- Синтаксис директивы parallel

Содержание
- 2. ОПЦИЯ COLLAPSE collapse(n) — n последовательных тесновложенных циклов ассоциируется с данной директивой. Для циклов образуется общее
- 3. ОПЦИЯ ORDERED Опция для указания о том, что в цикле могут встречаться директивы ordered. В этом
- 4. ОПЦИЯ NOWAIT По умолчанию в конце параллельного цикла происходит неявная барьерная синхронизация параллельно работающих тредов –
- 5. ПРИМЕР #include #define CHUNKSIZE 100 #define N 1000 main () { int i, chunk; float a[N],
- 6. ЗАКЛЮЧЕНИЕ ПО РАСПАРАЛЛЕЛИВАНИЮ ЦИКЛОВ При распараллеливании цикла надо убедиться в том, что итерации данного цикла не
- 7. ДИРЕКТИВА SECTIONS Используется для реализации функционального параллелизма. Эта директива определяет набор независимых секций кода, каждая из
- 8. СИНТАКСИС ДИРЕКТИВЫ SECTIONS #pragma omp sections [опции ...] newline private (list) firstprivate (list) lastprivate (list) reduction
- 9. ПРИМЕР int main() { int n; #pragma omp parallel private(n) { n=omp_get_thread_num(); #pragma omp sections {
- 10. Перед первым участком кода в блоке sections директива section не обязательна. Какие треды будут выполнять какую
- 11. Опция lastprivate определенно связана с последней section: int n=0; #pragma omp parallel { #pragma omp sections
- 12. Переменная n объявлена как lastprivate. Три треда, выполняющие секции section, присваивают своей локальным копиям n разные
- 13. С. – ожидание одних (выполняющихся тредов) другими (уже выполненными). С. действует в некоторых случаях (см. ранее
- 14. Синтаксис директивы: #pragma omp barrier Треды, выполняющие текущую параллельную область, дойдя до этой директивы, останавливаются и
- 15. #pragma omp parallel { printf("Message 1\n"); printf("Message 2\n"); #pragma omp barrier printf("Message 3\n"); } Выдачи разных
- 16. Синтаксис директивы: #pragma omp ordered { ... } Директива определяет блок внутри параллельного цикла, который должен
- 17. Для вложенных циклов выделенный блок операторов относится к самому внутреннему из циклов. Тред, выполняющий первую итерацию
- 18. int i, n; omp_set_num_threads(4); #pragma omp parallel private (i, n) { n=omp_get_thread_num(); #pragma omp for ordered
- 19. В результате: первая выдача будет неупорядоченной, вторая идёт в порядке по возрастанию номера итерации. ПРИМЕР –
- 20. В коде можно выделять критические разделы. С помощью критических разделов можно предотвратить одновременный доступ к одному
- 21. Синтаксис директивы: #pragma omp critical [name] { ... } ДИРЕКТИВА CRITICAL
- 22. В каждый момент времени критический раздел может выполнять не более одного треда. Если критический раздел уже
- 23. main() { int x; x = 0; #pragma omp parallel shared(x) { #pragma omp critical x
- 24. Блок выполняется единственным тредом Синтаксис директивы: #pragma omp single [опции ...] newline private (list) firstprivate (list)
- 25. После выполнения треда новые значения переменных списка будут доступны всем одноименным частным переменным (private и firstprivate),
- 26. int n; #pragma omp parallel private(n) { n=omp_get_thread_num(); printf("n (start): %d\n", n); #pragma omp single copyprivate(n)
- 27. Блок выполняется единственным master-тредом. Остальные треды пропускают блок и продолжают работу с оператора, расположенного за ним.
- 28. Используется для корректного обновления общих переменных. Применяется к отдельному оператору типа присваивания. Синтаксис директивы: #pragma omp
- 29. statement_expression: x op= expr;//составное присваивание x = x op expr; x++; ++x; x--; --x; х –
- 30. На время выполнения оператора блокируется доступ к данной переменной всем запущенным в данный момент тредам, кроме
- 31. int count = 0; #pragma omp parallel { #pragma omp atomic count++; } printf("number of threads:
- 32. Используется для согласования состояния памяти (консистентность). Синтаксис директивы: #pragma omp flush [(list)] ДИРЕКТИВА FLUSH
- 33. Значения всех переменных (или переменных из списка), временно хранящиеся в регистрах и кэш-памяти текущего треда, будут
- 35. Скачать презентацию

ОПЦИЯ COLLAPSE
collapse(n) — n последовательных тесновложенных циклов ассоциируется с данной директивой.
ОПЦИЯ COLLAPSE
collapse(n) — n последовательных тесновложенных циклов ассоциируется с данной директивой.

ОПЦИЯ ORDERED
Опция для указания о том, что в цикле могут встречаться
ОПЦИЯ ORDERED
Опция для указания о том, что в цикле могут встречаться

ОПЦИЯ NOWAIT
По умолчанию в конце параллельного цикла происходит неявная барьерная синхронизация
ОПЦИЯ NOWAIT
По умолчанию в конце параллельного цикла происходит неявная барьерная синхронизация

ПРИМЕР
#include
#define CHUNKSIZE 100
#define N 1000
main ()
{
ПРИМЕР
#include
#define CHUNKSIZE 100
#define N 1000
main ()
{

ЗАКЛЮЧЕНИЕ ПО РАСПАРАЛЛЕЛИВАНИЮ ЦИКЛОВ
При распараллеливании цикла надо убедиться в том, что
ЗАКЛЮЧЕНИЕ ПО РАСПАРАЛЛЕЛИВАНИЮ ЦИКЛОВ
При распараллеливании цикла надо убедиться в том, что

ДИРЕКТИВА SECTIONS
Используется для реализации функционального параллелизма.
Эта директива определяет набор независимых секций
ДИРЕКТИВА SECTIONS
Используется для реализации функционального параллелизма.
Эта директива определяет набор независимых секций
![СИНТАКСИС ДИРЕКТИВЫ SECTIONS #pragma omp sections [опции ...] newline private (list)](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1308376/slide-7.jpg)
СИНТАКСИС ДИРЕКТИВЫ SECTIONS
#pragma omp sections [опции ...] newline
private (list)
firstprivate
СИНТАКСИС ДИРЕКТИВЫ SECTIONS
#pragma omp sections [опции ...] newline
private (list)
firstprivate
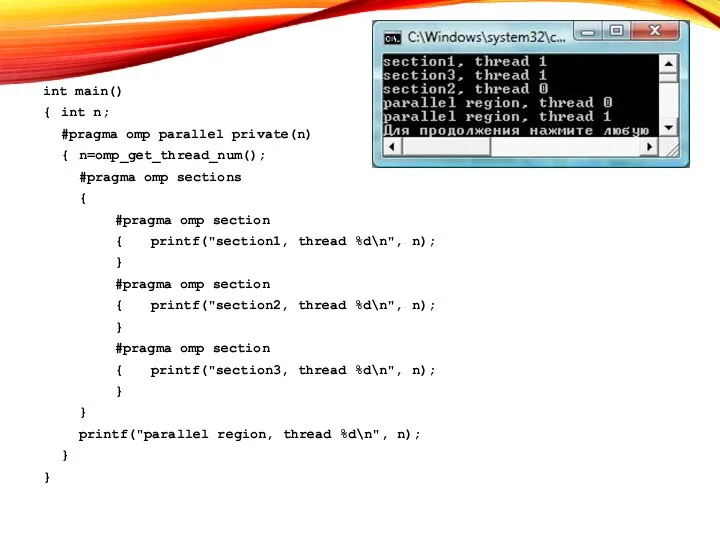
ПРИМЕР
int main()
{ int n;
#pragma omp parallel private(n)
{ n=omp_get_thread_num();
#pragma omp sections
{
#pragma omp section
{ printf("section1, thread
ПРИМЕР
int main()
{ int n;
#pragma omp parallel private(n)
{ n=omp_get_thread_num();
#pragma omp sections
{
#pragma omp section
{ printf("section1, thread

Перед первым участком кода в блоке sections директива section не обязательна.
Перед первым участком кода в блоке sections директива section не обязательна.

Опция lastprivate определенно связана с последней section:
int n=0;
#pragma omp parallel
{ #pragma omp
Опция lastprivate определенно связана с последней section:
int n=0;
#pragma omp parallel
{ #pragma omp

Переменная n объявлена как lastprivate.
Три треда, выполняющие секции section, присваивают
Переменная n объявлена как lastprivate.
Три треда, выполняющие секции section, присваивают

С. – ожидание одних (выполняющихся тредов) другими (уже выполненными).
С. действует в
С. – ожидание одних (выполняющихся тредов) другими (уже выполненными).
С. действует в

Синтаксис директивы:
#pragma omp barrier
Треды, выполняющие текущую параллельную область, дойдя до этой
Синтаксис директивы:
#pragma omp barrier
Треды, выполняющие текущую параллельную область, дойдя до этой

#pragma omp parallel
{
printf("Message 1\n");
printf("Message 2\n");
#pragma omp barrier
printf("Message 3\n");
}
Выдачи разных тредов Message
#pragma omp parallel
{
printf("Message 1\n");
printf("Message 2\n");
#pragma omp barrier
printf("Message 3\n");
}
Выдачи разных тредов Message

Синтаксис директивы:
#pragma omp ordered
{
...
}
Директива определяет блок внутри параллельного цикла, который должен
Синтаксис директивы:
#pragma omp ordered
{
...
}
Директива определяет блок внутри параллельного цикла, который должен

Для вложенных циклов выделенный блок операторов относится к самому внутреннему из
Для вложенных циклов выделенный блок операторов относится к самому внутреннему из

int i, n;
omp_set_num_threads(4);
#pragma omp parallel private (i, n)
{ n=omp_get_thread_num();
#pragma omp for ordered
for
int i, n;
omp_set_num_threads(4);
#pragma omp parallel private (i, n)
{ n=omp_get_thread_num();
#pragma omp for ordered
for
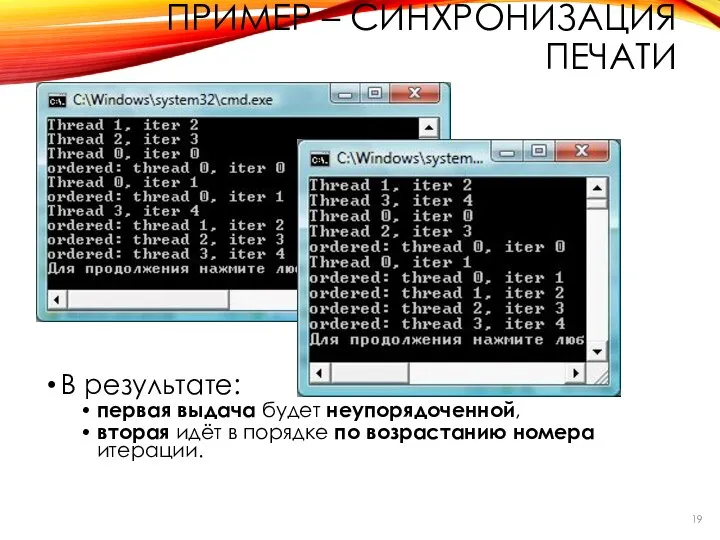
В результате:
первая выдача будет неупорядоченной,
вторая идёт в порядке по возрастанию
В результате:
первая выдача будет неупорядоченной,
вторая идёт в порядке по возрастанию

В коде можно выделять критические разделы.
С помощью критических разделов можно предотвратить
В коде можно выделять критические разделы.
С помощью критических разделов можно предотвратить
![Синтаксис директивы: #pragma omp critical [name] { ... } ДИРЕКТИВА CRITICAL](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1308376/slide-20.jpg)
Синтаксис директивы:
#pragma omp critical [name]
{
...
}
ДИРЕКТИВА CRITICAL
Синтаксис директивы:
#pragma omp critical [name]
{
...
}
ДИРЕКТИВА CRITICAL

В каждый момент времени критический раздел может выполнять не более одного
В каждый момент времени критический раздел может выполнять не более одного

main()
{
int x;
x = 0;
#pragma omp parallel shared(x)
main()
{
int x;
x = 0;
#pragma omp parallel shared(x)
![Блок выполняется единственным тредом Синтаксис директивы: #pragma omp single [опции ...]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1308376/slide-23.jpg)
Блок выполняется единственным тредом
Синтаксис директивы:
#pragma omp single [опции ...] newline
private
Блок выполняется единственным тредом
Синтаксис директивы:
#pragma omp single [опции ...] newline
private

После выполнения треда новые значения переменных списка будут доступны всем одноименным
После выполнения треда новые значения переменных списка будут доступны всем одноименным

int n;
#pragma omp parallel private(n)
{ n=omp_get_thread_num();
printf("n (start): %d\n", n);
#pragma omp single copyprivate(n)
{ n=100;
}
printf("n
int n;
#pragma omp parallel private(n)
{ n=omp_get_thread_num();
printf("n (start): %d\n", n);
#pragma omp single copyprivate(n)
{ n=100;
}
printf("n

Блок выполняется единственным master-тредом.
Остальные треды пропускают блок и продолжают работу с
Блок выполняется единственным master-тредом.
Остальные треды пропускают блок и продолжают работу с

Используется для корректного обновления общих переменных.
Применяется к отдельному оператору типа присваивания.
Синтаксис
Используется для корректного обновления общих переменных.
Применяется к отдельному оператору типа присваивания.
Синтаксис

statement_expression:
x op= expr;//составное присваивание
x = x op expr;
x++;
++x;
x--;
--x;
х – скалярная переменная,
statement_expression:
x op= expr;//составное присваивание
x = x op expr;
x++;
++x;
x--;
--x;
х – скалярная переменная,

На время выполнения оператора блокируется доступ к данной переменной всем запущенным
На время выполнения оператора блокируется доступ к данной переменной всем запущенным

int count = 0;
#pragma omp parallel
{
#pragma omp atomic
count++;
}
printf("number of threads: %d\n",
int count = 0;
#pragma omp parallel
{
#pragma omp atomic
count++;
}
printf("number of threads: %d\n",
![Используется для согласования состояния памяти (консистентность). Синтаксис директивы: #pragma omp flush [(list)] ДИРЕКТИВА FLUSH](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1308376/slide-31.jpg)
Используется для согласования состояния памяти (консистентность).
Синтаксис директивы:
#pragma omp flush [(list)]
ДИРЕКТИВА FLUSH
Используется для согласования состояния памяти (консистентность).
Синтаксис директивы:
#pragma omp flush [(list)]
ДИРЕКТИВА FLUSH

Значения всех переменных (или переменных из списка), временно хранящиеся в регистрах
Значения всех переменных (или переменных из списка), временно хранящиеся в регистрах
 Алгоритмизация вычислений
Алгоритмизация вычислений Гражданское общество и правовое государство
Гражданское общество и правовое государство Презентация Международные стандарты социального обеспечения в Германии, в Нидерландах и в Италии
Презентация Международные стандарты социального обеспечения в Германии, в Нидерландах и в Италии  Уголовная ответственность за совершение преступлений
Уголовная ответственность за совершение преступлений Обзорная лекция по спортивной физиологии
Обзорная лекция по спортивной физиологии Films. Vocabulary and Speaking
Films. Vocabulary and Speaking Технологии проектирования
Технологии проектирования  Презентация Игровая теория культуры Й.Хейзинги и Х.Ортеги-и-Гассета
Презентация Игровая теория культуры Й.Хейзинги и Х.Ортеги-и-Гассета  Появление христианства на Тверской земле
Появление христианства на Тверской земле Личностно ориентированная модель образования Учитель МОУ СОШ №1 Шмальц С.И.
Личностно ориентированная модель образования Учитель МОУ СОШ №1 Шмальц С.И. Презентация "Классификация налогов" - скачать презентации по Экономике_
Презентация "Классификация налогов" - скачать презентации по Экономике_ Тьюторские основы образования взрослых Н.П.Дерзкова, проректор АПК и ППРО
Тьюторские основы образования взрослых Н.П.Дерзкова, проректор АПК и ППРО Участие гражданина в политической жизни
Участие гражданина в политической жизни Биос - его структура и роль в компьютере. Автопроверка компьютера на разных стадиях его работы
Биос - его структура и роль в компьютере. Автопроверка компьютера на разных стадиях его работы АНДРЕЙ РУБЛЕВ
АНДРЕЙ РУБЛЕВ Народные символы и обереги
Народные символы и обереги Психология восприятия ПРЕЗЕНТАЦИЯ КУРСА «ПСИХОЛОГИЯ ВОСПРИЯТИЯ» ЧАСТЬ 2. ВОСПРИЯТИЕ ОБЪЕМА, РАССТОЯНИЯ, ДВИЖЕНИЯ ФАКТОРЫ ВОСПР
Психология восприятия ПРЕЗЕНТАЦИЯ КУРСА «ПСИХОЛОГИЯ ВОСПРИЯТИЯ» ЧАСТЬ 2. ВОСПРИЯТИЕ ОБЪЕМА, РАССТОЯНИЯ, ДВИЖЕНИЯ ФАКТОРЫ ВОСПР Реорганизация помещения 215
Реорганизация помещения 215 Аттестационная работа. Реализация программы внеурочной деятельности «Край Воронежский»
Аттестационная работа. Реализация программы внеурочной деятельности «Край Воронежский» Общеобязательные нормы, установленные государством. Право
Общеобязательные нормы, установленные государством. Право Дымковская игрушка
Дымковская игрушка Гидравлический расчет трубопроводов СГВ зданий
Гидравлический расчет трубопроводов СГВ зданий Исследование возможности использования «теплой» керамики при строительстве жилых зданий
Исследование возможности использования «теплой» керамики при строительстве жилых зданий Нанесение размеров на чертежах. Резьба и резьбовые соединения на чертежах
Нанесение размеров на чертежах. Резьба и резьбовые соединения на чертежах Общая характеристика права Древней Греции
Общая характеристика права Древней Греции На помощь сказочным героям Вперёд, в сказочную страну!!!
На помощь сказочным героям Вперёд, в сказочную страну!!! «Мы первыми сумели на Земле открыть Вселенной запертые двери» 100 лет со дня рождения С.П.Королёва 150 лет со дня рождения К.Э. Циолко
«Мы первыми сумели на Земле открыть Вселенной запертые двери» 100 лет со дня рождения С.П.Королёва 150 лет со дня рождения К.Э. Циолко Итальянцы: национальный характер
Итальянцы: национальный характер