- Технологии параллельных вычислений

Содержание
- 2. План Общие сведения Основные схемы параллельных систем Многопоточность OpenMP Обмен сообщениями MPI PVM Linda
- 3. Литература Спецификация OpenMP http://www.openmp.org/drupal/ MPI http://www-unix.mcs.anl.gov/mpi/
- 4. Особенности технологий для параллельных вычислений Параллелизм используется для ускорения вычислений Необходимы технологии, рассчитанные на быстрый обмен
- 5. Требования к параллельным вычислениям Одновременная работа нескольких устройств Устройства не должны простаивать в ожидании на что-либо
- 6. Модели параллельных вычислений Общая (разделяемая) память Многопоточность Распределенная память Обмен сообщениями
- 7. Топологии параллельных систем Различные устройства связаны между собой Структура связей между различными устройствами называется топологией параллельной
- 8. Примеры топологий звезда Линейка (ферма) решетка
- 9. Классы параллельных систем SISD SIMD MIMD
- 10. Цель созданий программных технологий параллельных вычислений Простая реализация Моделей Топологий Классов Декомпозиции Связи Синхронизации Частично используются
- 11. Создание параллельных программ в модели с общей памятью API операционной системы (стандарт POSIX) Порождение процессов Сигналы
- 12. Создание параллельных программ с обменом сообщениями API операционных систем Сокеты Стандарты MPI PVM Linda
- 13. Языки программирования с поддержкой параллелизма Поддержка автопараллелизма Pg[C, C++, Fortran] (Portland Group) Adaptor - Fortran Absoft
- 14. Процессы Процесс – код выполняющийся в отдельном адресном пространстве Множество процессов может выполняться на одной машине
- 15. Составные части процесса Память Сегменты кода Сегменты данных Сегменты стека Стек задачи Стек ядра Другие сегменты
- 16. Память Физическая память разбита на страницы (обычно фиксированного размера) Страницы объединяются в виртуальные области (сегменты) Каждый
- 17. Файловая система Системные вызовы open close read write Операционная система транслирует эти вызовы в специфические вызовы
- 18. Порождение процессов Один процесс может создать другой процесс Оба процесса будут выполняться параллельно fork+exec spawn Процесс
- 19. Особенности fork+exec и spawn fork Порожденный процесс наследует все ресурсы родителя! Порожденный процесс начинает выполняться с
- 20. Доступ к файловой системе В UNIX системах по возможности все реализовано как файл Обычные файлы open
- 21. Работа с файловой системой Открываем файл, канал, сокет open(), pipe(), socket() запись write() Чтение read() Закрываем
- 22. Память общего доступа Процесс создает область общей памяти Другие процессы присоединяют эту область к себе Все
- 23. Конфликты при обращении к общим ресурсам: a – общая переменная Процесс1 : считываем a=1 Процесс1 :
- 24. Семафоры Семафор – совместно используемая атомарная целочисленная переменная В каждый момент времени изменять значение семафора может
- 25. Синхронизация с помощью семафоров Процесс 1 Создать семафор Присвоить семафору 1 Уменьшить семафор на 1 (семафор
- 26. Сигналы Сигнал – аналог прерывания Асинхронное событие – неизвестно когда произойдет Один процесс может послать другому
- 27. Потоки Часть процесса, которая выполняется параллельно другими частями процесса Все ресурсы потоков - общие Для создания
- 28. Стандарт OpenMP OpenMP – стандарт который включает директивы компилятора, библиотеки и системные переменные, которые могут быть
- 29. Пример OpenMP int main (void){ int i; int k = 0; #pragma omp parallel for default(shared)
- 30. Обмен сообщениями Когда процессы работают на разных машинах, то доступ к одним и тем же данным
- 31. Системные API Сокеты – независимый от протокола интерфейс, который позволяет организовать взаимодействие между процессами в сети
- 32. Сокет Серверный процесс socket() – создание сокета bind() – назначение адреса listen() – перевод в режим
- 33. Диаграмма работы с сокетами Сервер socket() Создаем сокет bind() Назначаем адрес и порт cluster.univ.kiev.ua:22 listen() Переводим
- 34. Синхронный и асинхронный обмен Синхронный вызов – функции send(), recv(), accept(), connect() блокируются пока не будет
- 35. API для асинхронных операций ввода-вывода select(), poll() – проверка состояния сокетов Функция возвращает может ли блокирующий
- 36. Сравнение синхронного и асинхронного ввода-вывода Синхронный Простота программирования Меньшее количество ошибок Неэффективен для параллельных программ Обычно
- 37. Интерфейсы параллельного программирования Часто при написании параллельных программ приходится выполнять сложные операции обмена данными Передача от
- 38. Message Passing Interface (MPI) MPI - стандарт интерфейса (middleware) обмена сообщениями для компьютеров с распределенной памятью
- 39. Диаграмма соответвия между сокетами, MPI и др Интерфейс сокетов Интерфейсы взаимодействия с общей памятью Ядро Аппаратное
- 40. Основные определения Процесс Программа, которая выполняет свой код Процесс характеризуется только своим номером в группе Группы
- 41. Разработка и запуск MPI программ Пользователь разрабатывает программу с MPI вызовами Программа компилируется и компонуется с
- 42. Пример MPI программы int main(int argc, char* argv[]){ int my_number; //Мой номер процесса int proc_num; //общее
- 43. Результат работы MPI программы [saa@cluster mpi]$ mpirun -np 10 ./a.out I an process 0, sending data
- 44. Реализации MPI MPICH LAMMPI …. Существуют разные реализации Может отличаться все, кроме совместимости программного кода Некоторые
- 45. Parallel Virtual Machine (PVM) PVM – программные средства для создания параллельных вычислительных комплексов на базе коллекции
- 46. Основные компоненты Платформенно независимый протокол обмена и методы сериализации Библиотека libpvm3 с которой компилируются программы и
- 47. Основные операции Управление процессами Запуск pvm_spawn Обмен сигналами pvm_kill Выход pvm_exit Сериализация/десериализация Упаковка pvm_pk Распаковка pvm_up
- 48. Принцип создания параллельных программ Пользователь компилирует для всех платформ одну или несколько программ Программы помещаются каждая
- 49. Пример запуска машины PVM [saa@cluster mpi]$ pvm pvmd already running. pvm> conf conf 1 host, 1
- 50. Пример PVM программы #include #include #include int main(int argc, char* argv[]){ int p_tid, c_tid; int res;
- 51. Языки рассчитанные на параллельное программирование Обычно являются расширением к какому-либо из широко используемых языков и использую
- 53. Скачать презентацию

План
Общие сведения
Основные схемы параллельных систем
Многопоточность
OpenMP
Обмен сообщениями
MPI
PVM
Linda
План
Общие сведения
Основные схемы параллельных систем
Многопоточность
OpenMP
Обмен сообщениями
MPI
PVM
Linda

Литература
Спецификация OpenMP http://www.openmp.org/drupal/
MPI http://www-unix.mcs.anl.gov/mpi/
Литература
Спецификация OpenMP http://www.openmp.org/drupal/
MPI http://www-unix.mcs.anl.gov/mpi/

Особенности технологий для параллельных вычислений
Параллелизм используется для ускорения вычислений
Необходимы технологии, рассчитанные
Особенности технологий для параллельных вычислений
Параллелизм используется для ускорения вычислений
Необходимы технологии, рассчитанные

Требования к параллельным вычислениям
Одновременная работа нескольких устройств
Устройства не должны простаивать
Требования к параллельным вычислениям
Одновременная работа нескольких устройств
Устройства не должны простаивать

Модели параллельных вычислений
Общая (разделяемая) память
Многопоточность
Распределенная память
Обмен сообщениями
Модели параллельных вычислений
Общая (разделяемая) память
Многопоточность
Распределенная память
Обмен сообщениями

Топологии параллельных систем
Различные устройства связаны между собой
Структура связей между различными устройствами
Топологии параллельных систем
Различные устройства связаны между собой
Структура связей между различными устройствами
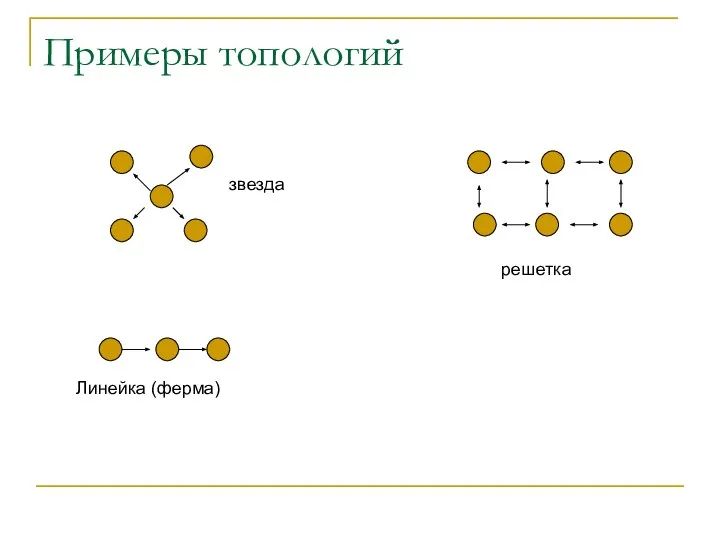
Примеры топологий
звезда
Линейка (ферма)
решетка
Примеры топологий
звезда
Линейка (ферма)
решетка

Классы параллельных систем
SISD
SIMD
MIMD
Классы параллельных систем
SISD
SIMD
MIMD

Цель созданий программных технологий параллельных вычислений
Простая реализация
Моделей
Топологий
Классов
Декомпозиции
Связи
Синхронизации
Частично используются рассмотренные ранее
Цель созданий программных технологий параллельных вычислений
Простая реализация
Моделей
Топологий
Классов
Декомпозиции
Связи
Синхронизации
Частично используются рассмотренные ранее

Создание параллельных программ в модели с общей памятью
API операционной системы
Создание параллельных программ в модели с общей памятью
API операционной системы

Создание параллельных программ с обменом сообщениями
API операционных систем
Сокеты
Стандарты
MPI
PVM
Linda
Создание параллельных программ с обменом сообщениями
API операционных систем
Сокеты
Стандарты
MPI
PVM
Linda
![Языки программирования с поддержкой параллелизма Поддержка автопараллелизма Pg[C, C++, Fortran] (Portland](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1302607/slide-12.jpg)
Языки программирования с поддержкой параллелизма
Поддержка автопараллелизма
Pg[C, C++, Fortran] (Portland Group)
Adaptor -
Языки программирования с поддержкой параллелизма
Поддержка автопараллелизма
Pg[C, C++, Fortran] (Portland Group)
Adaptor -

Процессы
Процесс – код выполняющийся в отдельном адресном пространстве
Множество процессов может выполняться
Процессы
Процесс – код выполняющийся в отдельном адресном пространстве
Множество процессов может выполняться
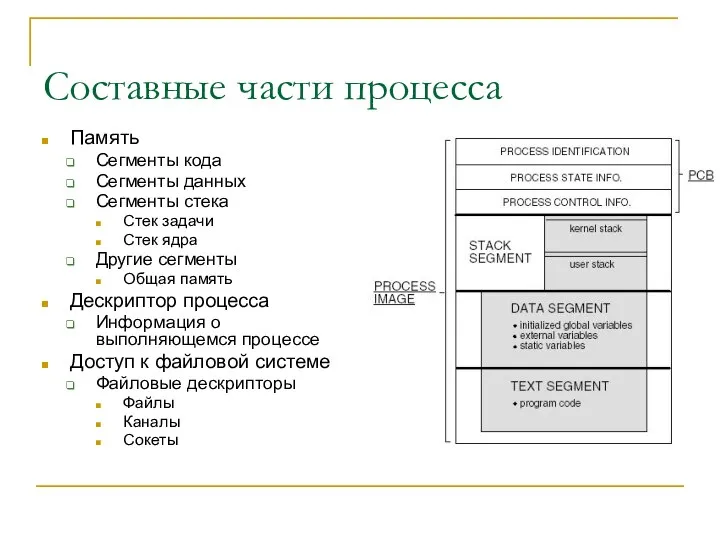
Составные части процесса
Память
Сегменты кода
Сегменты данных
Сегменты стека
Стек задачи
Стек ядра
Другие сегменты
Общая память
Дескриптор процесса
Информация
Составные части процесса
Память
Сегменты кода
Сегменты данных
Сегменты стека
Стек задачи
Стек ядра
Другие сегменты
Общая память
Дескриптор процесса
Информация

Память
Физическая память разбита на страницы (обычно фиксированного размера)
Страницы объединяются в виртуальные
Память
Физическая память разбита на страницы (обычно фиксированного размера)
Страницы объединяются в виртуальные

Файловая система
Системные вызовы
open
close
read
write
Операционная система транслирует эти вызовы в специфические вызовы конкретных
Файловая система
Системные вызовы
open
close
read
write
Операционная система транслирует эти вызовы в специфические вызовы конкретных
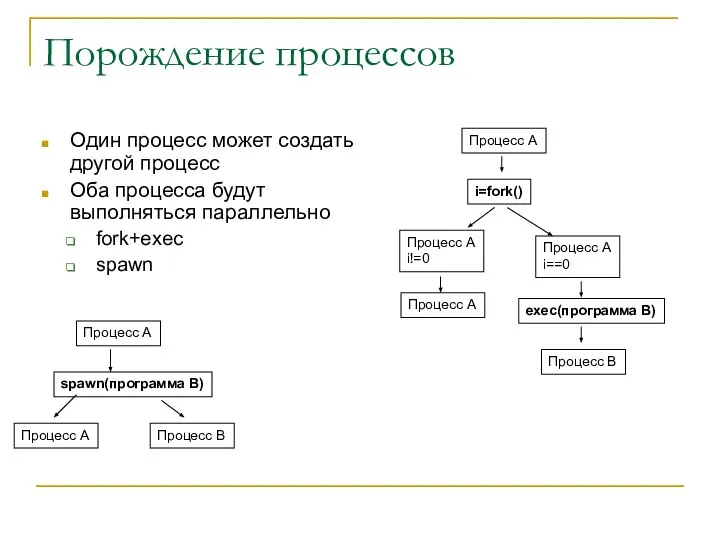
Порождение процессов
Один процесс может создать другой процесс
Оба процесса будут выполняться параллельно
fork+exec
spawn
Процесс
Порождение процессов
Один процесс может создать другой процесс
Оба процесса будут выполняться параллельно
fork+exec
spawn
Процесс

Особенности fork+exec и spawn
fork
Порожденный процесс наследует все ресурсы родителя!
Порожденный процесс начинает
Особенности fork+exec и spawn
fork
Порожденный процесс наследует все ресурсы родителя!
Порожденный процесс начинает

Доступ к файловой системе
В UNIX системах по возможности все реализовано
Доступ к файловой системе
В UNIX системах по возможности все реализовано
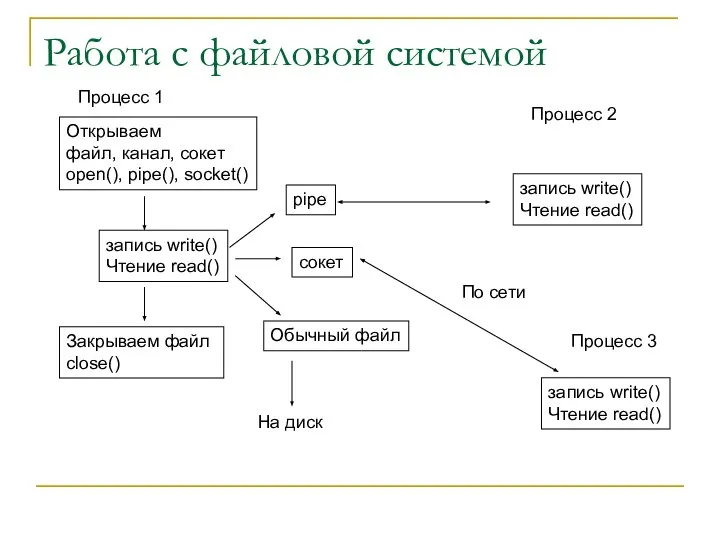
Работа с файловой системой
Открываем
файл, канал, сокет
open(), pipe(), socket()
запись write()
Чтение
Работа с файловой системой
Открываем
файл, канал, сокет
open(), pipe(), socket()
запись write()
Чтение

Память общего доступа
Процесс создает область общей памяти
Другие процессы присоединяют эту
Память общего доступа
Процесс создает область общей памяти
Другие процессы присоединяют эту

Конфликты при обращении к общим ресурсам: a – общая переменная
Процесс1 :
Конфликты при обращении к общим ресурсам: a – общая переменная
Процесс1 :

Семафоры
Семафор – совместно используемая атомарная целочисленная переменная
В каждый момент времени изменять
Семафоры
Семафор – совместно используемая атомарная целочисленная переменная
В каждый момент времени изменять

Синхронизация с помощью семафоров
Процесс 1
Создать семафор
Присвоить семафору 1
Уменьшить семафор на 1
Синхронизация с помощью семафоров
Процесс 1
Создать семафор
Присвоить семафору 1
Уменьшить семафор на 1

Сигналы
Сигнал – аналог прерывания
Асинхронное событие – неизвестно когда произойдет
Один процесс может
Сигналы
Сигнал – аналог прерывания
Асинхронное событие – неизвестно когда произойдет
Один процесс может

Потоки
Часть процесса, которая выполняется параллельно другими частями процесса
Все ресурсы потоков -
Потоки
Часть процесса, которая выполняется параллельно другими частями процесса
Все ресурсы потоков -

Стандарт OpenMP
OpenMP – стандарт который включает директивы компилятора, библиотеки и системные
Стандарт OpenMP
OpenMP – стандарт который включает директивы компилятора, библиотеки и системные

Пример OpenMP
int main (void){
int i;
int k = 0;
#pragma omp parallel for
Пример OpenMP
int main (void){
int i;
int k = 0;
#pragma omp parallel for

Обмен сообщениями
Когда процессы работают на разных машинах, то доступ к одним
Обмен сообщениями
Когда процессы работают на разных машинах, то доступ к одним

Системные API
Сокеты – независимый от протокола интерфейс, который позволяет организовать взаимодействие
Системные API
Сокеты – независимый от протокола интерфейс, который позволяет организовать взаимодействие

Сокет
Серверный процесс
socket() – создание сокета
bind() – назначение адреса
listen() – перевод в
Сокет
Серверный процесс
socket() – создание сокета
bind() – назначение адреса
listen() – перевод в
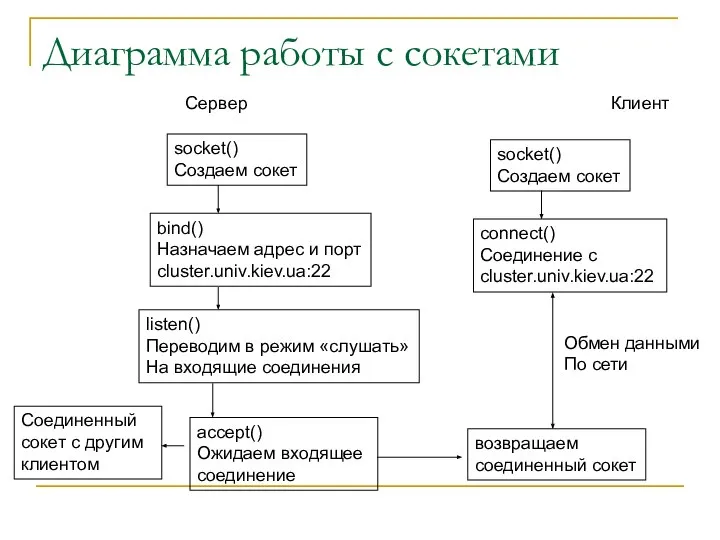
Диаграмма работы с сокетами
Сервер
socket()
Создаем сокет
bind()
Назначаем адрес и порт
cluster.univ.kiev.ua:22
listen()
Переводим в режим «слушать»
На
Диаграмма работы с сокетами
Сервер
socket()
Создаем сокет
bind()
Назначаем адрес и порт
cluster.univ.kiev.ua:22
listen()
Переводим в режим «слушать»
На

Синхронный и асинхронный обмен
Синхронный вызов –
функции send(), recv(), accept(), connect()
Синхронный и асинхронный обмен
Синхронный вызов –
функции send(), recv(), accept(), connect()

API для асинхронных операций ввода-вывода
select(), poll() – проверка состояния сокетов
Функция возвращает
API для асинхронных операций ввода-вывода
select(), poll() – проверка состояния сокетов
Функция возвращает

Сравнение синхронного и асинхронного ввода-вывода
Синхронный
Простота программирования
Меньшее количество ошибок
Неэффективен для параллельных программ
Обычно
Сравнение синхронного и асинхронного ввода-вывода
Синхронный
Простота программирования
Меньшее количество ошибок
Неэффективен для параллельных программ
Обычно

Интерфейсы параллельного программирования
Часто при написании параллельных программ приходится выполнять сложные операции
Интерфейсы параллельного программирования
Часто при написании параллельных программ приходится выполнять сложные операции

Message Passing Interface (MPI)
MPI - стандарт интерфейса (middleware) обмена сообщениями для
Message Passing Interface (MPI)
MPI - стандарт интерфейса (middleware) обмена сообщениями для

Диаграмма соответвия между сокетами, MPI и др
Интерфейс сокетов
Интерфейсы взаимодействия с общей памятью
Ядро
Аппаратное
Диаграмма соответвия между сокетами, MPI и др
Интерфейс сокетов
Интерфейсы взаимодействия с общей памятью
Ядро
Аппаратное

Основные определения
Процесс
Программа, которая выполняет свой код
Процесс характеризуется только своим номером
Основные определения
Процесс
Программа, которая выполняет свой код
Процесс характеризуется только своим номером

Разработка и запуск MPI программ
Пользователь разрабатывает программу с MPI вызовами
Программа компилируется
Разработка и запуск MPI программ
Пользователь разрабатывает программу с MPI вызовами
Программа компилируется
![Пример MPI программы int main(int argc, char* argv[]){ int my_number; //Мой](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1302607/slide-41.jpg)
Пример MPI программы
int main(int argc, char* argv[]){
int my_number; //Мой номер
Пример MPI программы
int main(int argc, char* argv[]){
int my_number; //Мой номер
![Результат работы MPI программы [saa@cluster mpi]$ mpirun -np 10 ./a.out I](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1302607/slide-42.jpg)
Результат работы MPI программы
[saa@cluster mpi]$ mpirun -np 10 ./a.out
I an process
Результат работы MPI программы
[saa@cluster mpi]$ mpirun -np 10 ./a.out
I an process

Реализации MPI
MPICH
LAMMPI
….
Существуют разные реализации
Может отличаться все, кроме совместимости программного кода
Некоторые реализации
Реализации MPI
MPICH
LAMMPI
….
Существуют разные реализации
Может отличаться все, кроме совместимости программного кода
Некоторые реализации

Parallel Virtual Machine (PVM)
PVM – программные средства для создания параллельных вычислительных
Parallel Virtual Machine (PVM)
PVM – программные средства для создания параллельных вычислительных

Основные компоненты
Платформенно независимый протокол обмена и методы сериализации
Библиотека libpvm3 с которой
Основные компоненты
Платформенно независимый протокол обмена и методы сериализации
Библиотека libpvm3 с которой

Основные операции
Управление процессами
Запуск pvm_spawn
Обмен сигналами pvm_kill
Выход pvm_exit
Сериализация/десериализация
Упаковка pvm_pk
Распаковка pvm_up
Отправка/прием
pvm_send
pvm_recv
Управление
Основные операции
Управление процессами
Запуск pvm_spawn
Обмен сигналами pvm_kill
Выход pvm_exit
Сериализация/десериализация
Упаковка pvm_pk
Распаковка pvm_up
Отправка/прием
pvm_send
pvm_recv
Управление

Принцип создания параллельных программ
Пользователь компилирует для всех платформ одну или несколько
Принцип создания параллельных программ
Пользователь компилирует для всех платформ одну или несколько
![Пример запуска машины PVM [saa@cluster mpi]$ pvm pvmd already running. pvm>](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1302607/slide-48.jpg)
Пример запуска машины PVM
[saa@cluster mpi]$ pvm
pvmd already running.
pvm> conf
conf
1 host, 1
Пример запуска машины PVM
[saa@cluster mpi]$ pvm
pvmd already running.
pvm> conf
conf
1 host, 1
![Пример PVM программы #include #include #include int main(int argc, char* argv[]){](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1302607/slide-49.jpg)
Пример PVM программы
#include
#include
#include
int main(int argc, char* argv[]){
int
Пример PVM программы
#include
#include
#include
int main(int argc, char* argv[]){
int

Языки рассчитанные на параллельное программирование
Обычно являются расширением к какому-либо из широко
Языки рассчитанные на параллельное программирование
Обычно являются расширением к какому-либо из широко
 Магнітостатичні хвилі в дотично намагніченому феромагнітному шарі
Магнітостатичні хвилі в дотично намагніченому феромагнітному шарі Презентация "Адаптированная Теория Ограничений" - скачать презентации по Экономике
Презентация "Адаптированная Теория Ограничений" - скачать презентации по Экономике Понятие и классификация педагогических целей
Понятие и классификация педагогических целей  Презентация "Художественная культура Востока" - скачать презентации по МХК
Презентация "Художественная культура Востока" - скачать презентации по МХК modul UJ 2019-2020.pptx
modul UJ 2019-2020.pptx Моральный фактор и антикоррупционное поведение сотрудника ОВД. (Тема 5)
Моральный фактор и антикоррупционное поведение сотрудника ОВД. (Тема 5) Основи технічного нормування праці. Сутність норм затрат праці. Структура робочого часу
Основи технічного нормування праці. Сутність норм затрат праці. Структура робочого часу Внутриличностные конфликты
Внутриличностные конфликты Музейный комплекс «Спас на Крови». Экскурсии
Музейный комплекс «Спас на Крови». Экскурсии Конный спорт
Конный спорт Презентация "Древнеегипетское искусство" - скачать презентации по МХК
Презентация "Древнеегипетское искусство" - скачать презентации по МХК Презентация на тему "Виды деятельности младших школьников" - скачать презентации по Педагогике
Презентация на тему "Виды деятельности младших школьников" - скачать презентации по Педагогике Презентация на тему "Каким быть современному учителю в современной школе" - скачать презентации по Педагогике
Презентация на тему "Каким быть современному учителю в современной школе" - скачать презентации по Педагогике Селекция мод. Режимы работы лазера
Селекция мод. Режимы работы лазера Глава 3. Экономика предприятия 16. Производство
Глава 3. Экономика предприятия 16. Производство  Действия сотрудников и студентов СВФУ имени М.К. Аммосова в кризисных ситуациях
Действия сотрудников и студентов СВФУ имени М.К. Аммосова в кризисных ситуациях Что такое «Красная книга». Окружающий мир 2 класс
Что такое «Красная книга». Окружающий мир 2 класс Презентация Факторы производства
Презентация Факторы производства История интернета
История интернета Общие принципы построения сетей
Общие принципы построения сетей PAUL CEZANNE (1839-1906)
PAUL CEZANNE (1839-1906)  Методика решения графических тестов
Методика решения графических тестов Музей-заповедник И.С. Тургенева Спасское-Лутовиново
Музей-заповедник И.С. Тургенева Спасское-Лутовиново Нормативно-правовое обеспечение и организация муниципального управления
Нормативно-правовое обеспечение и организация муниципального управления Автомобильные колеса и шины. Поверхности измерения биения колесного диска. Параметры колесных дисков Лада Гранта
Автомобильные колеса и шины. Поверхности измерения биения колесного диска. Параметры колесных дисков Лада Гранта Единая система конструкторской документации - ЕСКД
Единая система конструкторской документации - ЕСКД Система расстыковки «Союза». Лаборатория космической мысли
Система расстыковки «Союза». Лаборатория космической мысли Компания Крайслер
Компания Крайслер