- Методы решения оптимизационных задач

Содержание
- 2. Введение Примеры дискретных оптимизационных задач задача о кратчайшем пути: Пусть имеется несколько городов и известны попарные
- 3. В каждой задаче имеется лишь конечное число вариантов, из которых требуется осуществить выбор (путей между городами,
- 4. Типы задач: массовые и индивидуальные задачи. Все вышеприведенные примеры дают образцы именно массовых задач. Индивидуальная задача
- 5. Говорят, что алгоритм решает некоторую массовую задачу, если он решает любую ее индивидуальную задачу. Для оценки
- 6. При сравнении скорости роста двух неотрицательных функций f(n) и g(n) будем использовать следующие понятия. Будем говорить,
- 7. Например, справедливы следующие соотношения: log2n = О(n); n2 = О(2n); n = Ω (log2n): На практике
- 8. Алгоритмы и их сложности Таблица 1.2. Влияние технического совершенствования ЭВМ на полиномиальные и экспоненциальные алгоритмы Таблица
- 9. Пусть для решения некоторой задачи имеется алгоритм сложности n3. Тогда, как это следует из таблицы 1.2,
- 10. Алгоритмы будем записывать на некотором специальном языке, который назовем упрощенным Паскалем. В этом языке возможно использование
- 11. АЛГОРИТМ 1.1. ВЫБОР МИНИМАЛЬНОГО ЭЛЕМЕНТА Данные: числовое множество X. Результат: число minX - минимальный элемент X
- 12. Повсюду в дальнейшем будем использовать следующие обозначения. Для произвольного вещественного числа х через |_x_| (читается дно
- 13. Графы и сети Многие задачи дискретной оптимизации могут быть интерпретированы как задачи на сетях и графах.
- 14. Графы и сети Рис. 2.1. Изображение графов и орграфов, а) Неориентированный граф, б) Ориентированный граф
- 15. Удобно вершины графа считать пронумерованными натуральными числами, и на рисунках сразу вместо точки ставить соответствующий номер
- 16. Цепью (соответственно путем) в графе (орграфе) G = (V,E) назовем чередующуюся последовательность вершин и ребер (узлов
- 17. Цепь в графе (соответственно путь), начальная и конечная вершины (узлы) которого совпадают, будем называть циклом {контуром).
- 18. Графы и сети
- 19. Графы и сети Граф, имеющий ровно одну компоненту связности, будем называть связным. Из определения вытекает, что
- 20. Графы и сети Условимся считать, что в графах и орграфах нет ребер вида {v,v} и дуг
- 21. Деревья Одним из важнейших понятий в теории графов является понятие дерева. Деревом называется связный неориентированный граф
- 22. Ориентированный граф без контуров называется корневым деревом, если имеется в точности один узел, называемый корнем, в
- 23. Корневое дерево Корневое дерево Корневое дерево обычно изображают корнем вверх, располагая узлы одной глубины на одном
- 24. Корневое дерево Пусть G - (V,E) — корневое дерево, v,w V. Будем говорить, что узел v
- 25. Двоичные (бинарные) деревья Корневое дерево, каждый узел которого имеет не более двух сыновей, будем называть двоичным
- 26. Двоичные (бинарные) деревья Граф (орграф) будем называть взвешенным, если задана функция с: Е→R, иначе говоря, каждому
- 27. Машинное представление графов и сетей Ориентированный взвешенный граф будем называть сетью. Таким образом, взвешенный граф или
- 28. Машинное представление графов и сетей Разберем несколько способов машинного представления графа (орграфа) G = (V,E), где
- 29. Машинное представление графов и сетей А= Рис 2.3. б) Ориентированный граф и его матрица смежностей Легко
- 30. Машинное представление графов и сетей Однако, для ответа на вопросы «к каким вершинам (узлам) ведут ребра
- 31. Машинное представление графов и сетей Взвешенный граф (или сеть) G = (V,E,c), может быть задан в
- 32. Машинное представление графов и сетей Более экономным, чем матрица смежностей, и универсальным способом является представление графов
- 33. Машинное представление графов и сетей Начало каждого списка хранится в массиве НАЧАЛО, а именно, HAЧAJIO[v] является
- 34. Машинное представление графов и сетей НАЧАЛО Рис 2.3. Неориентированный граф и его списки смежностей.
- 35. Для ориентированных графов возможны два способа формирования списков смежностей. В первом в список ЗАПИСЬ[v] включаются лишь
- 36. Проанализируем способ представления графов и сетей списками смежностей. Понятно, что объем памяти, необходимый для представления графа
- 37. Однако, если определять степень всех вершин графа, то здесь сложность ответа будет O(n+m), так как каждое
- 38. Докажите, что в любом графе число вершин нечетной степени четно. В некоторых задачах удобно представлять граф
- 39. В тех случаях, когда нет необходимости добавлять и удалять ребра или дуги из графа, все списки
- 40. Поскольку каждое ребро графа встречается в таком массиве дважды (и имеет индексы в массиве от А[n+2]
- 41. Пример. Для неориентированного графа 1 2 3 4 массив смежностей должен быть следующим: 6 8 10
- 42. Поясним на примере: Количество вершин n = 4 Количество ребер m = 4 Ниже перечислены для
- 43. Для взвешенного неориентированного графа (25) 1 2 (4) (0) 3 4 (7) массив смежностей должен быть
- 44. Поясним Количество вершин n = 4 Количество ребер m = 4 Ниже перечислены для указанного в
- 45. Вернемся к предложенным на прошлой паре задачам. После решения задачи «Предложите алгоритм, сложности О(n), записывающий все
- 46. Входные данные содержат описание графа, заданного массивом смежности. В первой строке n - число элементов в
- 47. На выходе программа построчно выдает для каждой вершины (начиная с первой и до n-ой) пары вида
- 48. // Библиотеки #include #include #include #include using namespace std; void main() { int n = 0;
- 49. for (int i = 0; i temp_ar_number[i] = -1; } for(int i = 0; i cin
- 50. cout Формирование массива смежности int fict = 1;//фиктивная переменная начало ребра int k; for (int i
- 51. Вывод (печать) массива смежности cout for( int i = 0; i cout k = i+1; if(g[i].second.first
- 52. Формирование массива смежности vector > > g_convert; // обратные списки смежности fict = 1; for (int
- 53. Вывод массива смежности cout for( int i = 0; i cout k = i+1; if( g_convert[i].second.first
- 54. Обучающийся 1) рисует взвешенный граф, 2) «вручную» пишет на листке массив смежности (в прямом и обратном
- 55. Сортировка является неотъемлемой частью многих алгоритмов решения математических задач. Задача сортировки формулируется следующим образом: Дана последовательность
- 56. При формулировании задачи сортировки в общем виде информацию о последовательности элементов можно получать только с помощью
- 57. Алгоритм сортировки выбором Данные: массив А[1..n]. Результат: массив А[1..n] такой, что А[1] ≤ А[2] ≤ ...
- 58. Процедура MIN(i) выбирает минимальный элемент из массива аi,...,аn и ставит его на первое место, т.е. на
- 59. Сортировка выбором имеет вычислительную сложность O(n2). Действительно, в процедуре MIN(i) осуществляется (n-i) операции сравнения и, в
- 60. Приведем теорему, позволяющую оценить снизу сложность любого алгоритма сортировки. В любом алгоритме, упорядочивающем с помощью сравнений,
- 61. Двоичное дерево решений для сортировки трех элементов
- 62. Поскольку, всякое двоичное дерево высоты к имеет не более 2к листьев, то получаем, что должно выполняться
- 63. Алгоритм сортировки, называемый СОРТДЕРЕВО, имеет сложность O(n log n). В разных учебниках он называется: алгоритмом пирамидальной
- 64. Алгоритм СОРТДЕРЕВО Лемма. Двоичное дерево массива длины n имеет высоту Напомним, что высота корневого дерева есть
- 65. Пусть k - высота двоичного дерева массива длины n. Для всех s Тогда справедливо неравенство 1
- 66. Двоичное дерево массива А называется сортирующим деревом массива А, если выполняются условия: А[k] ≥ А[2 k]
- 67. На первом этапе двоичное дерево массива А преобразуется в сортирующее. Процедуру, осуществляющую это преобразование, будем называть
- 68. Перейдем к формальному описанию алгоритма СОРТДЕРЕВО. Начнем с описания процедуры ПСД (построение сортирующего дерева). В его
- 69. Алгоритм СОРТДЕРЕВО АЛГОРИТМ 3.2. СОРТДЕРЕВО Данные: массив элементов А[1..n]. Результат: массив элементов А[1..n], упорядоченный по неубыванию,
- 70. procedure ПСД; begin for i := downto 1 do ПЕРЕСЫПКА(i,n) End Ниже дано формальное описание процедур
- 71. procedure ПЕРЕСЫПКА( i ,j); begin if i ≤ then (* если i — не лист *)
- 72. Разберем пример, иллюстрирующий работу обеих этих процедур Пусть задан числовой массив А[1…10]: I 1 2 3
- 73. Алгоритм СОРТДЕРЕВО
- 74. Алгоритм СОРТДЕРЕВО Изобразим окончательный результат в виде таблицы: I 1 2 3 4 5 6 7
- 75. Алгоритм СОРТДЕРЕВО
- 76. Алгоритм СОРТДЕРЕВО На рис.3.4 дерево f) является сортирующим деревом исходного массива А, полученным в результате работы
- 77. Поиск в графе Поиск в графе Большинство алгоритмов на графах основаны на систематическом переборе всех вершин
- 78. Поиск в глубину Поиск начинается с некоторой фиксированной вершины v, называемой корневой вершиной поиска или корнем.
- 79. Поиск в глубину Тот факт, что в процессе поиска использовано именно ребро {v,w} отмечается обычно следующим
- 80. Поиск в глубину В общем случае, когда мы находимся в некоторой вершине v, возникают две возможности:
- 81. Поиск в глубину 2) Существует еще не просмотренная вершина w, смежная с вершиной v. Тогда ребро
- 82. Поиск в глубину Поиск в глубину завершается тогда, когда все вершины графа будут просмотрены. Здесь возможны
- 83. Поиск в глубину Представим формальное описание изложенного алгоритма поиска в глубину, основанную на рекурсивной процедуре ПВГ(v)
- 84. Поиск в глубину Примечание. Массив МЕТКА, используемый в алгоритме имеет по одному элементу для каждой вершины
- 85. Поиск в глубину На следующем рис. показано, как поиск в глубину исследует неориентированный граф G. Предполагается,
- 86. Поиск в глубину
- 87. Поиск в глубину В просмотренном графе G дуги ПВГ-деревьев обозначены стрелками в соответствии с ориентацией, полученной
- 88. Поиск в глубину Разберем теперь нерекурсивную версию процедуры ПВГ(v). Рекурсия устраняется стандартным способом с помощью стека.
- 89. Поиск в глубину Для организации такого процесса понадобится дополнительно массив указателей УКАЗ длины n, где n=|V|.
- 90. Поиск в глубину procedure ПВГ1(v); (* нерекурсивная версия *) begin СТЕК :=Ø; СТЕК v; METKA[v]:=l; while
- 91. Поиск в глубину Теорема. Сложность алгоритма Поиск в глубину 1 есть O(n+m). Следствие. Связные компоненты неориентированного
- 92. Поиск в глубину Поиск в глубину в ориентированном графе отличается от поиска в неориентированном графе только
- 93. Поиск в ширину Поиск в ширину Другое название этого популярнейшего метода — волновой алгоритм. Причины появления
- 94. Поиск в ширину Затем проходим все ребра {v,w}, инцидентные v, в каком-нибудь порядке и ориентируем их
- 95. Поиск в ширину Дальнейший поиск продолжается следующим образом. Берем очередную вершину v из очереди, проходим по
- 96. Поиск в ширину После этих действий вершина v считается использованной и удаляется из очереди. Говорят также,
- 97. Поиск в ширину На следующем рисунке (2) показано, как поиск в ширину исследует граф G, изображенный
- 98. Поиск в ширину
- 99. Поиск в ширину Отметим, что в ПВШ(1) - дереве поиска вершины 2, 3, 4 образуют первый
- 100. Поиск в ширину Отметим, что в ПВШ(1) – дереве поиска вершины 2, 3, 4 образуют первый
- 101. Поиск в ширину procedure ПВШ(v); (* поиск в ширину с корнем v *) begin ОЧЕРЕДЬ :=Ø;
- 102. Поиск в ширину В приведенном формальном описании алгоритма поиска в ширину переменная МЕТКА имеет тот же
- 103. Поиск в ширину В алгоритме Поиск в ширину 2 связность графа не предполагается. Для корневых вершин
- 104. Цепи и пути в графах Применительно к только связным неориентированным графам нетрудно проверить, что и ПВГ-дерево,
- 105. Цепи и пути в графах Если в ориентированном графе имеется дуга (v,w), то v — отец
- 106. Цепи и пути в графах Теорема 3. Пусть Т — ПВГ-дерево связного неориентированного графа G=(V,E), и
- 107. Цепи и пути в графах Как в ПВГ-дереве, так и в ПВШ-дереве для каждой вершины w,
- 108. Цепи и пути в графах В предлагаемом ниже алгоритме ПостроениеПути3 требуемый путь идентифицируется последовательностью вершин. Предполагается,
- 109. Цепи и пути в графах АЛГОРИТМ ПостроениеПути3. Данные: корневая вершина поиска v, вершина w. массив ОТЕЦ.
- 110. Цепи и пути в графах Понятно, что последовательность вершин v=v0,v1,...,vk=w, полученная считыванием СТЕКА, образует как v-w-путь
- 112. Скачать презентацию

Введение
Примеры дискретных оптимизационных задач
задача о кратчайшем пути:
Пусть имеется
Введение
Примеры дискретных оптимизационных задач
задача о кратчайшем пути:
Пусть имеется

В каждой задаче имеется лишь конечное число вариантов, из которых требуется
В каждой задаче имеется лишь конечное число вариантов, из которых требуется

Типы задач: массовые и индивидуальные задачи.
Все вышеприведенные примеры дают образцы
Типы задач: массовые и индивидуальные задачи.
Все вышеприведенные примеры дают образцы

Говорят, что алгоритм решает некоторую массовую задачу, если он решает любую
Говорят, что алгоритм решает некоторую массовую задачу, если он решает любую

При сравнении скорости роста двух неотрицательных функций f(n) и g(n) будем
При сравнении скорости роста двух неотрицательных функций f(n) и g(n) будем

Например, справедливы следующие соотношения:
log2n = О(n); n2 = О(2n); n
Например, справедливы следующие соотношения:
log2n = О(n); n2 = О(2n); n

Алгоритмы и их сложности
Таблица 1.2. Влияние технического совершенствования ЭВМ на полиномиальные
Алгоритмы и их сложности
Таблица 1.2. Влияние технического совершенствования ЭВМ на полиномиальные

Пусть для решения некоторой задачи имеется алгоритм сложности n3. Тогда, как
Пусть для решения некоторой задачи имеется алгоритм сложности n3. Тогда, как

Алгоритмы будем записывать на некотором специальном языке, который назовем упрощенным Паскалем.
Алгоритмы будем записывать на некотором специальном языке, который назовем упрощенным Паскалем.

АЛГОРИТМ 1.1. ВЫБОР МИНИМАЛЬНОГО ЭЛЕМЕНТА
Данные: числовое множество X.
Результат: число minX -
АЛГОРИТМ 1.1. ВЫБОР МИНИМАЛЬНОГО ЭЛЕМЕНТА
Данные: числовое множество X.
Результат: число minX -

Повсюду в дальнейшем будем использовать следующие обозначения. Для произвольного вещественного числа
Повсюду в дальнейшем будем использовать следующие обозначения. Для произвольного вещественного числа

Графы и сети
Многие задачи дискретной оптимизации могут быть интерпретированы как задачи
Графы и сети
Многие задачи дискретной оптимизации могут быть интерпретированы как задачи

Графы и сети
Рис. 2.1. Изображение графов и орграфов,
а) Неориентированный граф,
Графы и сети
Рис. 2.1. Изображение графов и орграфов,
а) Неориентированный граф,

Удобно вершины графа считать пронумерованными натуральными числами, и на рисунках сразу
Удобно вершины графа считать пронумерованными натуральными числами, и на рисунках сразу

Цепью (соответственно путем) в графе (орграфе)
G = (V,E) назовем чередующуюся
Цепью (соответственно путем) в графе (орграфе)
G = (V,E) назовем чередующуюся

Цепь в графе (соответственно путь), начальная и конечная вершины (узлы) которого
Цепь в графе (соответственно путь), начальная и конечная вершины (узлы) которого

Графы и сети
Графы и сети

Графы и сети
Граф, имеющий ровно одну компоненту связности, будем называть связным.
Графы и сети
Граф, имеющий ровно одну компоненту связности, будем называть связным.

Графы и сети
Условимся считать, что в графах и орграфах
нет ребер
Графы и сети
Условимся считать, что в графах и орграфах
нет ребер

Деревья
Одним из важнейших понятий в теории графов является понятие дерева. Деревом
Деревья
Одним из важнейших понятий в теории графов является понятие дерева. Деревом

Ориентированный граф без контуров называется корневым деревом, если
имеется в точности один
Ориентированный граф без контуров называется корневым деревом, если
имеется в точности один

Корневое дерево
Корневое дерево
Корневое дерево обычно изображают корнем вверх, располагая узлы одной
Корневое дерево
Корневое дерево
Корневое дерево обычно изображают корнем вверх, располагая узлы одной

Корневое дерево
Пусть G - (V,E) — корневое дерево, v,w V.
Будем
Корневое дерево
Пусть G - (V,E) — корневое дерево, v,w V.
Будем

Двоичные (бинарные) деревья
Корневое дерево, каждый узел которого имеет не более двух
Двоичные (бинарные) деревья
Корневое дерево, каждый узел которого имеет не более двух

Двоичные (бинарные) деревья
Граф (орграф) будем называть взвешенным,
если задана функция с:
Двоичные (бинарные) деревья
Граф (орграф) будем называть взвешенным,
если задана функция с:

Машинное представление графов и сетей
Ориентированный взвешенный граф будем
называть сетью.
Машинное представление графов и сетей
Ориентированный взвешенный граф будем
называть сетью.

Машинное представление графов и сетей
Разберем несколько способов машинного представления графа
Машинное представление графов и сетей
Разберем несколько способов машинного представления графа

Машинное представление графов и сетей
А=
Рис 2.3. б) Ориентированный граф и
Машинное представление графов и сетей
А=
Рис 2.3. б) Ориентированный граф и

Машинное представление графов и сетей
Однако, для ответа на вопросы
«к
Машинное представление графов и сетей
Однако, для ответа на вопросы
«к

Машинное представление графов и сетей
Взвешенный граф (или сеть) G =
Машинное представление графов и сетей
Взвешенный граф (или сеть) G =

Машинное представление графов и сетей
Более экономным, чем матрица смежностей, и
Машинное представление графов и сетей
Более экономным, чем матрица смежностей, и

Машинное представление графов и сетей
Начало каждого списка хранится в массиве
Машинное представление графов и сетей
Начало каждого списка хранится в массиве

Машинное представление графов и сетей
НАЧАЛО
Рис 2.3. Неориентированный граф и
Машинное представление графов и сетей
НАЧАЛО
Рис 2.3. Неориентированный граф и

Для ориентированных графов возможны два способа формирования списков смежностей.
В первом
Для ориентированных графов возможны два способа формирования списков смежностей.
В первом

Проанализируем способ представления графов и сетей списками смежностей.
Понятно, что объем памяти,
Проанализируем способ представления графов и сетей списками смежностей.
Понятно, что объем памяти,

Однако, если определять степень всех вершин графа,
то здесь сложность ответа
Однако, если определять степень всех вершин графа,
то здесь сложность ответа

Докажите, что в любом графе число вершин нечетной степени четно.
В некоторых
Докажите, что в любом графе число вершин нечетной степени четно.
В некоторых

В тех случаях, когда нет необходимости добавлять и удалять ребра или
В тех случаях, когда нет необходимости добавлять и удалять ребра или

Поскольку каждое ребро графа встречается в таком массиве дважды (и имеет
Поскольку каждое ребро графа встречается в таком массиве дважды (и имеет

Пример. Для неориентированного графа
1 2
3 4
массив смежностей должен быть следующим:
6 8 10 13
Пример. Для неориентированного графа
1 2
3 4
массив смежностей должен быть следующим:
6 8 10 13

Поясним на примере:
Количество вершин n = 4
Количество ребер m = 4
Ниже
Поясним на примере:
Количество вершин n = 4
Количество ребер m = 4
Ниже

Для взвешенного неориентированного графа
(25)
1 2
(4) (0)
3 4
(7)
Для взвешенного неориентированного графа
(25)
1 2
(4) (0)
3 4
(7)

Поясним
Количество вершин n = 4
Количество ребер m = 4
Ниже перечислены для
Поясним
Количество вершин n = 4
Количество ребер m = 4
Ниже перечислены для

Вернемся к предложенным на прошлой паре задачам.
После решения задачи «Предложите алгоритм,
Вернемся к предложенным на прошлой паре задачам.
После решения задачи «Предложите алгоритм,

Входные данные содержат описание графа,
заданного массивом смежности.
В первой строке n
Входные данные содержат описание графа,
заданного массивом смежности.
В первой строке n

На выходе программа построчно выдает для каждой вершины (начиная с первой
На выходе программа построчно выдает для каждой вершины (начиная с первой

// Библиотеки
#include
#include
#include
#include
using namespace std;
void main() {
int n
// Библиотеки
#include
#include
#include
#include
using namespace std;
void main() {
int n
![for (int i = 0; i temp_ar_number[i] = -1; } for(int](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/598020/slide-48.jpg)
for (int i = 0; i < temp; i++) {
temp_ar_number[i] =
for (int i = 0; i < temp; i++) {
temp_ar_number[i] =

cout << "\n" <<"Количество вершин n = "<< n << "\n";
Формирование
cout << "\n" <<"Количество вершин n = "<< n << "\n";
Формирование

Вывод (печать) массива смежности
cout <<«Список смежности в прямом порядке:\n";
for( int i
Вывод (печать) массива смежности
cout <<«Список смежности в прямом порядке:\n";
for( int i

Формирование массива смежности
vector < pair < int, pair > > g_convert;
Формирование массива смежности
vector < pair < int, pair

Вывод массива смежности
cout <<"\nCписок смежности в обратном порядке:\n";
for( int i =
Вывод массива смежности
cout <<"\nCписок смежности в обратном порядке:\n";
for( int i =

Обучающийся
1) рисует взвешенный граф,
2) «вручную» пишет на листке массив
Обучающийся
1) рисует взвешенный граф,
2) «вручную» пишет на листке массив

Сортировка является неотъемлемой частью многих алгоритмов решения математических задач.
Задача сортировки
Сортировка является неотъемлемой частью многих алгоритмов решения математических задач.
Задача сортировки

При формулировании задачи сортировки в общем виде информацию о последовательности элементов
При формулировании задачи сортировки в общем виде информацию о последовательности элементов
![Алгоритм сортировки выбором Данные: массив А[1..n]. Результат: массив А[1..n] такой, что](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/598020/slide-56.jpg)
Алгоритм сортировки выбором
Данные: массив А[1..n].
Результат:
массив А[1..n] такой, что А[1]
Алгоритм сортировки выбором
Данные: массив А[1..n].
Результат:
массив А[1..n] такой, что А[1]

Процедура MIN(i)
выбирает минимальный элемент из
массива аi,...,аn и ставит его
Процедура MIN(i)
выбирает минимальный элемент из
массива аi,...,аn и ставит его

Сортировка выбором имеет вычислительную сложность O(n2).
Действительно, в процедуре MIN(i) осуществляется (n-i)
Сортировка выбором имеет вычислительную сложность O(n2).
Действительно, в процедуре MIN(i) осуществляется (n-i)

Приведем теорему, позволяющую оценить снизу сложность любого алгоритма сортировки.
В любом алгоритме,
Приведем теорему, позволяющую оценить снизу сложность любого алгоритма сортировки.
В любом алгоритме,

Двоичное дерево решений для сортировки трех элементов
Двоичное дерево решений для сортировки трех элементов

Поскольку, всякое двоичное дерево высоты к имеет не более 2к листьев,
Поскольку, всякое двоичное дерево высоты к имеет не более 2к листьев,

Алгоритм сортировки, называемый СОРТДЕРЕВО, имеет сложность O(n log n).
В разных
Алгоритм сортировки, называемый СОРТДЕРЕВО, имеет сложность O(n log n).
В разных

Алгоритм СОРТДЕРЕВО
Лемма.
Двоичное дерево массива длины n имеет высоту
Напомним, что высота
Алгоритм СОРТДЕРЕВО
Лемма.
Двоичное дерево массива длины n имеет высоту
Напомним, что высота

Пусть k - высота двоичного дерева массива длины n.
Для всех
Пусть k - высота двоичного дерева массива длины n.
Для всех

Двоичное дерево массива А называется сортирующим деревом массива А, если выполняются
Двоичное дерево массива А называется сортирующим деревом массива А, если выполняются

На первом этапе двоичное дерево массива А преобразуется в сортирующее. Процедуру,
На первом этапе двоичное дерево массива А преобразуется в сортирующее. Процедуру,

Перейдем к формальному описанию алгоритма СОРТДЕРЕВО. Начнем с описания процедуры ПСД
Перейдем к формальному описанию алгоритма СОРТДЕРЕВО. Начнем с описания процедуры ПСД
![Алгоритм СОРТДЕРЕВО АЛГОРИТМ 3.2. СОРТДЕРЕВО Данные: массив элементов А[1..n]. Результат: массив](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/598020/slide-68.jpg)
Алгоритм СОРТДЕРЕВО
АЛГОРИТМ 3.2. СОРТДЕРЕВО
Данные: массив элементов А[1..n].
Результат: массив элементов
Алгоритм СОРТДЕРЕВО
АЛГОРИТМ 3.2. СОРТДЕРЕВО
Данные: массив элементов А[1..n].
Результат: массив элементов

procedure ПСД;
begin
for i := downto 1 do ПЕРЕСЫПКА(i,n)
End
Ниже дано формальное описание
procedure ПСД;
begin
for i := downto 1 do ПЕРЕСЫПКА(i,n)
End
Ниже дано формальное описание

procedure ПЕРЕСЫПКА( i ,j);
begin
if i ≤ then (* если i — не
procedure ПЕРЕСЫПКА( i ,j);
begin
if i ≤ then (* если i — не

Разберем пример, иллюстрирующий работу обеих этих процедур
Пусть задан числовой массив А[1…10]:
I 1 2 3 4 5 6 7 8 9 10
А[I] 2 3 6 1 4 5 8 0 7 9
Алгоритм
Разберем пример, иллюстрирующий работу обеих этих процедур
Пусть задан числовой массив А[1…10]:
I 1 2 3 4 5 6 7 8 9 10
А[I] 2 3 6 1 4 5 8 0 7 9
Алгоритм

Алгоритм СОРТДЕРЕВО
Алгоритм СОРТДЕРЕВО

Алгоритм СОРТДЕРЕВО
Изобразим окончательный результат в виде таблицы:
I 1 2 3 4 5 6 7 8 9 10
A[I] 9 7 8 2 4 5 6 0 1 3
Алгоритм СОРТДЕРЕВО
Изобразим окончательный результат в виде таблицы:
I 1 2 3 4 5 6 7 8 9 10
A[I] 9 7 8 2 4 5 6 0 1 3

Алгоритм СОРТДЕРЕВО
Алгоритм СОРТДЕРЕВО

Алгоритм СОРТДЕРЕВО
На рис.3.4 дерево f) является сортирующим деревом исходного массива
Алгоритм СОРТДЕРЕВО
На рис.3.4 дерево f) является сортирующим деревом исходного массива

Поиск в графе
Поиск в графе
Большинство алгоритмов на графах основаны на систематическом
Поиск в графе
Поиск в графе
Большинство алгоритмов на графах основаны на систематическом

Поиск в глубину
Поиск начинается с некоторой фиксированной вершины v, называемой
Поиск в глубину
Поиск начинается с некоторой фиксированной вершины v, называемой

Поиск в глубину
Тот факт, что в процессе поиска использовано именно
Поиск в глубину
Тот факт, что в процессе поиска использовано именно

Поиск в глубину
В общем случае, когда мы находимся в некоторой
Поиск в глубину
В общем случае, когда мы находимся в некоторой

Поиск в глубину
2) Существует еще не просмотренная вершина w, смежная
Поиск в глубину
2) Существует еще не просмотренная вершина w, смежная

Поиск в глубину
Поиск в глубину завершается тогда, когда все вершины
Поиск в глубину
Поиск в глубину завершается тогда, когда все вершины

Поиск в глубину
Представим формальное описание изложенного алгоритма поиска в глубину,
Поиск в глубину
Представим формальное описание изложенного алгоритма поиска в глубину,

Поиск в глубину
Примечание.
Массив МЕТКА, используемый в алгоритме имеет по одному
Поиск в глубину
Примечание.
Массив МЕТКА, используемый в алгоритме имеет по одному

Поиск в глубину
На следующем рис. показано,
как поиск в глубину
Поиск в глубину
На следующем рис. показано,
как поиск в глубину

Поиск в глубину
Поиск в глубину

Поиск в глубину
В просмотренном графе G дуги
ПВГ-деревьев обозначены стрелками
Поиск в глубину
В просмотренном графе G дуги
ПВГ-деревьев обозначены стрелками

Поиск в глубину
Разберем теперь нерекурсивную версию процедуры ПВГ(v).
Рекурсия устраняется
Поиск в глубину
Разберем теперь нерекурсивную версию процедуры ПВГ(v).
Рекурсия устраняется

Поиск в глубину
Для организации такого процесса понадобится дополнительно массив указателей
Поиск в глубину
Для организации такого процесса понадобится дополнительно массив указателей

Поиск в глубину
procedure ПВГ1(v); (* нерекурсивная версия *)
begin
СТЕК :=Ø; СТЕК
Поиск в глубину
procedure ПВГ1(v); (* нерекурсивная версия *)
begin
СТЕК :=Ø; СТЕК

Поиск в глубину
Теорема.
Сложность алгоритма
Поиск в глубину 1 есть
Поиск в глубину
Теорема.
Сложность алгоритма
Поиск в глубину 1 есть

Поиск в глубину
Поиск в глубину в ориентированном графе отличается от
Поиск в глубину
Поиск в глубину в ориентированном графе отличается от

Поиск в ширину
Поиск в ширину
Другое название этого популярнейшего метода
Поиск в ширину
Поиск в ширину
Другое название этого популярнейшего метода

Поиск в ширину
Затем проходим все ребра {v,w}, инцидентные v, в
Поиск в ширину
Затем проходим все ребра {v,w}, инцидентные v, в

Поиск в ширину
Дальнейший поиск продолжается следующим образом. Берем очередную вершину
Поиск в ширину
Дальнейший поиск продолжается следующим образом. Берем очередную вершину

Поиск в ширину
После этих действий вершина v считается использованной и
Поиск в ширину
После этих действий вершина v считается использованной и

Поиск в ширину
На следующем рисунке (2) показано, как поиск в
Поиск в ширину
На следующем рисунке (2) показано, как поиск в

Поиск в ширину
Поиск в ширину

Поиск в ширину
Отметим, что в ПВШ(1) - дереве поиска вершины
Поиск в ширину
Отметим, что в ПВШ(1) - дереве поиска вершины

Поиск в ширину
Отметим, что в ПВШ(1) –
дереве поиска вершины
Поиск в ширину
Отметим, что в ПВШ(1) –
дереве поиска вершины

Поиск в ширину
procedure ПВШ(v); (* поиск в ширину с корнем v
Поиск в ширину
procedure ПВШ(v); (* поиск в ширину с корнем v

Поиск в ширину
В приведенном формальном описании алгоритма поиска в ширину
Поиск в ширину
В приведенном формальном описании алгоритма поиска в ширину

Поиск в ширину
В алгоритме Поиск в ширину 2 связность графа
Поиск в ширину
В алгоритме Поиск в ширину 2 связность графа

Цепи и пути в графах
Применительно к только связным неориентированным графам
Цепи и пути в графах
Применительно к только связным неориентированным графам

Цепи и пути в графах
Если в ориентированном графе имеется дуга
Цепи и пути в графах
Если в ориентированном графе имеется дуга

Цепи и пути в графах
Теорема 3. Пусть Т — ПВГ-дерево
Цепи и пути в графах
Теорема 3. Пусть Т — ПВГ-дерево

Цепи и пути в графах
Как в ПВГ-дереве, так и в
Цепи и пути в графах
Как в ПВГ-дереве, так и в

Цепи и пути в графах
В предлагаемом ниже алгоритме ПостроениеПути3 требуемый
Цепи и пути в графах
В предлагаемом ниже алгоритме ПостроениеПути3 требуемый

Цепи и пути в графах
АЛГОРИТМ ПостроениеПути3.
Данные: корневая вершина поиска
Цепи и пути в графах
АЛГОРИТМ ПостроениеПути3.
Данные: корневая вершина поиска

Цепи и пути в графах
Понятно, что последовательность вершин v=v0,v1,...,vk=w, полученная
Цепи и пути в графах
Понятно, что последовательность вершин v=v0,v1,...,vk=w, полученная
 Логические элементы
Логические элементы  Задачи на сравнение предметов
Задачи на сравнение предметов Мера центральной тенденции
Мера центральной тенденции Математика
Математика Решение задач типа В10 МАОУ СОШ №3 г. Железнодорожный Автор: Гренкова Анна Александровна
Решение задач типа В10 МАОУ СОШ №3 г. Железнодорожный Автор: Гренкова Анна Александровна Физминутка в картинках
Физминутка в картинках Элементы математической логики. Интегральное исчисление функций одной переменной и его приложения
Элементы математической логики. Интегральное исчисление функций одной переменной и его приложения Усеченное гауссово моделирование. Методы моделирования дискретных свойств в Petrel
Усеченное гауссово моделирование. Методы моделирования дискретных свойств в Petrel Квадратные матрицы. Определители
Квадратные матрицы. Определители Геометрия сызымнарда (7 класс)
Геометрия сызымнарда (7 класс) Урок математики в 4 классе Тема: «Среднее арифметическое» Автор: учитель начальных классов ГБОУ ЦО №1456 Аксенова Ольга Борисовна
Урок математики в 4 классе Тема: «Среднее арифметическое» Автор: учитель начальных классов ГБОУ ЦО №1456 Аксенова Ольга Борисовна Модели временных рядов. (Лекция 7)
Модели временных рядов. (Лекция 7) Задания на повторение курса алгебры 9 класс
Задания на повторение курса алгебры 9 класс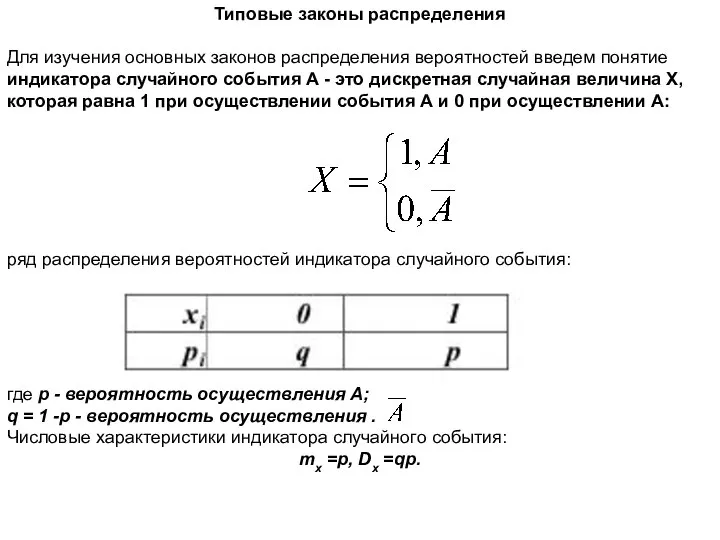 Типовые законы распределения
Типовые законы распределения ЗОЛОТОЕ СЕЧЕНИЕ Сергеев Никита 10A
ЗОЛОТОЕ СЕЧЕНИЕ Сергеев Никита 10A  Практическое применение интегралов в различных областях
Практическое применение интегралов в различных областях Элементы математической статистики
Элементы математической статистики  Закон больших чисел
Закон больших чисел Как измерить рост жирафа. Занимательная геометрия
Как измерить рост жирафа. Занимательная геометрия Виды треугольников
Виды треугольников Игра "Поле чудес" геометрия
Игра "Поле чудес" геометрия Арккосинус и решение уравнения cost=а
Арккосинус и решение уравнения cost=а Конструирование компетентностно-ориентированных заданий по математике
Конструирование компетентностно-ориентированных заданий по математике 20161108_urok_46_treugolniki._vidy_treugolnikov
20161108_urok_46_treugolniki._vidy_treugolnikov Презентация по математике "Свойства функций и их графики" - скачать бесплатно
Презентация по математике "Свойства функций и их графики" - скачать бесплатно Трапеция
Трапеция Аналитический метод отыскания точки минимума функции двух переменных
Аналитический метод отыскания точки минимума функции двух переменных Модуль числа. Противоположные числа
Модуль числа. Противоположные числа