Оптимизация тематического моделирования за счет изменения функции плотности в алгоритме семплирования Гиббса
- Оптимизация тематического моделирования за счет изменения функции плотности в алгоритме семплирования Гиббса

Содержание
- 2. Тематическое моделирование Тематическое моделирование - это способ построения модели коллекции текстовых документов, которая определяет, к каким
- 3. Тематическая модель (topic model) — модель коллекции текстовых документов, которая определяет, к каким темам относится каждый
- 4. Тематическое моделирование (Latent Dirichlet allocation) Основное предположение тематической модели Latent Dirichlet Allocation состоит в том, что
- 5. Тематическое моделирование
- 6. Задача классификации заключается в расчете (оценке) апостериорной информации на основании априорной информации. Такая оценка может быть
- 7. Задача восстановления априорного распределения p(x,y) Оценка функции p(x,y) может быть реализован при помощи трех методов. 1.
- 8. Семплирование по Гиббсу — алгоритм для генерации выборки совместного распределения множества случайных величин. Он используется для
- 10. Скачать презентацию

Тематическое моделирование
Тематическое моделирование - это способ построения модели коллекции текстовых документов,
Тематическое моделирование
Тематическое моделирование - это способ построения модели коллекции текстовых документов,
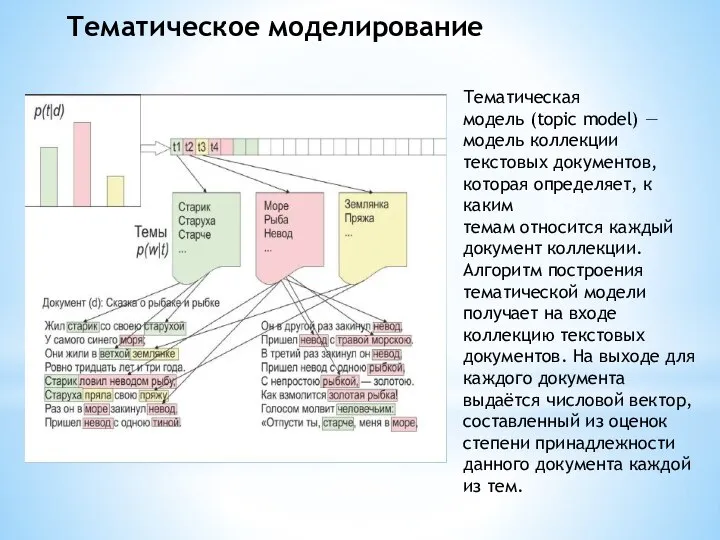
Тематическая
модель (topic model) —
модель коллекции
текстовых документов,
которая определяет, к каким
темам относится каждый
документ
Тематическая
модель (topic model) —
модель коллекции
текстовых документов,
которая определяет, к каким
темам относится каждый
документ

Тематическое моделирование
(Latent Dirichlet allocation)
Основное предположение тематической модели Latent Dirichlet Allocation
состоит в
Тематическое моделирование
(Latent Dirichlet allocation)
Основное предположение тематической модели Latent Dirichlet Allocation
состоит в

Тематическое моделирование
Тематическое моделирование

Задача классификации заключается в расчете (оценке) апостериорной информации на основании априорной
Задача классификации заключается в расчете (оценке) апостериорной информации на основании априорной

Задача восстановления априорного распределения p(x,y)
Оценка функции p(x,y) может быть реализован при
Задача восстановления априорного распределения p(x,y)
Оценка функции p(x,y) может быть реализован при

Семплирование по Гиббсу — алгоритм для генерации выборки совместного распределения множества случайных величин. Он используется
Семплирование по Гиббсу — алгоритм для генерации выборки совместного распределения множества случайных величин. Он используется
 Треугольники, 7 класс
Треугольники, 7 класс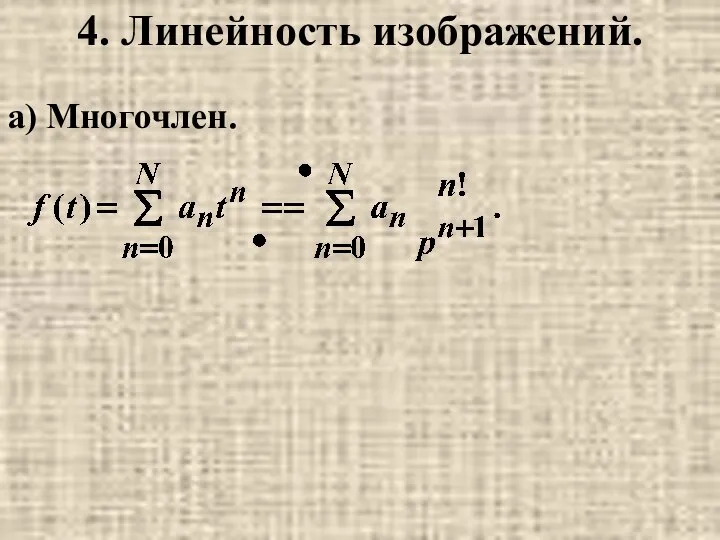 Линейность изображений
Линейность изображений Chapter 3. Polynomial and Rational Functions. 3.2 Polynomial Functions and Their Graphs
Chapter 3. Polynomial and Rational Functions. 3.2 Polynomial Functions and Their Graphs Признаки делимости на 10, на 5, на 2
Признаки делимости на 10, на 5, на 2 Арифметические действия с десятичными дробями Учитель математики Бадюк Ольга Ярославна, МКОУ «Москаленский лицей»
Арифметические действия с десятичными дробями Учитель математики Бадюк Ольга Ярославна, МКОУ «Москаленский лицей»  Текстовые задачи на движение
Текстовые задачи на движение Тела вращения. Цилиндр. Сечение. Вписанная и описанная призма. Конус. Сечение. Вписанная и описанная пирамида. Шар. Симметрия
Тела вращения. Цилиндр. Сечение. Вписанная и описанная призма. Конус. Сечение. Вписанная и описанная пирамида. Шар. Симметрия Нахождение процентов от числа и числа по его проценту. 5 класс
Нахождение процентов от числа и числа по его проценту. 5 класс Точка, линия, прямая и кривая линии. Число 2. Цифра 2
Точка, линия, прямая и кривая линии. Число 2. Цифра 2 Следствия из аксиом I - III
Следствия из аксиом I - III Признаки сходимости несобственных интегралов. Теорема 1. Признак сравнения несобственных интегралов 1 рода
Признаки сходимости несобственных интегралов. Теорема 1. Признак сравнения несобственных интегралов 1 рода Условная вероятность
Условная вероятность Подготовка к введению задач в 2 действия
Подготовка к введению задач в 2 действия Делимость натуральных чисел
Делимость натуральных чисел Лента Мебиуса. Все гениальное просто. (приложение)
Лента Мебиуса. Все гениальное просто. (приложение)  Подготовка к ГИА. Нахождение знаков коэффициентов квадратичной функции по графику
Подготовка к ГИА. Нахождение знаков коэффициентов квадратичной функции по графику 20161216_den_fibonachchi
20161216_den_fibonachchi Симметрические многочлены
Симметрические многочлены Три признака параллельности двух прямых
Три признака параллельности двух прямых Решение практико-ориентированных задач ЕГЭ
Решение практико-ориентированных задач ЕГЭ Пересекающиеся прямые. Вертикальные и смежные углы
Пересекающиеся прямые. Вертикальные и смежные углы Полуправильные многоугольники. Длина и площадь
Полуправильные многоугольники. Длина и площадь Криволинейные интегралы 2 рода
Криволинейные интегралы 2 рода Натуральные числа. Обобщающий урок
Натуральные числа. Обобщающий урок Логико-когнетивные основы урока алгебры
Логико-когнетивные основы урока алгебры Определение угла. Развернутый угол
Определение угла. Развернутый угол Інтегральне числення
Інтегральне числення Решение заданий ЕГЭ. Урок-консультация. 11 класс
Решение заданий ЕГЭ. Урок-консультация. 11 класс