- Директивы OpenMP - parallel

Содержание
- 2. СИНТАКСИС ДИРЕКТИВЫ PARALLEL #pragma omp parallel [опции ...] newline { } if (scalar_expression) num_threads (integer_expression) private
- 3. ОПЦИЯ IF if (scalar_expression) – распараллеливание по условию. Если значение выражения ≠ 0, то осуществляется распараллеливание.
- 4. ПРИМЕР #include #include using namespace std; int main() { int n; cout cout cin >> n;
- 5. ОПЦИЯ NUM_THREADS num_threads (integer_expression) – явное задание количества тредов, которые будут выполнять операторы параллельной области. По
- 6. ПРИМЕР #include #include using namespace std; int main() { int n; cout cout cin >> n;
- 7. ЧЕМ ОПРЕДЕЛЯЕТСЯ КОЛИЧЕСТВО ТРЕДОВ? Количество тредов в параллельной области определяется следующими параметрами в порядке старшинства: Значением
- 8. ОПЦИИ ДОСТУПНОСТИ ДАННЫХ Данные – Разделяемые, или общие (для всех тредов) Локальные (копии в каждом треде).
- 9. ОПЦИЯ PRIVATE private (list) - задаёт список переменных, для которых создается локальная копия в каждом треде.
- 10. ПРИМЕР float s = 0; #pragma omp parallel private(s) { s = s + 1;//некорректно }
- 11. ОПЦИЯ FIRSTPRIVATE firstprivate (list) - задаёт список переменных, для которых создается локальная копия в каждом треде.
- 12. ПРИМЕР float s = 0; #pragma omp parallel firstprivate(s) { s = s + 1;//корректно }
- 13. ОПЦИЯ SHARED shared (list) - задаёт список переменных, которые являются общими для всех тредов. Переменные должны
- 14. ОПЦИЯ DEFAULT default (shared|none) default (shared) всем переменным в параллельной области, которым явно не назначена локализация,
- 15. ОПЦИЯ REDUCTION reduction (operator: list) operator: +, *, -, &, |, ^, &&, || задаёт оператор
- 16. ПРИМЕР ... int n = 0; #pragma omp parallel reduction (+: n) { n++; cout cout
- 17. ДИРЕКТИВЫ OPENMP – PARALLEL FOR Основная директива для распараллеливания вычислений (распределения итераций цикла между тредами) .
- 18. ОГРАНИЧЕНИЯ НА ПАРАЛЛЕЛЬНЫЕ ЦИКЛЫ Результат программы не зависит от того, какой именно тред выполнит конкретную итерацию
- 19. СИНТАКСИС ДИРЕКТИВЫ PARALLEL FOR #pragma omp parallel for[опции ...] newline { ...for ... } schedule (type
- 20. СИНТАКСИС ДИРЕКТИВЫ FOR #pragma omp for[опции ...] newline { ...for ... } Используется внутри параллельной области,
- 21. ПРИМЕР: ВЫЧИСЛЕНИЕ СУММЫ void main () { int i; double ZZ, res=0.0; omp_set_num_threads(2) #pragma omp parallel
- 22. ОЦЕНКА ВРЕМЕНИ ВЫПОЛНЕНИЯ ПОСЛЕДОВАТЕЛЬНОЙ И ПАРАЛЛЕЛЬНОЙ ПРОГРАММ Функция double omp_get_wtime() возвращает в вызвавшем треде время в
- 23. ПРИМЕР ЗАМЕРА ВРЕМЕНИ ... double start_time, end_time, tick; start_time = omp_get_wtime(); ... end_time = omp_get_wtime(); tick
- 24. ПРИМЕР: ВЫЧИСЛЕНИЕ ЧИСЛА Π
- 25. ПРИМЕР: ВЫЧИСЛЕНИЕ ЧИСЛА Π void main () { long num_steps; cout cin >> num_steps; double step
- 26. ОПЦИИ ДИРЕКТИВЫ PARALLEL FOR #pragma omp parallel for[опции ...] newline { ...for ... } schedule (type
- 27. ОПЦИЯ LASTPRIVATE lastprivate (list) переменным из списка присваивается результат с последней итерации цикла - значение из
- 28. ОПЦИЯ SCHEDULE – УПРАВЛЕНИЕ НАГРУЗКОЙ schedule (type [,num_iters]) В зависимости от параметров (type, num_iters) выполнение итераций
- 29. STATIC – СТАТИЧЕСКОЕ РАСПРЕДЕЛЕНИЕ ЗАГРУЗКИ ТРЕДОВ: - КАЖДЫЙ ТРЕД (С НУЛЕВОГО) БЕРЕТ ДЛЯ ВЫПОЛНЕНИЯ БЛОК ИЗ
- 30. DYNAMIC – ДИНАМИЧЕСКОЕ РАСПРЕДЕЛЕНИЕ ЗАГРУЗКИ ТРЕДОВ: КАЖДЫЙ ТРЕД БЕРЕТ ДЛЯ ВЫПОЛНЕНИЯ БЛОК ИЗ ИТЕРАЦИЙ ЦИКЛА. ОСВОБОДИВШИЕСЯ
- 31. GUIDED – ДИНАМИЧЕСКОЕ РАСПРЕДЕЛЕНИЕ ЗАГРУЗКИ ТРЕДОВ: - КАЖДЫЙ ТРЕД БЕРЕТ ДЛЯ ВЫПОЛНЕНИЯ N0 (ЗАВИСИТ ОТ РЕАЛИЗАЦИИ)
- 32. RUNTIME – ДИНАМИЧЕСКОЕ РАСПРЕДЕЛЕНИЕ ЗАГРУЗКИ ТРЕДОВ CПОСОБ РАСПРЕДЕЛЕНИЯ ИТЕРАЦИЙ ВЫБИРАЕТСЯ ВО ВРЕМЯ РАБОТЫ ПРОГРАММЫ ПО ЗНАЧЕНИЮ
- 33. ПРИМЕР 1 #include #include #include int main(int argc, char *argv[]) {int i; #pragma omp parallel private(i)
- 34. РЕЗУЛЬТАТ
- 35. ЗАДАНИЕ Варьируя число итераций, тредов и размер начального блока, проанализировать распределение итераций по тредам. Изменяется ли
- 36. ПРИМЕР 2 msdn.microsoft.com/ru-ru/library/x5aw0hdf(v=vs.90).aspx
- 37. ЗАДАНИЕ Протестировать программу, изменяя значения основных параметров. Отобразить результат графически. Для каких режимов существенно количество тредов?
- 38. ПРИМЕР ИЛЛЮСТРАЦИИ
- 39. ОПЦИЯ COLLAPSE collapse(n) — n последовательных тесновложенных циклов ассоциируется с данной директивой. Для циклов образуется общее
- 40. ОПЦИЯ ORDERED Опция для указания о том, что в цикле могут встречаться директивы ordered. В этом
- 41. ОПЦИЯ NOWAIT По умолчанию в конце параллельного цикла происходит неявная барьерная синхронизация параллельно работающих тредов –
- 42. ПРИМЕР #include #define CHUNKSIZE 100 #define N 1000 main () { int i, chunk; float a[N],
- 43. ЗАКЛЮЧЕНИЕ ПО РАСПАРАЛЛЕЛИВАНИЮ ЦИКЛОВ При распараллеливании цикла надо убедиться в том, что итерации данного цикла не
- 44. ДИРЕКТИВА SECTIONS Используется для реализации функционального параллелизма. Эта директива определяет набор независимых секций кода, каждая из
- 45. СИНТАКСИС ДИРЕКТИВЫ SECTIONS #pragma omp sections [опции ...] newline private (list) firstprivate (list) lastprivate (list) reduction
- 47. Скачать презентацию
![СИНТАКСИС ДИРЕКТИВЫ PARALLEL #pragma omp parallel [опции ...] newline { }](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1308375/slide-1.jpg)
СИНТАКСИС ДИРЕКТИВЫ PARALLEL
#pragma omp parallel [опции ...] newline
{
}
if (scalar_expression)
num_threads (integer_expression)
private
СИНТАКСИС ДИРЕКТИВЫ PARALLEL
#pragma omp parallel [опции ...] newline
{
}
if (scalar_expression)
num_threads (integer_expression)
private

ОПЦИЯ IF
if (scalar_expression)
– распараллеливание по условию.
Если значение выражения ≠ 0,
то
ОПЦИЯ IF
if (scalar_expression)
– распараллеливание по условию.
Если значение выражения ≠ 0,
то
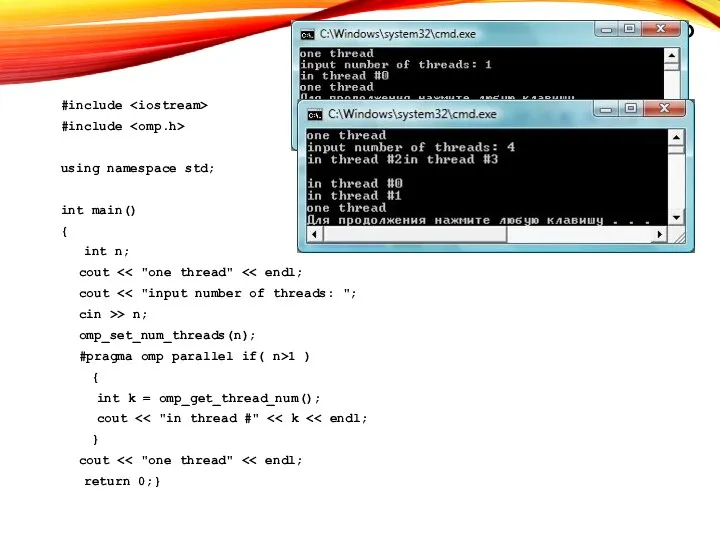
ПРИМЕР
#include
#include
using namespace std;
int main()
{
int n;
cout << "one thread"
ПРИМЕР
#include
#include
using namespace std;
int main()
{
int n;
cout << "one thread"

ОПЦИЯ NUM_THREADS
num_threads (integer_expression)
– явное задание количества тредов,
которые будут выполнять операторы
ОПЦИЯ NUM_THREADS
num_threads (integer_expression)
– явное задание количества тредов,
которые будут выполнять операторы
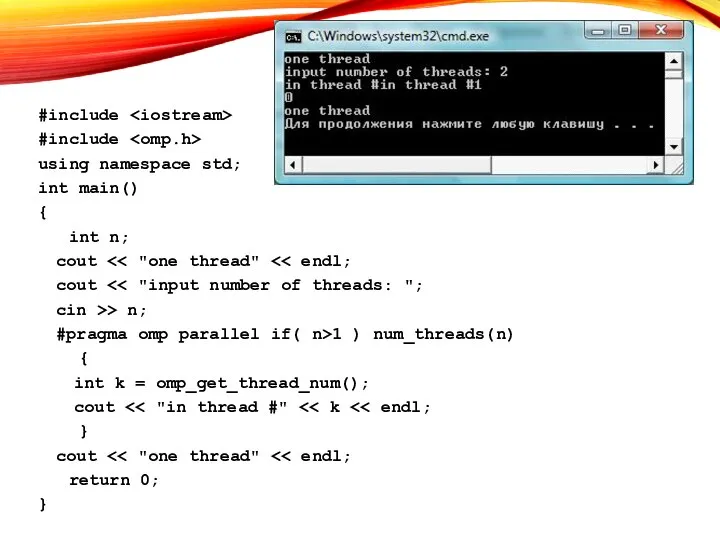
ПРИМЕР
#include
#include
using namespace std;
int main()
{
int n;
cout << "one thread"
ПРИМЕР
#include
#include
using namespace std;
int main()
{
int n;
cout << "one thread"

ЧЕМ ОПРЕДЕЛЯЕТСЯ КОЛИЧЕСТВО ТРЕДОВ?
Количество тредов в параллельной области определяется следующими параметрами
ЧЕМ ОПРЕДЕЛЯЕТСЯ КОЛИЧЕСТВО ТРЕДОВ?
Количество тредов в параллельной области определяется следующими параметрами

ОПЦИИ ДОСТУПНОСТИ ДАННЫХ
Данные –
Разделяемые, или общие (для всех тредов)
Локальные (копии в
ОПЦИИ ДОСТУПНОСТИ ДАННЫХ
Данные –
Разделяемые, или общие (для всех тредов)
Локальные (копии в

ОПЦИЯ PRIVATE
private (list)
- задаёт список переменных, для которых создается локальная копия
ОПЦИЯ PRIVATE
private (list)
- задаёт список переменных, для которых создается локальная копия

ПРИМЕР
float s = 0;
#pragma omp parallel private(s)
{
s = s + 1;//некорректно
}
Значение
ПРИМЕР
float s = 0;
#pragma omp parallel private(s)
{
s = s + 1;//некорректно
}
Значение

ОПЦИЯ FIRSTPRIVATE
firstprivate (list)
- задаёт список переменных, для которых создается локальная копия
ОПЦИЯ FIRSTPRIVATE
firstprivate (list)
- задаёт список переменных, для которых создается локальная копия

ПРИМЕР
float s = 0;
#pragma omp parallel firstprivate(s)
{
s = s + 1;//корректно
}
Значение
ПРИМЕР
float s = 0;
#pragma omp parallel firstprivate(s)
{
s = s + 1;//корректно
}
Значение

ОПЦИЯ SHARED
shared (list)
- задаёт список переменных, которые являются общими для всех
ОПЦИЯ SHARED
shared (list)
- задаёт список переменных, которые являются общими для всех

ОПЦИЯ DEFAULT
default (shared|none)
default (shared)
всем переменным в параллельной области, которым явно не
ОПЦИЯ DEFAULT
default (shared|none)
default (shared)
всем переменным в параллельной области, которым явно не

ОПЦИЯ REDUCTION
reduction (operator: list)
operator: +, *, -, &, |, ^,
ОПЦИЯ REDUCTION
reduction (operator: list)
operator: +, *, -, &, |, ^,

ПРИМЕР
...
int n = 0;
#pragma omp parallel reduction (+: n)
{
n++;
cout << "Текущее
ПРИМЕР
...
int n = 0;
#pragma omp parallel reduction (+: n)
{
n++;
cout << "Текущее

ДИРЕКТИВЫ OPENMP – PARALLEL FOR
Основная директива для распараллеливания вычислений (распределения итераций
ДИРЕКТИВЫ OPENMP – PARALLEL FOR
Основная директива для распараллеливания вычислений (распределения итераций

ОГРАНИЧЕНИЯ НА ПАРАЛЛЕЛЬНЫЕ ЦИКЛЫ
Результат программы не зависит от того,
какой именно
ОГРАНИЧЕНИЯ НА ПАРАЛЛЕЛЬНЫЕ ЦИКЛЫ
Результат программы не зависит от того, какой именно
![СИНТАКСИС ДИРЕКТИВЫ PARALLEL FOR #pragma omp parallel for[опции ...] newline {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1308375/slide-18.jpg)
СИНТАКСИС ДИРЕКТИВЫ PARALLEL FOR
#pragma omp parallel for[опции ...] newline
{ ...for ...
}
schedule (type
СИНТАКСИС ДИРЕКТИВЫ PARALLEL FOR
#pragma omp parallel for[опции ...] newline
{ ...for ...
}
schedule (type
![СИНТАКСИС ДИРЕКТИВЫ FOR #pragma omp for[опции ...] newline { ...for ...](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1308375/slide-19.jpg)
СИНТАКСИС ДИРЕКТИВЫ FOR
#pragma omp for[опции ...] newline
{ ...for ...
}
Используется внутри параллельной области,
СИНТАКСИС ДИРЕКТИВЫ FOR
#pragma omp for[опции ...] newline
{ ...for ...
}
Используется внутри параллельной области,

ПРИМЕР: ВЫЧИСЛЕНИЕ СУММЫ
void main ()
{
int i;
double ZZ, res=0.0;
omp_set_num_threads(2)
#pragma omp parallel for
ПРИМЕР: ВЫЧИСЛЕНИЕ СУММЫ
void main ()
{
int i;
double ZZ, res=0.0;
omp_set_num_threads(2)
#pragma omp parallel for

ОЦЕНКА ВРЕМЕНИ ВЫПОЛНЕНИЯ ПОСЛЕДОВАТЕЛЬНОЙ И ПАРАЛЛЕЛЬНОЙ ПРОГРАММ
Функция double omp_get_wtime()
возвращает в
ОЦЕНКА ВРЕМЕНИ ВЫПОЛНЕНИЯ ПОСЛЕДОВАТЕЛЬНОЙ И ПАРАЛЛЕЛЬНОЙ ПРОГРАММ
Функция double omp_get_wtime() возвращает в

ПРИМЕР ЗАМЕРА ВРЕМЕНИ
...
double start_time, end_time, tick;
start_time = omp_get_wtime();
...
end_time = omp_get_wtime();
tick =
ПРИМЕР ЗАМЕРА ВРЕМЕНИ
...
double start_time, end_time, tick;
start_time = omp_get_wtime();
...
end_time = omp_get_wtime();
tick =
ПРИМЕР: ВЫЧИСЛЕНИЕ ЧИСЛА Π
ПРИМЕР: ВЫЧИСЛЕНИЕ ЧИСЛА Π

ПРИМЕР: ВЫЧИСЛЕНИЕ ЧИСЛА Π
void main ()
{ long num_steps;
cout << "number
ПРИМЕР: ВЫЧИСЛЕНИЕ ЧИСЛА Π
void main ()
{ long num_steps;
cout << "number
![ОПЦИИ ДИРЕКТИВЫ PARALLEL FOR #pragma omp parallel for[опции ...] newline {](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1308375/slide-25.jpg)
ОПЦИИ ДИРЕКТИВЫ PARALLEL FOR
#pragma omp parallel for[опции ...] newline
{ ...for ...
}
schedule (type
ОПЦИИ ДИРЕКТИВЫ PARALLEL FOR
#pragma omp parallel for[опции ...] newline
{ ...for ...
}
schedule (type

ОПЦИЯ LASTPRIVATE
lastprivate (list)
переменным из списка присваивается результат с последней итерации
ОПЦИЯ LASTPRIVATE
lastprivate (list)
переменным из списка присваивается результат с последней итерации
![ОПЦИЯ SCHEDULE – УПРАВЛЕНИЕ НАГРУЗКОЙ schedule (type [,num_iters]) В зависимости от](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1308375/slide-27.jpg)
ОПЦИЯ SCHEDULE – УПРАВЛЕНИЕ НАГРУЗКОЙ
schedule (type [,num_iters])
В зависимости от параметров (type,
ОПЦИЯ SCHEDULE – УПРАВЛЕНИЕ НАГРУЗКОЙ
schedule (type [,num_iters])
В зависимости от параметров (type,

STATIC – СТАТИЧЕСКОЕ РАСПРЕДЕЛЕНИЕ
ЗАГРУЗКИ ТРЕДОВ:
- КАЖДЫЙ ТРЕД (С НУЛЕВОГО) БЕРЕТ
STATIC – СТАТИЧЕСКОЕ РАСПРЕДЕЛЕНИЕ ЗАГРУЗКИ ТРЕДОВ: - КАЖДЫЙ ТРЕД (С НУЛЕВОГО) БЕРЕТ

DYNAMIC – ДИНАМИЧЕСКОЕ РАСПРЕДЕЛЕНИЕ ЗАГРУЗКИ ТРЕДОВ:
КАЖДЫЙ ТРЕД БЕРЕТ ДЛЯ ВЫПОЛНЕНИЯ
DYNAMIC – ДИНАМИЧЕСКОЕ РАСПРЕДЕЛЕНИЕ ЗАГРУЗКИ ТРЕДОВ: КАЖДЫЙ ТРЕД БЕРЕТ ДЛЯ ВЫПОЛНЕНИЯ

GUIDED – ДИНАМИЧЕСКОЕ РАСПРЕДЕЛЕНИЕ ЗАГРУЗКИ ТРЕДОВ:
- КАЖДЫЙ ТРЕД БЕРЕТ ДЛЯ
GUIDED – ДИНАМИЧЕСКОЕ РАСПРЕДЕЛЕНИЕ ЗАГРУЗКИ ТРЕДОВ: - КАЖДЫЙ ТРЕД БЕРЕТ ДЛЯ

RUNTIME – ДИНАМИЧЕСКОЕ РАСПРЕДЕЛЕНИЕ ЗАГРУЗКИ ТРЕДОВ
CПОСОБ РАСПРЕДЕЛЕНИЯ ИТЕРАЦИЙ ВЫБИРАЕТСЯ
ВО
RUNTIME – ДИНАМИЧЕСКОЕ РАСПРЕДЕЛЕНИЕ ЗАГРУЗКИ ТРЕДОВ CПОСОБ РАСПРЕДЕЛЕНИЯ ИТЕРАЦИЙ ВЫБИРАЕТСЯ ВО
![ПРИМЕР 1 #include #include #include int main(int argc, char *argv[]) {int](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1308375/slide-32.jpg)
ПРИМЕР 1
#include
#include
#include
int main(int argc, char *argv[])
{int i;
#pragma omp
ПРИМЕР 1
#include
#include
#include
int main(int argc, char *argv[])
{int i;
#pragma omp
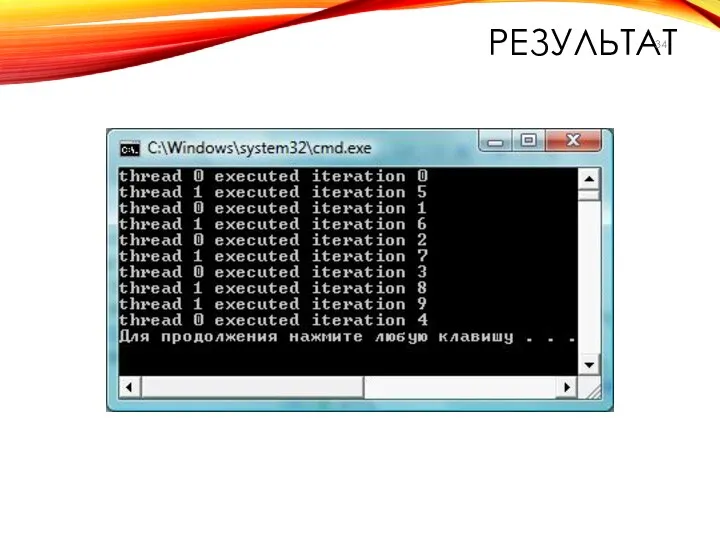
РЕЗУЛЬТАТ
РЕЗУЛЬТАТ

ЗАДАНИЕ
Варьируя число итераций, тредов и размер начального блока, проанализировать распределение итераций
ЗАДАНИЕ
Варьируя число итераций, тредов и размер начального блока, проанализировать распределение итераций

ПРИМЕР 2 msdn.microsoft.com/ru-ru/library/x5aw0hdf(v=vs.90).aspx
ПРИМЕР 2 msdn.microsoft.com/ru-ru/library/x5aw0hdf(v=vs.90).aspx

ЗАДАНИЕ
Протестировать программу, изменяя значения основных параметров.
Отобразить результат графически.
Для каких режимов существенно
ЗАДАНИЕ
Протестировать программу, изменяя значения основных параметров.
Отобразить результат графически.
Для каких режимов существенно
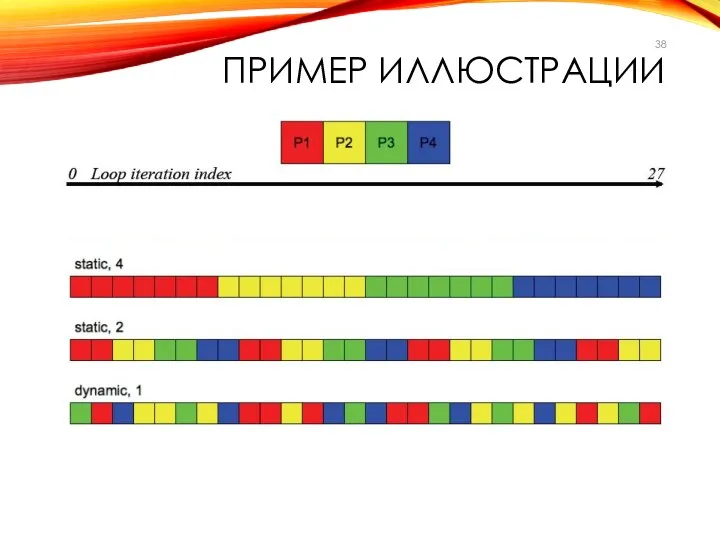
ПРИМЕР ИЛЛЮСТРАЦИИ
ПРИМЕР ИЛЛЮСТРАЦИИ

ОПЦИЯ COLLAPSE
collapse(n) — n последовательных тесновложенных циклов ассоциируется с данной директивой.
ОПЦИЯ COLLAPSE
collapse(n) — n последовательных тесновложенных циклов ассоциируется с данной директивой.

ОПЦИЯ ORDERED
Опция для указания о том, что в цикле могут встречаться
ОПЦИЯ ORDERED
Опция для указания о том, что в цикле могут встречаться

ОПЦИЯ NOWAIT
По умолчанию в конце параллельного цикла происходит неявная барьерная синхронизация
ОПЦИЯ NOWAIT
По умолчанию в конце параллельного цикла происходит неявная барьерная синхронизация

ПРИМЕР
#include
#define CHUNKSIZE 100
#define N 1000
main ()
{
ПРИМЕР
#include
#define CHUNKSIZE 100
#define N 1000
main ()
{

ЗАКЛЮЧЕНИЕ ПО РАСПАРАЛЛЕЛИВАНИЮ ЦИКЛОВ
При распараллеливании цикла надо убедиться в том, что
ЗАКЛЮЧЕНИЕ ПО РАСПАРАЛЛЕЛИВАНИЮ ЦИКЛОВ
При распараллеливании цикла надо убедиться в том, что

ДИРЕКТИВА SECTIONS
Используется для реализации функционального параллелизма.
Эта директива определяет набор независимых секций
ДИРЕКТИВА SECTIONS
Используется для реализации функционального параллелизма.
Эта директива определяет набор независимых секций
![СИНТАКСИС ДИРЕКТИВЫ SECTIONS #pragma omp sections [опции ...] newline private (list)](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1308375/slide-44.jpg)
СИНТАКСИС ДИРЕКТИВЫ SECTIONS
#pragma omp sections [опции ...] newline
private (list)
firstprivate
СИНТАКСИС ДИРЕКТИВЫ SECTIONS
#pragma omp sections [опции ...] newline
private (list)
firstprivate
 Женская и мужская сборные Казахстана по волейболу
Женская и мужская сборные Казахстана по волейболу Теоретическая механика. Основная литература (для заочников)
Теоретическая механика. Основная литература (для заочников) Методические особенности освоения технологии обработки графической и мультимедийной информации
Методические особенности освоения технологии обработки графической и мультимедийной информации Управление в обществе с ограниченной ответственностью Выполнила студентка 2го курса юридического факультета Червона Алена
Управление в обществе с ограниченной ответственностью Выполнила студентка 2го курса юридического факультета Червона Алена  Механизмдегі күштерді жіктеу
Механизмдегі күштерді жіктеу Клеефанерные балки
Клеефанерные балки  Диоды с переменной емкостью
Диоды с переменной емкостью огурец - презентация для начальной школы_
огурец - презентация для начальной школы_ Наноқұрылымды материалдар, олардың қасиеттері және практикада қолданылуы
Наноқұрылымды материалдар, олардың қасиеттері және практикада қолданылуы Презентация "Программа Неменского по Изо" - скачать презентации по МХК
Презентация "Программа Неменского по Изо" - скачать презентации по МХК Метрические задачи
Метрические задачи Понятие и виды деловой карьеры
Понятие и виды деловой карьеры Презентация Культура Византии
Презентация Культура Византии Проектирование БД
Проектирование БД Акмеология ФК и С
Акмеология ФК и С Dynamic of mas point
Dynamic of mas point ИНФАРКТ МИОКАРДА
ИНФАРКТ МИОКАРДА  Кампилобактерии, хеликобактерии
Кампилобактерии, хеликобактерии История праздника Halloween
История праздника Halloween Рынок и рыночная экономика Создатель: Семкова Н.В. – учитель истории и обществознания МКОУ «СОШ №10, г. Нижняя Салда, Свердловской
Рынок и рыночная экономика Создатель: Семкова Н.В. – учитель истории и обществознания МКОУ «СОШ №10, г. Нижняя Салда, Свердловской  Боевая хирургическая травма
Боевая хирургическая травма Вакцины, вакцинация и их роль в общественном здравоохранении Michael O. Favorov M.D., Ph.D., D.Sc. Проф., д.м.н. Михаил Олегович Фаворов Deputy
Вакцины, вакцинация и их роль в общественном здравоохранении Michael O. Favorov M.D., Ph.D., D.Sc. Проф., д.м.н. Михаил Олегович Фаворов Deputy  Понятие симметрии
Понятие симметрии  Презентация "Тайная вечеря" - скачать презентации по МХК
Презентация "Тайная вечеря" - скачать презентации по МХК Презентация Страхование школьников
Презентация Страхование школьников ЦЕНТР МЕДИЦИНЫ СНА г. Челябинск
ЦЕНТР МЕДИЦИНЫ СНА г. Челябинск Тема №6 «Скрытие данных». Занятие №3/4 «Встраивание информации за счет изменения времени задержки эхо-сигнала»
Тема №6 «Скрытие данных». Занятие №3/4 «Встраивание информации за счет изменения времени задержки эхо-сигнала» Т14 РТС УР.ppt
Т14 РТС УР.ppt