- Файловые системы. Файловая система NTFS. Общие сведения

Содержание
- 2. Файловая система NTFS Общие сведения
- 3. Краткое описание NTFS Разработана для быстрого выполнения стандартных файловых операций типа чтения, записи и поиска. Поддерживает
- 4. Вопрос Вспомните методы физической организации файловой системы.
- 5. Физическая организация NTFS NTFS использует физическую организацию близкую перечню номеров блоков (кластеров). Для увеличения эффективности кластеры
- 6. Тома NTFS Структура NTFS начинается с тома (volume), который соответствует логическому разделу на диске и создается,
- 7. Типы томов NTFS (1) Простой том (simple) Составной том (spanned) – том, использующий более одного раздела
- 8. Типы томов NTFS (2) Чередующийся набор томов (stripped, RAID 1) – том, состоящий из нескольких разделов,
- 9. Внутреннее имя тома В разделе HKEY_LOCAL_ MACHINE\SYSTEM\MountedDevices системного реестра хранится информация о базовых дисках. Внутреннее имя
- 10. Размер кластера тома NTFS Пользователь может определить размер кластера при форматировании тома NTFS /a: , т.е.
- 11. NTFS и архитектура Windows
- 12. Физическая структура NTFS Том NTFS условно делится на две части. Первые 12,5% тома отводятся под так
- 13. Механизм использования MFT-зоны Когда файлы уже нельзя записывать в обычное пространство, MFT-зона просто сокращается, освобождая таким
- 14. Первые 16 файлов NTFS (метафайлы) носят служебный характер. Метафайлы находятся корневом каталоге NTFS диска – они
- 15. Перечень метафайлов (1)
- 16. Перечень метафайлов (2)
- 17. Файлы и их атрибуты (1) Каждый файл на томе NTFS представлен записью MFT, под которое отводится
- 18. Файлы и их атрибуты (2) Обычно атрибуты располагаются непосредственно после заголовков, однако если длина значения слишком
- 19. Заголовок атрибута
- 20. Атрибуты файлов NTFS (1)
- 21. Атрибуты файлов NTFS(2)
- 22. Запись MFT заголовок записи MFT стандартная информация имя файла данные дескриптор безопасности* * в последних версиях
- 23. Резидентное хранение файлов и каталогов Файлы и каталоги с размером менее размера записи MFT могут полностью
- 24. Нерезидентное хранение файлов среднего размера В большинстве случаев все данные файла не помещаются в запись MFT,
- 25. Нерезидентное хранение файлов среднего размера На рисунке файл состоит из 3-х серий кластеров: 20 – 23,
- 26. Нерезидентное хранение больших файлов Если файл настолько велик (или сильно фрагментирован), что его атрибут данных не
- 27. Вопрос Сравните организацию хранения больших файлов в NTFS и файловых системах ОС UNIX.
- 28. Сжатие файлов Файловая система NTFS поддерживает прозрачное сжатие файлов следующим образом: Когда файловая система NTFS записывает
- 29. Пример сжатия файла (1)
- 30. Пример сжатия файла (2) На предыдущем слайде показан файл, в котором первые 16 блоков успешно сжаты
- 31. Разреженные файлы (sparse files) Если у вас есть файлы, которые содержат множество нулей, т.е. «пустые области»,
- 32. Создание разреженных файлов Разреженные файлы конвертируются с помощью следующей команды: fsutil sparse.
- 33. Многопоточные файлы При необходимости в одном файле, записанном на диске NTFS, можно хранить несколько потоков информации.
- 34. Пример создания многопоточного файла В интерфейсе командной строки перейдем в раздел NTFS (например, в папку, содержащую
- 35. Каталоги NTFS Каталог на NTFS представляет собой специфический файл, хранящий ссылки на другие файлы и каталоги,
- 36. Поиск в каталогах NTFS Для поиска файла с данным именем в линейном каталоге, таком, например, как
- 37. Бинарное дерево
- 38. Вопрос Нарисуйте бинарное дерево.
- 39. Простой и бинарный поиск
- 40. B+ дерево B+ дерево – структура данных, представляет собой сбалансированное дерево поиска. B+ дерево является модификацией
- 41. Хранение каталогов Небольшие записи каталогов находятся полностью внутри структуры MFT, для хранения используется атрибут $Index_Root (корневой
- 42. Пример хранения каталогов а) запись MFT для небольшого каталога (резидентное хранение) б) запись MFT для “большого”
- 43. Запись MFT для небольшого каталога Запись MFT для небольшого каталога содержит несколько записей, каждая из которых
- 44. Пример нерезидентного хранения каталогов (1) На рисунке показана запись MFT каталога, в трех узлах которой содержится
- 45. Пример нерезидентного хранения каталогов (2) Рассмотрим ситуацию открытия файла e.bak. Во-первых, NTFS считывает атрибут индексного корня
- 46. Пример нерезидентного хранения каталогов (3) На основании информации из $INDEX_ALLOCATION, файловая система преобразует VCN в логический
- 47. Хранение корневого каталога
- 49. Скачать презентацию

Файловая система NTFS
Общие сведения
Файловая система NTFS
Общие сведения

Краткое описание NTFS
Разработана для быстрого выполнения стандартных файловых операций типа чтения,
Краткое описание NTFS
Разработана для быстрого выполнения стандартных файловых операций типа чтения,

Вопрос
Вспомните методы физической организации файловой системы.
Вопрос
Вспомните методы физической организации файловой системы.

Физическая организация NTFS
NTFS использует физическую организацию близкую перечню номеров блоков (кластеров).
Для
Физическая организация NTFS
NTFS использует физическую организацию близкую перечню номеров блоков (кластеров).
Для
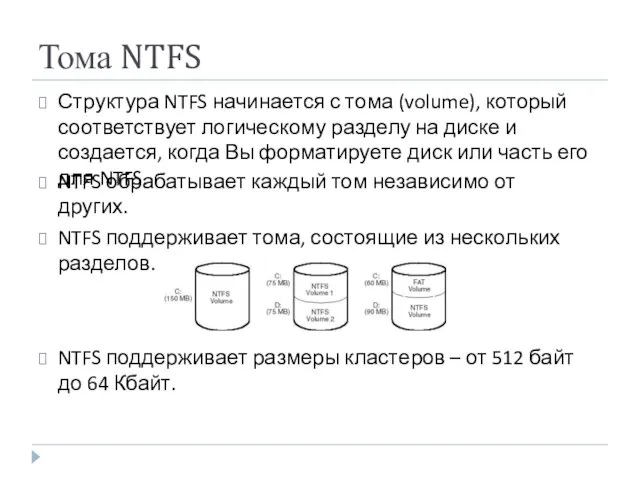
Тома NTFS
Структура NTFS начинается с тома (volume), который соответствует логическому разделу
Тома NTFS
Структура NTFS начинается с тома (volume), который соответствует логическому разделу

Типы томов NTFS (1)
Простой том (simple)
Составной том (spanned) – том, использующий
Типы томов NTFS (1)
Простой том (simple)
Составной том (spanned) – том, использующий

Типы томов NTFS (2)
Чередующийся набор томов (stripped, RAID 1) – том,
Типы томов NTFS (2)
Чередующийся набор томов (stripped, RAID 1) – том,

Внутреннее имя тома
В разделе HKEY_LOCAL_ MACHINE\SYSTEM\MountedDevices системного реестра хранится информация о
Внутреннее имя тома
В разделе HKEY_LOCAL_ MACHINE\SYSTEM\MountedDevices системного реестра хранится информация о
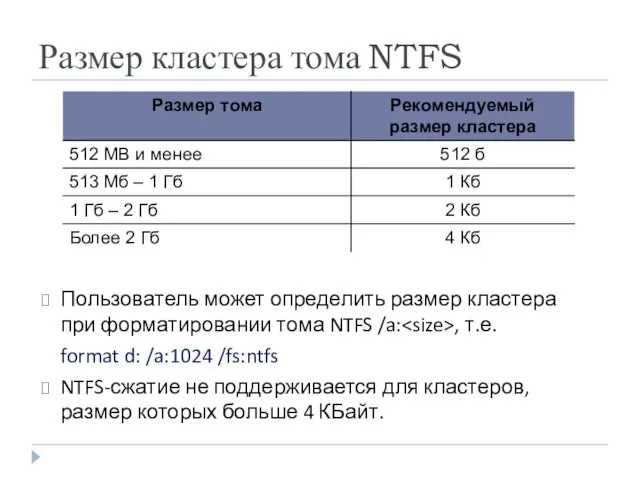
Размер кластера тома NTFS
Пользователь может определить размер кластера при форматировании тома
Размер кластера тома NTFS
Пользователь может определить размер кластера при форматировании тома
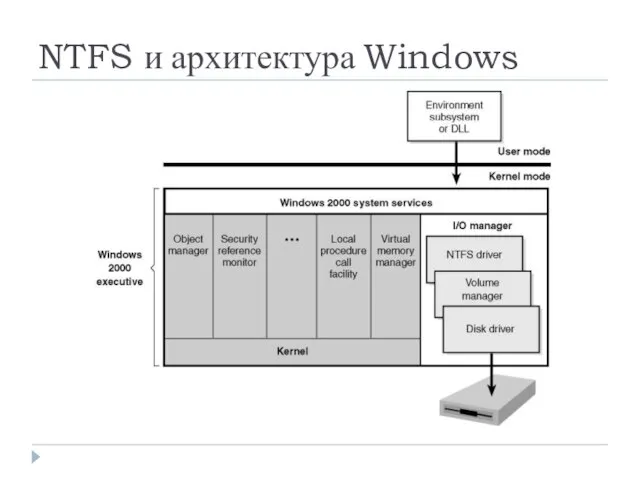
NTFS и архитектура Windows
NTFS и архитектура Windows
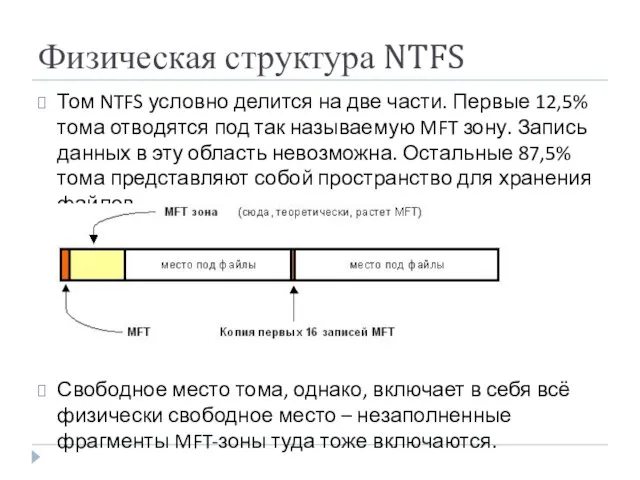
Физическая структура NTFS
Том NTFS условно делится на две части. Первые
Физическая структура NTFS
Том NTFS условно делится на две части. Первые

Механизм использования MFT-зоны
Когда файлы уже нельзя записывать в обычное пространство, MFT-зона
Механизм использования MFT-зоны
Когда файлы уже нельзя записывать в обычное пространство, MFT-зона

Первые 16 файлов NTFS (метафайлы) носят служебный характер.
Метафайлы находятся корневом
Первые 16 файлов NTFS (метафайлы) носят служебный характер.
Метафайлы находятся корневом
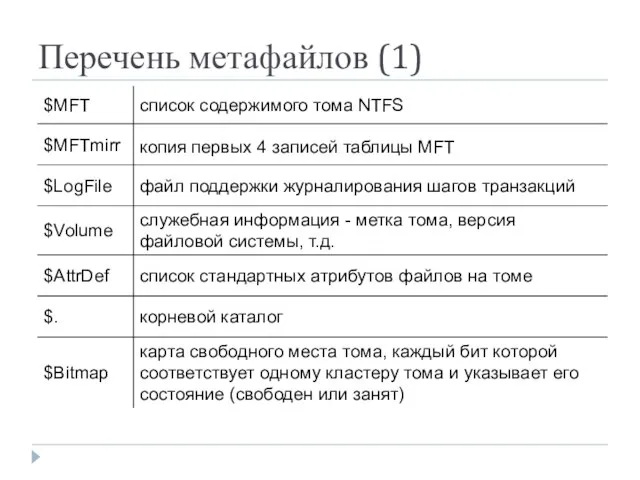
Перечень метафайлов (1)
Перечень метафайлов (1)
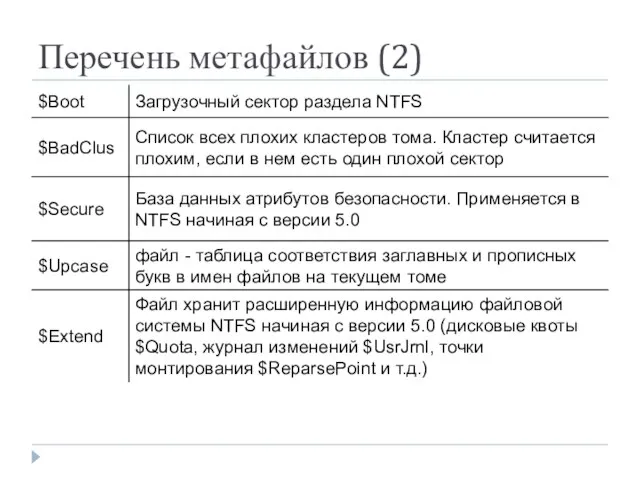
Перечень метафайлов (2)
Перечень метафайлов (2)
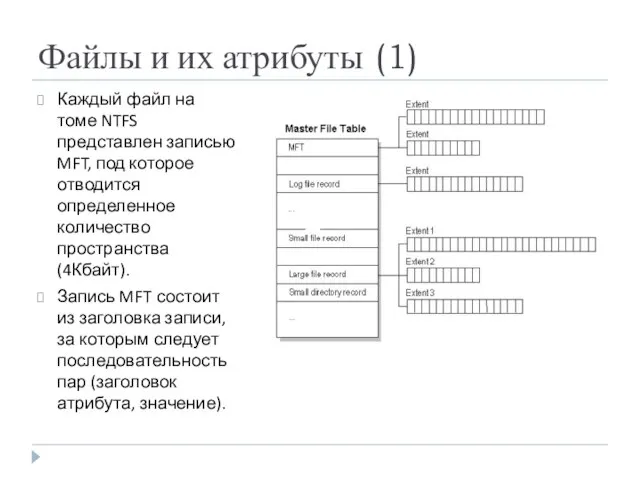
Файлы и их атрибуты (1)
Каждый файл на томе NTFS представлен записью
Файлы и их атрибуты (1)
Каждый файл на томе NTFS представлен записью
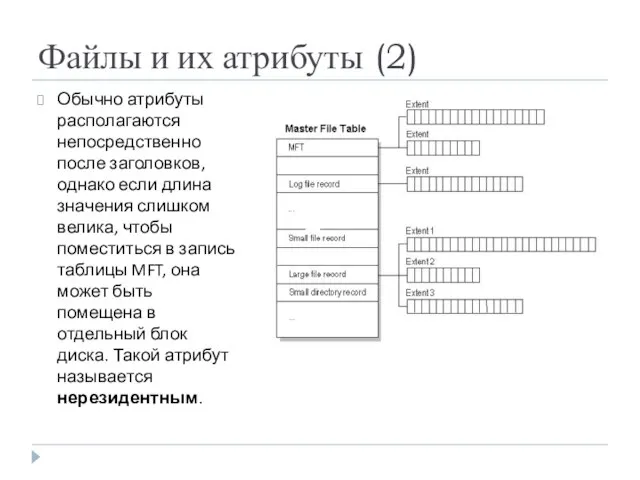
Файлы и их атрибуты (2)
Обычно атрибуты располагаются непосредственно после заголовков, однако
Файлы и их атрибуты (2)
Обычно атрибуты располагаются непосредственно после заголовков, однако
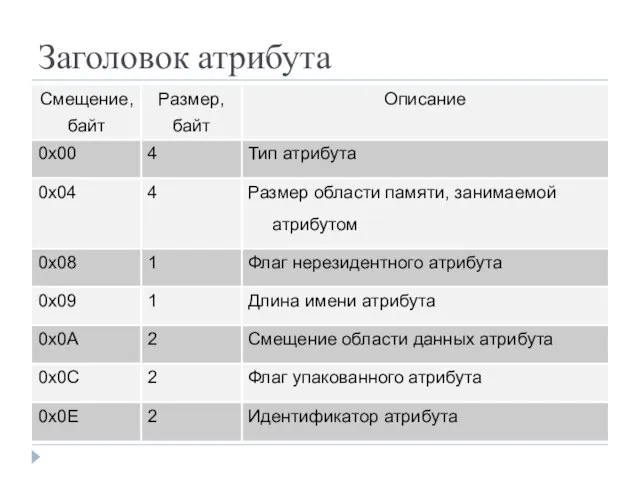
Заголовок атрибута
Заголовок атрибута
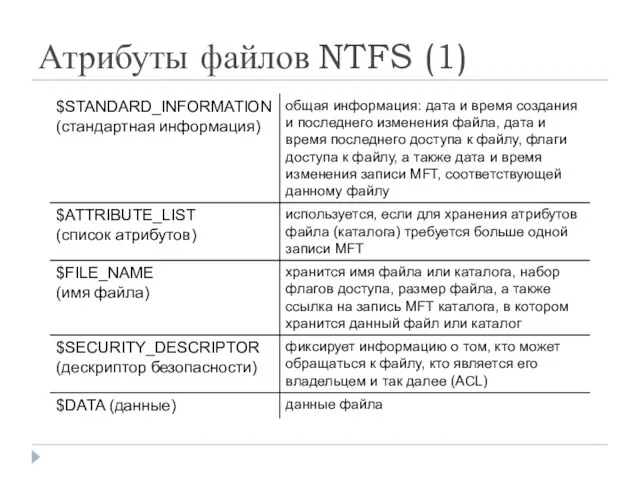
Атрибуты файлов NTFS (1)
Атрибуты файлов NTFS (1)
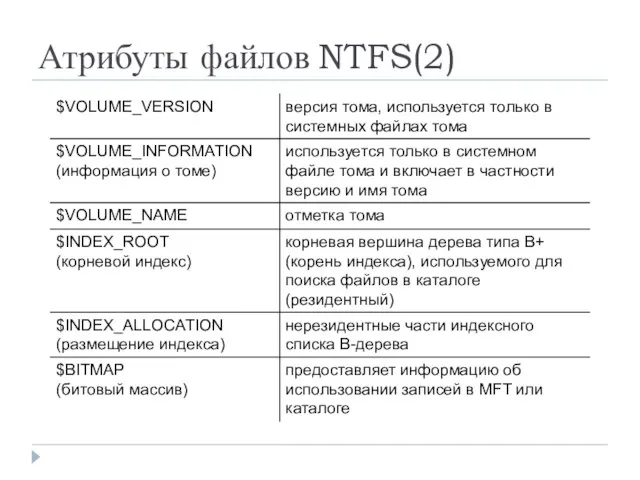
Атрибуты файлов NTFS(2)
Атрибуты файлов NTFS(2)
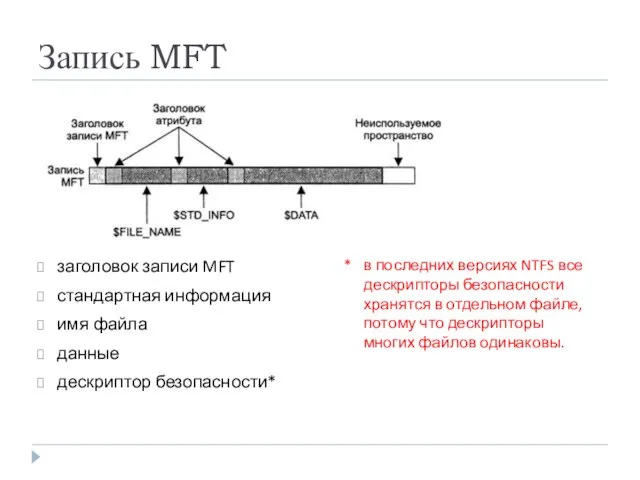
Запись MFT
заголовок записи MFT
стандартная информация
имя файла
данные
дескриптор безопасности*
* в последних версиях NTFS
Запись MFT
заголовок записи MFT
стандартная информация
имя файла
данные
дескриптор безопасности*
* в последних версиях NTFS
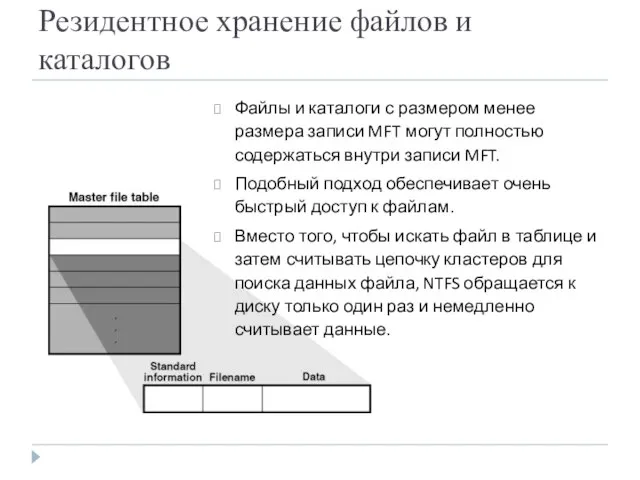
Резидентное хранение файлов и каталогов
Файлы и каталоги с размером менее размера
Резидентное хранение файлов и каталогов
Файлы и каталоги с размером менее размера
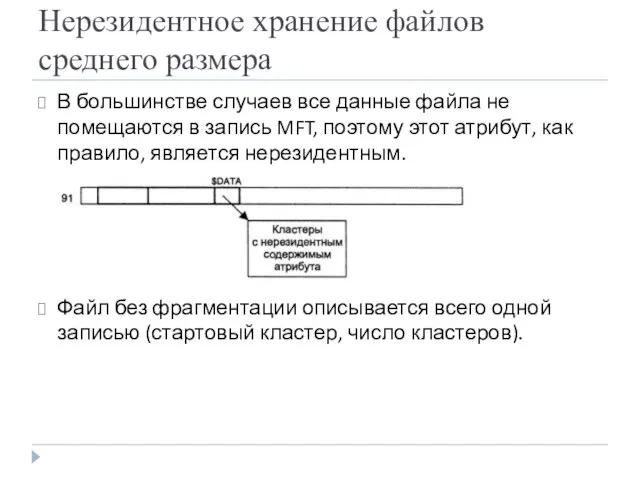
Нерезидентное хранение файлов среднего размера
В большинстве случаев все данные файла не
Нерезидентное хранение файлов среднего размера
В большинстве случаев все данные файла не
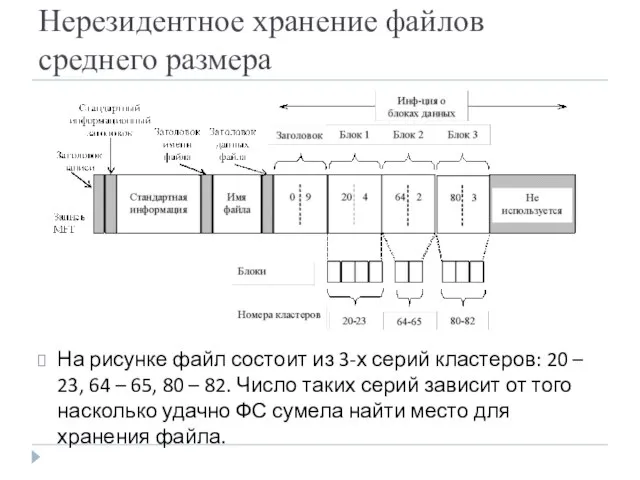
Нерезидентное хранение файлов среднего размера
На рисунке файл состоит из 3-х серий
Нерезидентное хранение файлов среднего размера
На рисунке файл состоит из 3-х серий
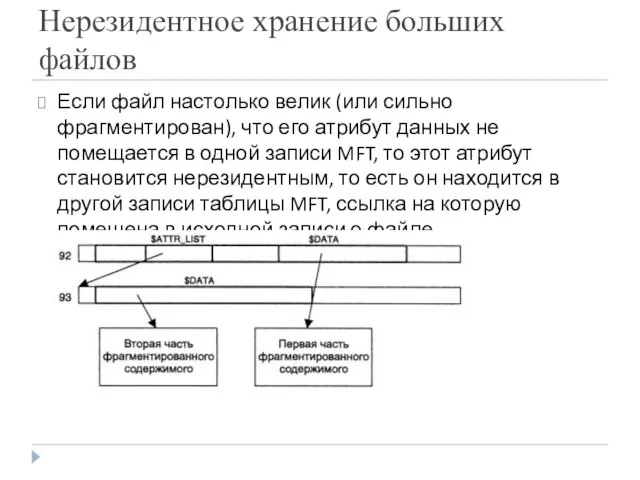
Нерезидентное хранение больших файлов
Если файл настолько велик (или сильно фрагментирован), что
Нерезидентное хранение больших файлов
Если файл настолько велик (или сильно фрагментирован), что

Вопрос
Сравните организацию хранения больших файлов в NTFS и файловых системах ОС
Вопрос
Сравните организацию хранения больших файлов в NTFS и файловых системах ОС

Сжатие файлов
Файловая система NTFS поддерживает прозрачное сжатие файлов следующим образом:
Когда файловая
Сжатие файлов
Файловая система NTFS поддерживает прозрачное сжатие файлов следующим образом:
Когда файловая
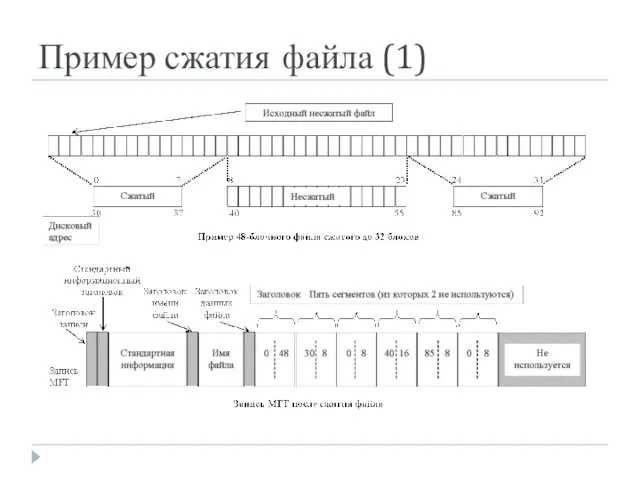
Пример сжатия файла (1)
Пример сжатия файла (1)

Пример сжатия файла (2)
На предыдущем слайде показан файл, в котором первые
Пример сжатия файла (2)
На предыдущем слайде показан файл, в котором первые

Разреженные файлы (sparse files)
Если у вас есть файлы, которые содержат множество
Разреженные файлы (sparse files)
Если у вас есть файлы, которые содержат множество

Создание разреженных файлов
Разреженные файлы конвертируются с помощью следующей команды: fsutil sparse.
Создание разреженных файлов
Разреженные файлы конвертируются с помощью следующей команды: fsutil sparse.

Многопоточные файлы
При необходимости в одном файле, записанном на диске NTFS, можно
Многопоточные файлы
При необходимости в одном файле, записанном на диске NTFS, можно

Пример создания многопоточного файла
В интерфейсе командной строки перейдем в раздел NTFS
Пример создания многопоточного файла
В интерфейсе командной строки перейдем в раздел NTFS

Каталоги NTFS
Каталог на NTFS представляет собой специфический файл, хранящий ссылки на
Каталоги NTFS
Каталог на NTFS представляет собой специфический файл, хранящий ссылки на

Поиск в каталогах NTFS
Для поиска файла с данным именем в линейном
Поиск в каталогах NTFS
Для поиска файла с данным именем в линейном
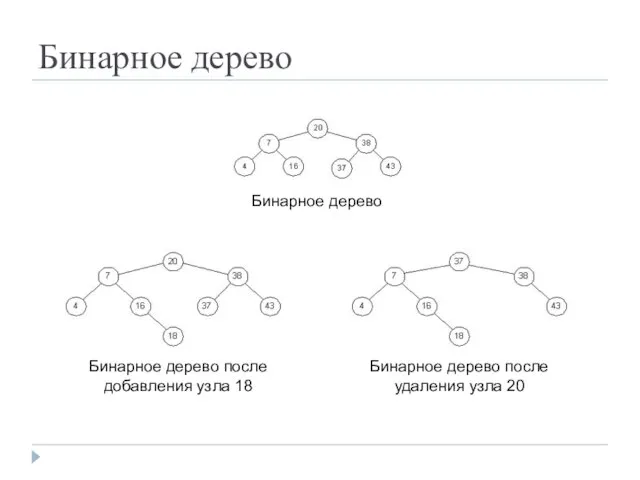
Бинарное дерево
Бинарное дерево

Вопрос
Нарисуйте бинарное дерево.
Вопрос
Нарисуйте бинарное дерево.
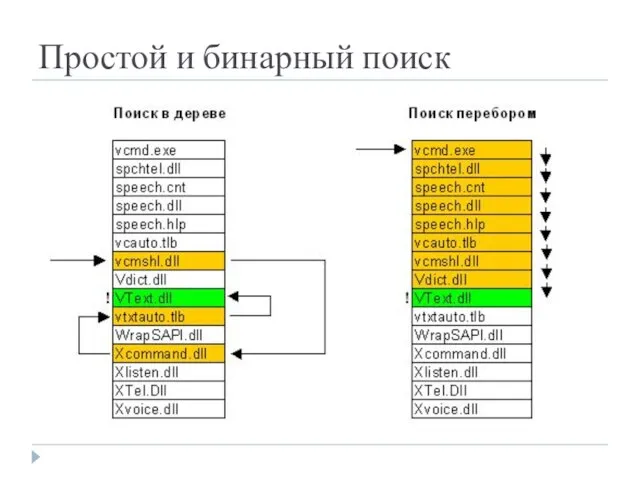
Простой и бинарный поиск
Простой и бинарный поиск
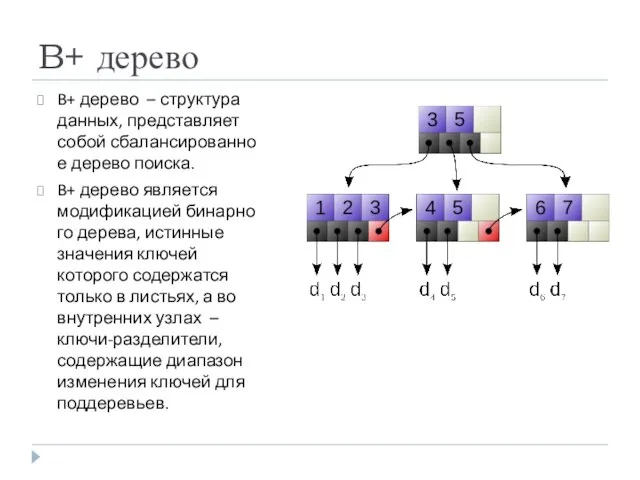
B+ дерево
B+ дерево – структура данных, представляет собой сбалансированное дерево поиска.
B+
B+ дерево
B+ дерево – структура данных, представляет собой сбалансированное дерево поиска.
B+

Хранение каталогов
Небольшие записи каталогов находятся полностью внутри структуры MFT, для хранения
Хранение каталогов
Небольшие записи каталогов находятся полностью внутри структуры MFT, для хранения
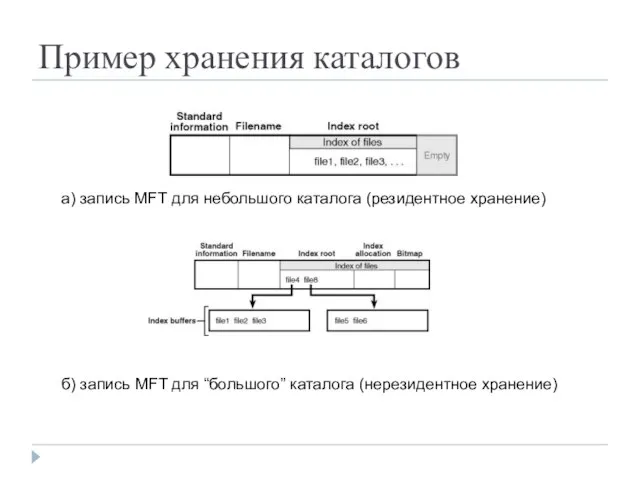
Пример хранения каталогов
а) запись MFT для небольшого каталога (резидентное хранение)
б) запись
Пример хранения каталогов
а) запись MFT для небольшого каталога (резидентное хранение)
б) запись
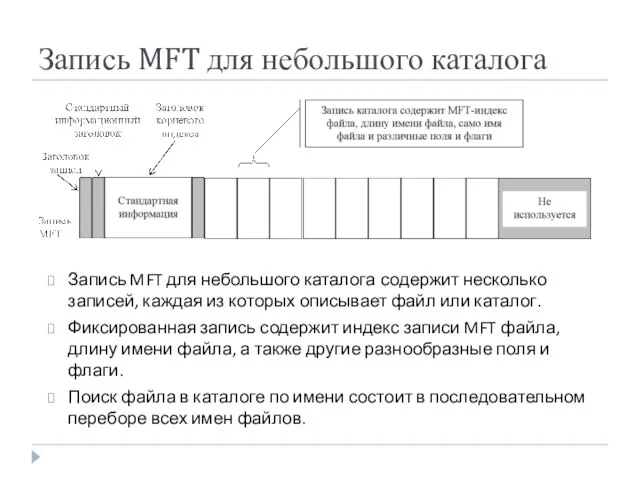
Запись MFT для небольшого каталога
Запись MFT для небольшого каталога содержит несколько
Запись MFT для небольшого каталога
Запись MFT для небольшого каталога содержит несколько
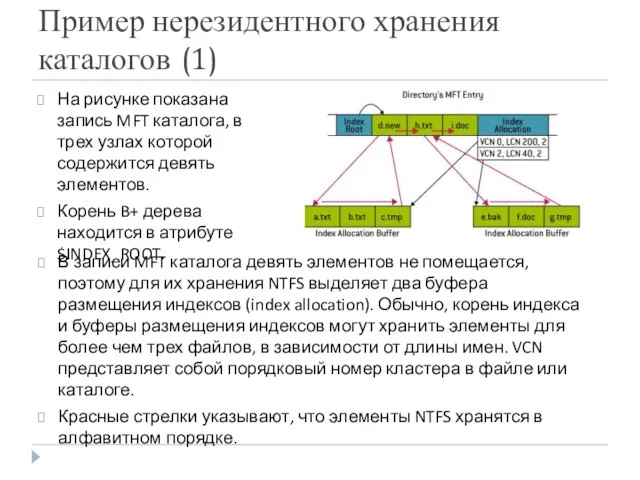
Пример нерезидентного хранения каталогов (1)
На рисунке показана запись MFT каталога, в
Пример нерезидентного хранения каталогов (1)
На рисунке показана запись MFT каталога, в
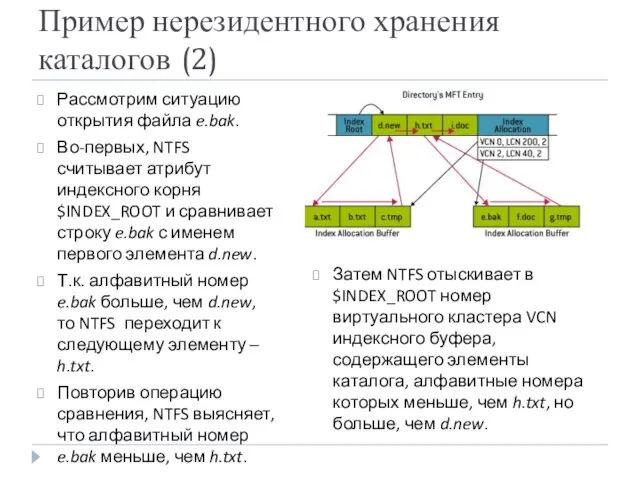
Пример нерезидентного хранения каталогов (2)
Рассмотрим ситуацию открытия файла e.bak.
Во-первых, NTFS считывает
Пример нерезидентного хранения каталогов (2)
Рассмотрим ситуацию открытия файла e.bak.
Во-первых, NTFS считывает
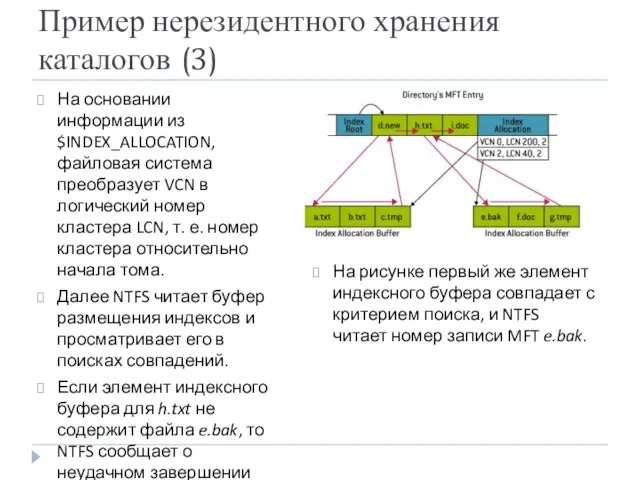
Пример нерезидентного хранения каталогов (3)
На основании информации из $INDEX_ALLOCATION, файловая система
Пример нерезидентного хранения каталогов (3)
На основании информации из $INDEX_ALLOCATION, файловая система
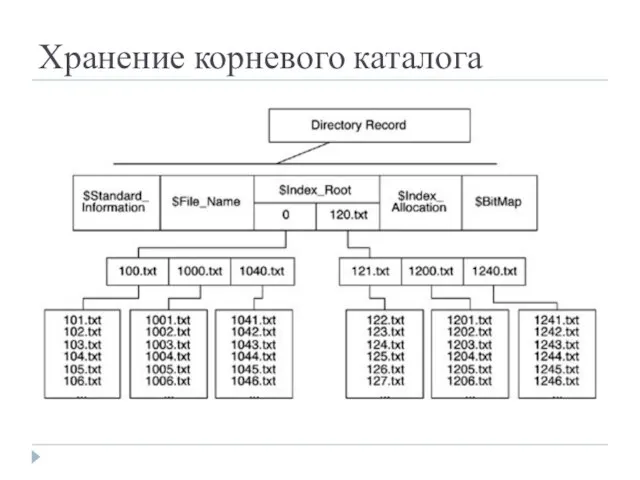
Хранение корневого каталога
Хранение корневого каталога
 Язык программирования Паскаль
Язык программирования Паскаль Презентация "Этапы решения задач на компьютере" - скачать презентации по Информатике
Презентация "Этапы решения задач на компьютере" - скачать презентации по Информатике Понятие алгоритма
Понятие алгоритма Общие сведения от языке Python
Общие сведения от языке Python mWirelessGames
mWirelessGames Logistic regression
Logistic regression Непозиционные системы счисления
Непозиционные системы счисления Методы проектирования БД
Методы проектирования БД Web
Web Информация и информатика
Информация и информатика Технология разработки приложений Windows в среде визуального программирования. Лекция 1 и 2
Технология разработки приложений Windows в среде визуального программирования. Лекция 1 и 2 Знакомство с интерфейсом программы Кумир
Знакомство с интерфейсом программы Кумир Clan Wars League. Первая лига клановых войн в России
Clan Wars League. Первая лига клановых войн в России Android Tool and Production Line Solution
Android Tool and Production Line Solution Векторная графика
Векторная графика Аттестационная работа. Создание проекта История развития вычислительной техники
Аттестационная работа. Создание проекта История развития вычислительной техники Вопросы для повторения Что означает WWW? Что такое гиперссылка? Из каких частей состоит гиперссылка? Гипертекст – это… С помощью какого языка создается Web-страница? 6. Какие существуют Web-страницы? 7. URL что означают эти буквы? 8.
Вопросы для повторения Что означает WWW? Что такое гиперссылка? Из каких частей состоит гиперссылка? Гипертекст – это… С помощью какого языка создается Web-страница? 6. Какие существуют Web-страницы? 7. URL что означают эти буквы? 8. Накопители информации
Накопители информации Динамическое программирование
Динамическое программирование Поколение ЭВМ
Поколение ЭВМ Решение задачи с использованием балочных элементов
Решение задачи с использованием балочных элементов Мова HTML
Мова HTML Пример составления и расчета сетевого графика
Пример составления и расчета сетевого графика Двоичное кодирование
Двоичное кодирование Компьютерный набор. Тема 3
Компьютерный набор. Тема 3 История операционных систем
История операционных систем Технологии управления с помощью мысли
Технологии управления с помощью мысли История возникновения систем счисления
История возникновения систем счисления