- OSNOVY_MATEMATIChESKOJ_STATISTIKI_1

Содержание
- 2. Задачи математической статистики Первая задача математической статистики - указать способы сбора и группировки статистических сведений, полученных
- 3. Генеральная и выборочная совокупности Выборочной совокупностью или просто выборкой называют совокупность случайно отобранных объектов. Генеральной совокупностью
- 4. Эмпирическая функция распределения Эмпирической функцией распределения (функцией распределения выборки) называют функцию , определяющую для каждого значения
- 5. ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ Будем называть выборочной статистикой любую величину, полученную в результате обработки данных эксперимента. Любая
- 6. ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ Определение. Оценка параметра x называется состоятельной, если при увеличении объема выборки n для
- 7. ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ Медианой mе называют варианту, которая делит вариационный ряд на две части, равные по
- 8. ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ Оценкой асимметрии теоретического распределения является ее выборочное значение: Оценкой теоретического эксцесса является его
- 9. ИНТЕРВАЛЬНОЕ ОЦЕНИВАНИЕ Доверительным интервалом для параметра θ называется интервал (θ 1 ,θ 2 ), накрывающий истинное
- 10. ИНТЕРВАЛЬНОЕ ОЦЕНИВАНИЕ Пусть γ = 1 - α - заданная доверительная вероятность, а и - квантили
- 11. Распределение некоторых статистик для НСВ Х ~ N(m,σ) 2. Выборочная дисперсия связана со случайной величиной соотношением:
- 12. Доверительный интервал для среднего при известной σ Пусть - выборка n наблюдений случайной величины X ~
- 13. Доверительный интервал для дисперсии В качестве оценки дисперсии используют выборочную дисперсию . Статистика имеет распределение χ2(n-1)
- 14. ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ Статистической гипотезой Н называется предположение относительно параметров или вида распределения случайной величины Х.
- 15. ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ Пусть V – множество значений статистики Z, а Vk – такое подмножество, что
- 16. ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ Уровень значимости α определяет размер критической области Vk. Положение критической области на множестве
- 17. ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ Если альтернативная гипотеза Н1: θ ≠ θ0, критическая область размещается на обоих хвостах
- 18. Сравнение двух дисперсий нормальных генеральных совокупностей При заданном уровне значимости α по двум выборкам объемов n1
- 19. Сравнение выборочной дисперсии с гипотетической генеральной дисперсией нормальной совокупности При заданном уровне значимости α по выборке
- 20. Сравнение двух средних генеральных совокупностей, дисперсии которых известны При заданном уровне значимости α по двум выборкам
- 21. КРИТЕРИЙ СОГЛАСИЯ ПИРСОНА Пусть по выборке случайной величины Х объема n необходимо проверить гипотезу Н0 о
- 22. КРИТЕРИЙ СОГЛАСИЯ ПИРСОНА Законы распределения: а) равномерный; б) экспоненциальный; в) нормальный
- 23. КРИТЕРИЙ СОГЛАСИЯ ПИРСОНА Гипотеза Н0 согласуется с результатами наблюдений на уровне значимости α, если , где
- 24. КРИТЕРИЙ СОГЛАСИЯ ПИРСОНА б) для нормального закона , где , - плотность нормального нормированного распределения; в)
- 25. МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ Пусть есть результаты некоторого эксперимента (xi,yi), i = 1, ... , n. Надо
- 26. МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ Введем обозначения: Тогда - вектор “подогнанных” с помощью регрессионного уравнения значений у, лежащий
- 27. МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ Условие ортогональности вектора к плоскости векторов и : . После преобразований: . Это
- 28. МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ В соответствии с теоремой Гаусса-Маркова оценки a* ~ N(a, σa), b* ~ N(b,
- 29. МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ Доверительный интервал для коэффициента а с надежностью γ имеет вид: . Коэффициентом детерминации
- 30. МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ Рассматривается следующее уравнение модели: y=β0+β1x+β2x2+...+βkxk+ε, где - вектор коэффициентов модели, х1 , х2
- 31. МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ Для оценки коэффициентов множественной регрессии необходимо использовать формулу, совпадающую со случаем парной регрессии:
- 32. МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ Для проверки значимости коэффициентов регрессии βi можно использовать гипотезу H0: βi = 0
- 33. "ПОДГОНКА" КРИВОЙ Пусть данные некоторого эксперимента представлены в виде таблицы значений переменных x и y. Ставится
- 34. "ПОДГОНКА" КРИВОЙ Используя необходимые условия экстремума функции нескольких переменных, получаем систему уравнений для определения параметров .
- 35. "ПОДГОНКА" КРИВОЙ Числа k и b определяются по встроенной функции ЛИНЕЙН, где вместо xi и yi
- 36. "ПОДГОНКА" КРИВОЙ
- 38. Скачать презентацию

Задачи математической статистики
Первая задача математической статистики - указать способы сбора и
Задачи математической статистики
Первая задача математической статистики - указать способы сбора и

Генеральная и выборочная совокупности
Выборочной совокупностью или просто выборкой называют совокупность случайно
Генеральная и выборочная совокупности
Выборочной совокупностью или просто выборкой называют совокупность случайно

Эмпирическая функция распределения
Эмпирической функцией распределения (функцией распределения выборки) называют функцию ,
Эмпирическая функция распределения
Эмпирической функцией распределения (функцией распределения выборки) называют функцию ,

ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ
Будем называть выборочной статистикой любую величину, полученную в результате
ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ
Будем называть выборочной статистикой любую величину, полученную в результате

ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ
Определение. Оценка параметра x называется состоятельной, если при увеличении
ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ
Определение. Оценка параметра x называется состоятельной, если при увеличении

ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ
Медианой mе называют варианту, которая делит вариационный ряд на
ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ
Медианой mе называют варианту, которая делит вариационный ряд на

ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ
Оценкой асимметрии теоретического распределения
является ее выборочное значение:
Оценкой теоретического эксцесса
ОЦЕНКА ПАРАМЕТРОВ РАСПРЕДЕЛЕНИЯ
Оценкой асимметрии теоретического распределения
является ее выборочное значение:
Оценкой теоретического эксцесса

ИНТЕРВАЛЬНОЕ ОЦЕНИВАНИЕ
Доверительным интервалом для параметра θ называется интервал
(θ 1 ,θ
ИНТЕРВАЛЬНОЕ ОЦЕНИВАНИЕ
Доверительным интервалом для параметра θ называется интервал
(θ 1 ,θ

ИНТЕРВАЛЬНОЕ ОЦЕНИВАНИЕ
Пусть γ = 1 - α - заданная доверительная вероятность,
ИНТЕРВАЛЬНОЕ ОЦЕНИВАНИЕ
Пусть γ = 1 - α - заданная доверительная вероятность,

Распределение некоторых статистик для НСВ Х ~ N(m,σ)
2. Выборочная дисперсия связана
Распределение некоторых статистик для НСВ Х ~ N(m,σ)
2. Выборочная дисперсия связана

Доверительный интервал для среднего при известной σ
Пусть - выборка n наблюдений
Доверительный интервал для среднего при известной σ
Пусть - выборка n наблюдений

Доверительный интервал для дисперсии
В качестве оценки дисперсии используют выборочную дисперсию
.
Доверительный интервал для дисперсии
В качестве оценки дисперсии используют выборочную дисперсию
.

ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ
Статистической гипотезой Н называется предположение относительно параметров или вида
ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ
Статистической гипотезой Н называется предположение относительно параметров или вида

ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ
Пусть V – множество значений статистики Z, а Vk
ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ
Пусть V – множество значений статистики Z, а Vk

ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ
Уровень значимости α определяет размер критической области Vk. Положение
ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ
Уровень значимости α определяет размер критической области Vk. Положение

ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ
Если альтернативная гипотеза
Н1: θ ≠ θ0, критическая область размещается
ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ
Если альтернативная гипотеза Н1: θ ≠ θ0, критическая область размещается

Сравнение двух дисперсий нормальных генеральных совокупностей
При заданном уровне значимости α по
Сравнение двух дисперсий нормальных генеральных совокупностей
При заданном уровне значимости α по

Сравнение выборочной дисперсии с гипотетической генеральной дисперсией нормальной совокупности
При заданном уровне
Сравнение выборочной дисперсии с гипотетической генеральной дисперсией нормальной совокупности
При заданном уровне

Сравнение двух средних генеральных совокупностей, дисперсии которых известны
При заданном уровне значимости
Сравнение двух средних генеральных совокупностей, дисперсии которых известны
При заданном уровне значимости

КРИТЕРИЙ СОГЛАСИЯ ПИРСОНА
Пусть по выборке случайной величины Х объема n необходимо
КРИТЕРИЙ СОГЛАСИЯ ПИРСОНА
Пусть по выборке случайной величины Х объема n необходимо
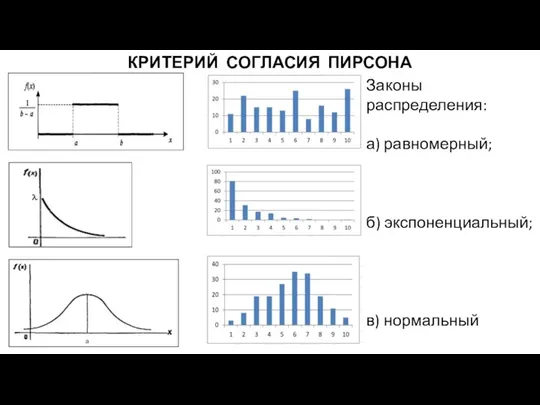
КРИТЕРИЙ СОГЛАСИЯ ПИРСОНА
Законы распределения:
а) равномерный;
б) экспоненциальный;
в) нормальный
КРИТЕРИЙ СОГЛАСИЯ ПИРСОНА
Законы распределения:
а) равномерный;
б) экспоненциальный;
в) нормальный

КРИТЕРИЙ СОГЛАСИЯ ПИРСОНА
Гипотеза Н0 согласуется с результатами наблюдений на уровне значимости
КРИТЕРИЙ СОГЛАСИЯ ПИРСОНА
Гипотеза Н0 согласуется с результатами наблюдений на уровне значимости

КРИТЕРИЙ СОГЛАСИЯ ПИРСОНА
б) для нормального закона , где ,
- плотность
КРИТЕРИЙ СОГЛАСИЯ ПИРСОНА
б) для нормального закона , где ,
- плотность

МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ
Пусть есть результаты некоторого эксперимента (xi,yi), i = 1,
МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ
Пусть есть результаты некоторого эксперимента (xi,yi), i = 1,

МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ
Введем обозначения:
Тогда - вектор “подогнанных” с помощью регрессионного
МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ
Введем обозначения:
Тогда - вектор “подогнанных” с помощью регрессионного

МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ
Условие ортогональности вектора к плоскости векторов и :
.
МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ
Условие ортогональности вектора к плоскости векторов и :
.

МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ
В соответствии с теоремой Гаусса-Маркова оценки a* ~ N(a,
МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ
В соответствии с теоремой Гаусса-Маркова оценки a* ~ N(a,

МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ
Доверительный интервал для коэффициента а с надежностью γ имеет
МОДЕЛЬ ПАРНОЙ РЕГРЕССИИ
Доверительный интервал для коэффициента а с надежностью γ имеет

МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ
Рассматривается следующее уравнение модели: y=β0+β1x+β2x2+...+βkxk+ε,
где - вектор коэффициентов модели,
МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ
Рассматривается следующее уравнение модели: y=β0+β1x+β2x2+...+βkxk+ε,
где - вектор коэффициентов модели,

МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ
Для оценки коэффициентов множественной регрессии необходимо использовать формулу, совпадающую
МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ
Для оценки коэффициентов множественной регрессии необходимо использовать формулу, совпадающую

МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ
Для проверки значимости коэффициентов регрессии βi можно использовать гипотезу
МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ
Для проверки значимости коэффициентов регрессии βi можно использовать гипотезу

"ПОДГОНКА" КРИВОЙ
Пусть данные некоторого эксперимента представлены в виде таблицы значений переменных
"ПОДГОНКА" КРИВОЙ
Пусть данные некоторого эксперимента представлены в виде таблицы значений переменных

"ПОДГОНКА" КРИВОЙ
Используя необходимые условия экстремума функции нескольких переменных, получаем систему уравнений
"ПОДГОНКА" КРИВОЙ
Используя необходимые условия экстремума функции нескольких переменных, получаем систему уравнений

"ПОДГОНКА" КРИВОЙ
Числа k и b определяются по встроенной функции ЛИНЕЙН, где
"ПОДГОНКА" КРИВОЙ
Числа k и b определяются по встроенной функции ЛИНЕЙН, где

"ПОДГОНКА" КРИВОЙ
"ПОДГОНКА" КРИВОЙ
 Теория вероятностей. ЕГЭ (задание №4.)
Теория вероятностей. ЕГЭ (задание №4.) Комбинация шара с геометрическими телами
Комбинация шара с геометрическими телами Позиция 7 ЕГЭ 2016. Физический смысл производной
Позиция 7 ЕГЭ 2016. Физический смысл производной Решение задач (В4). Подготовка к ЕГЭ
Решение задач (В4). Подготовка к ЕГЭ Комбинаторные задачи о числах
Комбинаторные задачи о числах Рациональные выражения. Урок 1-2
Рациональные выражения. Урок 1-2 Степенная функция
Степенная функция Признаки деления на 3, на 9
Признаки деления на 3, на 9 Занимательная математика. Игра
Занимательная математика. Игра Скрещивающиеся прямые
Скрещивающиеся прямые Independent samples using the test statistic
Independent samples using the test statistic Проценты. Устный математический диктант
Проценты. Устный математический диктант Деление двузначного числа на однозначное. Урок математики в 3 классе
Деление двузначного числа на однозначное. Урок математики в 3 классе Знакомство с геометрическими фигурами. Круг
Знакомство с геометрическими фигурами. Круг Занимательная математика. Устный счёт- гимнастика ума
Занимательная математика. Устный счёт- гимнастика ума Решение иррациональных неравенств
Решение иррациональных неравенств Основные виды уравнений высших степеней
Основные виды уравнений высших степеней Аттестационная работа. Разработка урока «Решение задач на применение второго признака равенства треугольников» 7 класс
Аттестационная работа. Разработка урока «Решение задач на применение второго признака равенства треугольников» 7 класс ეკონომიკისა და ბიზნესის სტატისტიკა. სტატისტიკის კურსის შესავალი მონაცემთა წარმოდგენის ხერხე
ეკონომიკისა და ბიზნესის სტატისტიკა. სტატისტიკის კურსის შესავალი მონაცემთა წარმოდგენის ხერხე Признаки равенства треугольников
Признаки равенства треугольников Тема: Сложение натуральных чисел и его свойства Гущина Ирина Николаевна учитель математики и информатики
Тема: Сложение натуральных чисел и его свойства Гущина Ирина Николаевна учитель математики и информатики Вероятность и статистика на ЕГЭ
Вероятность и статистика на ЕГЭ Окружность. Примеры решения задач. Подготовка к ОГЭ
Окружность. Примеры решения задач. Подготовка к ОГЭ Тригонометрические функции
Тригонометрические функции Сумма углов треугольника
Сумма углов треугольника Разработка урока математики в 6-ом классе учителя МОУ «СОШ №21» Володкиной Елены Владимировны
Разработка урока математики в 6-ом классе учителя МОУ «СОШ №21» Володкиной Елены Владимировны Тест. Признаки подобия треугольников
Тест. Признаки подобия треугольников Узнаем, как начертить угол, какие могут быть углы, научимся строить углы
Узнаем, как начертить угол, какие могут быть углы, научимся строить углы