- Специализированные компьютерные системы. Микропроцессорная техника (лекция 1)

Содержание
- 2. Филиппенко И.В. АПВТ Некоторые определения Микропроцессорная техника включает технические и программные средства, используемые для построения различных
- 3. Филиппенко И.В. АПВТ Микроконтроллер Термин «микроконтроллер» (МК) вытеснил из употребления термин «однокристальная микро-ЭВМ». На одном кристалле
- 4. Филиппенко И.В. АПВТ Проектирование (этапы) При разработке системы любого назначения на базе микроконтроллеров, в общем случае,
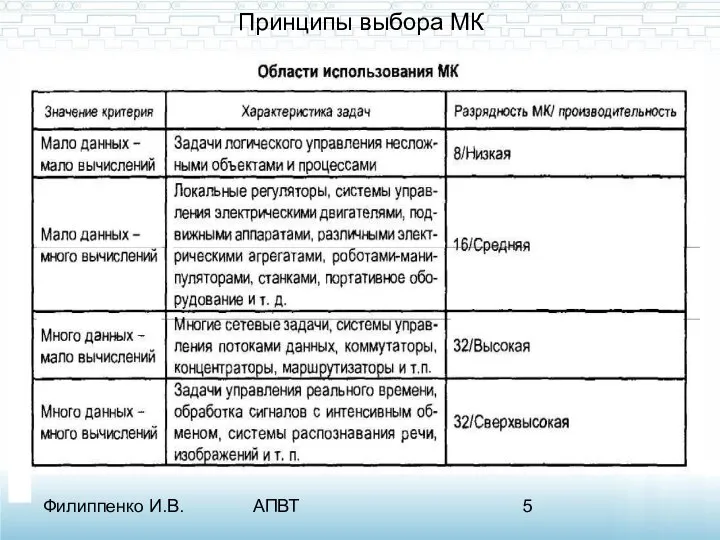
- 5. Филиппенко И.В. АПВТ Принципы выбора МК
- 6. Филиппенко И.В. АПВТ Архитектура микропроцессора Архитектурой процессора называется комплекс его аппаратных и программных средств, предоставляемых пользователю
- 7. Филиппенко И.В. АПВТ Архитектура МП ( CISC ) CISC (Complex Instruction Set Computer) – архитектура peaлизована
- 8. Филиппенко И.В. АПВТ Архитектура МП ( RISC ) RISC (Reduced Instruction Set Computer) - архитектура отличается
- 9. Филиппенко И.В. АПВТ Архитектура МП (VLIW) Very Large Instruction Word) – архитектура появилась относительно недавно -в
- 10. Филиппенко И.В. АПВТ Фон-Нейман, Гарвард Кроме набора выполняемых команд и способов адресации важной архитектурной особенностью микропроцессоров
- 11. Филиппенко И.В. АПВТ Гарвард vs Фон Нейман
- 12. Филиппенко И.В. АПВТ Архитектура Фон-Неймана (Принстонская архитектура) Принстонская архитектура (Фон-Неймана), характеризуется использованием общей оперативной памяти для
- 13. Филиппенко И.В. АПВТ «Бутылочное горлышко» архитектуры Фон-Неймана A common bus is used for data as well
- 14. Филиппенко И.В. АПВТ Гарвардская архитектура Гарвардская архитектура характеризуется физическим разделением памяти команд (программ) и памяти данных.
- 15. Филиппенко И.В. АПВТ Гарвардская архитектура Гарвардская архитектура почти не использовалась до конца 70-х. Separate data and
- 16. Филиппенко И.В. АПВТ Конвейер Во внутренней структуре современных высокопроизводительных микропроцессоров реализуется конвейерный принцип выполнения команд. При
- 17. Филиппенко И.В. АПВТ Ожидание, простой Эффективная работа конвейера обеспечивается только при его равномерной загрузке однотипными командами.
- 18. Филиппенко И.В. АПВТ Эффективность использования конвейера Эффективность использования конвейера определяется типом поступающих команд При поступлении однородных
- 19. Филиппенко И.В. АПВТ Предсказания ветвлений Если выполняется условие ветвления, то приходится производить перезагрузку конвейера командами из
- 20. Филиппенко И.В. АПВТ Структура микропроцессорного устройства Системная шина содержит большое количество проводников, которые в соответствии с
- 21. Филиппенко И.В. АПВТ Архитектура Фон Неймана (Принстонская) Упрощенная структура МПС принстонской архитектуры (фон-Неймана), использующая трехшинную магистраль.
- 22. Филиппенко И.В. АПВТ Системная шина В первых двух случаях передачей данных управляет процессор. Память или интерфейс
- 23. Филиппенко И.В. АПВТ ЦПУ, Синхронизация Центральным процессорным устройством (ЦПУ) в системе является микропроцессор (МП), выполняющий арифметические
- 24. Филиппенко И.В. АПВТ Разрядность шины. Шина данных. Шина данных используется как для передачи данных в направлении
- 25. Филиппенко И.В. АПВТ Шина адреса. Все адресное пространство МПС разделено на пространство адресов памяти и пространство
- 26. Филиппенко И.В. АПВТ Шина управления. Основными сигналами, передаваемыми по этой шине, являются сигналы управления записью-чтением из
- 27. Филиппенко И.В. АПВТ Таймеры Таймеры предназначены для формирования временных интервалов, подсчета входных сигналов, деления частоты. Применяются,
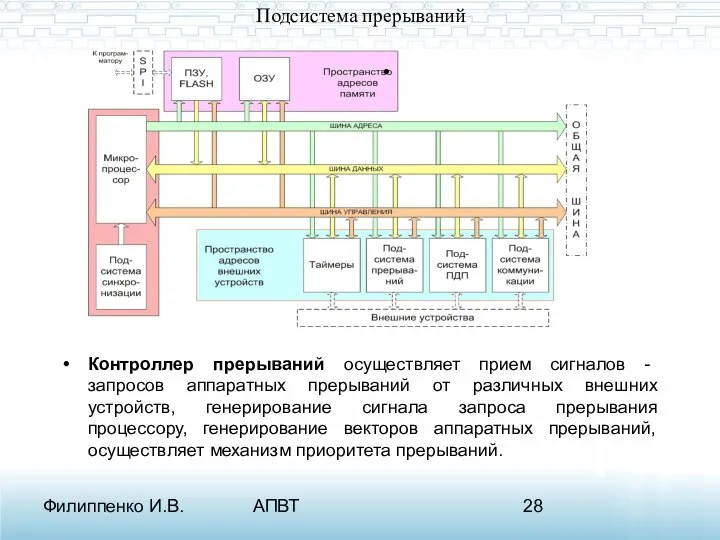
- 28. Филиппенко И.В. АПВТ Подсистема прерываний Контроллер прерываний осуществляет прием сигналов - запросов аппаратных прерываний от различных
- 29. Филиппенко И.В. АПВТ Подсистема прерываний Во всех этих ситуациях микропроцессор завершает выполнение очередной команды и заносит
- 30. Филиппенко И.В. АПВТ Прерывания Аппаратные прерывания могут быть маскируемые или немаскируемые. Запросы маскируемых прерываний обслуживаются только
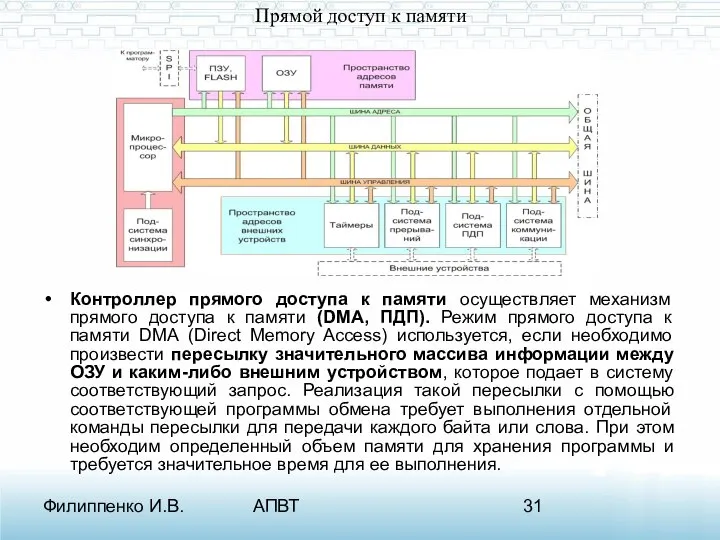
- 31. Филиппенко И.В. АПВТ Прямой доступ к памяти Контроллер прямого доступа к памяти осуществляет механизм прямого доступа
- 32. Филиппенко И.В. АПВТ Механизм ПДП В большинстве современных микропроцессорных систем пересылка массивов информации обеспечивается с помощью
- 34. Скачать презентацию

Филиппенко И.В.
АПВТ
Некоторые определения
Микропроцессорная техника включает технические и программные средства, используемые для
Филиппенко И.В.
АПВТ
Некоторые определения
Микропроцессорная техника включает технические и программные средства, используемые для

Филиппенко И.В.
АПВТ
Микроконтроллер
Термин «микроконтроллер» (МК) вытеснил из употребления термин «однокристальная микро-ЭВМ».
На
Филиппенко И.В.
АПВТ
Микроконтроллер
Термин «микроконтроллер» (МК) вытеснил из употребления термин «однокристальная микро-ЭВМ».
На

Филиппенко И.В.
АПВТ
Проектирование (этапы)
При разработке системы любого назначения на базе микроконтроллеров, в
Филиппенко И.В.
АПВТ
Проектирование (этапы)
При разработке системы любого назначения на базе микроконтроллеров, в
Филиппенко И.В.
АПВТ
Принципы выбора МК
Филиппенко И.В.
АПВТ
Принципы выбора МК

Филиппенко И.В.
АПВТ
Архитектура микропроцессора
Архитектурой процессора называется комплекс его аппаратных и программных средств,
Филиппенко И.В.
АПВТ
Архитектура микропроцессора
Архитектурой процессора называется комплекс его аппаратных и программных средств,

Филиппенко И.В.
АПВТ
Архитектура МП ( CISC )
CISC (Complex Instruction Set Computer) –
Филиппенко И.В.
АПВТ
Архитектура МП ( CISC )
CISC (Complex Instruction Set Computer) –

Филиппенко И.В.
АПВТ
Архитектура МП ( RISC )
RISC (Reduced Instruction Set Computer) -
Филиппенко И.В.
АПВТ
Архитектура МП ( RISC )
RISC (Reduced Instruction Set Computer) -

Филиппенко И.В.
АПВТ
Архитектура МП (VLIW)
Very Large Instruction Word) – архитектура появилась относительно
Филиппенко И.В.
АПВТ
Архитектура МП (VLIW)
Very Large Instruction Word) – архитектура появилась относительно

Филиппенко И.В.
АПВТ
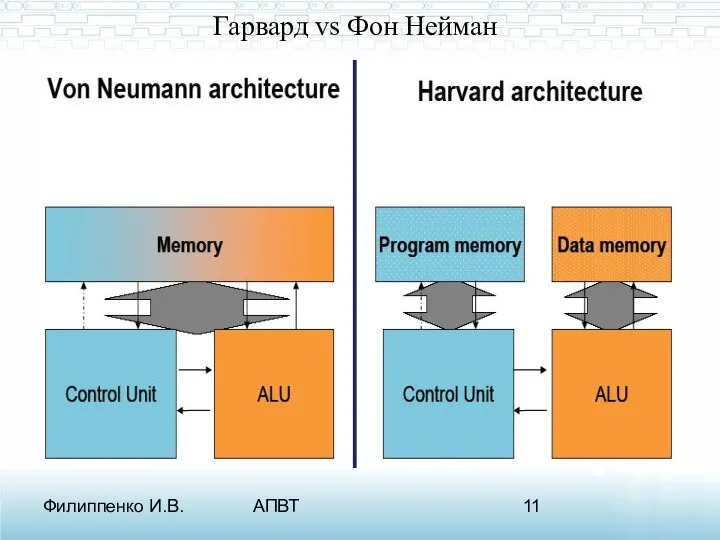
Фон-Нейман, Гарвард
Кроме набора выполняемых команд и способов адресации важной архитектурной
Филиппенко И.В.
АПВТ
Фон-Нейман, Гарвард
Кроме набора выполняемых команд и способов адресации важной архитектурной
Филиппенко И.В.
АПВТ
Гарвард vs Фон Нейман
Филиппенко И.В.
АПВТ
Гарвард vs Фон Нейман

Филиппенко И.В.
АПВТ
Архитектура Фон-Неймана (Принстонская архитектура)
Принстонская архитектура (Фон-Неймана), характеризуется использованием общей оперативной
Филиппенко И.В.
АПВТ
Архитектура Фон-Неймана (Принстонская архитектура)
Принстонская архитектура (Фон-Неймана), характеризуется использованием общей оперативной
Филиппенко И.В.
АПВТ
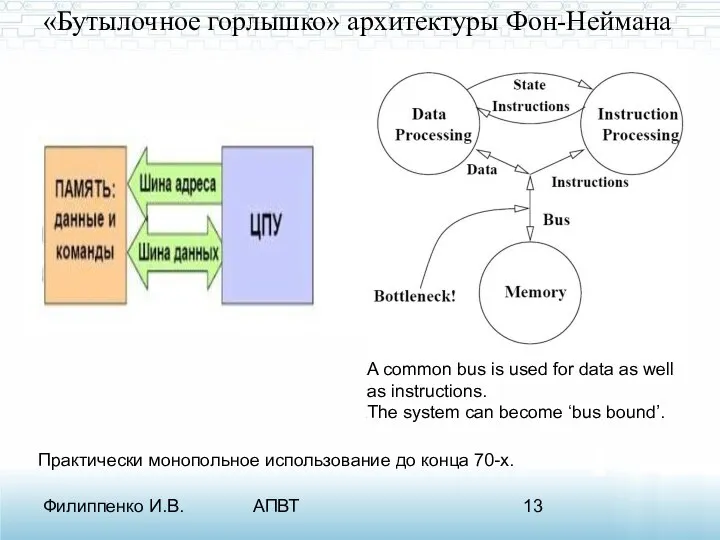
«Бутылочное горлышко» архитектуры Фон-Неймана
A common bus is used for data
Филиппенко И.В.
АПВТ
«Бутылочное горлышко» архитектуры Фон-Неймана
A common bus is used for data

Филиппенко И.В.
АПВТ
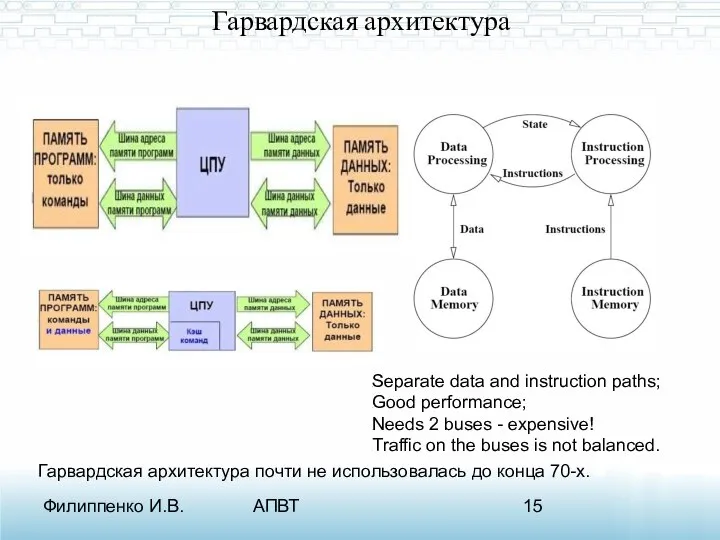
Гарвардская архитектура
Гарвардская архитектура характеризуется физическим разделением памяти команд (программ) и
Филиппенко И.В.
АПВТ
Гарвардская архитектура
Гарвардская архитектура характеризуется физическим разделением памяти команд (программ) и
Филиппенко И.В.
АПВТ
Гарвардская архитектура
Гарвардская архитектура почти не использовалась до конца 70-х.
Separate data
Филиппенко И.В.
АПВТ
Гарвардская архитектура
Гарвардская архитектура почти не использовалась до конца 70-х.
Separate data
Филиппенко И.В.
АПВТ
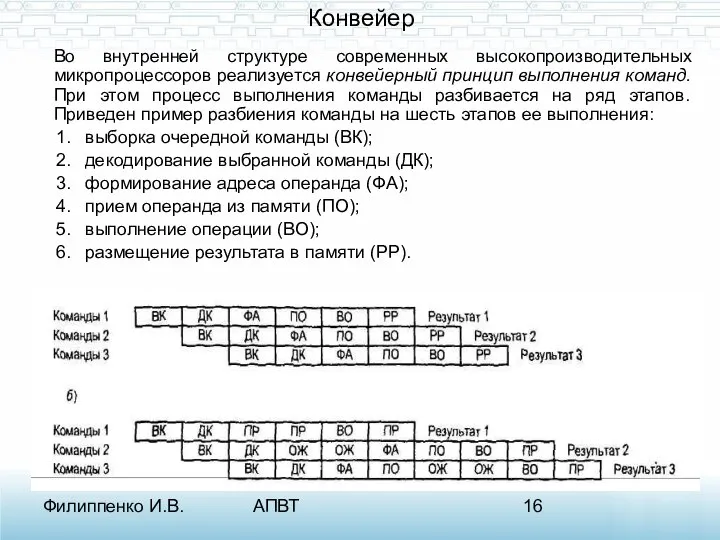
Конвейер
Во внутренней структуре современных высокопроизводительных микропроцессоров реализуется конвейерный принцип выполнения
Филиппенко И.В.
АПВТ
Конвейер
Во внутренней структуре современных высокопроизводительных микропроцессоров реализуется конвейерный принцип выполнения

Филиппенко И.В.
АПВТ
Ожидание, простой
Эффективная работа конвейера обеспечивается только при его равномерной
Филиппенко И.В.
АПВТ
Ожидание, простой
Эффективная работа конвейера обеспечивается только при его равномерной

Филиппенко И.В.
АПВТ
Эффективность использования конвейера
Эффективность использования конвейера определяется типом поступающих команд
При
Филиппенко И.В.
АПВТ
Эффективность использования конвейера
Эффективность использования конвейера определяется типом поступающих команд
При

Филиппенко И.В.
АПВТ
Предсказания ветвлений
Если выполняется условие ветвления, то приходится производить перезагрузку конвейера
Филиппенко И.В.
АПВТ
Предсказания ветвлений
Если выполняется условие ветвления, то приходится производить перезагрузку конвейера
Филиппенко И.В.
АПВТ
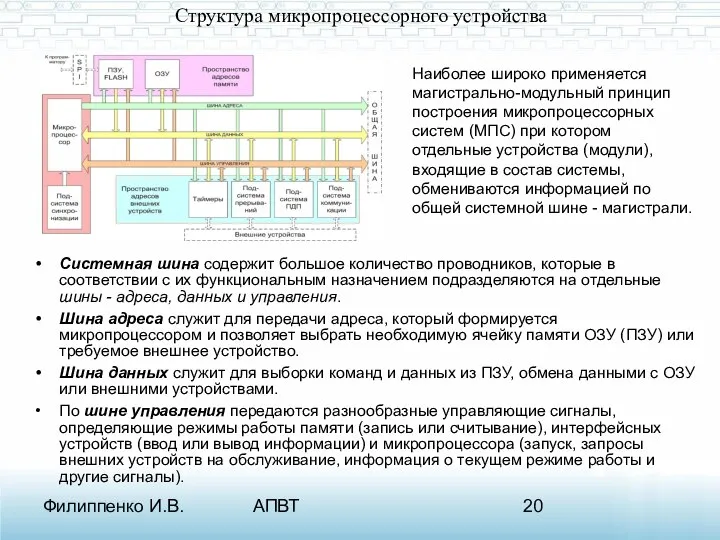
Структура микропроцессорного устройства
Системная шина содержит большое количество проводников, которые в
Филиппенко И.В.
АПВТ
Структура микропроцессорного устройства
Системная шина содержит большое количество проводников, которые в
Филиппенко И.В.
АПВТ
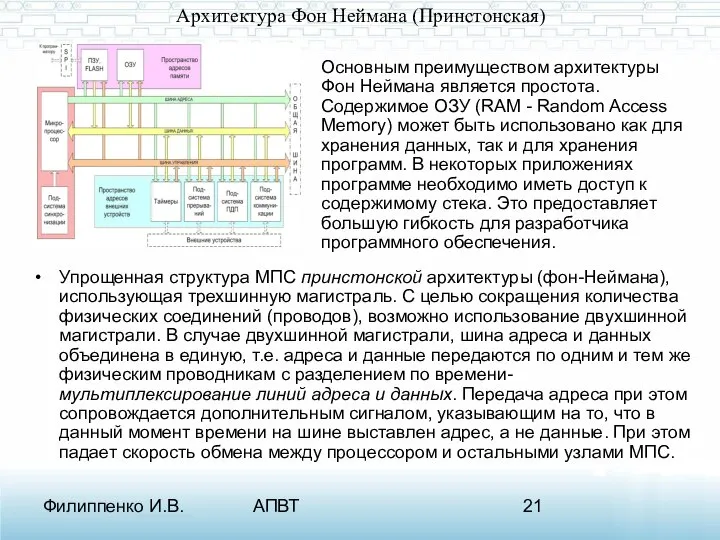
Архитектура Фон Неймана (Принстонская)
Упрощенная структура МПС принстонской архитектуры (фон-Неймана), использующая
Филиппенко И.В.
АПВТ
Архитектура Фон Неймана (Принстонская)
Упрощенная структура МПС принстонской архитектуры (фон-Неймана), использующая
Филиппенко И.В.
АПВТ
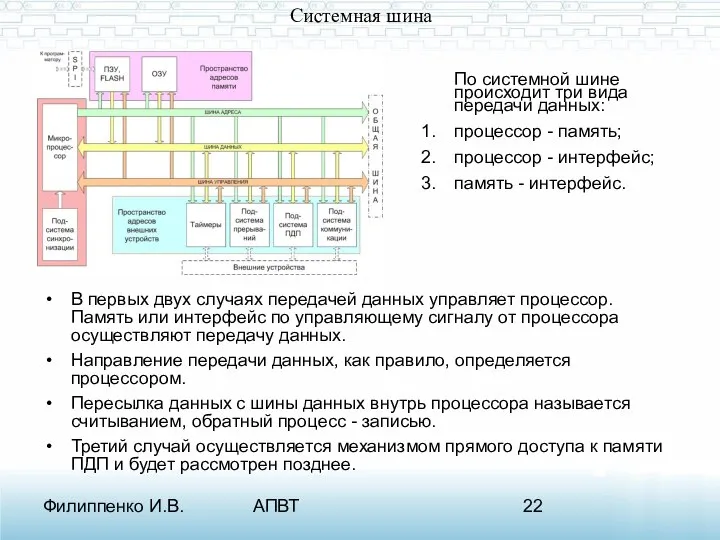
Системная шина
В первых двух случаях передачей данных управляет процессор. Память
Филиппенко И.В.
АПВТ
Системная шина
В первых двух случаях передачей данных управляет процессор. Память
Филиппенко И.В.
АПВТ
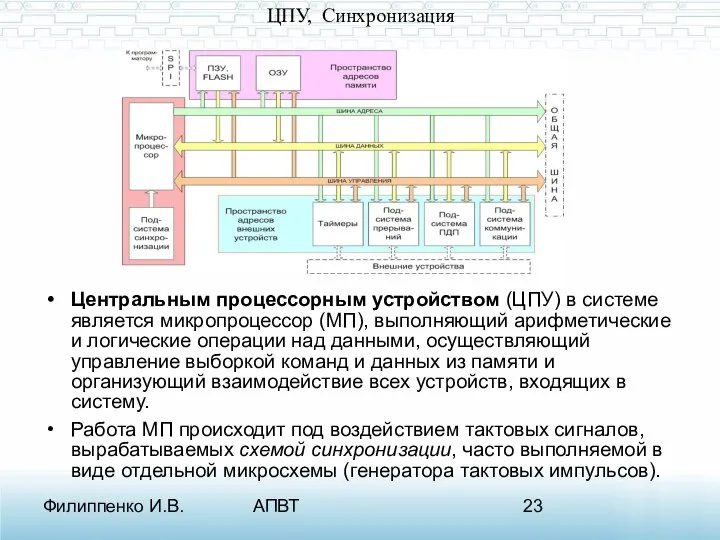
ЦПУ, Синхронизация
Центральным процессорным устройством (ЦПУ) в системе является микропроцессор (МП),
Филиппенко И.В.
АПВТ
ЦПУ, Синхронизация
Центральным процессорным устройством (ЦПУ) в системе является микропроцессор (МП),
Филиппенко И.В.
АПВТ
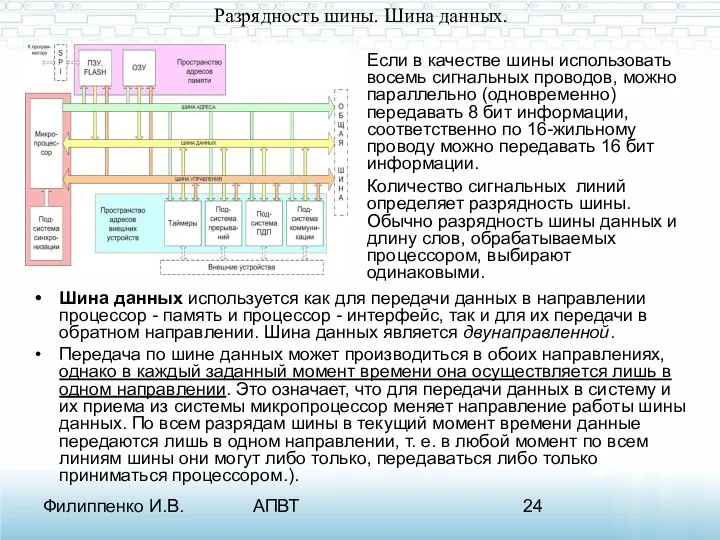
Разрядность шины. Шина данных.
Шина данных используется как для передачи данных
Филиппенко И.В.
АПВТ
Разрядность шины. Шина данных.
Шина данных используется как для передачи данных

Филиппенко И.В.
АПВТ
Шина адреса.
Все адресное пространство МПС разделено на пространство адресов памяти
Филиппенко И.В.
АПВТ
Шина адреса.
Все адресное пространство МПС разделено на пространство адресов памяти
Филиппенко И.В.
АПВТ
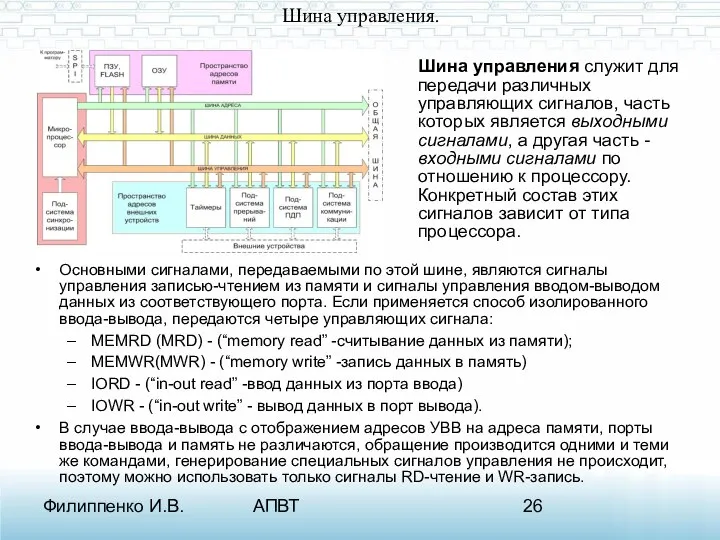
Шина управления.
Основными сигналами, передаваемыми по этой шине, являются сигналы управления
Филиппенко И.В.
АПВТ
Шина управления.
Основными сигналами, передаваемыми по этой шине, являются сигналы управления
Филиппенко И.В.
АПВТ
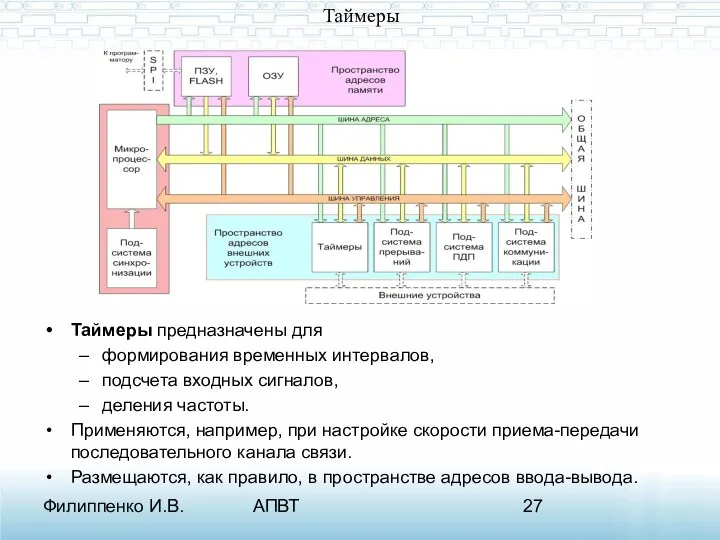
Таймеры
Таймеры предназначены для
формирования временных интервалов,
подсчета входных сигналов,
деления
Филиппенко И.В.
АПВТ
Таймеры
Таймеры предназначены для
формирования временных интервалов,
подсчета входных сигналов,
деления
Филиппенко И.В.
АПВТ
Подсистема прерываний
Контроллер прерываний осуществляет прием сигналов - запросов аппаратных прерываний
Филиппенко И.В.
АПВТ
Подсистема прерываний
Контроллер прерываний осуществляет прием сигналов - запросов аппаратных прерываний

Филиппенко И.В.
АПВТ
Подсистема прерываний
Во всех этих ситуациях микропроцессор завершает выполнение очередной команды
Филиппенко И.В.
АПВТ
Подсистема прерываний
Во всех этих ситуациях микропроцессор завершает выполнение очередной команды

Филиппенко И.В.
АПВТ
Прерывания
Аппаратные прерывания могут быть маскируемые или немаскируемые.
Запросы маскируемых прерываний обслуживаются
Филиппенко И.В.
АПВТ
Прерывания
Аппаратные прерывания могут быть маскируемые или немаскируемые.
Запросы маскируемых прерываний обслуживаются
Филиппенко И.В.
АПВТ
Прямой доступ к памяти
Контроллер прямого доступа к памяти осуществляет механизм
Филиппенко И.В.
АПВТ
Прямой доступ к памяти
Контроллер прямого доступа к памяти осуществляет механизм

Филиппенко И.В.
АПВТ
Механизм ПДП
В большинстве современных микропроцессорных систем пересылка массивов информации обеспечивается
Филиппенко И.В.
АПВТ
Механизм ПДП
В большинстве современных микропроцессорных систем пересылка массивов информации обеспечивается
 Проверка адекватности модели
Проверка адекватности модели Интегральные микросхемы
Интегральные микросхемы 20170522_5-6_klass
20170522_5-6_klass Dezvoltarea încrederii în sine în cadrul serviciului militar
Dezvoltarea încrederii în sine în cadrul serviciului militar Петровское время в памяти потомков
Петровское время в памяти потомков Презентацияstate
Презентацияstate История возникновения телевидения
История возникновения телевидения Виды транспорта
Виды транспорта КОУ Школа-интернат №19, учитель истории Богданова Ирина Игоревна
КОУ Школа-интернат №19, учитель истории Богданова Ирина Игоревна конкурс Лучший фармацевт
конкурс Лучший фармацевт Холодильные установки на транспорте
Холодильные установки на транспорте Книги на глиняных дощечках
Книги на глиняных дощечках Указания к выполнению работы №5
Указания к выполнению работы №5 Указания по устойчивости энергосистем. Понятия, термины и определения
Указания по устойчивости энергосистем. Понятия, термины и определения Пингвины. Выразительность материалов для работы в объеме
Пингвины. Выразительность материалов для работы в объеме Постреанимационная болезнь
Постреанимационная болезнь Заставка
Заставка Храмы Донбасса
Храмы Донбасса Системные вопросы проектирования автомобильных радаров
Системные вопросы проектирования автомобильных радаров Les vêtements
Les vêtements Картинки для малышей
Картинки для малышей 20151113_zanyatie_t_t
20151113_zanyatie_t_t Романские храмы и монастыри
Романские храмы и монастыри The puzzle
The puzzle Задачи и методы машинного обучения
Задачи и методы машинного обучения Проект_КДЦ_Москва_#ОБЪЕДИНЕННЫЕ_СМЫСЛОМ
Проект_КДЦ_Москва_#ОБЪЕДИНЕННЫЕ_СМЫСЛОМ Эко транспорт Сигвей
Эко транспорт Сигвей Профессиональное образование глазами студентов
Профессиональное образование глазами студентов