- Презентация по математике "ОСНОВЫ БИОСТАТИСТИКИ" - скачать бесплатно

Содержание
- 2. Оценка ассоциаций «генотип-фенотип» и их значимости Факторы, влияющие на значимость оценок Объединение выборок и метаисследования Учет
- 3. Выявление ассоциаций «генотип-фенотип»: минимальный набор действий Фенотип - качественный признак (например: «здоровый - больной», «русский -
- 4. OR – непременный атрибут «case-control association study» (выявление «генов предрасположенности» к заболеванию путем сопоставлений частот генотипов
- 5. Soft для вычисления OR и проведения матаисследований
- 6. Статистический анализ сопряженности генотипов и количественных признаков Самое простое и необходимое: вычисление средних значений признака для
- 7. Сравнение частот генотипов для групп с низким (или высоким) значением признака Самое простое и необходимое: вычисление
- 8. Сравнение частот генотипов для групп с низким (или высоким) значением признака Логистическая и пуассоновская регрессии р
- 9. Soft для работы с генотипами и гаплотипами WinStat for Excel Free! Free!
- 10. Оценка ассоциаций «генотип-фенотип» и их значимости Факторы, влияющие на значимость оценок Объединение выборок и метаисследования Учет
- 11. Чуть-чуть об ошибках статистических тестов Ошибка I рода (α) Вероятность отвергнуть правильную нулевую гипотезу = Вероятность
- 12. От чего зависят ошибки статистических тестов? От размаха реально существующих отличий и разброса данных От объемов
- 13. Сравнение частот при уровне значимости 0.05 Объемы выборок в опыте и контроле одинаковы Если в контроле
- 14. Оценка ассоциаций «генотип-фенотип» и их значимости Факторы, влияющие на значимость оценок Объединение выборок и метаисследования Учет
- 15. Проверка однородности материала и вычисление OR для нескольких выборок Выборки можно объединять, если Можно ли объединить
- 16. Mantel-Haenszel test
- 17. Объединение выборок с незначимыми эффектами Если ассоциации нет, то случаи «больше-меньше» должны появляться с вероятностью ½
- 18. Mantel-Haenszel test with WinPepi: результаты Протективное действие гетерозиготы w/d CCR5 достоверно, но не велико: OR=1.15
- 19. Оценка ассоциаций «генотип-фенотип» и их значимости Факторы, влияющие на значимость оценок Объединение выборок и метаисследования Учет
- 20. Генерируем две одинаково распределенные выборки по 100 особей с 20-локусными генотипами Как это бывает? Наблюдаем появление
- 21. Как избежать фальшивых открытий? False Discovery Rate control: FDR - контроль Permutation test (компьютерная перестановка лэйблов
- 22. Зависимость ошибки II рода от числа тестов (SNP) при использовании поправки Бонферрони Вероятность пропустить ген с
- 23. Новый принцип проверки статистических гипотез: FDR-контроль False Discovery Rate control: Benjamini, Hochberg (1995) Вероятность хотя бы
- 24. Пример: множественные сравнения по 10 тестам Значимые различия без поправок на множественность Располагаем тесты в порядке
- 25. Permutation tests: случайные перестановки пометок «case-control» в компьютерных симуляциях по алгоритму: Что делать, если FDR не
- 27. Скачать презентацию

Оценка ассоциаций «генотип-фенотип» и их значимости
Факторы, влияющие на
Оценка ассоциаций «генотип-фенотип» и их значимости
Факторы, влияющие на
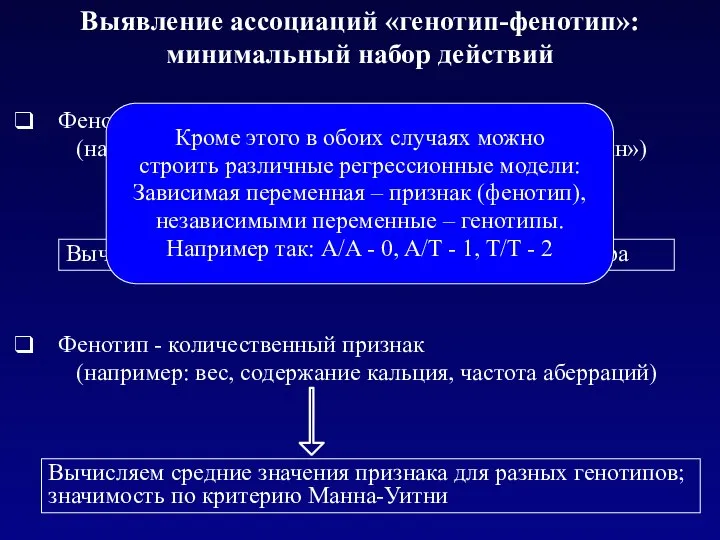
Выявление ассоциаций «генотип-фенотип»:
минимальный набор действий
Фенотип - качественный признак
(например:
Выявление ассоциаций «генотип-фенотип»:
минимальный набор действий
Фенотип - качественный признак
(например:
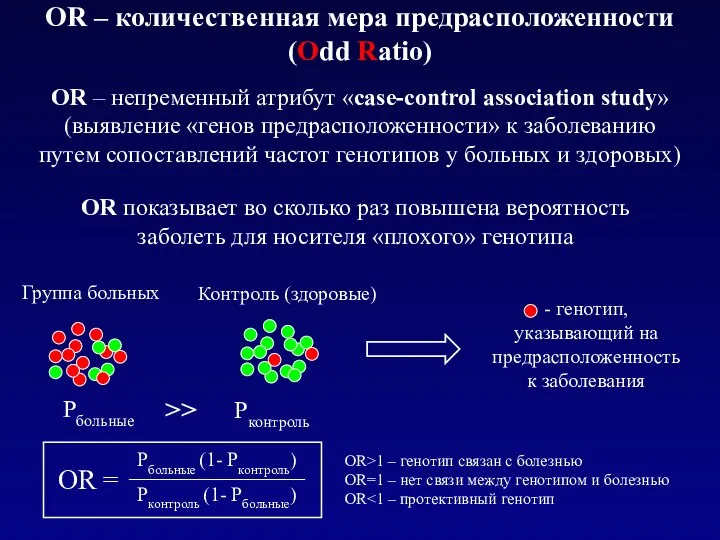
OR – непременный атрибут «case-control association study»
(выявление «генов предрасположенности» к
OR – непременный атрибут «case-control association study»
(выявление «генов предрасположенности» к

Soft для вычисления OR
и проведения матаисследований
Soft для вычисления OR
и проведения матаисследований
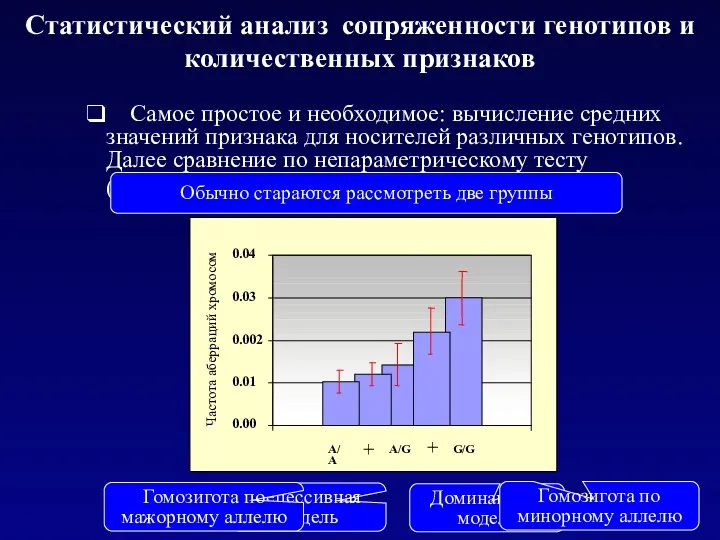
Статистический анализ сопряженности генотипов и количественных признаков
Самое простое и необходимое:
Статистический анализ сопряженности генотипов и количественных признаков
Самое простое и необходимое:

Сравнение частот генотипов для групп с низким (или высоким) значением
Сравнение частот генотипов для групп с низким (или высоким) значением
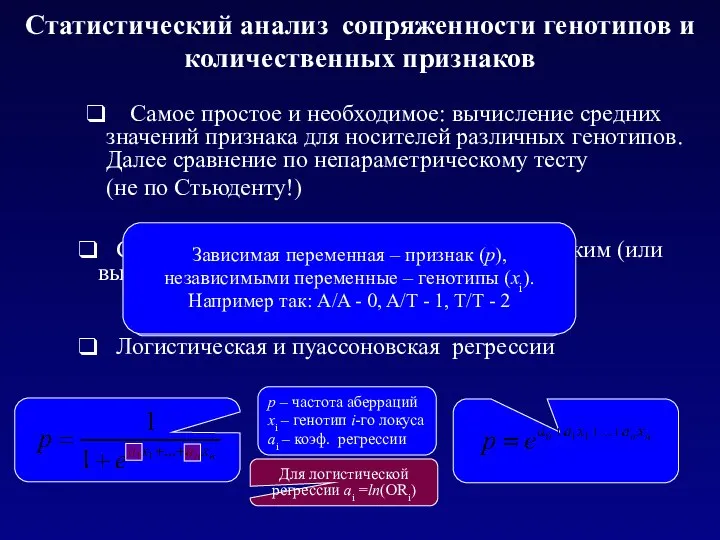
Сравнение частот генотипов для групп с низким (или высоким) значением
Сравнение частот генотипов для групп с низким (или высоким) значением
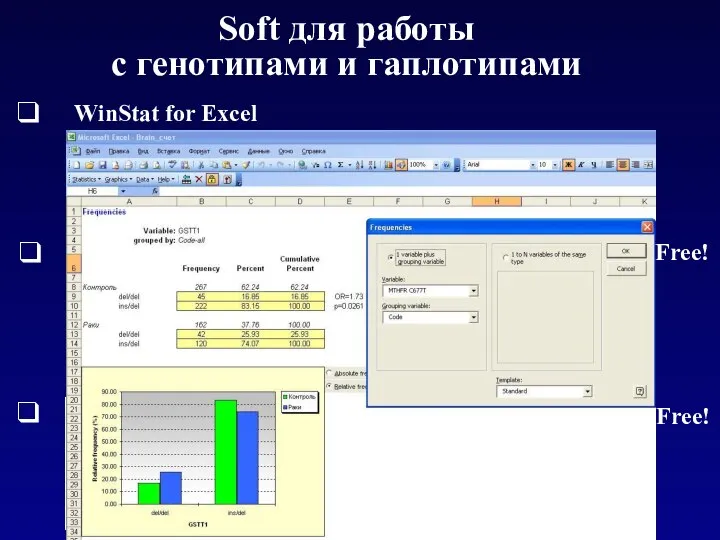
Soft для работы
с генотипами и гаплотипами
WinStat for Excel
Free!
Free!
Soft для работы
с генотипами и гаплотипами
WinStat for Excel
Free!
Free!

Оценка ассоциаций «генотип-фенотип» и их значимости
Факторы, влияющие на
Оценка ассоциаций «генотип-фенотип» и их значимости
Факторы, влияющие на

Чуть-чуть об ошибках статистических тестов
Ошибка I рода (α)
Вероятность отвергнуть правильную
Чуть-чуть об ошибках статистических тестов
Ошибка I рода (α)
Вероятность отвергнуть правильную

От чего зависят ошибки статистических тестов?
От размаха реально существующих отличий
От чего зависят ошибки статистических тестов?
От размаха реально существующих отличий
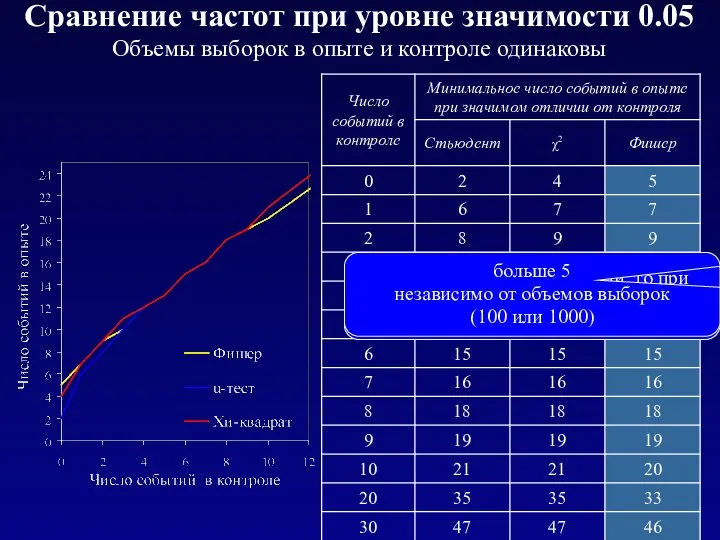
Сравнение частот при уровне значимости 0.05 Объемы выборок в опыте и
Сравнение частот при уровне значимости 0.05 Объемы выборок в опыте и

Оценка ассоциаций «генотип-фенотип» и их значимости
Факторы, влияющие на
Оценка ассоциаций «генотип-фенотип» и их значимости
Факторы, влияющие на

Проверка однородности материала и вычисление OR для нескольких выборок
Выборки можно объединять,
Проверка однородности материала и вычисление OR для нескольких выборок
Выборки можно объединять,
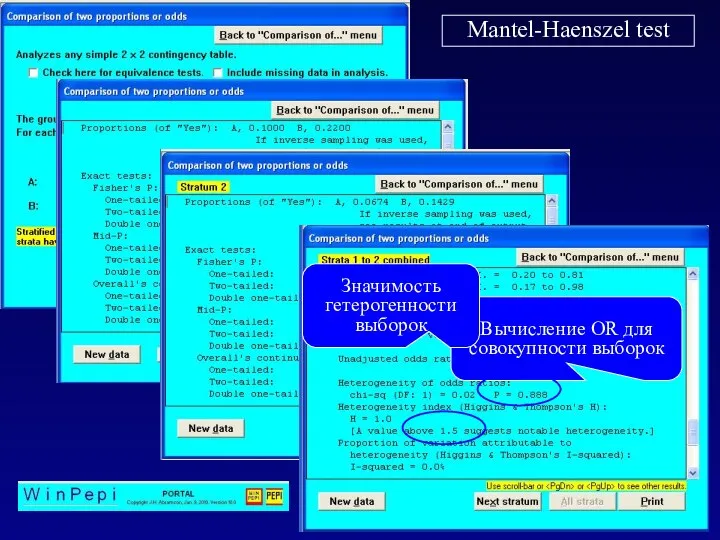
Mantel-Haenszel test
Mantel-Haenszel test
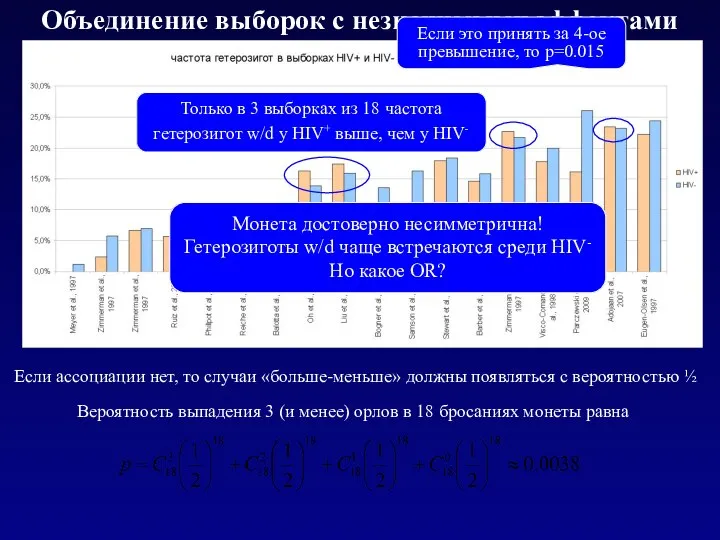
Объединение выборок с незначимыми эффектами
Если ассоциации нет, то случаи «больше-меньше» должны
Объединение выборок с незначимыми эффектами
Если ассоциации нет, то случаи «больше-меньше» должны
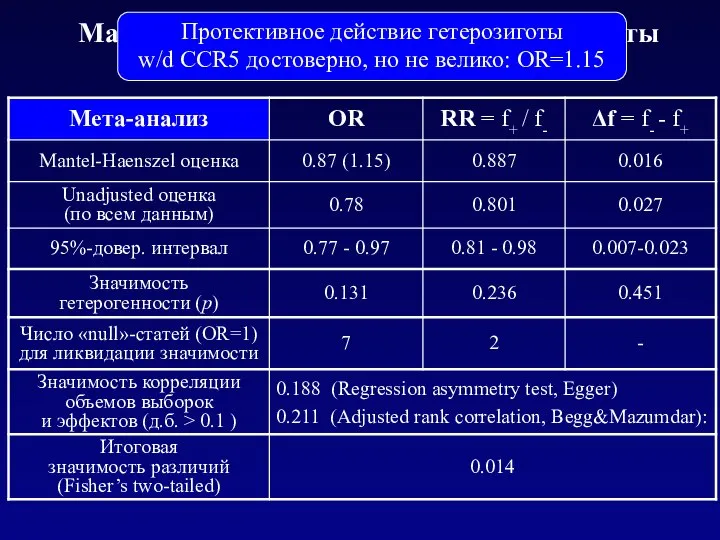
Mantel-Haenszel test with WinPepi: результаты
Протективное действие гетерозиготы
w/d CCR5 достоверно, но
Mantel-Haenszel test with WinPepi: результаты
Протективное действие гетерозиготы
w/d CCR5 достоверно, но

Оценка ассоциаций «генотип-фенотип» и их значимости
Факторы, влияющие на
Оценка ассоциаций «генотип-фенотип» и их значимости
Факторы, влияющие на
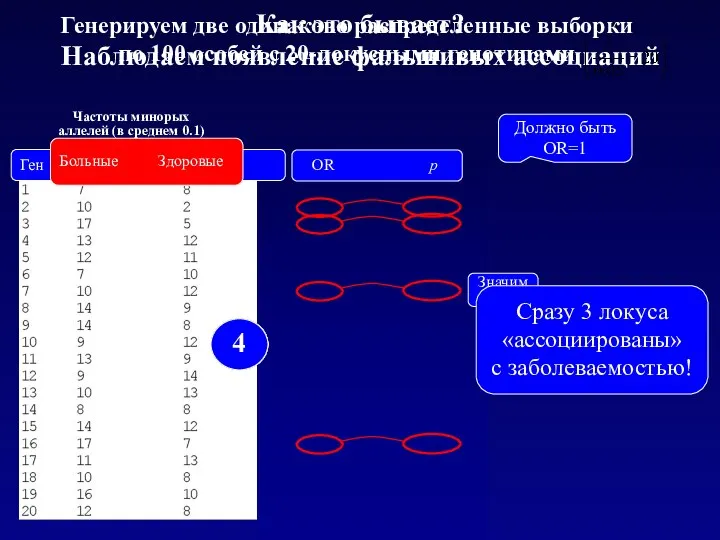
Генерируем две одинаково распределенные выборки
по 100 особей с 20-локусными генотипами
Как
Генерируем две одинаково распределенные выборки
по 100 особей с 20-локусными генотипами
Как

Как избежать фальшивых открытий?
False Discovery Rate control: FDR - контроль
Как избежать фальшивых открытий?
False Discovery Rate control: FDR - контроль
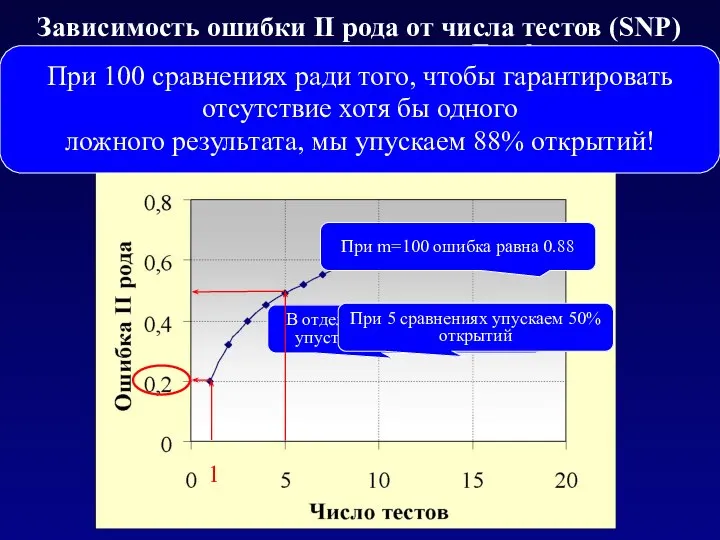
Зависимость ошибки II рода от числа тестов (SNP) при использовании поправки
Зависимость ошибки II рода от числа тестов (SNP) при использовании поправки
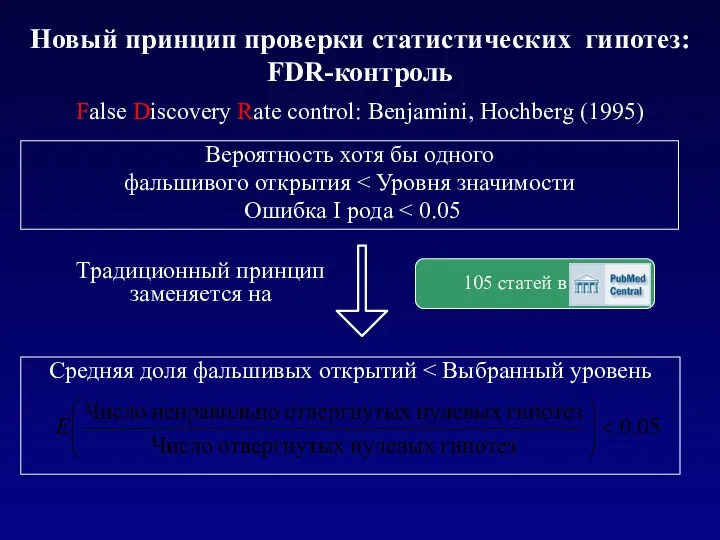
Новый принцип проверки статистических гипотез: FDR-контроль
False Discovery Rate control: Benjamini,
Новый принцип проверки статистических гипотез: FDR-контроль
False Discovery Rate control: Benjamini,
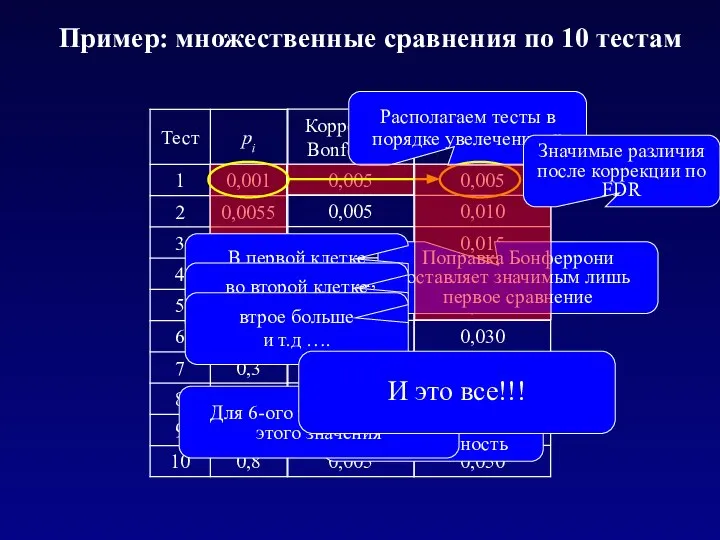
Пример: множественные сравнения по 10 тестам
Значимые различия без поправок на множественность
Располагаем
Пример: множественные сравнения по 10 тестам
Значимые различия без поправок на множественность
Располагаем

Permutation tests:
случайные перестановки пометок «case-control»
в компьютерных симуляциях по алгоритму:
Что
Permutation tests:
случайные перестановки пометок «case-control»
в компьютерных симуляциях по алгоритму:
Что
 Показательные уравнения и неравенства
Показательные уравнения и неравенства Операции над графами
Операции над графами Развитие математики в России
Развитие математики в России Решение задач алгебраическим способом. 5 класс
Решение задач алгебраическим способом. 5 класс Изучаем цифры. Помоги белочке собрать запасы на зиму
Изучаем цифры. Помоги белочке собрать запасы на зиму Презентация по математике "Уравнение касательной и нормали к графику функции" - скачать
Презентация по математике "Уравнение касательной и нормали к графику функции" - скачать  Задачи на нахождение 4 пропорционального (3 класс)
Задачи на нахождение 4 пропорционального (3 класс) Бенефис линейной функции. 7 класс
Бенефис линейной функции. 7 класс Решение треугольников. Типы задач на решение треугольников
Решение треугольников. Типы задач на решение треугольников Функция нескольких переменных
Функция нескольких переменных Позиция 7 ЕГЭ 2016. Применение производной к исследованию функций по графику производной. Геометрический смысл производной
Позиция 7 ЕГЭ 2016. Применение производной к исследованию функций по графику производной. Геометрический смысл производной Математическая викторина. 2 тур. Великие и знаменитые
Математическая викторина. 2 тур. Великие и знаменитые Иерархическая кластеризация
Иерархическая кластеризация Арифметическая и геометрическая прогрессии
Арифметическая и геометрическая прогрессии Алгебраические дроби
Алгебраические дроби  Различные способы представления математической информации
Различные способы представления математической информации Векторы (повторение)
Векторы (повторение)  Головоломка пентамино
Головоломка пентамино Высота треугольника ГБОУ СОШ №854 Разработано Учителем математики Филипповой Н.А.
Высота треугольника ГБОУ СОШ №854 Разработано Учителем математики Филипповой Н.А.  Линейные неравенства с одной переменной
Линейные неравенства с одной переменной Вычитание дробных чисел. 5 класс
Вычитание дробных чисел. 5 класс Логика высказываний и булевы алгебры (Boolean Algebra and Logic)
Логика высказываний и булевы алгебры (Boolean Algebra and Logic) Задачи на площади в заданиях ГИА по математике. Задачи на клетчатой бумаге
Задачи на площади в заданиях ГИА по математике. Задачи на клетчатой бумаге Моделирование систем. Имитационные модели, дискретные и на базе дифференциальных уравнений
Моделирование систем. Имитационные модели, дискретные и на базе дифференциальных уравнений Логическое отрицание (инверсия) Логическое умножение (конъюнкция) Логическое сложение (дизъюнкция) Логическое следование (импли
Логическое отрицание (инверсия) Логическое умножение (конъюнкция) Логическое сложение (дизъюнкция) Логическое следование (импли В поисках клада! Интерактивное занятие по математике в средней группе
В поисках клада! Интерактивное занятие по математике в средней группе Возникновение и развитие геометрии
Возникновение и развитие геометрии Теория вероятностей. Статистические методы обработки информации
Теория вероятностей. Статистические методы обработки информации