- Оптимизация запросов

Содержание
- 2. Под оптимизацией запросов в реляционных СУБД, имеют в виду такой способ обработки запросов, когда по начальному
- 3. Первая фаза: запрос, заданный на языке запросов, подвергается лексическому и синтаксическому анализу. При этом вырабатывается его
- 4. Вторая фаза: запрос во внутреннем представлении подвергается логической оптимизации. Применяются различные преобразования, "улучшающие" начальное представление запроса:
- 5. Третья фаза: генерация на основе информации, которой располагает оптимизатор, набора альтернативных процедурных планов выполнения данного запроса
- 6. Четвертая фаза: формируется выполняемое представление плана. Выполняемое представление плана может быть: программой в машинных кодах,если система
- 7. Вопрос 2. Синтаксическая оптимизация запросов На этапе логической оптимизации производятся эквивалентные преобразования внутреннего представления запроса, которые
- 8. предикат включает в точности два имени поля разных отношений (или двух разных вхождений одного отношения). Его
- 9. 2.2 Преобразования запросов с изменением порядка реляционных операций В оптимизаторах распространены логические преобразования, связанные с изменением
- 10. Поэтому естественно стремиться к такому преобразованию запроса, содержащего предикаты со вложенными подзапросами, которое сделает семантику подзапроса
- 11. Пример SELECT Ri.Ck FROM Ri WHERE Ri.Ch IS IN ( SELECT Rj.Cm FROM Rj WHERE Ri.Cn
- 12. Вопрос 3. Семантическая оптимизация запросов Рассмотренные преобразования запросов основывались на семантике языка запросов, но в них
- 13. Пусть база данных состоит из отношений EMP и DEPT. Схема отношения Служащие - EMP (EMP#, EMPNAME,
- 14. Если семантическая оптимизация имеет дело только со знаниями, представленными в виде ограничений целостности базы данных, то
- 15. Оптимизирующие преобразования, рассмотренные выше, оставляют внутреннее представление запроса непроцедурным. Процедурным планом выполнения запроса называется такое его
- 16. Обе задачи решаются на основе фиксированных встроенных в оптимизатор алгоритмов. Оптимизатор может быть рассчитан на то,
- 17. Генерация плана выполнения сложного запроса - это многоэтапный процесс, в ходе которого учитываются свойства создаваемых при
- 18. После генерации множества планов выполнения запроса нужно выбрать один, наиболее эффективный план, в соответствии с которым
- 19. Рассмотрим предикат R.C op const. Степень селективности предиката зависит: от вида операции сравнения; значения константы; распределения
- 20. Характеристики отношения R: T - число кортежей в данном отношении N - число блоков внешней памяти,
- 21. 4.3. Более точные оценки При отказе от предположения о равномерности распределения значений поля отношения необходимо уметь
- 22. Область значений поля разбивается на N интервалов равного размера, и для каждого интервала подсчитывается число значений
- 23. Тогда средняя оценка степени селективности (SUMi-1 + SUMi) / (2 ( T), и ошибка оценки может
- 25. Скачать презентацию

Под оптимизацией запросов в реляционных СУБД, имеют в виду такой способ
Под оптимизацией запросов в реляционных СУБД, имеют в виду такой способ
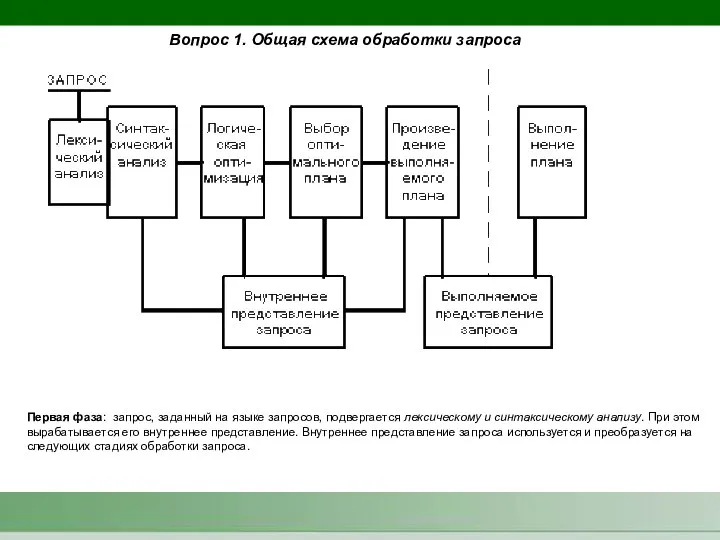
Первая фаза: запрос, заданный на языке запросов, подвергается лексическому и синтаксическому
Первая фаза: запрос, заданный на языке запросов, подвергается лексическому и синтаксическому
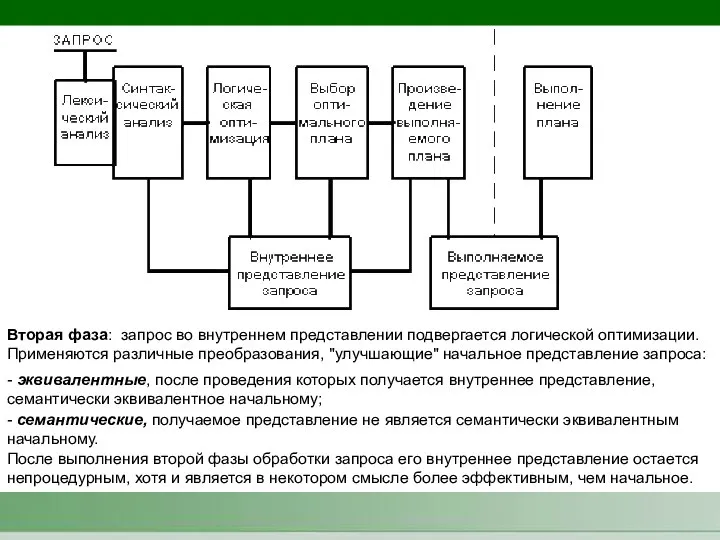
Вторая фаза: запрос во внутреннем представлении подвергается логической оптимизации.
Применяются различные
Вторая фаза: запрос во внутреннем представлении подвергается логической оптимизации.
Применяются различные
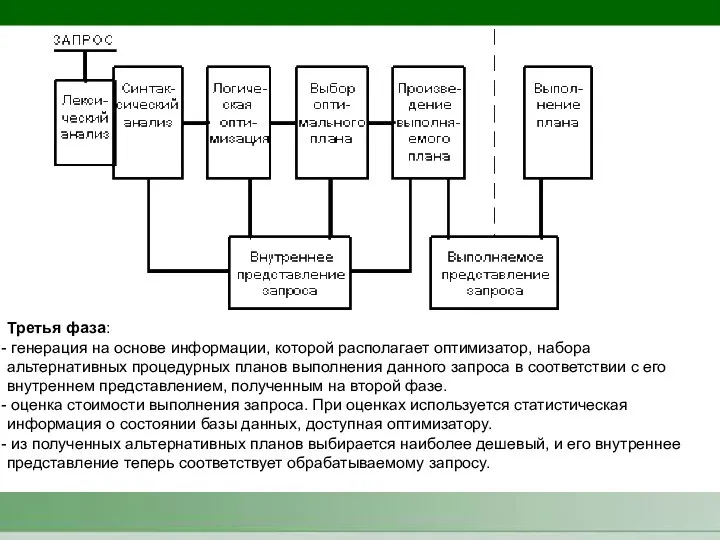
Третья фаза:
генерация на основе информации, которой располагает оптимизатор, набора альтернативных
Третья фаза:
генерация на основе информации, которой располагает оптимизатор, набора альтернативных
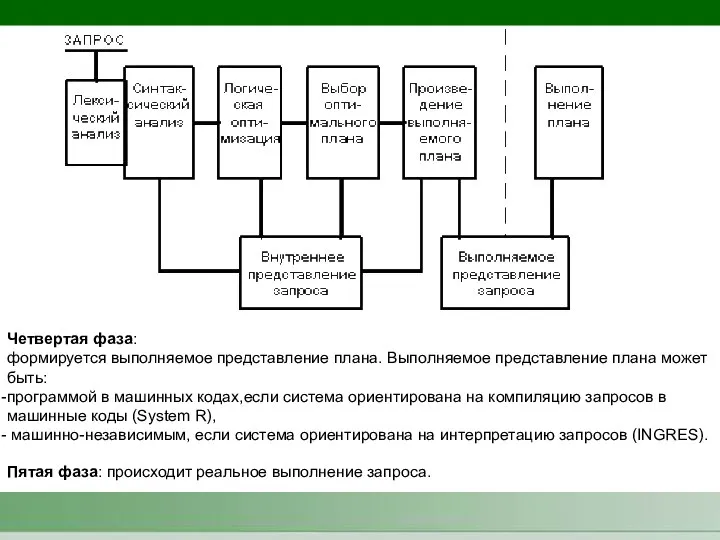
Четвертая фаза:
формируется выполняемое представление плана. Выполняемое представление плана может быть:
программой в
Четвертая фаза:
формируется выполняемое представление плана. Выполняемое представление плана может быть:
программой в

Вопрос 2. Синтаксическая оптимизация запросов
На этапе логической оптимизации производятся эквивалентные
Вопрос 2. Синтаксическая оптимизация запросов
На этапе логической оптимизации производятся эквивалентные

предикат включает в точности два имени поля разных отношений (или
предикат включает в точности два имени поля разных отношений (или

2.2 Преобразования запросов с изменением порядка реляционных операций
В оптимизаторах распространены логические
2.2 Преобразования запросов с изменением порядка реляционных операций
В оптимизаторах распространены логические

Поэтому естественно стремиться к такому преобразованию запроса, содержащего предикаты со вложенными
Поэтому естественно стремиться к такому преобразованию запроса, содержащего предикаты со вложенными

Пример
SELECT Ri.Ck FROM Ri
WHERE Ri.Ch IS IN
(
Пример
SELECT Ri.Ck FROM Ri
WHERE Ri.Ch IS IN
(

Вопрос 3. Семантическая оптимизация запросов
Рассмотренные преобразования запросов основывались на семантике
Вопрос 3. Семантическая оптимизация запросов
Рассмотренные преобразования запросов основывались на семантике

Пусть база данных состоит из отношений EMP и DEPT.
Схема отношения
Пусть база данных состоит из отношений EMP и DEPT.
Схема отношения

Если семантическая оптимизация имеет дело только со знаниями, представленными в виде
Если семантическая оптимизация имеет дело только со знаниями, представленными в виде

Оптимизирующие преобразования, рассмотренные выше, оставляют внутреннее представление запроса непроцедурным.
Процедурным планом
Оптимизирующие преобразования, рассмотренные выше, оставляют внутреннее представление запроса непроцедурным.
Процедурным планом

Обе задачи решаются на основе фиксированных встроенных в оптимизатор алгоритмов.
Оптимизатор
Обе задачи решаются на основе фиксированных встроенных в оптимизатор алгоритмов.
Оптимизатор

Генерация плана выполнения сложного запроса - это многоэтапный процесс, в ходе
Генерация плана выполнения сложного запроса - это многоэтапный процесс, в ходе

После генерации множества планов выполнения запроса нужно выбрать один, наиболее эффективный
После генерации множества планов выполнения запроса нужно выбрать один, наиболее эффективный

Рассмотрим предикат R.C op const.
Степень селективности предиката зависит:
от вида операции
Рассмотрим предикат R.C op const.
Степень селективности предиката зависит:
от вида операции

Характеристики отношения R:
T - число кортежей в данном отношении
N
Характеристики отношения R:
T - число кортежей в данном отношении
N

4.3. Более точные оценки
При отказе от предположения о равномерности распределения
4.3. Более точные оценки
При отказе от предположения о равномерности распределения

Область значений поля разбивается на N интервалов равного размера, и для
Область значений поля разбивается на N интервалов равного размера, и для

Тогда средняя оценка степени селективности (SUMi-1 + SUMi) / (2 (
Тогда средняя оценка степени селективности (SUMi-1 + SUMi) / (2 (
 Усыновление в РФ Процесс. Органы и госслужащие, а также негосударственные организации, участвующие в процессе усыновления в СПб
Усыновление в РФ Процесс. Органы и госслужащие, а также негосударственные организации, участвующие в процессе усыновления в СПб Генератор сигналов на основе звуковой платы
Генератор сигналов на основе звуковой платы Программирование на языке Паскаль
Программирование на языке Паскаль ЦВП
ЦВП Велика Британия
Велика Британия Презентация "Новые чудеса света" - скачать презентации по МХК
Презентация "Новые чудеса света" - скачать презентации по МХК Проскомидия. Первая часть Литургии
Проскомидия. Первая часть Литургии Театр Востока
Театр Востока Презентация Корпоративные социальные инвестиции. Понятие, виды, индикаторы
Презентация Корпоративные социальные инвестиции. Понятие, виды, индикаторы Диалектика
Диалектика  Язык программирования Java
Язык программирования Java Роботизированная коробка передач
Роботизированная коробка передач Теоретико-правовые основы международной системы ПОД/ФТ (противодействие отмыванию доходов и финансированию терроризма)
Теоретико-правовые основы международной системы ПОД/ФТ (противодействие отмыванию доходов и финансированию терроризма) Анализ маркетинговой деятельности компании Красный куб подзаголовок
Анализ маркетинговой деятельности компании Красный куб подзаголовок Аманкелді Үдербайұлы Иманов (03.04.1873 18.5.1919)
Аманкелді Үдербайұлы Иманов (03.04.1873 18.5.1919) Художник и учёный Урок искусства 9 класс , Учитель Сомко Е.В.
Художник и учёный Урок искусства 9 класс , Учитель Сомко Е.В.  Кровельные и гидроизоляционные материалы
Кровельные и гидроизоляционные материалы Разработка вертикально-сверлильного станка
Разработка вертикально-сверлильного станка Легкая атлетика
Легкая атлетика Поисковое продвижение (SEO)
Поисковое продвижение (SEO) Ремонт штукатурки фасада с последующей окраской водными составами
Ремонт штукатурки фасада с последующей окраской водными составами Презентация_быстрые сервисы_и_ как правильно передать показания ПУ
Презентация_быстрые сервисы_и_ как правильно передать показания ПУ Особенности организации работы по физическому развитию детей дошкольного возраста в соответствии с ФГОС ДО
Особенности организации работы по физическому развитию детей дошкольного возраста в соответствии с ФГОС ДО Галактики, виды галактик
Галактики, виды галактик Сервлеты, компоненты приложений Java 2 Platform Enterprise Edition. (Лекция 17)
Сервлеты, компоненты приложений Java 2 Platform Enterprise Edition. (Лекция 17) Система змащення двигуна УТД - 20С1
Система змащення двигуна УТД - 20С1 Христос - наша праведность (оправдание) и наше освящение
Христос - наша праведность (оправдание) и наше освящение Культура как система знаков
Культура как система знаков