропавшие изменения,
Проблемы промежуточных данных,
Проблемы несогласованных данных,
Проблемы строк-фантомов.
Проблемы параллельного выполнения транзакций.
Пропавшие изменения,
Проблемы промежуточных данных,
Проблемы несогласованных данных,
Проблемы строк-фантомов.
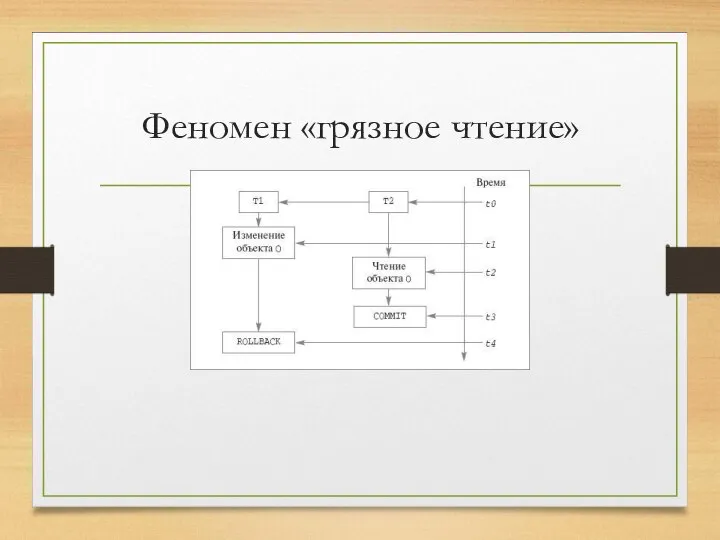
Феномен «грязное чтение»
Феномен «грязное чтение»

Феномен фантомов
Феномен фантомов
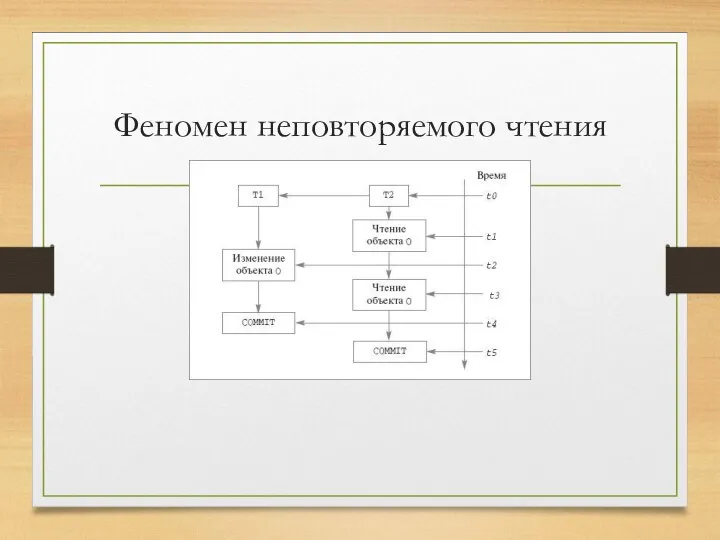
Феномен неповторяемого чтения
Феномен неповторяемого чтения

Как бороться с проблемами?
Сериализация транзакций.
Выработать процедуру согласованного выполнения Т:
В ходе
Как бороться с проблемами?
Сериализация транзакций.
Выработать процедуру согласованного выполнения Т:
В ходе

Сериализация транзакций.
Самый популярный механизм реализации сериализации Т – механизм блокировок.
Сериализация транзакций.
Самый популярный механизм реализации сериализации Т – механизм блокировок.

Блокировки
Чтобы запретить нескольким пользователям одновременно изменять данные в базе и считывать
Блокировки
Чтобы запретить нескольким пользователям одновременно изменять данные в базе и считывать

Режимы блокировок:
Разделяемый
Обновления
Монопольный
Намерения
Схемы
Массового обновления
Режимы блокировок:
Разделяемый
Обновления
Монопольный
Намерения
Схемы
Массового обновления

Разделяемая блокировка
Применяется только для чтения и позволяет параллельным транзакциям одновременно считывать
Разделяемая блокировка
Применяется только для чтения и позволяет параллельным транзакциям одновременно считывать

Блокировка обновления
Применяется, когда допустимо обновление ресурса. Только одна транзакция единовременно может
Блокировка обновления
Применяется, когда допустимо обновление ресурса. Только одна транзакция единовременно может

Блокировка намерения
Монопольная блокировка
Применяется для модификации данных. При этом никакая другая транзакция
Блокировка намерения
Монопольная блокировка
Применяется для модификации данных. При этом никакая другая транзакция

Блокировка намерения
применяется для иерархического упорядочения блокировок.
Блокировка схемы
применяется при выполнении операции,
Блокировка намерения
применяется для иерархического упорядочения блокировок.
Блокировка схемы
применяется при выполнении операции,

Блокировка массового обновления
Применяется при копировании больших объемов данных в таблицу с
Блокировка массового обновления
Применяется при копировании больших объемов данных в таблицу с

Индексы
это набор ссылок, упорядоченных по определенному столбцу таблицы,
это наборы уникальных
Индексы
это набор ссылок, упорядоченных по определенному столбцу таблицы,
это наборы уникальных

Файлы
Индексированный файл – это основной файл, содержащий данные отношения, для которого
Файлы
Индексированный файл – это основной файл, содержащий данные отношения, для которого

Индекс
представляет собой физический объект базы данных, имеющий структуру b-дерева и используемый
Индекс
представляет собой физический объект базы данных, имеющий структуру b-дерева и используемый

Кластерный индекс
Создание кластерного индекса приводит к физической сортировке данных.
У каждой таблицы
Кластерный индекс
Создание кластерного индекса приводит к физической сортировке данных.
У каждой таблицы

Некластерные индексы
позволяют индексировать данные на основании значения ключа в каждой записи.
SQL
Некластерные индексы
позволяют индексировать данные на основании значения ключа в каждой записи.
SQL

Полнотекстовый индекс
- хранящаяся в базе проиндексированных текстов совокупность идентификаторов, определяющих учитываемую
Полнотекстовый индекс
- хранящаяся в базе проиндексированных текстов совокупность идентификаторов, определяющих учитываемую

Индексы (создание)
CREATE INDEX имя_индекса
ON имя_таблицы (столбцы для индексации)
Индексы (создание)
CREATE INDEX имя_индекса
ON имя_таблицы (столбцы для индексации)

Индексы. Что следует учитывать:
Индексы повышают производительность операций выборки, но ухудшают производительность
Индексы. Что следует учитывать:
Индексы повышают производительность операций выборки, но ухудшают производительность
 Класична задача криптографії
Класична задача криптографії “Егемен Қазақстан” мен “Казахстанская правда”
“Егемен Қазақстан” мен “Казахстанская правда” Презентация "Информация и кодирование информации" - скачать презентации по Информатике
Презентация "Информация и кодирование информации" - скачать презентации по Информатике Всемирная паутина & 1.6
Всемирная паутина & 1.6 Презентация "Устройство ввода и вывода информации" - скачать презентации по Информатике
Презентация "Устройство ввода и вывода информации" - скачать презентации по Информатике Системы электронного документооборота (СЭД) «ДЕЛО»
Системы электронного документооборота (СЭД) «ДЕЛО»  Операционные системы. Введение. Основные сведения об ОС
Операционные системы. Введение. Основные сведения об ОС Файловая структура компьютера
Файловая структура компьютера Поняття текстового процесора. Основи роботи в MS Word
Поняття текстового процесора. Основи роботи в MS Word Презентация "Компьютерные презентации Мультимедийные технологии" - скачать презентации по Информатике
Презентация "Компьютерные презентации Мультимедийные технологии" - скачать презентации по Информатике Технические средства дистанционной передачи информации
Технические средства дистанционной передачи информации Информационное моделирование. 8 класс
Информационное моделирование. 8 класс Introduction to cloud computing
Introduction to cloud computing Перевод чисел в различные системы счисления
Перевод чисел в различные системы счисления HTML+CSS (верстка)
HTML+CSS (верстка) HTML. Первые шаги
HTML. Первые шаги MySQL. Добавление данных
MySQL. Добавление данных Задачи линейного программирования. (Тема 3)
Задачи линейного программирования. (Тема 3) Схема компьютера
Схема компьютера Наукометрические показатели
Наукометрические показатели Кодирование основных типов алгоритмических структур на языках объектно — ориентированного и процедурного программирования
Кодирование основных типов алгоритмических структур на языках объектно — ориентированного и процедурного программирования Информационная безопасность. Общие принципы. Виды безопасности. (Лекция 3)
Информационная безопасность. Общие принципы. Виды безопасности. (Лекция 3) Засоби передачі інформації
Засоби передачі інформації Технологии работы с молодежью: ведение сообществ в социальных сетях
Технологии работы с молодежью: ведение сообществ в социальных сетях Оператор условного перехода: усеченная (неполная) форма
Оператор условного перехода: усеченная (неполная) форма Строковый тип данных в языке С. Параметры запуска. Компиляция
Строковый тип данных в языке С. Параметры запуска. Компиляция Представления
Представления Компьютерлік желілер жайлы жалпы түсініктер
Компьютерлік желілер жайлы жалпы түсініктер