- Лексические анализаторы

Содержание
- 2. Системное программное обеспечение Тема № 11 Лексические анализаторы
- 3. Системное программное обеспечение Лексические анализаторы Назначение лексического анализатора Лексема (лексическая единица языка) – это структурная единица
- 4. Системное программное обеспечение Лексические анализаторы Назначение лексического анализатора С теоретической точки зрения ЛА не является обязательной
- 5. Системное программное обеспечение Лексические анализаторы Основные функции ЛА: исключить из текста исходной программы комментарии, незначащие пробелы,
- 6. Системное программное обеспечение Лексические анализаторы последовательная – ЛА просматривает весь текст исходной программы от начала до
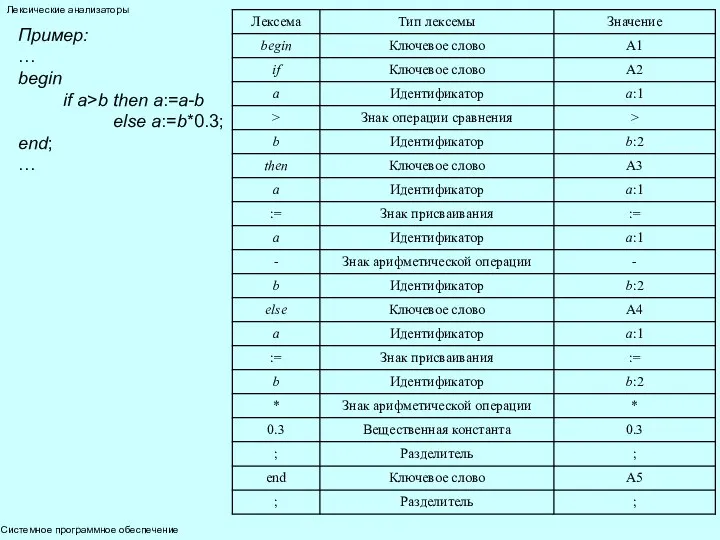
- 7. Системное программное обеспечение Лексические анализаторы Пример: … begin if a>b then a:=a-b else a:=b*0.3; end; …
- 8. Системное программное обеспечение Лексические анализаторы Принципы построения лексических анализаторов Лексический анализатор имеет дело с такими объектами,
- 9. Системное программное обеспечение Лексические анализаторы Для большинства входных языков границы лексем распознаются по заданным терминальным символам
- 10. Системное программное обеспечение Лексические анализаторы Лексический анализатор работает прямо, если для данного входного текста (цепочки символов
- 12. Скачать презентацию

Системное программное обеспечение
Тема № 11
Лексические анализаторы
Системное программное обеспечение
Тема № 11
Лексические анализаторы

Системное программное обеспечение
Лексические анализаторы
Назначение лексического анализатора
Лексема (лексическая единица языка) – это
Системное программное обеспечение
Лексические анализаторы
Назначение лексического анализатора
Лексема (лексическая единица языка) – это

Системное программное обеспечение
Лексические анализаторы
Назначение лексического анализатора
С теоретической точки зрения ЛА не
Системное программное обеспечение
Лексические анализаторы
Назначение лексического анализатора
С теоретической точки зрения ЛА не

Системное программное обеспечение
Лексические анализаторы
Основные функции ЛА:
исключить из текста исходной программы
Системное программное обеспечение
Лексические анализаторы
Основные функции ЛА:
исключить из текста исходной программы

Системное программное обеспечение
Лексические анализаторы
последовательная – ЛА просматривает весь текст исходной
Системное программное обеспечение
Лексические анализаторы
последовательная – ЛА просматривает весь текст исходной
Системное программное обеспечение
Лексические анализаторы
Пример:
…
begin
if a>b then a:=a-b
else a:=b*0.3;
end;
…
Системное программное обеспечение
Лексические анализаторы
Пример:
…
begin
if a>b then a:=a-b
else a:=b*0.3;
end;
…

Системное программное обеспечение
Лексические анализаторы
Принципы построения лексических анализаторов
Лексический анализатор имеет дело с
Системное программное обеспечение
Лексические анализаторы
Принципы построения лексических анализаторов
Лексический анализатор имеет дело с

Системное программное обеспечение
Лексические анализаторы
Для большинства входных языков границы лексем распознаются по
Системное программное обеспечение
Лексические анализаторы
Для большинства входных языков границы лексем распознаются по

Системное программное обеспечение
Лексические анализаторы
Лексический анализатор работает прямо, если для данного входного
Системное программное обеспечение
Лексические анализаторы
Лексический анализатор работает прямо, если для данного входного
 Виртуальные функции и полиморфизм
Виртуальные функции и полиморфизм Общественное здоровье: современное состояние и тенденции
Общественное здоровье: современное состояние и тенденции  Работа с родителями в начальной школе
Работа с родителями в начальной школе Современный футбол. Состояние и перспективы
Современный футбол. Состояние и перспективы Понятие о человеке
Понятие о человеке Георгафичечкая школа Выполнила: студентка 3-го курса группы Т-083 Восколович Юля.
Георгафичечкая школа Выполнила: студентка 3-го курса группы Т-083 Восколович Юля.  Дидактические игры в формировании пространственных и временных отношений
Дидактические игры в формировании пространственных и временных отношений  Волны
Волны L700 download user guide. Flash loader v0.x Lite 7.0.2
L700 download user guide. Flash loader v0.x Lite 7.0.2 Indo-european family of languages
Indo-european family of languages Архитектурная концепция проекта ТПУ Химки
Архитектурная концепция проекта ТПУ Химки Презентация Понятие и классификация оборотных средств, источники формирования
Презентация Понятие и классификация оборотных средств, источники формирования Презентация на тему "Адаптация первоклассников" - скачать презентации по Педагогике
Презентация на тему "Адаптация первоклассников" - скачать презентации по Педагогике Дизайн сувенирной продукции Выполнили: Александра Митюшова, 303 гр. Светлана Шагалина, 303 гр. Проверила: доктор филос
Дизайн сувенирной продукции Выполнили: Александра Митюшова, 303 гр. Светлана Шагалина, 303 гр. Проверила: доктор филос Электробезопасность
Электробезопасность  Элтон Мэйо
Элтон Мэйо Формирование и реализация государственной политики. (Тема 7)
Формирование и реализация государственной политики. (Тема 7) Введение в риск - менеджмент
Введение в риск - менеджмент Ситуационный подход к управлению Выполнила: Познякова Инна С-4411б
Ситуационный подход к управлению Выполнила: Познякова Инна С-4411б Why do we come to church
Why do we come to church Физиологические механизмы утомления и восстановления
Физиологические механизмы утомления и восстановления КРАЗ-260» жүк автокөлік қозғалтқышының салқындату жүйесі
КРАЗ-260» жүк автокөлік қозғалтқышының салқындату жүйесі Динамические структуры данных (язык Си)
Динамические структуры данных (язык Си) Конструкции многоэтажных зданий. Здания со стенами из крупных панелей
Конструкции многоэтажных зданий. Здания со стенами из крупных панелей Проектно-исследовательская работа на тему: « Анализ орфографических, грамматических и пунктуационных ошибок в текстах реклам»
Проектно-исследовательская работа на тему: « Анализ орфографических, грамматических и пунктуационных ошибок в текстах реклам»  Правовые основы перемещения через таможенную границу товаров и транспортных средств. Лекция 3 (очники)
Правовые основы перемещения через таможенную границу товаров и транспортных средств. Лекция 3 (очники) ТАНКОВАЯ КОЛОННА «ТАМБОВСКИЙ КОЛХОЗНИК
ТАНКОВАЯ КОЛОННА «ТАМБОВСКИЙ КОЛХОЗНИК Основи мікро- і наноелектроніки. МДН транзистори. (Лекція 9)
Основи мікро- і наноелектроніки. МДН транзистори. (Лекція 9)