- Основы цифровой схемотехники

Содержание
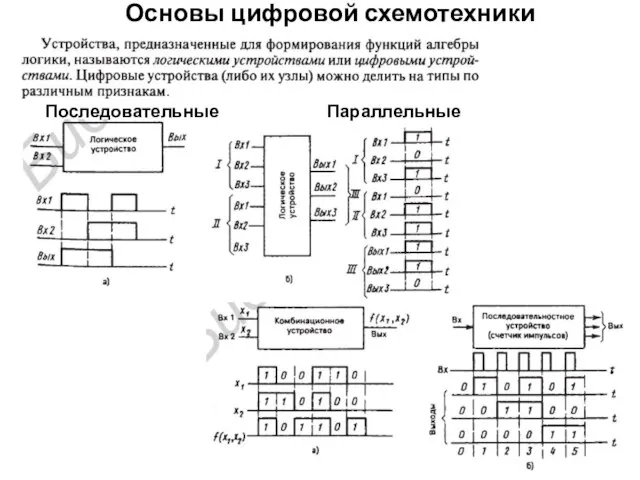
- 2. Основы цифровой схемотехники Последовательные Параллельные
- 3. Логические элементы Синтез КУ в базисе ИЛИ_НЕ и И-НЕ КНФ - формула имеет вид конъюнкции дизъюнкций
- 4. Представление чисел в цифровых устройствах
- 5. Триггеры
- 6. Шифраторы, дешифраторы, мультиплексоры, демультиплексоры
- 7. Регистры Сдвиговый регистр
- 8. Счетчики, сумматоры Одноразрядный двоичный сумматор. В каждом из разрядов определяется цифра суммы путем сложения по модулю
- 9. Память
- 10. Структура процессора (обобщенная) Микрооперации
- 11. Структура процессора в составе ЭВМ Команда – вид операции, подлежащей к исполнению в процессоре.
- 12. Цифровые автоматы Множества: Возможных входных сигналов x1, x2, …, xn Внутренних состояний a0, a1, …, ak
- 13. Цифровые автоматы (пример)
- 14. Принцип микропрограммного управления Управляющая память хранит кодовые комбинации микрокоманд и выдает их в ОУ ПА Пример
- 15. Микропроцессор Микропроцессор — процессор (устройство, отвечающее за выполнение арифметических, логических операций и операций управления, записанных в
- 16. Обобщенная структура МПС При работе с высокоскоростными ПУ используется режим прямого доступа к памяти (ПДП)
- 17. Микропроцессор. Машинный код. Машинный код (платформенно-ориентированный код), машинный язык — система команд (набор кодов операций) конкретной
- 18. Прерывания процессора Прерывание (interrupt) — сигнал, сообщающий процессору о наступлении какого-либо события, выполнение текущей последовательности команд
- 19. Стек процессора Стек - регистр хранящий информацию для возврата управления из подпрограмм (процедур) в программу и/или
- 20. Архитектура процессора Архитектура процессора — количественная составляющая компонентов микроархитектуры (регистр флагов или регистры процессора), рассматриваемая IT-специалистами
- 21. Архитектуры
- 22. Архитектура Фон Неймана Однородная память микропроцессора. В память могут записываться различные программы. При этом специальная программа-загрузчик
- 23. Гарвардская архитектура Два вида памяти микропроцессора: Память программ (для хранения инструкций микропроцессора); память данных (для временного
- 24. Типовые структуры операционного блока Двухшинная структура Одношинная структура В результате того, что входные данные к арифметико-логическому
- 25. Команды микропроцессора Разрядность команд совпадает с разрядностью микропроцессора. Команда микропроцессора состоит из инструкции и обозначается код
- 26. 32-разрядная архитектура ARM На RISC-архитектуре, отклонения от принципов RISC: Переменное количество циклов выполнения для простых инструкций.
- 27. Архитектура многоядерных процессоров Архитектура многоядерных процессоров во многом повторяет архитектуру симметричных мультипроцессоров (SMP-машин) только в меньших
- 28. Иерархия ЗУ Применение многопортовых ЗУ Сетевые устройства с разделяемыми ресурсами и многопроцессорные устройства обработки данных. В
- 29. Функциональная классификация ЗУ
- 30. Многопортовая память Многопортовая память - это статическое ОЗУ с двумя или более независимыми интерфейсами, обеспечивающими доступ
- 31. Принцип работы асинхронного двухпортового ОЗУ BUSY' удерживается все время, пока не закончится операция обращения к памяти.
- 32. Принцип работы асинхронного двухпортового ОЗУ Прерывания. Интерфейс системы прерываний асинхронных двухпортовых ОЗУ содержит буфер сообщений и
- 33. Интерфейсы Интерфейс - совокупность средств и методов взаимодействия между элементами системы. Совокупность унифицированных технических и программных
- 34. Интерфейсы микропроцессора
- 35. Пропускные способности проводных интерфейсов
- 36. Интерфейс UART UART (Universal Asynchronous Receiver/Transmitter) - универсальный асинхронный приёмопередатчик, интерфейс для связи цифровых устройств, предназначенный
- 37. Интерфейс RS-232-С RS-232-C соединяет два устройства. Линия передачи первого соединяется с линией приема второго и наоборот
- 38. Интерфейс RS-232-С Схема 4-проводной линии связи FG - заземление -TxD - данные, передаваемые компьютером в последовательном
- 39. Интерфейс RS-485 RS-485 — TIA/EIA-485 Electrical Characteristics of Generators and Receivers for Use in Balanced Digital
- 40. Дифференциальная передача сигналов
- 41. LVDS ( Low Voltage Differential Signaling ) - передача информации дифференциальными сигналами малых напряжений ( до
- 42. Низковольтная дифференциальная передача сигналов Подключения Применение Параметры трансивера (пример)
- 43. MOSI — выход ведущего, вход ведомого (Master Out Slave In) для передачи данных от ведущего устройства
- 44. Интерфейс SPI Возможно четыре режима работы интерфейса SPI, характеризующиеся двумя параметрами : CPOL - исходный уровень
- 45. Интерфейс I2C I²C (Inter-Integrated Circuit) — последовательная шина данных для связи интегральных схем, использующая две двунаправленные
- 46. Интерфейс I2C Две двунаправленные линии, подтянутые к напряжению питания и управляемые через открытый коллектор или открытый
- 47. Интерфейс I2C протокол
- 48. Интерфейс I2C временная диаграмма Минимальные значения времени в таблице указаны для максимальной скорости передачи 100 кбит/с.
- 49. Интерфейс CAN Режим передачи — последовательный, широковещательный, пакетный. CAN разработан компанией Robert Bosch GmbH в 1980-х
- 50. Интерфейс CAN Cвойства: каждому сообщению (не устройству) устанавливается свой приоритет; гарантированная величина паузы между двумя актами
- 51. Интерфейс CAN. Трансивер " доминантное состояние" состояние линии для обозначения состояния линии с током, "рецессивное состояние"
- 52. Интерфейс CAN. Протокол Виды кадров Кадр данных (data frame) — передаёт данные; Кадр удаленного запроса (remote
- 53. Интерфейс CAN. Протокол
- 54. Интерфейс 1-wire 1-Wire (один провод) — двунаправленная шина связи для устройств с низкоскоростной передачей данных (до
- 55. Интерфейс 1-wire протокол Передача информационных битов по шине 1-Wire: а – мастер передает сигналы, б –
- 56. Интерфейс JTAG JTAG (Joint Test Action Group) — рабочая группа по разработке cтандарта IEEE 1149 (
- 57. Интерфейс JTAG Возможность программирования микроконтроллера (или ПЛИС) и подключённой к его выводам микросхемы флэш-памяти. Два способа
- 58. Проектирование МПС. Уровни представления МПС В начальной стадии проектирования МПС на концептуальном уровне. В процессе разработки
- 59. Этапы проектирование МПС 1. Формализация требований к системе (составляются внешние спецификации, перечисляются функции системы, формализуется техническое
- 60. Операционная система МПС. Общие сведения. Операционная система - комплекс взаимосвязанных программ, предназначенных для управления ресурсами МПС
- 61. Операционная система МПС. Функции. Основные функции: Исполнение запросов программ (ввод и вывод данных, запуск и остановка
- 62. ОС Linux Linux — общее название Unix-подобных ОС, основанных на одноимённом ядре. UNIX — семейство переносимых,
- 63. ОС Linux. Ядро. SCI - уровень, предоставляющий средства для вызова функций ядра из пространства пользователя. Этот
- 64. ОС Linux. Виртуальная файловая система. VFS предоставляет коммутационную матрицу между пользователями и файловыми системами На верхнем
- 65. Структура и состав ОС Android для смартфона Приложению предоставляются уже реализованные возможности других приложений, к которым
- 66. Классификация интегральных схем mask-programmable gate array (MPGA) laser-programmable gate array (LPGA)
- 67. Классификация интегральных схем MPGA
- 68. Программируемые логические матрицы (ПЛМ) ПЛМ и ПЛИС – это микросхемы, содержащие много (>тысячи) логических элементов (ЛЭ)
- 69. Структура ПЛМ Основная идея работы ПЛМ (PLA — Programmable logic Array) заключается в реализации логической функции,
- 70. ПЛМ на плавких перемычках Каждый из вх. сигналов (A,B) и их инверсий соединяется с одним из
- 71. ПЛМ, разновидности Некоторые ПЛМ включают в себя до 10000 эквивалентных вентилей (двухвходовых И-НЕ или ИЛИ-НЕ). Число
- 72. Программируемые логические матрицы Программируемая логическая матрица (ПЛМ) – это универсальная структура, позволяющая запрограммировать систему булевых функций
- 73. Программируемые логические матрицы
- 74. ПЛМ. Пример реализации шифратора/дешифратора
- 75. ПЛМ. Пример реализации мультиплексора/демультиплексора Схема де-
- 76. ПЛМ. Пример реализации регистра
- 77. Обобщенная модель ПЛИС на основе ПЛМ Основу всех ПЛИС составляет логическая матрица. Она может быть полной
- 78. Классификация ПЛИС
- 79. Свойства и преимущества ПЛИС
- 80. HDL общие сведения HDL (Hardware Description Language) - язык описания аппаратуры. VHDL и Verilog были разработаны
- 81. CPLD – сложные программируемые логические устройства
- 82. Блоки ввода/вывода CPLD
- 83. Программируемая матрица соединений Передача сигналов от ПМС в ФБ
- 84. Функциональные блоки CPLD Структура ФБ
- 85. Макроячейка ФБ CPLD
- 86. Программируемые пользователем вентильные матрицы FPGA
- 87. Блоки ввода/вывода FPGA
- 88. Межсоединения FPGA
- 89. Функциональные блоки FPGA Через верх. вх. MUX1 и нижн. вх. MUX2 ф-ции G и F могут
- 90. ПЛИС с комбинированной архитектурой Семейство FLEX
- 91. Логические элементы ПЛИС семейства FLEX
- 92. Блоки памяти ПЛИС семейства FLEX
- 93. HDL модульность
- 94. HDL модульность
- 95. HDL модульность
- 96. HDL модульность
- 97. HDL тестирующая программа
- 98. HDL программирование
- 99. HDL операторы
- 100. Verilog операторы
- 102. Скачать презентацию
Основы цифровой схемотехники
Последовательные Параллельные
Основы цифровой схемотехники
Последовательные Параллельные
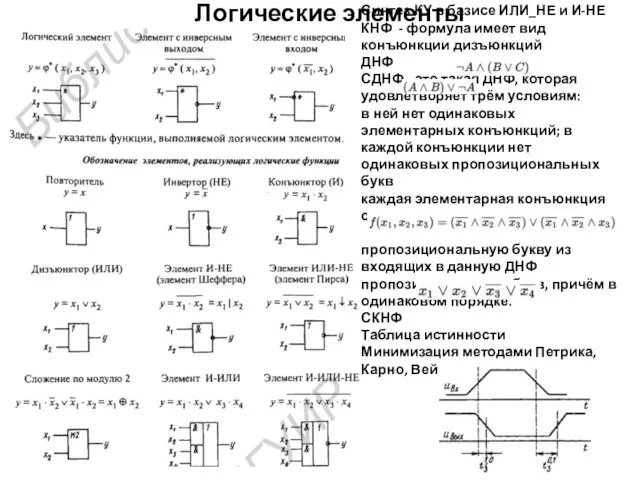
Логические элементы
Синтез КУ в базисе ИЛИ_НЕ и И-НЕ
КНФ - формула имеет
Логические элементы
Синтез КУ в базисе ИЛИ_НЕ и И-НЕ
КНФ - формула имеет
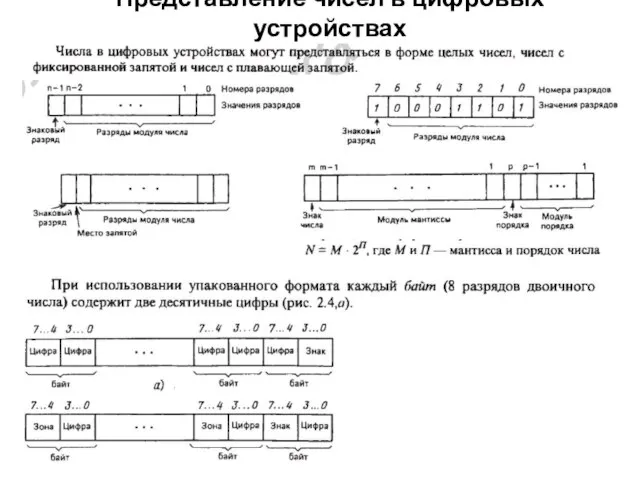
Представление чисел в цифровых устройствах
Представление чисел в цифровых устройствах
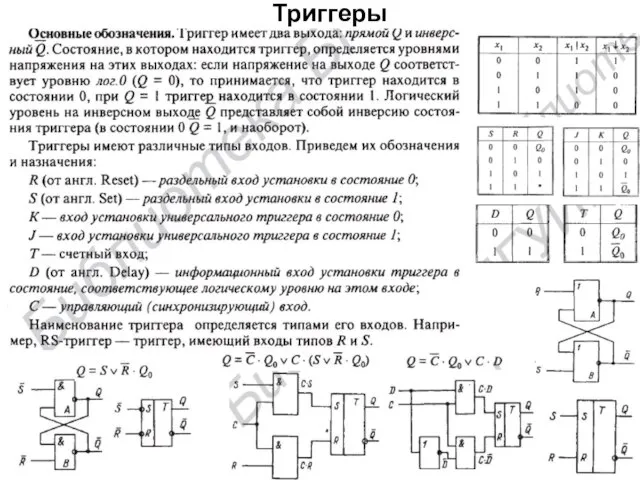
Триггеры
Триггеры

Шифраторы, дешифраторы, мультиплексоры, демультиплексоры
Шифраторы, дешифраторы, мультиплексоры, демультиплексоры
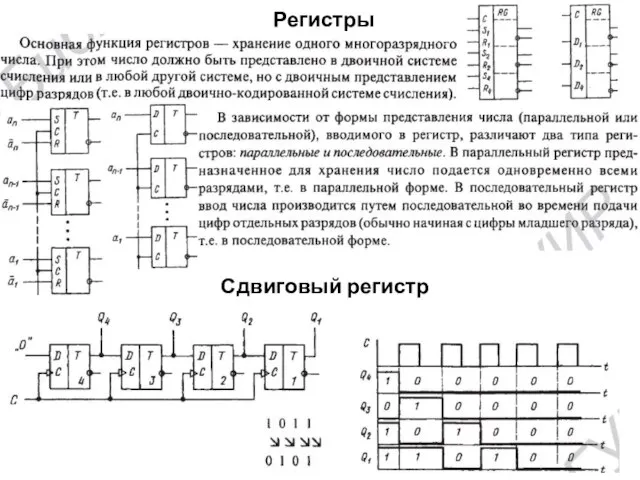
Регистры
Сдвиговый регистр
Регистры
Сдвиговый регистр
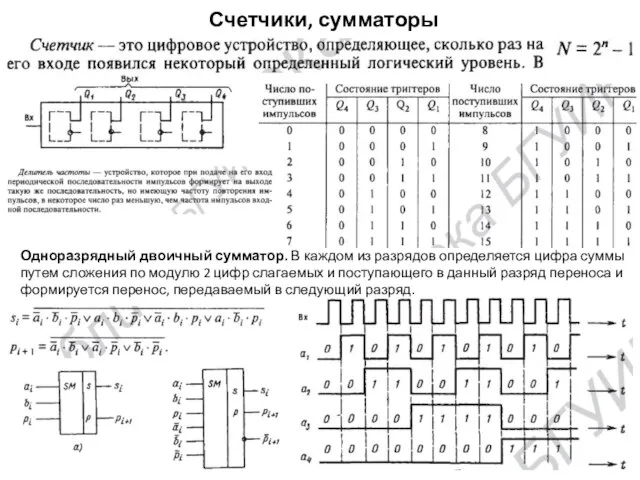
Счетчики, сумматоры
Одноразрядный двоичный сумматор. В каждом из разрядов определяется цифра суммы
Счетчики, сумматоры
Одноразрядный двоичный сумматор. В каждом из разрядов определяется цифра суммы
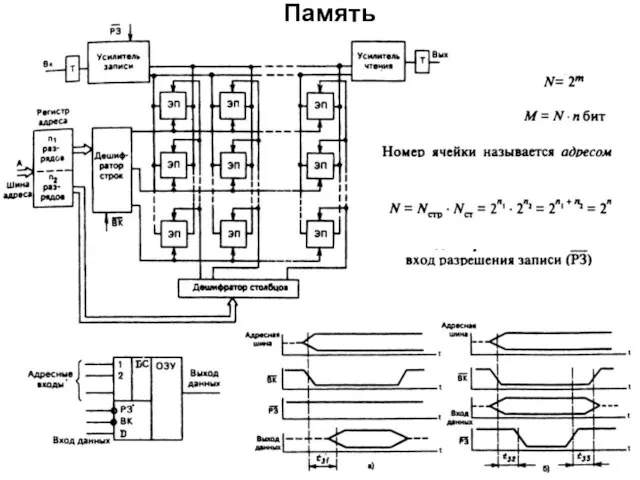
Память
Память

Структура процессора (обобщенная)
Микрооперации
Структура процессора (обобщенная)
Микрооперации
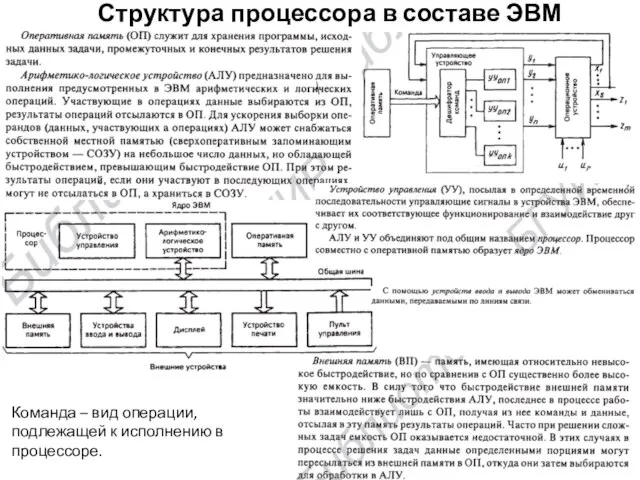
Структура процессора в составе ЭВМ
Команда – вид операции, подлежащей к исполнению
Структура процессора в составе ЭВМ
Команда – вид операции, подлежащей к исполнению

Цифровые автоматы
Множества:
Возможных входных сигналов x1, x2, …, xn
Внутренних состояний
a0, a1, …,
Цифровые автоматы
Множества:
Возможных входных сигналов x1, x2, …, xn
Внутренних состояний
a0, a1, …,

Цифровые автоматы (пример)
Цифровые автоматы (пример)
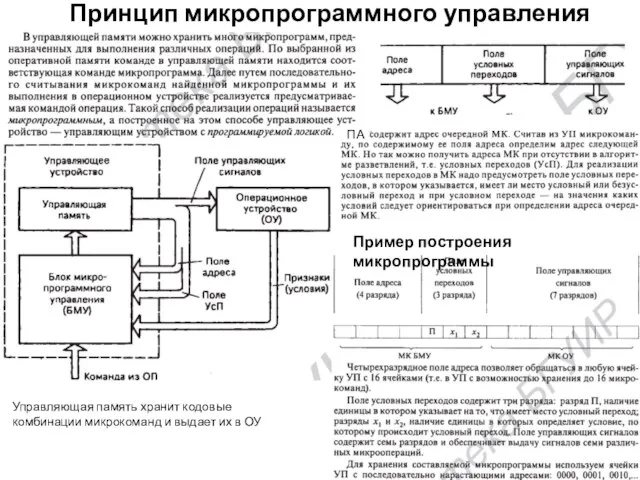
Принцип микропрограммного управления
Управляющая память хранит кодовые комбинации микрокоманд и выдает их
Принцип микропрограммного управления
Управляющая память хранит кодовые комбинации микрокоманд и выдает их

Микропроцессор
Микропроцессор — процессор (устройство, отвечающее за выполнение арифметических, логических операций и
Микропроцессор
Микропроцессор — процессор (устройство, отвечающее за выполнение арифметических, логических операций и
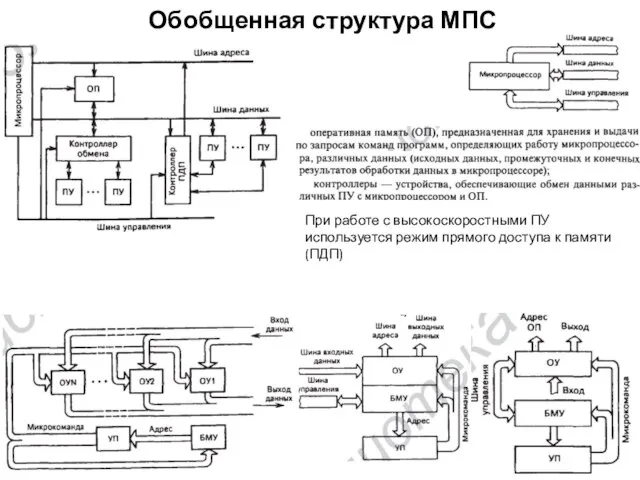
Обобщенная структура МПС
При работе с высокоскоростными ПУ используется режим прямого доступа
Обобщенная структура МПС
При работе с высокоскоростными ПУ используется режим прямого доступа

Микропроцессор. Машинный код.
Машинный код (платформенно-ориентированный код), машинный язык — система команд
Микропроцессор. Машинный код.
Машинный код (платформенно-ориентированный код), машинный язык — система команд

Прерывания процессора
Прерывание (interrupt) — сигнал, сообщающий процессору о наступлении какого-либо события,
Прерывания процессора
Прерывание (interrupt) — сигнал, сообщающий процессору о наступлении какого-либо события,
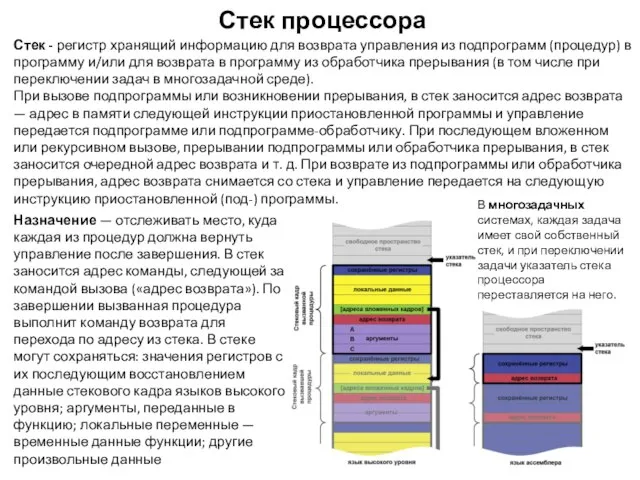
Стек процессора
Стек - регистр хранящий информацию для возврата управления из подпрограмм
Стек процессора
Стек - регистр хранящий информацию для возврата управления из подпрограмм

Архитектура процессора
Архитектура процессора — количественная составляющая компонентов микроархитектуры (регистр флагов или регистры процессора), рассматриваемая IT-специалистами в
Архитектура процессора
Архитектура процессора — количественная составляющая компонентов микроархитектуры (регистр флагов или регистры процессора), рассматриваемая IT-специалистами в
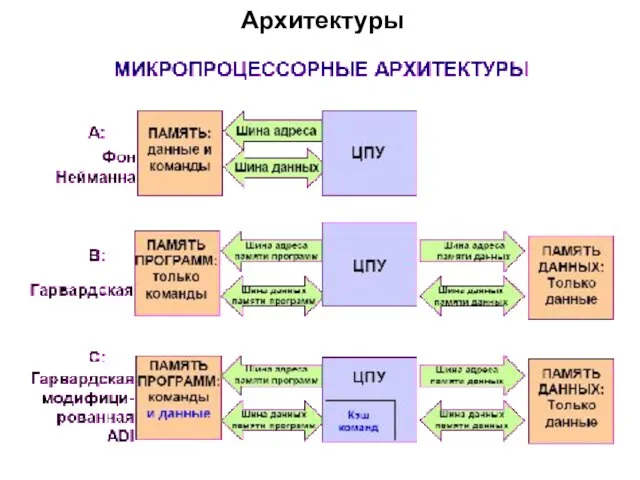
Архитектуры
Архитектуры
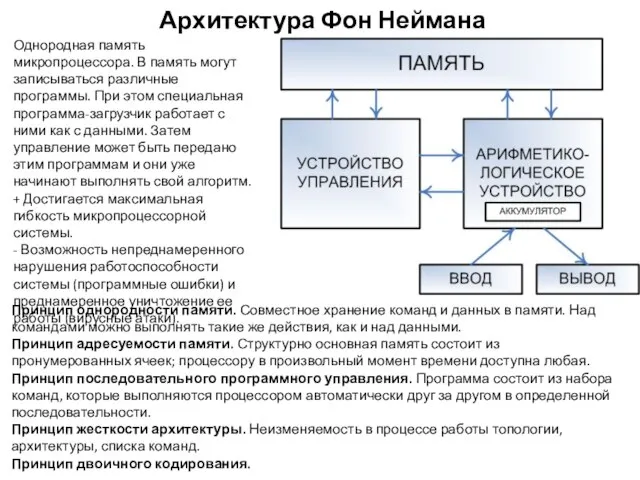
Архитектура Фон Неймана
Однородная память микропроцессора. В память могут записываться различные программы.
Архитектура Фон Неймана
Однородная память микропроцессора. В память могут записываться различные программы.
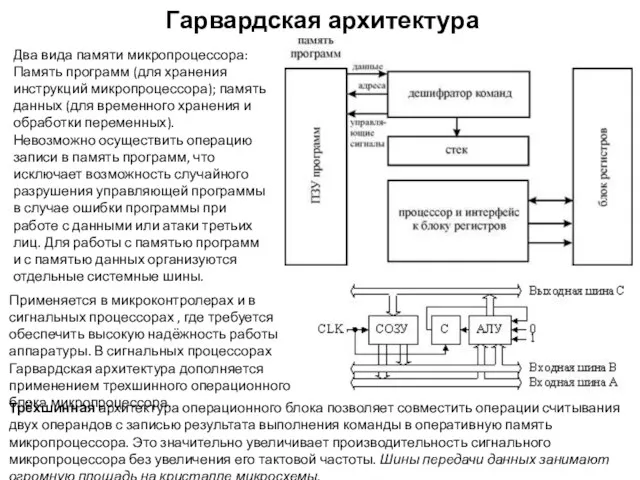
Гарвардская архитектура
Два вида памяти микропроцессора:
Память программ (для хранения инструкций микропроцессора); память
Гарвардская архитектура
Два вида памяти микропроцессора:
Память программ (для хранения инструкций микропроцессора); память
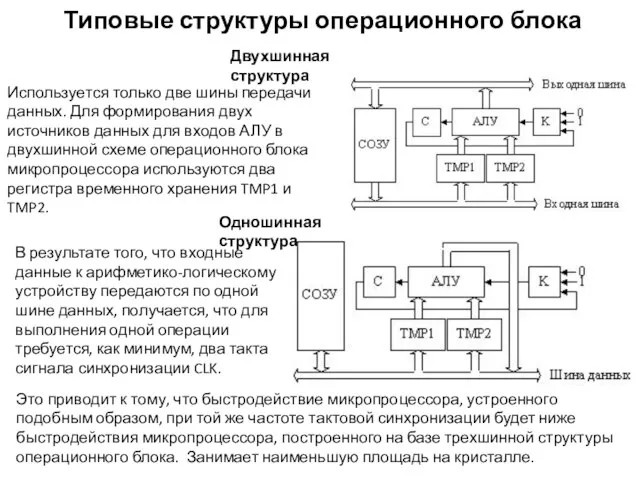
Типовые структуры операционного блока
Двухшинная структура
Одношинная структура
В результате того, что входные данные
Типовые структуры операционного блока
Двухшинная структура
Одношинная структура
В результате того, что входные данные

Команды микропроцессора
Разрядность команд совпадает с разрядностью микропроцессора. Команда микропроцессора состоит из
Команды микропроцессора
Разрядность команд совпадает с разрядностью микропроцессора. Команда микропроцессора состоит из

32-разрядная архитектура ARM
На RISC-архитектуре, отклонения от принципов RISC:
Переменное количество циклов выполнения
32-разрядная архитектура ARM
На RISC-архитектуре, отклонения от принципов RISC:
Переменное количество циклов выполнения

Архитектура многоядерных процессоров
Архитектура многоядерных процессоров во многом повторяет архитектуру симметричных мультипроцессоров
Архитектура многоядерных процессоров
Архитектура многоядерных процессоров во многом повторяет архитектуру симметричных мультипроцессоров
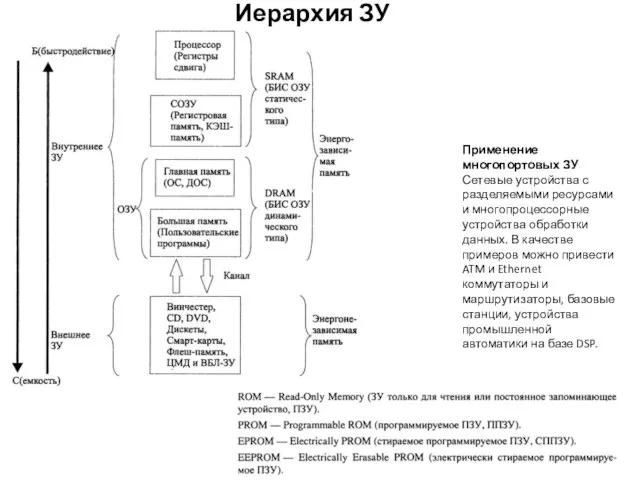
Иерархия ЗУ
Применение многопортовых ЗУ
Сетевые устройства с разделяемыми ресурсами и многопроцессорные
Иерархия ЗУ
Применение многопортовых ЗУ
Сетевые устройства с разделяемыми ресурсами и многопроцессорные
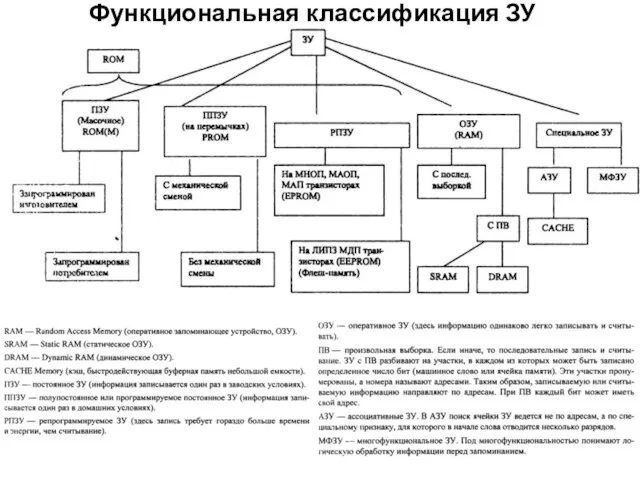
Функциональная классификация ЗУ
Функциональная классификация ЗУ

Многопортовая память
Многопортовая память - это статическое ОЗУ с двумя или более
Многопортовая память
Многопортовая память - это статическое ОЗУ с двумя или более

Принцип работы асинхронного двухпортового ОЗУ
BUSY' удерживается все время, пока не закончится
Принцип работы асинхронного двухпортового ОЗУ
BUSY' удерживается все время, пока не закончится

Принцип работы асинхронного двухпортового ОЗУ
Прерывания. Интерфейс системы прерываний асинхронных двухпортовых ОЗУ
Принцип работы асинхронного двухпортового ОЗУ
Прерывания. Интерфейс системы прерываний асинхронных двухпортовых ОЗУ

Интерфейсы
Интерфейс - совокупность средств и методов взаимодействия между элементами системы. Совокупность
Интерфейсы
Интерфейс - совокупность средств и методов взаимодействия между элементами системы. Совокупность
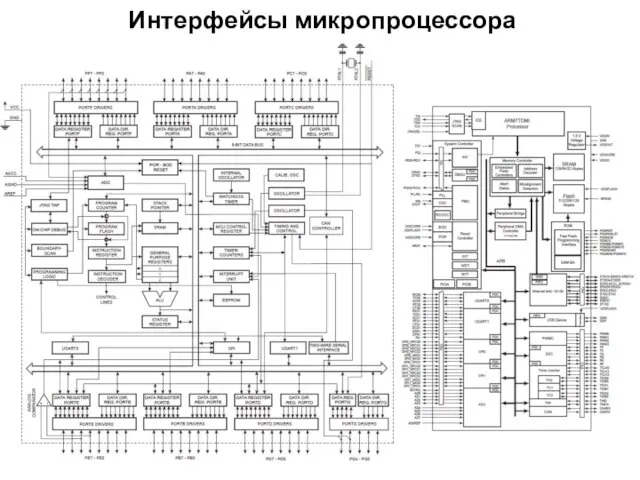
Интерфейсы микропроцессора
Интерфейсы микропроцессора
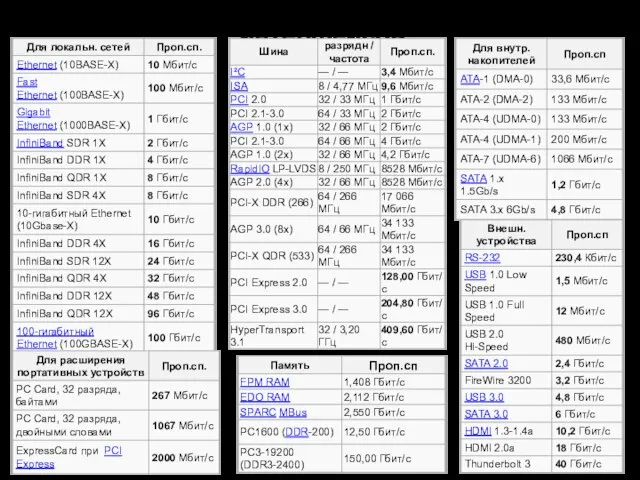
Пропускные способности проводных интерфейсов
Пропускные способности проводных интерфейсов
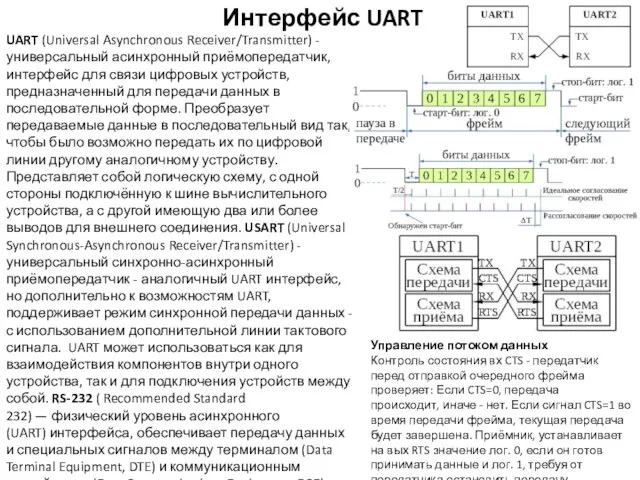
Интерфейс UART
UART (Universal Asynchronous Receiver/Transmitter) - универсальный асинхронный приёмопередатчик, интерфейс для
Интерфейс UART
UART (Universal Asynchronous Receiver/Transmitter) - универсальный асинхронный приёмопередатчик, интерфейс для

Интерфейс RS-232-С
RS-232-C соединяет два устройства. Линия передачи первого соединяется с линией
Интерфейс RS-232-С
RS-232-C соединяет два устройства. Линия передачи первого соединяется с линией
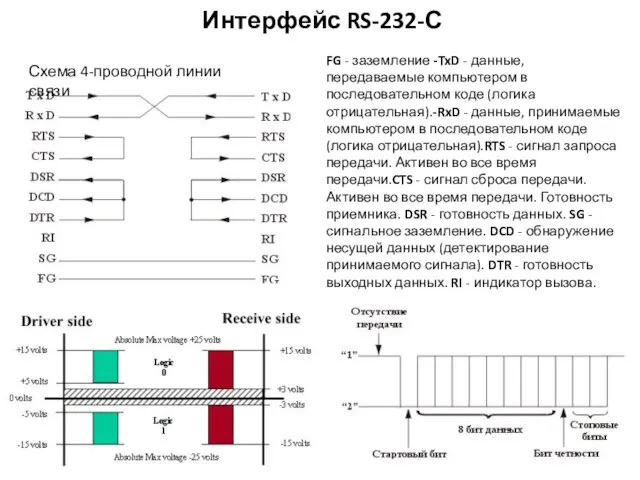
Интерфейс RS-232-С
Схема 4-проводной линии связи
FG - заземление -TxD - данные, передаваемые компьютером в
Интерфейс RS-232-С
Схема 4-проводной линии связи
FG - заземление -TxD - данные, передаваемые компьютером в
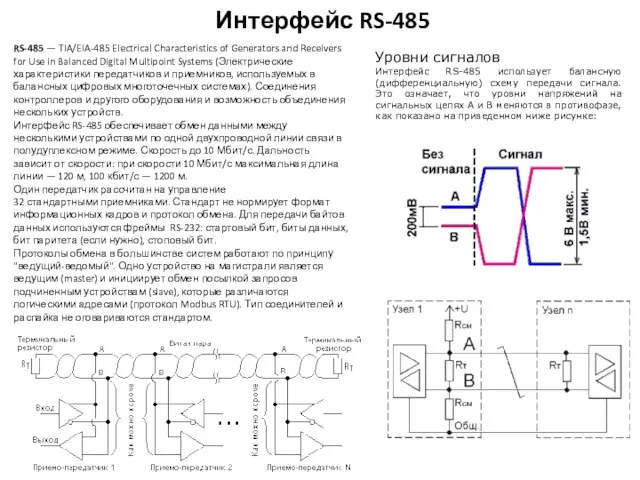
Интерфейс RS-485
RS-485 — TIA/EIA-485 Electrical Characteristics of Generators and Receivers for Use in
Интерфейс RS-485
RS-485 — TIA/EIA-485 Electrical Characteristics of Generators and Receivers for Use in
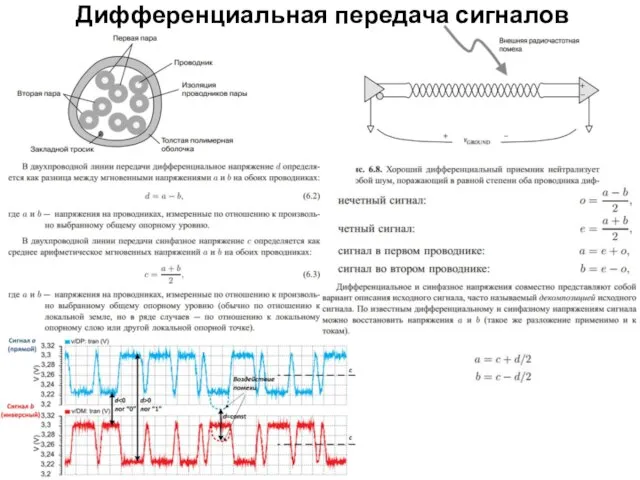
Дифференциальная передача сигналов
Дифференциальная передача сигналов
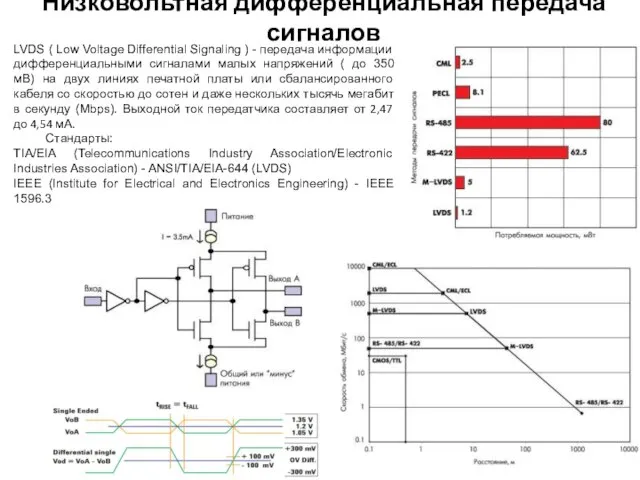
LVDS ( Low Voltage Differential Signaling ) - передача информации дифференциальными
LVDS ( Low Voltage Differential Signaling ) - передача информации дифференциальными
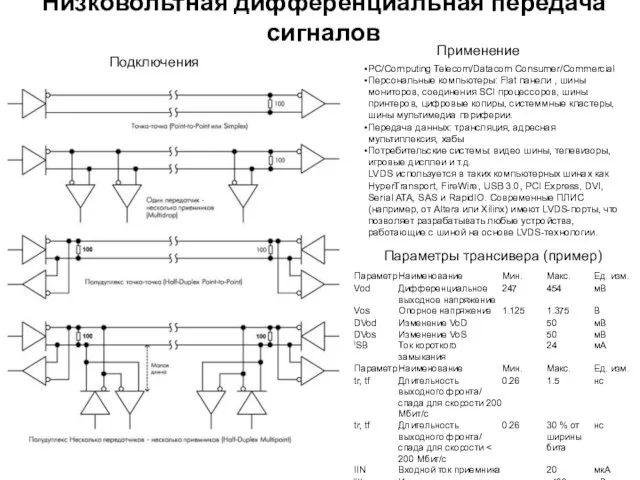
Низковольтная дифференциальная передача сигналов
Подключения
Применение
Параметры трансивера (пример)
Низковольтная дифференциальная передача сигналов
Подключения
Применение
Параметры трансивера (пример)
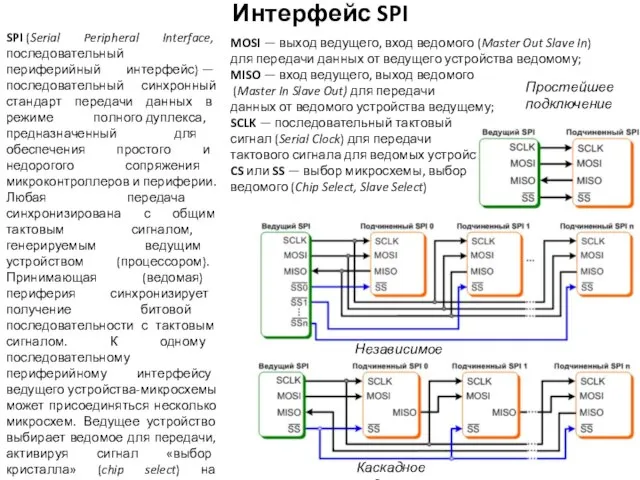
MOSI — выход ведущего, вход ведомого (Master Out Slave In) для передачи
MOSI — выход ведущего, вход ведомого (Master Out Slave In) для передачи
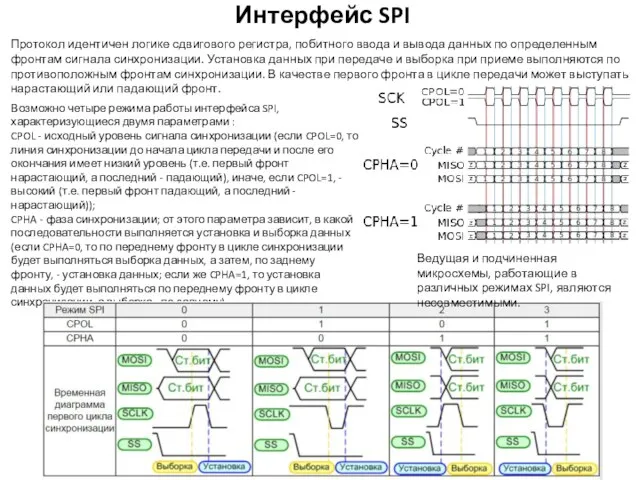
Интерфейс SPI
Возможно четыре режима работы интерфейса SPI, характеризующиеся двумя параметрами :
CPOL
Интерфейс SPI
Возможно четыре режима работы интерфейса SPI, характеризующиеся двумя параметрами :
CPOL
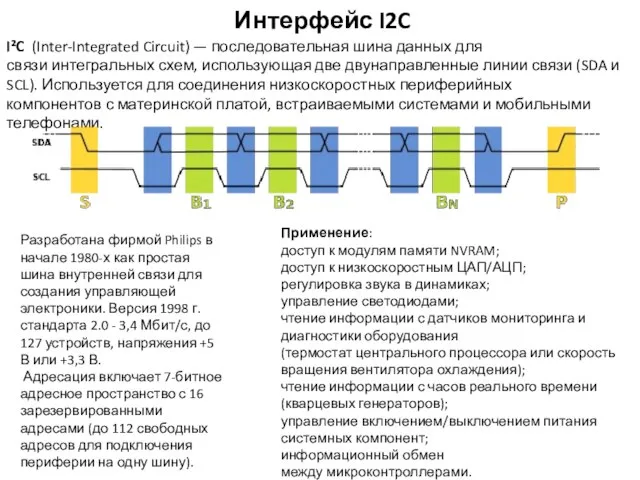
Интерфейс I2C
I²C (Inter-Integrated Circuit) — последовательная шина данных для связи интегральных схем, использующая две двунаправленные
Интерфейс I2C
I²C (Inter-Integrated Circuit) — последовательная шина данных для связи интегральных схем, использующая две двунаправленные

Интерфейс I2C
Две двунаправленные линии, подтянутые к напряжению питания и управляемые через
Интерфейс I2C
Две двунаправленные линии, подтянутые к напряжению питания и управляемые через
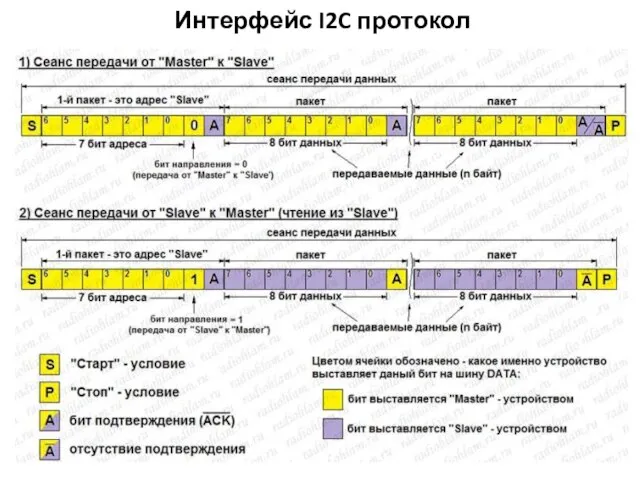
Интерфейс I2C протокол
Интерфейс I2C протокол
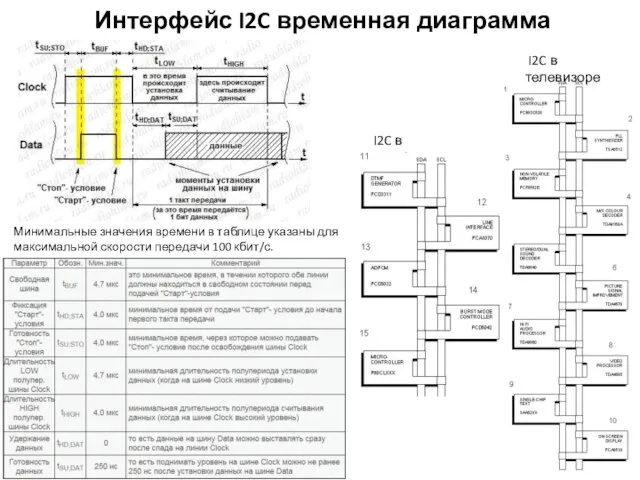
Интерфейс I2C временная диаграмма
Минимальные значения времени в таблице указаны для максимальной
Интерфейс I2C временная диаграмма
Минимальные значения времени в таблице указаны для максимальной
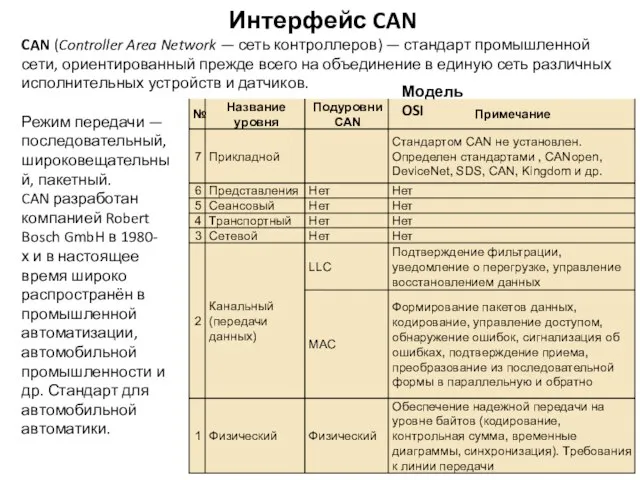
Интерфейс CAN
Режим передачи — последовательный, широковещательный, пакетный.
CAN разработан компанией Robert Bosch GmbH в 1980-х и
Интерфейс CAN
Режим передачи — последовательный, широковещательный, пакетный.
CAN разработан компанией Robert Bosch GmbH в 1980-х и
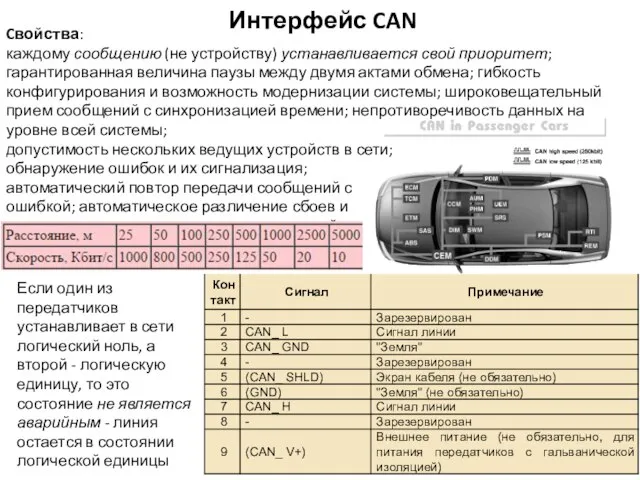
Интерфейс CAN
Cвойства:
каждому сообщению (не устройству) устанавливается свой приоритет; гарантированная величина паузы между двумя актами
Интерфейс CAN
Cвойства:
каждому сообщению (не устройству) устанавливается свой приоритет; гарантированная величина паузы между двумя актами
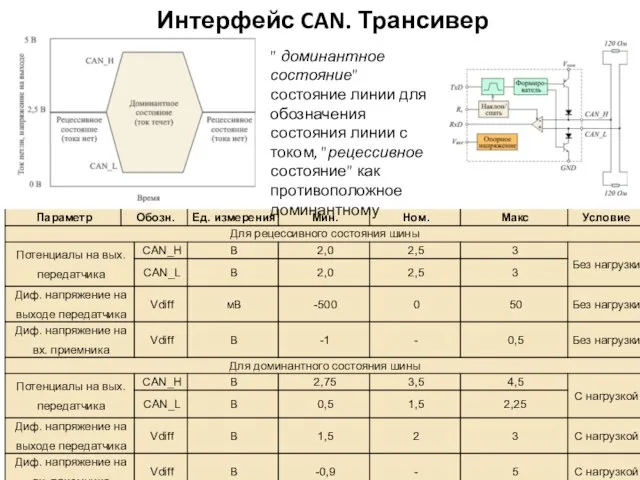
Интерфейс CAN. Трансивер
" доминантное состояние" состояние линии для обозначения состояния линии с
Интерфейс CAN. Трансивер
" доминантное состояние" состояние линии для обозначения состояния линии с
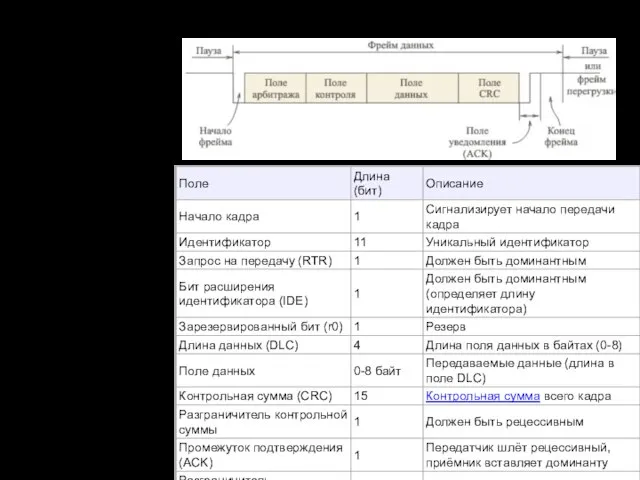
Интерфейс CAN. Протокол
Виды кадров
Кадр данных (data frame) — передаёт данные;
Кадр удаленного запроса (remote
Интерфейс CAN. Протокол
Виды кадров
Кадр данных (data frame) — передаёт данные;
Кадр удаленного запроса (remote
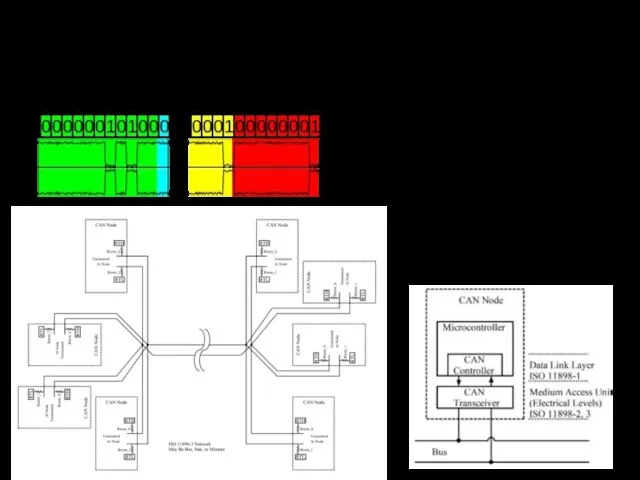
Интерфейс CAN. Протокол
Интерфейс CAN. Протокол

Интерфейс 1-wire
1-Wire (один провод) — двунаправленная шина связи для устройств с низкоскоростной передачей данных (до 125 Кбит/с),
Интерфейс 1-wire
1-Wire (один провод) — двунаправленная шина связи для устройств с низкоскоростной передачей данных (до 125 Кбит/с),
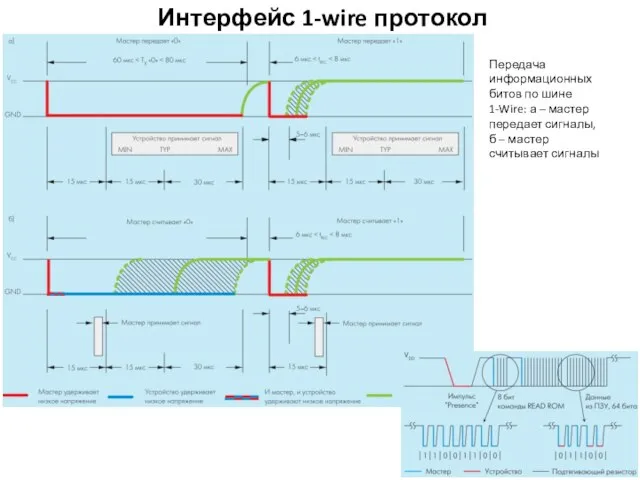
Интерфейс 1-wire протокол
Передача информационных битов по шине 1-Wire: а –
Интерфейс 1-wire протокол
Передача информационных битов по шине 1-Wire: а –

Интерфейс JTAG
JTAG (Joint Test Action Group) — рабочая группа по разработке cтандарта IEEE 1149 (
Интерфейс JTAG
JTAG (Joint Test Action Group) — рабочая группа по разработке cтандарта IEEE 1149 (
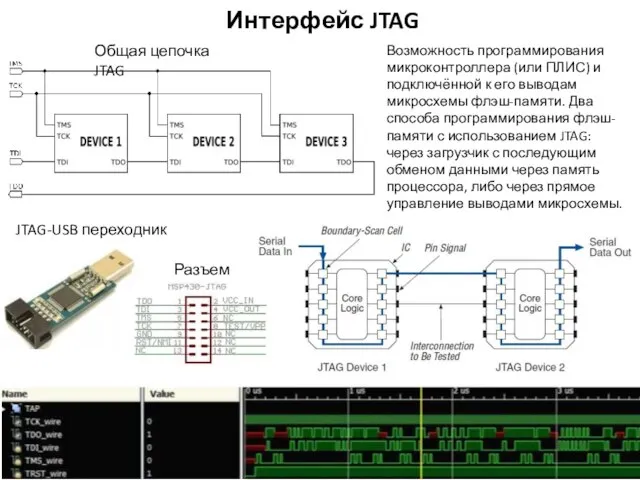
Интерфейс JTAG
Возможность программирования микроконтроллера (или ПЛИС) и подключённой к его выводам микросхемы флэш-памяти. Два
Интерфейс JTAG
Возможность программирования микроконтроллера (или ПЛИС) и подключённой к его выводам микросхемы флэш-памяти. Два

Проектирование МПС. Уровни представления МПС
В начальной стадии проектирования МПС на концептуальном
Проектирование МПС. Уровни представления МПС
В начальной стадии проектирования МПС на концептуальном

Этапы проектирование МПС
1. Формализация требований к системе (составляются внешние спецификации,
Этапы проектирование МПС
1. Формализация требований к системе (составляются внешние спецификации,
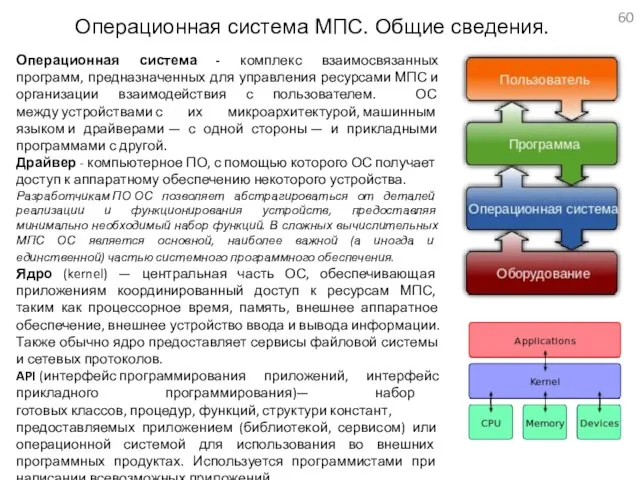
Операционная система МПС. Общие сведения.
Операционная система - комплекс взаимосвязанных программ, предназначенных
Операционная система МПС. Общие сведения.
Операционная система - комплекс взаимосвязанных программ, предназначенных

Операционная система МПС. Функции.
Основные функции:
Исполнение запросов программ (ввод и вывод данных,
Операционная система МПС. Функции.
Основные функции:
Исполнение запросов программ (ввод и вывод данных,
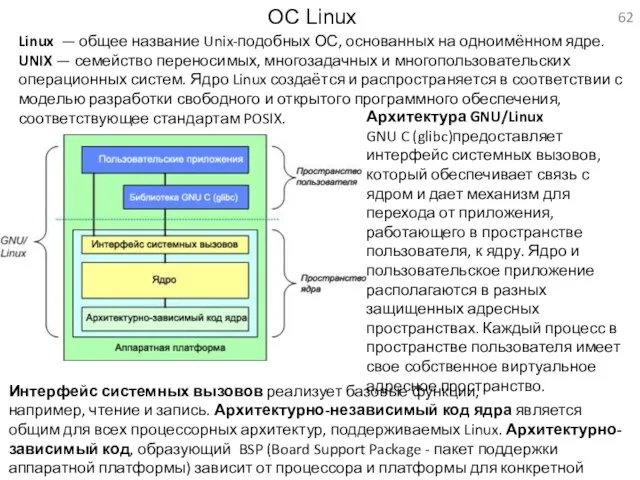
ОС Linux
Linux — общее название Unix-подобных ОС, основанных на одноимённом ядре. UNIX —
ОС Linux
Linux — общее название Unix-подобных ОС, основанных на одноимённом ядре. UNIX —
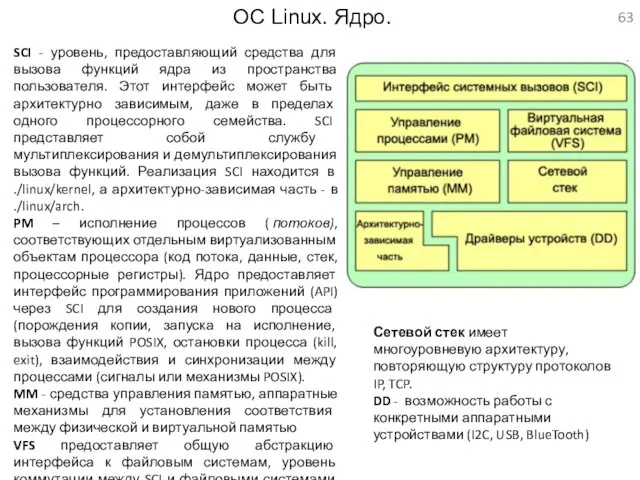
ОС Linux. Ядро.
SCI - уровень, предоставляющий средства для вызова функций ядра
ОС Linux. Ядро.
SCI - уровень, предоставляющий средства для вызова функций ядра
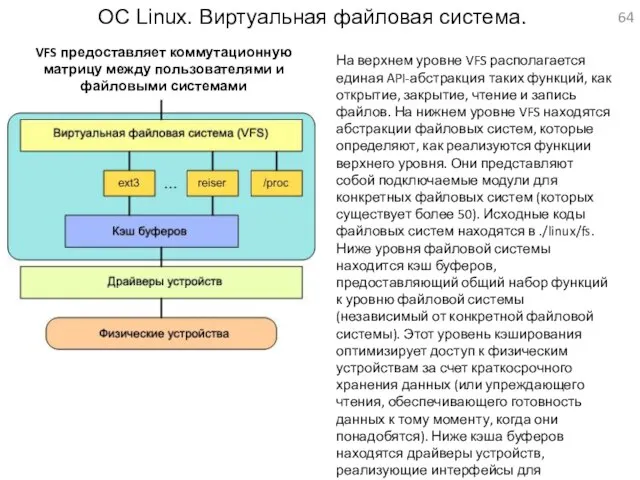
ОС Linux. Виртуальная файловая система.
VFS предоставляет коммутационную матрицу между пользователями и
ОС Linux. Виртуальная файловая система.
VFS предоставляет коммутационную матрицу между пользователями и
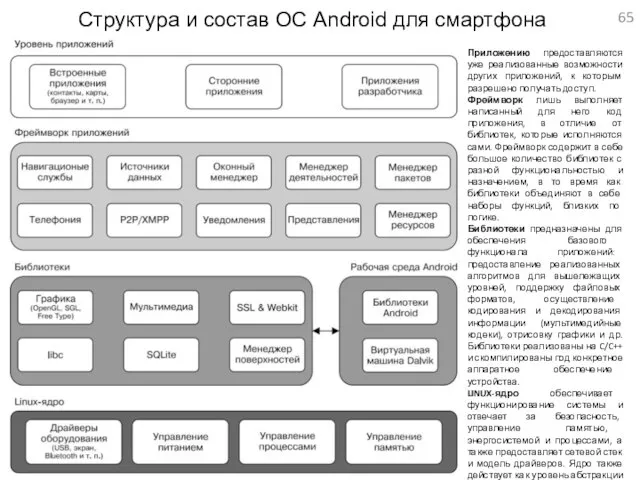
Структура и состав ОС Android для смартфона
Приложению предоставляются уже реализованные возможности
Структура и состав ОС Android для смартфона
Приложению предоставляются уже реализованные возможности
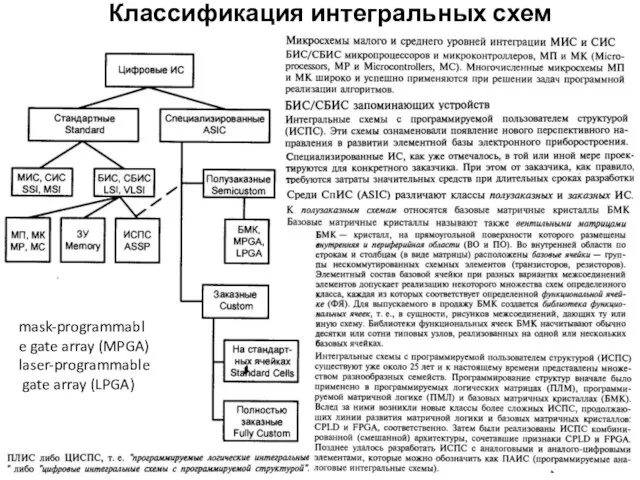
Классификация интегральных схем
mask-programmable gate array (MPGA)
laser-programmable gate array (LPGA)
Классификация интегральных схем
mask-programmable gate array (MPGA)
laser-programmable gate array (LPGA)
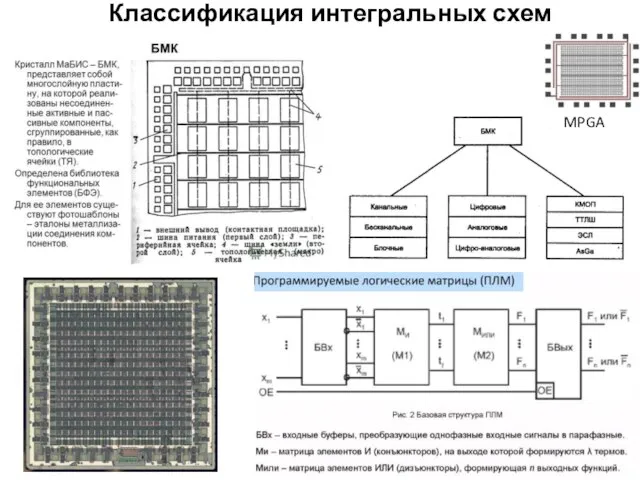
Классификация интегральных схем
MPGA
Классификация интегральных схем
MPGA

Программируемые логические матрицы (ПЛМ)
ПЛМ и ПЛИС – это микросхемы, содержащие много
Программируемые логические матрицы (ПЛМ)
ПЛМ и ПЛИС – это микросхемы, содержащие много
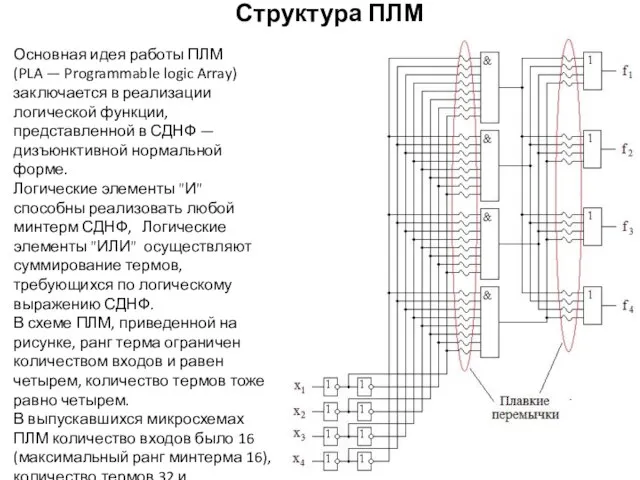
Структура ПЛМ
Основная идея работы ПЛМ (PLA — Programmable logic Array)
заключается в реализации
Структура ПЛМ
Основная идея работы ПЛМ (PLA — Programmable logic Array)
заключается в реализации
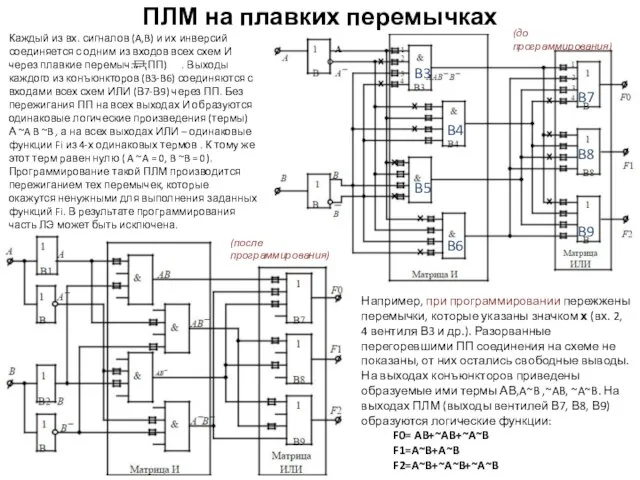
ПЛМ на плавких перемычках
Каждый из вх. сигналов (A,B) и их инверсий
ПЛМ на плавких перемычках
Каждый из вх. сигналов (A,B) и их инверсий
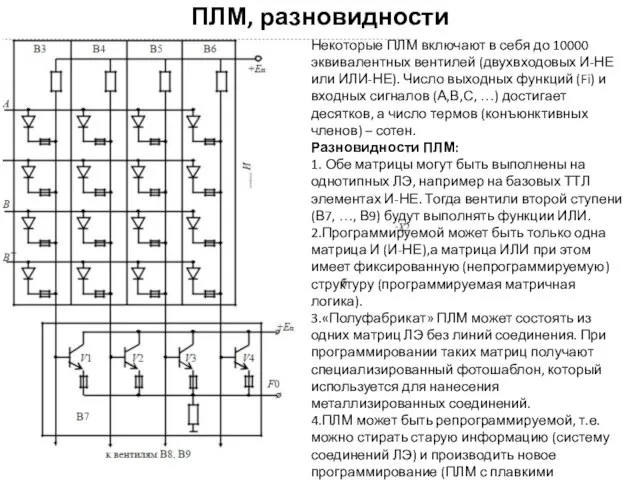
ПЛМ, разновидности
Некоторые ПЛМ включают в себя до 10000 эквивалентных вентилей
ПЛМ, разновидности
Некоторые ПЛМ включают в себя до 10000 эквивалентных вентилей

Программируемые логические матрицы
Программируемая логическая матрица (ПЛМ) – это универсальная структура, позволяющая запрограммировать
Программируемые логические матрицы
Программируемая логическая матрица (ПЛМ) – это универсальная структура, позволяющая запрограммировать

Программируемые логические матрицы
Программируемые логические матрицы

ПЛМ. Пример реализации шифратора/дешифратора
ПЛМ. Пример реализации шифратора/дешифратора
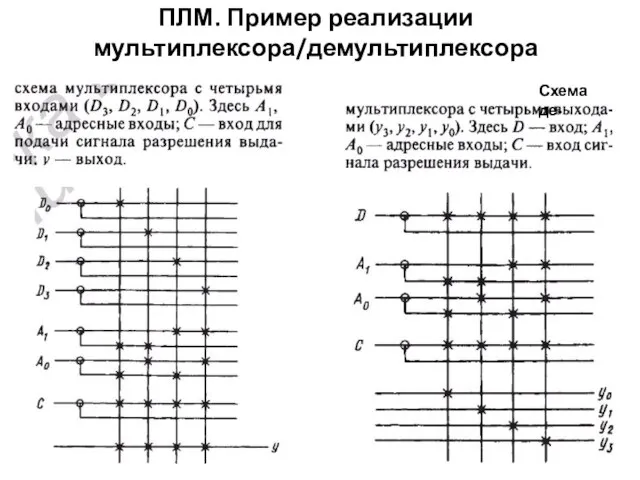
ПЛМ. Пример реализации мультиплексора/демультиплексора
Схема де-
ПЛМ. Пример реализации мультиплексора/демультиплексора
Схема де-

ПЛМ. Пример реализации регистра
ПЛМ. Пример реализации регистра

Обобщенная модель ПЛИС на основе ПЛМ
Основу всех ПЛИС составляет логическая матрица.
Обобщенная модель ПЛИС на основе ПЛМ
Основу всех ПЛИС составляет логическая матрица.

Классификация ПЛИС
Классификация ПЛИС
Свойства и преимущества ПЛИС
Свойства и преимущества ПЛИС

HDL общие сведения
HDL (Hardware Description Language) - язык описания аппаратуры. VHDL
HDL общие сведения
HDL (Hardware Description Language) - язык описания аппаратуры. VHDL

CPLD – сложные программируемые логические устройства
CPLD – сложные программируемые логические устройства
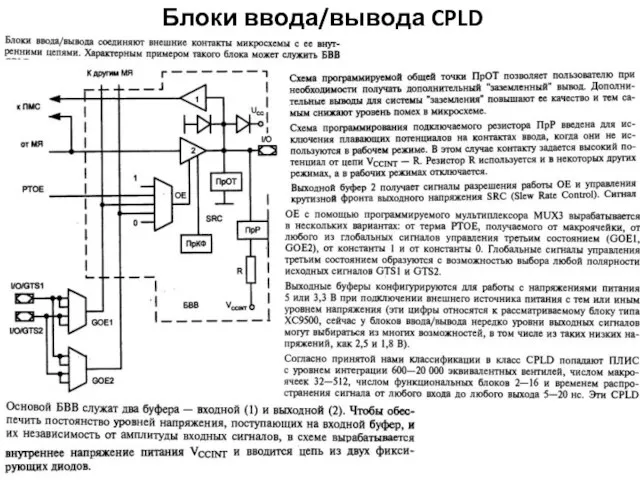
Блоки ввода/вывода CPLD
Блоки ввода/вывода CPLD

Программируемая матрица соединений
Передача сигналов от ПМС в ФБ
Программируемая матрица соединений
Передача сигналов от ПМС в ФБ

Функциональные блоки CPLD
Структура ФБ
Функциональные блоки CPLD
Структура ФБ

Макроячейка ФБ CPLD
Макроячейка ФБ CPLD
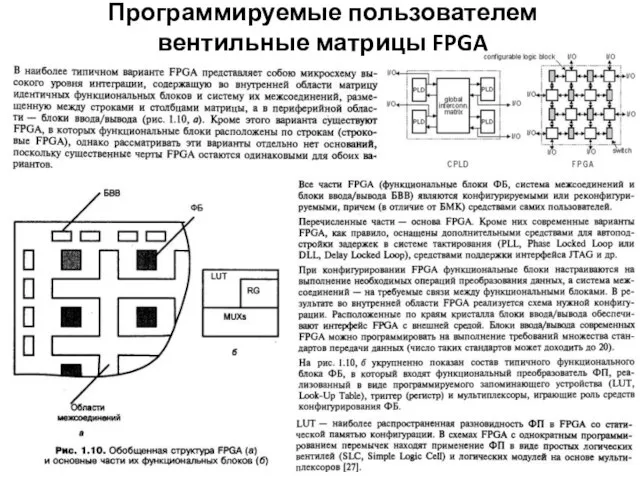
Программируемые пользователем вентильные матрицы FPGA
Программируемые пользователем вентильные матрицы FPGA
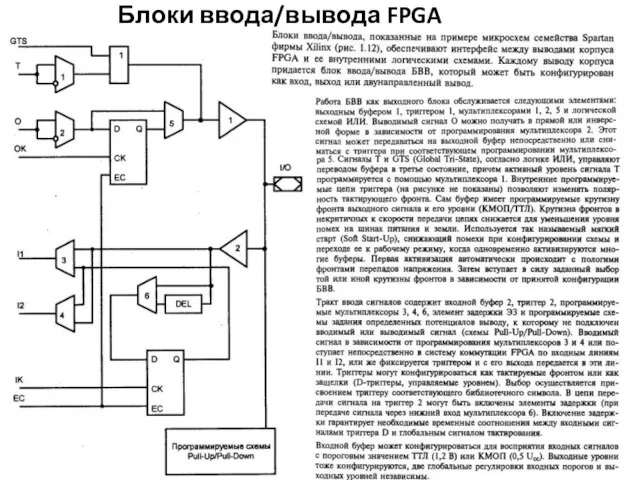
Блоки ввода/вывода FPGA
Блоки ввода/вывода FPGA

Межсоединения FPGA
Межсоединения FPGA

Функциональные блоки FPGA
Через верх. вх. MUX1 и нижн. вх. MUX2 ф-ции
Функциональные блоки FPGA
Через верх. вх. MUX1 и нижн. вх. MUX2 ф-ции

ПЛИС с комбинированной архитектурой
Семейство FLEX
ПЛИС с комбинированной архитектурой
Семейство FLEX

Логические элементы ПЛИС семейства FLEX
Логические элементы ПЛИС семейства FLEX

Блоки памяти ПЛИС семейства FLEX
Блоки памяти ПЛИС семейства FLEX

HDL модульность
HDL модульность

HDL модульность
HDL модульность

HDL модульность
HDL модульность

HDL модульность
HDL модульность

HDL тестирующая программа
HDL тестирующая программа
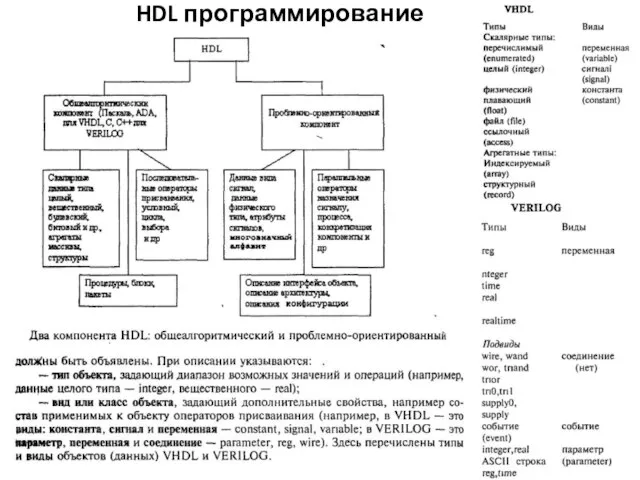
HDL программирование
HDL программирование
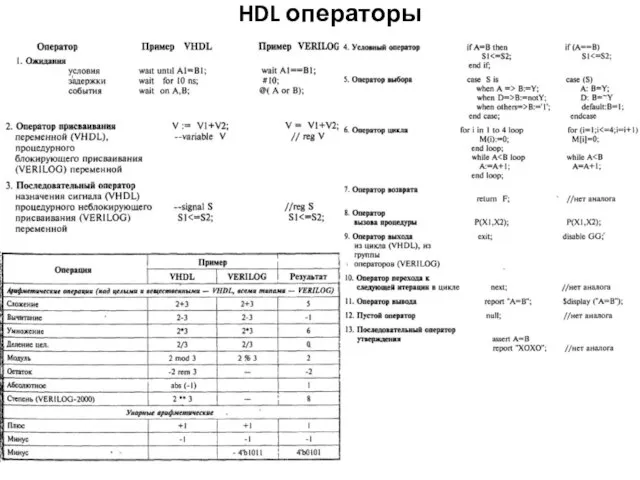
HDL операторы
HDL операторы
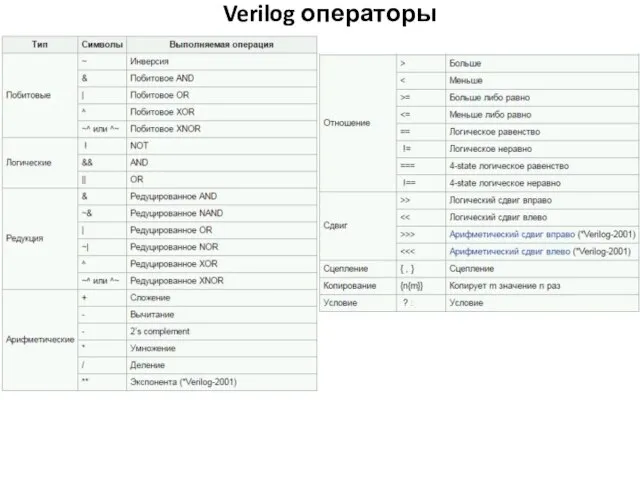
Verilog операторы
Verilog операторы
 20160108_zhivichkova_e._i._schastlivyy_skazochnyy_sluchay
20160108_zhivichkova_e._i._schastlivyy_skazochnyy_sluchay Автомобилестроение в Европе на примере одного из городов Германии
Автомобилестроение в Европе на примере одного из городов Германии Второй цикл семинаров по медиаобразованию и духовно-нравственному воспитанию для преподавателей Тверского региона
Второй цикл семинаров по медиаобразованию и духовно-нравственному воспитанию для преподавателей Тверского региона Программа (концепция) развития муниципального образования Город Ижевск
Программа (концепция) развития муниципального образования Город Ижевск Психодиагностика
Психодиагностика Дорога к храму
Дорога к храму 20180115_zvuk_sh_powerpoint
20180115_zvuk_sh_powerpoint Адаптация обучающихся с расстройствами аутистического спектра (РАС) в специализированном классе общеобразовательной школы
Адаптация обучающихся с расстройствами аутистического спектра (РАС) в специализированном классе общеобразовательной школы תהליך מקוצר לרישום
תהליך מקוצר לרישום Покер Roofbuilder
Покер Roofbuilder Корневая система
Корневая система 20130320_blok1
20130320_blok1 Транспортировка углеводородного сырья с месторождения
Транспортировка углеводородного сырья с месторождения Свойства пластовых флюидов, отношения PVT
Свойства пластовых флюидов, отношения PVT Топливно – энергетический комплекс России (ТЭК)
Топливно – энергетический комплекс России (ТЭК) Влияние минорных тональностей на психофизиологическое состояние человека
Влияние минорных тональностей на психофизиологическое состояние человека Експертиза риби та рибних товарів
Експертиза риби та рибних товарів Колористические типы внешности человека. Аксессуары
Колористические типы внешности человека. Аксессуары Новые возможности видеокамер IP-P Starvis
Новые возможности видеокамер IP-P Starvis Теоретические основы реконструкции. Формы и виды реконструкции
Теоретические основы реконструкции. Формы и виды реконструкции Диакритические знаки во французском языке
Диакритические знаки во французском языке 20151117_distantsionnoe_obuchenie
20151117_distantsionnoe_obuchenie Экстрактивная и азеотропная ректификация
Экстрактивная и азеотропная ректификация Кундалини Рэйки
Кундалини Рэйки The way of making the mold: d60-48 holder-01 mold report
The way of making the mold: d60-48 holder-01 mold report LaserJet Enterprise M60x/M63x NPI Technical Training
LaserJet Enterprise M60x/M63x NPI Technical Training den-rozhdeniya_1
den-rozhdeniya_1 Морфологическая норма
Морфологическая норма