- Статистическая обработка данных

Содержание
- 2. "Статистика знает всё" известно, сколько какой пищи съедает в год средний гражданин республики: известно, сколько в
- 3. Статистическая обработка данных. Ребята, мы переходим к изучению нового раздела, связанного с вопросами обработки данных различных
- 4. Статистическая обработка данных. Давайте рассмотрим какой-нибудь пример, где нам может пригодиться обработка информации. Пусть у нас
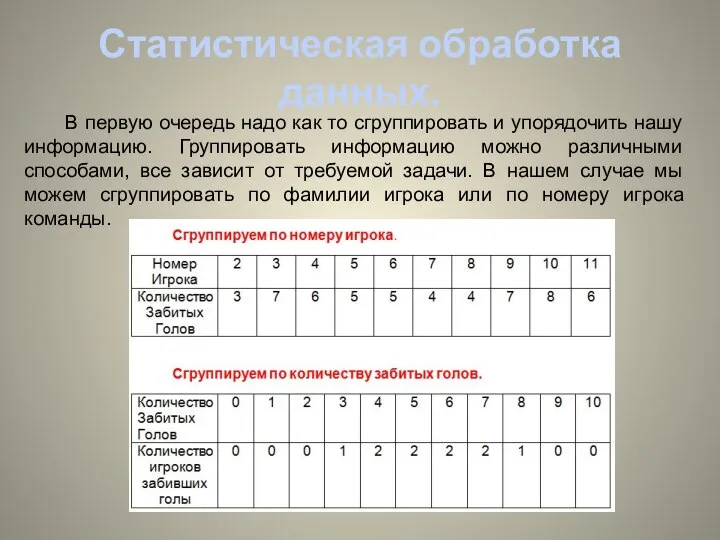
- 5. Статистическая обработка данных. В первую очередь надо как то сгруппировать и упорядочить нашу информацию. Группировать информацию
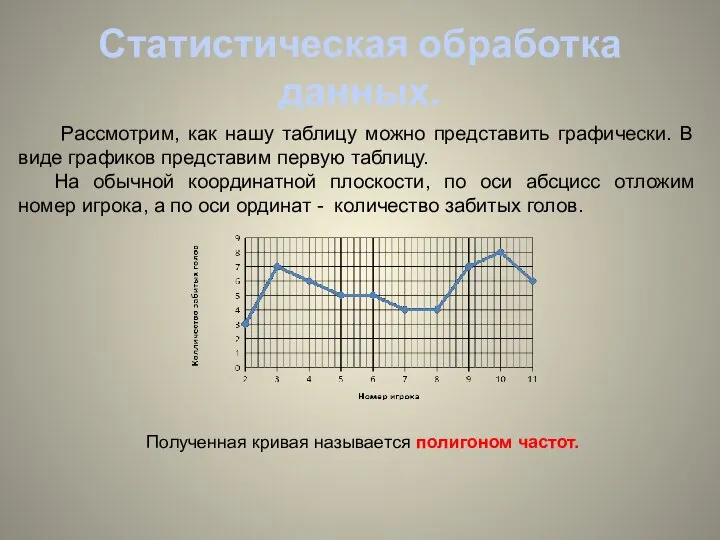
- 6. Статистическая обработка данных. Рассмотрим, как нашу таблицу можно представить графически. В виде графиков представим первую таблицу.
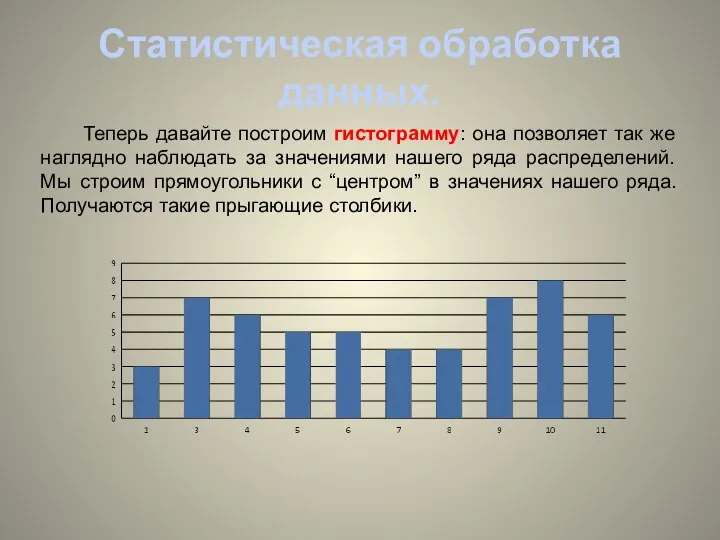
- 7. Статистическая обработка данных. Теперь давайте построим гистограмму: она позволяет так же наглядно наблюдать за значениями нашего
- 8. Статистическая обработка данных. Нам осталось построить еще один тип диаграммы – круговую диаграмму. Представим, что наш
- 9. Статистическая обработка данных. Ну вот, мы с вами научились немного обрабатывать данные. Давайте напишем небольшой алгоритм
- 10. Статистическая обработка данных. Но на этом обработка информации не заканчивается, для нашего ряда распределения можно найти
- 11. Статистическая обработка данных. Среднее значение выборки (Хср). Суммируя все результаты и поделив на объем выборки можно
- 12. Статистическая обработка данных. Варианта измерения – каждое число встретившиеся в результате измерения. В нашем случае для
- 13. Статистическая обработка данных. При составлении таблицы, не всегда получается, что варианты расположены через равные промежутки. Варианта
- 14. Статистическая обработка данных. Частота варианты– числовая характеристика, показывающая часть или долю которую составляет варианта от всей
- 15. Статистическая обработка данных. Вернемся к среднему значению, данная числовая характеристика часто является очень полезной. Но не
- 16. Статистическая обработка данных. Одной из наиболее распространённых характеристик выборки значений случайной величины, чьё распределение по вероятностям
- 17. Статистическая обработка данных. Рассмотрим на примере вычисление математического ожидания: Применим формулу вычисления математического ожидания М =
- 18. Статистическая обработка данных. Еще одна важная числовая характеристика – Дисперсия, или разброс значений вокруг среднего значения.
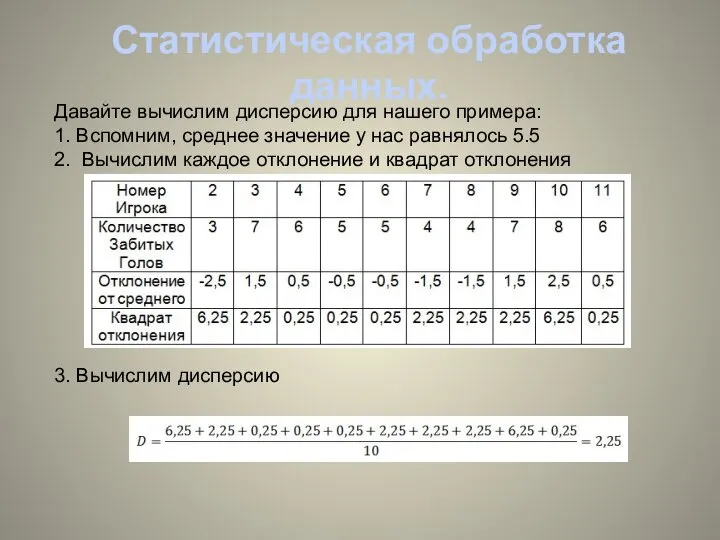
- 19. Статистическая обработка данных. Давайте вычислим дисперсию для нашего примера: 1. Вспомним, среднее значение у нас равнялось
- 20. Статистическая обработка данных. Методы математической статистики позволяют обрабатывать практически любые данные, главное подходить к обработке данных
- 22. Скачать презентацию

"Статистика знает всё" известно, сколько какой пищи съедает в год средний
"Статистика знает всё" известно, сколько какой пищи съедает в год средний

Статистическая обработка данных.
Ребята, мы переходим к изучению нового раздела, связанного с
Статистическая обработка данных.
Ребята, мы переходим к изучению нового раздела, связанного с

Статистическая обработка данных.
Давайте рассмотрим какой-нибудь пример, где нам может пригодиться обработка
Статистическая обработка данных.
Давайте рассмотрим какой-нибудь пример, где нам может пригодиться обработка
Статистическая обработка данных.
В первую очередь надо как то сгруппировать
Статистическая обработка данных.
В первую очередь надо как то сгруппировать
Статистическая обработка данных.
Рассмотрим, как нашу таблицу можно представить графически. В
Статистическая обработка данных.
Рассмотрим, как нашу таблицу можно представить графически. В
Статистическая обработка данных.
Теперь давайте построим гистограмму: она позволяет так же
Статистическая обработка данных.
Теперь давайте построим гистограмму: она позволяет так же

Статистическая обработка данных.
Нам осталось построить еще один тип диаграммы –
Статистическая обработка данных.
Нам осталось построить еще один тип диаграммы –

Статистическая обработка данных.
Ну вот, мы с вами научились немного обрабатывать данные.
Статистическая обработка данных.
Ну вот, мы с вами научились немного обрабатывать данные.

Статистическая обработка данных.
Но на этом обработка информации не заканчивается, для нашего
Статистическая обработка данных.
Но на этом обработка информации не заканчивается, для нашего

Статистическая обработка данных.
Среднее значение выборки (Хср). Суммируя все результаты и
Статистическая обработка данных.
Среднее значение выборки (Хср). Суммируя все результаты и

Статистическая обработка данных.
Варианта измерения – каждое число встретившиеся в результате измерения.
Статистическая обработка данных.
Варианта измерения – каждое число встретившиеся в результате измерения.

Статистическая обработка данных.
При составлении таблицы, не всегда получается, что варианты расположены
Статистическая обработка данных.
При составлении таблицы, не всегда получается, что варианты расположены

Статистическая обработка данных.
Частота варианты– числовая характеристика, показывающая часть или долю которую
Статистическая обработка данных.
Частота варианты– числовая характеристика, показывающая часть или долю которую

Статистическая обработка данных.
Вернемся к среднему значению, данная числовая характеристика часто является
Статистическая обработка данных.
Вернемся к среднему значению, данная числовая характеристика часто является

Статистическая обработка данных.
Одной из наиболее распространённых характеристик выборки значений случайной величины,
Статистическая обработка данных.
Одной из наиболее распространённых характеристик выборки значений случайной величины,

Статистическая обработка данных.
Рассмотрим на примере вычисление математического ожидания:
Применим формулу вычисления математического
Статистическая обработка данных.
Рассмотрим на примере вычисление математического ожидания:
Применим формулу вычисления математического

Статистическая обработка данных.
Еще одна важная числовая характеристика – Дисперсия, или разброс
Статистическая обработка данных.
Еще одна важная числовая характеристика – Дисперсия, или разброс
Статистическая обработка данных.
Давайте вычислим дисперсию для нашего примера:
1. Вспомним, среднее значение
Статистическая обработка данных.
Давайте вычислим дисперсию для нашего примера:
1. Вспомним, среднее значение

Статистическая обработка данных.
Методы математической статистики позволяют обрабатывать практически любые данные, главное
Статистическая обработка данных.
Методы математической статистики позволяют обрабатывать практически любые данные, главное
 Многоликая парабола
Многоликая парабола Применение математических методов в профессиональной деятельности
Применение математических методов в профессиональной деятельности Теорема Пифагора
Теорема Пифагора Деление десятичной дроби на десятичную дробь
Деление десятичной дроби на десятичную дробь Решение систем неравенств с одной переменной
Решение систем неравенств с одной переменной Сопровождение исследовательской деятельности обучающихся как условие реализации ФГОС
Сопровождение исследовательской деятельности обучающихся как условие реализации ФГОС Презентация на тему Векторы (повторение)
Презентация на тему Векторы (повторение)  Решение задач. Урок математики в 5 классе
Решение задач. Урок математики в 5 классе Рациональные числа
Рациональные числа Проверка и оценка знаний таблицы умножения и деления
Проверка и оценка знаний таблицы умножения и деления Задачи на смеси, сплавы и растворы
Задачи на смеси, сплавы и растворы Параллельность прямых и плоскостей. Задания для устного счета. Упражнение 2
Параллельность прямых и плоскостей. Задания для устного счета. Упражнение 2 Теория вероятности
Теория вероятности Объем прямой призмы
Объем прямой призмы Элективный курс. Алгебра 11 класс
Элективный курс. Алгебра 11 класс Длина окружности. Площадь круга. 6 класс
Длина окружности. Площадь круга. 6 класс Как научиться быстро считать без калькулятора
Как научиться быстро считать без калькулятора Презентация по математике "Леонтий Филиппович Магницкий" - скачать
Презентация по математике "Леонтий Филиппович Магницкий" - скачать  Устный счет 3 класс Составила учитель Начальных классов Земзюлина Лариса Владимировна Песчанская СОШ № 2
Устный счет 3 класс Составила учитель Начальных классов Земзюлина Лариса Владимировна Песчанская СОШ № 2  Формализм задачи линейной оптимизации на примере транспортной задачи
Формализм задачи линейной оптимизации на примере транспортной задачи Тела вращения: цилиндр, конус, шар (сфера)
Тела вращения: цилиндр, конус, шар (сфера) Показательные уравнения и неравенства
Показательные уравнения и неравенства Экскурсия в царство всех наук
Экскурсия в царство всех наук Математика в стихах А приходилось вам урок в стихах прожить, Где математика как сказка внеземная?.. Вы много повидали и
Математика в стихах А приходилось вам урок в стихах прожить, Где математика как сказка внеземная?.. Вы много повидали и  Методы интегрирования. (Семинар 14)
Методы интегрирования. (Семинар 14) Тест. Задания В6, ЕГЭ по математике
Тест. Задания В6, ЕГЭ по математике Начальные геометрические сведения. (7 класс)
Начальные геометрические сведения. (7 класс) Задачи на доказательство № 25 из ОГЭ (геометрия)
Задачи на доказательство № 25 из ОГЭ (геометрия)